3000幀動畫圖解MySQL為什麼需要binlog、redo log和undo log
全文建立在MySQL的儲存引擎為InnoDB的基礎上
先看一條SQL如何入庫的:

這是一條很簡單的更新SQL,從MySQL伺服器端接收到SQL到落盤,先後經過了MySQL Server層和InnoDB儲存引擎。
- Server層就像一個產品經理,分析客戶的需求,並給出實現需求的方案。
- InnoDB就像一個基層程式設計師,實現產品經理給出的具體方案。
在MySQL」分析需求,實現方案「的過程中,還夾雜著記憶體操作和磁碟操作,以及記錄各種紀錄檔。
他們到底有什麼用處?他們之間到底怎麼配合的?MySQL又為什麼要分層呢?InnoDB裡面的那一塊Buffer Pool又是什麼?
我們慢慢分析。
分層結構
MySQL為什麼要分為Server層和儲存引擎兩層呢?
這個問題官方也沒有給出明確的答案,但是也不難猜,簡單來說就是為了「解耦」。
Server層和儲存引擎各司其職,分工明確,使用者可以根據不同的需求去使用合適的儲存引擎,多好的設計,對不對?
後來的發展也驗證了「分層設計」的優越性:MySQL最初搭載的儲存引擎是自研的只支援簡單查詢的MyISAM的前身ISAM,後來與Sleepycat合作研發了Berkeley DB引擎,支援了事務。江山代有才人出,技術後浪推前浪,MySQL在持續的升級著自己的儲存引擎的過程中,遇到了橫空出世的InnoDB,InnoDB的功能強大讓MySQL倍感壓力。
自己的儲存引擎打不過InnoDB怎麼辦?
打不過就加入!

MySQL選擇了和InnoDB合作。正是因為MySQL儲存引擎的外掛化設計,兩個公司合作的非常順利,MySQL也在合作後不久就釋出了正式支援nnoDB的4.0版本以及經典的4.1版本。
MySQL兼併天下模式也成為MySQL走向繁榮的一個重要因素。這能讓MySQL長久地保持著極強競爭力。時至今日,MySQL依然佔據著極高資料庫市場份額,僅次於王牌資料庫Oracle。

Buffer Pool
在InnoDB裡,有一塊非常重要的結構——Buffer Pool。

Buffer Pool是個什麼東西呢?
Buffer Pool就是一塊用於快取MySQL磁碟資料的記憶體空間。
為什麼要快取MySQL磁碟資料呢?
我們通過一個例子說明,我們先假設沒有Buffer Pool,user表裡面只有一條記錄,記錄的age = 1,假設需要執行三條SQL:
- 事務A:update user set age = 2
- 事務B:update user set age = 3
- 事務C:update user set age = 4
如果沒有Buffer Pool,那執行就是這樣的:

從圖上可以看出,每次更新都需要從磁碟拿資料(1次IO),修改完了需要刷到磁碟(1次IO),也就是每次更新都需要2次磁碟IO。三次更新需要6次磁碟IO。
而有了Buffer Pool,執行就成了這樣:

從圖上可以看出,只需要在第一次執行的時候將資料從磁碟拿到Buffer Pool(1次IO),第三次執行完將資料刷回磁碟(1次IO),整個過程只需要2次磁碟IO,比沒有Buffer Pool節省了4次磁碟IO的時間。
當然,Buffer Pool真正的運轉流程沒有這麼簡單,具體實現細節和優化技巧還有很多,由於篇幅有限,本文不做詳細描述。
我想表達的是:Buffer Pool就是將磁碟IO轉換成了記憶體操作,節省了時間,提高了效率。
Buffer Pool是提高了效率沒錯,但是出現了一個問題,Buffer Pool是基於記憶體的,而只要一斷電,記憶體裡面的資料就會全部丟失。
如果斷電的時候Buffer Pool的資料還沒來得及刷到磁碟,那麼這些資料就丟失了嗎?
還是上面的那個例子,如果三個事務執行完畢,在age = 4還沒有刷到磁碟的時候,突然斷電,資料就全部丟掉了:

試想一下,如果這些丟失的資料是核心的使用者交易資料,那使用者能接受嗎?
答案是否定的。
那InnoDB是如何做到資料不會丟失的呢?
今天的第一個紀錄檔——redo log登場了。
恢復 - redo log
顧名思義,redo是重做的意思,redo log就是重做紀錄檔的意思。
redo log是如何保證資料不會丟失的呢?
就是在修改之後,先將修改後的值記錄到磁碟上的redo log中,就算突然斷電了,Buffer Pool中的資料全部丟失了,來電的時候也可以根據redo log恢復Buffer Pool,這樣既利用到了Buffer Pool的記憶體高效性,也保證了資料不會丟失。
我們通過一個例子說明,我們先假設沒有Buffer Pool,user表裡面只有一條記錄,記錄的age = 1,假設需要執行一條SQL:
- 事務A:update user set age = 2
執行過程如下:

如上圖,有了redo log之後,將age修改成2之後,馬上將age = 2寫到redo log裡面,如果這個時候突然斷電記憶體資料丟失,在來電的時候,可以將redo log裡面的資料讀出來恢復資料,用這樣的方式保證了資料不會丟失。
你可能會問,redo log檔案也在磁碟上,資料檔案也在磁碟上,都是磁碟操作,何必多此一舉?為什麼不直接將修改的資料寫到資料檔案裡面去呢?

傻瓜,因為redo log是磁碟順序寫,資料刷盤是磁碟隨機寫,磁碟的順序寫比隨機寫高效的多啊。
這種先預寫紀錄檔後面再將資料刷盤的機制,有一個高大上的專業名詞——WAL(Write-ahead logging),翻譯成中文就是預寫式紀錄檔。
雖然磁碟順序寫已經很高效了,但是和記憶體操作還是有一定的差距。
那麼,有沒有辦法進一步優化一下呢?
答案是可以。那就是給redo log也加一個記憶體buffer,也就是redo log buffer,用這種套娃式的方法進一步提高效率。

redo log buffer具體是怎麼配合刷盤呢?
在這個問題之前之前,我們先來捋一下MySQL伺服器端和作業系統的關係:
MySQL伺服器端是一個程序,它執行於作業系統之上。也就是說,作業系統掛了MySQL一定掛了,但是MySQL掛了作業系統不一定掛。
所以MySQL掛了有兩種情況:
- MySQL掛了,作業系統也掛了,也就是常說的伺服器宕機了。這種情況Buffer Pool裡面的資料會全部丟失,作業系統的os cache裡面的資料也會丟失。
- MySQL掛了,作業系統沒有掛。這種情況Buffer Pool裡面的資料會全部丟失,作業系統的os cache裡面的資料不會丟失。
OK,瞭解了MySQL伺服器端和作業系統的關係之後,再來看redo log的落盤機制。redo log的刷盤機制由引數innodb_flush_log_at_trx_commit控制,這個引數有3個值可以設定:
- innodb_flush_log_at_trx_commit = 1:實時寫,實時刷
- innodb_flush_log_at_trx_commit = 0:延遲寫,延遲刷
- innodb_flush_log_at_trx_commit = 2:實時寫,延遲刷
寫可以理解成寫到作業系統的快取(os cache),刷可以理解成把作業系統裡面的快取刷到磁碟。
這三種策略的區別,我們分開討論:
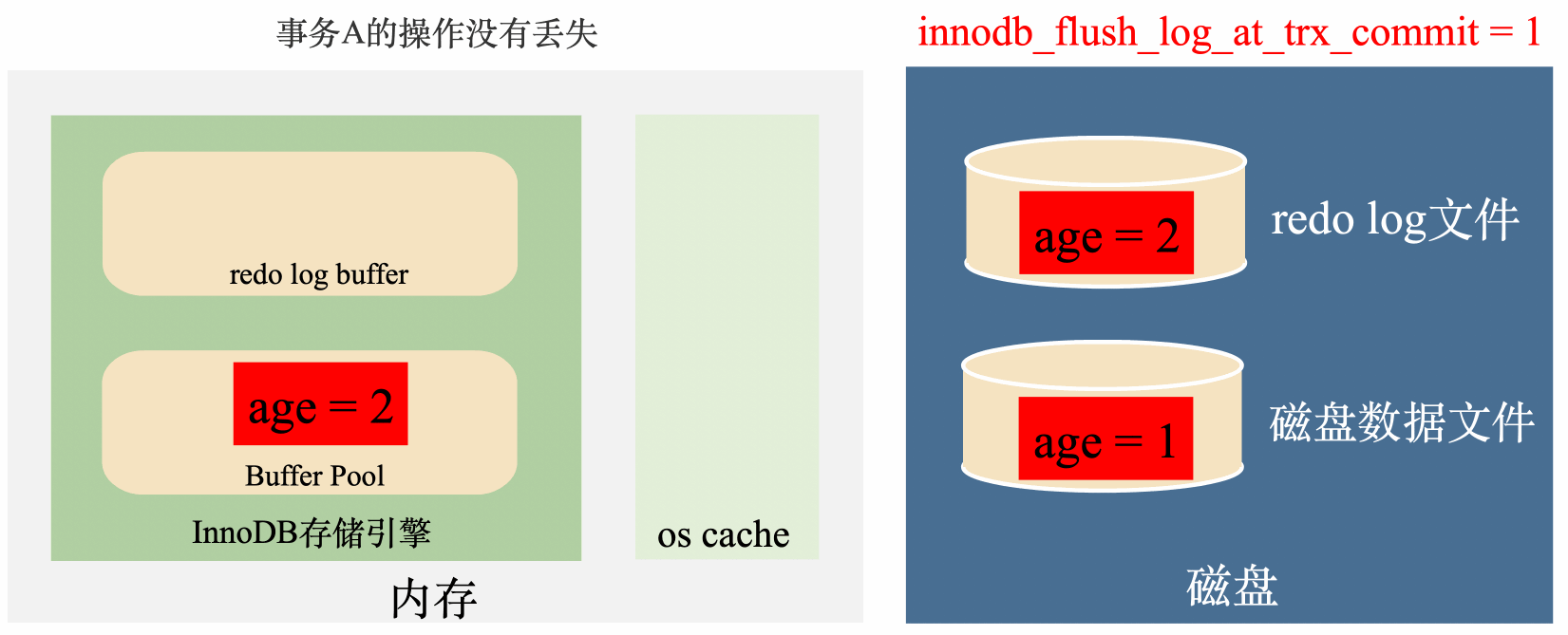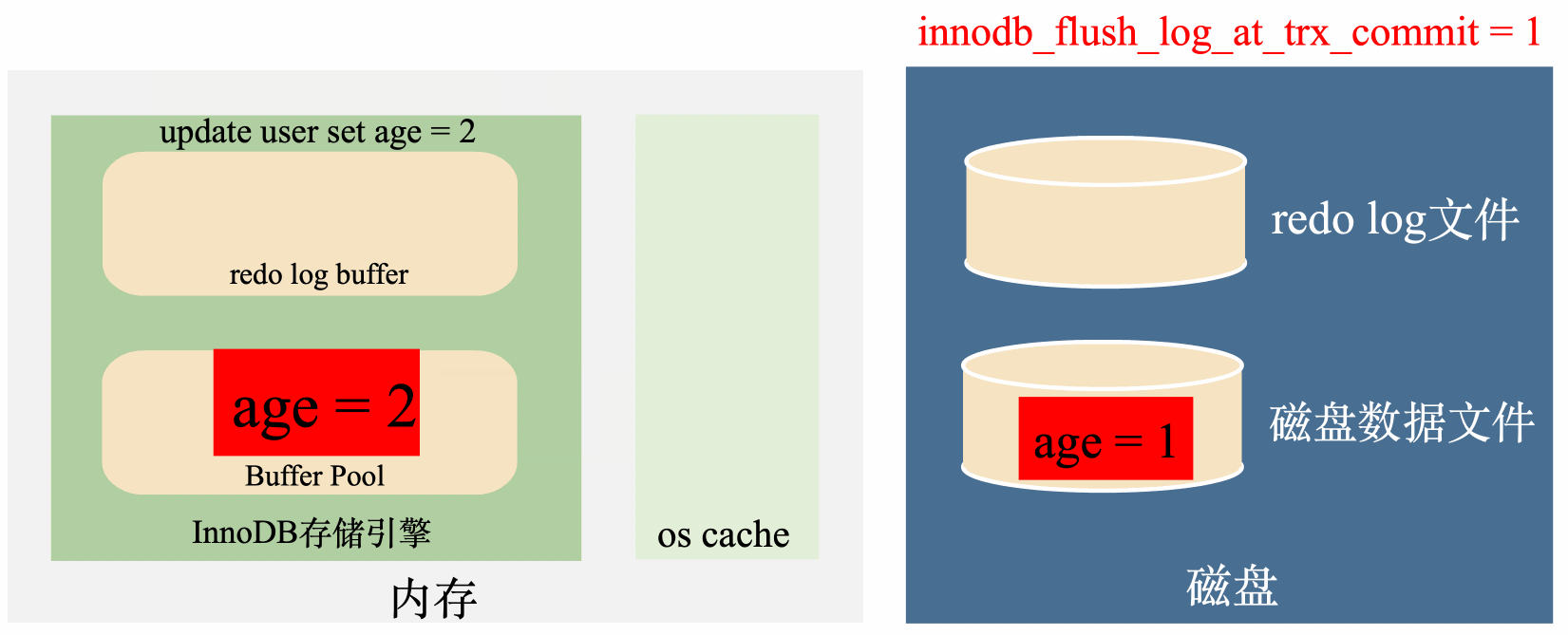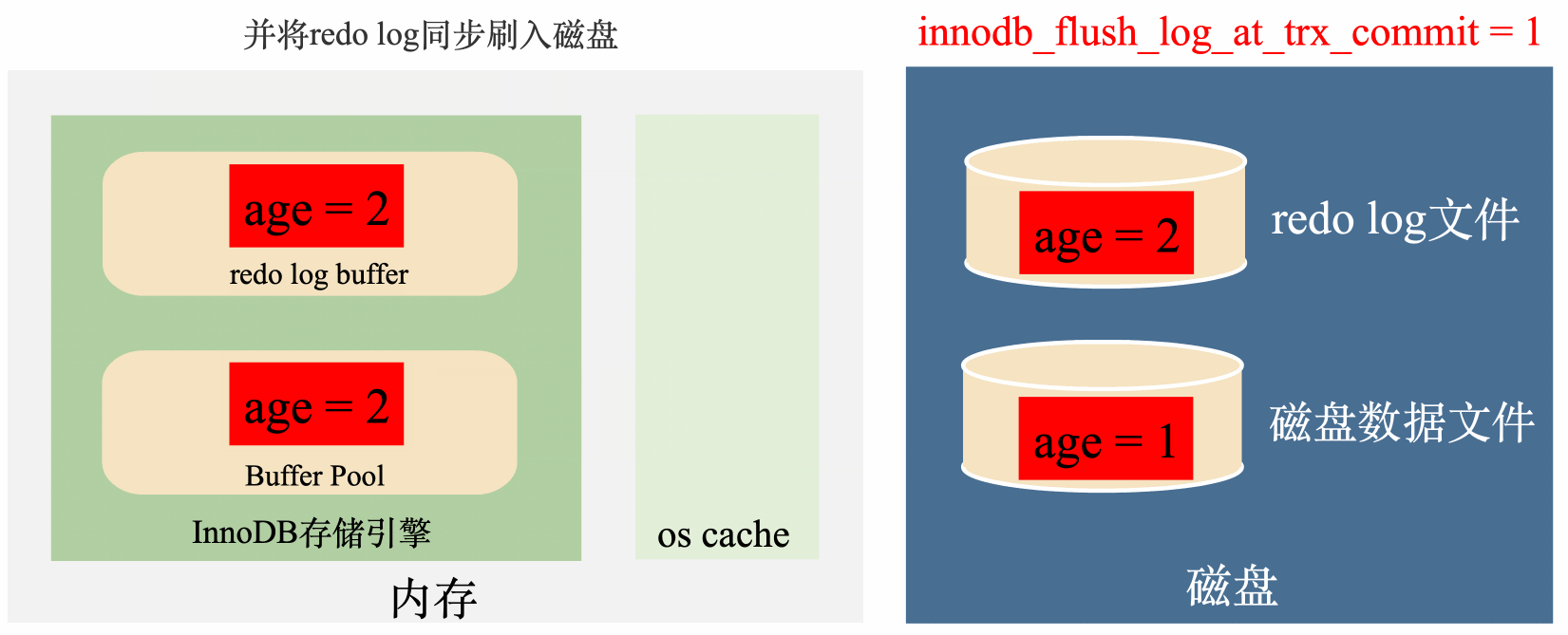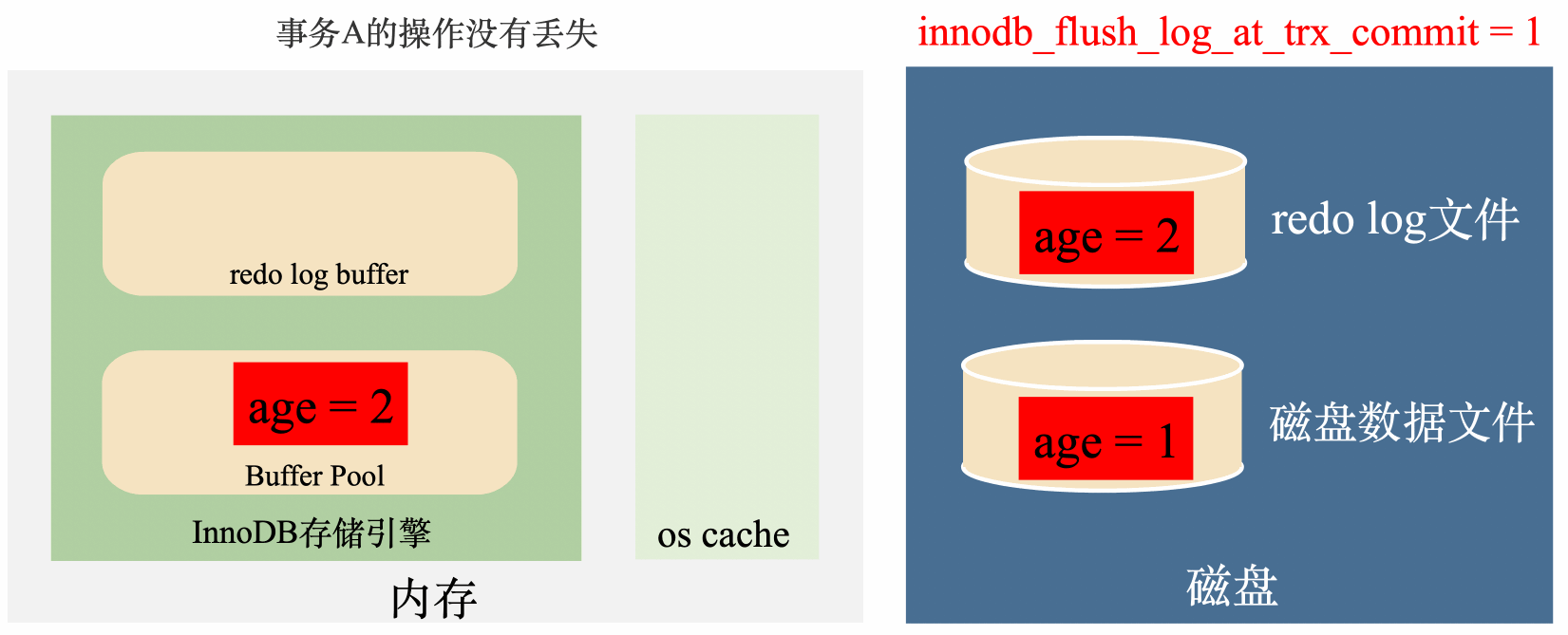
innodb_flush_log_at_trx_commit = 1:實時寫,實時刷
這種策略會在每次事務提交之前,每次都會將資料從redo log刷到磁碟中去,理論上只要磁碟不出問題,資料就不會丟失。
總結來說,這種策略效率最低,但是丟資料風險也最低。
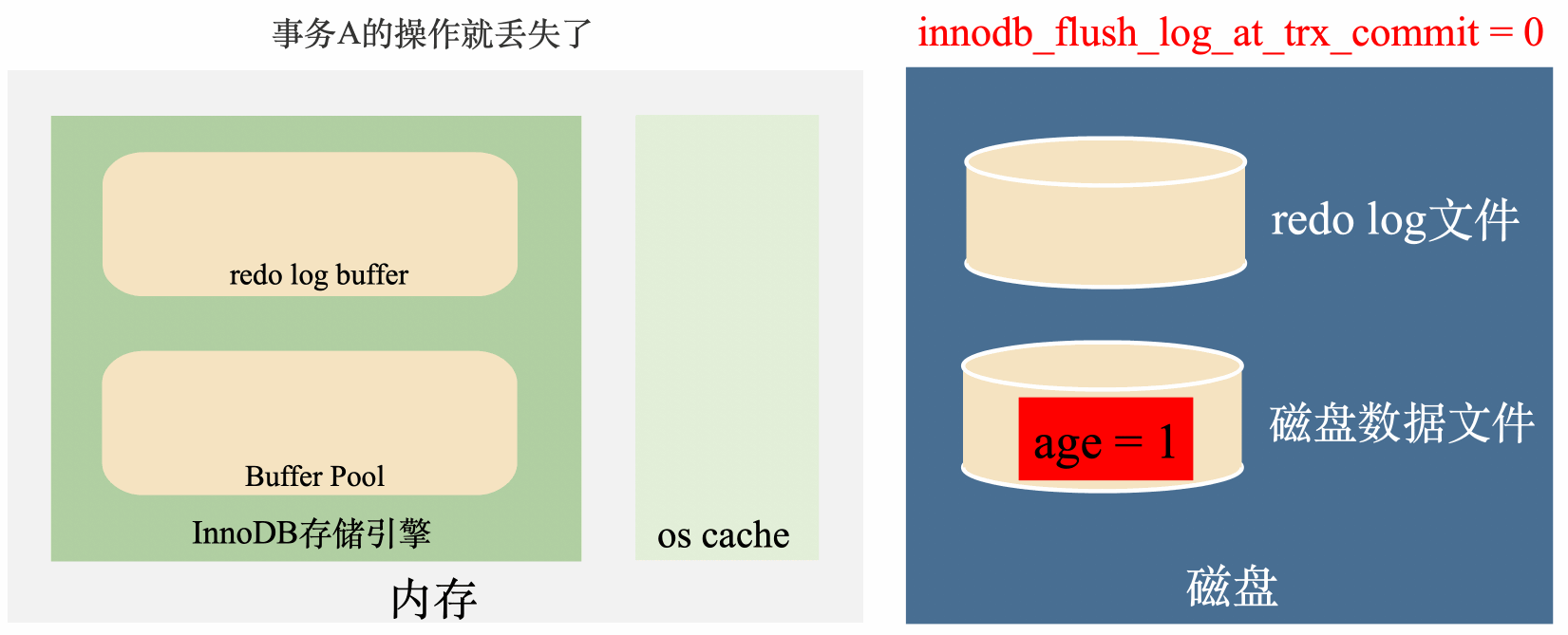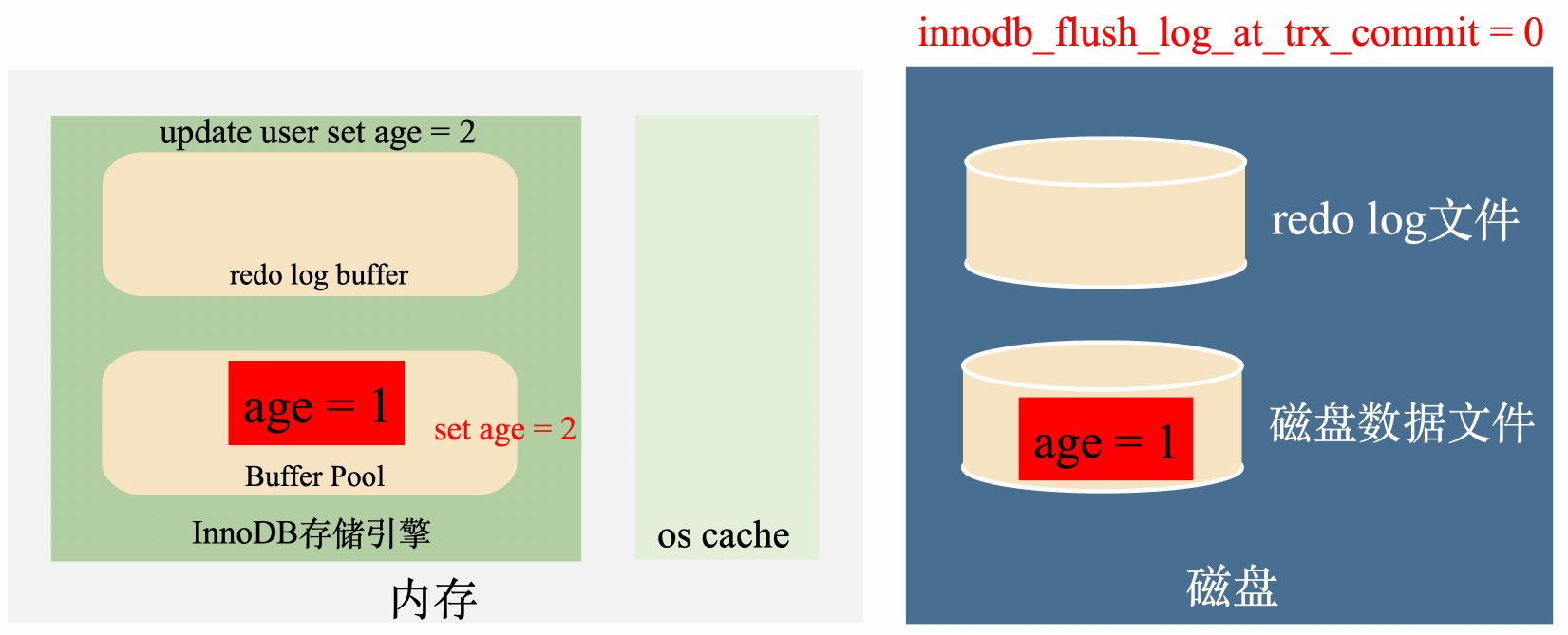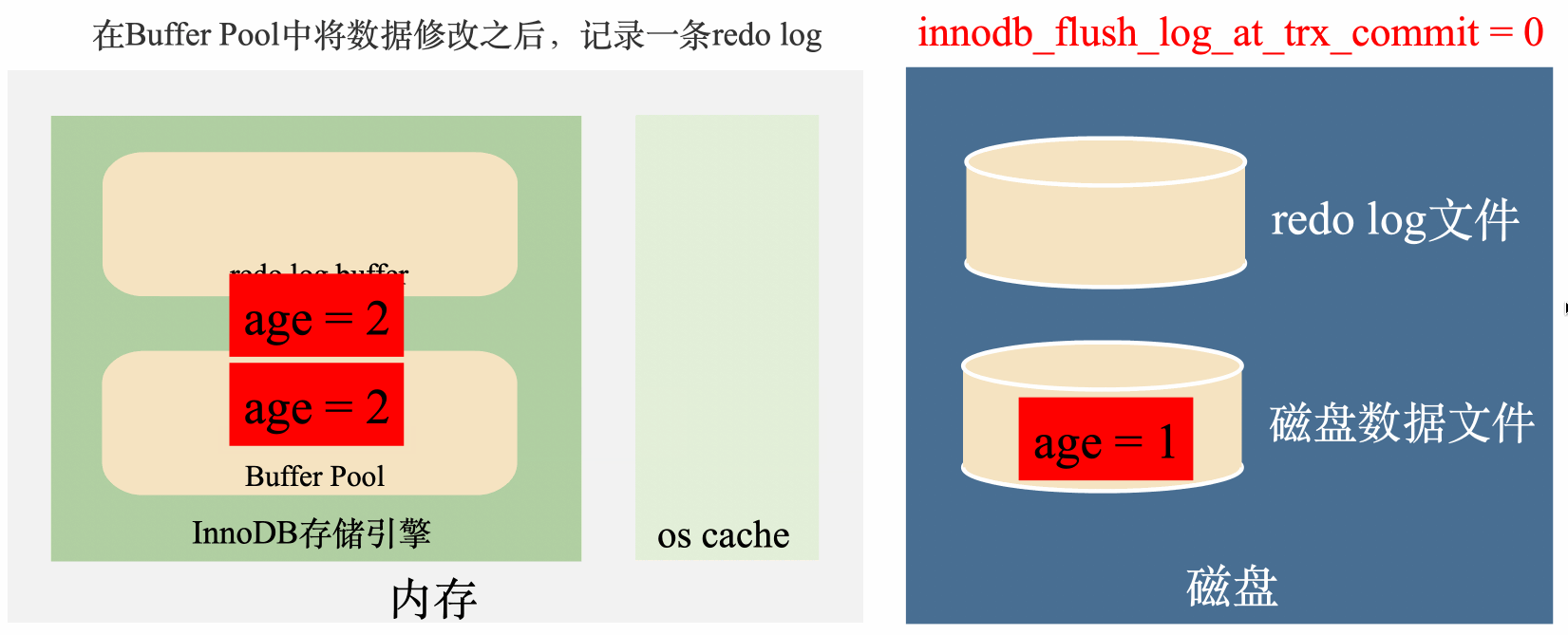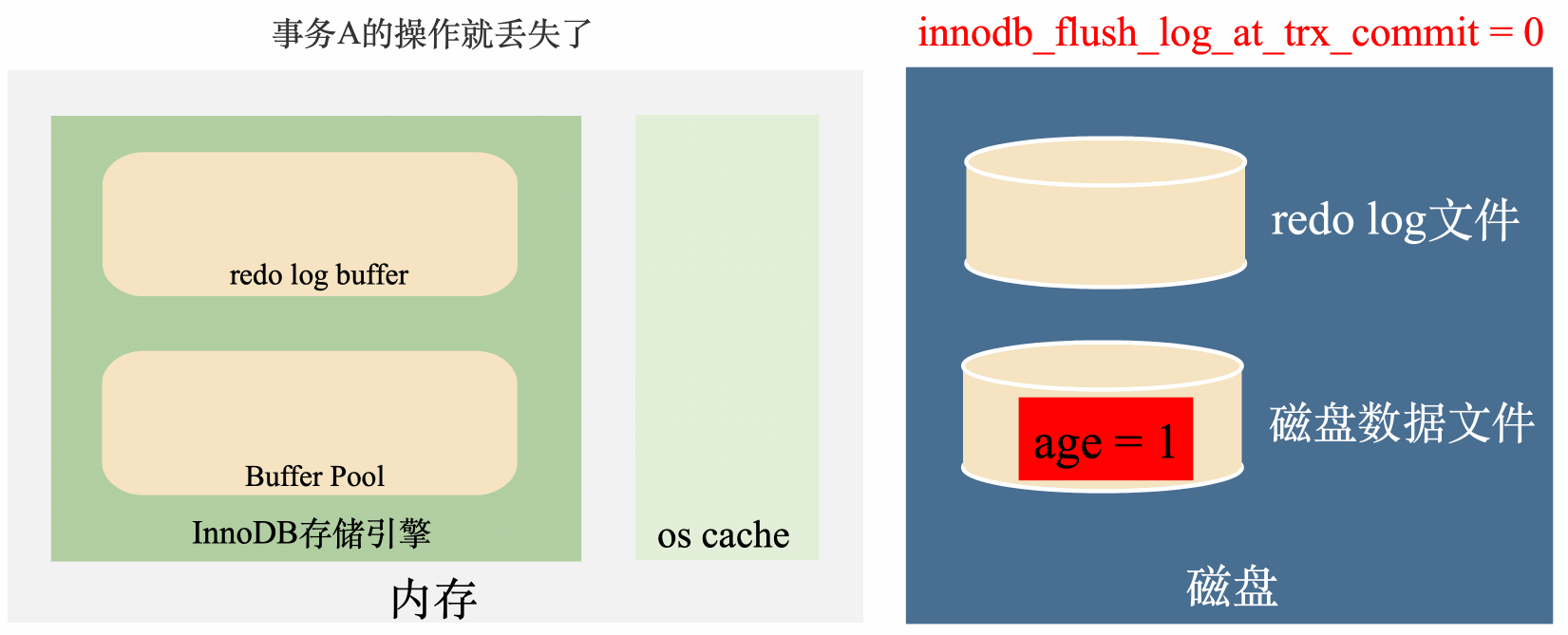
innodb_flush_log_at_trx_commit = 0:延遲寫,延遲刷
這種策略在事務提交時,只會把資料寫到redo log buffer中,然後讓後臺執行緒定時去將redo log buffer裡面的資料刷到磁碟。
這種策略是最高效的,但是我們都知道,定時任務是有間隙的,但是如果事務提交後,後臺執行緒沒來得及將redo log刷到磁碟,這個時候不管是MySQL程序掛了還是作業系統掛了,這一部分資料都會丟失。
總結來說這種策略效率最高,丟資料的風險也最高。
innodb_flush_log_at_trx_commit = 2:實時寫,延遲刷
這種策略在事務提交之前會把redo log寫到os cache中,但並不會實時地將redo log刷到磁碟,而是會每秒執行一次重新整理磁碟操作。
這種情況下如果MySQL程序掛了,作業系統沒掛的話,作業系統還是會將os cache刷到磁碟,資料不會丟失,如下圖:

但如果MySQL所在的伺服器掛掉了,也就是作業系統都掛了,那麼os cache也會被清空,資料還是會丟失。如下圖:

所以,這種redo log刷盤策略是上面兩種策略的折中策略,效率比較高,丟失資料的風險比較低,絕大多情況下都推薦這種策略。
總結一下,redo log的作用是用於恢復資料,寫redo log的過程是磁碟順序寫,有三種刷盤策略,有innodb_flush_log_at_trx_commit 引數控制,推薦設定成2。
回滾 - undo log
我們都知道,InnoDB是支援事務的,而事務是可以回滾的。
假如一個事務將age=1修改成了age=2,在事務還沒有提交的時候,後臺執行緒已經將age=2刷入了磁碟。這個時候,不管是記憶體還是磁碟上,age都變成了2,如果事務要回滾,找不到修改之前的age=1,無法回滾了。

那怎麼辦呢?
很簡單,把修改之前的age=1存起來,回滾的時候根據存起來的age=1回滾就行了。
MySQL確實是這麼幹的!這個記錄修改之前的資料的過程,叫做記錄undo log。undo翻譯成中文是復原、回滾的意思,undo log的主要作用也就是回滾資料。
如何回滾呢?看下面這個圖:
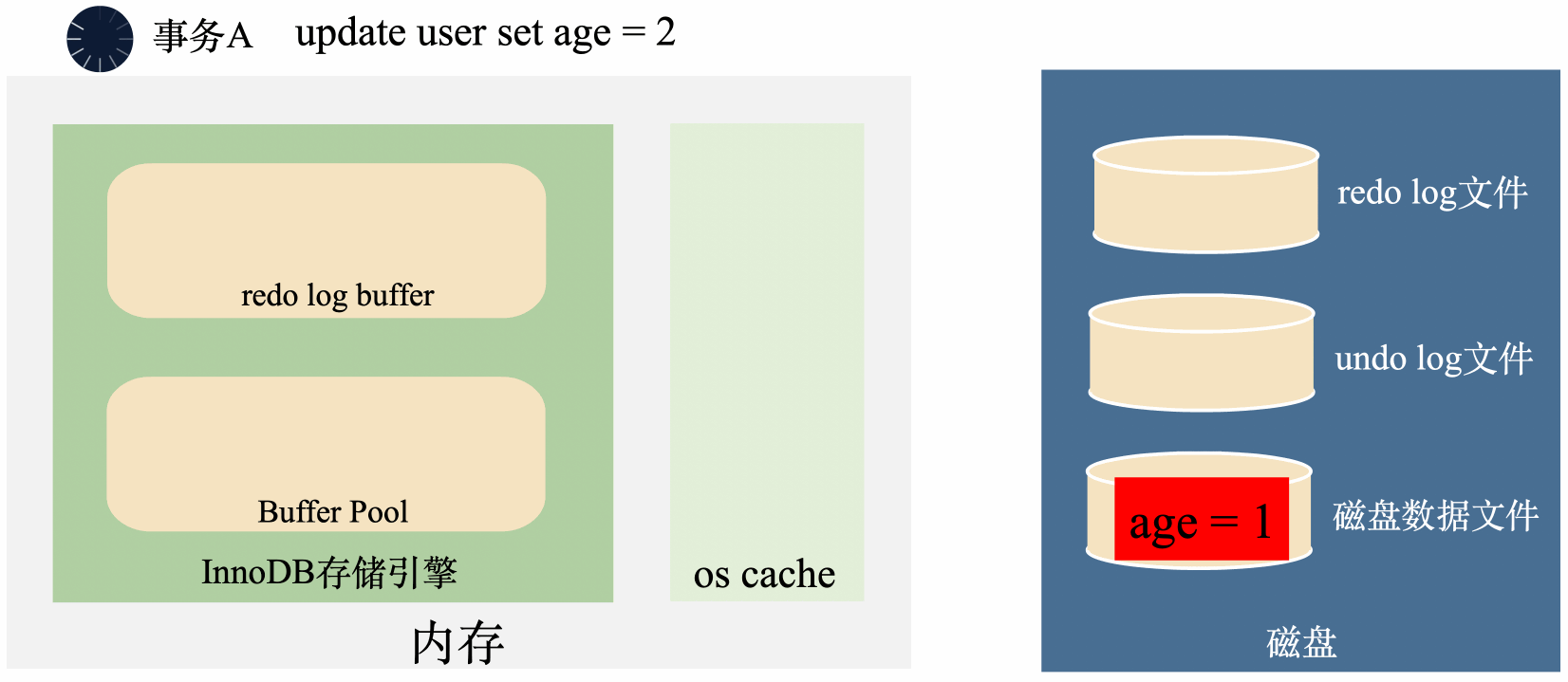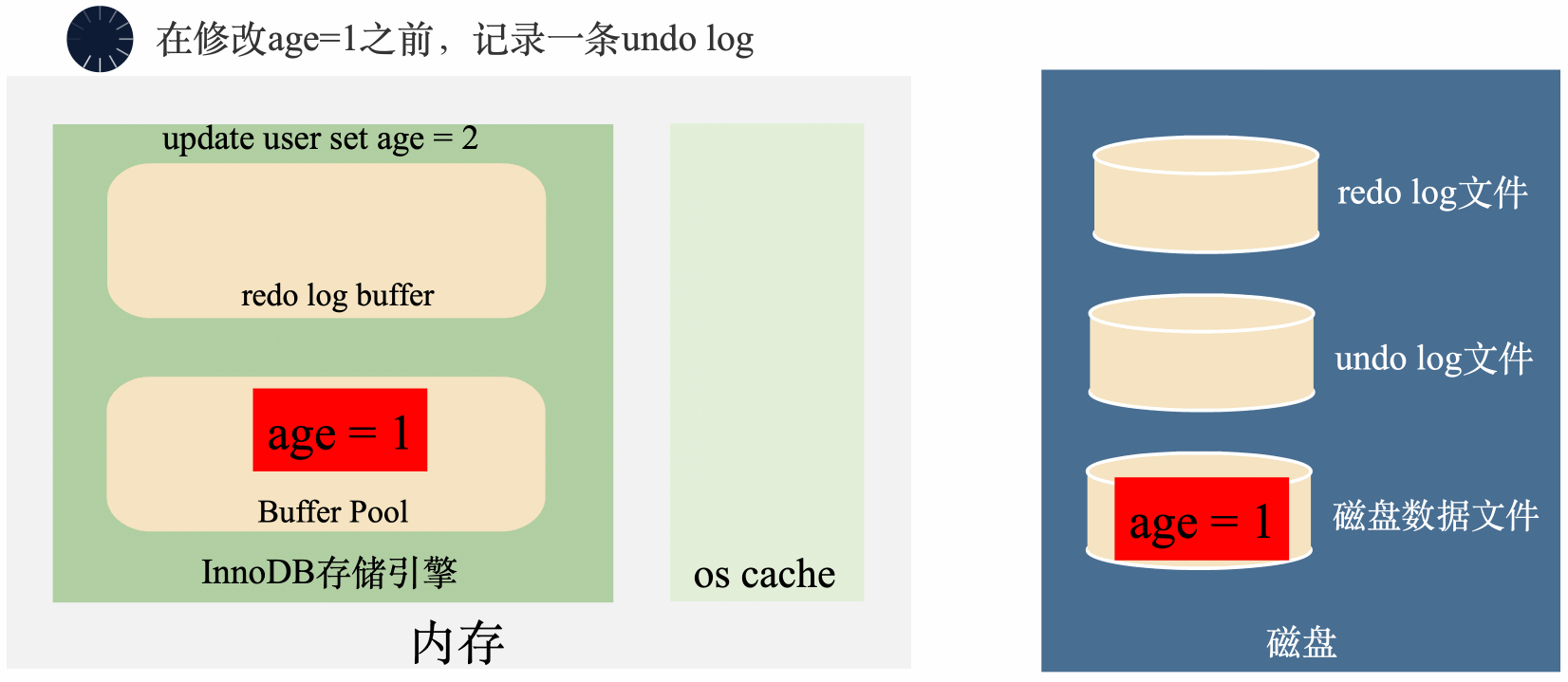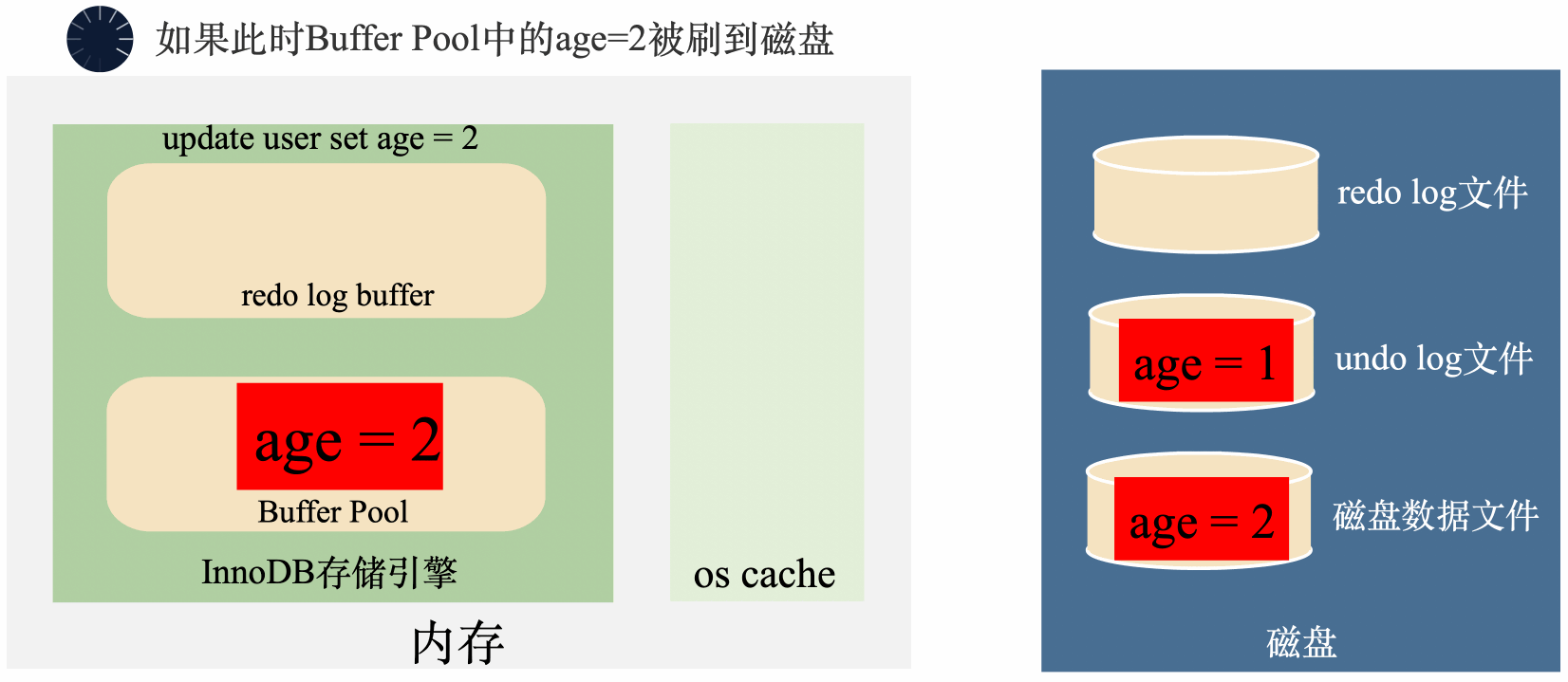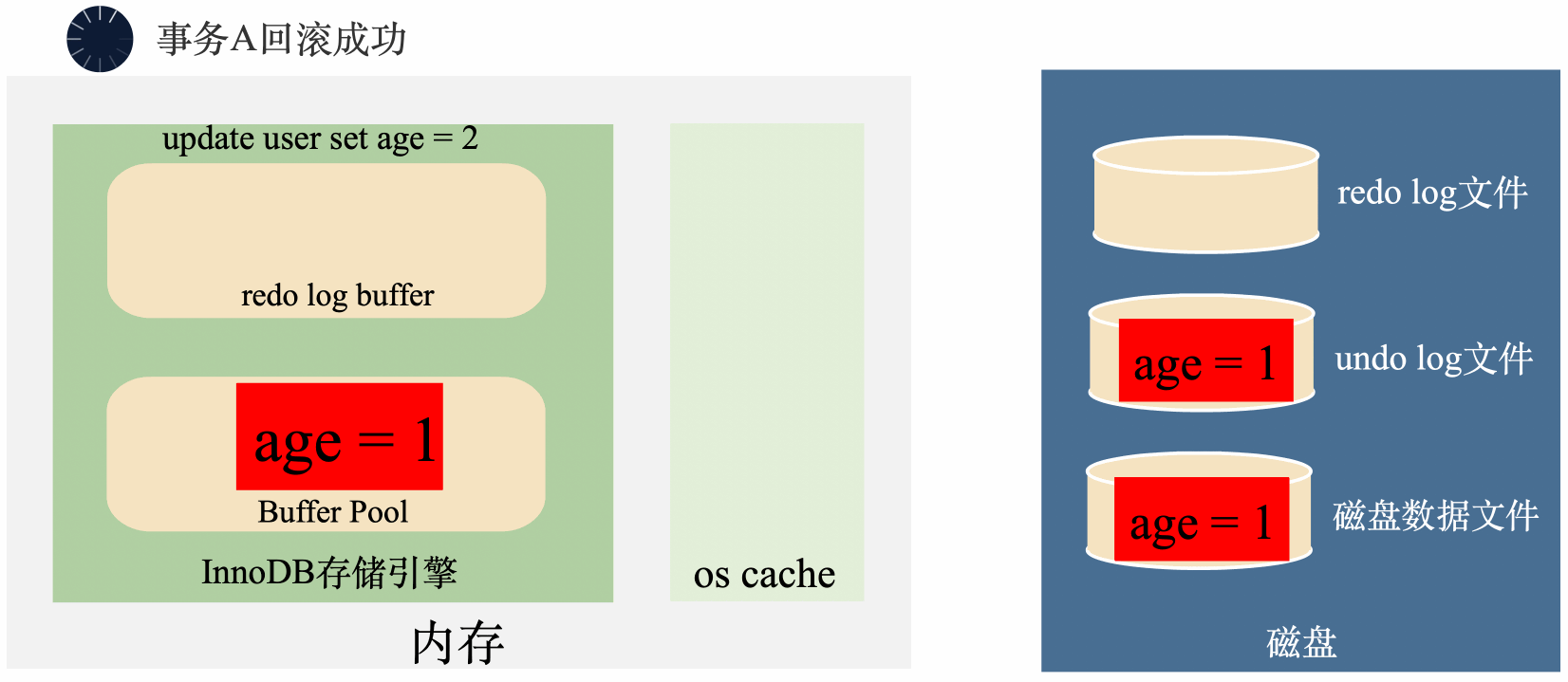
MySQL在將age = 1修改成age = 2之前,先將age = 1存到undo log裡面去,這樣需要回滾的時候,可以將undo log裡面的age = 1讀出來回滾。
需要注意的是,undo log預設存在全域性表空間裡面,你可以簡單的理解成undo log也是記錄在一個MySQL的表裡面,插入一條undo log和插入一條普通資料是類似。也就是說,寫undo log的過程中同樣也是要寫入redo log的。
歸檔 - binlog
undo log記錄的是修改之前的資料,提供回滾的能力。
redo log記錄的是修改之後的資料,提供了崩潰恢復的能力。
那binlog是幹什麼的呢?
binlog記錄的是修改之後的資料,用於歸檔。
和redo log紀錄檔類似,binlog也有著自己的刷盤策略,通過sync_binlog引數控制:
- sync_binlog = 0 :每次提交事務前將binlog寫入os cache,由作業系統控制什麼時候刷到磁碟
- sync_binlog =1 :採用同步寫磁碟的方式來寫binlog,不使用os cache來寫binlog
- sync_binlog = N :當每進行n次事務提交之後,呼叫一次fsync將os cache中的binlog強制刷到磁碟
那麼問題來了,binlog和redo log都是記錄的修改之後的值,這兩者有什麼區別呢?有redo log為什麼還需要binlog呢?
首先看兩者的一些區別:
- binlog是邏輯紀錄檔,記錄的是對哪一個表的哪一行做了什麼修改;redo log是物理紀錄檔,記錄的是對哪個資料頁中的哪個記錄做了什麼修改,如果你還不瞭解資料頁,你可以理解成對磁碟上的哪個資料做了修改。
- binlog是追加寫;redo log是迴圈寫,紀錄檔檔案有固定大小,會覆蓋之前的資料。
- binlog是Server層的紀錄檔;redo log是InnoDB的紀錄檔。如果不使用InnoDB引擎,是沒有redo log的。
但說實話,我覺得這些區別並不是redo log不能取代binlog的原因,MySQL官方完全可以調整redo log讓他兼併binlog的能力,但他沒有這麼做,為什麼呢?
我認為不用redo log取代binlog最大的原因是「沒必要」。
為什麼這麼說呢?
第一點,binlog的生態已經建立起來。MySQL高可用主要就是依賴binlog複製,還有很多公司的資料分析系統和資料處理系統,也都是依賴的binlog。取代binlog去改變一個生態費力了不討好。
第二點,binlog並不是MySQL的瓶頸,花時間在沒有瓶頸的地方沒必要。
總結
總結一下:
- Buffer Pool是MySQL程序管理的一塊記憶體空間,有減少磁碟IO次數的作用。
- redo log是InnoDB儲存引擎的一種紀錄檔,主要作用是崩潰恢復,有三種刷盤策略,有innodb_flush_log_at_trx_commit 引數控制,推薦設定成2。
- undo log是InnoDB儲存引擎的一種紀錄檔,主要作用是回滾。
- binlog是MySQL Server層的一種紀錄檔,主要作用是歸檔。
- MySQL掛了有兩種情況:作業系統掛了MySQL程序跟著掛了;作業系統沒掛,但是MySQL程序掛了。
最後,再用一張圖總結一下全文的知識點:
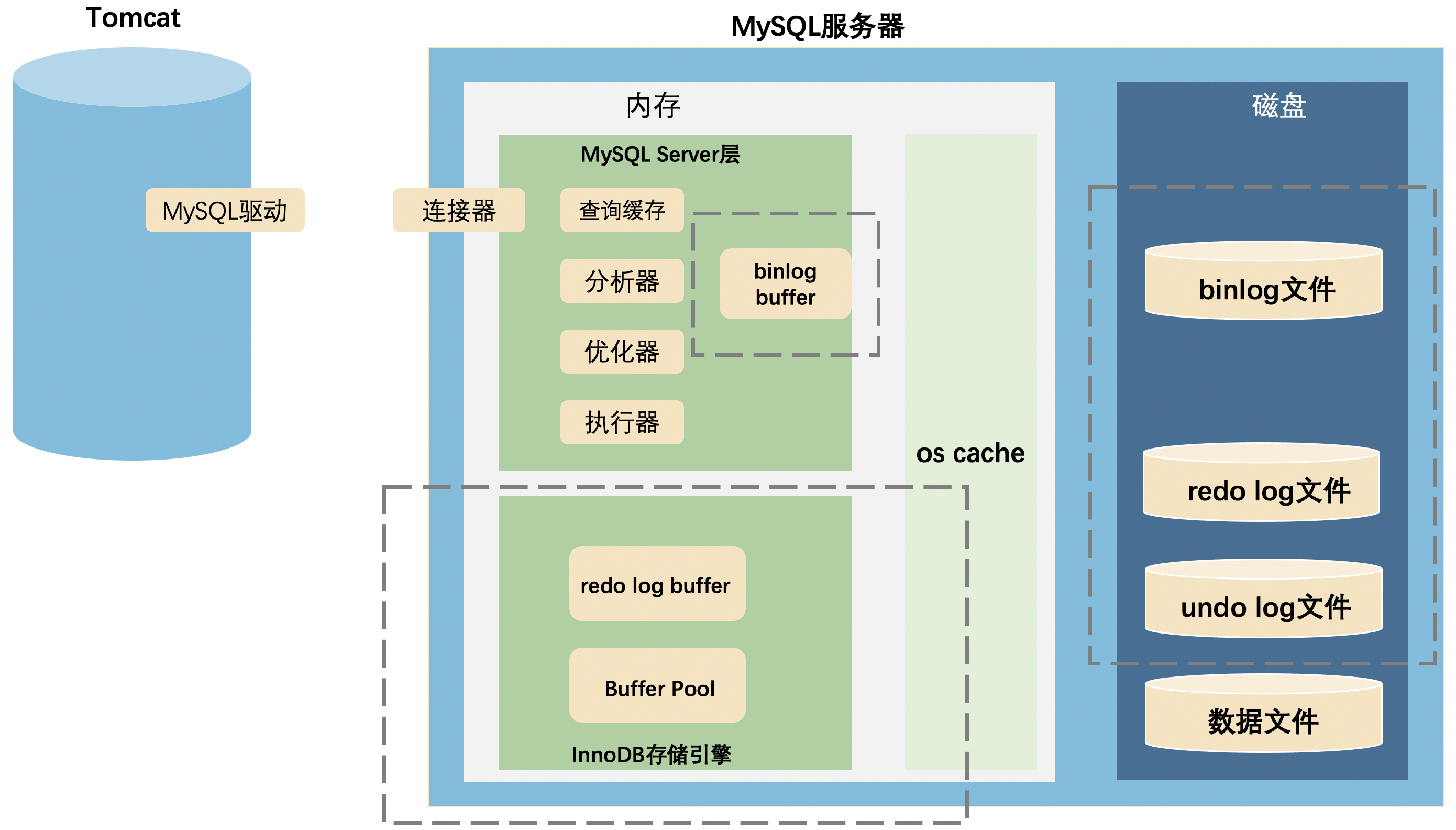
寫在最後
這篇文章寫在一年之前,本來覺得是一篇水文沒想要發,最近無聊修改了一下發了出來,希望能夠用動圖的形式幫助到MySQL基礎不太好的朋友,大神忽略就好。
需要強調的一點是,由於作者水平有限,本文只是淺顯的從無到有地闡述了MySQL幾種紀錄檔的大致作用,過程中省略了很多細節,比如Buffer Pool的實現細節,比如undo log和MVCC的關係,比如binlog buffer、change buffer的存在,比如redo log的兩階段提交。
如果您有任何問題,我們可以探討,如果您在文中發現錯誤,還望您指出,萬分感謝!
好了,今天的文章就到這裡了。
感謝你的閱讀!我是CoderW,我們下期再見。
最後,歡迎關注我的公眾號「CoderW」一起探討進步~~~~
參考資料
- 《MySQL實戰45講》
- 《從根兒上理解MySQL》
- 《MySQL技術內幕—InnoDB儲存引擎》第2版
