如何發現截斷的資料項
截斷(形容詞):縮寫、刪節、縮減、剪下、剪裁、裁剪、修剪……
資料項被截斷的一種情況是將其輸入到資料庫欄位中,該欄位的字元限制比資料項的長度要短。例如,字串:
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA是 60 個字元長。如果你將其輸入到具有 50 個字元限制的“位置”欄位,則可以獲得:
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #末尾帶有一個空格截斷也可能導致資料錯誤,比如你打算輸入:
Sally Ann Hunter (aka Sally Cleveland)但是你忘記了閉合的括號:
Sally Ann Hunter (aka Sally Cleveland這會讓使用資料的使用者覺得 Sally 是否有被修剪掉了資料項的其它的別名。
截斷的資料項很難檢測。在稽核資料時,我使用三種不同的方法來查詢可能的截斷,但我仍然可能會錯過一些。
資料項的長度分布。第一種方法是捕獲我在各個欄位中找到的大多數截斷的資料。我將欄位傳遞給 awk 命令,該命令按欄位寬度計算資料項,然後我使用 sort 以寬度的逆序列印計數。例如,要檢查以 tab 分隔的檔案 midges 中的第 33 個欄位:
awk -F"\t" 'NR>1 {a[length($33)]++} \ END {for (i in a) print i FS a[i]}' midges | sort -nr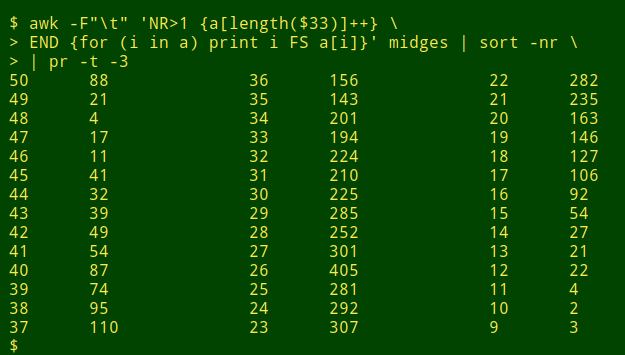
最長的條目恰好有 50 個字元,這是可疑的,並且在該寬度處存在資料項的“凸起”,這更加可疑。檢查這些 50 個字元的專案會發現截斷:
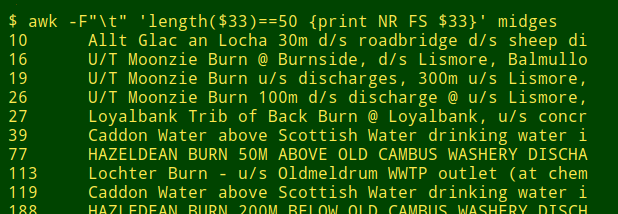
我用這種方式檢查的其他資料表有 100、200 和 255 個字元的“凸起”。在每種情況下,這種“凸起”都包含明顯的截斷。
未匹配的括號。第二種方法查詢類似 ...(Sally Cleveland 的資料項。一個很好的起點是資料表中所有標點符號的統計。這裡我檢查檔案 mag2:
grep -o "[[:punct:]]" file | sort | uniqc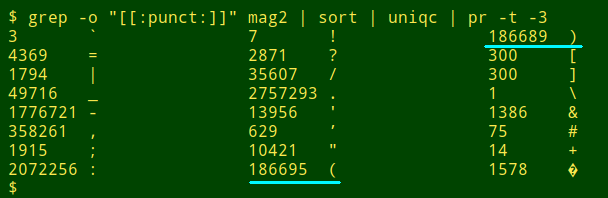
請注意,mag2 中的開括號和閉括號的數量不相等。要檢視發生了什麼,我使用 unmatched 函數,它接受三個引數並檢查資料表中的所有欄位。第一個引數是檔名,第二個和第三個是開括號和閉括號,用引號括起來。
unmatched(){ awk -F"\t" -v start="$2" -v end="$3" \ '{for (i=1;i<=NF;i++) \ if (split($i,a,start) != split($i,b,end)) \ print "line "NR", field "i":\n"$i}' "$1"}如果在欄位中找到開括號和閉括號之間不匹配,則 unmatched 會報告行號和欄位號。這依賴於 awk 的 split 函數,它返回由分隔符分隔的元素數(包括空格)。這個數位總是比分隔符的數量多一個:
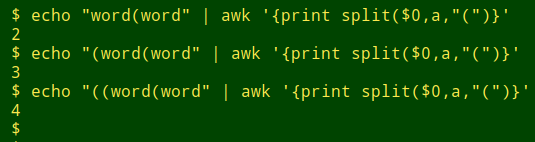
這裡 ummatched 檢查 mag2 中的圓括號並找到一些可能的截斷:
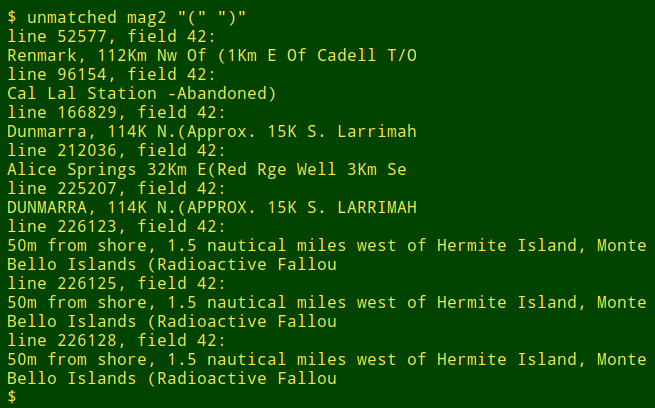
我使用 unmatched 來找到不匹配的圓括號 ()、方括號 []、花括號 {} 和尖括號 <>,但該函數可用於任何配對的標點字元。
意外的結尾。第三種方法查詢以尾隨空格或非終止標點符號結尾的資料項,如逗號或連字元。這可以在單個欄位上用 cut 用管道輸入到 grep 完成,或者用 awk 一步完成。在這裡,我正在檢查以製表符分隔的表 herp5 的欄位 47,並提取可疑資料項及其行號:
cut -f47 herp5 | grep -n "[ ,;:-]$"或awk -F"\t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5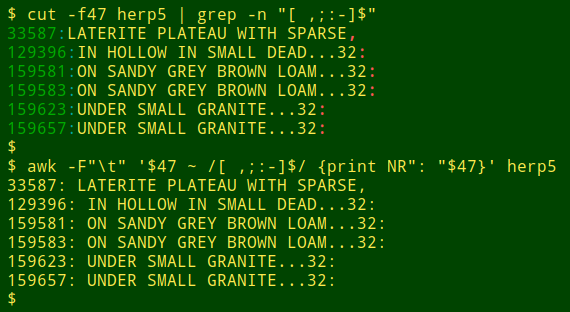
用於製表符分隔檔案的 awk 命令的全欄位版本是:
awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/) \ print "line "NR", field "i":\n"$i}' file謹慎的想法。在我對欄位進行的驗證測試期間也會出現截斷。例如,我可能會在“年”的欄位中檢查合理的 4 位數條目,並且有個 198 可能是 198n?還是 1898 年?帶有丟失字元的截斷資料項是個謎。 作為資料審計員,我只能報告(可能的)字元損失,並建議資料編制者或管理者恢復(可能)丟失的字元。