深度學習100例-迴圈神經網路(LSTM)實現股票預測 | 第10天
文章目錄
一、前言
今天是第10天,我們將使用LSTM完成股票開盤價格的預測,最後的R2可達到0.74,相對傳統的RNN的0.72提高了兩個百分點。
我的環境:
- 語言環境:Python3.6.5
- 編譯器:jupyter notebook
- 深度學習環境:TensorFlow2.4.1
- 資料和程式碼:📌【傳送門】
來自專欄:【深度學習100例】
往期精彩內容:
- 深度學習100例-折積神經網路(LeNet-5)深度學習裡的「Hello Word」 | 第22天
- 深度學習100例-折積神經網路(CNN)實現mnist手寫數位識別 | 第1天
- 深度學習100例-折積神經網路(CNN)服裝影象分類 | 第3天
- 深度學習100例-折積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-折積神經網路(CNN)天氣識別 | 第5天
- 深度學習100例-折積神經網路(VGG-16)識別海賊王草帽一夥 | 第6天
- 深度學習100例-折積神經網路(ResNet-50)鳥類識別 | 第8天
- 深度學習100例-迴圈神經網路(RNN)股票預測 | 第9天
如果你還是一名小白,可以看看我這個專門為你寫的專欄:《小白入門深度學習》,幫助零基礎的你入門深度學習。
二、LSTM的是什麼
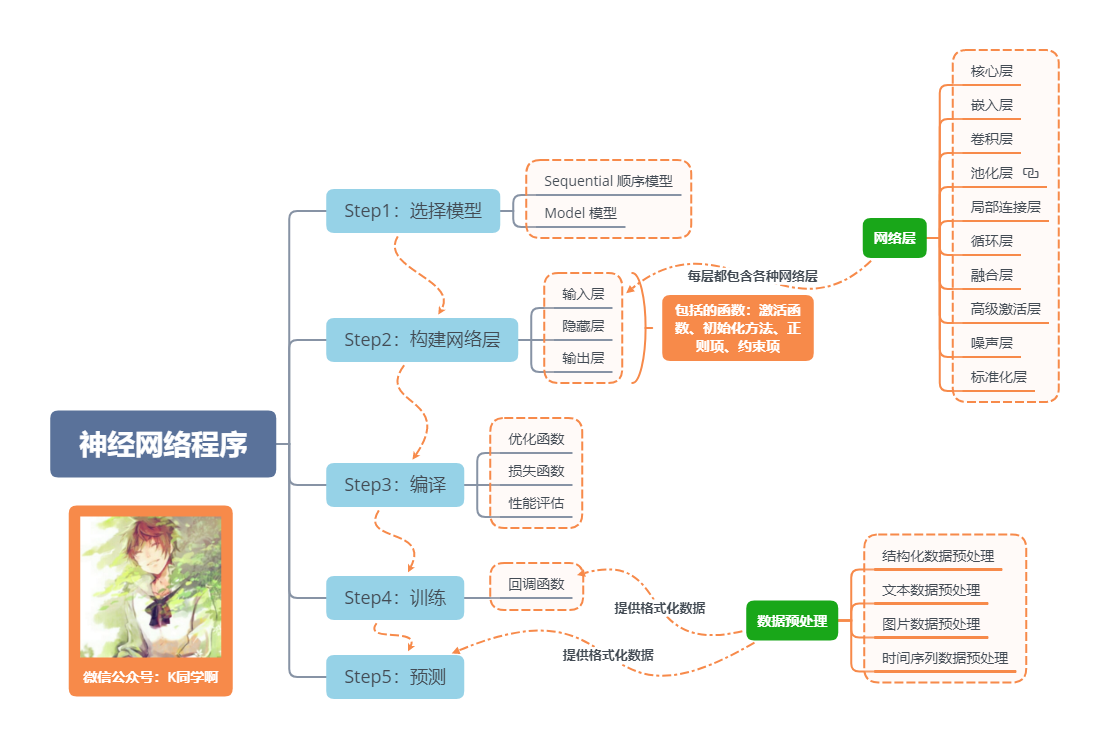
神經網路程式的基本流程
一句話介紹LSTM,它是RNN的進階版,如果說RNN的最大限度是理解一句話,那麼LSTM的最大限度則是理解一段話,詳細介紹如下:
LSTM,全稱為長短期記憶網路(Long Short Term Memory networks),是一種特殊的RNN,能夠學習到長期依賴關係。LSTM由Hochreiter & Schmidhuber (1997)提出,許多研究者進行了一系列的工作對其改進並使之發揚光大。LSTM在許多問題上效果非常好,現在被廣泛使用。
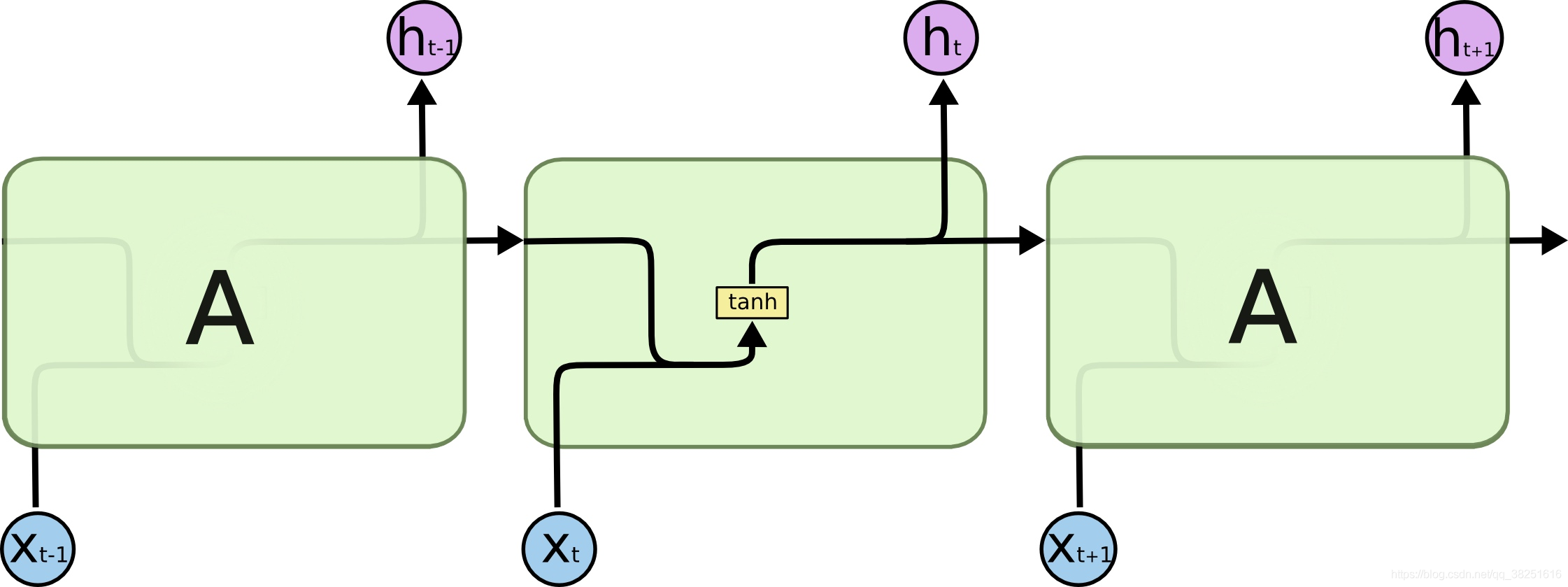
所有的迴圈神經網路都有著重複的神經網路模組形成鏈的形式。在普通的RNN中,重複模組結構非常簡單,其結構如下:
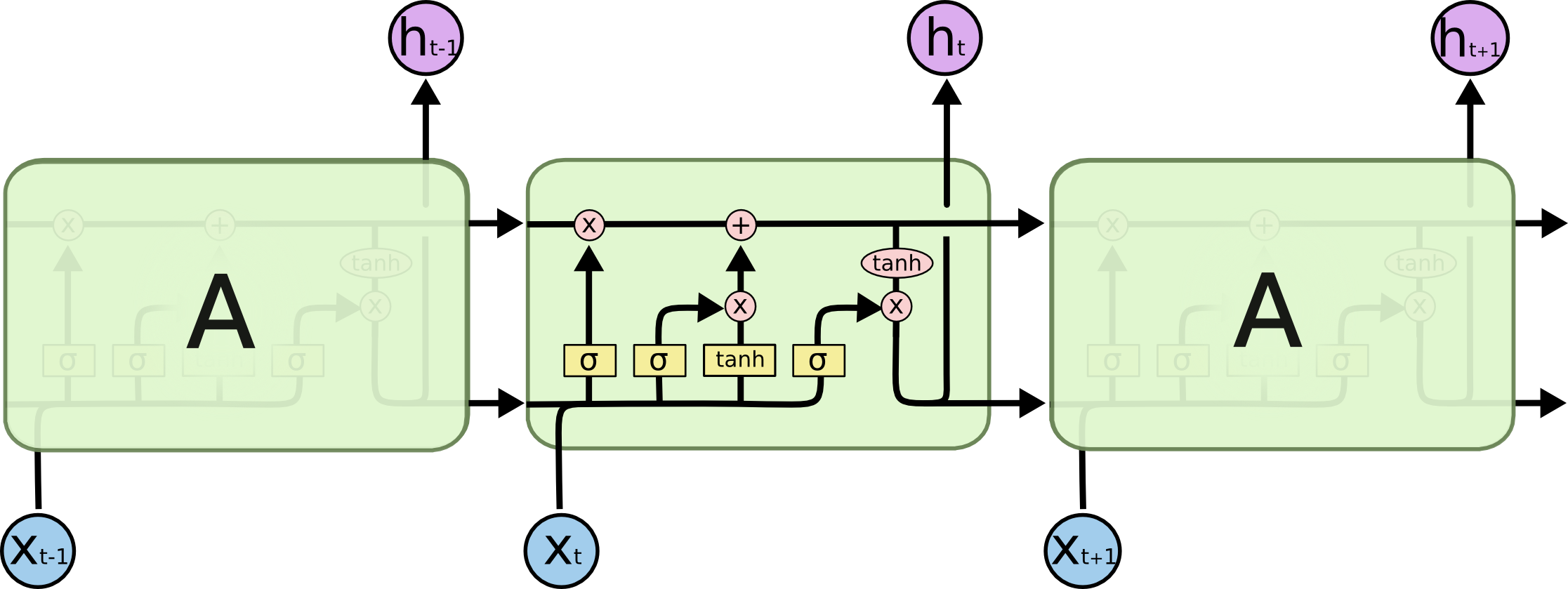
LSTM避免了長期依賴的問題。可以記住長期資訊!LSTM內部有較為複雜的結構。能通過門控狀態來選擇調整傳輸的資訊,記住需要長時間記憶的資訊,忘記不重要的資訊,其結構如下:
三、準備工作
1.設定GPU
如果使用的是CPU可以註釋掉這部分的程式碼。
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #設定GPU視訊記憶體用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
2.設定相關引數
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 支援中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
from numpy import array
from sklearn import metrics
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense,LSTM,Bidirectional
# 確保結果儘可能重現
from numpy.random import seed
seed(1)
tf.random.set_seed(1)
# 設定相關引數
n_timestamp = 40 # 時間戳
n_epochs = 20 # 訓練輪數
# ====================================
# 選擇模型:
# 1: 單層 LSTM
# 2: 多層 LSTM
# 3: 雙向 LSTM
# ====================================
model_type = 1
3.載入資料
data = pd.read_csv('./datasets/SH600519.csv') # 讀取股票檔案
data
| Unnamed: 0 | date | open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|---|---|
| 0 | 74 | 2010-04-26 | 88.702 | 87.381 | 89.072 | 87.362 | 107036.13 | 600519 |
| 1 | 75 | 2010-04-27 | 87.355 | 84.841 | 87.355 | 84.681 | 58234.48 | 600519 |
| 2 | 76 | 2010-04-28 | 84.235 | 84.318 | 85.128 | 83.597 | 26287.43 | 600519 |
| 3 | 77 | 2010-04-29 | 84.592 | 85.671 | 86.315 | 84.592 | 34501.20 | 600519 |
| 4 | 78 | 2010-04-30 | 83.871 | 82.340 | 83.871 | 81.523 | 85566.70 | 600519 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2421 | 2495 | 2020-04-20 | 1221.000 | 1227.300 | 1231.500 | 1216.800 | 24239.00 | 600519 |
| 2422 | 2496 | 2020-04-21 | 1221.020 | 1200.000 | 1223.990 | 1193.000 | 29224.00 | 600519 |
| 2423 | 2497 | 2020-04-22 | 1206.000 | 1244.500 | 1249.500 | 1202.220 | 44035.00 | 600519 |
| 2424 | 2498 | 2020-04-23 | 1250.000 | 1252.260 | 1265.680 | 1247.770 | 26899.00 | 600519 |
| 2425 | 2499 | 2020-04-24 | 1248.000 | 1250.560 | 1259.890 | 1235.180 | 19122.00 | 600519 |
2426 rows × 8 columns
"""
前(2426-300=2126)天的開盤價作為訓練集,後300天的開盤價作為測試集
"""
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
四、資料預處理
1.歸一化
#將資料歸一化,範圍是0到1
sc = MinMaxScaler(feature_range=(0, 1))
training_set_scaled = sc.fit_transform(training_set)
testing_set_scaled = sc.transform(test_set)
2.時間戳函數
# 取前 n_timestamp 天的資料為 X;n_timestamp+1天資料為 Y。
def data_split(sequence, n_timestamp):
X = []
y = []
for i in range(len(sequence)):
end_ix = i + n_timestamp
if end_ix > len(sequence)-1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return array(X), array(y)
X_train, y_train = data_split(training_set_scaled, n_timestamp)
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test, y_test = data_split(testing_set_scaled, n_timestamp)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
五、構建模型
# 建構 LSTM模型
if model_type == 1:
# 單層 LSTM
model = Sequential()
model.add(LSTM(units=50, activation='relu',
input_shape=(X_train.shape[1], 1)))
model.add(Dense(units=1))
if model_type == 2:
# 多層 LSTM
model = Sequential()
model.add(LSTM(units=50, activation='relu', return_sequences=True,
input_shape=(X_train.shape[1], 1)))
model.add(LSTM(units=50, activation='relu'))
model.add(Dense(1))
if model_type == 3:
# 雙向 LSTM
model = Sequential()
model.add(Bidirectional(LSTM(50, activation='relu'),
input_shape=(X_train.shape[1], 1)))
model.add(Dense(1))
model.summary() # 輸出模型結構
WARNING:tensorflow:Layer lstm will not use cuDNN kernel since it doesn't meet the cuDNN kernel criteria. It will use generic GPU kernel as fallback when running on GPU
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 50) 10400
_________________________________________________________________
dense (Dense) (None, 1) 51
=================================================================
Total params: 10,451
Trainable params: 10,451
Non-trainable params: 0
_________________________________________________________________
六、啟用模型
# 該應用只觀測loss數值,不觀測準確率,所以刪去metrics選項,一會在每個epoch迭代顯示時只顯示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 損失函數用均方誤差
七、訓練模型
history = model.fit(X_train, y_train,
batch_size=64,
epochs=n_epochs,
validation_data=(X_test, y_test),
validation_freq=1) #測試的epoch間隔數
model.summary()
Epoch 1/20
33/33 [==============================] - 5s 107ms/step - loss: 0.1049 - val_loss: 0.0569
Epoch 2/20
33/33 [==============================] - 3s 86ms/step - loss: 0.0074 - val_loss: 1.1616
Epoch 3/20
33/33 [==============================] - 3s 83ms/step - loss: 0.0012 - val_loss: 0.1408
Epoch 4/20
33/33 [==============================] - 3s 78ms/step - loss: 5.8758e-04 - val_loss: 0.0421
Epoch 5/20
33/33 [==============================] - 3s 84ms/step - loss: 5.3411e-04 - val_loss: 0.0159
Epoch 6/20
33/33 [==============================] - 3s 81ms/step - loss: 3.9690e-04 - val_loss: 0.0034
Epoch 7/20
33/33 [==============================] - 3s 84ms/step - loss: 4.3521e-04 - val_loss: 0.0032
Epoch 8/20
33/33 [==============================] - 3s 85ms/step - loss: 3.8233e-04 - val_loss: 0.0059
Epoch 9/20
33/33 [==============================] - 3s 81ms/step - loss: 3.6539e-04 - val_loss: 0.0082
Epoch 10/20
33/33 [==============================] - 3s 81ms/step - loss: 3.1790e-04 - val_loss: 0.0141
Epoch 11/20
33/33 [==============================] - 3s 82ms/step - loss: 3.5332e-04 - val_loss: 0.0166
Epoch 12/20
33/33 [==============================] - 3s 86ms/step - loss: 3.2684e-04 - val_loss: 0.0155
Epoch 13/20
33/33 [==============================] - 3s 80ms/step - loss: 2.6495e-04 - val_loss: 0.0149
Epoch 14/20
33/33 [==============================] - 3s 84ms/step - loss: 3.1398e-04 - val_loss: 0.0172
Epoch 15/20
33/33 [==============================] - 3s 80ms/step - loss: 3.4533e-04 - val_loss: 0.0077
Epoch 16/20
33/33 [==============================] - 3s 81ms/step - loss: 2.9621e-04 - val_loss: 0.0082
Epoch 17/20
33/33 [==============================] - 3s 83ms/step - loss: 2.2228e-04 - val_loss: 0.0092
Epoch 18/20
33/33 [==============================] - 3s 86ms/step - loss: 2.4517e-04 - val_loss: 0.0093
Epoch 19/20
33/33 [==============================] - 3s 86ms/step - loss: 2.7179e-04 - val_loss: 0.0053
Epoch 20/20
33/33 [==============================] - 3s 82ms/step - loss: 2.5923e-04 - val_loss: 0.0054
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 50) 10400
_________________________________________________________________
dense (Dense) (None, 1) 51
=================================================================
Total params: 10,451
Trainable params: 10,451
Non-trainable params: 0
_________________________________________________________________
八、結果視覺化
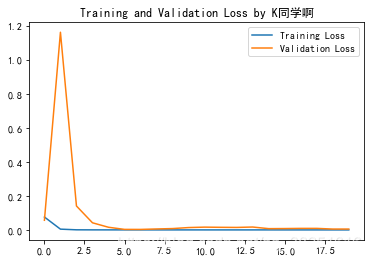
1.繪製loss圖
plt.plot(history.history['loss'] , label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss by K同學啊')
plt.legend()
plt.show()
2.預測
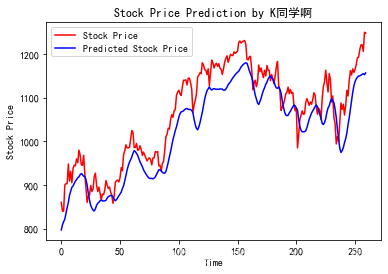
predicted_stock_price = model.predict(X_test) # 測試集輸入模型進行預測
predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 對預測資料還原---從(0,1)反歸一化到原始範圍
real_stock_price = sc.inverse_transform(y_test)# 對真實資料還原---從(0,1)反歸一化到原始範圍
# 畫出真實資料和預測資料的對比曲線
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.title('Stock Price Prediction by K同學啊')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
3.評估
"""
MSE :均方誤差 -----> 預測值減真實值求平方後求均值
RMSE :均方根誤差 -----> 對均方誤差開方
MAE :平均絕對誤差-----> 預測值減真實值求絕對值後求均值
R2 :決定係數,可以簡單理解為反映模型擬合優度的重要的統計量
詳細介紹可以參考文章:https://blog.csdn.net/qq_38251616/article/details/107997435
"""
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方誤差: %.5f' % MSE)
print('均方根誤差: %.5f' % RMSE)
print('平均絕對誤差: %.5f' % MAE)
print('R2: %.5f' % R2)
均方誤差: 2688.75170
均方根誤差: 51.85317
平均絕對誤差: 44.97829
R2: 0.74036
擬合度除了更換模型外,還可以通過調整引數來提高,這裡主要是介紹LSTM,就不對調參做詳細介紹了。
往期精彩內容:
- 深度學習100例-折積神經網路(CNN)實現mnist手寫數位識別 | 第1天
- 深度學習100例-折積神經網路(CNN)服裝影象分類 | 第3天
- 深度學習100例-折積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-折積神經網路(CNN)天氣識別 | 第5天
- 深度學習100例-折積神經網路(VGG-16)識別海賊王草帽一夥 | 第6天
- 深度學習100例-折積神經網路(ResNet-50)鳥類識別 | 第8天
- 深度學習100例-迴圈神經網路(RNN)股票預測 | 第9天
來自專欄:《深度學習100例》
如果覺得本文對你有幫助記得 點個關注,給個贊,加個收藏
最後再送大家一本,幫助大家拿到 BAT 等一線大廠 offer 的資料結構刷題筆記,是谷歌和阿里的大佬寫的,對於演演算法薄弱或者需要提高的同學都十分受用(提取碼:9go2 ):
以及我整理的7K+本開源電子書,總有一本可以幫到你 💖(提取碼:4eg0)