【Python爬蟲】4萬字,詳解selenium從入門到實戰【錯過再無】
👉跳轉文末👈 獲取實戰原始碼與作者聯絡方式,共同學習進步
文章目錄

簡介
Selenium 是最廣泛使用的開源 Web UI(使用者介面)自動化測試套件之一。Selenium 支援的語言套件括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驅動程式最受 Python 和 C#歡迎。 Selenium 測試指令碼可以使用任何支援的程式語言進行編碼,並且可以直接在大多數現代 Web 瀏覽器中執行。在爬蟲領域 selenium 同樣是一把利器,能夠解決大部分的網頁的反爬問題,但也不是萬能的,它最明顯的缺點就是速度慢。下面就進入正式的 study 階段。
selenium安裝
開啟 cmd,輸入下面命令進行安裝。
pip install -i https://pypi.douban.com/simple selenium
執行後,使用 pip show selenium 檢視是否安裝成功。
安裝瀏覽器驅動
針對不同的瀏覽器,需要安裝不同的驅動。下面列舉了常見的瀏覽器與對應的驅動程式下載連結,部分網址需要 「科學上網」 才能開啟哦(dddd)。
- Firefox 瀏覽器驅動:Firefox
- Chrome 瀏覽器驅動:Chrome
- IE 瀏覽器驅動:IE
- Edge 瀏覽器驅動:Edge
- PhantomJS 瀏覽器驅動:PhantomJS
- Opera 瀏覽器驅動:Opera
這裡以安裝 Chrome 驅動作為演示。但 Chrome 在用 selenium 進行自動化測試時還是有部分 bug ,常規使用沒什麼問題,但如果出現一些很少見的報錯,可以使用 Firefox 進行嘗試,畢竟是 selenium 官方推薦使用的。
確定瀏覽器版本
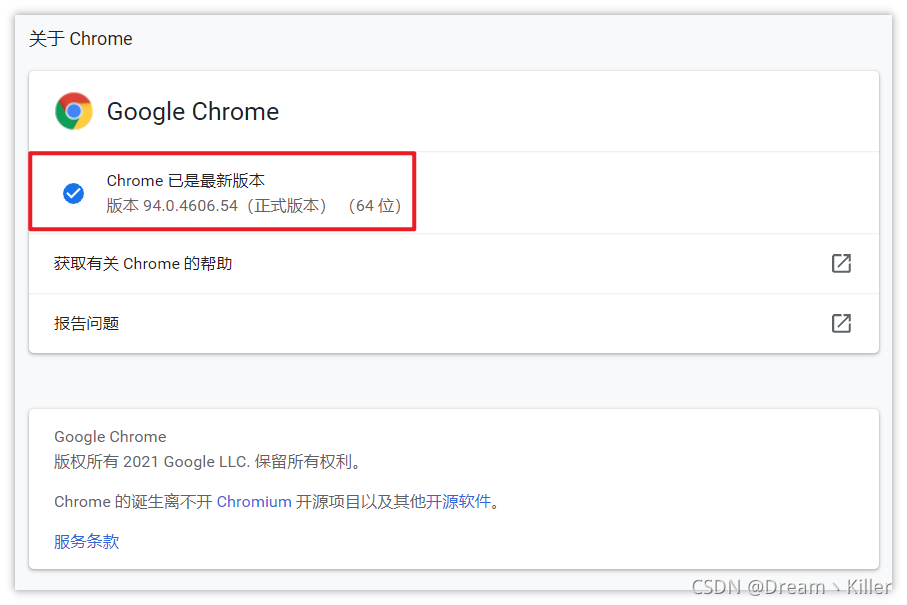
在新分頁輸入 chrome://settings/ 進入設定介面,然後選擇 【關於 Chrome】
檢視自己的版本資訊。這裡我的版本是94,這樣在下載對應版本的 Chrome 驅動即可。
下載驅動
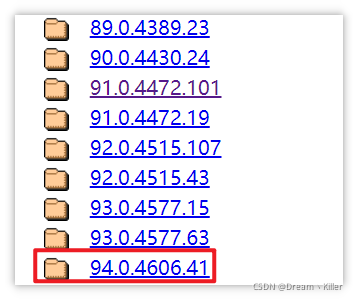
開啟 Chrome驅動 。單擊對應的版本。
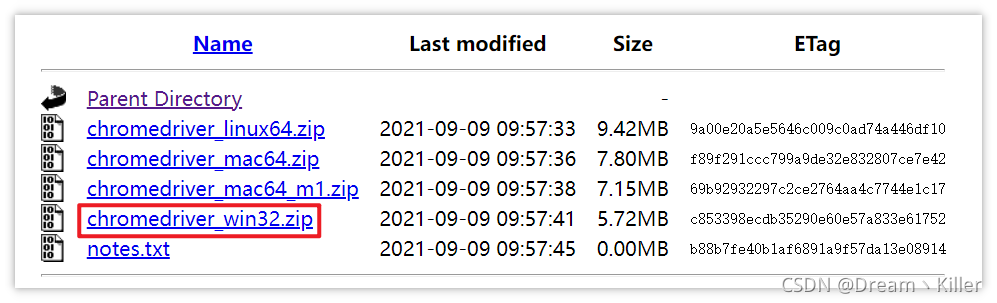
根據自己的作業系統,選擇下載。
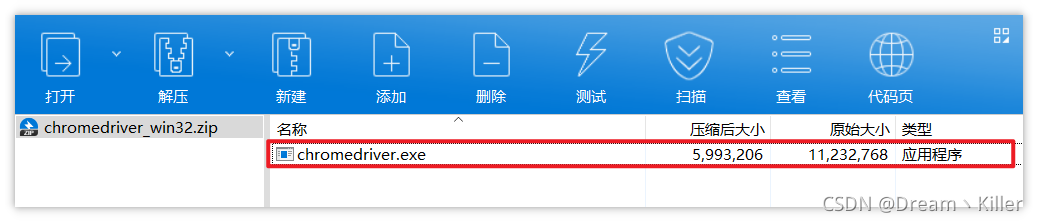
下載完成後,壓縮包內只有一個 exe 檔案。
將 chromedriver.exe 儲存到任意位置,並把當前路徑儲存到環境變數中(我的電腦>>右鍵屬性>>高階系統設定>>高階>>環境變數>>系統變數>>Path),新增的時候要注意不要把 path 變數給覆蓋了,如果覆蓋了千萬別關機,然後百度。新增成功後使用下面程式碼進行測試。
from selenium import webdriver
# Chrome瀏覽器
driver = webdriver.Chrome()
定位頁面元素
開啟指定頁面
使用 selenium 定位頁面元素的前提是你已經瞭解基本的頁面佈局及各種標籤含義,當然如果之前沒有接觸過,現在我也可以帶你簡單的瞭解一下。
以我們熟知的 CSDN 為例,我們進入首頁,按 【F12】 進入開發者工具。紅框中顯示的就是頁面的程式碼,我們要做的就是從程式碼中定位獲取我們需要的元素。
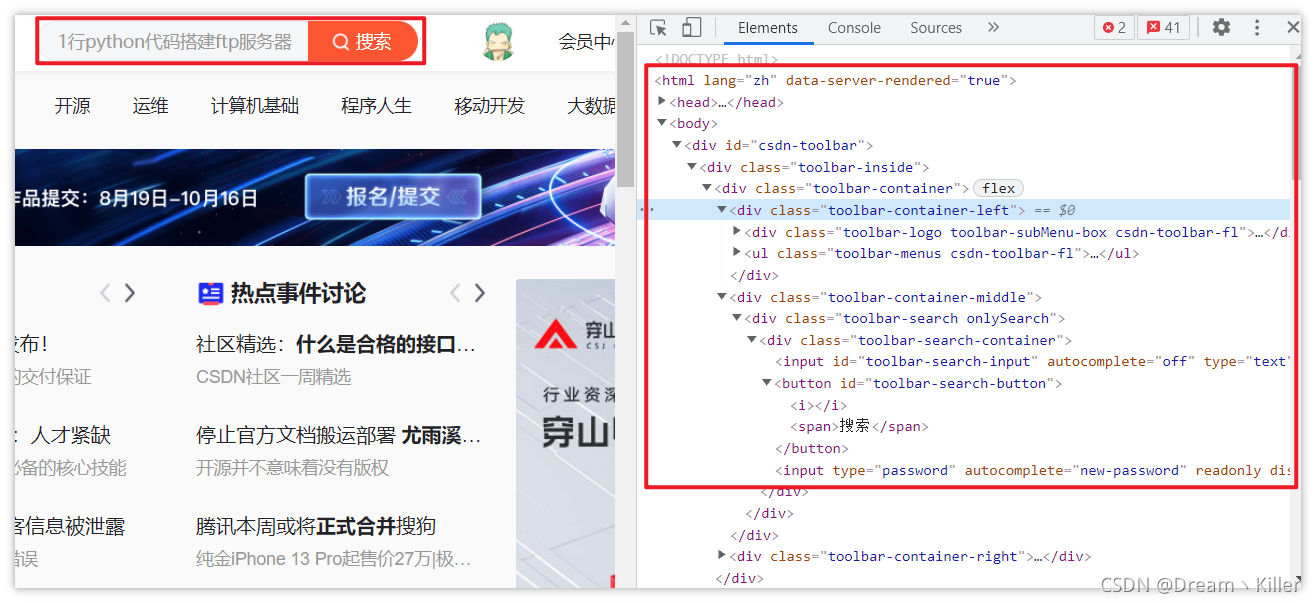
想要定位並獲取頁面中的資訊,首先要使用 webdriver 開啟指定頁面,再去定位。
from selenium import webdriver
# Chrome瀏覽器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
執行上面語句後會發現,瀏覽器開啟 CSDN 主頁後會馬上關閉,想要防止瀏覽器自動關閉,可以新增下面程式碼。
# 不自動關閉瀏覽器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 將option作為引數新增到Chrome中
driver = webdriver.Chrome(chrome_options=option)
這樣將上面的程式碼組合再開啟瀏覽器就不會自動關閉了。
from selenium import webdriver
# 不自動關閉瀏覽器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 注意此處新增了chrome_options引數
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://www.csdn.net/')
下面我們再來看看幾種常見的頁面元素定位方式。
id 定位
標籤的 id 具有唯一性,就像人的身份證,假設有個 input 標籤如下。
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++難在哪裡?">
我們可以通過 id 定位到它,由於 id 的唯一性,我們可以不用管其他的標籤的內容。
driver.find_element_by_id("toolbar-search-input")
name 定位
name 指定標籤的名稱,在頁面中可以不唯一。假設有個 meta 標籤如下
<meta name="keywords" content="CSDN部落格,CSDN學院,CSDN論壇,CSDN直播">
我們可以使用 find_element_by_name 定位到 meta 標籤。
driver.find_element_by_name("keywords")
class 定位
class 指定標籤的類名,在頁面中可以不唯一。假設有個 div 標籤如下
<div class="toolbar-search-container">
我們可以使用 find_element_by_class_name 定位到 div 標籤。
driver.find_element_by_class_name("toolbar-search-container")
tag 定位
每個 tag 往往用來定義一類功能,所以通過 tag 來識別某個元素的成功率很低,每個頁面一般都用很多相同的 tag ,比如:\<div\>、\<input\> 等。這裡還是用上面的 div 作為例子。
<div class="toolbar-search-container">
我們可以使用 find_element_by_class_name 定位到 div 標籤。
driver.find_element_by_tag_name("div")
xpath 定位
xpath 是一種在 XML 檔案中定位元素的語言,它擁有多種定位方式,下面通過範例我們看一下它的幾種使用方式。
<html>
<head>...<head/>
<body>
<div id="csdn-toolbar">
<div class="toolbar-inside">
<div class="toolbar-container">
<div class="toolbar-container-left">...</div>
<div class="toolbar-container-middle">
<div class="toolbar-search onlySearch">
<div class="toolbar-search-container">
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++難在哪裡?">
根據上面的標籤需要定位 最後一行 input 標籤,以下列出了四種方式,xpath 定位的方式多樣並不唯一,使用時根據情況進行解析即可。
# 絕對路徑(層級關係)定位
driver.find_element_by_xpath(
"/html/body/div/div/div/div[2]/div/div/input[1]")
# 利用元素屬性定位
driver.find_element_by_xpath(
"//*[@id='toolbar-search-input']"))
# 層級+元素屬性定位
driver.find_element_by_xpath(
"//div[@id='csdn-toolbar']/div/div/div[2]/div/div/input[1]")
# 邏輯運運算元定位
driver.find_element_by_xpath(
"//*[@id='toolbar-search-input' and @autocomplete='off']")
css 定位
CSS 使用選擇器來為頁面元素繫結屬性,它可以較為靈活的選擇控制元件的任意屬性,一般定位速度比 xpath 要快,但使用起來略有難度。
CSS 選擇器常見語法:
| 方法 | 例子 | 描述 |
|---|---|---|
| .class | .toolbar-search-container | 選擇 class = 'toolbar-search-container' 的所有元素 |
| #id | #toolbar-search-input | 選擇 id = 'toolbar-search-input' 的元素 |
| * | * | 選擇所有元素 |
| element | input | 選擇所有 <input\> 元素 |
| element>element | div>input | 選擇父元素為 <div\> 的所有 <input\> 元素 |
| element+element | div+input | 選擇同一級中在 <div\> 之後的所有 <input\> 元素 |
| [attribute=value] | type='text' | 選擇 type = 'text' 的所有元素 |
舉個簡單的例子,同樣定位上面範例中的 input 標籤。
driver.find_element_by_css_selector('#toolbar-search-input')
driver.find_element_by_css_selector('html>body>div>div>div>div>div>div>input')
link 定位
link 專門用來定位文字連結,假如要定位下面這一標籤。
<div class="practice-box" data-v-04f46969="">加入!每日一練</div>
我們使用 find_element_by_link_text 並指明標籤內全部文字即可定位。
driver.find_element_by_link_text("加入!每日一練")
partial_link 定位
partial_link 翻譯過來就是「部分連結」,對於有些文字很長,這時候就可以只指定部分文字即可定位,同樣使用剛才的例子。
<div class="practice-box" data-v-04f46969="">加入!每日一練</div>
我們使用 find_element_by_partial_link_text 並指明標籤內部分文字進行定位。
driver.find_element_by_partial_link_text("加入")
瀏覽器控制
修改瀏覽器視窗大小
webdriver 提供 set_window_size() 方法來修改瀏覽器視窗的大小。
from selenium import webdriver
# Chrome瀏覽器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
# 設定瀏覽器瀏覽器的寬高為:600x800
driver.set_window_size(600, 800)
也可以使用 maximize_window() 方法可以實現瀏覽器全螢幕顯示。
from selenium import webdriver
# Chrome瀏覽器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
# 設定瀏覽器瀏覽器的寬高為:600x800
driver.maximize_window()
瀏覽器前進&後退
webdriver 提供 back 和 forward 方法來實現頁面的後退與前進。下面我們 ①進入CSDN首頁,②開啟CSDN個人主頁,③back 返回到CSDN首頁,④ forward 前進到個人主頁。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
# 存取CSDN首頁
driver.get('https://www.csdn.net/')
sleep(2)
#存取CSDN個人主頁
driver.get('https://blog.csdn.net/qq_43965708')
sleep(2)
#返回(後退)到CSDN首頁
driver.back()
sleep(2)
#前進到個人主頁
driver.forward()
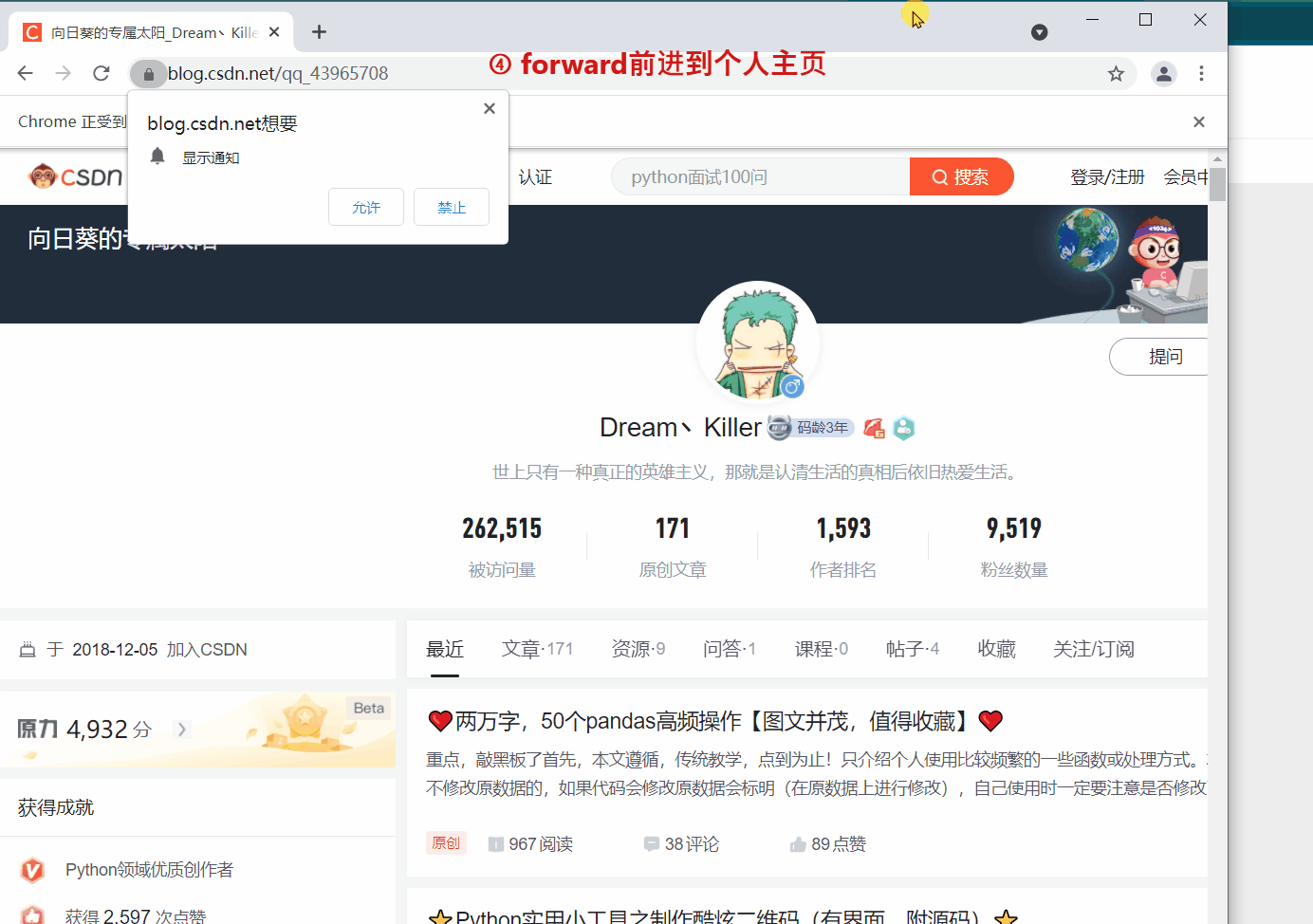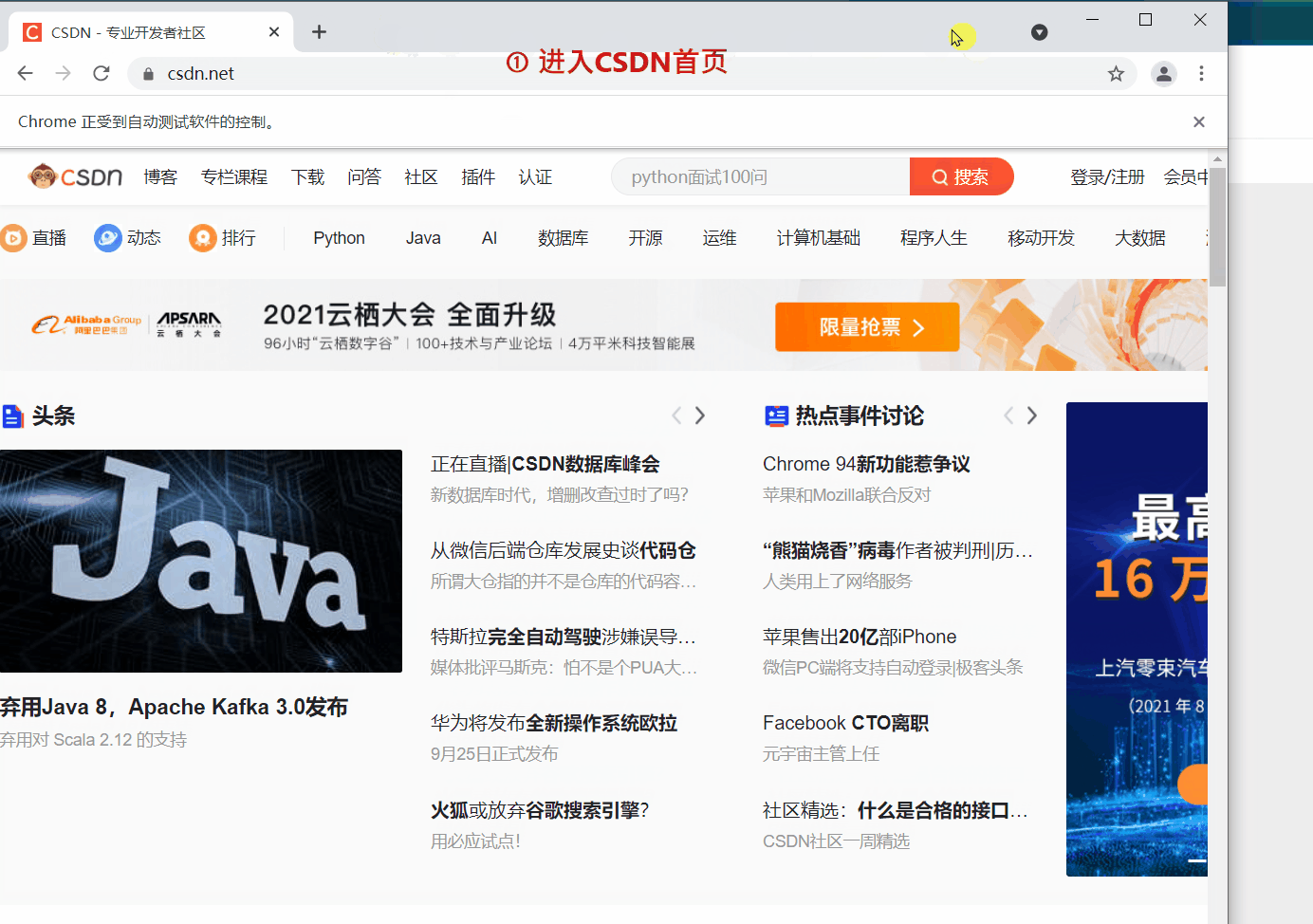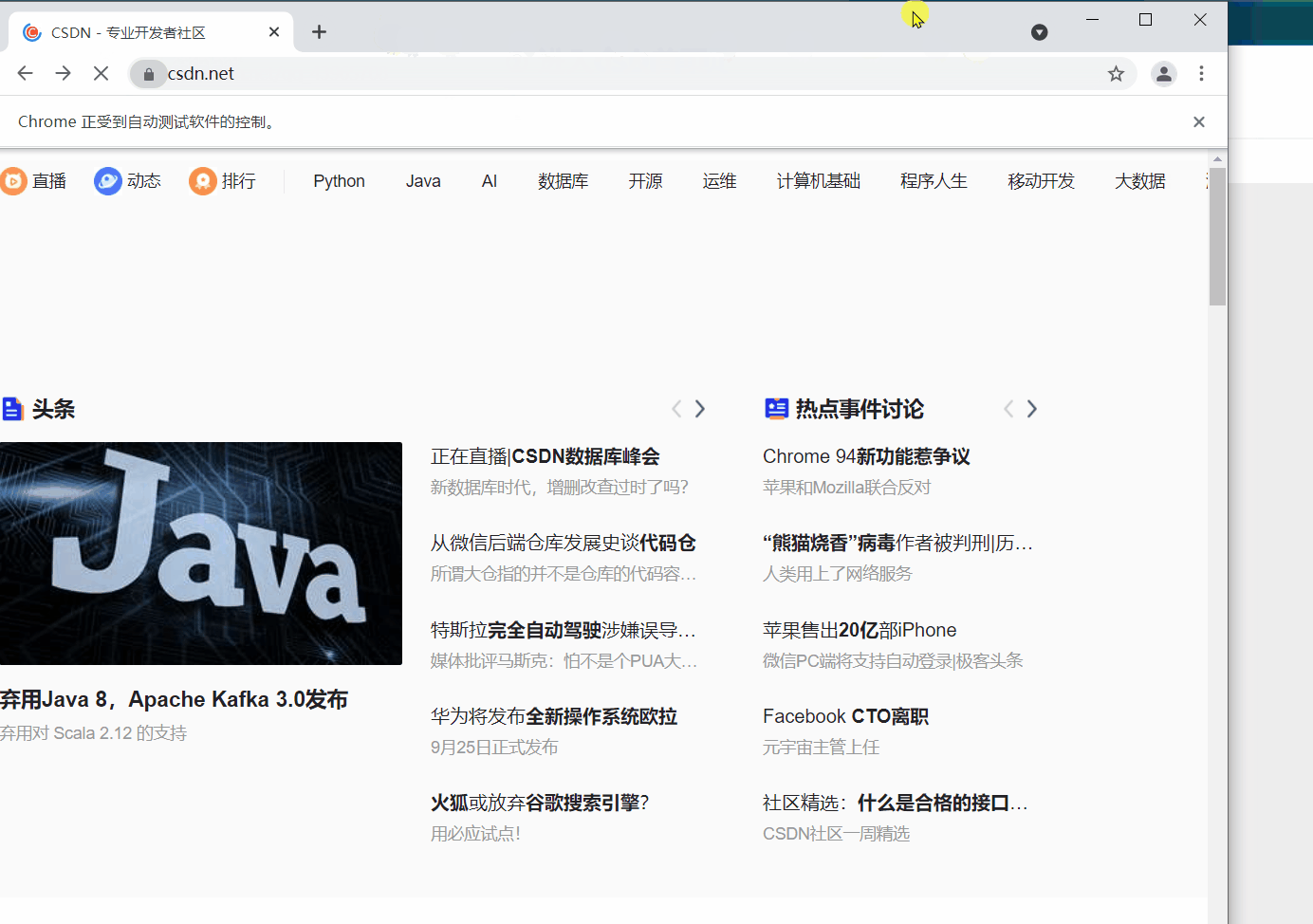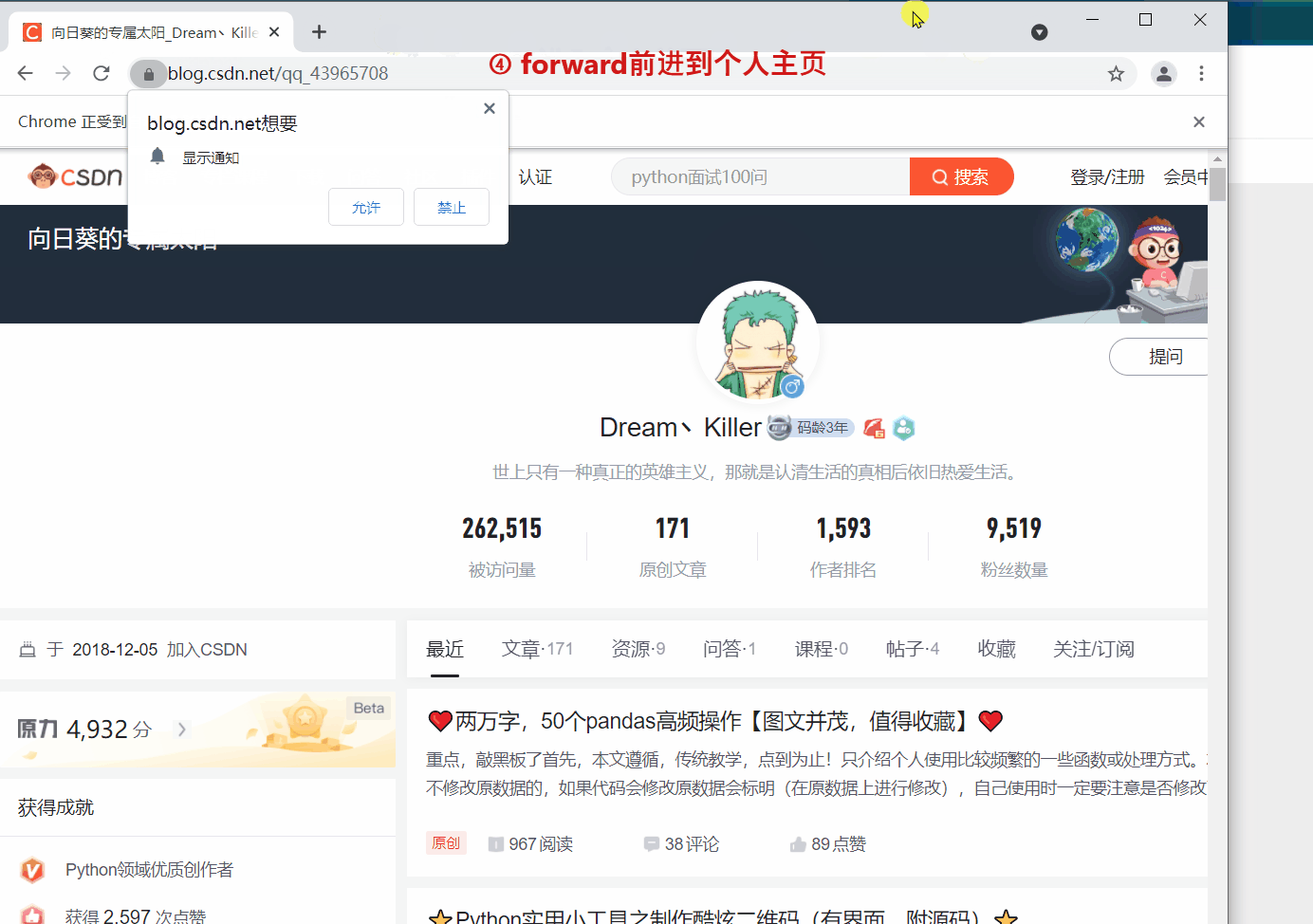
細心的讀者會發現第二次 get() 開啟新頁面時,會在原來的頁面開啟,而不是在新標籤中開啟。如果想的話也可以在新的分頁中開啟新的連結,但需要更改一下程式碼,執行 js 語句來開啟新的標籤。
# 在原頁面開啟
driver.get('https://blog.csdn.net/qq_43965708')
# 新標籤中開啟
js = "window.open('https://blog.csdn.net/qq_43965708')"
driver.execute_script(js)
瀏覽器重新整理
在一些特殊情況下我們可能需要重新整理頁面來獲取最新的頁面資料,這時我們可以使用 refresh() 來重新整理當前頁面。
# 重新整理頁面
driver.refresh()
瀏覽器視窗切換
在很多時候我們都需要用到視窗切換,比如:當我們點選註冊按鈕時,它一般會開啟一個新的分頁,但實際上程式碼並沒有切換到最新頁面中,這時你如果要定位註冊頁面的標籤就會發現定位不到,這時就需要將實際視窗切換到最新開啟的那個視窗。我們先獲取當前各個視窗的控制程式碼,這些資訊的儲存順序是按照時間來的,最新開啟的視窗放在陣列的末尾,這時我們就可以定位到最新開啟的那個視窗了。
# 獲取開啟的多個視窗控制程式碼
windows = driver.window_handles
# 切換到當前最新開啟的視窗
driver.switch_to.window(windows[-1])
常見操作
webdriver中的常見操作有:
| 方法 | 描述 |
|---|---|
send_keys() | 模擬輸入指定內容 |
clear() | 清除文字內容 |
is_displayed() | 判斷該元素是否可見 |
get_attribute() | 獲取標籤屬性值 |
size | 返回元素的尺寸 |
text | 返回元素文字 |
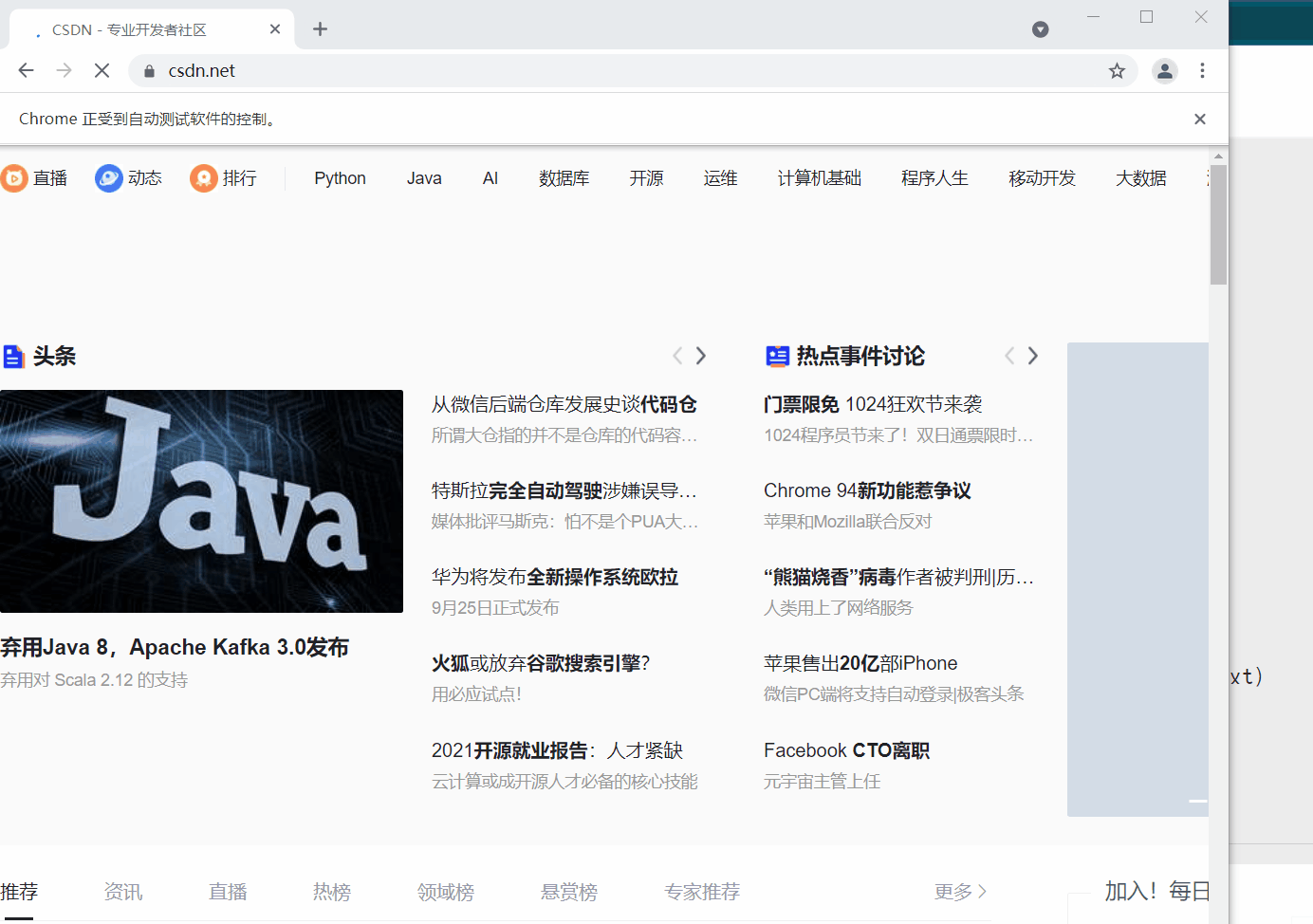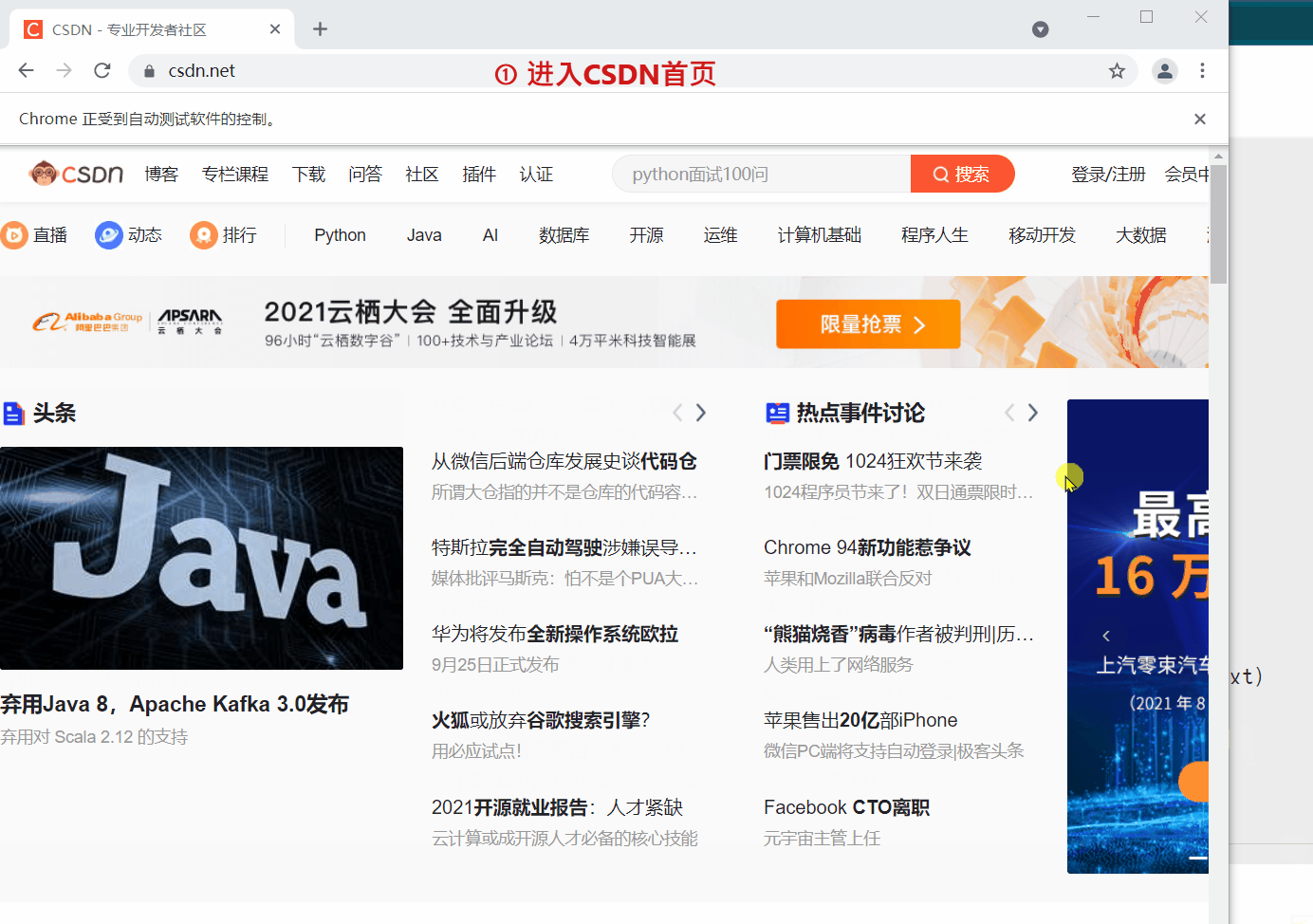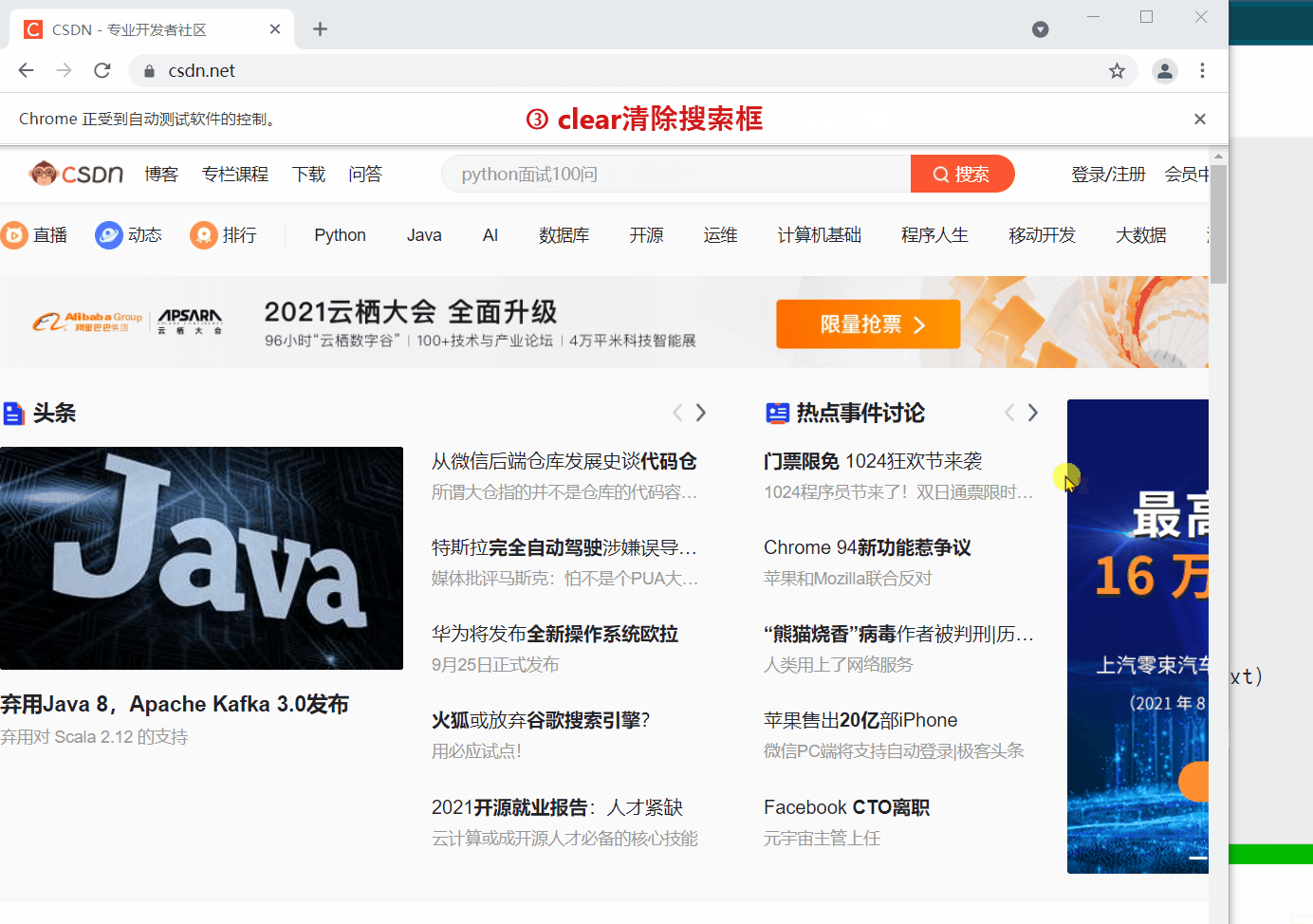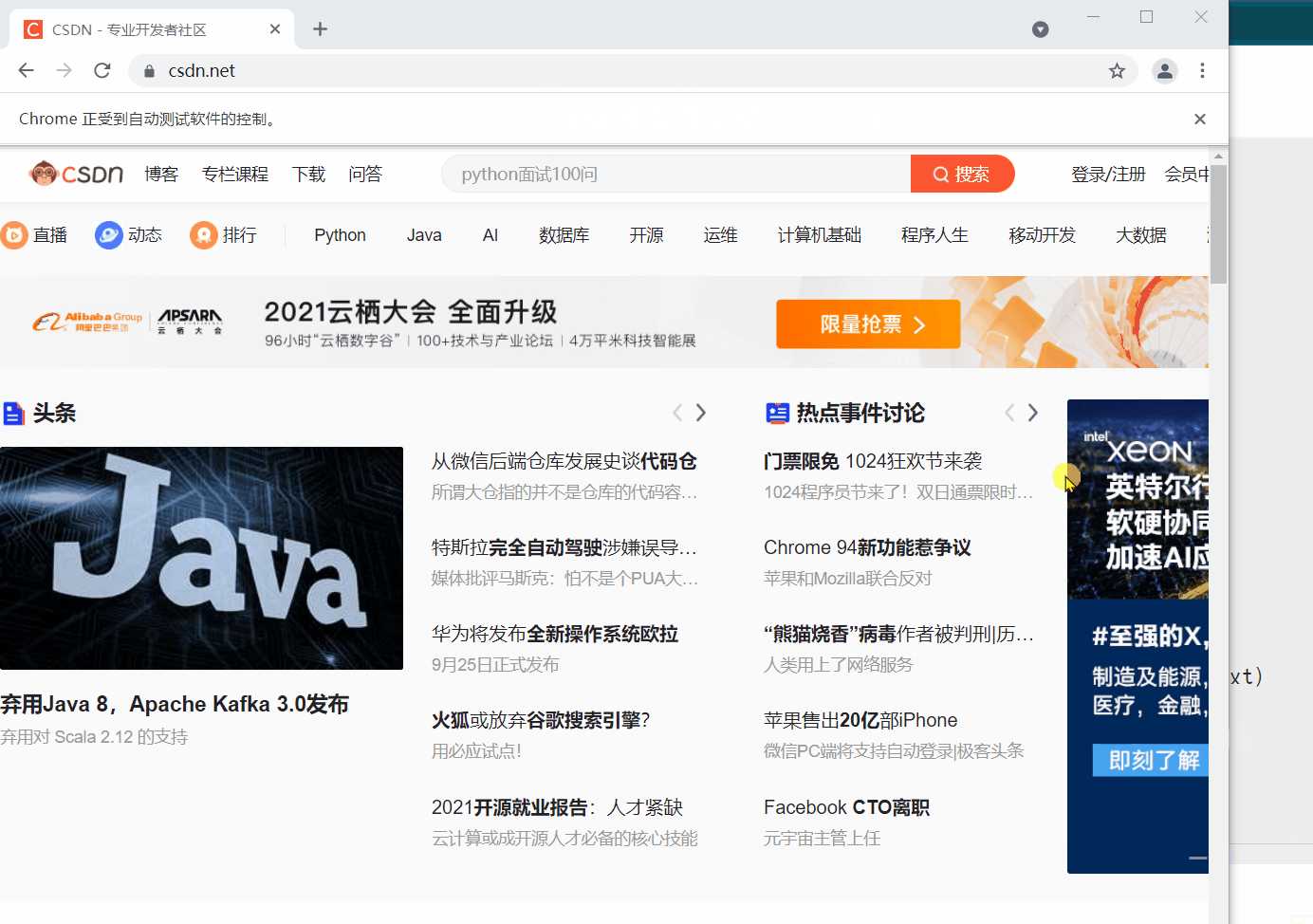
接下來還是用 CSDN 首頁為例,需要用到的就是搜素框和搜尋按鈕。通過下面的例子就可以氣息的瞭解各個操作的用法了。

from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
sleep(2)
# 定位搜尋輸入框
text_label = driver.find_element_by_xpath('//*[@id="toolbar-search-input"]')
# 在搜尋方塊中輸入 Dream丶Killer
text_label.send_keys('Dream丶Killer')
sleep(2)
# 清除搜尋方塊中的內容
text_label.clear()
# 輸出搜尋方塊元素是否可見
print(text_label.is_displayed())
# 輸出placeholder的值
print(text_label.get_attribute('placeholder'))
# 定位搜尋按鈕
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 輸出按鈕的大小
print(button.size)
# 輸出按鈕上的文字
print(button.text)
'''輸出內容
True
python面試100問
{'height': 32, 'width': 28}
搜尋
'''
滑鼠控制
在webdriver 中,滑鼠操作都封裝在ActionChains類中,常見方法如下:
| 方法 | 描述 |
|---|---|
click() | 單擊左鍵 |
context_click() | 單擊右鍵 |
double_click() | 雙擊 |
drag_and_drop() | 拖動 |
move_to_element() | 滑鼠懸停 |
perform() | 執行所有ActionChains中儲存的動作 |
單擊左鍵
模擬完成單擊滑鼠左鍵的操作,一般點選進入子頁面等會用到,左鍵不需要用到 ActionChains 。
# 定位搜尋按鈕
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 執行單擊操作
button.click()
單擊右鍵
滑鼠右擊的操作與左擊有很大不同,需要使用 ActionChains 。
from selenium.webdriver.common.action_chains import ActionChains
# 定位搜尋按鈕
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 右鍵搜尋按鈕
ActionChains(driver).context_click(button).perform()
雙擊
模擬滑鼠雙擊操作。
# 定位搜尋按鈕
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 執行雙擊動作
ActionChains(driver).double_click(button).perform()
拖動
模擬滑鼠拖動操作,該操作有兩個必要引數,
- source:滑鼠拖動的元素
- target:滑鼠拖至並釋放的目標元素
# 定位要拖動的元素
source = driver.find_element_by_xpath('xxx')
# 定位目標元素
target = driver.find_element_by_xpath('xxx')
# 執行拖動動作
ActionChains(driver).drag_and_drop(source, target).perform()
滑鼠懸停
模擬懸停的作用一般是為了顯示隱藏的下拉框,比如 CSDN 主頁的收藏欄,我們看一下效果。
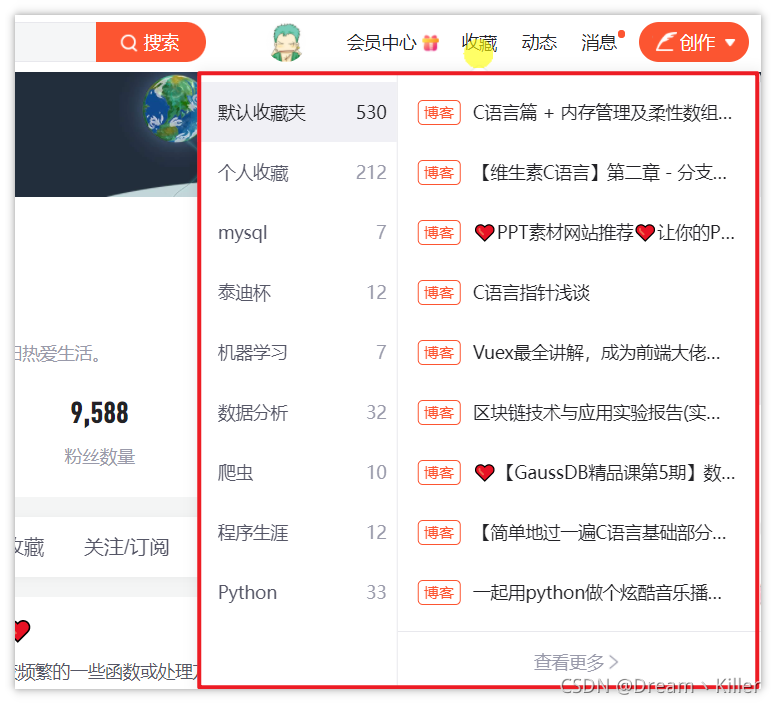
# 定位收藏欄
collect = driver.find_element_by_xpath('//*[@id="csdn-toolbar"]/div/div/div[3]/div/div[3]/a')
# 懸停至收藏標籤處
ActionChains(driver).move_to_element(collect).perform()
鍵盤控制
webdriver 中 Keys 類幾乎提供了鍵盤上的所有按鍵方法,我們可以使用 send_keys + Keys 實現輸出鍵盤上的組合按鍵如 「Ctrl + C」、「Ctrl + V」 等。
from selenium.webdriver.common.keys import Keys
# 定位輸入框並輸入文字
driver.find_element_by_id('xxx').send_keys('Dream丶killer')
# 模擬確認鍵進行跳轉(輸入內容後)
driver.find_element_by_id('xxx').send_keys(Keys.ENTER)
# 使用 Backspace 來刪除一個字元
driver.find_element_by_id('xxx').send_keys(Keys.BACK_SPACE)
# Ctrl + A 全選輸入框中內容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'a')
# Ctrl + C 複製輸入框中內容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'c')
# Ctrl + V 貼上輸入框中內容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'v')
其他常見鍵盤操作:
| 操作 | 描述 |
|---|---|
Keys.F1 | F1鍵 |
Keys.SPACE | 空格 |
Keys.TAB | Tab鍵 |
Keys.ESCAPE | ESC鍵 |
Keys.ALT | Alt鍵 |
Keys.SHIFT | Shift鍵 |
Keys.ARROW_DOWN | 向下箭頭 |
Keys.ARROW_LEFT | 向左箭頭 |
Keys.ARROW_RIGHT | 向右箭頭 |
Keys.ARROW_UP | 向上箭頭 |
設定元素等待
很多頁面都使用 ajax 技術,頁面的元素不是同時被載入出來的,為了防止定位這些尚在載入的元素報錯,可以設定元素等來增加指令碼的穩定性。webdriver 中的等待分為 顯式等待 和 隱式等待。
顯式等待
顯式等待:設定一個超時時間,每個一段時間就去檢測一次該元素是否存在,如果存在則執行後續內容,如果超過最大時間(超時時間)則丟擲超時異常(TimeoutException)。顯示等待需要使用 WebDriverWait,同時配合 until 或 not until 。下面詳細講解一下。
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
driver:瀏覽器驅動timeout:超時時間,單位秒poll_frequency:每次檢測的間隔時間,預設為0.5秒ignored_exceptions:指定忽略的異常,如果在呼叫until或until_not的過程中丟擲指定忽略的異常,則不中斷程式碼,預設忽略的只有NoSuchElementException。
until(method, message=’ ‘)
until_not(method, message=’ ')
method:指定預期條件的判斷方法,在等待期間,每隔一段時間呼叫該方法,判斷元素是否存在,直到元素出現。until_not正好相反,當元素消失或指定條件不成立,則繼續執行後續程式碼message: 如果超時,丟擲TimeoutException,並顯示message中的內容
method 中的預期條件判斷方法是由 expected_conditions 提供,下面列舉常用方法。
先定義一個定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator = (By.ID, 'kw')
element = driver.find_element_by_id('kw')
| 方法 | 描述 |
|---|---|
| title_is(‘百度一下’) | 判斷當前頁面的 title 是否等於預期 |
| title_contains(‘百度’) | 判斷當前頁面的 title 是否包含預期字串 |
| presence_of_element_located(locator) | 判斷元素是否被加到了 dom 樹裡,並不代表該元素一定可見 |
| visibility_of_element_located(locator) | 判斷元素是否可見,可見代表元素非隱藏,並且元素的寬和高都不等於0 |
| visibility_of(element) | 跟上一個方法作用相同,但傳入引數為 element |
| text_to_be_present_in_element(locator , ‘百度’) | 判斷元素中的 text 是否包含了預期的字串 |
| text_to_be_present_in_element_value(locator , ‘某值’) | 判斷元素中的 value 屬性是否包含了預期的字串 |
| frame_to_be_available_and_switch_to_it(locator) | 判斷該 frame 是否可以 switch 進去,True 則 switch 進去,反之 False |
| invisibility_of_element_located(locator) | 判斷元素中是否不存在於 dom 樹或不可見 |
| element_to_be_clickable(locator) | 判斷元素中是否可見並且是可點選的 |
| staleness_of(element) | 等待元素從 dom 樹中移除 |
| element_to_be_selected(element) | 判斷元素是否被選中,一般用在下拉選單 |
| element_selection_state_to_be(element, True) | 判斷元素的選中狀態是否符合預期,引數 element,第二個引數為 True/False |
| element_located_selection_state_to_be(locator, True) | 跟上一個方法作用相同,但傳入引數為 locator |
| alert_is_present() | 判斷頁面上是否存在 alert |
下面寫一個簡單的例子,這裡定位一個頁面不存在的元素,丟擲的異常資訊正是我們指定的內容。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, 'kw')),
message='超時啦!')

隱式等待
隱式等待也是指定一個超時時間,如果超出這個時間指定元素還沒有被載入出來,就會丟擲 NoSuchElementException 異常。
除了丟擲的異常不同外,還有一點,隱式等待是全域性性的,即執行過程中,如果元素可以定位到,它不會影響程式碼執行,但如果定位不到,則它會以輪詢的方式不斷地存取元素直到元素被找到,若超過指定時間,則丟擲異常。
使用 implicitly_wait() 來實現隱式等待,使用難度相對於顯式等待要簡單很多。
範例:開啟個人主頁,設定一個隱式等待時間 5s,通過 id 定位一個不存在的元素,最後列印 丟擲的異常 與 執行時間。
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43965708')
start = time()
driver.implicitly_wait(5)
try:
driver.find_element_by_id('kw')
except Exception as e:
print(e)
print(f'耗時:{time()-start}')

程式碼執行到 driver.find_element_by_id('kw') 這句之後觸發隱式等待,在輪詢檢查 5s 後仍然沒有定位到元素,丟擲異常。
強制等待
使用 time.sleep() 強制等待,設定固定的休眠時間,對於程式碼的執行效率會有影響。以上面的例子作為參照,將 隱式等待 改為 強制等待。
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43965708')
start = time()
sleep(5)
try:
driver.find_element_by_id('kw')
except Exception as e:
print(e)
print(f'耗時:{time()-start}')

值得一提的是,對於定位不到元素的時候,從耗時方面隱式等待和強制等待沒什麼區別。但如果元素經過 2s 後被載入出來,這時隱式等待就會繼續執行下面的程式碼,但 sleep還要繼續等待 3s。
定位一組元素
上篇講述了定位一個元素的 8 種方法,定位一組元素使用的方法只需要將 element 改為 elements 即可,它的使用場景一般是為了批次操作元素。
find_elements_by_id()find_elements_by_name()find_elements_by_class_name()find_elements_by_tag_name()find_elements_by_xpath()find_elements_by_css_selector()find_elements_by_link_text()find_elements_by_partial_link_text()
這裡以 CSDN 首頁的一個 部落格專家欄 為例。
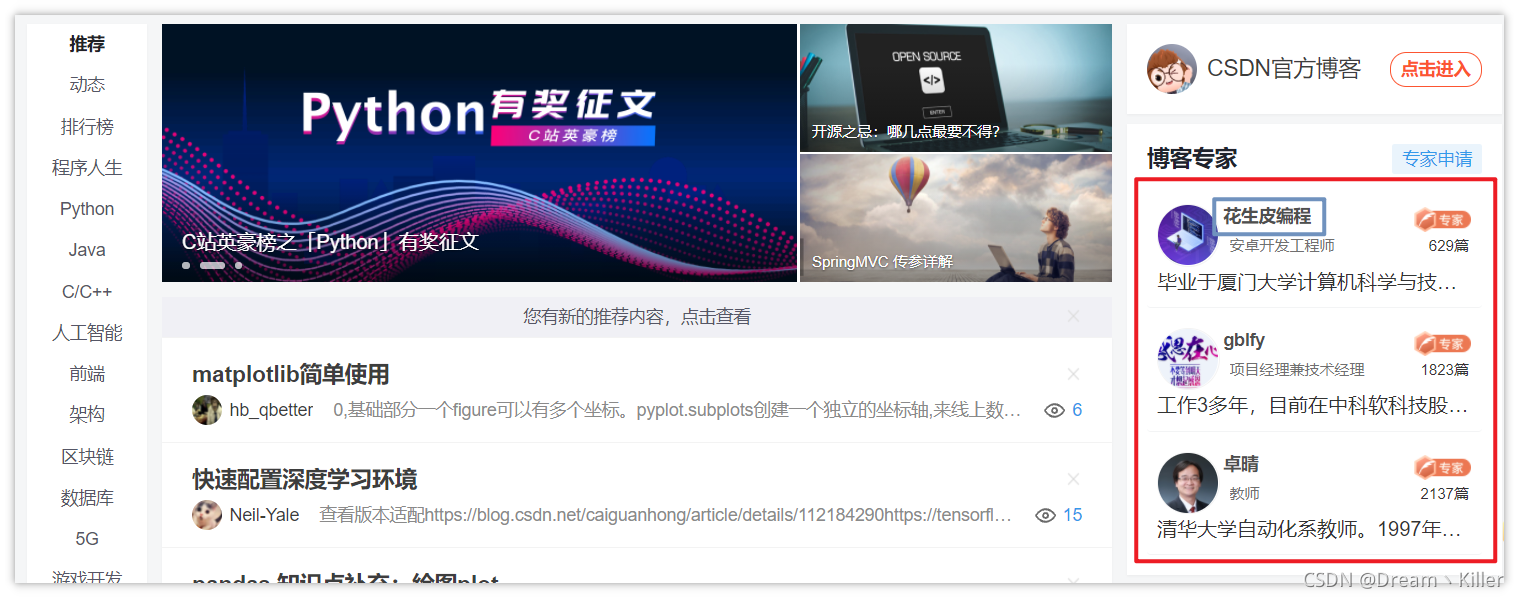
下面使用 find_elements_by_xpath 來定位三位專家的名稱。

這是專家名稱部分的頁面程式碼,不知各位有沒有想到如何通過 xpath 定位這一組專家的名稱呢?
from selenium import webdriver
# 設定無頭瀏覽器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(options=option)
driver.get('https://blog.csdn.net/')
p_list = driver.find_elements_by_xpath("//p[@class='name']")
name = [p.text for p in p_list]
name

切換操作
視窗切換
在 selenium 操作頁面的時候,可能會因為點選某個連結而跳轉到一個新的頁面(開啟了一個新分頁),這時候 selenium 實際還是處於上一個頁面的,需要我們進行切換才能夠定位最新頁面上的元素。
視窗切換需要使用 switch_to.windows() 方法。
首先我們先看看下面的程式碼。
程式碼流程:先進入 【CSDN首頁】,儲存當前頁面的控制程式碼,然後再點選左側 【CSDN官方部落格】跳轉進入新的分頁,再次儲存頁面的控制程式碼,我們驗證一下 selenium 會不會自動定位到新開啟的視窗。
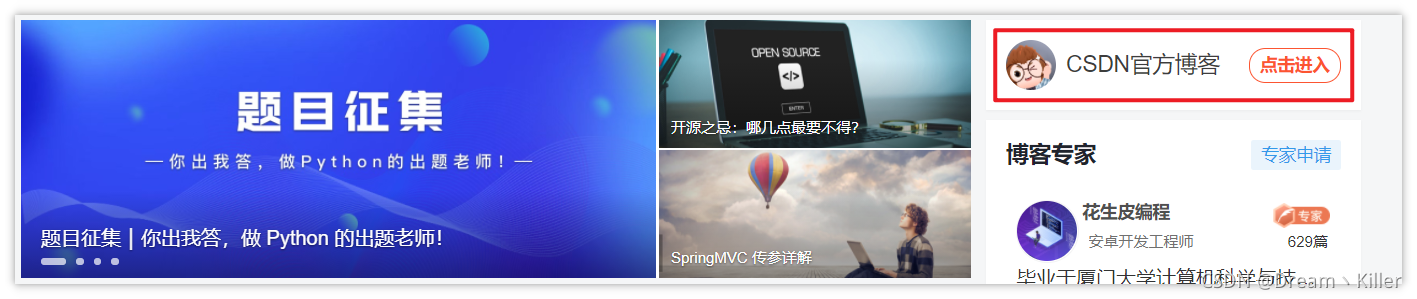
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
# 設定隱式等待
driver.implicitly_wait(3)
# 獲取當前視窗的控制程式碼
handles.append(driver.current_window_handle)
# 點選 python,進入分類頁面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 獲取當前視窗的控制程式碼
handles.append(driver.current_window_handle)
print(handles)
# 獲取當前所有視窗的控制程式碼
print(driver.window_handles)

可以看到第一個列表 handle 是相同的,說明 selenium 實際操作的還是 CSDN首頁 ,並未切換到新頁面。
下面使用 switch_to.windows() 進行切換。
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
# 設定隱式等待
driver.implicitly_wait(3)
# 獲取當前視窗的控制程式碼
handles.append(driver.current_window_handle)
# 點選 python,進入分類頁面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 切換視窗
driver.switch_to.window(driver.window_handles[-1])
# 獲取當前視窗的控制程式碼
handles.append(driver.current_window_handle)
print(handles)
print(driver.window_handles)

上面程式碼在點選跳轉後,使用 switch_to 切換視窗,window_handles 返回的 handle 列表是按照頁面出現時間進行排序的,最新開啟的頁面肯定是最後一個,這樣用 driver.window_handles[-1] + switch_to 即可跳轉到最新開啟的頁面了。
那如果開啟的視窗有多個,如何跳轉到之前開啟的視窗,如果確實有這個需求,那麼開啟視窗是就需要記錄每一個視窗的 key(別名) 與 value(handle),儲存到字典中,後續根據 key 來取 handle 。
表單切換
很多頁面也會用帶 frame/iframe 表單巢狀,對於這種內嵌的頁面 selenium 是無法直接定位的,需要使用 switch_to.frame() 方法將當前操作的物件切換成 frame/iframe 內嵌的頁面。
switch_to.frame() 預設可以用的 id 或 name 屬性直接定位,但如果 iframe 沒有 id 或 name ,這時就需要使用 xpath 進行定位。下面先寫一個包含 iframe 的頁面做測試用。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div p {
color: #red;
animation: change 2s infinite;
}
@keyframes change {
from {
color: red;
}
to {
color: blue;
}
}
</style>
</head>
<body>
<div>
<p>公眾號:Python新視野</p>
<p>CSDN:Dream丶Killer</p>
<p>微信:python-sun</p>
</div>
<iframe src="https://blog.csdn.net/qq_43965708" width="400" height="200"></iframe>
<!-- <iframe id="CSDN_info" name="Dream丶Killer" src="https://blog.csdn.net/qq_43965708" width="400" height="200"></iframe> -->
</body>
</html>
現在我們定位紅框中的 CSDN 按鈕,可以跳轉到 CSDN 首頁。
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()
# 讀取本地html檔案
driver.get('file:///' + str(Path(Path.cwd(), 'iframe測試.html')))
# 1.通過id定位
driver.switch_to.frame('CSDN_info')
# 2.通過name定位
# driver.switch_to.frame('Dream丶Killer')
# 通過xpath定位
# 3.iframe_label = driver.find_element_by_xpath('/html/body/iframe')
# driver.switch_to.frame(iframe_label)
driver.find_element_by_xpath('//*[@id="csdn-toolbar"]/div/div/div[1]/div/a/img').click()
這裡列舉了三種定位方式,都可以定位 iframe 。

彈窗處理
JavaScript 有三種彈窗 alert(確認)、confirm(確認、取消)、prompt(文字方塊、確認、取消)。
處理方式:先定位(switch_to.alert自動獲取當前彈窗),再使用 text、accept、dismiss、send_keys 等方法進行操作
| 方法 | 描述 |
|---|---|
text | 獲取彈窗中的文字 |
accept | 接受(確認)彈窗內容 |
dismiss | 解除(取消)彈窗 |
send_keys | 傳送文字至警告框 |
這裡寫一個簡單的測試頁面,其中包含三個按鈕,分別對應三個彈窗。
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
<button id="alert">alert</button>
<button id="confirm">confirm</button>
<button id="prompt">prompt</button>
<script type="text/javascript">
const dom1 = document.getElementById("alert")
dom1.addEventListener('click', function(){
alert("alert hello")
})
const dom2 = document.getElementById("confirm")
dom2.addEventListener('click', function(){
confirm("confirm hello")
})
const dom3 = document.getElementById("prompt")
dom3.addEventListener('click', function(){
prompt("prompt hello")
})
</script>
</body>
</html>

下面使用上面的方法進行測試。為了防止彈窗操作過快,每次操作彈窗,都使用 sleep 強制等待一段時間。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Firefox()
driver.get('file:///' + str(Path(Path.cwd(), '彈窗.html')))
sleep(2)
# 點選alert按鈕
driver.find_element_by_xpath('//*[@id="alert"]').click()
sleep(1)
alert = driver.switch_to.alert
# 列印alert彈窗的文字
print(alert.text)
# 確認
alert.accept()
sleep(2)
# 點選confirm按鈕
driver.find_element_by_xpath('//*[@id="confirm"]').click()
sleep(1)
confirm = driver.switch_to.alert
print(confirm.text)
# 取消
confirm.dismiss()
sleep(2)
# 點選confirm按鈕
driver.find_element_by_xpath('//*[@id="prompt"]').click()
sleep(1)
prompt = driver.switch_to.alert
print(prompt.text)
# 向prompt的輸入框中傳入文字
prompt.send_keys("Dream丶Killer")
sleep(2)
prompt.accept()
'''輸出
alert hello
confirm hello
prompt hello
'''

注:細心地讀者應該會發現這次操作的瀏覽器是
Firefox,為什麼不用Chrome呢?原因是測試時發現執行prompt的send_keys時,不能將文字填入輸入框。嘗試了各種方法並檢視原始碼後確認不是程式碼的問題,之後通過其他渠道得知原因可能是Chrome的版本與selenium版本的問題,但也沒有很方便的解決方案,因此沒有繼續深究,改用Firefox可成功執行。這裡記錄一下我的Chrome版本,如果有大佬懂得如何在Chrome上解決這個問題,請在評論區指導一下,提前感謝!
selenium:3.141.0
Chrome:94.0.4606.71

上傳 & 下載檔案
上傳檔案
常見的 web 頁面的上傳,一般使用 input 標籤或是外掛(JavaScript、Ajax),對於 input 標籤的上傳,可以直接使用 send_keys(路徑) 來進行上傳。
先寫一個測試用的頁面。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<input type="file" name="">
</body>
</html>

下面通過 xpath 定位 input 標籤,然後使用 send_keys(str(file_path) 上傳檔案。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Chrome()
file_path = Path(Path.cwd(), '上傳下載.html')
driver.get('file:///' + str(file_path))
driver.find_element_by_xpath('//*[@name="upload"]').send_keys(str(file_path))

下載檔案
Chrome瀏覽器
Firefox 瀏覽器要想實現檔案下載,需要通過 add_experimental_option 新增 prefs 引數。
download.default_directory:設定下載路徑。profile.default_content_settings.popups:0 禁止彈出視窗。
下面測試下載搜狗圖片。指定儲存路徑為程式碼所在路徑。
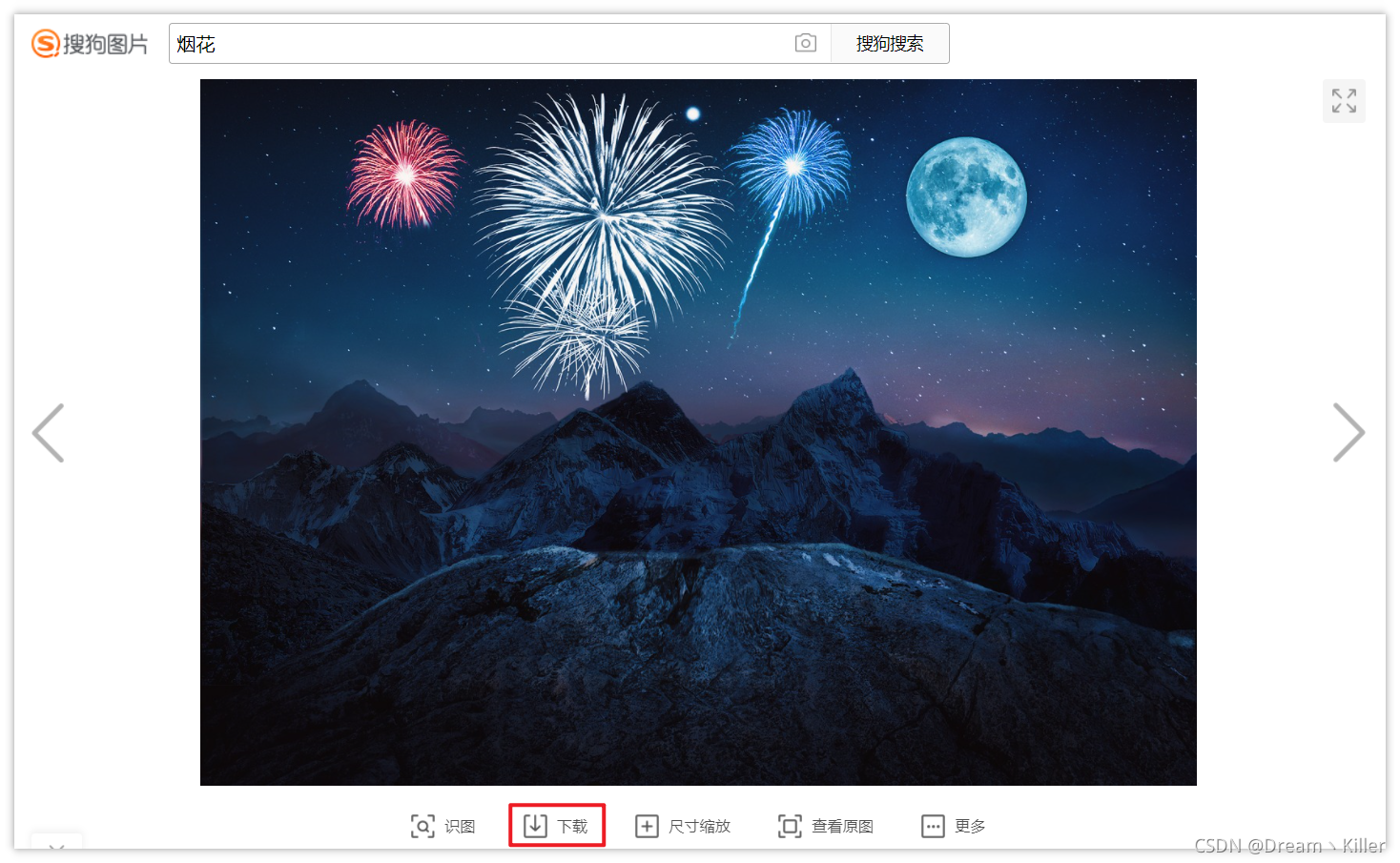
from selenium import webdriver
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory': str(Path.cwd())}
option = webdriver.ChromeOptions()
option.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(options=option)
driver.get("https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright")
driver.find_element_by_xpath('/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a').click()
driver.switch_to.window(driver.window_handles[-1])
driver.find_element_by_xpath('./html').send_keys('thisisunsafe')
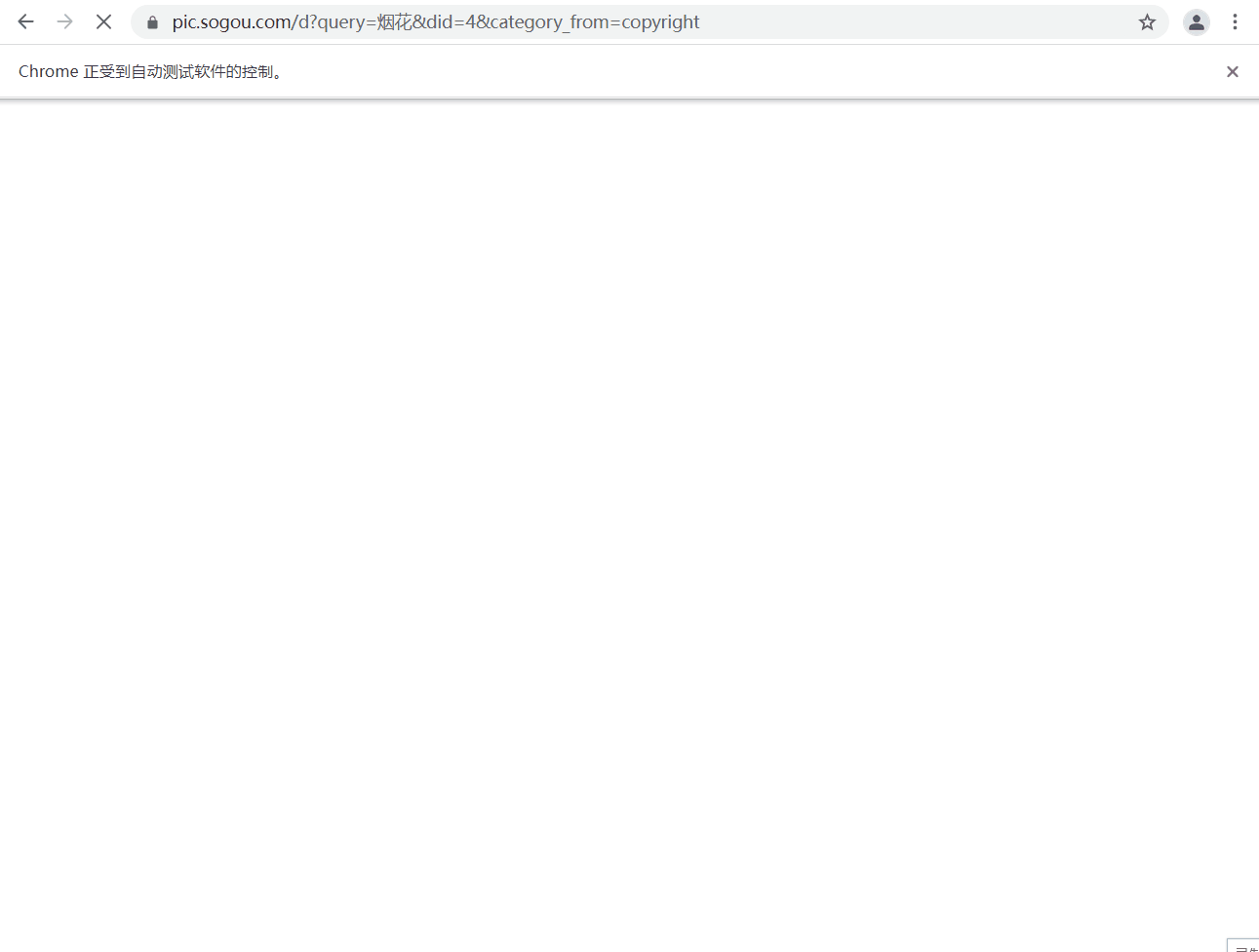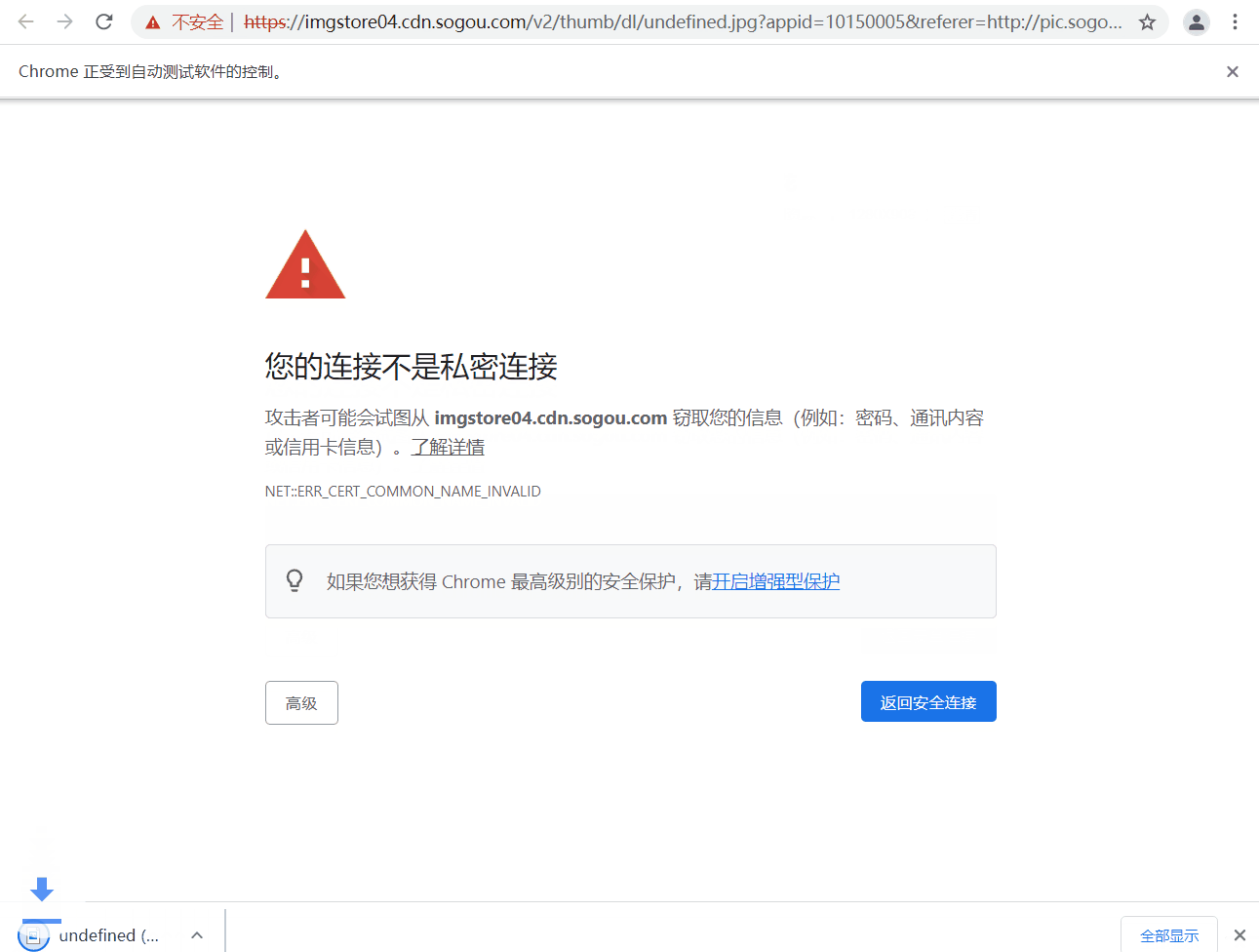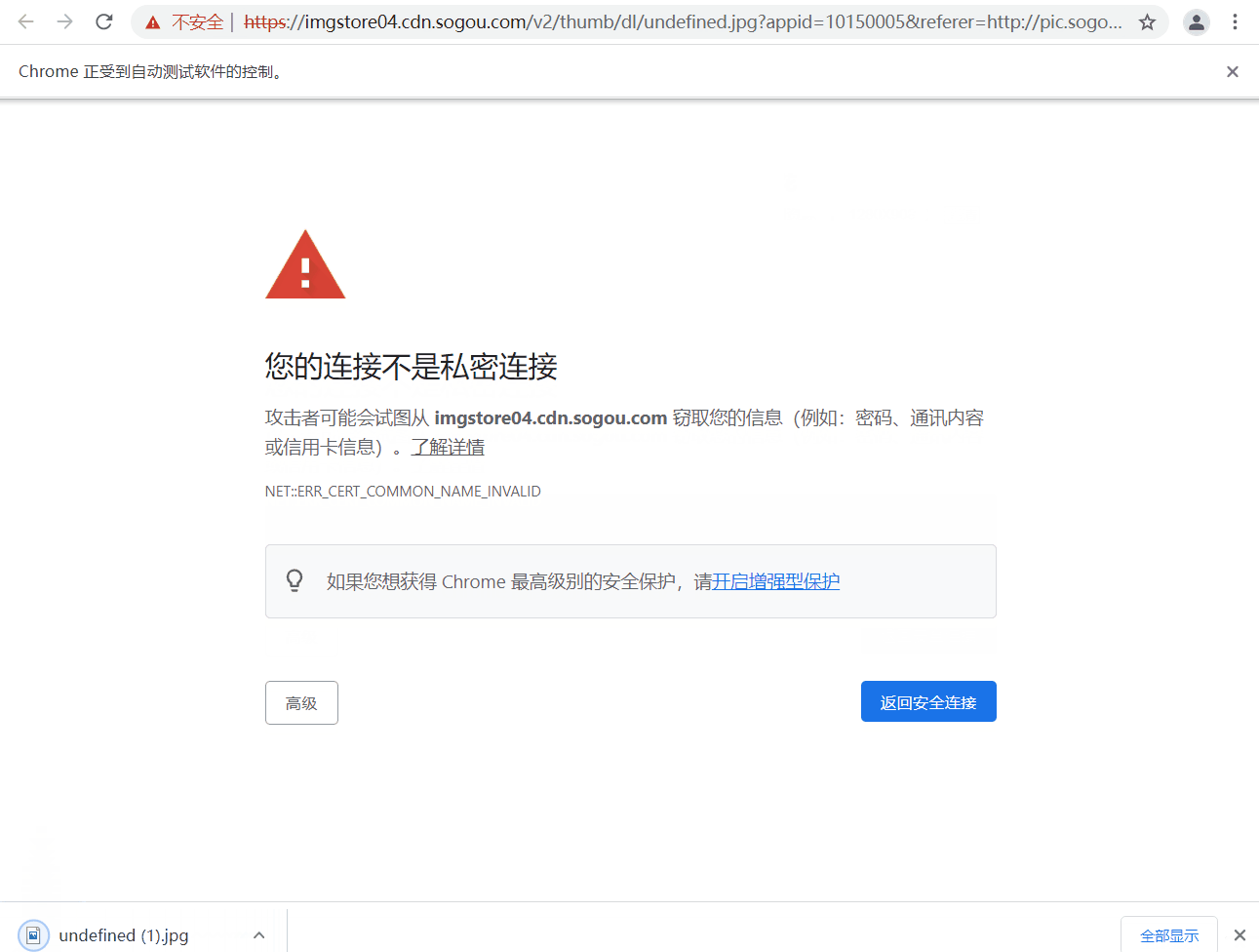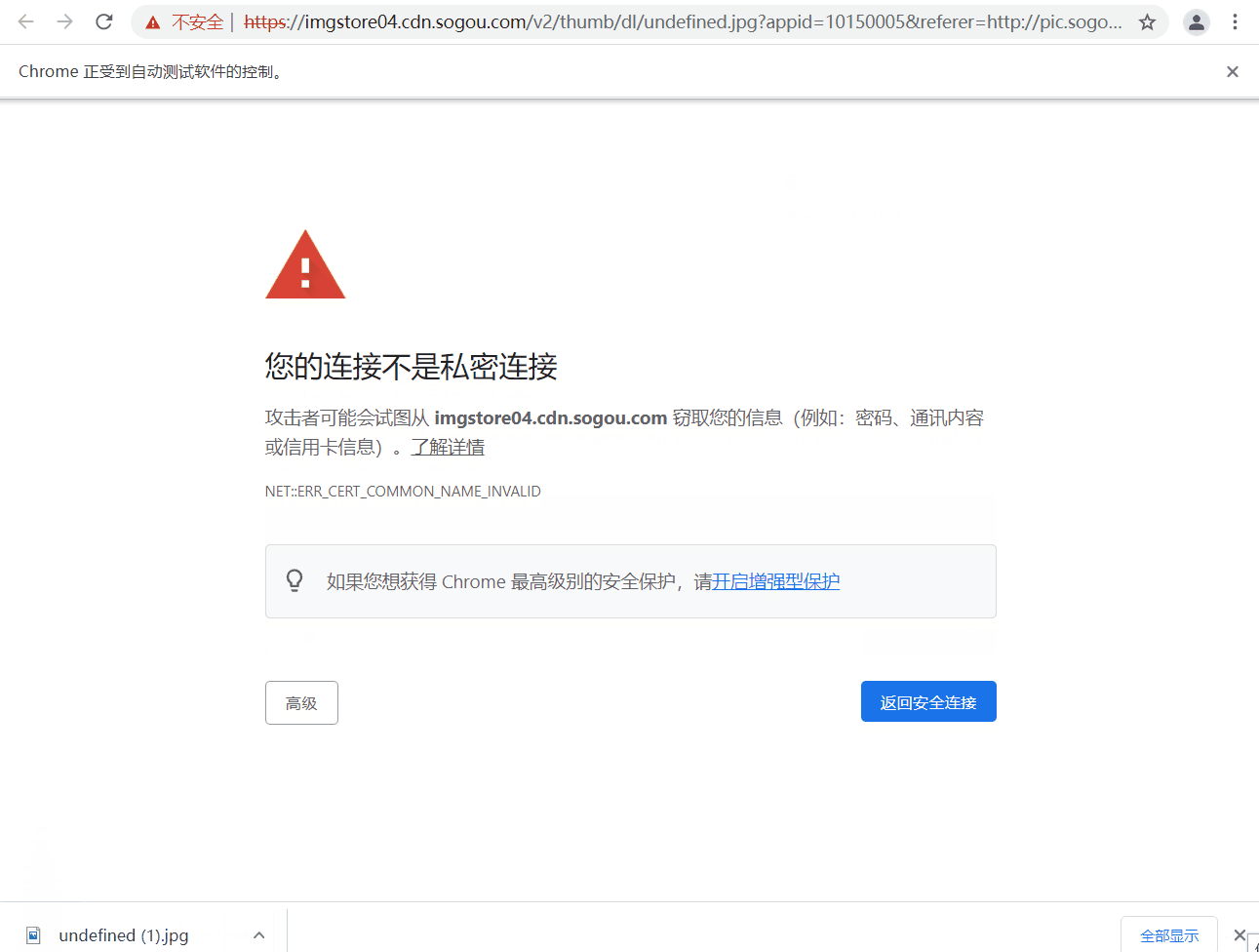
程式碼最後兩句猜測有理解什麼意思的嗎~,哈哈,實際作用是當你彈出像下面的頁面 「您的連線不是私密連線」 時,可以直接鍵盤輸入 「thisisunsafe」 直接存取連結。那麼這個鍵盤輸入字串的操作就是之間講到的
send_keys,但由於該分頁是新開啟的,所以要通過switch_to.window()將視窗切換到最新的分頁。
Firefox瀏覽器
Firefox 瀏覽器要想實現檔案下載,需要通過 set_preference 設定 FirefoxProfile() 的一些屬性。
browser.download.foladerList:0 代表按瀏覽器預設下載路徑;2 儲存到指定的目錄。browser.download.dir:指定下載目錄。browser.download.manager.showWhenStarting:是否顯示開始,boolean型別。browser.helperApps.neverAsk.saveToDisk:對指定檔案型別不再彈出框進行詢問。- HTTP Content-type對照表:https://www.runoob.com/http/http-content-type.html
from selenium import webdriver
import os
fp = webdriver.FirefoxProfile()
fp.set_preference("browser.download.dir",os.getcwd())
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showhenStarting",True)
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/octet-stream")
driver = webdriver.Firefox(firefox_profile = fp)
driver.get("https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright")
driver.find_element_by_xpath('/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a').click()
執行效果與 Chrome 基本一致,這裡就不再展示了。
cookies操作
cookies 是識別使用者登入與否的關鍵,爬蟲中常常使用 selenium + requests 實現 cookie持久化,即先用 selenium 模擬登陸獲取 cookie ,再通過 requests 攜帶 cookie 進行請求。
webdriver 提供 cookies 的幾種操作:讀取、新增刪除。
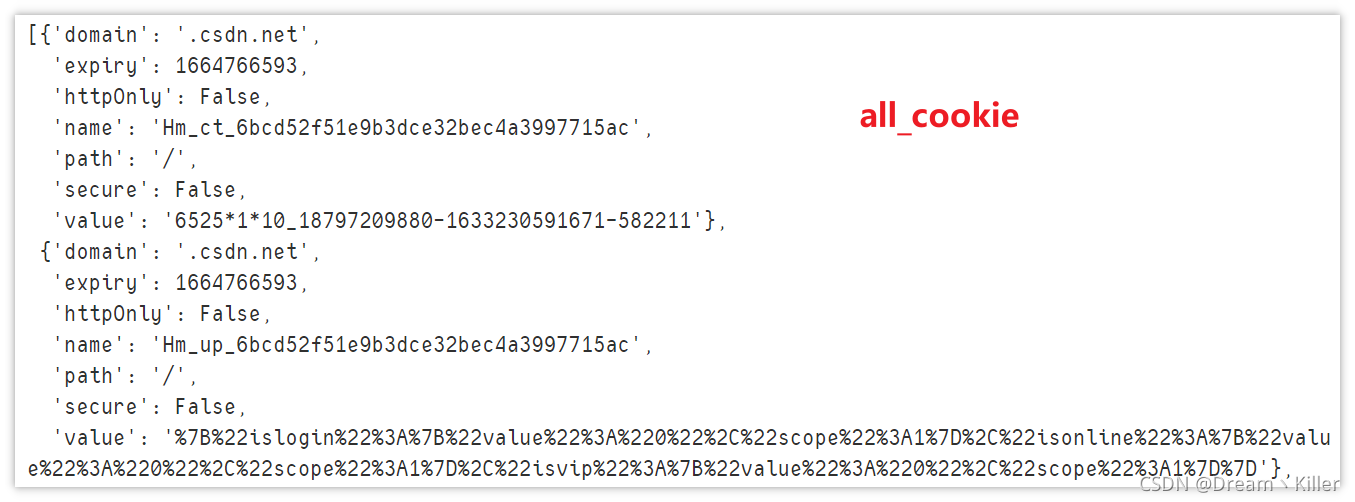
get_cookies:以字典的形式返回當前對談中可見的cookie資訊。get_cookie(name):返回cookie字典中key == name的cookie資訊。add_cookie(cookie_dict):將cookie新增到當前對談中delete_cookie(name):刪除指定名稱的單個cookie。delete_all_cookies():刪除對談範圍內的所有cookie。
下面看一下簡單的範例,演示了它們的用法。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/")
# 輸出所有cookie資訊
print(driver.get_cookies())
cookie_dict = {
'domain': '.csdn.net',
'expiry': 1664765502,
'httpOnly': False,
'name': 'test',
'path': '/',
'secure': True,
'value': 'null'}
# 新增cookie
driver.add_cookie(cookie_dict)
# 顯示 name = 'test' 的cookie資訊
print(driver.get_cookie('test'))
# 刪除 name = 'test' 的cookie資訊
driver.delete_cookie('test')
# 刪除當前對談中的所有cookie
driver.delete_all_cookies()

呼叫JavaScript
webdriver 對於卷軸的處理需要用到 JavaScript ,同時也可以向 textarea 文字方塊中輸入文字( webdriver 只能定位,不能輸入文字),webdriver 中使用execute_script方法實現 JavaScript 的執行。
滑動卷軸
通過 x ,y 座標滑動
對於這種通過座標滑動的方法,我們需要知道做表的起始位置在頁面左上角(0,0),下面看一下範例,滑動 CSDN 首頁。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/")
sleep(1)
js = "window.scrollTo(0,500);"
driver.execute_script(js)
通過參照標籤滑動
這種方式需要先找一個參照標籤,然後將卷軸滑動至該標籤的位置。下面還是用 CSDN 首頁做範例,我們用迴圈來實現重複滑動。該 li 標籤實際是一種懶載入,當使用者滑動至最後標籤時,才會載入後面的資料。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/")
sleep(1)
driver.implicitly_wait(3)
for i in range(31, 102, 10):
sleep(1)
target = driver.find_element_by_xpath(f'//*[@id="feedlist_id"]/li[{i}]')
driver.execute_script("arguments[0].scrollIntoView();", target)
其他操作
關閉所有頁面
使用 quit() 方法可以關閉所有視窗並退出驅動程式。
driver.quit()
關閉當前頁面
使用 close() 方法可以關閉當前頁面,使用時要注意 「當前頁面」 這四個字,當你關閉新開啟的頁面時,需要切換視窗才能操作新視窗並將它關閉。,下面看一個簡單的例子,這裡不切換視窗,看一下是否能夠關閉新開啟的頁面。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
driver.implicitly_wait(3)
# 點選進入新頁面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 切換視窗
# driver.switch_to.window(driver.window_handles[-1])
sleep(3)
driver.close()
可以看到,在不切換視窗時,driver 物件還是操作最開始的頁面。
對當前頁面進行截圖
wendriver 中使用 get_screenshot_as_file() 對 「當前頁面」 進行截圖,這裡和上面的 close() 方法一樣,對於新視窗的操作,一定要切換視窗,不然截的還是原頁面的圖。對頁面截圖這一功能,主要用在我們測試時記錄報錯頁面的,我們可以將 try except 結合 get_screenshot_as_file() 一起使用來實現這一效果。
try:
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
except:
driver.get_screenshot_as_file(r'C:\Users\pc\Desktop\screenshot.png')
selenium進階
selenium隱藏指紋特徵
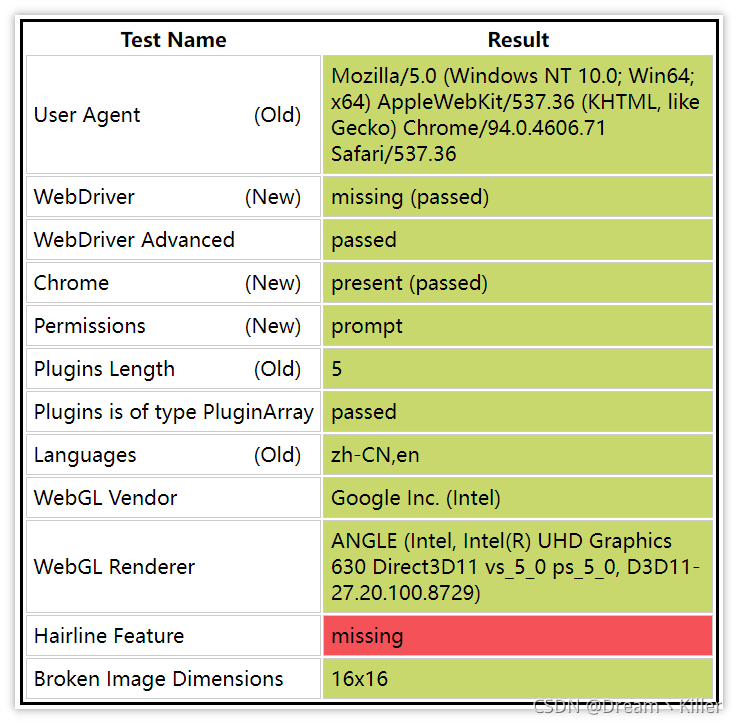
selenium 對於部分網站來說十分強大,但它也不是萬能的,實際上,selenium 啟動的瀏覽器,有幾十個特徵可以被網站檢測到,輕鬆的識別出你是爬蟲。
不相信?接著往下看,首先你手動開啟瀏覽器輸入https://bot.sannysoft.com/,在網路無異常的情況下,顯示應該如下:
下面通過 selenium 來開啟瀏覽器。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://bot.sannysoft.com/')
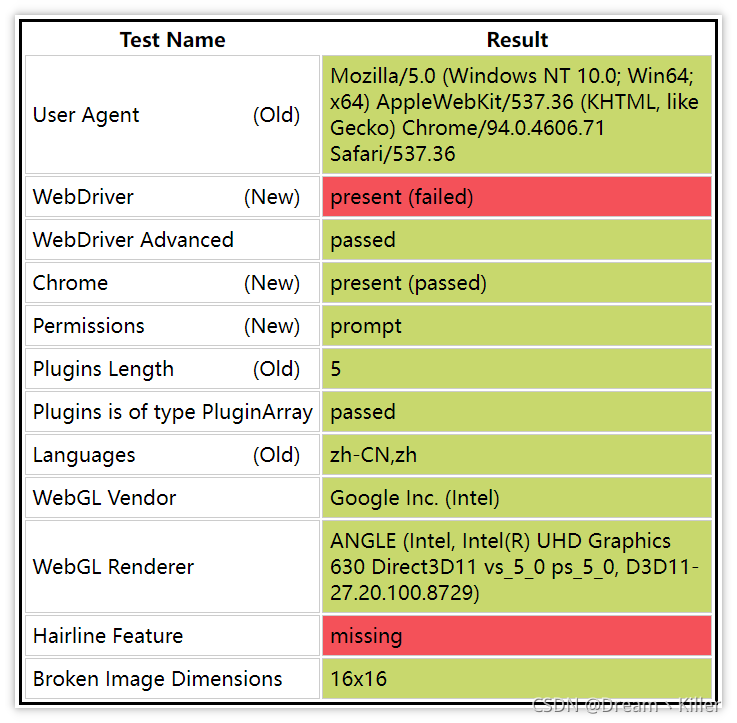
通過 webdriver:present 可以看到瀏覽器已經識別出了你是爬蟲,我們再試一下無頭瀏覽器。
from selenium import webdriver
# 設定無頭瀏覽器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome()
driver.get('https://bot.sannysoft.com/')
# 對當前頁面進行截圖
driver.save_screenshot('page.png')

沒錯,就是這麼真實,對於常規網站可能沒什麼反爬,但真正想要抓你還是一抓一個準的。
說了這麼多,是不是 selenium 真的不行?彆著急,實際還是解決方法的。關鍵點在於如何在瀏覽器檢測之前將這些特徵進行隱藏,事實上,前人已經為我們鋪好了路,解決這個問題的關鍵,實際就是一個 stealth.min.js 檔案,這個檔案是給 puppeteer 用的,在 Python 中使用的話需要單獨執行這個檔案,該檔案獲取方式需要安裝 node.js ,如果已安裝的讀者可以直接執行如下命令即可在當前目錄生成該檔案。
npx extract-stealth-evasions
這裡我已經成功獲取了 stealth.min.js 檔案。
連結:https://pan.baidu.com/s/1O6co1Exa8eks6QmKAst91g
提取碼:關注文末小卡片回覆「隱藏指紋特徵」獲取
下面我們在網站檢測之前先執行該js檔案隱藏特徵,同樣使用無頭瀏覽器,看是否有效。
import time
from selenium.webdriver import Chrome
option = webdriver.ChromeOptions()
option.add_argument("--headless")
# 無頭瀏覽器需要新增user-agent來隱藏特徵
option.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36')
driver = Chrome(options=option)
driver.implicitly_wait(5)
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://bot.sannysoft.com/')
driver.save_screenshot('hidden_features.png')
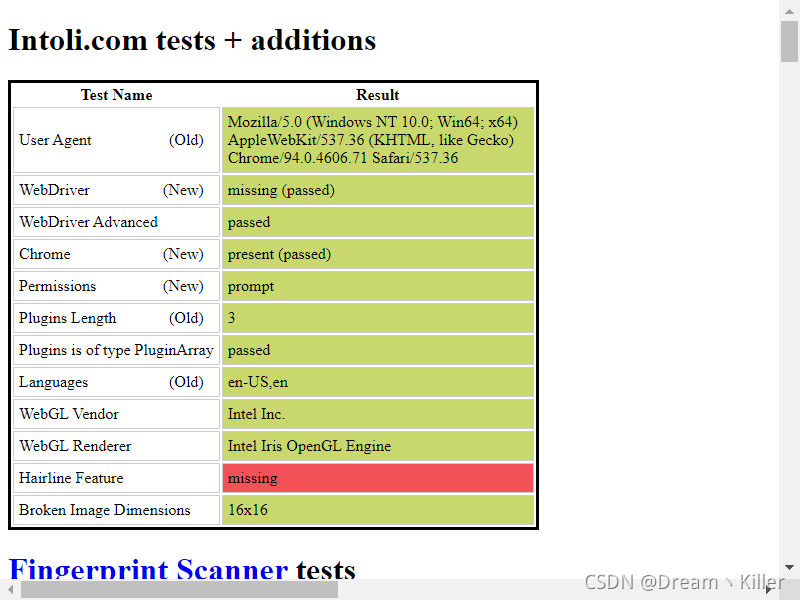
通過 stealth.min.js 的隱藏,可以看到這次使用無頭瀏覽器特徵基本都以隱藏,已經十分接近人工開啟瀏覽器了。
實戰:selenium模擬登入B站
登入驗證碼處理
selenium 中的難點驗證碼破解在上文中並沒有提及,因為確實沒有很好的方式,一般都需要通過第三方平臺實現破解,本案例中使用的是超級鷹平臺(收費,大概1元30次,測試用衝個1元就足夠)。下面實戰開始!
分析登入介面結構
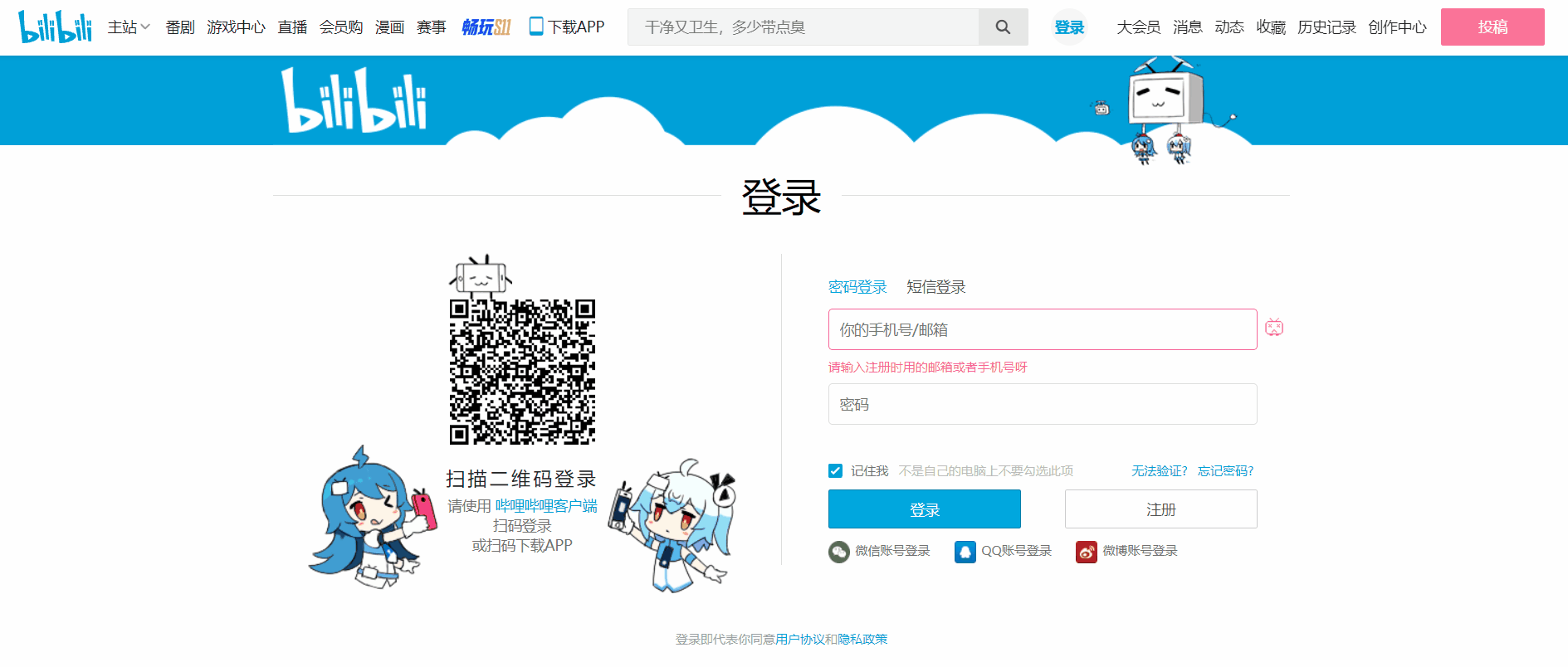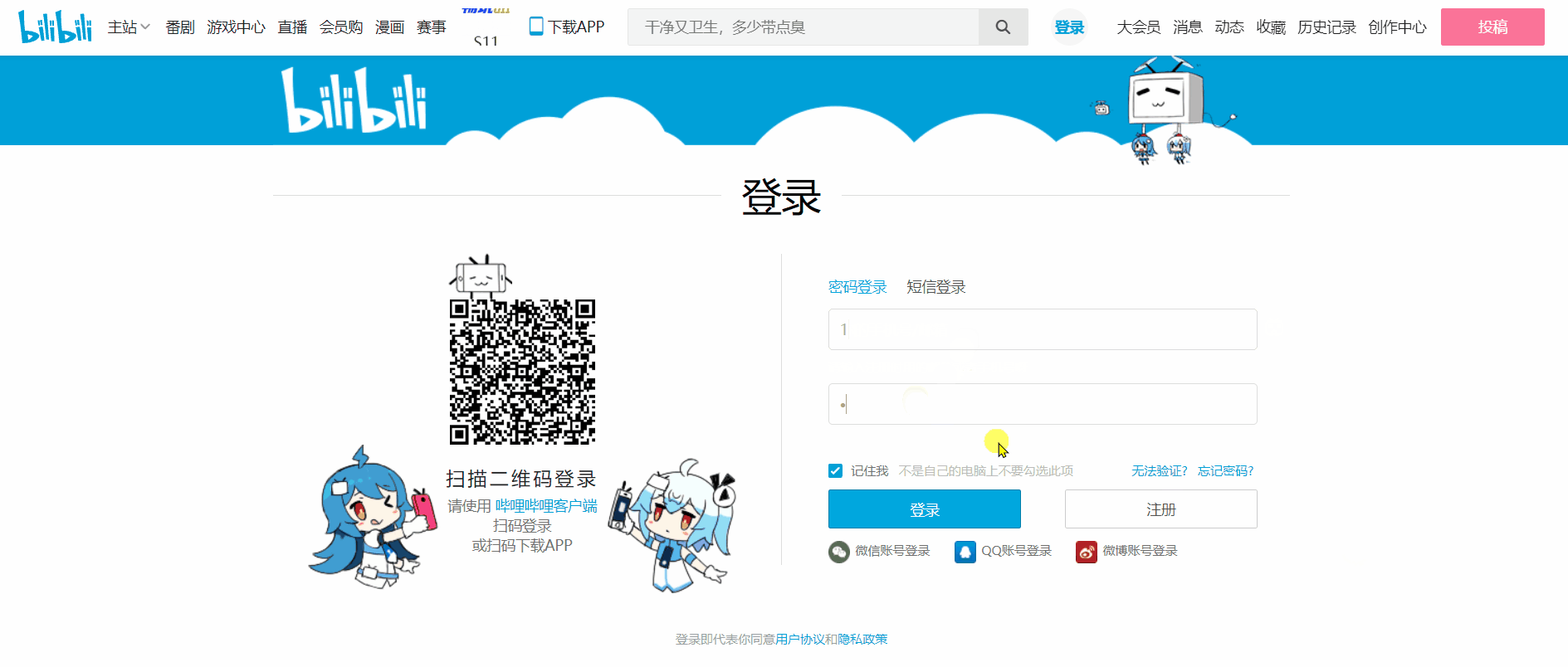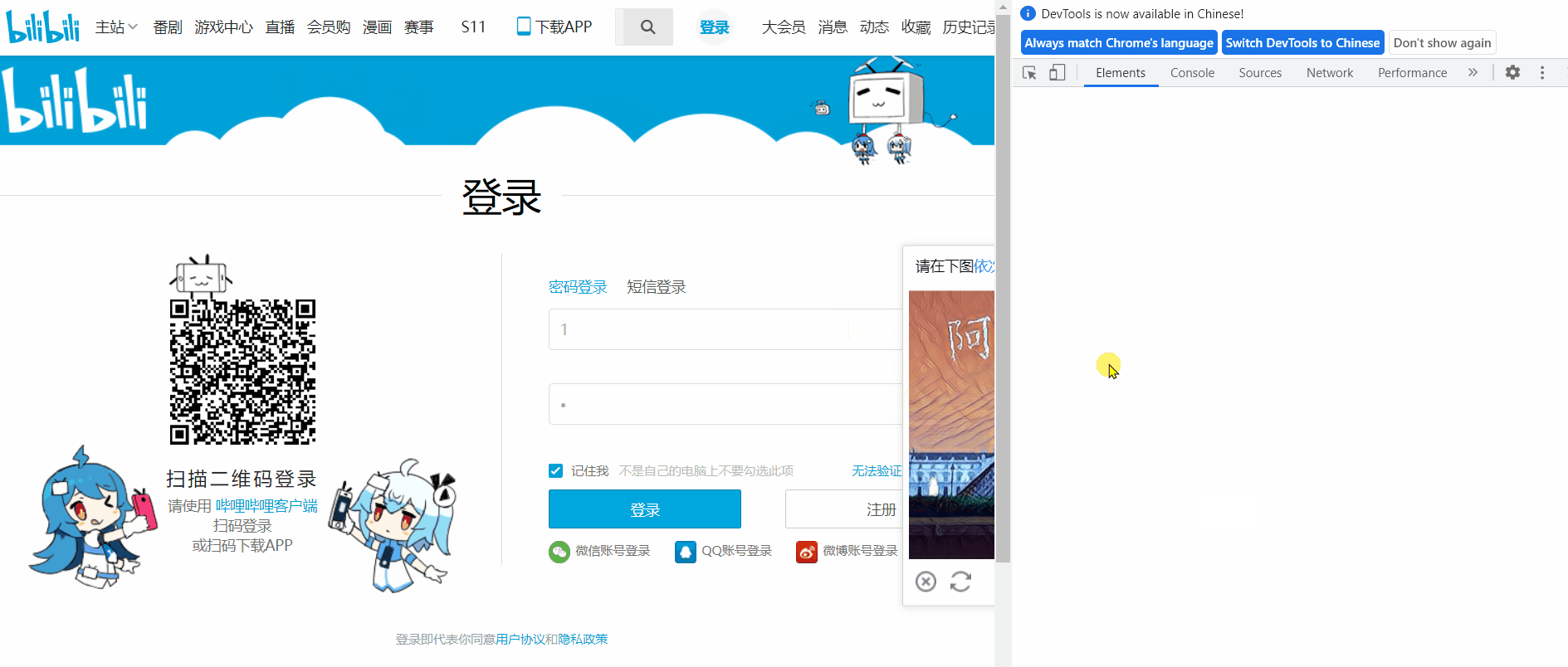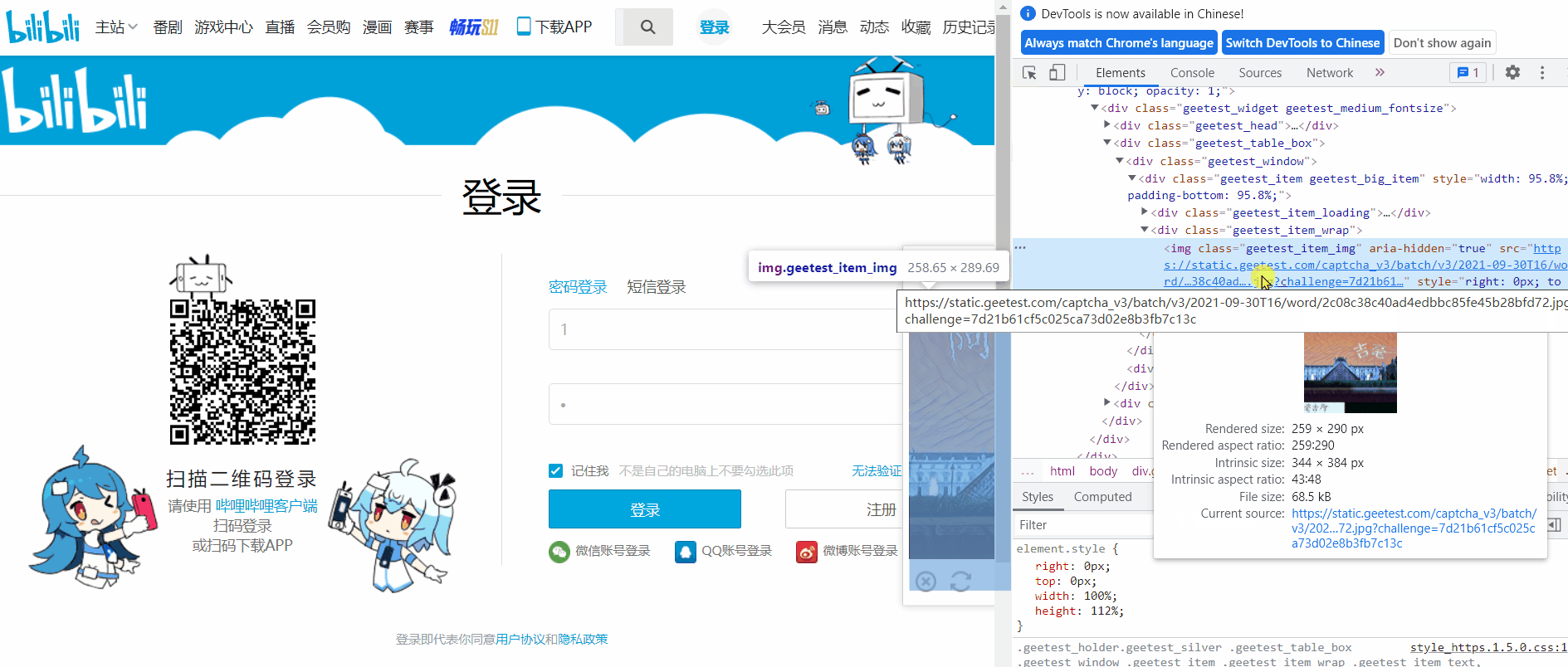
B站登入介面如下。
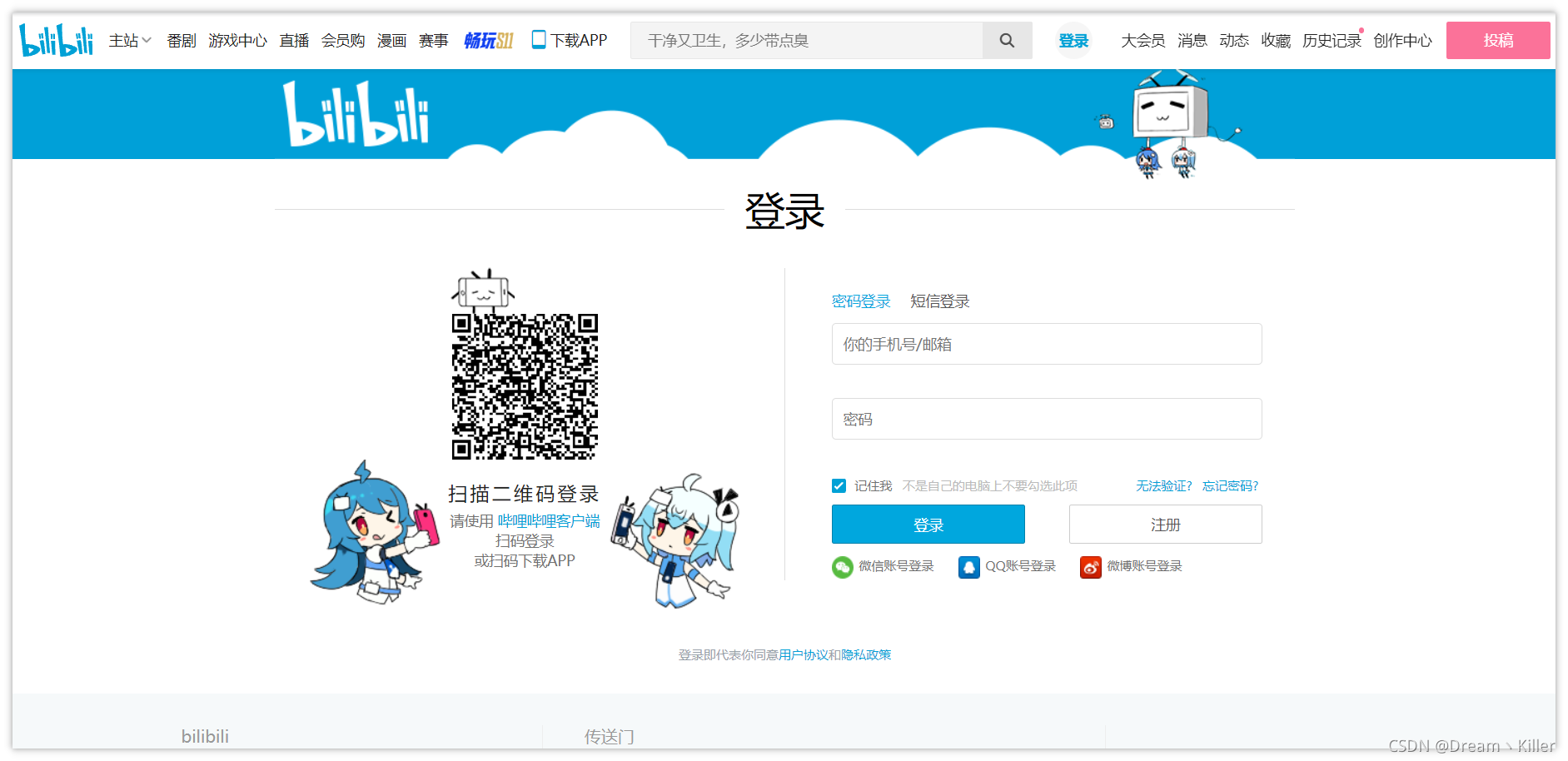
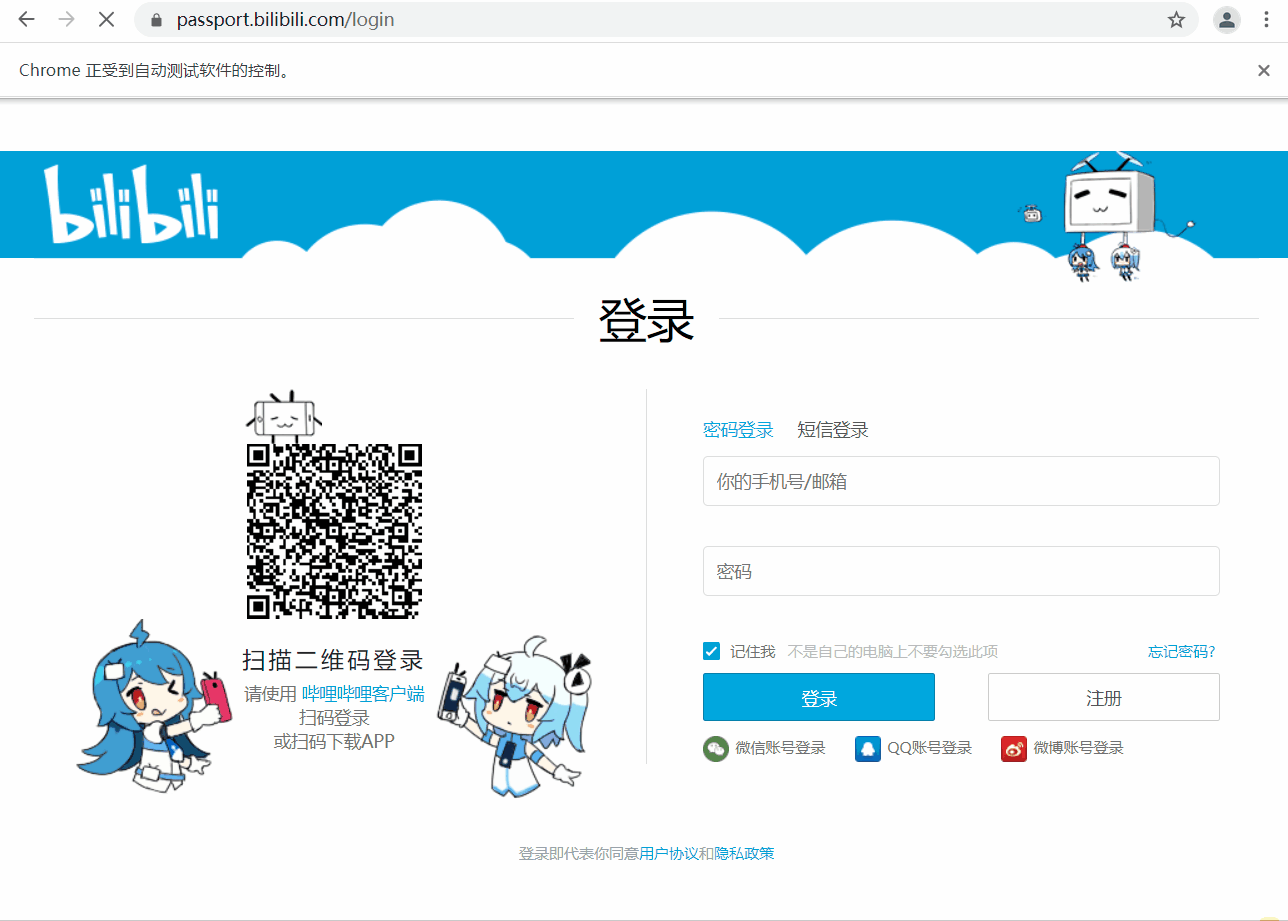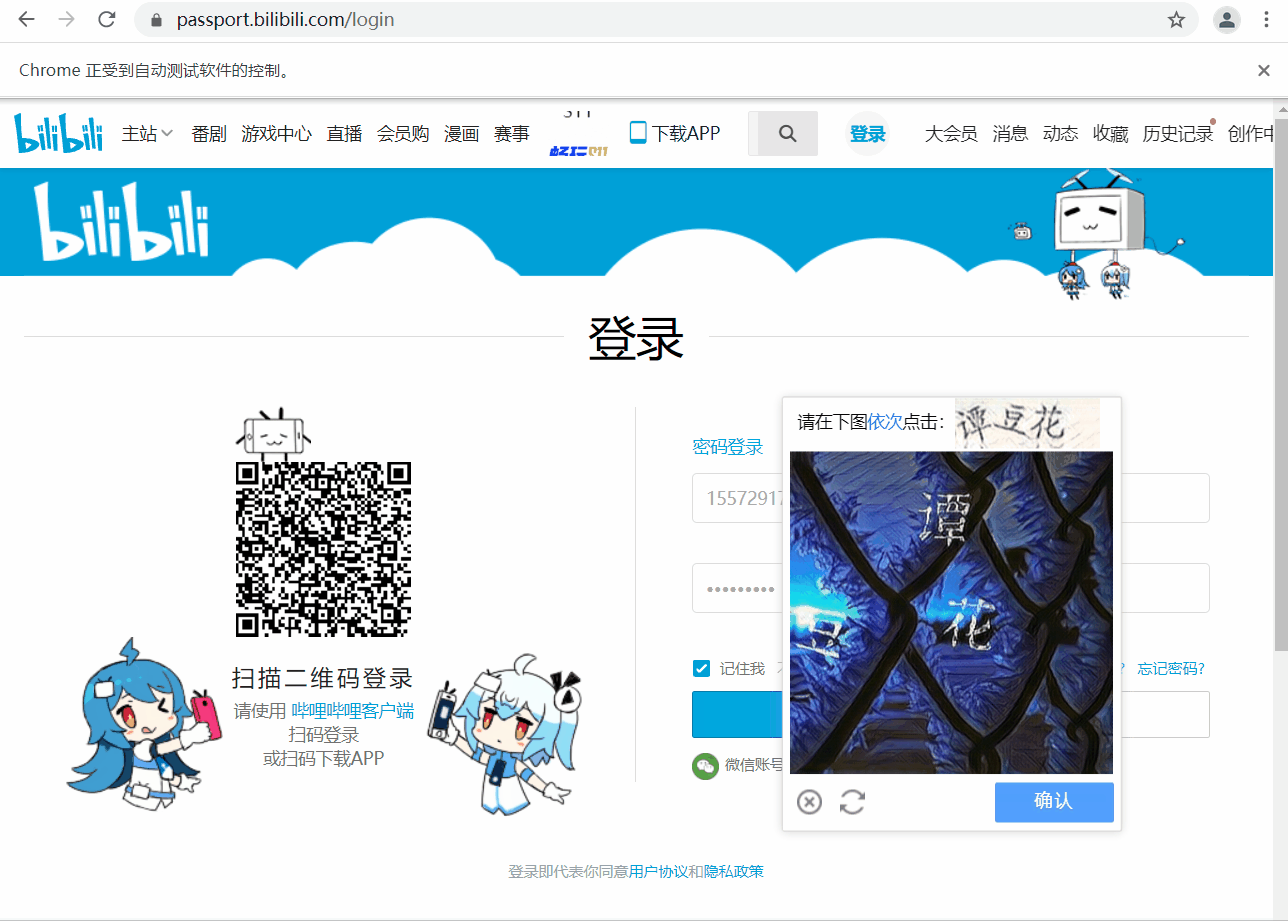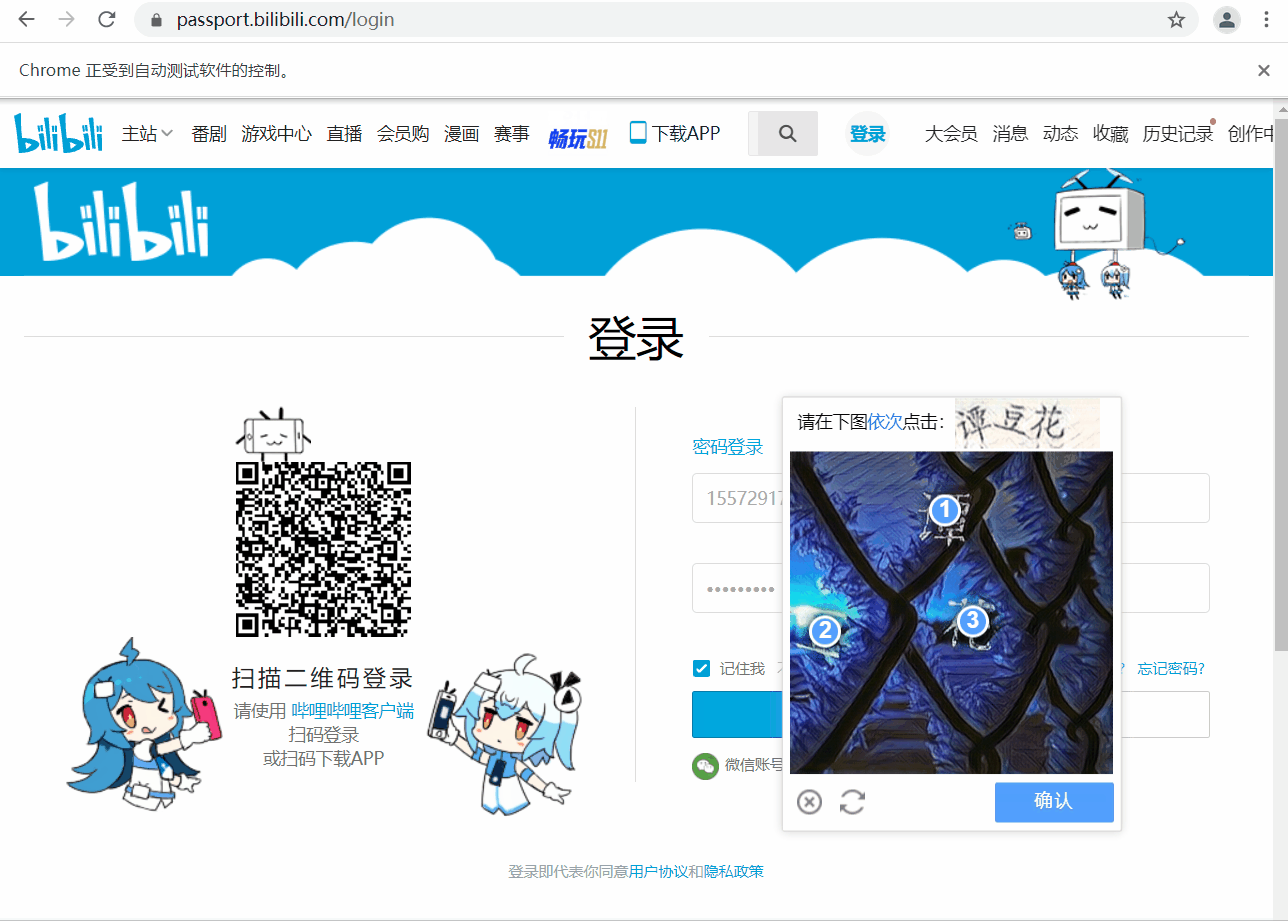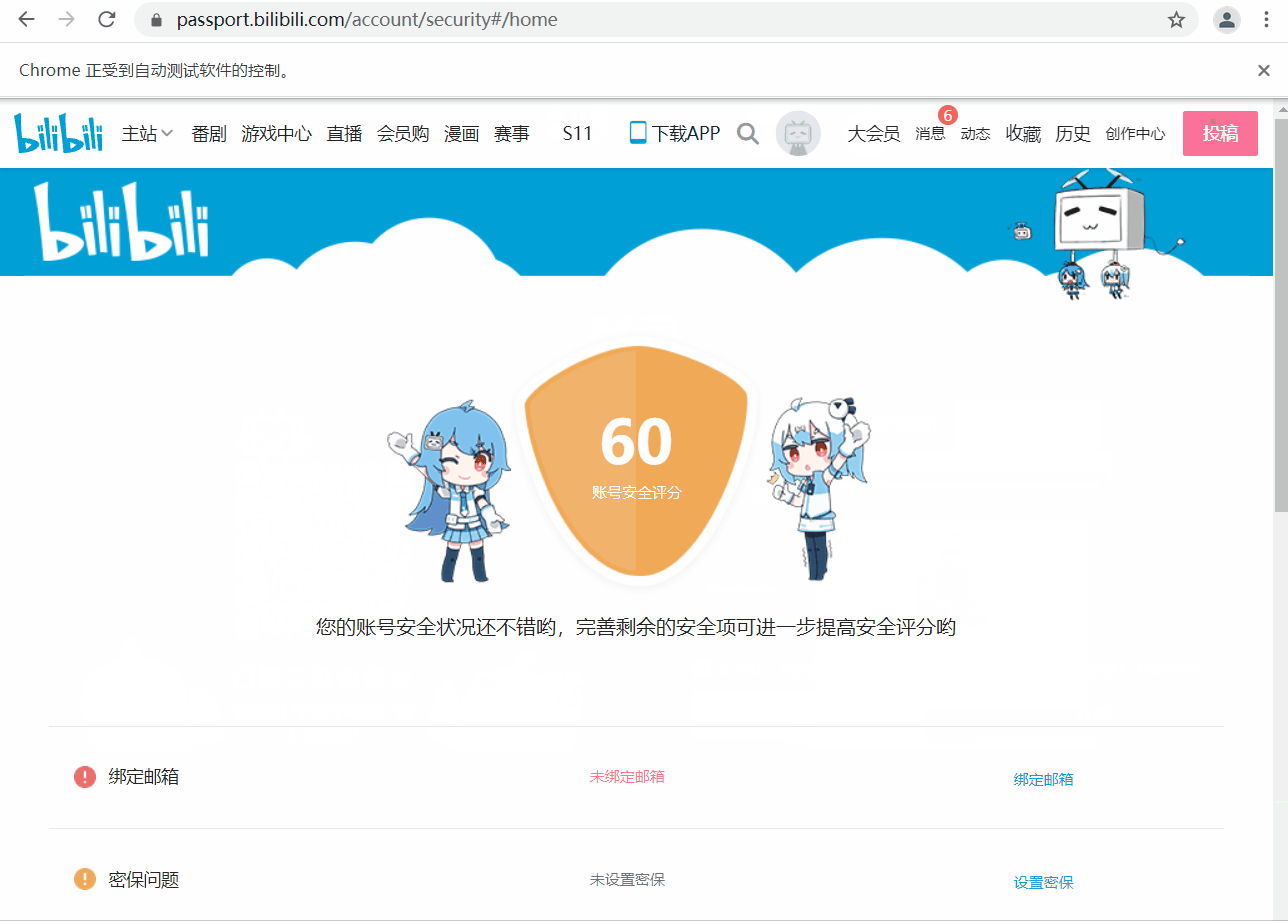
首先明確我們的目標,開啟登陸介面,定位使用者名稱和密碼對應的標籤,輸入相關資料後,點選登入,此時頁面會彈出文字驗證碼。
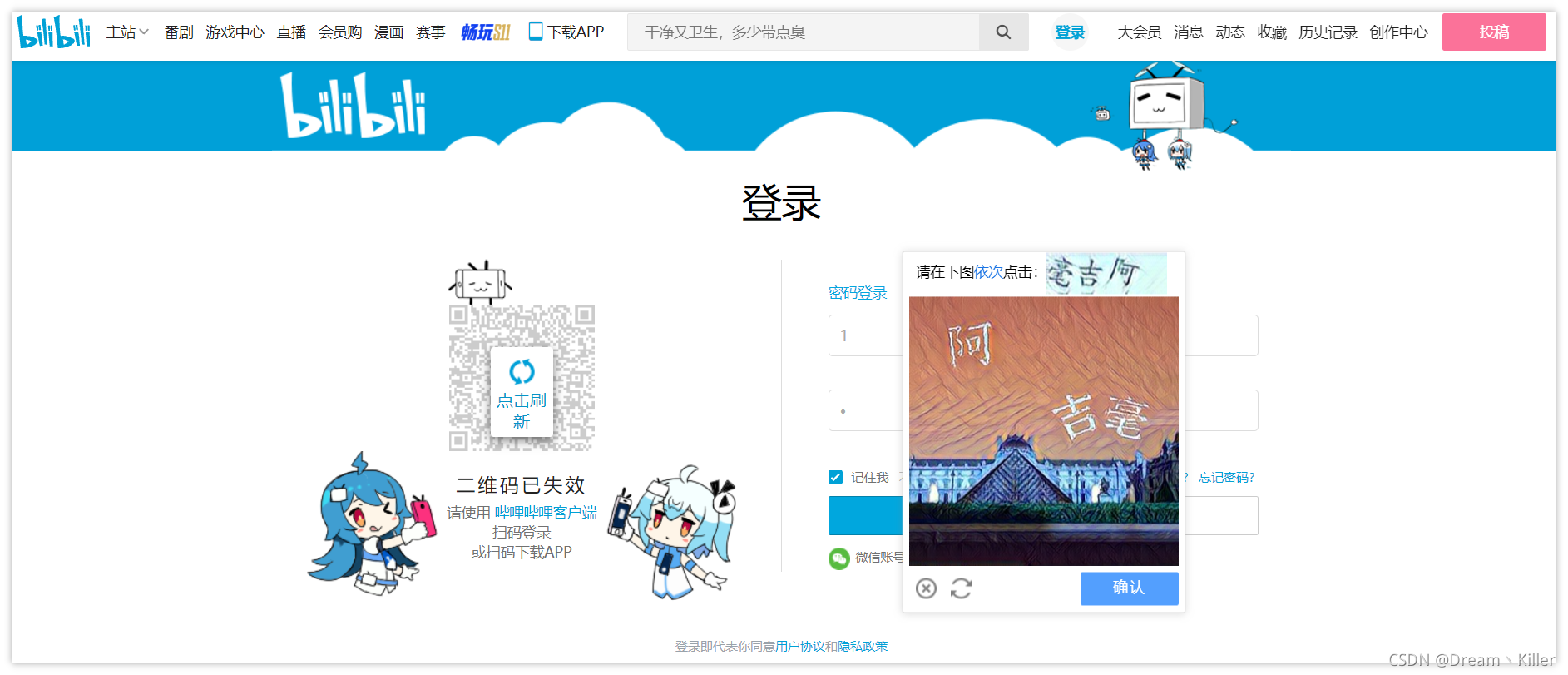
下文會用兩種方法進行驗證碼圖片的獲取,並提交給超級鷹進行識別,接收到漢字的座標後,處理座標資料,然後用動作鏈點選對應座標操作,完成登入。
下面使用 selenium 開啟登入頁面。
driver.get('https://passport.bilibili.com/login')
# 定位使用者名稱,密碼輸入框
username = driver.find_element_by_id('login-username')
password = driver.find_element_by_id('login-passwd')
# 將自己的使用者名稱密碼替換xxxxxx
username.send_keys('xxxxxx')
password.send_keys('xxxxxx')
# 定位登入按鈕並點選
driver.find_element_by_xpath('//*[@id="geetest-wrap"]/div/div[5]/a[1]').click()
獲取頁面當前驗證碼圖片
方法一、頁面截圖,將驗證碼區域進行裁剪儲存
使用此方法時,注意我們擷取驗證碼圖片時需要擷取完整,不要只截圖片部分,上面文字也需要。完整驗證碼截圖如下:
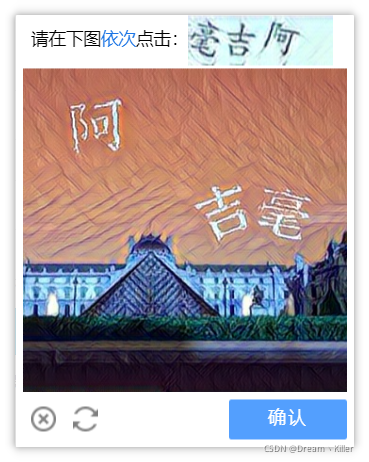
首先將點選登入後的頁面進行截圖,然後定位到驗證碼的位置,通過location()方法獲取驗證碼左上角的座標, size() 獲取驗證碼的寬和高,左上角座標加上寬和高就是驗證碼右下角的座標。獲取座標後就可以用**crop()**方法來進行裁剪,然後將裁剪到的驗證碼圖片儲存。
此時雖然獲取了驗證碼圖片,但是還不能直接提交給超級鷹。
因為超級鷹識別的驗證碼圖片的寬和高有限制,最好不超過 460px,310px。
但是擷取到的驗證碼圖片寬高為 338px,432px,這時就要先將圖片縮小一倍再提交即可,等到收到座標資料再將座標乘2。
def save_img():
# 對當前頁面進行截圖儲存
driver.save_screenshot('page.png')
# 定位驗證碼圖片的位置
code_img_ele = driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div')
# 獲取驗證碼左上角的座標x,y
location = code_img_ele.location
# 獲取驗證碼圖片對應的長和寬
size = code_img_ele.size
# 左上角和右下角的座標
rangle = (
int(location['x'] * 1.25), int(location['y'] * 1.25), int((location['x'] + size['width']) * 1.25),
int((location['y'] + size['height']) * 1.25)
)
i = Image.open('./page.png')
code_img_name = './code.png'
# crop根據rangle元組內的座標進行裁剪
frame = i.crop(rangle)
frame.save(code_img_name)
return code_img_ele
def narrow_img():
# 縮小圖片
code = Image.open('./code.png')
small_img = code.resize((169, 216))
small_img.save('./small_img.png')
print(code.size, small_img.size)
方法二、通過網頁獲取圖片地址,並儲存
這種方法比上一種更加方便,分析網頁原始碼獲取圖片地址,對該地址傳送請求,接收返回的二進位制檔案,進行儲存。首先開啟網頁原始碼找到圖片地址。
圖片地址是 img 標籤的 src 屬性值,通過 xpath 得到地址,直接對此 url 傳送請求,接收資料並儲存即可。
注意:由於獲取的圖片的高度仍然大於超級鷹標準格式,所以也需要將圖片縮小。
# 獲取img標籤的src屬性值
img_url = driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[2]/div[1]/div/div[2]/img').get_attribute('src')
headers = {
'Users-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
# 獲取圖片二進位制資料
img_data = requests.get(url=img_url, headers=headers).content
with open('./node1.png', 'wb')as fp:
fp.write(img_data)
i = Image.open('./node1.png')
# 將圖片縮小並儲存,設定寬為172,高為192
small_img = i.resize((172, 192))
small_img.save('./small_img1.png')
使用超級鷹識別驗證碼
這部分沒什麼說的,直接呼叫就行。
# 將驗證碼提交給超級鷹進行識別
chaojiying = Chaojiying_Client('使用者名稱', '密碼', '96001') # 使用者中心>>軟體ID 生成一個替換 96001
im = open('small_img.png', 'rb').read() # 本地圖片檔案路徑 來替換 a.jpg 有時WIN系統須要//
# 9004是驗證碼型別
print(chaojiying.PostPic(im, 9004)['pic_str'])
result = chaojiying.PostPic(im, 9004)['pic_str']
提取座標資料,動作鏈點選
超級鷹識別返回的資料格式是:123,12 | 234,21 。我們可以將資料以 ' | ' 進行分割,儲存到列表中,再以逗號分割將 x,y 的座標儲存,得到 [ [123,12],[234,21] ] 這一格式,然後遍歷這一列表,使用動作鏈對每一個列表元素對應的 x,y 指定的位置進行點選操作,最後定位並點選確認,登入成功。
all_list = [] # 要儲存即將被點選的點的座標 [[x1,y1],[x2,y2]]
if '|' in result:
list_1 = result.split('|')
count_1 = len(list_1)
for i in range(count_1):
xy_list = []
x = int(list_1[i].split(',')[0])
y = int(list_1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else:
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_list = []
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
# 遍歷列表,使用動作鏈對每一個列表元素對應的x,y指定的位置進行點選操作
# x,y座標乘2和0.8,是由於
for l in all_list:
x = l[0] * 2 * 0.8
y = l[1] * 2 * 0.8
# 將點選操作的參照物移動到指定的模組,
# 若用方法二獲取的驗證碼圖片,要新增下面程式碼對code_img_ele賦值
# code_img_ele = bro.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[2]/div[1]/div/div[2]/img')
ActionChains(driver).move_to_element_with_offset(code_img_ele, x, y).click().perform()
print('點選已完成')
# 完成動作鏈點選操作後,定位確認按鈕並點選
driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[3]/a').click()
執行效果
由於驗證碼處理需要用到第三方平臺,外加設定了強制等待,整體執行速度較慢。
❤️原始碼獲取❤️
對於剛入門 Python 或是想要入門 Python 的小夥伴,可以通過下方小卡片聯絡作者,一起交流學習,都是從新手走過來的,有時候一個簡單的問題卡很久,但可能別人的一點撥就會恍然大悟,由衷的希望大家能夠共同進步。