etcd:增加30%的寫入效能
etcd:增加30%的寫入效能
本文最終的解決方式很簡單,就是將現有卷升級為支援更高IOPS的卷,但解決問題的過程值得推薦。
譯自:etcd: getting 30% more write/s
我們的團隊看管著大約30套自建的Kubernetes叢集,最近需要針對etcd叢集進行效能分析。
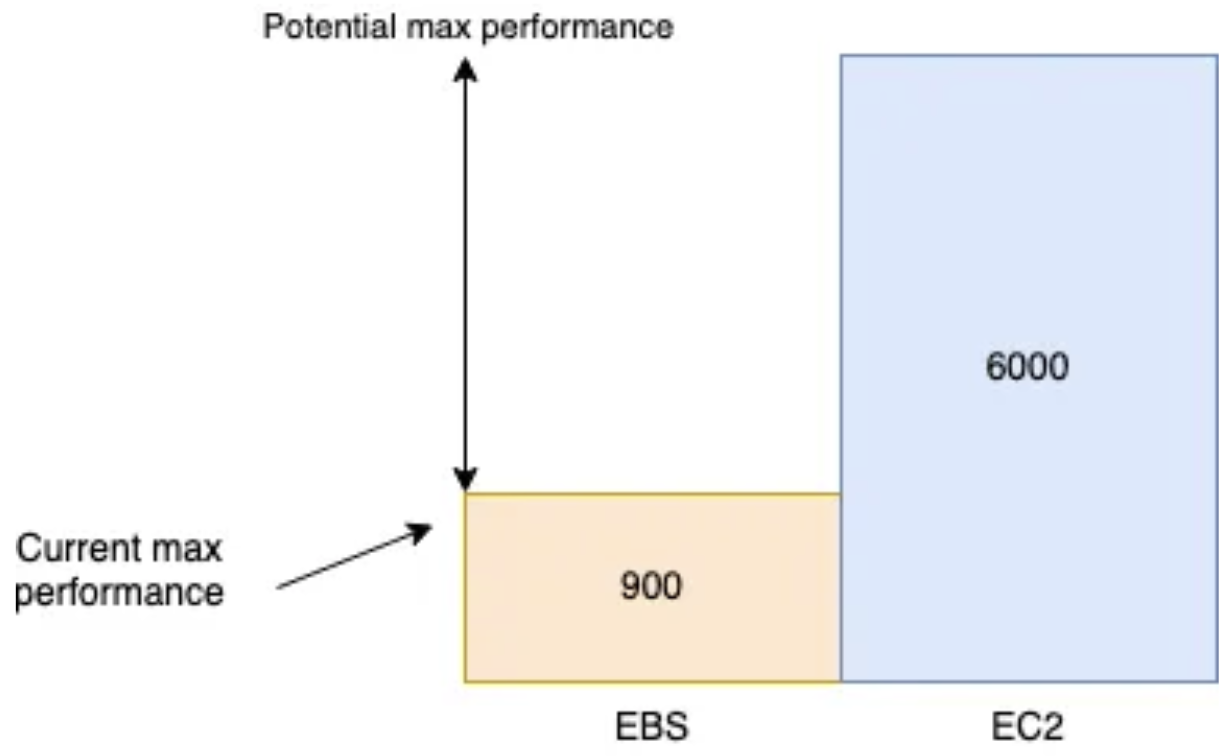
每個etcd叢集有5個成員,範例型號為m6i.xlarge,最大支援6000 IOPS。每個成員有3個卷:
- root卷
- write-ahead-log的卷
- 資料庫卷
每個卷的型號為 gp2,大小為300gb,最大支援900 IOPS:
測試寫效能
首先(在單獨的範例上執行)執行etcdctl check perf命令,模擬etcd叢集的負載,並列印結果。可以通過--load引數來模擬不同大小的叢集負載,支援引數為:s(small), m(medium), l(large), xl(xLarge)。
當load為s時,測試是通過的。
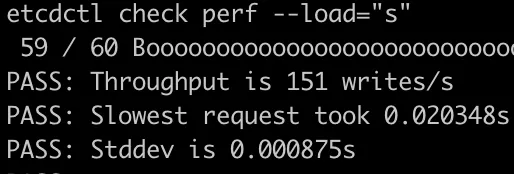
但當load為l時,測試失敗。可以看到,叢集可執行6.6K/s的寫操作,可以認為我們的叢集介於中等叢集和大型叢集之間。
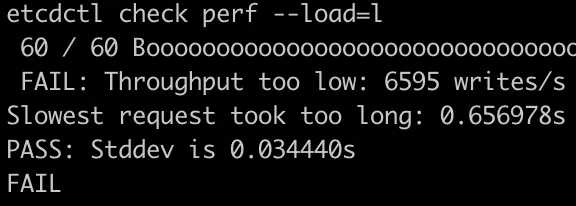
下面是使用iostat展示的磁碟狀態,其中nvme1n1是etcd的write-ahead-log卷,其IO使用率已經達到100%,導致etcd的執行緒等待IO。

下面使用fio來檢視fdatasync的延遲(見附錄):
fio --rw=write --ioengine=sync --fdatasync=1 --directory=benchmark --size=22m --bs=2300 --name=sandbox
...
Jobs: 1 (f=1): [W(1)][100.0%][w=1594KiB/s][w=709 IOPS][eta 00m:00s]
...
fsync/fdatasync/sync_file_range:
sync (usec): min=476, max=10320, avg=1422.54, stdev=727.83
sync percentiles (usec):
| 1.00th=[ 523], 5.00th=[ 545], 10.00th=[ 570], 20.00th=[ 603],
| 30.00th=[ 660], 40.00th=[ 775], 50.00th=[ 1811], 60.00th=[ 1909],
| 70.00th=[ 1975], 80.00th=[ 2057], 90.00th=[ 2180], 95.00th=[ 2278],
| 99.00th=[ 2671], 99.50th=[ 2933], 99.90th=[ 4621], 99.95th=[ 5538],
| 99.99th=[ 7767]
...
Disk stats (read/write):
nvme1n1: ios=0/21315, merge=0/11364, ticks=0/13865, in_queue=13865, util=99.40%
可以看到fdatasync延遲的99th百分比為 2671 usec (或 2.7ms),說明叢集足夠快(etcd官方建議最小10ms)。從上面的輸出還可以看到報告的IOPS為709,相比gp2 EBS 卷宣稱的900 IOPS來說並不算低。
升級為GP3
下面將卷升級為GP3(支援最小3000 IOPS)。
Jobs: 1 (f=1): [W(1)][100.0%][w=2482KiB/s][w=1105 IOPS][eta 00m:00s]
...
iops : min= 912, max= 1140, avg=1040.11, stdev=57.90, samples=19
...
fsync/fdatasync/sync_file_range:
sync (usec): min=327, max=5087, avg=700.24, stdev=240.46
sync percentiles (usec):
| 1.00th=[ 392], 5.00th=[ 429], 10.00th=[ 457], 20.00th=[ 506],
| 30.00th=[ 553], 40.00th=[ 603], 50.00th=[ 652], 60.00th=[ 709],
| 70.00th=[ 734], 80.00th=[ 857], 90.00th=[ 1045], 95.00th=[ 1172],
| 99.00th=[ 1450], 99.50th=[ 1549], 99.90th=[ 1844], 99.95th=[ 1975],
| 99.99th=[ 3556]
...
Disk stats (read/write):
nvme2n1: ios=5628/10328, merge=0/29, ticks=2535/7153, in_queue=9688, util=99.09%
可以看到IOPS變為了1105,但遠低於預期,通過檢視磁碟的使用率,發現瓶頸仍然是EBS卷。
鑑於範例型別支援的最大IOPS約為6000,我決定冒險一試,看看結果如何:
Jobs: 1 (f=1): [W(1)][100.0%][w=2535KiB/s][w=1129 IOPS][eta 00m:00s]
...
fsync/fdatasync/sync_file_range:
sync (usec): min=370, max=3924, avg=611.54, stdev=126.78
sync percentiles (usec):
| 1.00th=[ 420], 5.00th=[ 453], 10.00th=[ 474], 20.00th=[ 506],
| 30.00th=[ 537], 40.00th=[ 562], 50.00th=[ 594], 60.00th=[ 635],
| 70.00th=[ 676], 80.00th=[ 717], 90.00th=[ 734], 95.00th=[ 807],
| 99.00th=[ 963], 99.50th=[ 1057], 99.90th=[ 1254], 99.95th=[ 1336],
| 99.99th=[ 2900]
...
可以看到的確遇到了瓶頸,當IOPS規格從900變為3000時,實際IOPS增加了30%,但IOPS規格從3000變為6000時卻沒有什麼變化。
IOPS到哪裡去了?
作業系統通常會快取寫操作,當寫操作結束之後,資料仍然存在快取中,需要等待重新整理到磁碟。
資料庫則不同,它需要知道資料寫入的時間和地點。假設一個執行EFTPOS(電子錢包轉帳)交易的資料庫被突然重啟,僅僅知道資料被"最終"寫入是不夠的。
AWS在其檔案中提到:
事務敏感的應用對I/O延遲比較敏感,適合使用SSD卷。可以通過保持低佇列長度和合適的IOPS數量來保持高IOPS,同時降低延遲。持續增加捲的IOPS會導致I/O延遲的增加。
吞吐量敏感的應用則對I/O延遲增加不那麼敏感,適合使用HDD卷。可以通過在執行大量順序I/O時保持高佇列長度來保證HDD卷的高吞吐量。
etcd在每個事務之後都會使用一個fdatasync系統呼叫,這也是為什麼在fio命令中指定—fdatasync=1的原因。
fsync()會將檔案描述符fd參照的所有(被修改的)核心資料重新整理到磁碟裝置(或其他永久儲存裝置),這樣就可以檢索到這些資訊(即便系統崩潰或重啟)。該呼叫在裝置返回前會被阻塞,此外,它還會重新整理檔案的後設資料(參見stat(2))
fdatasync() 類似 fsync(),但不會重新整理修改後的後設資料(除非需要該後設資料才能正確處理後續的資料檢索)。例如,修改st_atime或st_mtime並不會重新整理,因為它們不會影響後續資料的讀取,但對檔案大小(st_size)的修改,則需要重新整理後設資料。
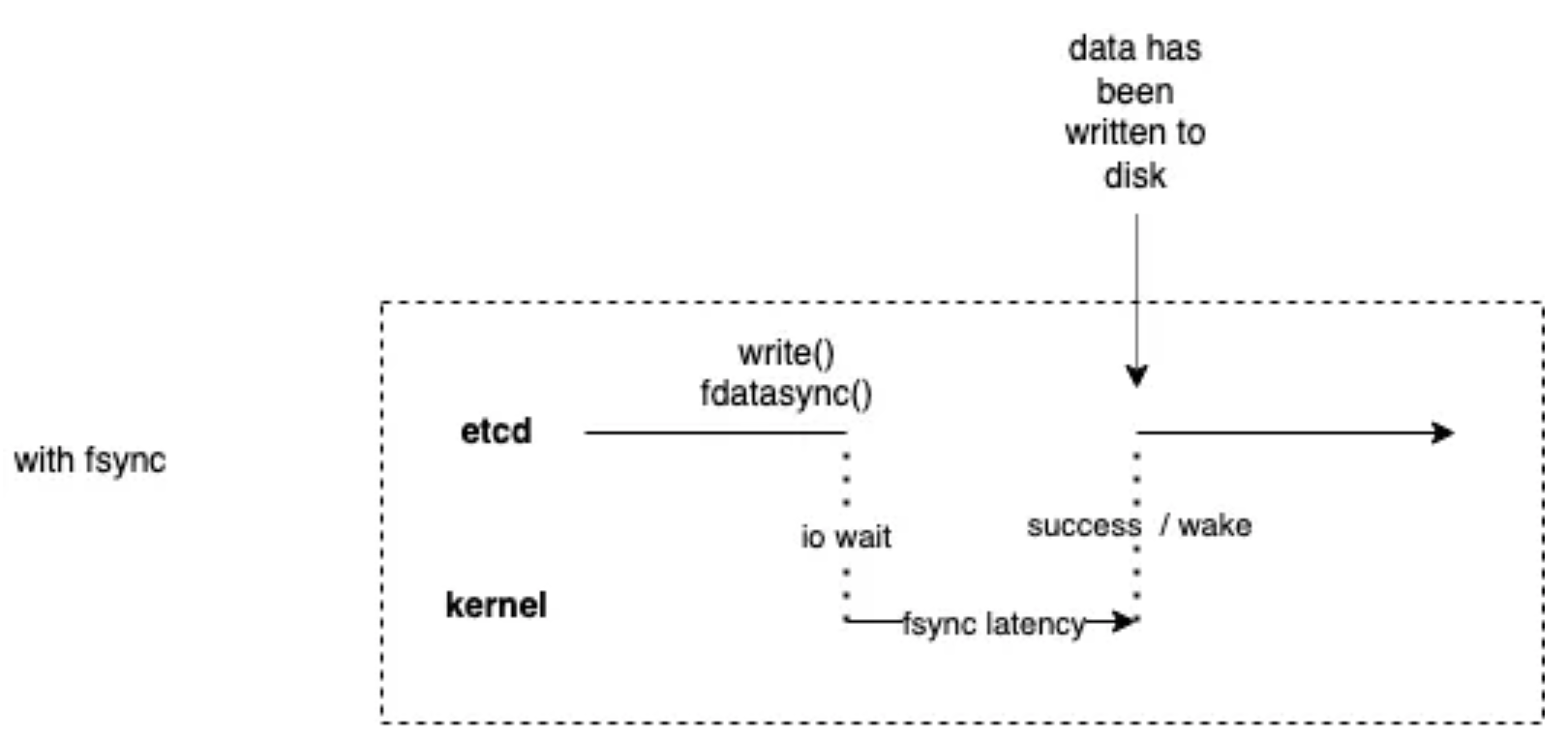
可以看到這種處理方式對效能的影響比較大。
下表展示了各個卷型別的最大效能,與etcd相關的是Max synchronous write:
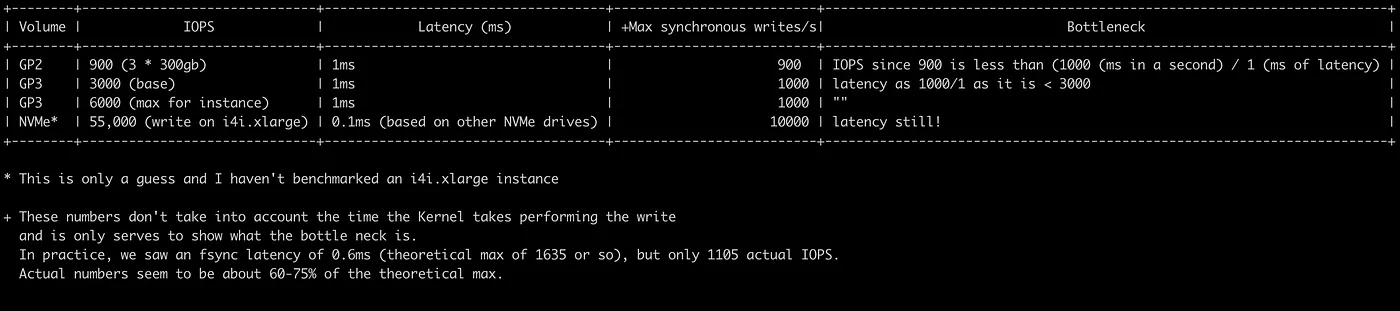
可以看到etcd的iops一方面和自身實現有關,另一方面收到儲存本身的限制。
附錄
使用Fio來測試Etcd的儲存效能
etcd叢集的效能嚴重依賴儲存的效能,為了理解相關的儲存效能,etcd暴露了一些Prometheus指標,其中一個為
wal_fsync_duration_seconds,etcd建議當99%的指標值均小於10ms時說明儲存足夠快。可以使用fio來驗證etcd的處理速度,在下面命令中,test-data為測試的掛載點目錄:fio --rw=write --ioengine=sync --fdatasync=1 --directory=test-data --size=22m --bs=2300 --name=mytest在命令輸出中,只需關注fdatasync的99th百分比是否小於10ms,在本場景中,為2180微秒,說明儲存足夠快:
fsync/fdatasync/sync_file_range: sync (usec): min=534, max=15766, avg=1273.08, stdev=1084.70 sync percentiles (usec): | 1.00th=[ 553], 5.00th=[ 578], 10.00th=[ 594], 20.00th=[ 627], | 30.00th=[ 709], 40.00th=[ 750], 50.00th=[ 783], 60.00th=[ 1549], | 70.00th=[ 1729], 80.00th=[ 1991], 90.00th=[ 2180], 95.00th=[ 2278], | 99.00th=[ 2376], 99.50th=[ 9634], 99.90th=[15795], 99.95th=[15795], | 99.99th=[15795]注意:
- 可以根據特定的場景條件
--size和--bs- 在本例中,fio是唯一的I/O,但在實際場景中,除了和
wal_fsync_duration_seconds相關聯的寫入之外,很可能還會有其他寫入儲存的操作,因此,如果從fio觀察到的99th百分比略低於10ms時,可能並不是因為儲存不夠快。- fio的版本不能低於3.5,老版本不支援fdatasync
Etcd WALs
資料庫通常都會使用WAL,etcd也不例外。etcd會將針對key-value儲存的特定操作(在apply前)寫入WAL中,當一個成員崩潰並重啟,就可以通過WAL恢復事務處理。
因此,在使用者端新增或更新key-value儲存前,etcd都會將操作記錄到WAL,在進一步處理前,etcd必須100%保證WAL表項被持久化。由於存在快取,因此僅僅使用
write系統呼叫是不夠的。為了保證資料能夠寫入持久化儲存,需要在write之後執行fdatasync系統呼叫(這也是etcd實際的做法)。使用fio存取儲存
為了獲得有意義的結果,需要保證fio生成的寫入負載和etcd寫入WAL檔案的方式類似。因此fio也必須採用順序寫入檔案的方式,並在執行write系統呼叫之後再執行
fdatasync系統呼叫。為了達到順序寫的目的,需要指定--rw=write,為了保證fio使用的是write系統呼叫,而不是其他系統呼叫(如 pwrite),需要使用--ioengine=sync,最後,為了保證每個write呼叫之後都執行fdatasync,需要指定--fdatasync=1,另外兩個引數--size和--bs需要根據實際情況進行調整。
本文來自部落格園,作者:charlieroro,轉載請註明原文連結:https://www.cnblogs.com/charlieroro/p/17379469.html