【資料結構與演演算法學習】線性表(順序表、單連結串列、雙向連結串列、迴圈連結串列)
實現語言:C++
1. 線性表相關概念
線性表(Linear List)
是由n(n≥0)個具有相同特性(資料型別)的資料元素(結點)a1,a2,...,ai-1,ai,ai+1,...,an組成的有限序列。
其中,a1為線性起點(起始結點),an為線性終點(終端結點)。對於每一個資料元素ai,我們稱ai-1為它的直接前驅,ai+1為它的直接後繼。i(1≤i≤n)為下標,是元素的序號,表示元素在表中的位置;n為資料元素總個數,即表長。當n=0時,稱線性表為空表。
線性表的儲存結構
在計算機中,線性表有兩種基本的儲存結構:順序儲存結構和鏈式儲存結構。
2. 順序儲存
線性表的順序表示又稱為順序儲存結構或順序映像。順序儲存,即把邏輯上相鄰的資料元素儲存在物理上相鄰的儲存單元中。其特點是依次儲存,地址連續——中間沒有空出儲存單元,且任一元素可隨機存取。
線性表的第一個資料元素a1的儲存位置,稱為線性表的起始位置或基地址。
順序表中元素儲存位置的計算
LOC(ai) = LOC(a1) + (i-1) x m (m為每個元素佔用的儲存單元)
每個元素的存取時間複雜度為O(1),我們稱之為隨機存取。
順序表的表示
#define LIST_INIT_SIZE 100 // 線性表儲存空間的初始分配量
typedef struct{
ElemType elem[LIST_INIT_SIZE];
int length; // 當前長度
}SqList;
例如:多項式 Pn(x) = p1xe1 + p2xe2 + ... + pmxem 的順序儲存結構型別定義如下:
#include <stdlib.h>
#define MAXSIZE 1000 // 多項式可能達到的最大長度
typedef struct { // 多項式非零項的定義
float p; // 係數
int e; // 指數
}Polynomial;
typedef struct {
Polynomial* data; // 儲存空間的基地址
int length; // 多項式中當前項的個數
}SqList; // 多項式的順序儲存結構型別定義為SqList
int main(int argc, char** argv) {
SqList L;
// 開闢指定長度的地址空間,並返回這段空間的首地址
L.data = (Polynomial*)malloc(sizeof(Polynomial) * MAXSIZE);
// 釋放申請的記憶體空間
free(L.data);
SqList L2;
// 動態申請存放Polynomial型別物件的記憶體空間,成功則返回Polynomial型別的指標,指向新分配的記憶體
L2.data = new Polynomial();
// 釋放指標L2.data所指向的記憶體
delete L2.data;
return 0;
}
2.1 順序表基礎操作
// 初始化順序表(構造一個空的順序表)
Status InitList_Sq(SqList& L) {
L.elem = new ElemType[MAXSIZE]; // 為順序表分配儲存空間
if (!L.elem) exit(OVERFLOW); // 儲存分配失敗
L.length = 0; // 空表長度為0
return OK;
}
// 銷燬順序表
void DestroyList(SqList& L) {
if(L.elem) delete L.elem; // 釋放儲存空間
}
// 清空線性表
void ClearList(SqList& L) {
L.length = 0; // 將順序表的長度置0
}
// 求線性表的長度
int GetLength(SqList L) {
return (L.length);
}
// 判斷順序表L是否為空
int IsEmpty(SqList L) {
if (L.length == 0) return 1;
else return 0;
}
// 順序表的取值(根據位置i獲取相應位置資料元素的內容)
int GetElem(SqList L, int i, ElemType& e) {
if (i<1 || i>L.length) return 0;
e = L.elem[i - 1]; // 第i-1個單元儲存著第i個資料
return 1;
}
順序表初始化、銷燬順序表、清空順序表、求順序表長度、判斷順序表是否為空及順序表的取值等操作,它們的時間複雜度都為O(1)
2.2 順序表的查詢
// 順序表的查詢
int LocateElem(SqList L, ElemType e) {
for (int i = 0; i < L.length; i++) {
if (L.elem[i] == e)
return i + 1;
}
return 0;
}
平均查詢長度ASL(Average Search Length):為確定記錄在表中的位置,需要與給定值進行比較的關鍵字的個數的期望值叫做查詢演演算法的平均查詢長度。
含有n個記錄的表,查詢成功時:
ASL = 1/n * (1+2+...+n) = (n+1)/2
所以,順序表查詢演演算法的平均時間複雜度為:O(n)
2.3 順序表的插入
【演演算法思路】
- 判斷插入位置i是否合法;
- 判斷順序表的儲存空間是否已滿,若已滿返回ERROR;
- 將第n至第i位的元素依次向後移動一個位置,空出第i個位置;
- 將要插入的新元素e放入第i個位置;
- 表長加1,插入成功返回OK。
【程式碼】
// 順序表的插入(在順序表L的第i個位置插入元素e)
int ListInsert(SqList& L, int i, ElemType e) {
L.length += 1;
if (i <= 0 || i > L.length + 1) return 0; // 判斷i值是否合法
if (L.length == MAXSIZE) return 0; // 判斷當前儲存空間是否已滿
for (int k = L.length - 1; k >= i - 1; k--)
L.elem[k + 1] = L.elem[k]; // 插入位置及之後的元素後移
L.elem[i-1] = e;
L.length ++;
return 1;
}
【演演算法分析】
演演算法時間主要耗費在移動元素的操作上。
若插入在尾結點之後,則需要移動0次;若插入在首結點之前,則需要移動n次;在各個位置插入(共n+1種可能)的平均移動次數為:E = 1/(n+1) * (0+1+...+n) = n/2
所以,順序表插入演演算法的平均時間複雜度為:O(n)
2.4 順序表的刪除
【演演算法思路】
- 判斷刪除位置i是否合法;
- 將第i+1至第n位的元素依次向前移動一個位置;
- 表長減1,刪除成功返回OK。
【程式碼】
// 順序表的刪除(刪除順序表L第i個位置的元素e)
int ListDelete(SqList& L, int i, ElemType& e) {
if (i < 1 || i > L.length) return 0; // 判斷i值是否合法(1<=i<=L.length)
for (int k = i; k < L.length - 1; k++)
L.elem[k - 1] = L.elem[k]; // 被刪除之後的元素前移
L.length--;
return 1;
}
【演演算法分析】
演演算法時間主要耗費在移動元素的操作上。
若刪除尾結點,則需要移動0次;若刪除首結點,則需要移動n-1次;在各個位置刪除(共n種可能)的平均移動次數為:E = 1/n * (0+1+...+n-1) = (n-1)/2
所以,順序表刪除演演算法的平均時間複雜度為:O(n)
由於沒有佔用輔助空間,順序表所有操作的空間複雜度都為:O(1)
2.5 順序表的優缺點
優點:
- 儲存密度大(結點本身所佔儲存量 / 結點結構所佔儲存量 = 1);
- 可以隨機存取表中任一元素。
缺點:
- 在插入、刪除某一元素時,需要移動大量元素;
- 浪費儲存空間;
- 屬於靜態儲存形式,資料元素的個數不能自由擴充。
3. 鏈式儲存
鏈式儲存結構又稱為非順序映像或鏈式映像。其特點是:
- 結點在記憶體中的位置是任意的,即邏輯上相鄰的資料元素在物理上不一定相鄰。
- 存取時只能通過頭指標進入連結串列,並通過每個結點的指標域依次向後順序掃描其餘結點,所以尋找第一個結點和最後一個結點所花費的時間不等。這種存取元素的方法被稱為順序存取法。
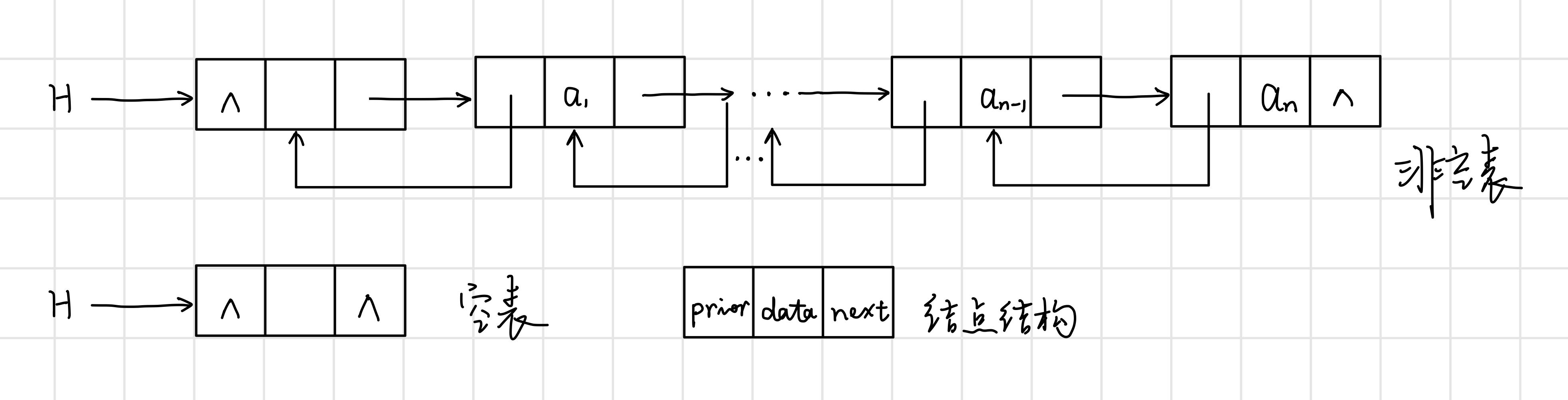
鏈式儲存相關術語:
- 結點:資料元素的儲存映像。由資料域和指標域兩部分組成。
- 連結串列:n個結點由指標鏈組成一個連結串列。它是線性表的鏈式儲存映像,稱為線性表的鏈式儲存結構。
- 單連結串列:結點只有一個指標域的連結串列,結點包括當前元素的資料和其後繼元素的地址。
- 雙連結串列:結點有兩個指標域的連結串列,結點當前元素的資料、其前驅元素的地址以及其後繼元素的地址。
- 迴圈連結串列:首尾相接的連結串列。
- 頭指標:指向連結串列中第一個結點的指標。
- 首元結點:連結串列中儲存第一個資料元素a1的結點。
- 頭結點:在連結串列的首元結點之前附設的一個結點。
- 空表:連結串列中無元素,稱為空連結串列(頭指標和頭結點仍然在)。
Q1:如何表示空表?
- 無頭結點時,頭指標為空時表示空表。
- 有頭結點時,當頭結點的指標域為空時表示空表。
Q2:在連結串列中附設頭結點有什麼好處?
- 便於首元結點的處理:首元結點的地址儲存在頭結點的指標域中,所以在連結串列的第一個位置上的操作和其他位置一致,無需進行特殊處理。
- 便於空表和非空表的統一處理:無論連結串列是否為空,頭指標都是指向頭結點的非空指標,因此空表和非空表的處理也就統一了。
Q3:頭結點的資料域內裝的是什麼?
頭結點的資料域可以為空,也可以存放線性表長度等附加資訊,但此結點不能計入連結串列長度值。
3.1 單連結串列
單連結串列是由表頭唯一確定,因此單連結串列可以用頭指標的名字來命名。若頭指標名為L,則把連結串列稱為表L。
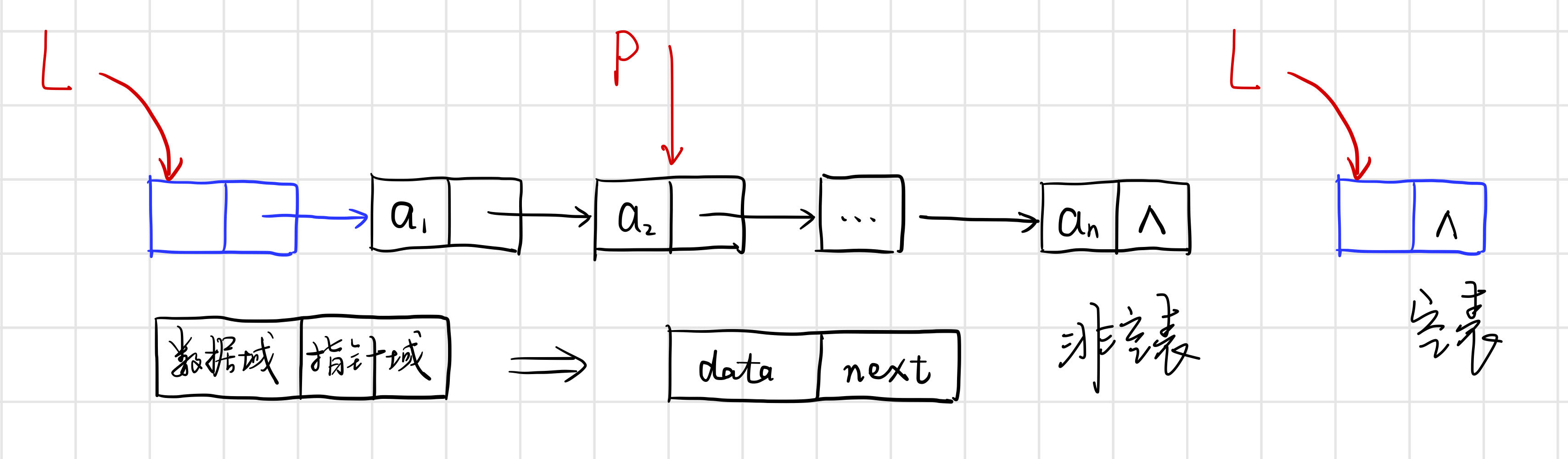
單連結串列的儲存結構
typedef char ElemType;
typedef struct Lnode { // 宣告結點的資料型別和指向結點的指標型別
ElemType data; // 結點的資料域
struct Lnode* next; // 結點的指標域
}Lnode, *LinkList; // LinkList為指向結構體Lnode的指標型別
定義連結串列和節點指標可以用 LinkList L; 或LNode* L;
這兩種方式等價,但為了表述清晰,一般建議使用LinkList定義連結串列,Lnode定義結點指標。即:
定義連結串列:LinkList L;
定義節點指標:Lnode* p;
3.1.1 單連結串列的初始化(帶頭結點)
即構造一個如圖的空表:
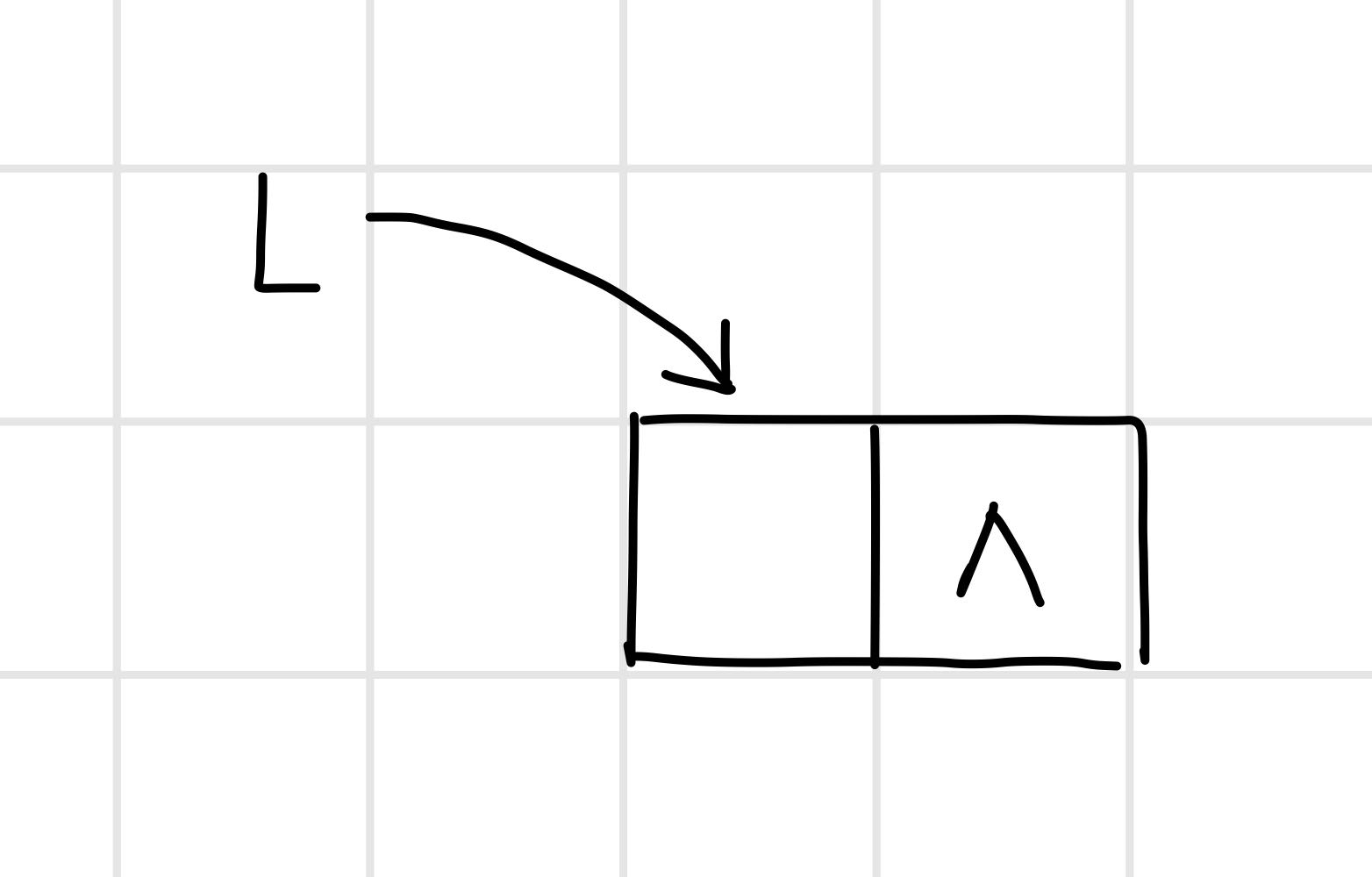
【演演算法思路】
- 生成新結點作頭結點,用頭指標L指向頭結點;
- 將頭結點的指標域置空。
【程式碼】
// 單連結串列的初始化(帶頭結點)
int InitList(LinkList& L) {
L = new LNode; // 或L = (LinkList)malloc(sizeof(LNode));
L->next= NULL;
return 1;
}
3.1.2 判斷單連結串列是否為空
【演演算法思路】
判斷頭結點指標域是否為空。
【程式碼】
int ListEmpty(LinkList L) {
if (L->next)
return 0;
else
return 1;
}
3.1.3 單連結串列的銷燬
【演演算法思路】
從頭指標開始,依次釋放所有節點。
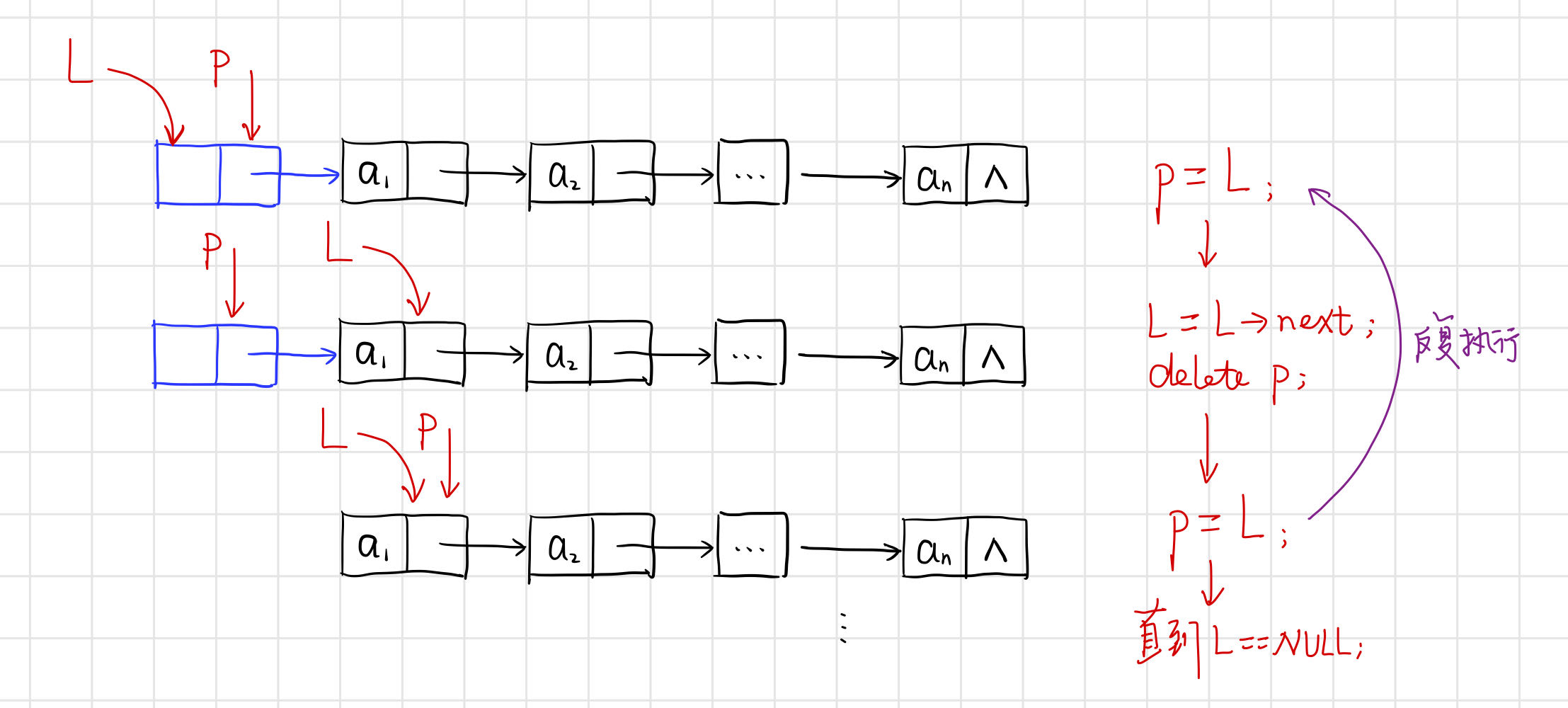
【程式碼】
// 單連結串列的銷燬
int DestroyList_L(LinkList& L) {
Lnode* p;
while (L) {
p = L;
L = (LinkList)L->next;
delete p;
}
return 1;
}
3.1.4 清空單連結串列
【演演算法思路】
從首元結點開始,依次釋放所有結點,並將頭結點指標域設定為空。
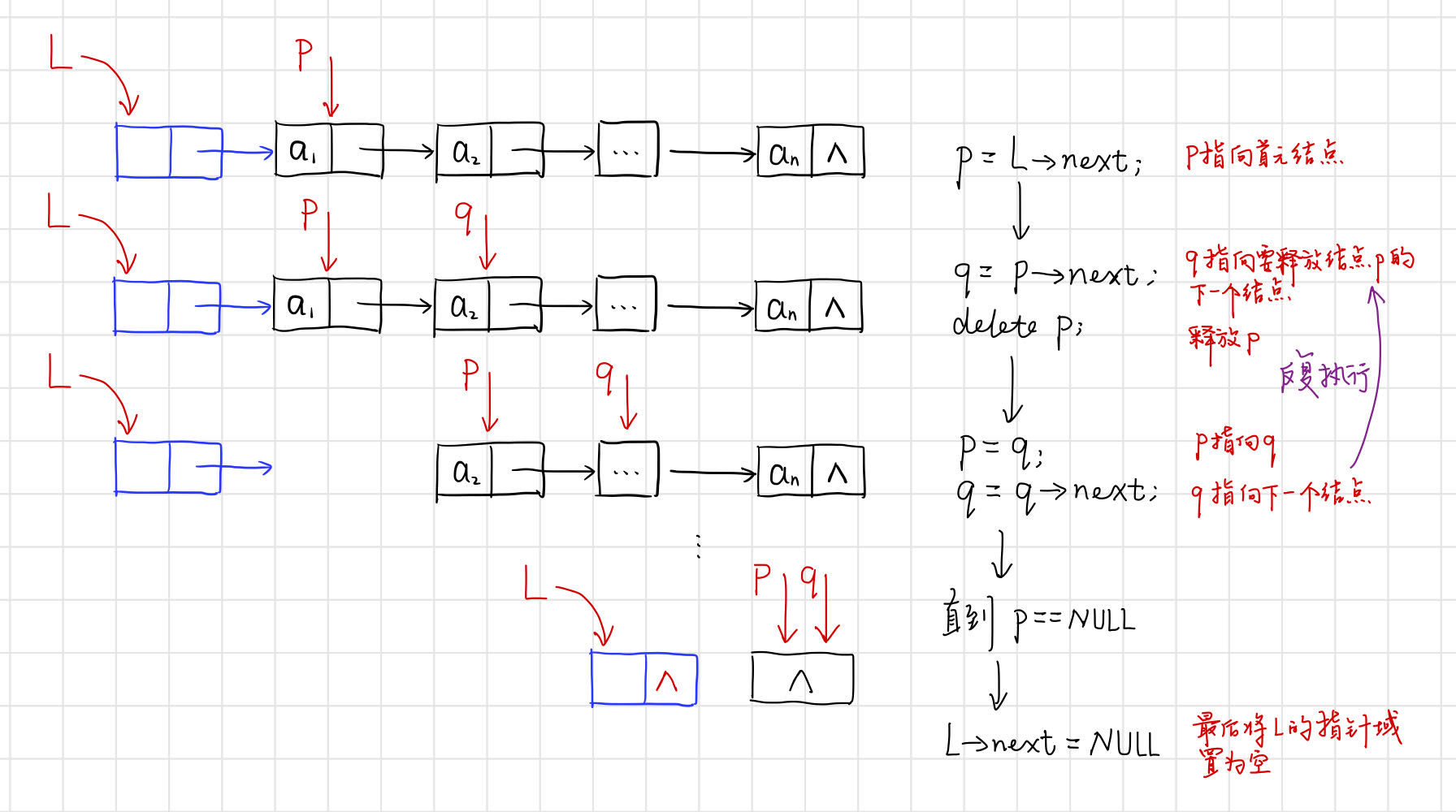
【程式碼】
// 清空單連結串列
int ClearList(LinkList& L) {
Lnode *p, *q;
p = (Lnode*)L->next;
while (L) {
q = (Lnode*)p->next;
delete p;
p = q;
}
L->next = nullptr;
}
3.1.5 求單連結串列的表長
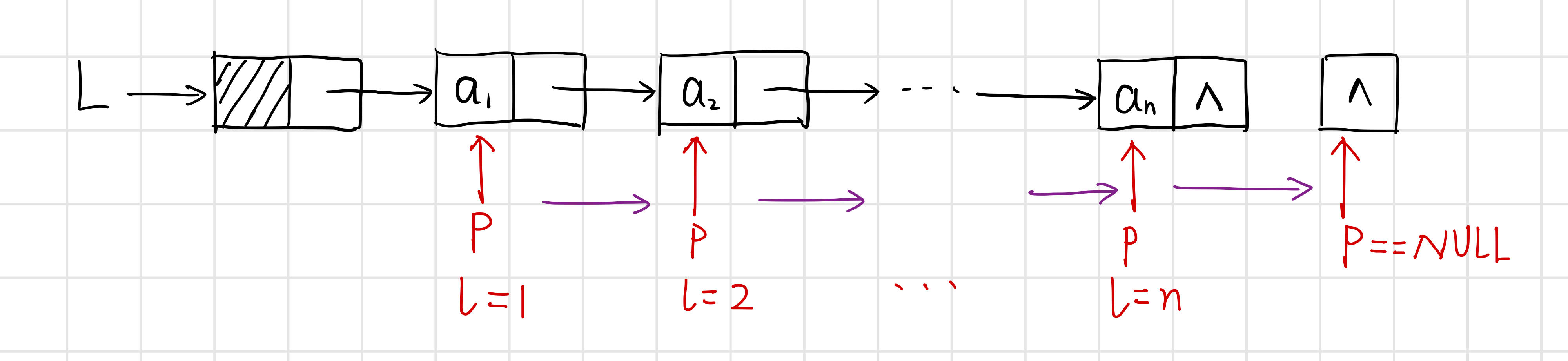
【演演算法思路】
從首元結點開始,依次計數所有結點。
【程式碼】
// 求單連結串列的表長
int ListLength(LinkList L) {
Lnode* p;
int len;
p = (Lnode*)L->next; // p指向第一個結點(首元結點)
while (p) {
len++;
p = (Lnode*)p->next;
}
return len;
}
3.1.6 取值
【演演算法思路】
從連結串列的頭指標出發,順著鏈域next逐個結點往下搜尋,直至搜尋到第i個結點位置。我們稱之為順序存取。
【程式碼】
// 取值:取單連結串列中第i個元素的內容,通過變數e返回
int GetElem(LinkList L, int i, ElemType& e)
{
Lnode* p;
p = (Lnode*)L->next;
int j = 1;
while (p && j < i) { // 向後掃描,直到p指向第i個元素或p為空
p = (Lnode*)p->next;
j++;
}
// 第i個元素不存在,分三種情況:i<1,i超過表長,L為空表)
if (!p || i < 1) return 0;
e = p->data;
return 1;
}
3.1.7 查詢
【演演算法思路】
- 從第一個結點起,依次與待查詢資料e相比較;
- 如果找到一個其值與e相等的資料元素,則返回其在連結串列中的位置或地址;
- 如果查遍整個連結串列都沒有找到其值和e相等的元素,則返回0或NULL。
【程式碼】
// 按值查詢—根據指定資料獲取該資料所在的位置(地址)
Lnode* LocateElemAddress(LinkList L, ElemType e) {
Lnode* p = (Lnode*)L->next;
while (p && p->data != e)
p = (Lnode*)p->next;
// if (!p) return nullptr; // 空表或未查詢到返回NULL
return p;
}
// 按值查詢—根據指定資料獲取該資料的位置序號
int LocateElemIndex(LinkList L, ElemType e) {
Lnode* p = (Lnode*)L->next;
int j = 1;
while (p && p->data != e) {
p = (Lnode*)p->next;
j++;
}
if (!p) return 0; // 空表或未查詢到返回0
return j;
}
【演演算法分析】
因線性連結串列只能順序存取,即在查詢時要從頭指標找起,因此查詢的時間複雜度為:O(n)
3.1.8 插入新結點
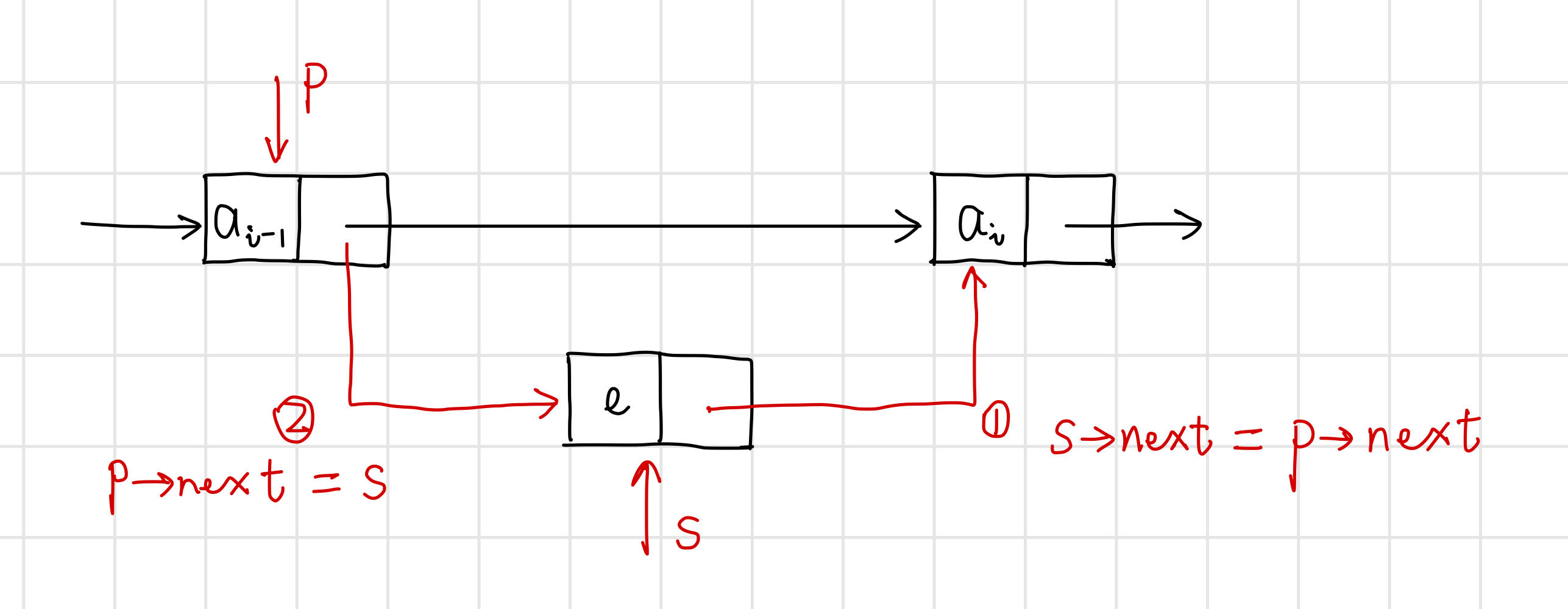
【演演算法思路】
- 首先找到ai-1的儲存位置p;
- 生成一個資料域為e的新結點s;
- 插入新結點:首先新結點的指標域指向結點ai,然後結點ai-1的指標域指向新結點。
【程式碼】
// 在單連結串列L中第i個元素之前插入資料元素e
int ListInsert(LinkList& L, int i, ElemType e) {
// 先找到第i-1個元素的位置
Lnode* p = L;
int j = 0;
while (p && j < i - 1) {
p = (Lnode*)p->next;
j++;
}
if (!p || i < 1) return 0; // i<1或i超過表長+1,插入位置非法
// 將結點s插入L中
LinkList s = new Lnode; // 生成新結點s
s->data = e; // 結點s的資料域置為e
s->next = p->next; // 新結點s指標域指向第i個結點
p->next = s; // 第i-1個結點的指標域指向新結點s
return 1;
}
【演演算法分析】
在編譯 p->next = s 這句程式碼是會報異常:「不能將Lnode*型別的值分配到Lnode型別的實體」。
因線性連結串列不需要移動元素,只要修改指標,一般情況下插入操作的時間複雜度為:O(1)。但是,如果要在單連結串列中進行前插操作,由於要從頭查詢前驅結點,其時間複雜度為:O(n)。
3.1.9 刪除結點
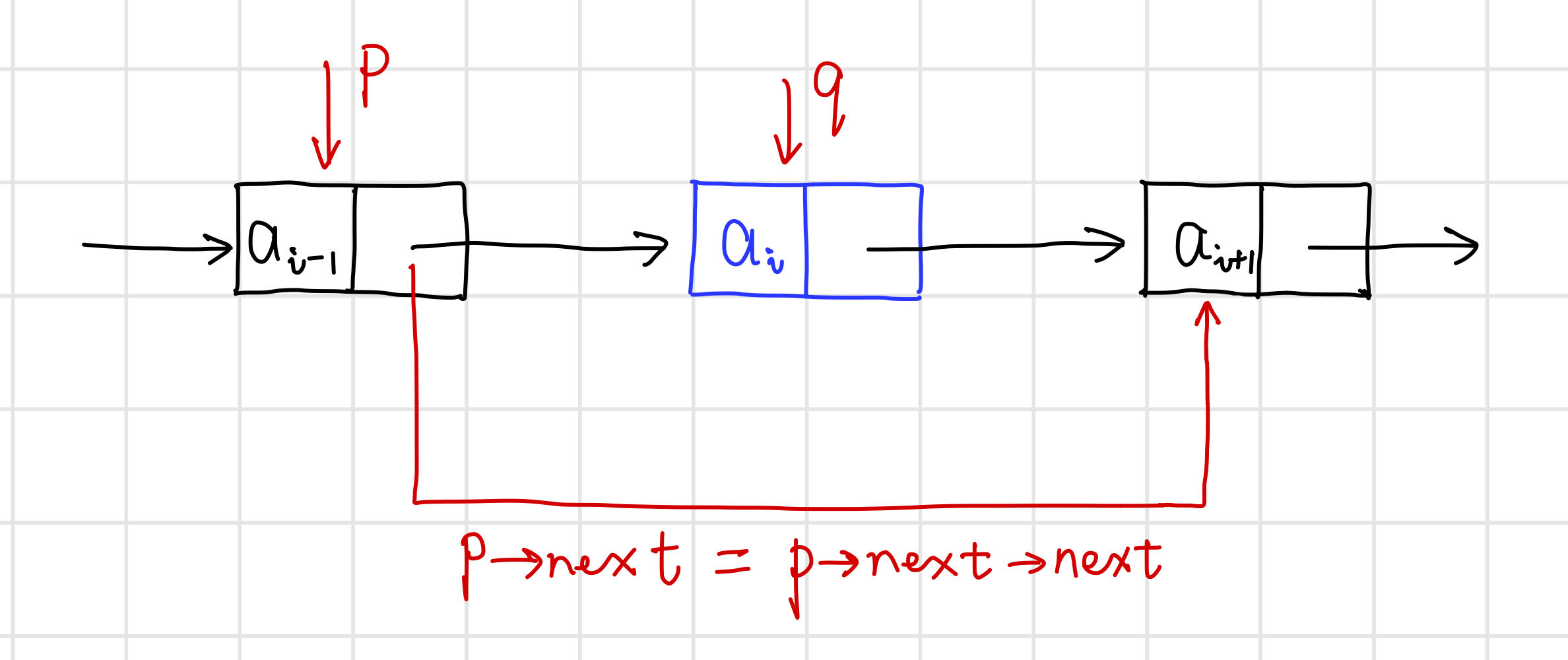
【演演算法思路】
- 首先找到ai-1的儲存位置p,儲存要刪除的ai的值(如果有必要);
- p的指標域指向結點ai+1;
- 釋放結點ai的空間。
【程式碼】
// 刪除單連結串列L中第i個資料元素(結點)
int ListDelete(LinkList& L, int i, ElemType& e) {
// 先找到第i-1個元素的位置
Lnode* p = L;
int j = 0;
while (p && j < i - 1) {
p = (Lnode*)p->next;
j++;
}
if (!p || i < 1) return 0; // i<1或i超過表長,刪除位置非法
// 刪除第i個結點
Lnode* q = (Lnode*)p->next; // 臨時儲存被刪結點的地址以備釋放
p->next = q->next; // 改變刪除結點前驅結點的指標域
e = q->data; // 儲存刪除結點的資料域
delete q; // 釋放刪除結點的空間
return 1;
}
【演演算法分析】
其時間複雜度和插入操作一致。
3.1.10 建立單連結串列
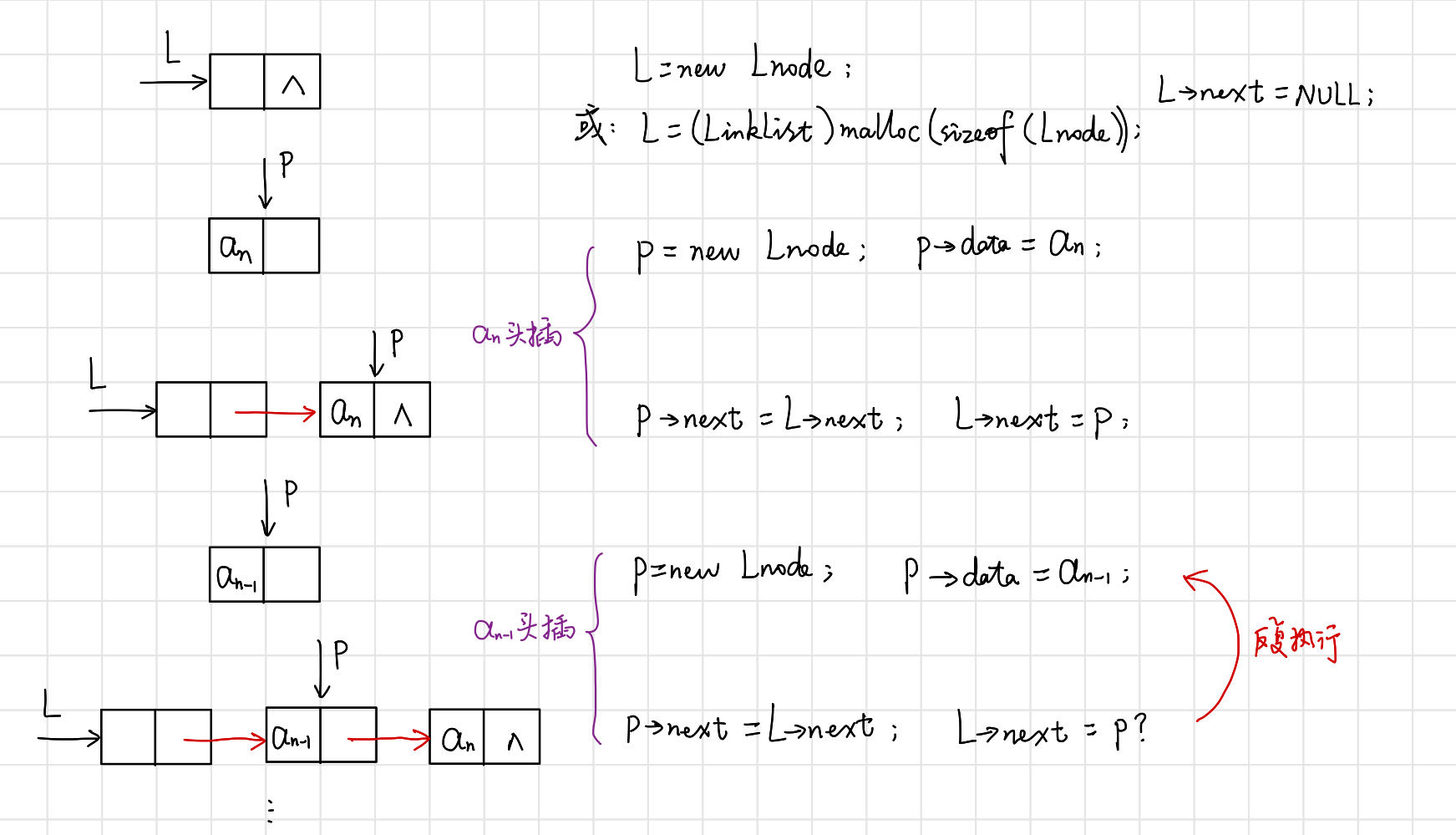
(1)頭插法——元素插入在連結串列頭部,也叫前插法。
【演演算法思路】
- 從一個空表開始,重複讀入資料;
- 生成新結點,將讀入資料存放到新結點的資料域中;
- 從最後一個結點開始,依次將各結點插入到連結串列的前端。
【程式碼】
// 建立單連結串列:頭插法
void CreateList(LinkList& L, int n) {
L = new Lnode;
L->next = nullptr;
for (int i = n; i > 0; i--) {
Lnode* p = new Lnode; // 輸入新結點 p = (Lnode*)malloc(sizeof(Lnode));
std::cin >> p->data; // 輸入元素值 scanf(&p->data);
p ->next = L->next; // 插入到表頭
L->next = p; // 不能將Lnode*型別的值分配到Lnode型別的實體
}
}
(2)尾插法——元素插入在連結串列尾部,也叫後插法。
【演演算法思路】
- 從一個空表L開始,將新結點逐個插入到連結串列尾部,尾指標r指向連結串列的尾結點;
- 初始時,r和L都指向頭結點。每讀入一個資料元素則申請一個新結點,將新結點插入到尾結點後,r指向新結點。
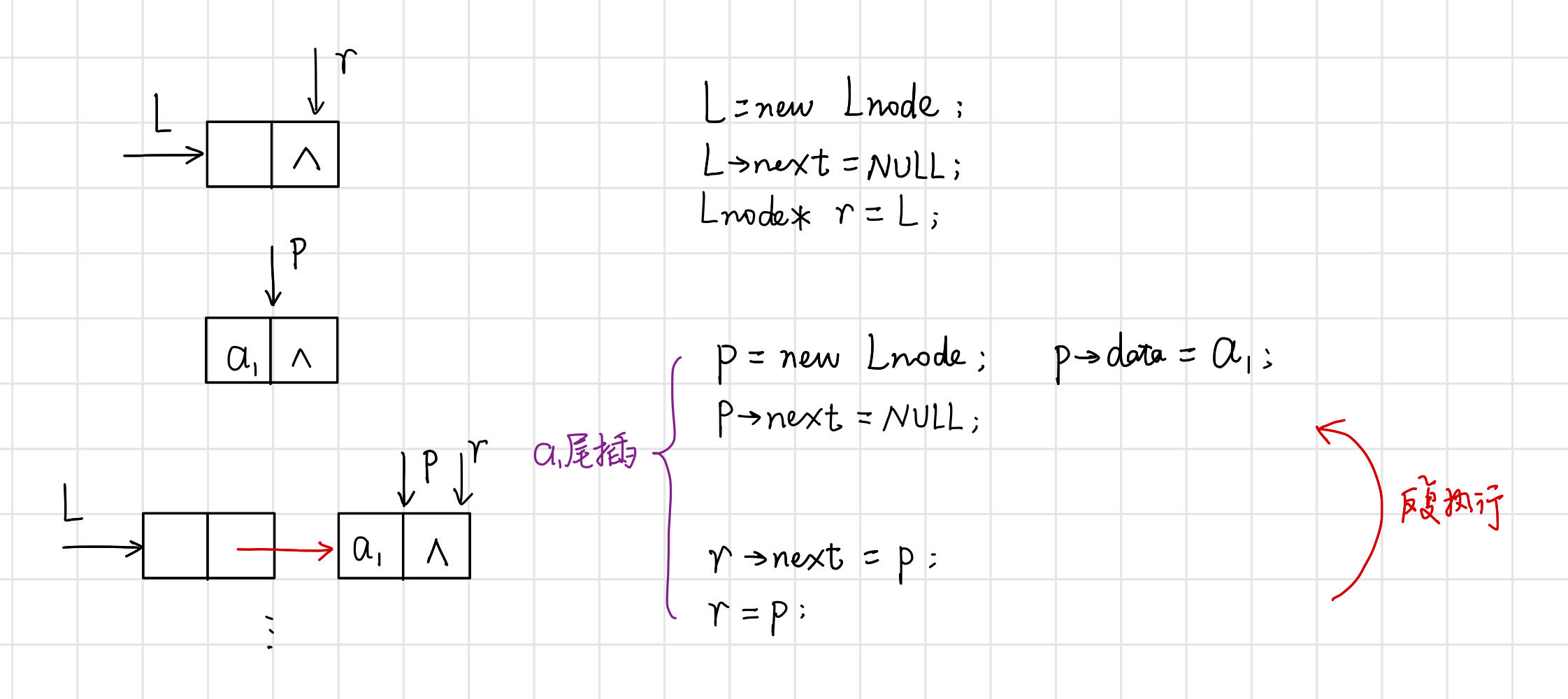
【程式碼】
// 建立單連結串列:尾插法
void CreateList_R(LinkList& L, int n) {
L = new Lnode;
L->next = nullptr;
Lnode* r = L; // 尾指標r指向頭結點
for (int i = 0; i < n; i++) {
Lnode* p = new Lnode; // 輸入新結點
std::cin >> p->data; // 輸入元素值
p->next = nullptr; // 指標域置空
r->next = p; // 插入到表尾
r = p; // r指向新的尾結點
}
}
【演演算法分析】
建立單連結串列時間複雜度為:O(n)
3.2 雙向連結串列
雙向連結串列:在單連結串列的每個結點裡再增加一個指向其直接前驅的指標域prior,這樣鏈中就形成了兩個方向不同的鏈,故稱為雙向連結串列。
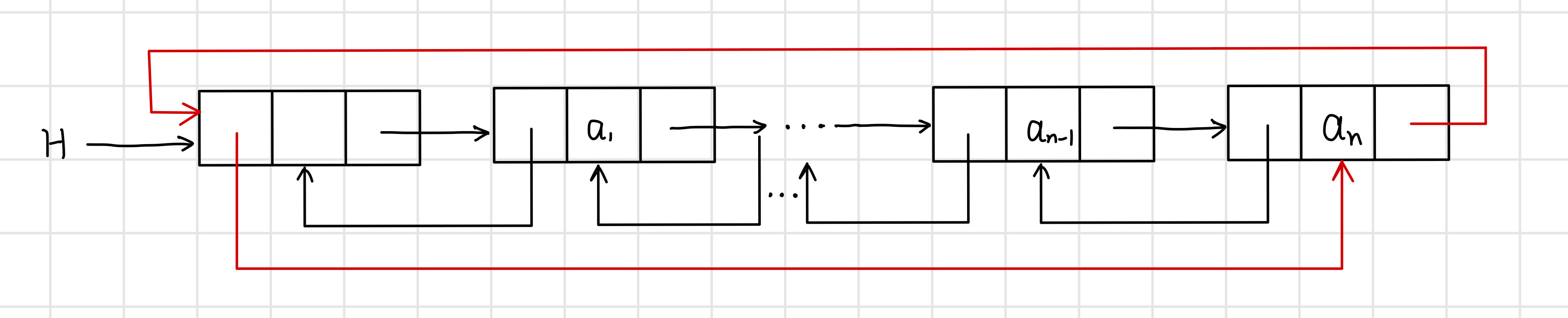
雙向迴圈連結串列:讓頭結點的前驅指標指向連結串列的最後一個結點;讓最後一個節點的後繼指標指向頭結點。
雙向連結串列的結構定義
// 雙向連結串列結點結構定義
typedef struct DuLnode {
ElemType data;
struct DuLnode* prior, * next;
}DuLnode, *DuLinkList;
雙向連結串列結構具有對稱性(設指標p指向某一結點):
p -> prior -> next = p = p ->next -> prior
在雙向連結串列中有些操作(求表長、取值等),因僅涉及一個方向的指標,所以他們的演演算法與線性連結串列相同。但在插入、刪除時,則需要同時修改兩個方向上的指標,兩者的時間複雜度都為O(n)。
3.2.1 雙向連結串列的插入
【演演算法思路】
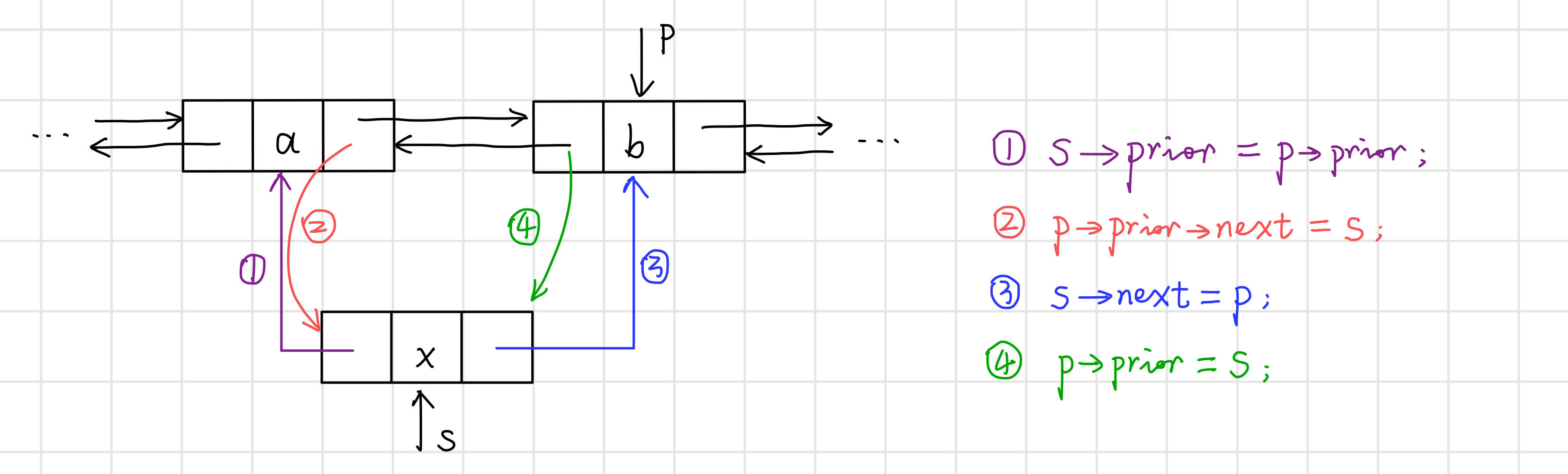
【程式碼】
// 雙向連結串列的插入
int ListInsert_Dbl(DblLinkList& L, int i, ElemType e) {
// 先找到第i個元素的位置
DblLnode* p = L->next;
int j = 1;
while (p != L && j < i) {
p = (DblLnode*)p->next;
j++;
}
if (p == L || i < 1) return 0; // i<1或i超過表長+1,插入位置非法
// 插入新結點
DblLnode* s = new DblLnode;
s->data = e;
s->prior = p->prior; // ①
p->prior->next = s; // ②
s->next = p; // ③
p->prior = s; // ④
return 1;
}
3.2.2 雙向連結串列的刪除
【演演算法思路】
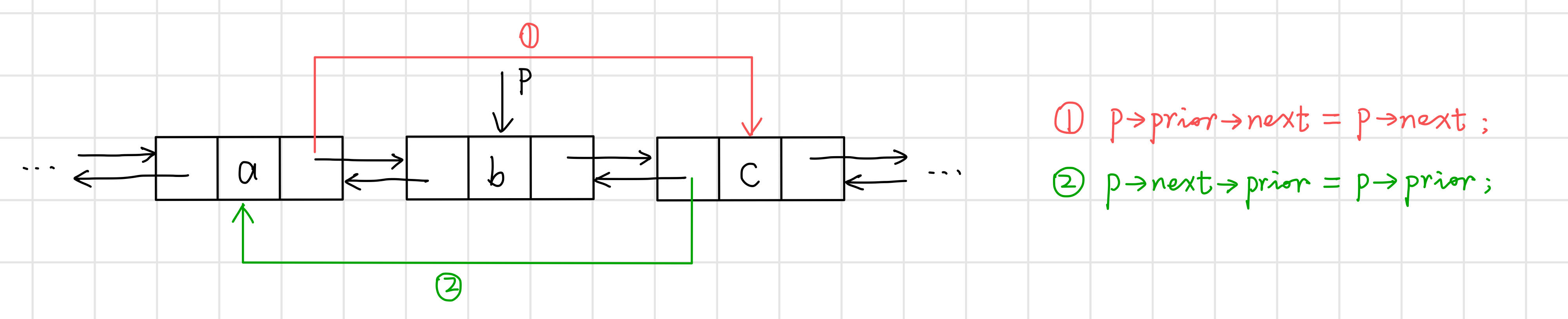
【程式碼】
// 雙向連結串列刪除結點
int ListDelete_Dbl(DblLinkList& L, int i, ElemType e) {
// 先找到第i個元素的位置
DblLnode* p = L->next;
int j = 1;
while (p!=L && j < i) {
p = (DblLnode*)p->next;
j++;
}
if (p==L || i < 1) return 0; // i<1或i超過表長,刪除位置非法
// 刪除新結點
p->prior->next = p->next; // ①
p->next->prior = p->prior; // ②
return 1;
}
3.3 迴圈連結串列
迴圈連結串列是一種頭尾相接的連結串列,表中最後一個結點的指標域指向頭結點,整個連結串列形成一個環。
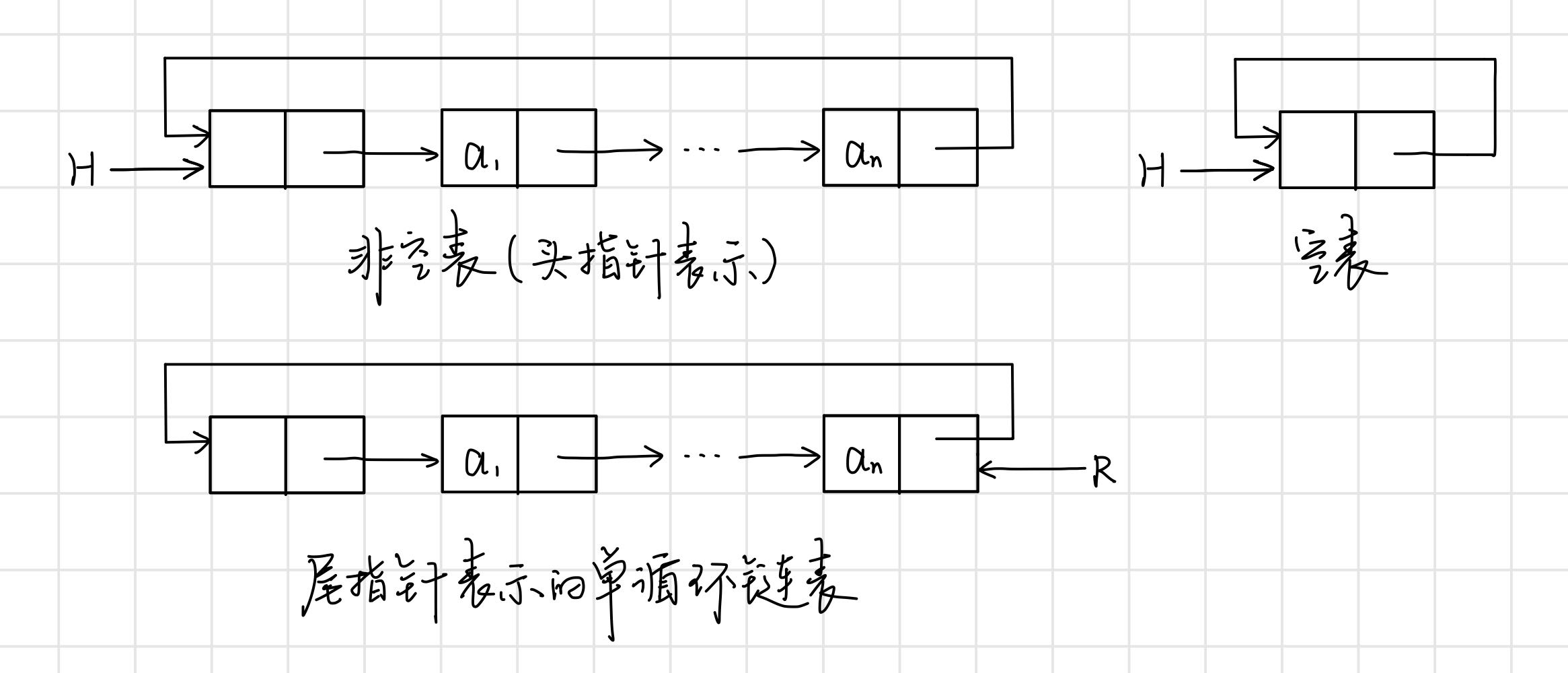
優點:從表中任一結點出發均可找到表中其他結點。
範例:帶尾指標迴圈連結串列的合併(將Tb合併在Ta之後)
【演演算法思路】
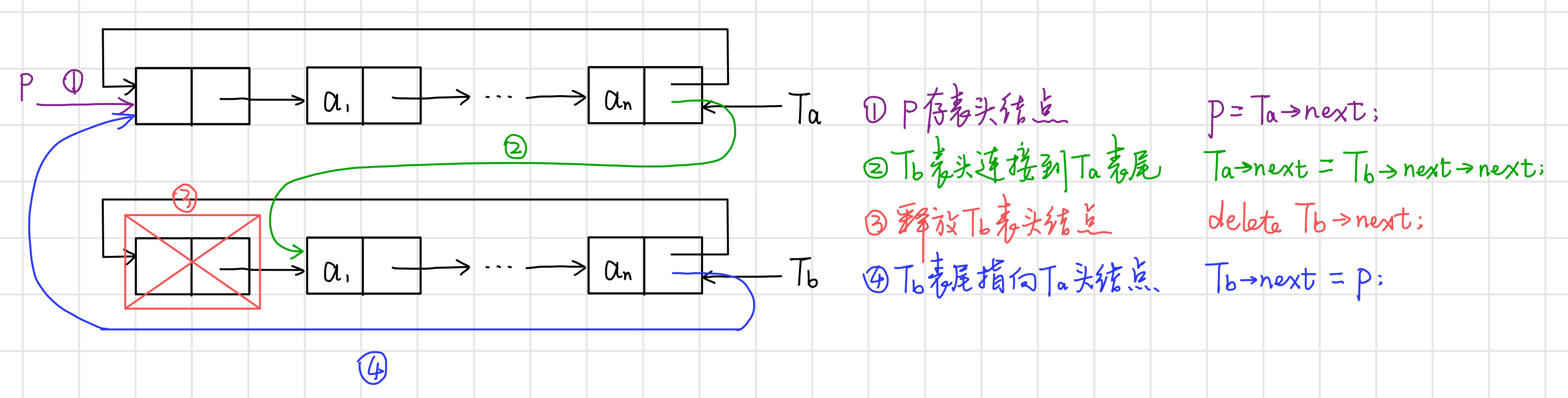
【程式碼】
// 帶尾指標迴圈連結串列的合併
LinkList Connect(LinkList Ta, LinkList Tb) {
Lnode* p;
p = (Lnode*)Ta->next; // p存表頭結點
Ta->next = Tb->next->next; // Tb表頭連線到Ta表尾
delete Tb->next; // 釋放Tb表頭結點
Tb->next = p; // Tb表尾指向Ta頭結點
return Tb;
}
3.4 單連結串列、雙向連結串列和迴圈連結串列的時間效率比較
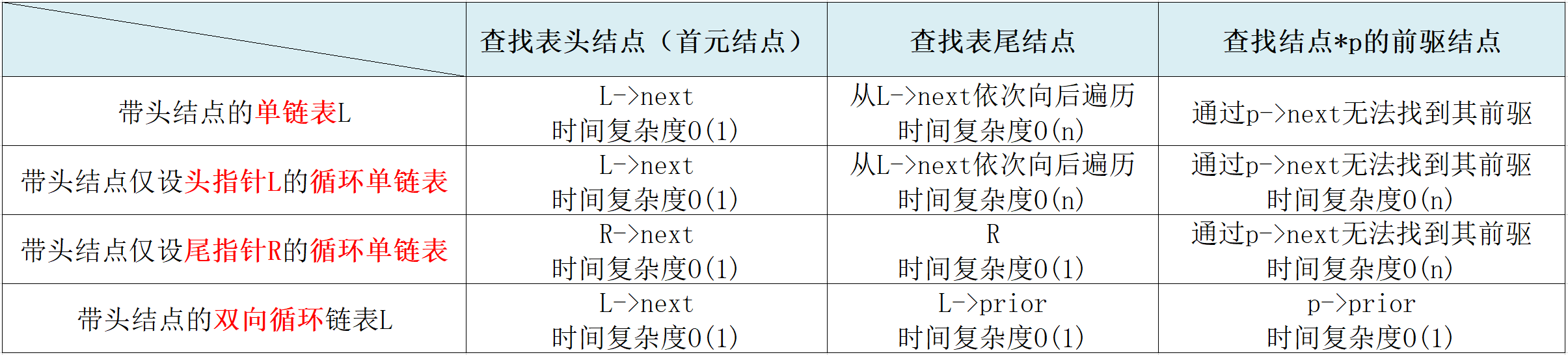
4. 順序表和連結串列的比較
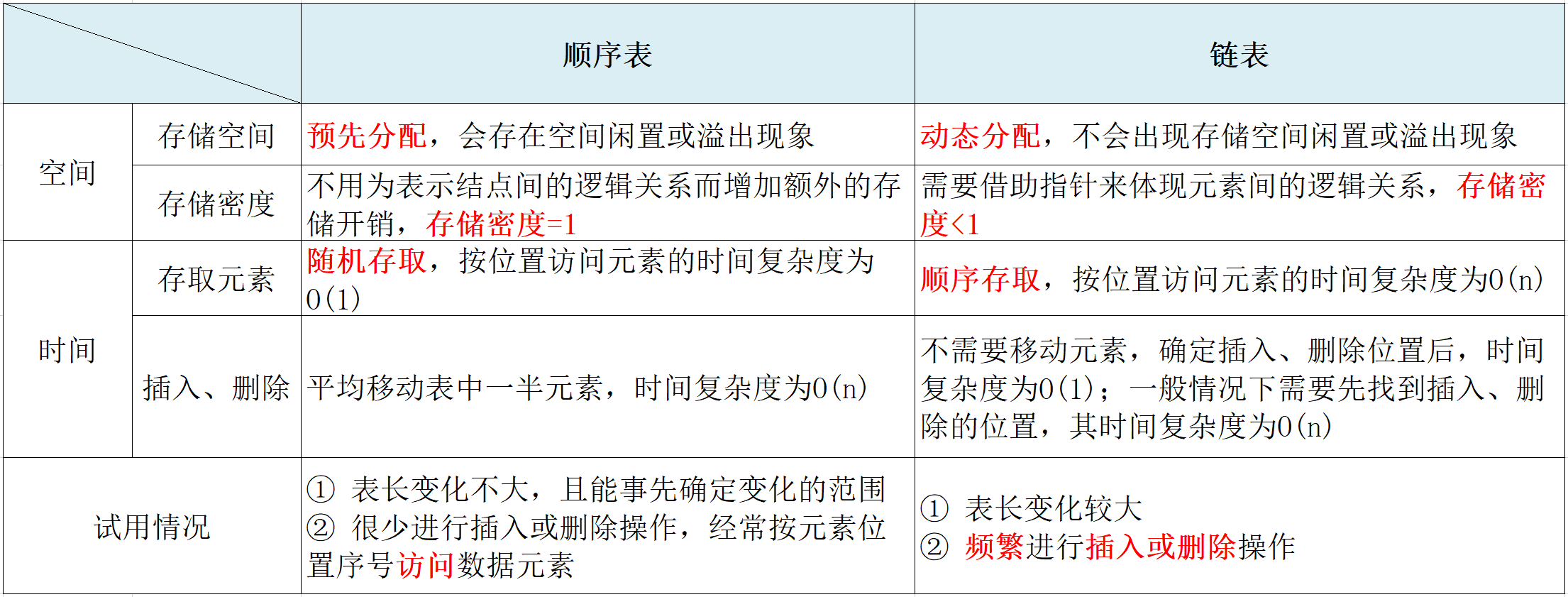
儲存密度定義:
儲存密度 = 結點資料本身佔用的空間 / 結點佔用的空間總量
比如單連結串列某個節點p,其資料域佔8個位元組,指標域佔4個位元組,其儲存密度 = 8/12 = 67%。
5. 線性表的應用
5.1 有序表的合併
已知線性表La和Lb中的資料元素按值非遞減有序排列,現要求將La和Lb歸併為一個新的線性表Lc,且Lc中的資料元素仍按值非遞減有序排列。
例如:La=(1,7,8) Lb=(2,4,6,8,10,11) → Lc=(1,2,4,6,7,8,8,10,11)
(1)順序表實現有序表合併
【演演算法思路】
- 建立一個空表Lc;
- 依次從La和Lb中「摘取」元素值較小的結點插入到Lc表的最後,直至其中一個表變為空;
- 繼續將La或Lb其中一個表的剩餘結點插入到Lc表的最後。
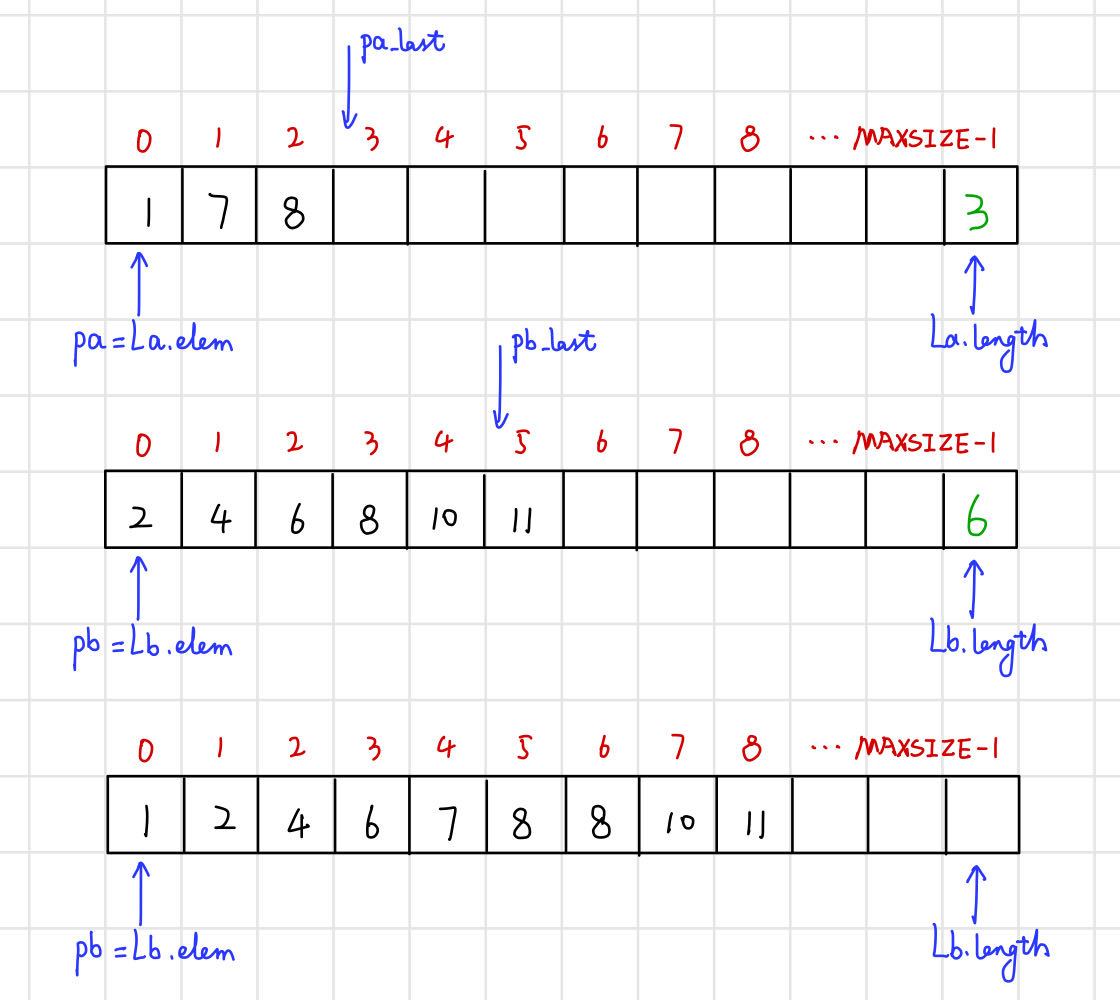
【程式碼】
// 有序表合併:用順序表實現
void MergeList_Sq(SqList La, SqList Lb, SqList& Lc) {
ElemType* pa = La.elem;
ElemType* pb = Lb.elem; // 指標pa和pb的初值分別指向兩個表的第一個元素
Lc.length = La.length + Lb.length; // 新表長為待合併兩表的長度之和
Lc.elem = new ElemType[Lc.length]; // 為合併後的新表分配一個陣列空間
ElemType* pc = Lc.elem; // 指標pc指向新表的第一個元素
ElemType* pa_last = La.elem + La.length - 1; // 指標pa_last指向La表的最後一個元素
ElemType* pb_last = Lb.elem + Lb.length - 1; // 指標pb_last指向Lb表的最後一個元素
while (pa <= pa_last && pb <= pb_last) {
if (*pa < *pb) *pc++ = *pa++; // 依次「摘取」兩表中較小的結點加入Lc
else *pc++ = *pb++;
}
while (pa <= pa_last) *pc++ = *pa++; // Lb表已到達表尾,將La中剩餘元素加入Lc
while (pb <= pb_last) *pc++ = *pb++; // La表已到達表尾,將Lb中剩餘元素加入Lc
}
【演演算法分析】
時間複雜度:O(ListLength(La) + ListLength(Lb))
空間複雜度:O(ListLength(La) + ListLength(Lb))
(2)連結串列實現有序表合併
【演演算法思路】
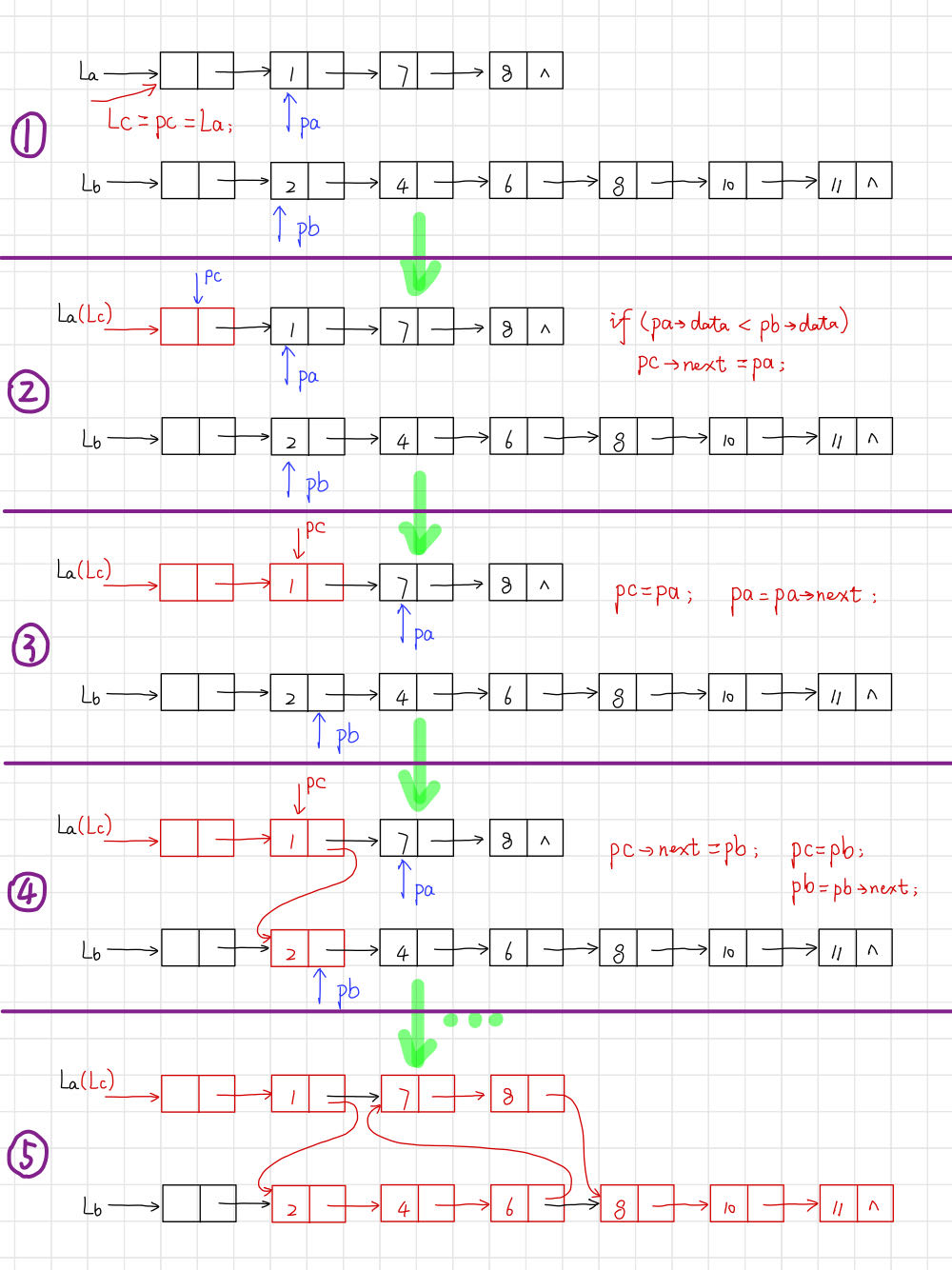
【程式碼】
// 有序表合併:用連結串列實現
void MergeList_L(LinkList& La, LinkList& Lb, LinkList& Lc) {
Lnode* pa = (Lnode*)La->next;
Lnode* pb = (Lnode*)Lb->next;
Lnode* pc = Lc = La; // 用La的頭結點作為Lc的頭結點
while (pa && pb) {
if (pa->data <= pb->data) {
pc->next = pa;
pc = pa;
pa = (Lnode*)pa->next;
}
else {
pc->next = pb;
pc = pb;
pb = (Lnode*)pb->next;
}
}
pc->next = pa ? pa : pb; // 插入剩餘段
delete Lb; // 釋放Lb的頭結點
}
【演演算法分析】
時間複雜度:O(ListLength(La) + ListLength(Lb))
空間複雜度:O(1)