詳解一致性雜湊
在單機系統中,所有的資料都儲存在同一個伺服器下,當資料量越來越多的時候,超過了單機儲存容量的上限,就需要使用分散式儲存系統,在分散式儲存系統重,資料會被拆分到不同的儲存服務下,減少單機服務的壓力。
雜湊演演算法
在分散式系統中,每個節點儲存的資料都是不同的。通過使用分散式儲存,將資料水平拆分到不同的節點上,新的資料也會分配到新的節點上,比如使用取模方式分配節點,先用hash演演算法算出hash值,然後使用hash/N,N是節點數,比如三個節點。
- 取模值=0,分配節點1
- 取模值=1,分配節點2
- 取模值=2,分配節點3
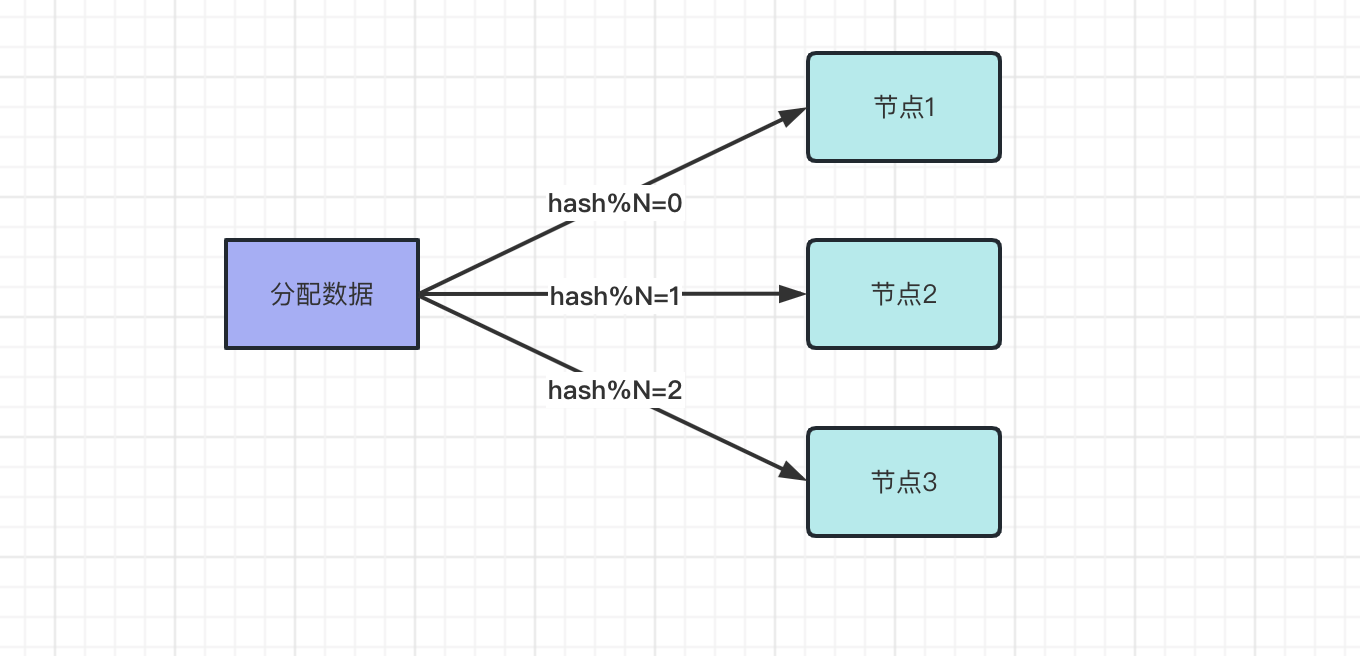
如果節點數量是固定的,資料分配方式是固定的,獲取資料的方式也是固定,資料也能正常的獲取。
如果節點數量發生了變化,新增或者減少節點時,比如新增節點4,原來分配到節點1的資料被分配到節點4,原來的資料對映都無效,資料也無法正常獲取了。這就需要使用到一致性雜湊演演算法。
一致性雜湊
一致性雜湊,從名字就能看出來,該演演算法符合一致性原則,當服務節點數量增加或減少,資料還能正常獲取到。那一致性雜湊有什麼神奇的地方呢?先介紹什麼是一致性雜湊:
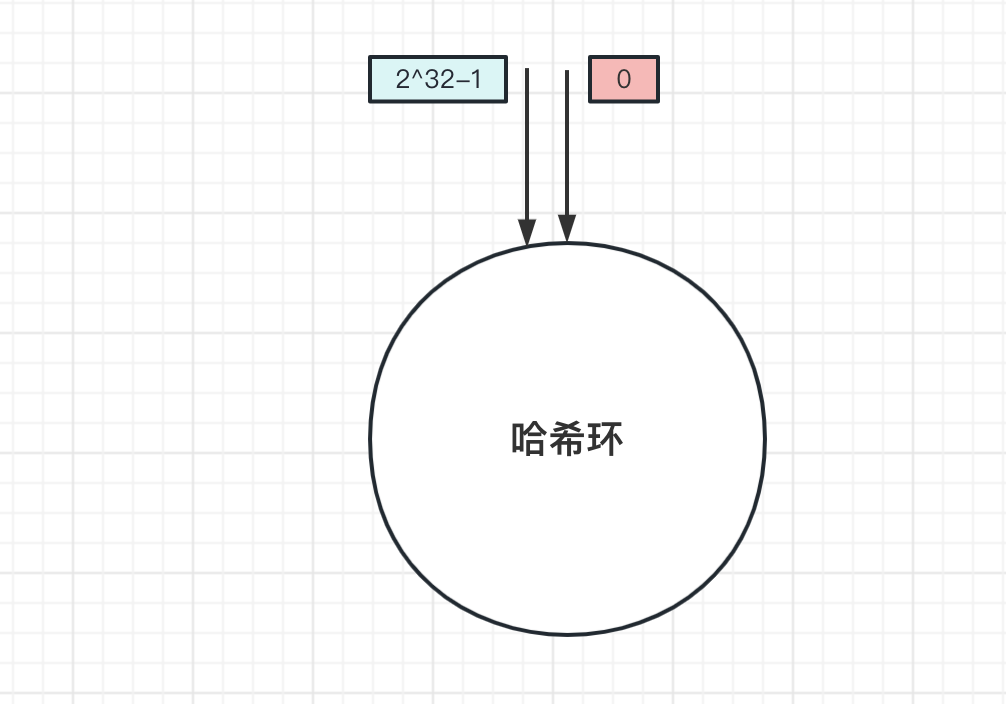
上面是一個雜湊環,環上有2^32個節點。和上面取模演演算法一樣,一致性雜湊演演算法也是取模演演算法,不同的是一致雜湊演演算法是對2^32個節點取模運算,雜湊環的節點是固定的,取模運算結果值也是固定的。
- 資料先進行雜湊運算,獲取雜湊值。
- 對雜湊值對
2^32取模運算。
取模後的值一定是在雜湊環上。那是如何找到儲存的節點呢?答案在環上往順時針方向找到第一個節點。
比如雜湊環上,有三個節點,分別是節點1、節點2、節點3,平均分佈在雜湊環上:
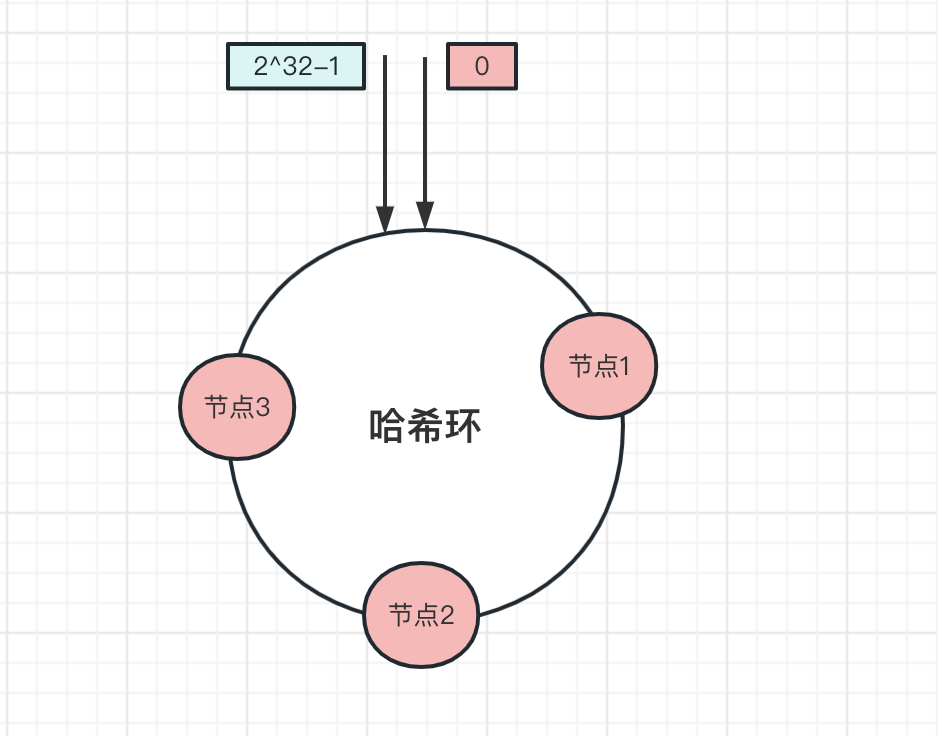
新增一個資料,先算出來雜湊值,確定該資料在雜湊環上的位置,然後從這個位置順時針方向找到第一個節點,就是儲存資料的節點。
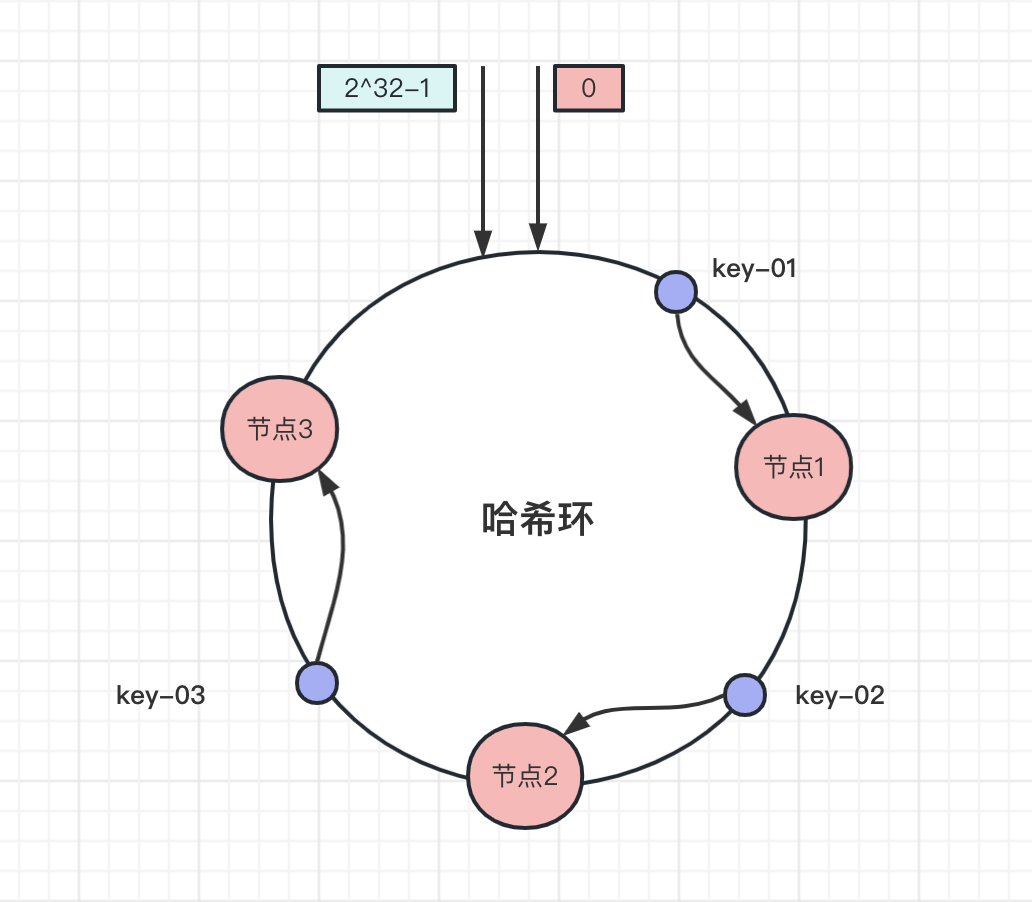
比如下圖中資料key-01,先算出該資料在雜湊環的位置,往順時針方向找到第一個節點,也就是節點1,同理key-02、key-03順時針分別找到節點2和節點3:
增減節點
增加一個節點之後,比如新增加一個節點4,經過雜湊計算獲取節點的位置:
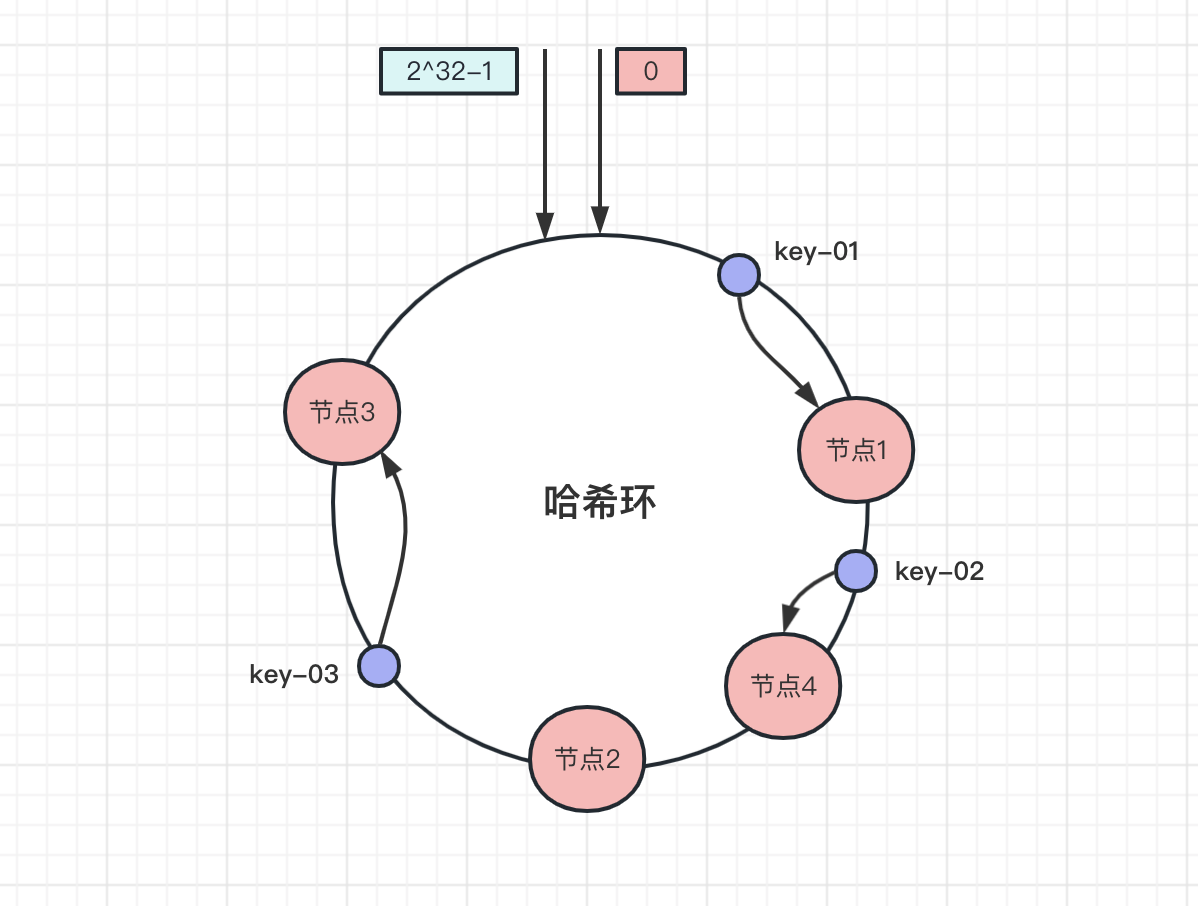
可以看到,此時key-01和key-03資料不受影響,key-02儲存的節點從節點2遷移到了節點4。
那減少一個節點,移除節點1:
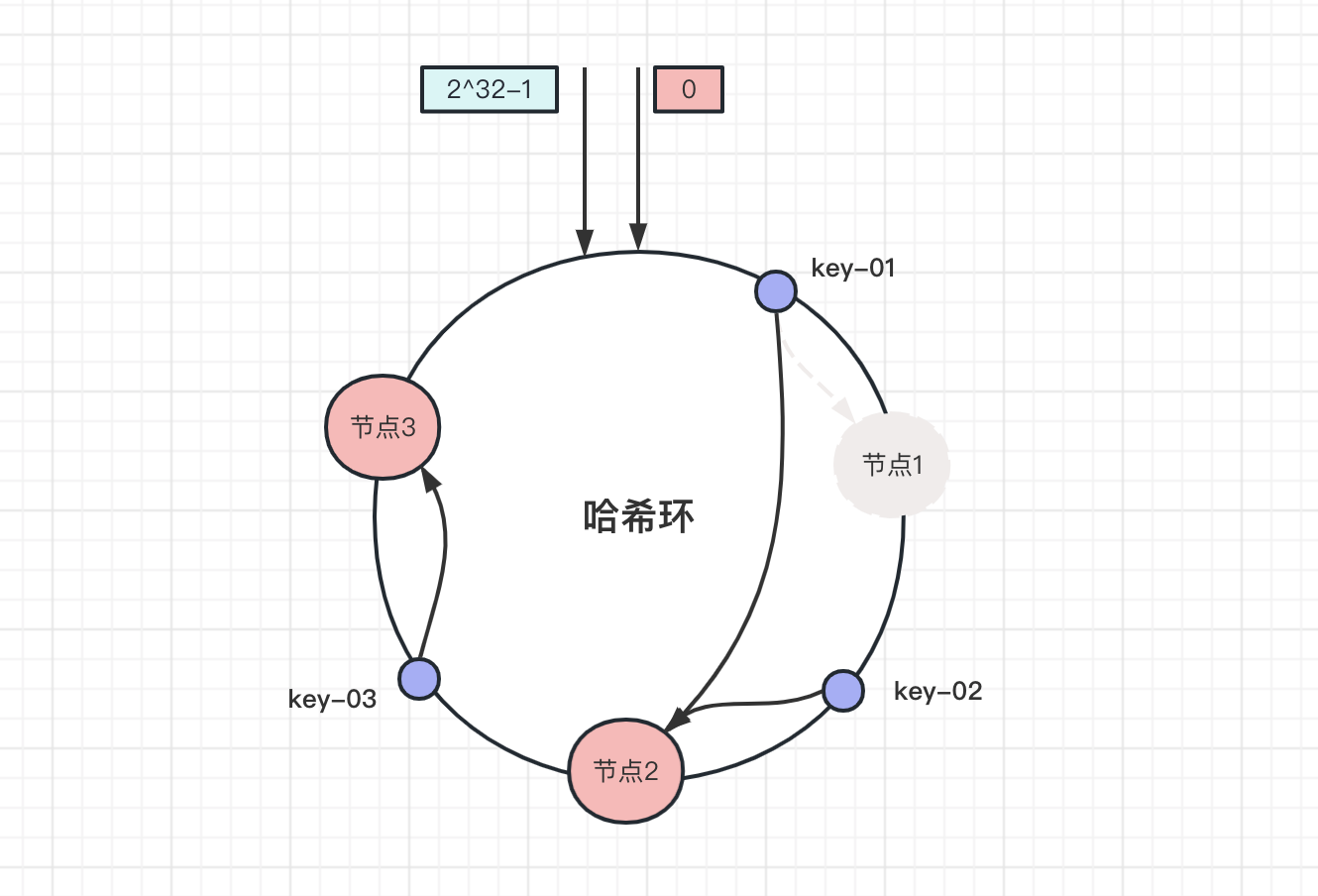
此時key-02和key-03資料不受影響,只有key-01被遷移到節點2。
在一致性雜湊上,增加或減少節點,影響的節點從新節點逆時針方向到上一個節點的資料。
對伺服器節點擴容或者縮容,影響的資料只佔整體資料一小部分,對整體系統的影響不大,對於資料準確性要求多的資料則不適用一致性雜湊。
資料傾斜
上面資料是均勻的分佈在雜湊環上,每個節點的儲存壓力都比較均衡,但是一致性雜湊並不能保證資料會平均的分佈在各個節點上,當大量的資料都分佈在同一個節點上,如下圖所示,大量的節點都分佈在節點3上:
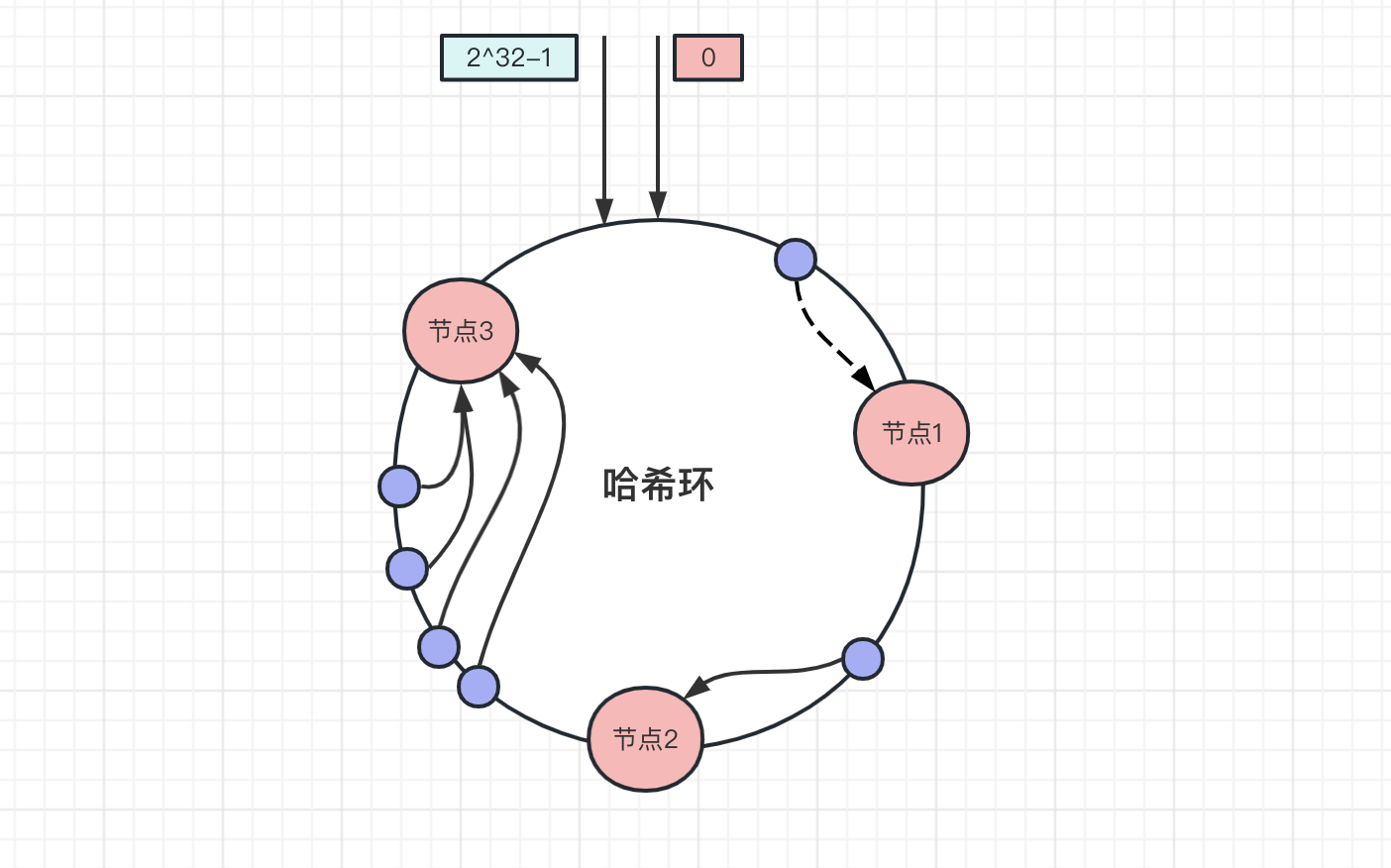
此時請求存取資料主要是集中在節點3上,而環上的節點伺服器設定基本是一致的,不會因為某個伺服器壓力大,就單獨加大某個伺服器的設定。節點3資料儲存和存取量是其他節點的幾倍以上,當請求壓力超過了服務處理的上限後,就會導致節點3崩潰,節點3掛了之後,全部資料壓力都會轉移到節點1,節點1也會宕機,最後形成雪崩。
資料傾斜解決
為了解決資料傾斜問題,一致性雜湊演演算法引入了虛擬節點,一個節點對應多個虛擬節點,上面三個真實節點,每個節點引入3個虛擬節點:
節點1引入三個虛擬節點:1A、1B、1C節點2引入三個虛擬節點:2A、2B、2C節點3引入三個虛擬節點:3A、3B、3C
引入虛擬節點之後,環上一共有9個節點:

節點數量多了之後,資料在雜湊環上的分佈就更加均勻了,就不容易出現上面資料傾斜的問題,當有資料儲存到1A虛擬節點,在通過1A虛擬節點就能找到真實節點節點1了。
在實際應用中,虛擬節點的數量遠大於上面虛擬節點數量。虛擬節點越多,對應的資料分佈就更加的均勻。比如Nginx的一致性雜湊演演算法中的虛擬節點就有160個。
虛擬節點除了使資料分佈更加均衡之外,也會極大的提高資料的穩定性,當節點的數量變化時,會有不同的節點分擔資料的請求壓力,而不會像上面一樣,當一個節點掛了,資料全都轉到另一個節點上,導致雪崩發生。
總結
- 常見的雜湊演演算法,先計算出雜湊值,再根據服務數量取模(hash%N),將資料儲存到固定的伺服器下。
- 當節點增加或者減少,N發生了變化,原來
hash%N方式都失效了,資料也無法正常的獲取了。
- 當節點增加或者減少,N發生了變化,原來
- 一致性雜湊演演算法就是為了解決節點數量發生變化時,資料一致性的問題。
- 在一個環上有
2^32節點,新增一個資料,先算出來雜湊值,然後取模,算出來在環上的位置,往順時針找到第一個服務節點,就是儲存的服務節點。 - 如果新增或者減少服務,比如服務掛了,或者服務擴容了。只是影響從新的服務節點逆時針方向摘到的第一個服務節點,其他資料不受影響。
- 在一個環上有
- 雜湊環資料分佈不均勻時,出現
資料傾斜,就需要引入虛擬節點,一個服務節點對應多個虛擬節點,存取資料請求到虛擬節點,再找到對應的真實服務節點。虛擬節點越多,資料的分佈就越均衡。同時,新增或者減少節點,會有不同的服務節點分攤壓力,使服務更加穩定。