K8S in Action 讀後感(概念簡介)
一、K8S的用武之地
今天,大型單體應用正被逐漸拆分成小的、可獨立執行的元件,我們稱之為微服務。微服務彼此之間解耦,所以它們可以被獨立開發、部署、升級、伸縮。這使得我們可以對每一個微服務實現快速迭代,並且迭代的速度可以和市場需求變化的速度保持一致。
但是,隨著部署元件的增多和資料中心的增長,設定、管理並保持系統的正常執行變得越來越困難。如果我們想要獲得足夠高的資源利用率並降低硬體成本,把元件部署在什麼地方變得越來越難以決策。手動做所有的事情,顯然不太可行。我們需要一些自動化的措施,包括自動排程、設定、監管和故障處理。這正是K8S的用武之地。
K8S抽象了資料中心的硬體基礎設施,使得對外暴露的只是一個巨大的資源池。它讓我們在部署和執行元件時,不用關注底層的伺服器。使用K8S部署多元件應用時,它會為每個元件都選擇一臺合適的伺服器,部署之後它能夠保證每個元件可以輕易地發現其他元件,並彼此之間實現通訊。
通過K8S部署應用程式時,你的叢集包含多少節點都是一樣的。叢集規模不會造成什麼差異性,額外的叢集節點只是代表一些額外的可用來部署應用的資源。
二、K8S叢集架構
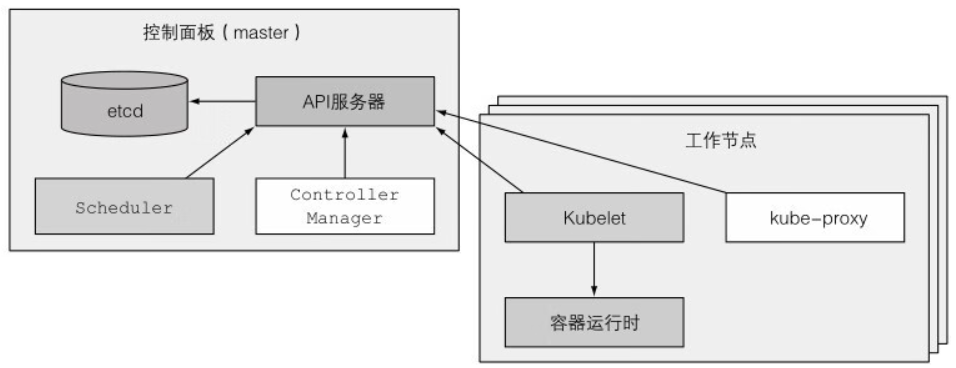
一個K8S叢集由多個節點組成,節點可分為兩種型別:
主節點:負責管理和排程工作節點
工作節點:負責執行部署的應用程式,每臺伺服器都是一個工作節點(主節點除外)
API伺服器:主節點和工作節點的通訊媒介
Scheduler:負責排程應用(為應用的每個可部署元件分配一個工作節點)
Controller Manager:它執行叢集級別的功能,如複製元件、持續跟蹤工作節點、處理失敗節點等。
etcd:持久化儲存叢集設定
容器執行時:Docker、Containerd、RTK或其他容器型別。
Kubelet:管理所在的節點的容器
Kube-Proxy:負責元件之間的負載均衡網路流量
三、容器的隔離機制
一個容器裡執行的程序實際上執行在宿主機的作業系統上,就像所有其他程序一樣(不像虛擬機器器,程序是執行在不同的作業系統上的)。但在容器裡的程序仍然是和其他程序隔離的。對於容器內程序本身而言,就好像是在機器和作業系統上執行的唯一一個程序。
容器的隔離機制主要依靠 Linux 名稱空間 namespace 和 Linux 控制組 cgroups。namespace 提供隔離檢視(檔案、程序、網路介面、主機名等),cgroups 限制程序可使用的資源(CPU、記憶體、網路頻寬等)。
預設情況下,每個 Linux 系統最初僅有一個名稱空間,所有系統資源都屬於這一個名稱空間,但是你能建立額外的名稱空間,以及在它們之間組織資源。這就是容器的隔離機制。
四、K8S的最小單位 pod
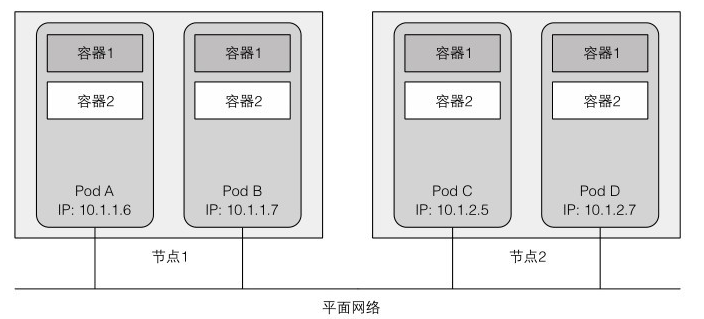
一個 pod 由一個或一組緊密相關的容器組成,它們總是一起執行在同一個工作節點上。
每個 pod 就像是一個獨立的邏輯機器,擁有自己的 IP,即使不同的 pod 執行在同一個工作節點,它們也是獨立的。
前面我們講到容器的隔離機制是通過 namespace 和 cgroup 來實現的,一個 pod 內的容器,或者說是容器組通常需要共用某些資源,K8S 通過設定 Docker 來讓一個 pod 內的所有容器共用相同的 network 和 UTS 名稱空間,這樣它們都有相同的主機名和網路介面。但這也意味著在同一 pod 中的容器執行的多個程序不能繫結到相同的埠號,否則會導致埠衝突,這也表示著一個道理有共用就有衝突。
K8S 叢集中的所有 pod 都在同一個共用網路地址空間中,每個 pod 都可以通過其他 pod 的 IP 地址來實現相互存取。
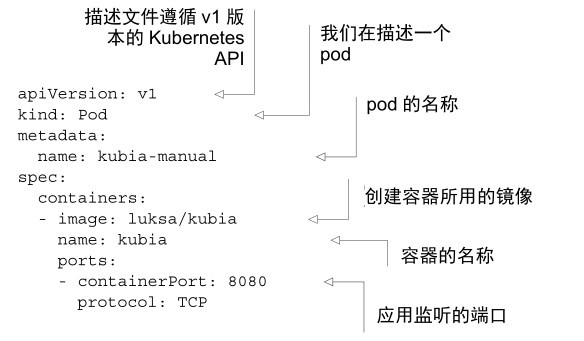
pod 的定義
已部署 pod 的 yaml 通常包含三個部分:
metadata:包括名稱、名稱空間、標籤和關於該容器的其他資訊
spec:包含 pod 內容的實際說明,例如 pod 的容器、卷和其他資料
status:包含執行中的 pod 的當前資訊(建立新的 pod 不需要這一部分)
一個簡單的 pod 定義 yaml:
五、pod 的建立和管理者
pod 並不是直接建立出來的,它是通過 ReplicatiionController、ReplicaSet 或 Deployment......等方式建立出來的。
ReplicaSet 是 ReplicationController 的升級版,ReplicaSet 在標籤選擇器上擁有更強大的選擇功能。
但是 ReplicaSet 也很少使用,我們通常用更高階的資源物件 Deployment,它會建立 ReplicaSet 來建立和管理 pod。
當然還有一些其他資源物件如:DaemonSet、Job、CronJob.....等等。
六、服務
由於 pod 是動態的,為了高可用並且通常不是單節點,沒有一個固定存取的 IP。前面提到過K8S擁有負載均衡和彈性伸縮的能力,它提供了服務這個資源物件。如果想要從叢集外部存取 pod 的話,就需要藉助 LoadBalancer 服務來存取,LoadBalancer 服務擁有一個不變的 IP,這樣 pod 就可以自由的伸縮了。
服務有多種,LoadBalancer 服務相當於是對叢集外部的,Service 是對叢集內部的,主要目的就是使叢集內部的其他 pod 可以存取當前這組 pod,叢集外部是沒法存取這個 IP的。
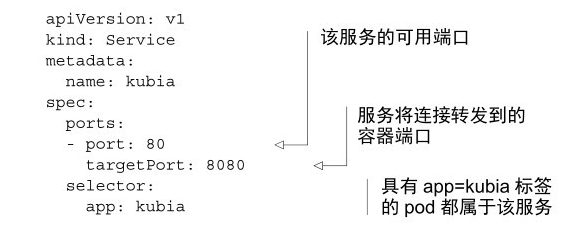
另外,服務並不是和 pod 直接相連的,相反,有一種資源介於兩者之間,它就是 Endpoint 資源,Endpoint 資源就是暴露一個服務的 IP 地址和埠的列表。
如果建立不包含 pod 選擇器的服務,K8S 將不會建立 Endpoint 資源(畢竟缺少選擇器,不知道服務中包含哪些 pod),你可能會想為什麼要用 Endpoint 資源,直接用選擇器不行嘛。儘管在 spec 服務中定義了 pod 選擇器,但在重定向傳入連線時不會直接使用它。相反,選擇器用於構建 IP 和埠列表,然後儲存在 Endpoint 資源中。當用戶端連線到服務時,服務代理選擇這些 IP 和埠中的一個,並將連線重定向到該位置監聽的伺服器。另外,Endpoint 物件需要與服務具有相同的名稱,幷包含該服務的目標 IP 地址和埠列表。如果不是手動建立 Endpoint,Endpoint 對於開發者來說幾乎是無感的。
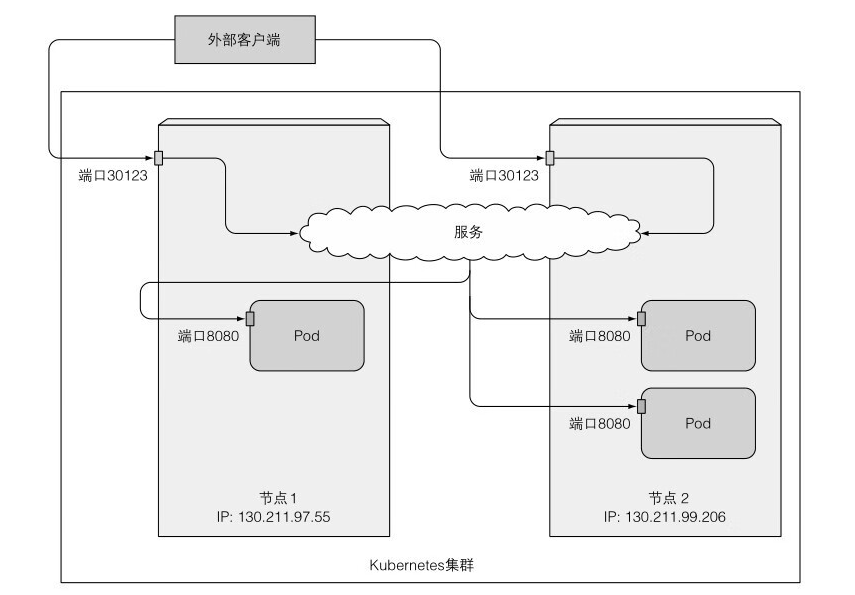
前面說到的都是將服務暴露給叢集內部(LoadBalancer除外),如果想將服務暴露給叢集外部,可以將服務的型別設定為 NodePort,這樣每個叢集節點都會在節點上開啟一個埠,然後將埠上收到的流量重定向到基礎服務。
如圖所示:
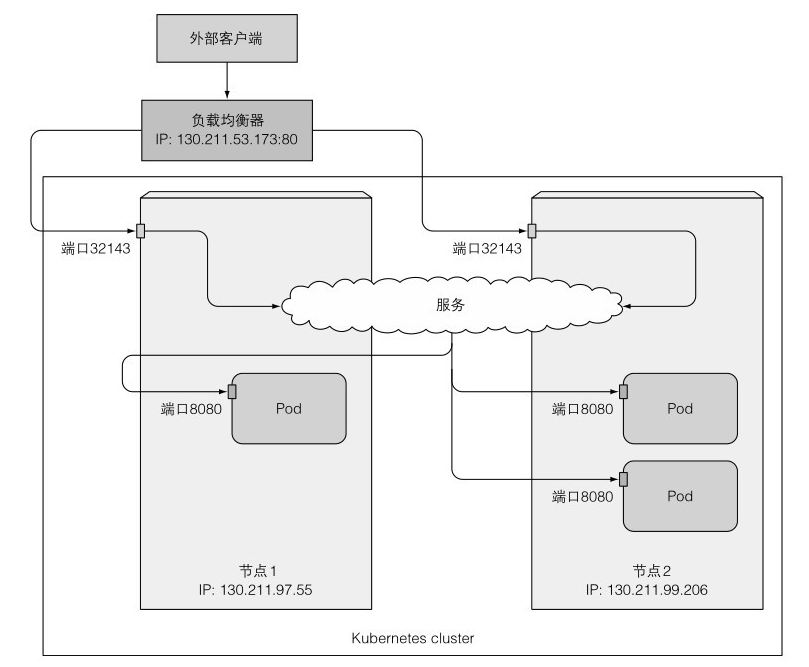
當然也可以將服務的型別設定為 LoadBalancer,它是 NodePort 型別的一種擴充套件,這使得服務可以通過一個專用的負載均衡器來存取,這是有 K8S 中正在執行的雲基礎設施提供的。負載均衡器將流量重定向到跨所有節點的節點埠,使用者端通過負載均衡器的 IP 連線到服務。
如圖所示:
還可以通過 Ingress 資源,這是一種完全不同的機制,通過一個 IP 地址公開多個服務。
七、標籤、註解和名稱空間
標籤可用於組織 pod,也可組織所有其他的 K8S 資源。一個資源可以擁有多個標籤,通常我們在建立資源的時候就會將標籤附件到資源上,但也可以之後新增標籤或修改標籤。

標籤是一個鍵值對,上面就是 creation_method 和 env 兩個標籤。另外,上面說了標籤不僅用於組織 pod,還可以組織其他 K8S 資源,比如你的 pod 對硬體有特定要求,比如需要 GPU 等特殊資源,你還可以對節點打標籤。讓 pod 排程到擁有該標籤的節點上。

除標籤外,pod 和其它物件還可以包含註解。註解也是鍵值對,所以它們非常相似。但是註解不是用於儲存標識資訊而存在的,因為已經有標籤了,註解主要用於工具使用。
標籤是用於組織資源的,由於每個物件都可以擁有多個標籤,因此這些物件組是可以重疊的,另外當在叢集中工作時,如果沒有明確指定標籤選擇器,我們總能看到所有物件。
但是,當你想將物件分割成完全獨立且不重疊的組時,就需要用到名稱空間了。這個名稱空間和 Linux 名稱空間不一樣,這個僅為物件名稱提供一個作用域。
八、健康檢查
K8S 可以通過存活探針檢查容器是否還在執行。可以為 pod 中的每個容器指定存活探針。如果探測失敗,K8S 將定期執行探針並重新啟動容器。
HTTP GET 探針:對給定的URL執行 GET 請求,如果探測器收到相應,並且狀態碼不代表錯誤,則探測成功。
TCP 通訊端探針:嘗試與容器指定埠建立 TCP 連線,如果連線建立成功,則探測成功。
Exec 探針:在容器內執行任意命令,並檢查命令的退出狀態碼。如果狀態碼是 0,則探測成功。
九、ReplicationController、ReplicaSet、DaemonSet、Job、CronJob
ReplicationController 是一種 K8S 資源,可確保它的 pod 始終保持執行狀態,如果 pod 因任何原因消失,則 ReplicationController 會注意到缺少了的 pod 並建立替代 pod。
ReplicationController 會持續監控正在執行的 pod 列表,並保 pod 的數目與期望相符,如果執行的 pod 太少則會建立新副本,否則會刪除多餘副本。
一個 ReplicationController 有三個主要部分:
Label Selector(標籤選擇器):確定 ReplicationController 作用域中有哪些 pod
Replica Count(副本個數):指定應執行的 pod 數量
Pod Template(pod 模板):用於建立新的 pod 副本
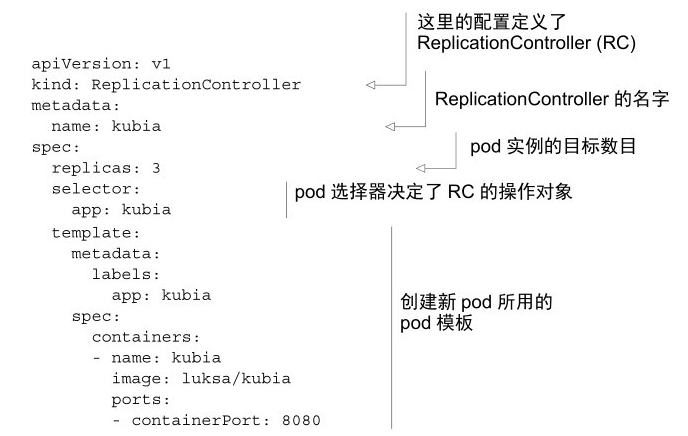
ReplicaSet 的行為和 ReplicationController 完全相同,但 pod 選擇器的表達能力更強,可完全替代 ReplicationController。

DaemonSet 和 ReplicaSet 的區別是,它會在每個節點上都執行一個 pod,比如紀錄檔收集器和資源監控器就有這樣的需求。

前面介紹的都是需要持續執行的 pod,如果你想要執行完成工作後就終止任務的情況就需要用到 Job。
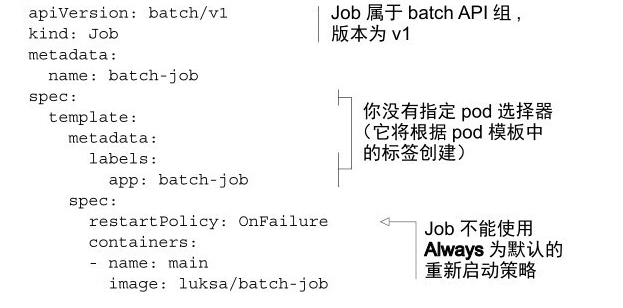
Job 資源在建立時會立即執行 pod,但是更多的需求是定時執行,這就要用到 CronJob。

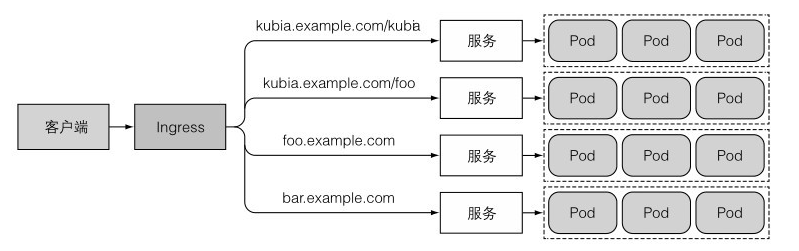
十、Ingress
為什麼需要 Ingress,一個重要的原因是每個 LoadBalancer 服務都需要自己的負載均衡器,以及獨有的公有 IP 地址,而 Ingress 只需要一個公網 IP 就能為許多服務提供存取。當用戶端向 Ingress 發生 HTTP 請求時,Ingress 會根據請求的主機名和路徑決定請求轉發到的服務,如圖所示:
十一、就緒探針
不知道你有沒有考慮到這麼一種情況,如果 pod 的標籤與服務的 pod 選擇器相匹配,那麼 pod 就將作為服務的後端,請求就會被重定向到 pod 上,但是如果 pod 沒有準備好,如何處理服務請求呢?
該 pod 可能需要時間來載入設定或資料,或者可能需要執行預熱過程以防止第一個用請求時間太長影響使用者體驗。在這種情況下,不希望該 pod 立即開始接受請求,尤其是在執行的範例可以正確快速地處理請求的情況下。不要將請求轉發到正在啟動的 pod 中,直到完全準備就緒。
與前面介紹的存活探針類似,K8S 還允許為容器定義準備就緒探針,就緒探針也有三種型別:Exec 探針、HTTP GET 探針、TCP Socket 探針。
十二、Headless
上面我們已經知道服務可提供負載均衡的能力,將請求轉發到隨機的一個 pod 上,但是如果你想要讓請求連線到所有的 pod,那該怎麼辦呢?
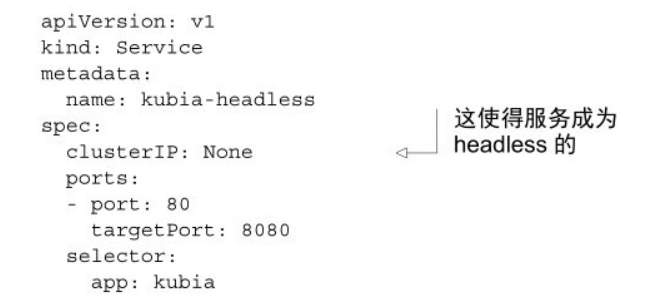
幸運的是,K8S 允許使用者端通過 DNS 查詢發現 pod IP。通常,當執行服務的 DNS 查詢時,DNS 伺服器會返回單個 IP---服務的叢集 IP。但是如果告訴K8S 不需要為服務提供叢集 IP(通過在服務 spec 中將 clusterIP 欄位設定為 None 來完成此操作),則 DNS 伺服器將返回 pod IP 而不是單個服務 IP。DNS 伺服器不會返回單個 DNS 記錄,而是會為該服務返回多個記錄,每個記錄指向當時支援該服務的單個 pod 的 IP。
將服務的 spec 中的 clusterIP 欄位設定為 None 會使服務成為 headless 服務:
十三、卷
我們之前說過,pod 類似邏輯主機,在邏輯主機中執行的程序共用諸如 CPU、RAM、網路介面等資源,或許你會認為程序也能共用磁碟,那你就錯了。pod 中的每個容器都有自己的獨立檔案系統,因為檔案系統來自容器映象。
K8S 中的卷是 pod 的一個組成部分,因此像容器一樣在 pod 的規範中就定義了。它們不是獨立的 K8S 物件,也不能單獨建立或刪除。 pod 中的所有容器都可以使用卷,但必須先將它掛載在每個需要存取它的容器中。在每個容器中,都可以在其檔案系統的任意位置掛載卷。
假設有一個帶有三個容器的 pod,一個容器執行了一個 web 伺服器,該 web 伺服器的 HTML 頁面目錄位於 /var/htdocs,並將站點存取紀錄檔儲存到 /var/logs 目錄中。第二個容器執行了一個代理來建立 HTML 檔案,並將它們存放在 /var/html 中,第三個容器處理在 /var/logs 目錄中找到的紀錄檔。每個容器都有一個明確的用途,但是每個容器單獨使用就沒多大用處了。但是如果將兩個卷新增到 pod 中,並在三個容器的適當路徑上掛載它們,就會建立一個完善的系統。
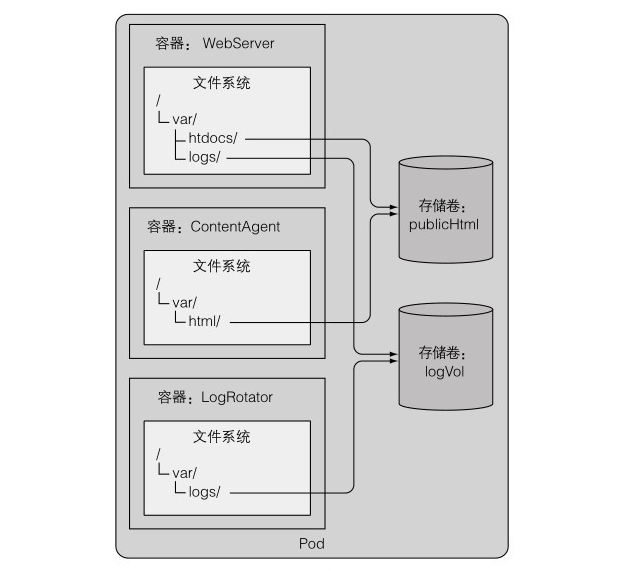
常見的卷有如下幾種:
- emptypDir:用於儲存臨時資料的簡單空目錄,卷的生命週期和 pod 相關聯,所以當刪除 pod 時,卷的內容就會丟失。
- gitRepo:通過檢出 git 倉庫的內容來初始化卷,通過克隆 Git 倉庫並在 pod 啟動時拉取最新版本(建立容器之前)填充資料,缺點是不能和 repo 保持同步,每次將更改推播到 gitRepo時,需要刪除 pod 才能更新。
- hostPath:用於將目錄從工作節點的檔案系統掛載到 pod 中,hostPath 卷指向節點檔案系統上的特定檔案或目錄,這表示著他和節點相關,另外他是永續性儲存,因為 gitRepo 和 emptyDir 卷的內容會在 pod 被刪除時被刪除,而 hostPath 的內容則不會被刪除。
1、emptyDir

2、gitRepo

3、hostPath
hostPath 雖然可用於持久化儲存卷,但是使用的很少,通常使用其他雲端儲存卷,例如 gce、aws 儲存卷。
十四、ConfigMap 和 Secret
幾乎所有的應用程式都需要設定資訊,並且這些設定資料不應該被嵌入應用本身。通常傳遞設定選項給容器化應用程式的方法是環境變數、命令列引數、亦或者是通過 gitRepo 儲存卷,但其實還有一種更好的方式,那就是 ConfigMap。
儘管絕大多數設定選項並未包含敏感資訊,少量設定可能含有證書、私鑰,以及其他需要保持安全的相似資料,這型別資料需要被特殊對待,這就需要用到 Secret。
應用設定的關鍵在於能夠在多個環境中區分設定選項,將設定從應用程式原始碼中分離,可頻繁變更設定值,而不用重新部署 pod。如果將 pod 定義描述看作是應用程式原始碼,顯然需要將設定移除 pod 定義。
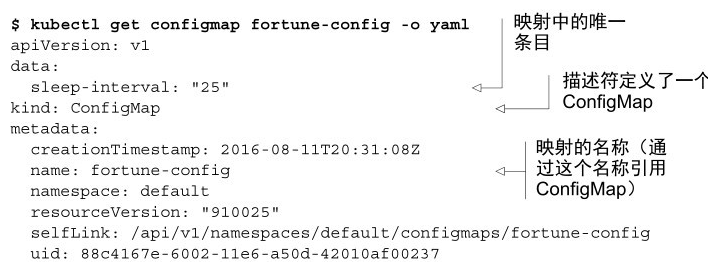
1、ConfigMap 定義
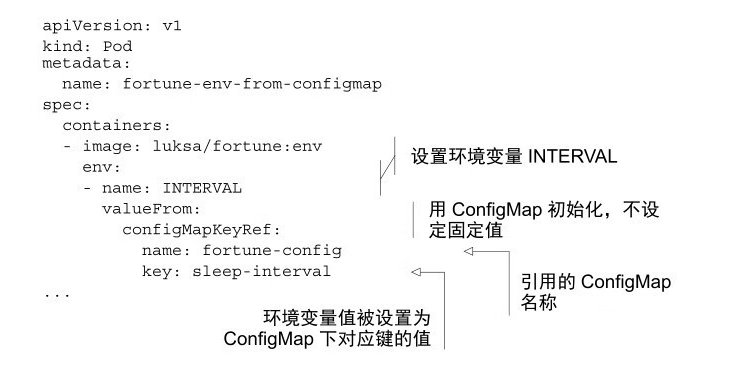
2、使用 ConfigMap
十五、Downward API
前面通過環境變數、或者 ConfigMap、Secret 卷嚮應用傳遞設定資料都是預先知道的。但是對於那些不能預先知道的資料,比如 pod 的 IP、主機名或者是 pod 自身的名稱該怎麼獲取呢?此外對於那些已經在 pod 中定義的資料,比如 pod 的標籤和註解又該如何獲取呢?這些問題都可以使用 Downward API 解決。Downward API 允許我們通過環境變數或檔案傳遞 pod 的後設資料。Downward API 主要是將在 pod 的定義和狀態中取得的資料作為環境變數和檔案的值。
十六、Deployment
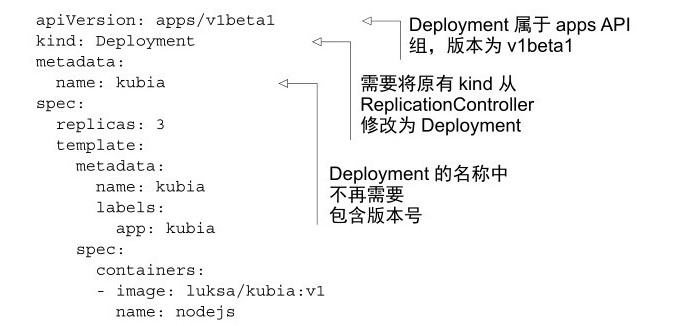
Deployment 是一種更高價資源,用於部署應用程式並以宣告的方式升級應用,而不是通過 ReplicationController 或 ReplicaSet 進行部署,它們都被認為是更底層的概念。當建立一個 Deployment 時,ReplicatSet 資源也會隨之建立。使用 Deployment 可以更容易的更新應用程式,因為可以直接定義單個 Deployment 資源所需達到的狀態,並讓 K8S 處理中間的狀態。總之,部署應用程式使用 Deployment 就行了。
十七、Statefulset
我們之前使用 ReplicaSet 建立的 pod 都是共用一個持久卷:
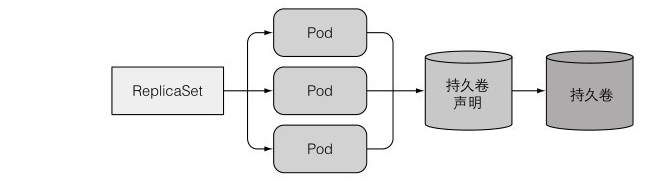
那能不能通過一個 ReplicaSet 讓多個 pod 副本都指定獨立的持久卷宣告呢,很明顯這是做不到的,除非你先手動建立 pod,之後在建立 ReplicaSet 來管理它們,但是如果發生節點故障後,你還需要手動管理它們,所以這是不合適的。
由於每個副本都是獨立有狀態的,所以你先得建立多個持久卷宣告,當建立 Statefulset 的時候,你就需要指定 pod 對應的持久卷。
十八、總結
K8S 的一些資源物件書中介紹的大概就這些了,上面只是一些簡單的概念,具體還是需要看書和實操深入理解。