雲原生虛擬網路 tun/tap & veth-pair
雲原生虛擬網路 tun/tap & veth-pair
轉載請宣告出處哦~,本篇文章釋出於luozhiyun的部落格:https://www.luozhiyun.com/archives/684
以前在研究 k8s 網路的時候,很多東西都看不太懂,只是蜻蜓點水過一下,這段時間打算惡補一下虛擬網路方面的知識,感興趣的不妨一起探討學習一下。
概述
目前主流的虛擬網路卡方案有tun/tap和veth兩種。在時間上 tun/tap 出現得更早,在 Linux Kernel 2.4 版之後釋出的核心都會預設編譯 tun/tap 的驅動。並且 tun/tap 應用非常廣泛,其中雲原生虛擬網路中, flannel 的 UDP 模式中的 flannel0 就是一個 tun 裝置,OpenVPN 也利用到了 tun/tap 進行資料的轉發。
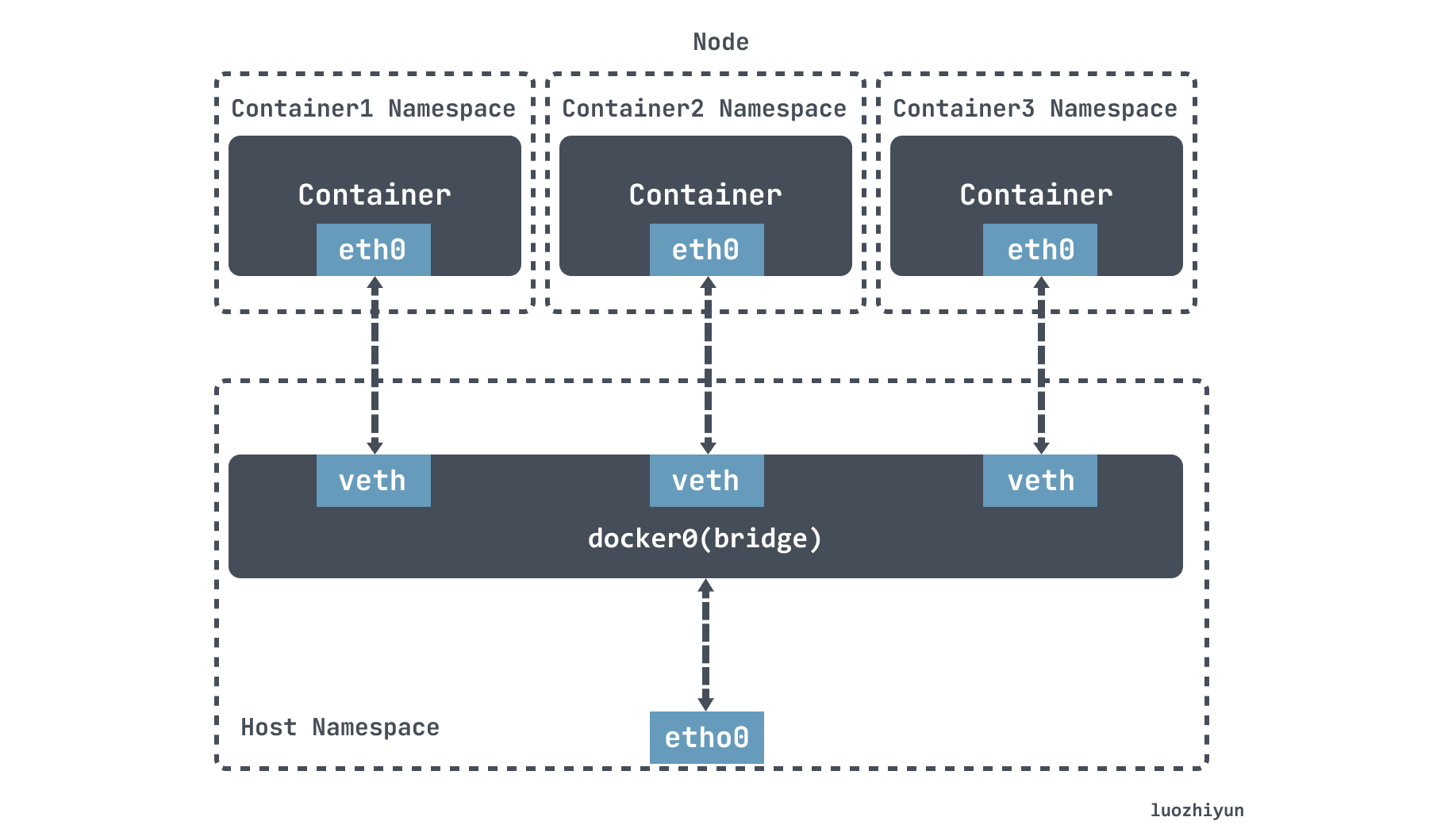
veth 是另一種主流的虛擬網路卡方案,在 Linux Kernel 2.6 版本,Linux 開始支援網路名空間隔離的同時,也提供了專門的虛擬乙太網(Virtual Ethernet,習慣簡寫做 veth)讓兩個隔離的網路名稱空間之間可以互相通訊。veth 實際上不是一個裝置,而是一對裝置,因而也常被稱作 Veth-Pair。
Docker 中的 Bridge 模式就是依靠 veth-pair 連線到 docker0 網橋上與宿主機乃至外界的其他機器通訊的。
tun/tap
tun 和 tap 是兩個相對獨立的虛擬網路裝置,它們作為虛擬網路卡,除了不具備物理網路卡的硬體功能外,它們和物理網路卡的功能是一樣的,此外tun/tap負責在核心網路協定棧和使用者空間之間傳輸資料。
- tun 裝置是一個三層網路層裝置,從 /dev/net/tun 字元裝置上讀取的是 IP 封包,寫入的也只能是 IP 封包,因此常用於一些對等IP隧道,例如OpenVPN,IPSec等;
- tap 裝置是二層鏈路層裝置,等同於一個乙太網裝置,從 /dev/tap0 字元裝置上讀取 MAC 層資料框,寫入的也只能是 MAC 層資料框,因此常用來作為虛擬機器器模擬網路卡使用;
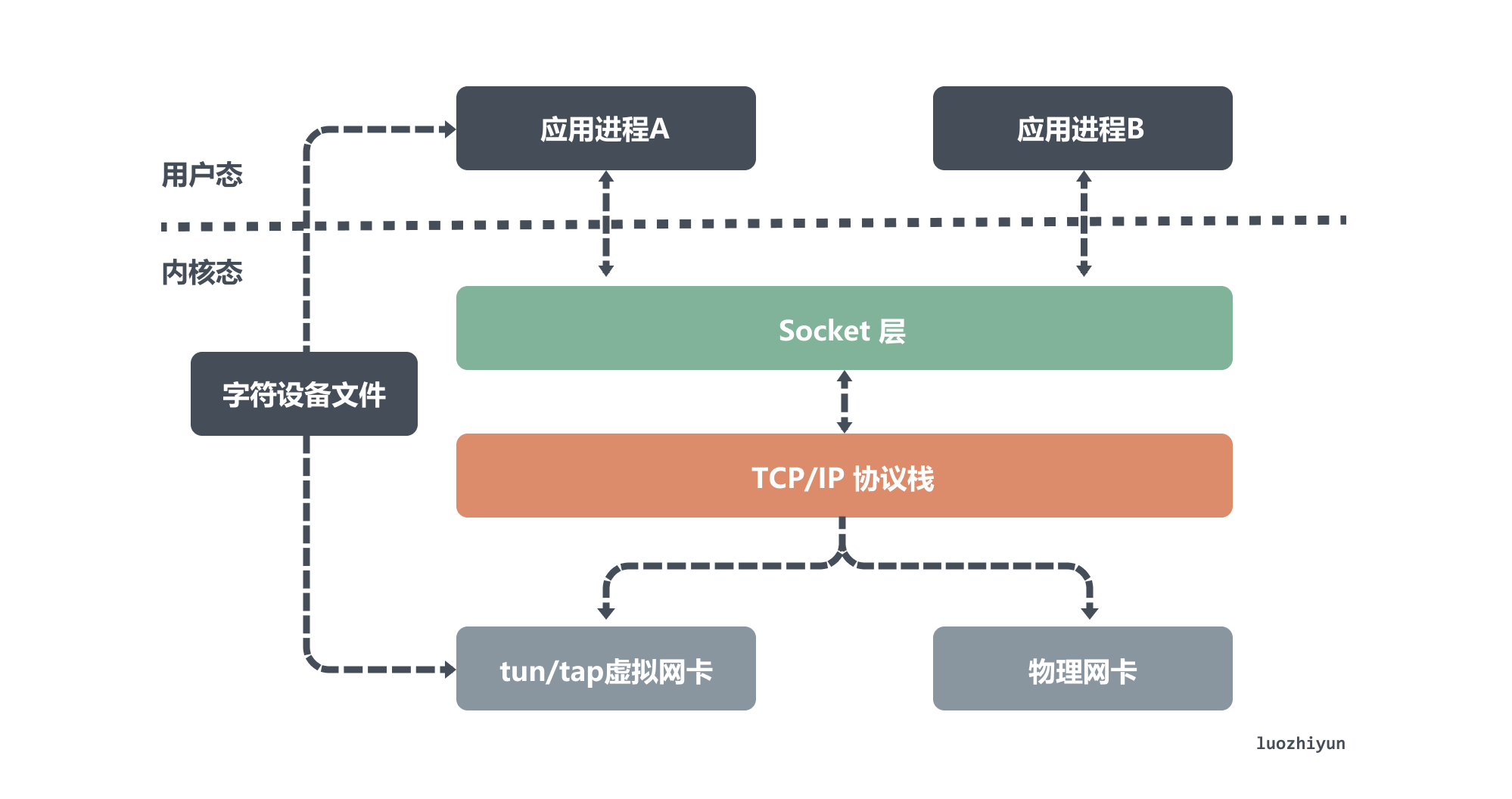
從上面圖中,我們可以看出物理網路卡和 tun/tap 裝置模擬的虛擬網路卡的區別,雖然它們的一端都是連著網路協定棧,但是物理網路卡另一端連線的是物理網路,而 tun/tap 裝置另一端連線的是一個檔案作為傳輸通道。
根據前面的介紹,我們大約知道虛擬網路卡主要有兩個功能,一個是連線其它裝置(虛擬網路卡或物理網路卡)和 Bridge 這是 tap 裝置的作用;另一個是提供使用者空間程式去收發虛擬網路卡上的資料,這是 tun 裝置的作用。
主要區別是因為它們作用在不同的網路協定層,換句話說 tap裝置是一個二層裝置所以通常接入到 Bridge上作為區域網的一個節點,tun裝置是一個三層裝置通常用來實現 vpn。
OpenVPN 使用 tun 裝置收發資料
OpenVPN 是使用 tun 裝置的常見例子,它可以方便的在不同網路存取場所之間搭建類似於區域網的專用網路通道。其核心機制就是在 OpenVPN 伺服器和使用者端所在的計算機上都安裝一個 tun 裝置,通過其虛擬 IP 實現相互存取。
例如公網上的兩個主機節點A、B,物理網路卡上設定的IP分別是 ipA_eth0 和 ipB_eth0。然後在A、B兩個節點上分別執行 openvpn 的使用者端和伺服器端,它們會在自己的節點上建立 tun 裝置,且都會讀取或寫入這個 tun 裝置。
假設這兩個裝置對應的虛擬 IP 是 ipA_tun0 和 ipB_tun0,那麼節點 B 上面的應用程式想要通過虛擬 IP 對節點 A 通訊,那麼封包流向就是:
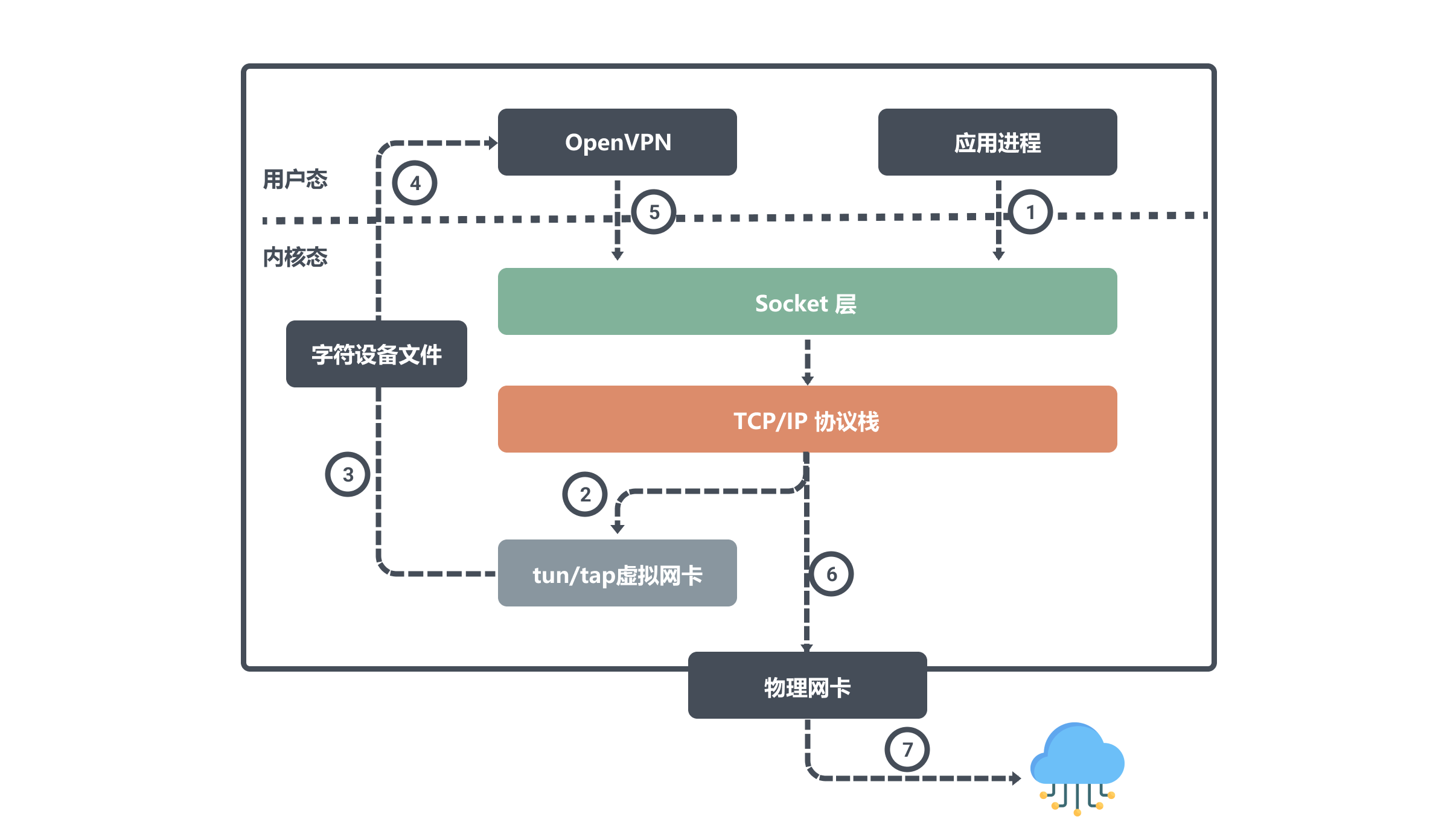
使用者程序對 ipA_tun0 發起請求,經過路由決策後核心將資料從網路協定棧寫入 tun0 裝置;然後 OpenVPN 從字元裝置檔案中讀取 tun0 裝置資料,將資料請求發出去;核心網路協定棧根據路由決策將資料從本機的 eth0 介面流出發往 ipA_eth0 。
同樣我們來看看節點 A 是如何接受資料:
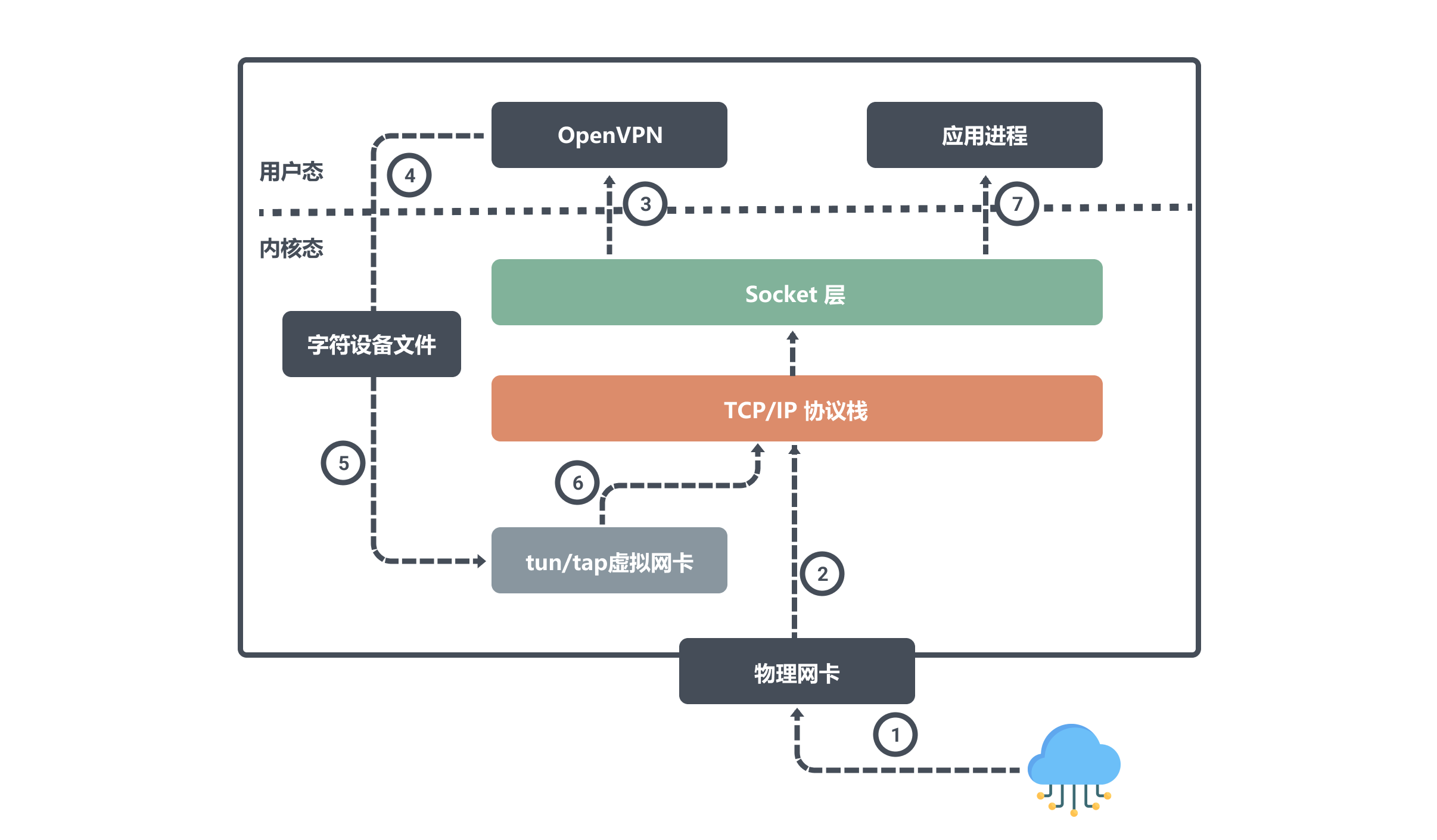
當節點A 通過物理網路卡 eth0 接受到資料後會將寫入核心網路協定棧,因為目標埠號是OpenVPN程式所監聽的,所以網路協定棧會將資料交給 OpenVPN ;
OpenVPN 程式得到資料之後,發現目標IP是tun0裝置的,於是將資料從使用者空間寫入到字元裝置檔案中,然後 tun0 裝置會將資料寫入到協定棧中,網路協定棧最終將資料轉發給應用程序。
從上面我們知道使用 tun/tap 裝置傳輸資料需要經過兩次協定棧,不可避免地會有一定的效能損耗,如果條件允許,容器對容器的直接通訊並不會把 tun/tap 作為首選方案,一般是基於稍後介紹的 veth 來實現的。但是 tun/tap 沒有 veth 那樣要求裝置成對出現、資料要原樣傳輸的限制,封包到使用者態程式後,程式設計師就有完全掌控的權力,要進行哪些修改,要傳送到什麼地方,都可以編寫程式碼去實現,因此 tun/tap 方案比起 veth 方案有更廣泛的適用範圍。
flannel UDP 模式使用 tun 裝置收發資料
早期 flannel 利用 tun 裝置實現了 UDP 模式下的跨主網路相互存取,實際上原理和上面的 OpenVPN 是差不多的。
在 flannel 中 flannel0 是一個三層的 tun 裝置,用作在作業系統核心和使用者應用程式之間傳遞 IP 包。當作業系統將一個 IP 包傳送給 flannel0 裝置之後,flannel0 就會把這個 IP 包,交給建立這個裝置的應用程式,也就是 flanneld 程序,flanneld 程序是一個 UDP 程序,負責處理 flannel0 傳送過來的封包:
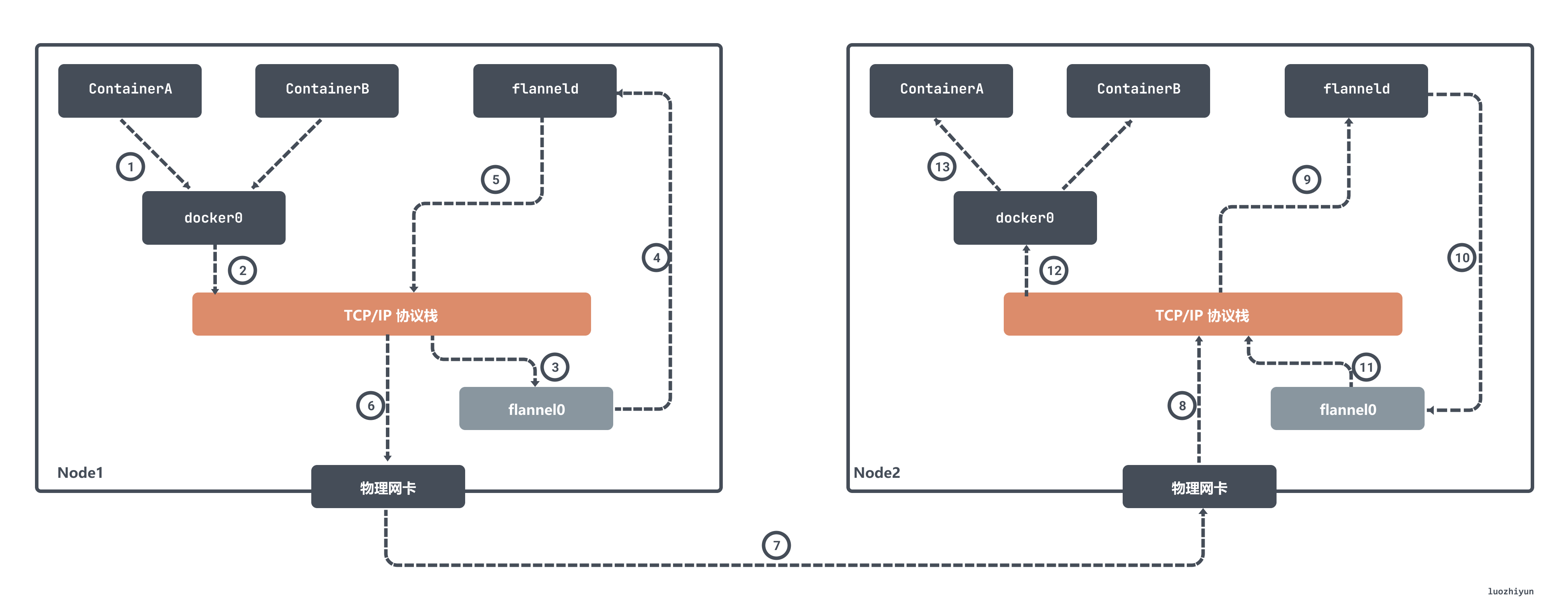
flanneld 程序會根據目的 IP 的地址匹配到對應的子網,從 Etcd 中找到這個子網對應的宿主機 Node2 的 IP 地址,然後將這個封包直接封裝在 UDP 包裡面,然後傳送給 Node 2。由於每臺宿主機上的 flanneld 都監聽著一個 8285 埠,所以 Node2 機器上 flanneld 程序會從 8285 埠獲取到傳過來的資料,解析出封裝在裡面的發給 ContainerA 的 IP 地址。
flanneld 會直接把這個 IP 包傳送給它所管理的 TUN 裝置,即 flannel0 裝置。然後網路棧會將這個封包根據路由傳送到 docker0 網橋,docker0 網橋會扮演二層交換機的角色,將封包傳送給正確的埠,進而通過 veth pair 裝置進入到 containerA 的 Network Namespace 裡。
上面所講的 Flannel UDP 模式現在已經廢棄,原因就是因為它經過三次使用者態與核心態之間的資料拷貝。容器傳送封包經過 docker0 網橋進入核心態一次;封包由 flannel0 裝置進入到 flanneld 程序又一次;第三次是 flanneld 進行 UDP 封包之後重新進入核心態,將 UDP 包通過宿主機的 eth0 發出去。
tap 裝置作為虛擬機器器網路卡
上面我們也說了,tap 裝置是一個二層鏈路層裝置,通常用作實現虛擬網路卡。以 qemu-kvm 為例,它利用 tap 裝置和 Bridge 配合使用擁有極大的靈活性,可以實現各種各樣的網路拓撲。
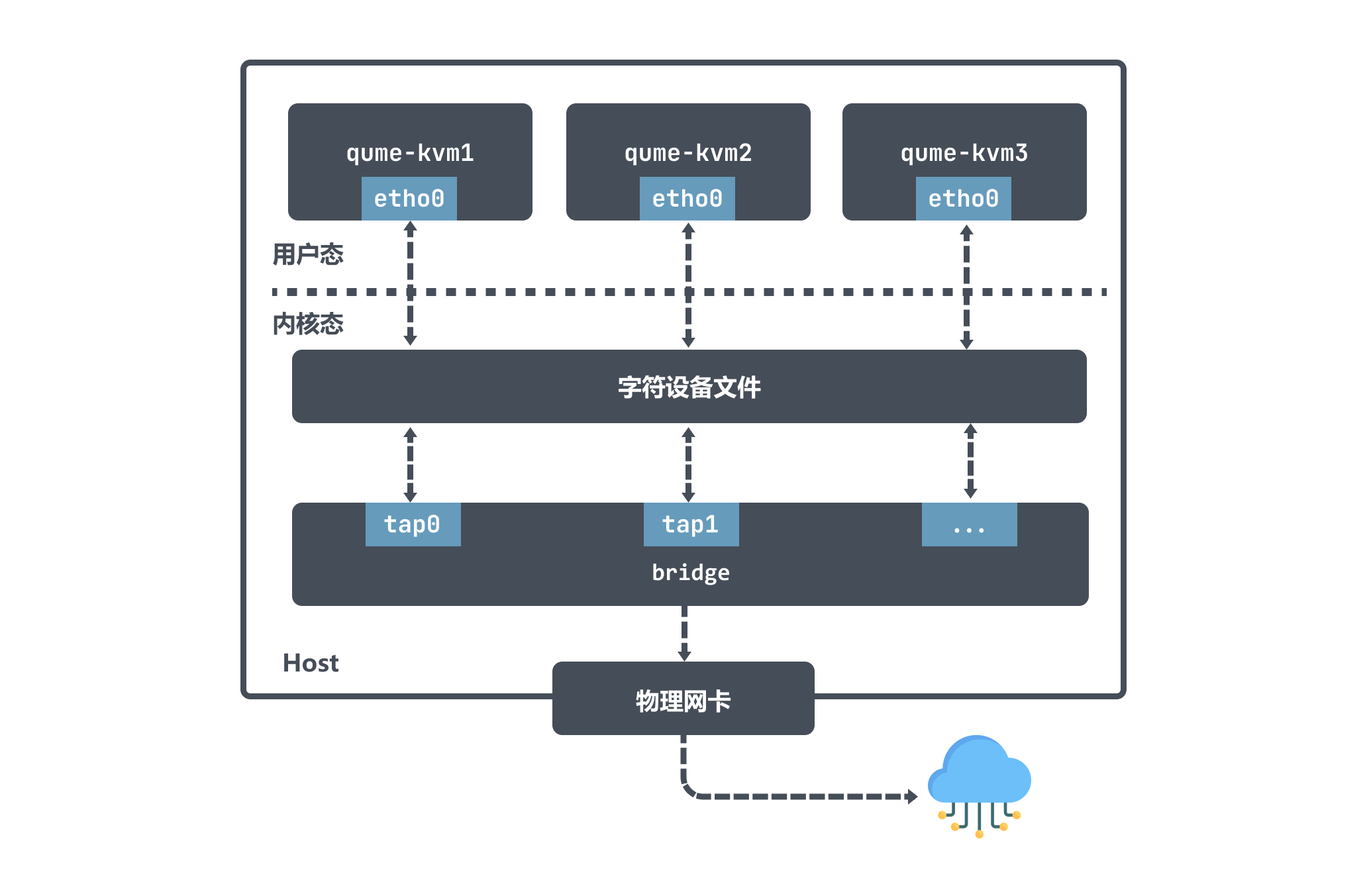
在 qume-kvm 開啟 tap 模式之後,在啟動的時候會向核心註冊了一個tap型別虛擬網路卡 tapx,x 代表依次遞增的數位; 這個虛擬網路卡 tapx 是繫結在 Bridge 上面的,是它上面的一個介面,最終資料會通過 Bridge 來進行轉發。
qume-kvm 會通過其網路卡 eth0 向外傳送資料,從 Host 角度看就是使用者層程式 qume-kvm 程序將字元裝置寫入資料;然後 tapx 裝置會收到資料後由 Bridge 決定封包如何轉發。如果 qume-kvm 要和外界通訊,那麼封包會被傳送到物理網路卡,最終實現與外部通訊。
從上面的圖也可以看出 qume-kvm 發出的封包通過 tap 裝置先到達 Bridge ,然後到物理網路中,封包不需要經過主機的的協定棧,這樣效率也比較高。
veth-pair
veth-pair 就是一對的虛擬裝置介面,它是成對出現的,一端連著協定棧,一端彼此相連著,在 veth 裝置的其中一端輸入資料,這些資料就會從裝置的另外一端原樣不變地流出:
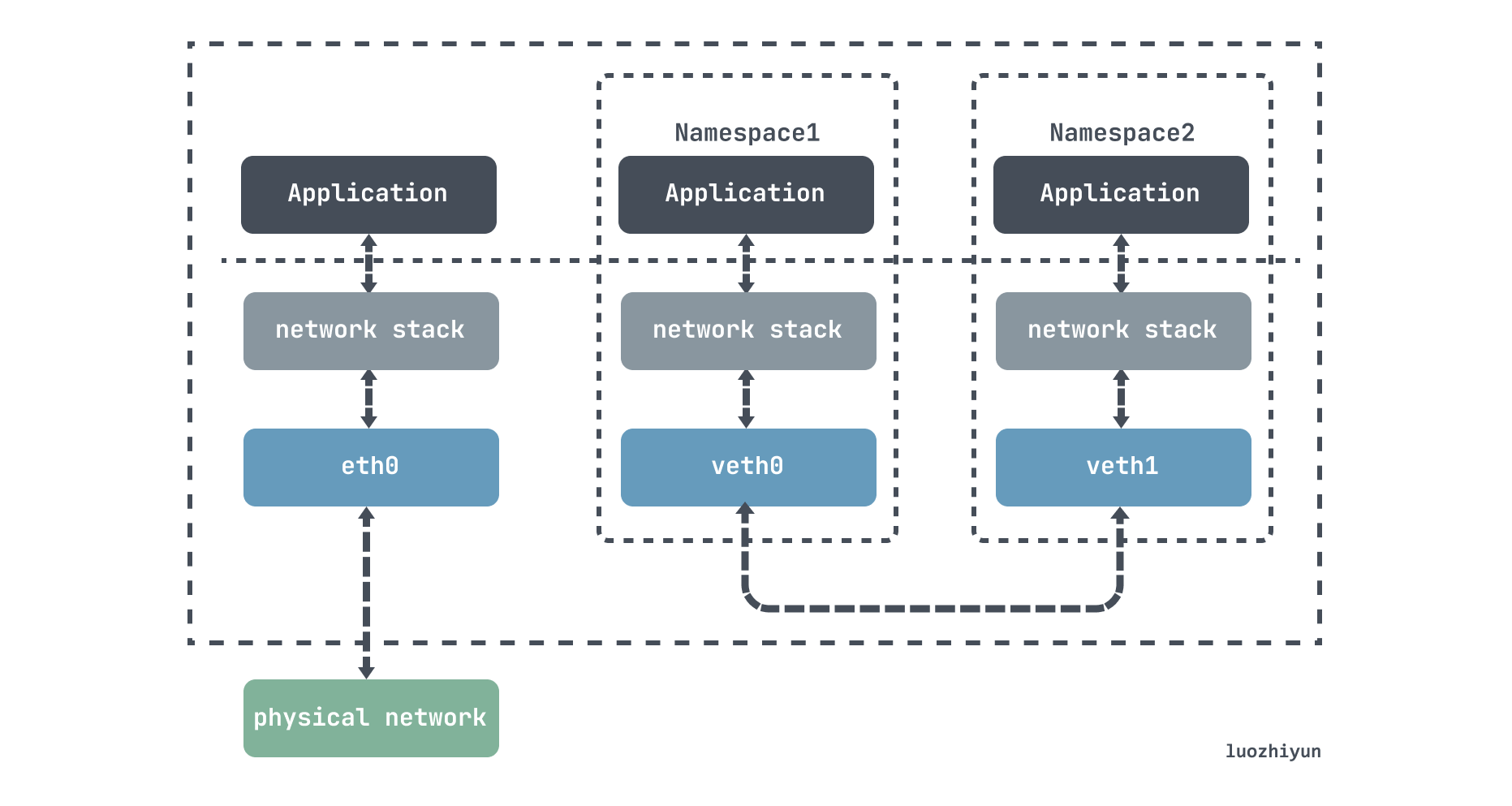
利用它可以連線各種虛擬裝置,兩個 namespace 裝置之間的連線就可以通過 veth-pair 來傳輸資料。
下面我們做一下實驗,構造一個 ns1 和 ns2 利用 veth 通訊的過程,看看veth是如何收發請求包的。
# 建立兩個namespace
ip netns add ns1
ip netns add ns2
# 通過ip link命令新增vethDemo0和vethDemo1
ip link add vethDemo0 type veth peer name vethDemo1
# 將 vethDemo0 vethDemo1 分別加入兩個 ns
ip link set vethDemo0 netns ns1
ip link set vethDemo1 netns ns2
# 給兩個 vethDemo0 vethDemo1 配上 IP 並啟用
ip netns exec ns1 ip addr add 10.1.1.2/24 dev vethDemo0
ip netns exec ns1 ip link set vethDemo0 up
ip netns exec ns2 ip addr add 10.1.1.3/24 dev vethDemo1
ip netns exec ns2 ip link set vethDemo1 up
然後我們可以看到 namespace 裡面設定好了各自的虛擬網路卡以及對應的ip:
~ # ip netns exec ns1 ip addr
root@VM_243_186_centos
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
7: vethDemo0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether d2:3f:ea:b1:be:57 brd ff:ff:ff:ff:ff:ff
inet 10.1.1.2/24 scope global vethDemo0
valid_lft forever preferred_lft forever
inet6 fe80::d03f:eaff:feb1:be57/64 scope link
valid_lft forever preferred_lft forever
然後我們 ping vethDemo1 裝置的 ip:
ip netns exec ns1 ping 10.1.1.3
對兩個網路卡進行抓包:
~ # ip netns exec ns1 tcpdump -n -i vethDemo0 root@VM_243_186_centos
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on vethDemo0, link-type EN10MB (Ethernet), capture size 262144 bytes
20:19:14.339853 ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
20:19:14.339877 ARP, Reply 10.1.1.3 is-at 0e:2f:e6:ce:4b:36, length 28
20:19:14.339880 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 27402, seq 1, length 64
20:19:14.339894 IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 27402, seq 1, length 64
~ # ip netns exec ns2 tcpdump -n -i vethDemo1 root@VM_243_186_centos
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on vethDemo1, link-type EN10MB (Ethernet), capture size 262144 bytes
20:19:14.339862 ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
20:19:14.339877 ARP, Reply 10.1.1.3 is-at 0e:2f:e6:ce:4b:36, length 28
20:19:14.339881 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 27402, seq 1, length 64
20:19:14.339893 IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 27402, seq 1, length 64
通過上面的抓包,並結合ping相關概念,我們大致可以瞭解到:
- ping程序構造ICMP echo請求包,並通過socket發給協定棧;
- 協定棧根據目的IP地址和系統路由表,知道去 10.1.1.3 的封包應該要由 10.1.1.2 口出去;
- 由於是第一次存取 10.1.1.3,剛開始沒有它的 mac 地址,所以協定棧會先傳送 ARP 出去,詢問 10.1.1.3 的 mac 地址;
- 協定棧將 ARP 包交給 vethDemo0,讓它發出去;
- 由於 vethDemo0 的另一端連的是 vethDemo1,所以ARP請求包就轉發給了 vethDemo1;
- vethDemo1 收到 ARP 包後,轉交給另一端的協定棧,做出 ARP 應答,迴應告訴 mac 地址 ;
- 當拿到10.1.1.3 的 mac 地址之後,再發出 ping 請求會構造一個ICMP request 傳送給目的地,然後ping命令回顯成功;
總結
本篇文章只是講了兩種常見的虛擬網路裝置。起因是在看 flannel 的時候,書裡面都會講到 flannel0 是一個 tun 裝置,但是什麼是 tun 裝置卻不明白,所以導致 flannel 也看的不明白。
經過研究,發現 tun/tap 裝置是一個虛擬網路裝置,負責資料轉發,但是它需要通過檔案作為傳輸通道,這樣不可避免的引申出 tun/tap 裝置為什麼要轉發兩次,這也是為什麼 flannel 裝置 UDP 模式下效能不好的原因,導致了後面這種模式被廢棄掉。
因為 tun/tap 裝置作為虛擬網路裝置效能不好,容器對容器的直接通訊並不會把 tun/tap 作為首選方案,一般是基於稍後介紹的 veth 來實現的。veth 作為一個二層裝置,可以讓兩個隔離的網路名稱空間之間可以互相通訊,不需要反覆多次經過網路協定棧, veth pair 是一端連著協定棧,另一端彼此相連的,資料之間的傳輸變得十分簡單,這也讓 veth 比起 tap/tun 具有更好的效能。
Reference
https://zhuanlan.zhihu.com/p/293659939
https://segmentfault.com/a/1190000009249039
https://segmentfault.com/a/1190000009251098
https://www.junmajinlong.com/virtual/network/all_about_tun_tap/
https://www.junmajinlong.com/virtual/network/data_flow_about_openvpn/
https://www.zhaohuabing.com/post/2020-02-24-linux-taptun/
https://zhuanlan.zhihu.com/p/462501573
http://icyfenix.cn/immutable-infrastructure/network/linux-vnet.html
https://opengers.github.io/openstack/openstack-base-virtual-network-devices-tuntap-veth/
https://tomwei7.com/2021/10/09/qemu-network-config/
https://time.geekbang.org/column/article/65287
https://blog.csdn.net/qq_41586875/article/details/119943074
https://man7.org/linux/man-pages/man4/veth.4.html
