資料測試實踐:從一個bug開始的巨量資料引擎相容性探索
作者:京東零售 李曉潔
我們常常忘記,天才也取決於其所能掌握的資料,即使阿基米德也無法設計出愛迪生的發明。——Ernest Dimnet
在巨量資料時代,精準而有效的資料對於每個致力於長期發展的組織來說都是重要資產之一,而資料測試更是不可或缺的一部分。資料測試不僅關注資料加工的程式碼邏輯,還要考慮巨量資料執行引擎帶來的影響,因為各種引擎框架將對同一份資料產生不同的計算或檢索結果。本文將從一個年度賬單bug引入,講解在資料測試實踐中對巨量資料執行引擎相容性差異的探索。
一、需求內容
京東-我的京東-年度賬單是一年一次,以使用者視角對在平臺一年的消費情況進行總結。賬單從購物,權益,服務等方面切入,幫助使用者挖掘在自我難以認知的資料角度,通過這種方式讓使用者從賬單中發掘打動內心的立意,並主動進行分享和傳播。本次,我京年度賬單以「2022購物印象」為主題,通過不同的資料維度組成村落故事線,使用者以虛擬人物形象貫穿始終,使用者瀏覽完故事線後,可生成購物印象。
年度賬單其中一個報表為使用者年度購買的小家電品類。該報表使用年度賬單彙總表中的小家電品類集合欄位,計算了2022年度某使用者全年最後購買的兩款小家電所在的品類。本文bug分享將圍繞這個欄位展開。
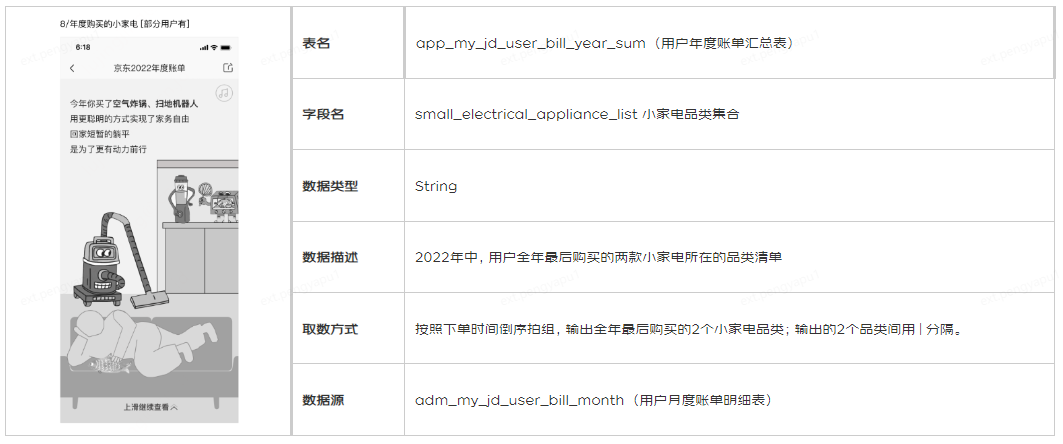
二、 缺陷描述
缺陷描述:在APP層使用者年度賬單彙總模型app_my_jd_user_bill_year_sum中,對於小家電品類集合欄位,APP表結果與手動計算結果不一致。
以使用者'Mercury'、'樂樂1024'、'活力少年'的購買資料為例,上游ADM層以array<string>型別儲存使用者每月購買的小家電相關品類,如下圖所示:
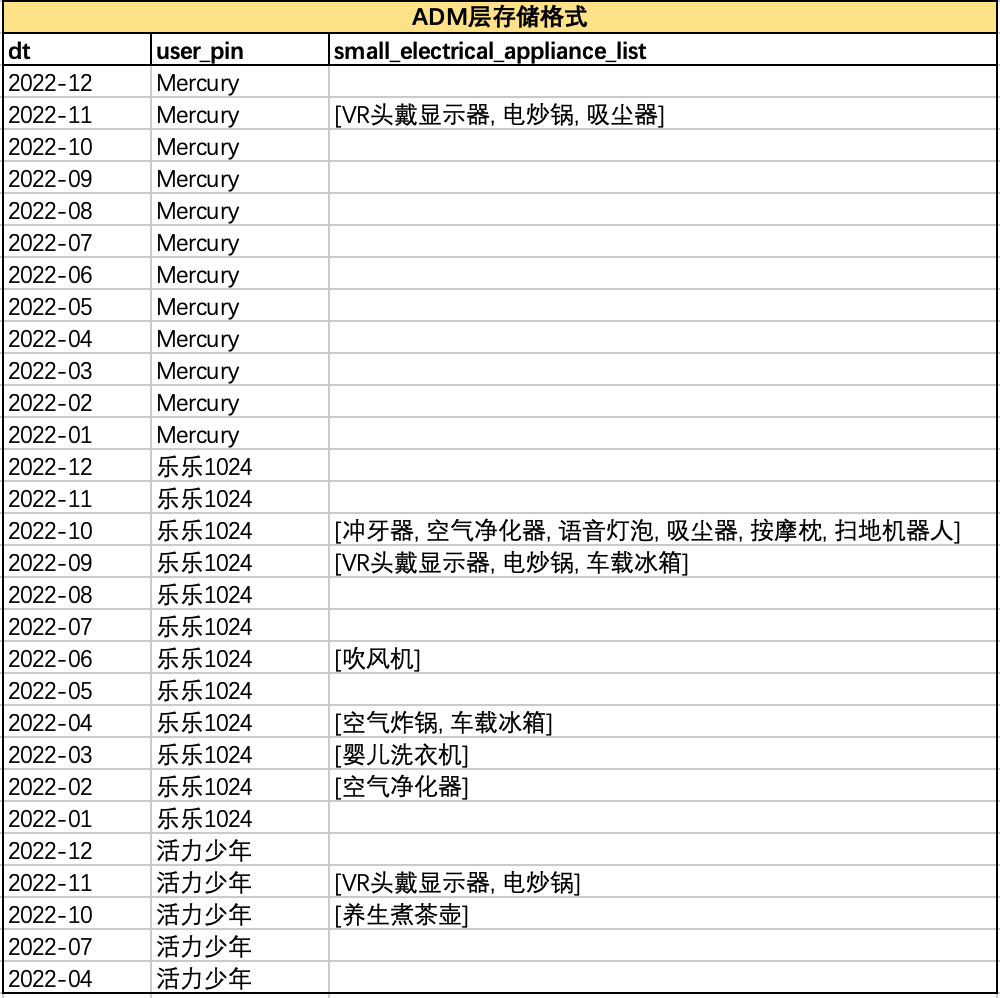
• 根據小家電品類集合欄位定義,APP層應取這三個使用者全年最後購買的2個品類,即'Mercury'在2022年11月購買的VR頭戴顯示器、電炒鍋,'樂樂1024'在2022年10月購買的衝牙器、空氣淨化器,'活力少年'在2022年10月購買的VR頭戴顯示器、電炒鍋。因此,經手動計算,APP層正確計算結果應為:

• 而APP層年度賬單彙總表中的小家電集合品類如下,結果錯誤,不符合預期結果。

三、 缺陷排查過程
1. 執行引擎相容差異
測試排查中,首先發現了Hive和Spark引擎之間的語法相容差異。
• 當使用APP層指令碼中小家電品類集合口徑構建SQL,手動對上游表執行查詢時發現,Hive引擎得到的集合有序,執行結果正確:

• 使用Spark引擎執行查詢時,集合亂序,執行結果錯誤:

2. 指令碼梳理
缺陷原因為集合亂序導致的取數錯誤。每個使用者在上游ADM存在12個陣列對應12個月購買小家電品類的集合,需要集合函數(collect)將12個月分組資料倒序排序,匯合成1個列表,然後取列表前兩個元素。
HQL提供兩種分組聚合函數:collect_list()和collect_set(),區別在於collect_set()會對列表元素去重。由於使用者不同月購買的品類集合可能重複,因此指令碼使用了collect_set()。
然而collect_set()將導致集合亂序,集合中元素不再按月份倒序排列,取出List[0]和List[1]不是使用者全年最後購買的兩個小家電品類。
SELECT
user_pin,
small_electrical_appliance_list,
concat_ws('|', small_electrical_appliance_list[0], small_electrical_appliance_list[1]) AS small_electrical_appliance
FROM(
SELECT
user_pin,
collect_set(concat_ws(',', small_electrical_appliance_list_split)) AS small_electrical_appliance_list
FROM(
SELECT
dt,
user_pin,
small_electrical_appliance_list,
concat_ws(',', small_electrical_appliance_list) AS small_electrical_appliance
FROM adm_my_jd_user_bill_month
WHERE
dt >= '2022-01'
AND dt <= '2022-12'
ORDER BY dt DESC) tmp
lateral VIEW explode(SPLIT(small_electrical_appliance, ',')) tmp AS small_electrical_appliance_list_split
GROUP BY user_log_acct )
3. 結論
• 計算指令碼邏輯錯誤,不應使用collect_set()聚合分組。
• 在原生Hive/Spark中,collect_set()函數均無法保證集合有序,而巨量資料平臺Hive對集合計算有序。因此,該指令碼在Hive引擎下可以達到生成全年最後購買兩個小家電品類的預期目標,但spark引擎則無法得到正確結果。
• Hive執行效率較低,研發通常通過Spark引擎執行,最終導致結果錯誤。
四、巨量資料計算引擎相容差異
1. collect_list()/collect_set() 在hive/spark和presto之間的區別
• collect_set()與collect_list()在Presto中無法相容。
• 替代函數:array_agg() (https://prestodb.io/docs/current/functions/aggregate.html?highlight=array_agg)
| Hive/Spark | Presto |
|---|---|
| collect_list() | array_agg() |
| collect_set() | array_distinct(array_agg()) |
2. 行轉列函數在hive和presto之間的區別
• Hive使用lateral VIEW explode()執行行轉列的操作,而Presto不支援該函數。這種單列的值轉換成和student列一對多的行的值對映.
◦ Hive/Spark query:
lateral VIEW explode(SPLIT(small_electrical_appliance, ',')) tmp AS small_electrical_appliance_list_split
• Presto支援UNNEST來擴充套件array和map。檔案:(https://prestodb.io/docs/current/migration/from-hive.html)
◦ Presto query:
CROSS JOIN UNNEST(SPLIT(small_electrical_appliance, ',')) AS small_electrical_appliance_list_split;
3. 隱式轉換在引擎之間的區別
• Hive/Spark支援包括字串型別到數位型別在內的多種隱式轉換,如將字串'07'轉化為數位7,然後進行比較操作。
◦ Hive隱式轉換規則:詳見連結 Allowed Implicit Conversions
• 雖然Presto也有自己的一套隱式型別轉換規則包含在public Optional<Type> coerceTypeBase(Type sourceType, String resultTypeBase)方法中,但對資料型別的要求更為嚴格。一些在Hive中常見的數位與字串進行比較的查詢語句,Presto會直接拋型別不一致的錯誤。
◦ 下圖為Hive和Presto的隱式轉換規則,藍色區域是Presto和Hive都支援的型別轉換,綠色區域是Presto不支援但是Hive支援的型別轉換,紅色區域是兩者都不支援的型別轉換。可以看到,hive的隱式轉換更為廣泛,而presto尤其在字元型別的隱式轉換中更為嚴格。
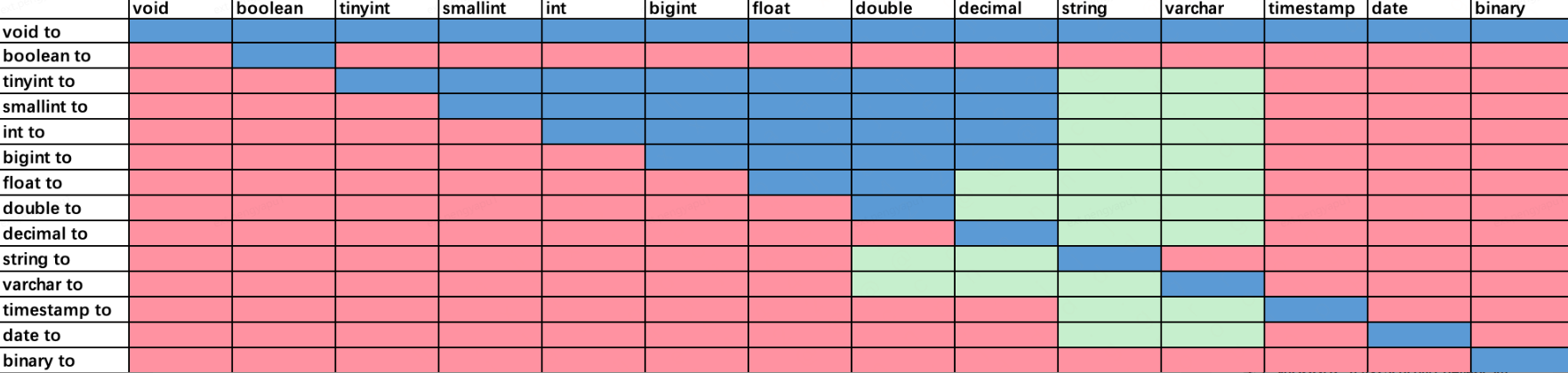
• 隱式轉換範例:
--Hive/Spark隱式轉換
'07' >= 6 -- true (CAST('07' AS DOUBLE) >= CAST(6 AS DOUBLE))
'test' <> 1 -- NULL
'1' = 1.0 -- true
--Presto隱式轉換
'07' >= 6 -- false (CAST('07' AS Varchar) >= CAST(6 AS Varchar))
'test' <> 1 -- true
'1' = 1.0 -- ERROR:io.prestosql.spi.PrestoException: Unexpected parameters (varchar(1), decimal(2,1)) for function $operator$equal. Expected: $operator$equal(T, T) T:comparable