自監督單目深度估計研究
注:剛入門depth estimation,這也是以後的主要研究方向,歡迎同一個方向的加入QQ群(602708168)交流。
1. 論文簡介
論文題目:Digging Into Self-Supervised Monocular Depth Estimation
Paper地址:https://openaccess.thecvf.com/content_ICCV_2019/papers/Godard_Digging_Into_Self-Supervised_Monocular_Depth_Estimation_ICCV_2019_paper.pdf
發表刊物:ICCV
發表時間:2019
2. Abstract
半監督作為有效解決資料不足的手段;
在本文中,作者提出了一種半監督深度估計方法;
半監督嘗試從更復雜的模型結構,損失函數,影象形成模型三個方面來縮小與全監督的差距。
本文的工作細節:
- 最小化重投影損失,解決遮擋問題;
- 全解析度多尺度採用方法,降低視覺偽影;
- 一個自動掩碼損失,忽略違反相機運動假設的訓練畫素;
在KITTTI資料集上取得了滿意的效果。

3. Introduction
說明單目深度估計的研究價值。
並已有工作從立體對或視訊資料來訓練單目深度估計模型。


現有的兩種半監督方法:
基於視訊的,除了估計深度圖以外,還要用一個位姿估計網路估計相機的變換;
基於立體對的,一次性離線校準,但可能導致遮擋和紋理複製偽影。

本文的三個主要工作,前面已經提到。


4. Related Work
4.1 Supervised Depth Estimation
從單個影象估計深度是一個固有的不適定問題,因為相同的輸入影象可以投射到多個合理的深度。
為了解決這個問題,基於學習的方法已經證明自己能夠擬合預測模型,利用彩色影象與其相應深度之間的關係。
研究人員探索了多種方法,如結合區域性預測[19,55],非引數場景取樣[24],到端到端監督學習[9,31,10]。基於學習的演演算法也是立體估計[72,42,60,25]和光流[20,63]效能最好的演演算法之一。

上述許多方法都是完全監督的,在訓練過程中需要地面真相深度。然而,在不同的現實環境中,這是具有挑戰性的。因此,越來越多的工作利用弱監督訓練資料,例如,以已知物件大小[66]、稀疏順序深度[77,6]、監督外觀匹配項[72,73]或未配對的合成深度資料[45,2,16,78]的形式,所有這些都仍然需要收集額外的深度或其他註釋。合成訓練資料是一種替代[41],但要生成包含各種真實世界外觀和運動的大量合成資料並非易事。最近的研究表明,傳統的結構從運動(SfM)管道可以為攝像機姿態和深度生成稀疏訓練訊號[35,28,68],其中SfM通常作為預處理執行步驟與學習解耦。最近,[65]在我們的模型基礎上,結合傳統立體聲演演算法的噪聲深度提示,改進了深度預測。

4.2 Self-supervised Depth Estimation
在缺乏地面真實深度的情況下,一種替代方法是使用影象重建作為監督訊號來訓練深度估計模型。在這裡,模型以立體對或單目序列的形式給出一組影象作為輸入。通過對給定影象的深度產生幻覺並將其投射到附近的檢視中,模型通過最小化影象重建誤差來訓練。

4.2.1 Self-supervised Stereo Training

4.2.2 Self-supervised Monocular Training
一種約束較少的自我監督形式是使用單目視訊,其中連續的時間幀提供訓練訊號。在這裡,除了預測深度之外,網路還必須估計幀之間的相機姿勢,這在物體運動的情況下具有挑戰性。這個估計的相機姿勢只在訓練期間需要,以幫助約束深度估計網路。
在第一個單目自監督方法中,[76]訓練了一個深度估計網路和一個單獨的姿態網路。為了處理非剛性場景運動,一個附加的運動解釋掩碼允許模型忽略違反剛性場景假設的特定區域。然而,他們的模型的後續迭代可線上禁用這一術語,實現了優越的效能。受[4]的啟發,[61]提出了使用多個運動掩模的更復雜的運動模型。然而,這並沒有得到充分的評估,因此很難理解其效用。[71]還將運動分解為剛性和非剛性成分,使用深度和光流來解釋物體的運動。這改善了流量估計,但在流量和深度聯合訓練時沒有改善

最近的方法已經開始縮小單眼和基於立體的自我監督之間的效能差距。[70]約束預測深度與預測表面法線一致,[69]強制邊緣一致。[40]提出了一種基於匹配損失的近似幾何,以鼓勵時間深度一致性。[62]使用深度歸一化層來克服由[15]中常用的深度平滑項引起的對較小深度值的偏好。[5]使用預先計算的範例分割掩碼已知類別,以幫助處理移動物件。

4.2.3 Appearance Based Losses
自我監督訓練通常依賴於對幀間物體表面的外觀(即亮度恆常性)和材料屬性(例如蘭伯特性)的假設。[15]表明,與簡單的兩兩畫素差異相比,包含基於外觀損失的區域性結構[64]顯著提高了深度估計效能[67,12,76]。[28]擴充套件了這種方法,包括誤差擬合項,[43]探索將其與基於對抗的損失相結合,以鼓勵逼真的合成影象。最後,受[72]的啟發,[73]使用ground truth depth來訓練一個外觀匹配項。

5. Method
在這裡,我們描述了我們的深度預測網路,它接受單一顏色輸入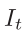 並生成深度圖
並生成深度圖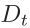 。
。
我們首先回顧了單眼深度估計的自監督訓練背後的關鍵思想,然後描述了我們的深度估計網路和聯合訓練損失。
5.1 Self-Supervised Training
自監督深度估計通過訓練網路從另一個影象的角度預測目標影象的外觀,將學習問題作為一種新的檢視合成問題(其實就是投影,根據估計的深度圖,相機內參,相機位姿矩陣,一個視角的影象,可以投影到另一個視角的影象)。
這樣就可以把深度估計看成一箇中間過程,投影得到的影象和其他視角的影象計算loss來約束網路。這種方法在後面的很多工作中都有用到。
但是,每個畫素都有非常多的可能不正確的深度,給定相對位姿都可以正確地重建兩個檢視。
經典的雙目和多視角立體視覺方法通常通過加強深度圖的平滑性來解決這種模糊性,並通過全域性優化(例如[11])求解逐畫素深度時計算修補程式上的照片一致性。


這裡主要講了幾個損失函數。
投影損失,它所計算的兩個輸入分別是目標視角下的影象和將源視角下的影象投影得到的影象;投影過程為估計的深度圖,相機位姿矩陣,相機內參,源視角下的影象。
另外還計算了光測誤差和邊界感知平滑損失。

在立體匹配中投影最為常用,並且通常是一個深度估計網路和一個位姿估計網路。

5.2 Improved Self-Supervised Depth Estimation
現有的單目方法產生的深度質量低於最好的全監督模型。為了縮小這一差距,本文提出了幾項改進,可以顯著提高預測深度質量,而不需要新增額外的模型元件,這些元件也需要訓練(見圖3)。
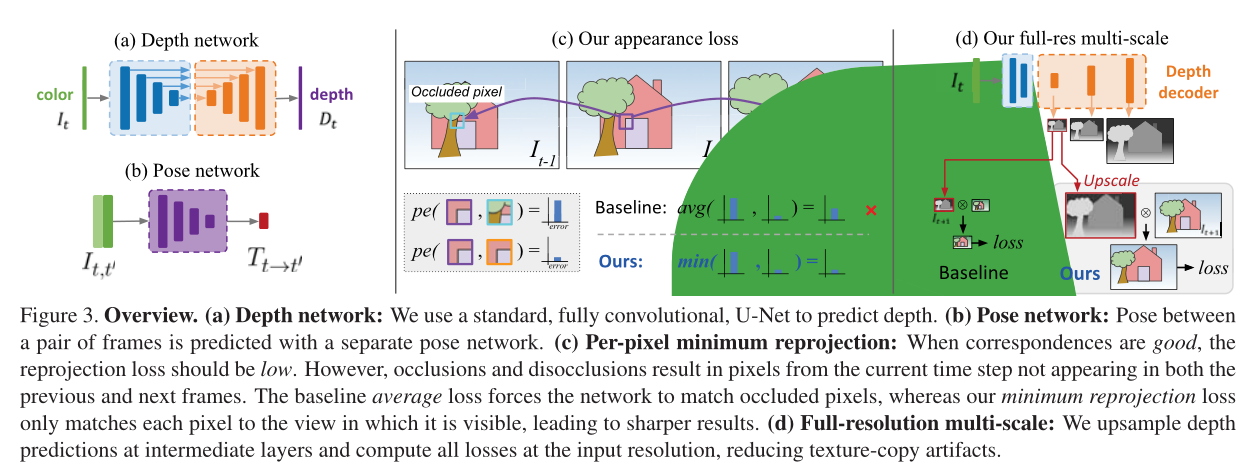
5.2.1 Per-Pixel Minimum Reprojection Loss
在計算多個源影象的重投影誤差時,現有的自監督深度估計方法將每個可用源影象的重投影誤差平均在一起。這可能會導致畫素在目標影象中可見,但在某些源影象中不可見(如圖3(c))。如果網路預測了這樣一個畫素的正確深度,那麼閉塞源影象中的對應顏色很可能與目標不匹配,從而導致高光度誤差懲罰。
這樣的問題畫素來自兩個主要類別:由於影象邊界的自我運動而超出視野的畫素,以及被遮擋的畫素。可以通過在重投影損失中掩蓋這些畫素來減少視域外畫素的影響[40,61],但這不能處理去遮擋,其中平均重投影會導致模糊的深度不連續。(這種方法相當於跳過遮擋)



5.2.2 Auto-Masking Stationary Pixels
自監督單眼訓練通常在移動攝像機和靜態場景的假設下進行。當這些假設失效時,例如當攝像機靜止或場景中有物體運動時,效能會受到很大影響。這個問題在預測測試時間深度圖中表現為無限深度的「洞」,因為在訓練[38]期間通常觀察到物體在移動(圖2)。這激發了我們的第二個貢獻:一個簡單的自動遮蔽方法,過濾掉序列中從一幀到下一幀不改變外觀的畫素。這可以讓網路忽略與攝像機速度相同的物體,甚至在攝像機停止移動時忽略單目視訊中的整幀

像其他工作[76,61,38]一樣,我們也對損失應用逐畫素掩碼μ,選擇性地加權畫素。然而,與之前的工作相反,我們的掩碼是二進位制的,因此μ∈{0,1},並且在網路的正向傳遞上自動計算,而不是從物件運動中學習或估計。我們觀察到,序列中相鄰幀之間保持相同的畫素通常表示靜態攝像機,以等效相對平移移動的物體到攝像機,或低紋理區域。因此,我們將μ設定為僅包括丟失的畫素,其中扭曲影象的重投影誤差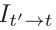 低於原始的、未扭曲的源影象
低於原始的、未扭曲的源影象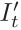 ,即
,即

其中[]為艾弗森方陣。當相機和另一個物體都以相似的速度移動時,μ防止影象中保持靜止的畫素汙染損失。類似地,當相機靜止時,掩模可以過濾掉影象中的所有畫素(圖5)。
我們實驗表明,這種簡單和廉價的修改損失帶來了顯著的改善。


5.2.3 Multi-scale Estimation
由於雙線性取樣器[21]的梯度局域性,為了防止訓練目標陷入區域性極小值,現有模型使用多尺度深度預測和影象重建。這裡,總損耗是解碼器中每個標度上的單個損耗的組合。[12,15]計算影象在每個解碼器層解析度上的光度誤差。我們觀察到,在中間較低解析度的深度圖中,這傾向於在大的低紋理區域中建立「洞」,以及紋理複製偽影(深度圖中的細節不正確地從彩色影象轉移過來)。深度孔可能出現在低解析度的低紋理區域,其中光度誤差是不明確的。這使得深度網路的任務變得複雜,現在可以自由地預測不正確的深度

受立體重建[56]技術的啟發,我們提出了對這種多尺度公式的改進,其中我們解耦了用於計算重投影誤差的視差影象和彩色影象的解析度。我們不計算模糊低解析度影象上的光度誤差,而是首先對低解析度深度圖(從中間層)上取樣到輸入影象解析度,然後重新投影,重新取樣,並在這個較高的輸入解析度下計算誤差pe(圖3 (d))。這個過程類似於匹配修補程式,因為低解析度的視差值將在高解析度影象中扭曲整個畫素「修補程式」。這有效地限制了每個比例尺上的深度圖朝著相同的目標工作,即儘可能準確地重建高解析度輸入目標影象。

5.3 Additional Considerations
我們的深度估計網路基於通用的U-Net架構[53],即一個編碼器-解碼器網路,具有跳過連線,使我們能夠表示深度抽象特徵以及區域性資訊。我們使用ResNet18[17]作為編碼器,與現有工作[15]中使用的更大、更慢的disnet和ResNet50模型相比,它包含11M個引數。與[30,16]類似,我們從ImageNet[54]上預訓練的權重開始,並表明與從頭開始訓練相比,這提高了我們緊湊模型的準確性(表2)。我們的深度解碼器類似於[15],輸出處是sigmoids,其他地方是ELU非線性[7]。我們將sigmoid輸出σ轉換為深度D = 1/(aσ + b),其中選擇a和b將D限制在0.1到100個單位之間。我們在解碼器中使用反射填充來代替零填充,當樣本落在影象邊界之外時,返回源影象中最接近邊界畫素的值。我們發現這大大減少了現有方法(例如[15])中的邊界構件。


對於姿態估計,我們遵循[62]並使用軸角表示來預測旋轉,並將旋轉和平移輸出按0.01縮放。對於單目訓練,我們使用三幀的序列長度,而我們的姿態網路由ResNet18組成,修改為接受一對彩色影象(或六個通道)作為輸入,並預測單個6-DoF相對姿態。我們執行水平翻轉和以下訓練增強,概率為50%:隨機亮度、對比度、飽和度和色調抖動,範圍分別為±0.2、±0.2、±0.2和±0.1。重要的是,顏色增強只應用於饋送到網路的影象,而不是用於計算Lp的影象。輸入到姿態和深度網路的所有三張影象都使用相同的引數進行增強。

訓練引數設定;
我們的模型在PyTorch[46]中實現,使用Adam[26]訓練了20個epoch,除非另有說明,批次處理大小為12,輸入/輸出解析度為640 × 192。對於前15個epoch,我們使用10−4的學習率,然後對於其餘的epoch,學習率下降到10−5。這是使用10%的資料的專用驗證集選擇的。
平滑項λ設定為0.001。對於立體聲(S)、單眼(M)和單眼加立體聲模型(MS),單個Titan Xp的訓練分別需要8小時、12小時和15小時。

6. Experiments
在這裡,我們驗證:(1)與現有的畫素平均相比,我們的重投影損失有助於處理被遮擋的畫素,(2)我們的自動掩蔽改善了結果,特別是在使用靜態攝像機的場景訓練時,以及(3)我們的多尺度外觀匹配損失提高了精度。我們在KITTI 2015立體資料集[13]上評估了名為Monodepth2的模型,以便與之前發表的單目方法進行比較。
6.1 KITTI Eigen Split
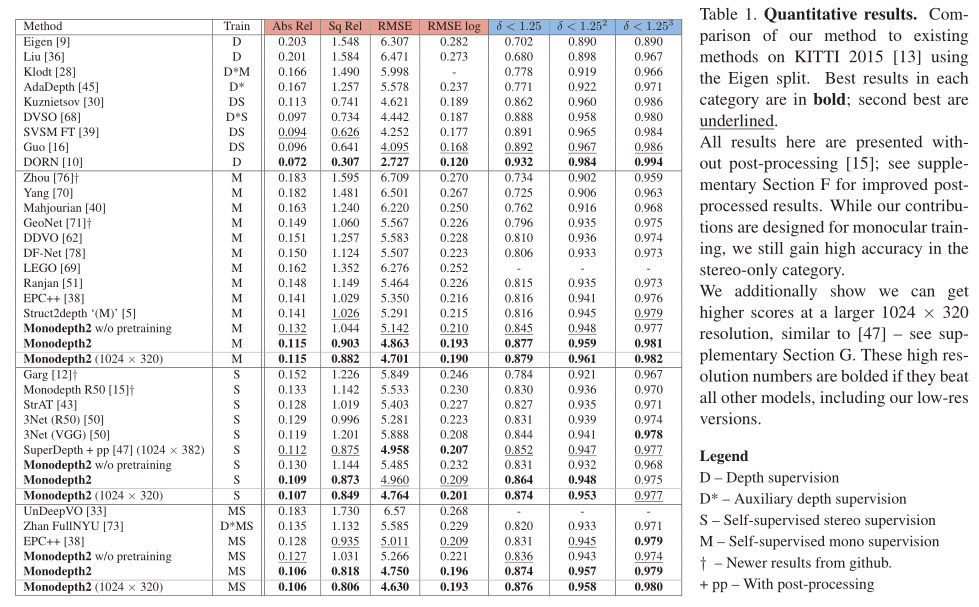
我們使用Eigen et al[8]的資料分割。除燒蝕實驗外,對於使用單眼序列(即單眼和單眼加立體)的訓練,我們遵循Zhou等人[76]的預處理來去除靜態幀。結果有39810個單眼三影象對用於訓練,4424個用於驗證。我們對所有影象使用相同的intrinsic,將相機的主點設定為影象中心,焦距設定為KITTI中所有焦距的平均值。對於立體和混合訓練,我們將兩個立體幀之間的變換設為一個固定長度的純水平平移。在評估過程中,我們將每個標準作業[15]的深度限制在80m。對於我們的單目模型,我們使用[76]引入的逐影象中值真實值縮放來報告結果。另請參閱補充材料D.2節,瞭解我們對整個測試集應用單箇中值縮放的結果,而不是獨立縮放每個影象。對於使用任何立體監控的結果,我們不執行中值縮放,因為在訓練期間可以從已知的攝像機基線推斷出尺度。

我們比較了用不同型別的自我監督訓練的模型的幾個變體的結果:僅單目視訊(M),僅立體(S)和兩者(MS)。表1中的結果表明,我們的單目方法優於所有現有的最先進的自監督方法。我們也優於最近明確計算光流和運動掩模的方法([38,51])。定性結果見圖7和補充部分E。
然而,與所有基於影象重建的深度估計方法一樣,當場景包含違反我們外觀損失的蘭伯假設的物件時,我們的模型會中斷(圖8)。

正如預期的那樣,M和S訓練資料的組合提高了準確性,這在對大深度誤差(如RMSE)敏感的指標上尤其明顯。儘管我們的貢獻是圍繞單眼訓練設計的,但我們發現在只有立體的情況下,我們仍然表現良好。儘管我們使用了比[47]的1024 × 384更低的解析度,但我們獲得了很高的精度,訓練時間大大減少(20對200 epoch),並且不使用後處理。


6.1.1 KITTI Eigen Split
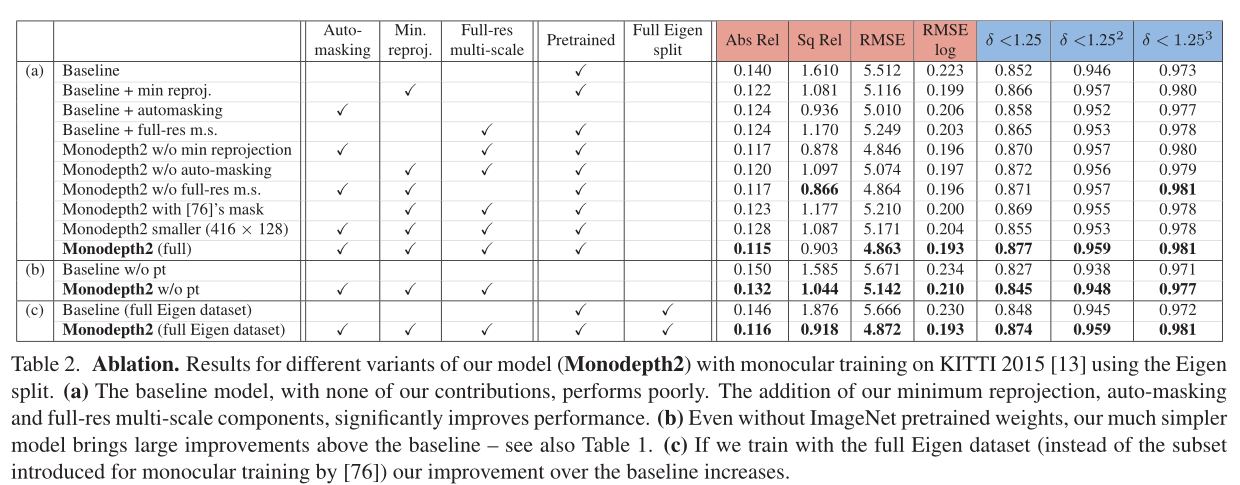
為了更好地理解我們的模型的組成部分如何對單眼訓練的整體表現做出貢獻,在表2(a)中,我們通過改變模型的各個組成部分來進行消融研究。我們看到基線模型,沒有我們的任何貢獻,表現最差。當組合在一起時,我們所有的元件都會帶來顯著的改進(Monodepth2 (full))。更多的實驗依次關閉我們的完整模型的部分在補充材料C節中顯示。

完整的Eigen [8] KITTI分割包含幾個序列,其中相機不會在幀之間移動,例如資料捕捉車停在紅綠燈前。這些「無相機運動」序列可能會導致自監督單目訓練的問題,因此,在訓練時通常會使用昂貴的計算光流來排除它們[76]。我們報告在表2(c)中完整的特徵資料分割上訓練的單目結果,即不移除幀。在KITTI完整分割上訓練的基線模型比我們的完整模型表現得更差。
此外,在表2(a)中,我們用[76]中的預測掩碼的重新實現取代了我們的自動掩碼損失。
我們發現這種消融實驗模型比不使用掩蔽更差,而我們的自動掩蔽在所有情況下都改善了結果。我們在圖5中看到了一個自動遮蔽在實踐中如何工作的例子。


我們遵循之前的工作[14,30,16],使用在ImageNet[54]上預訓練的權重初始化我們的編碼器。雖然其他一些單目深度預測工作選擇不使用ImageNet預訓練,但我們在表1中顯示,即使沒有預訓練,我們仍然可以獲得最先進的結果。我們訓練這些「w/o預訓練」模型30個epoch,以確保收斂。表2顯示了我們的貢獻給預訓練網路和從頭訓練的網路帶來的好處;更多的消融見補充材料C部分。

6.2 Additional Datasets
在補充材料的A節中,我們展示了KITTI的里程計評估。雖然我們的重點是更好的深度估計,但我們的姿態網路的表現與其他競爭方法相當。競爭的方法通常向它們的姿態網路提供更多的幀,這可能會提高它們的泛化能力。我們使用這種新的基準分割訓練模型,並使用線上伺服器[27]對其進行評估,並在補充部分D.3中提供結果。此外,93%的特徵分割測試幀具有[59]提供的更高質量的地面真值深度。像[1]一樣,我們使用這些而不是重新投影的LIDAR掃描來將我們的方法與幾個現有的基線演演算法進行比較,仍然顯示出優越的效能。

我們還在最近推出的KITTI深度預測評估資料集[59]上進行了實驗,該資料集具有更準確的地面真實深度,解決了質量問題


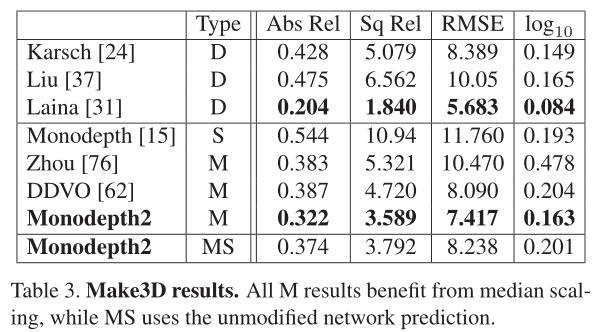
在表3中,我們使用在KITTI上訓練的模型報告Make3D資料集[55]上的效能。我們優於所有不使用深度監督的方法,評估標準為[15]。但是,使用Make3D時應該謹慎,因為它的地面真實值深度和輸入影象沒有很好地對齊,從而導致潛在的評估問題。我們對2 × 1的中心作物進行評估,並對我們的M模型應用中值縮放。定性結果見圖6和補充部分E。

7. 總結
本文的主要貢獻:
- 提出了一個最小化投影損失(minimum reprojection loss),解決了遮擋問題;
- 提出了一個自動掩碼損失(auto-masking loss),忽略混淆,靜止畫素;
- 提出了一種全解析度多尺度取樣方法;
這篇工作還是挺有意義的,後續很多工作都與之對比。
8. 結語
努力去愛周圍的每一個人,付出,不一定有收穫,但是不付出就一定沒有收穫! 給街頭賣藝的人零錢,不和深夜還在擺攤的小販討價還價。願我的部落格對你有所幫助(*^▽^*)(*^▽^*)!
如果客官喜歡小生的園子,記得關注小生喲,小生會持續更新(#^.^#)(#^.^#)。