你真的瞭解http,https嗎?萬字長文帶你深入瞭解http!

目錄
HTTP

HTTP協定簡介
HTTP協定(超文字傳輸協定HyperText Transfer Protocol),它是基於TCP協定的應用層傳輸協定,簡單來說就是使用者端和伺服器端進行資料傳輸的一種規則。
注意: 使用者端與伺服器的角色不是固定的,一端充當使用者端,也可能在某次請求中充當伺服器。這取決與請求的發起端。HTTP協定屬於應用層,建立在傳輸層協定TCP之上。使用者端通過與伺服器建立TCP連線,之後傳送HTTP請求與接收HTTP響應都是通過存取Socket介面來呼叫TCP協定實現。
HTTP是一種無狀態 (stateless) 協定, HTTP協定本身不會對傳送過的請求和相應的通訊狀態進行持久化處理。這樣做的目的是為了保持HTTP協定的簡單性,從而能夠快速處理大量的事務, 提高效率。
協定
- 協定規定了通訊雙方必須遵循的資料傳輸格式,這樣通訊雙方按照約定的格式才能準確的通訊。
無狀態
- 無狀態是指兩次連線通訊之間是沒有任何關係的,每次都是一個新的連線,伺服器端不會記錄前後的請求資訊。
使用者端/伺服器端模型
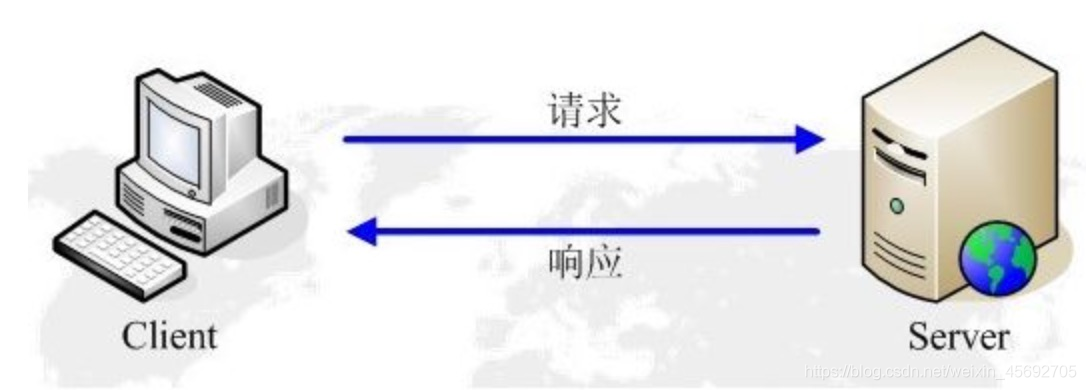
七層網路模型
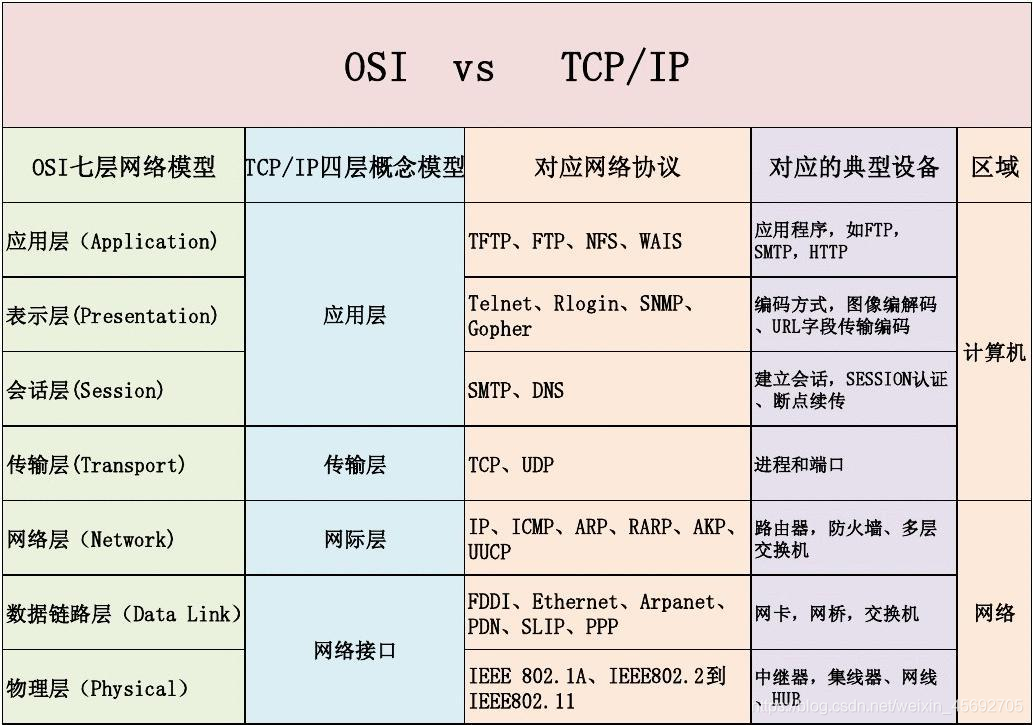
HTTP工作原理
- HTTP協定定義Web使用者端如何從Web伺服器請求Web頁面,以及伺服器如何把Web頁面傳送給使用者端。HTTP協定採用了請求/響應模型。使用者端向伺服器傳送一個請求報文,請求報文包含請求的方法、URL、協定版本、請求頭部和請求資料。伺服器以一個狀態行作為響應,響應的內容包括協定的版本、成功或者錯誤程式碼、伺服器資訊、響應頭部和響應資料。
以下是 HTTP 請求/響應的步驟:
-
使用者端連線到Web伺服器:一個HTTP使用者端,通常是瀏覽器,與Web伺服器的HTTP埠(預設為80)建立一個TCP通訊端連線。例如,http://www.baidu.com。
-
傳送HTTP請求:通過TCP通訊端,使用者端向Web伺服器傳送一個文字的請求報文,一個請求報文由請求行、請求頭部、空行和請求資料4部分組成。
-
伺服器接受請求並返回HTTP響應:Web伺服器解析請求,定位請求資源。伺服器將資源複本寫到TCP通訊端,由使用者端讀取。一個響應由狀態行、響應頭部、空行和響應資料4部分組成。
-
釋放連線TCP連線:若connection 模式為close,則伺服器主動關閉TCP連線,使用者端被動關閉連線,釋放TCP連線;若connection 模式為keepalive,則該連線會保持一段時間,在該時間內可以繼續接收請求;
-
使用者端瀏覽器解析HTML內容:使用者端瀏覽器首先解析狀態行,檢視表明請求是否成功的狀態程式碼。然後解析每一個響應頭,響應頭告知以下為若干位元組的HTML檔案和檔案的字元集。使用者端瀏覽器讀取響應資料HTML,根據HTML的語法對其進行格式化,並在瀏覽器視窗中顯示。
例如:在瀏覽器位址列鍵入URL,按下回車之後會經歷以下流程:
- 瀏覽器向 DNS 伺服器請求解析該 URL 中的域名所對應的 IP 地址;
- 解析出 IP 地址後,根據該 IP 地址和預設埠 80,和伺服器建立TCP連線;
- 瀏覽器發出讀取檔案(URL 中域名後面部分對應的檔案)的HTTP 請求,該請求報文作為 TCP 三次握手的第三個報文的資料傳送給伺服器;
- 伺服器對瀏覽器請求作出響應,並把對應的 html 文字傳送給瀏覽器;
- 釋放 TCP連線;
- 瀏覽器將該 html 文字並顯示內容;

http協定是基於TCP/IP協定之上的應用層協定。
基於 請求-響應 的模式
- HTTP協定規定,請求從使用者端發出,最後伺服器端響應該請求並 返回。換句話說,肯定是先從使用者端開始建立通訊的,伺服器端在沒有 接收到請求之前不會傳送響應。
無狀態儲存
- HTTP是一種不儲存狀態,即無狀態(stateless)協定。HTTP協定 自身不對請求和響應之間的通訊狀態進行儲存。也就是說在HTTP這個 級別,協定對於傳送過的請求或響應都不做持久化處理。
- 使用HTTP協定,每當有新的請求傳送時,就會有對應的新響應產 生。協定本身並不保留之前一切的請求或響應報文的資訊。這是為了更快地處理大量事務,確保協定的可伸縮性,而特意把HTTP協定設計成 如此簡單的。可是,隨著Web的不斷髮展,因無狀態而導致業務處理變得棘手 的情況增多了。比如,使用者登入到一家購物網站,即使他跳轉到該站的 其他頁面後,也需要能繼續保持登入狀態。針對這個範例,網站為了能 夠掌握是誰送出的請求,需要儲存使用者的狀態。HTTP/1.1雖然是無狀態協定,但為了實現期望的保持狀態功能, 於是引入了Cookie技術。有了Cookie再用HTTP協定通訊,就可以管 理狀態了。有關Cookie的詳細內容稍後講解。
無連線
- 無連線的含義是限制每次連線只處理一個請求。伺服器處理完客戶的請求,並收到客戶的應答後,即斷開連線。採用這種方式可以節省傳輸時間,並且可以提高並行效能,不能和每個使用者建立長久的連線,請求一次相應一次,伺服器端和使用者端就中斷了。但是無連線有兩種方式,早期的http協定是一個請求一個響應之後,直接就斷開了,但是現在的http協定1.1版本不是直接就斷開了,而是等幾秒鐘,這幾秒鐘是等什麼呢,等著使用者有後續的操作,如果使用者在這幾秒鐘之內有新的請求,那麼還是通過之前的連線通道來收發訊息,如果過了這幾秒鐘使用者沒有傳送新的請求,那麼就會斷開連線,這樣可以提高效率,減少短時間內建立連線的次數,因為建立連線也是耗時的,預設的好像是3秒中現在,但是這個時間是可以通過咱們後端的程式碼來調整的,自己網站根據自己網站使用者的行為來分析統計出一個最優的等待時間。
HTTP的五大特點
-
支援客戶/伺服器模式。
-
簡單快速:客戶向伺服器請求服務時,只需傳送請求方法和路徑。請求方法常用的有GET、HEAD、POST。每種方法規定了客戶與伺服器聯絡的型別不同。由於HTTP協定簡單,使得HTTP伺服器的程式規模小,因而通訊速度很快。
-
靈活:HTTP允許傳輸任意型別的資料物件。正在傳輸的型別由Content-Type加以標記。
-
無連線:無連線的含義是限制每次連線只處理一個請求。伺服器處理完客戶的請求,並收到客戶的應答後,即斷開連線。採用這種方式可以節省傳輸時間。早期這麼做的原因是請求資源少,追求快。後來通過
Connection: Keep-Alive實現長連線 -
無狀態:HTTP協定是無狀態協定。無狀態是指協定對於事務處理沒有記憶能力。缺少狀態意味著如果後續處理需要前面的資訊,則它必須重傳,這樣可能導致每次連線傳送的資料量增大。另一方面,在伺服器不需要先前資訊時它的應答就較快。
URI和URL的區別
URI,是uniform resource identifier,統一資源識別符號,用來唯一的標識一個資源。
- Web上可用的每種資源如HTML檔案、影象、視訊片段、程式等都是一個來URI來定位的
URI一般由三部組成:
- 存取資源的命名機制
- 存放資源的主機名
- 資源自身的名稱,由路徑表示,著重強調於資源。
URL是uniform resource locator,統一資源定位器,它是一種具體的URI,即URL可以用來標識一個資源,而且還指明瞭如何locate這個資源。
URL是Internet上用來描述資訊資源的字串,主要用在各種WWW客戶程式和伺服器程式上,特別是著名的Mosaic。
- 採用URL可以用一種統一的格式來描述各種資訊資源,包括檔案、伺服器的地址和目錄等。
URL一般由三部組成:
- 協定(或稱為服務方式)
- 存有該資源的主機IP地址(有時也包括埠號)
- 主機資源的具體地址。如目錄和檔名等
URN,uniform resource name,統一資源命名,是通過名字來標識資源,比如 mailto:java-net@java.sun.com。
-
URI是以一種抽象的,高層次概念定義統一資源標識,而URL和URN則是具體的資源標識的方式。URL和URN都是一種URI。籠統地說,每個 URL 都是 URI,但不一定每個 URI 都是 URL。這是因為 URI 還包括一個子類,即統一資源名稱 (URN),它命名資源但不指定如何定位資源。上面的 mailto、news 和 isbn URI 都是 URN 的範例。
-
在Java的URI中,一個URI範例可以代表絕對的,也可以是相對的,只要它符合URI的語法規則。而URL類則不僅符合語意,還包含了定位該資源的資訊,因此它不能是相對的。
-
在Java類庫中,URI類不包含任何存取資源的方法,它唯一的作用就是解析。
-
相反的是,URL類可以開啟一個到達資源的流。
URL
- HTTP使用統一資源識別符號(Uniform Resource Identifiers, URI)來傳輸資料和建立連線。URL是一種特殊型別的URI,包含了用於查詢某個資源的足夠的資訊。
URL構成
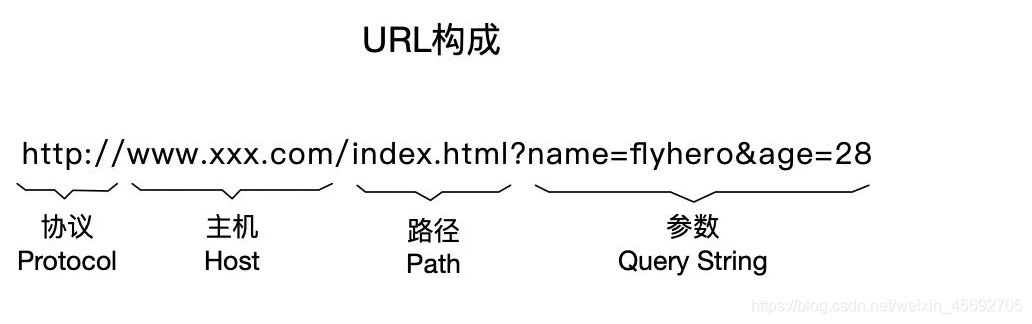
URL,全稱是UniformResourceLocator, 中文叫統一資源定位符,是網際網路上用來標識某一處資源的地址。以下面這個URL為例,介紹下普通URL的各部分組成:
從上面的URL可以看出,一個完整的URL包括以下幾部分:
-
協定部分:該URL的協定部分為「http:」,這代表網頁使用的是HTTP協定。在Internet中可以使用多種協定,如HTTP,FTP等等本例中使用的是HTTP協定。在"HTTP"後面的「//」為分隔符。
2.域名部分:該URL的域名部分為「www.aspxfans.com」。一個URL中,也可以使用IP地址作為域名使用 -
埠部分:跟在域名後面的是埠,域名和埠之間使用「:」作為分隔符。埠不是一個URL必須的部分,如果省略埠部分,將採用預設埠 (這裡的連結就採用的預設埠) -
虛擬目錄部分:從域名後的第一個「/」開始到最後一個「/」為止,是虛擬目錄部分。虛擬目錄也不是一個URL必須的部分。本例中沒有虛擬目錄。 -
檔名部分:從域名後的最後一個「/」開始到「?」為止,是檔名部分,如果沒有「?」,則是從域名後的最後一個「/」開始到「#」為止,是檔案部分,如果沒有「?」和「#」,那麼從域名後的最後一個「/」開始到結束,都是檔名部分。本例中的檔名是「weixin_45692705」。檔名部分也不是一個URL必須的部分,如果省略該部分,則使用預設的檔名。 -
錨部分:從「#」開始到最後,都是錨部分。本例中沒有錨部分。錨部分也不是一個URL必須的部分. -
引數部分:從「?」開始到「#」為止之間的部分為引數部分,又稱搜尋部分、查詢部分。本例中的引數部分為「spm=1011.2124.3001.5343」。引數可以允許有多個引數,引數與引數之間用「&」作為分隔符。
請求訊息Request
- 使用者端傳送一個HTTP請求到伺服器的請求訊息包括以下格式:
請求行,請求頭,請求體
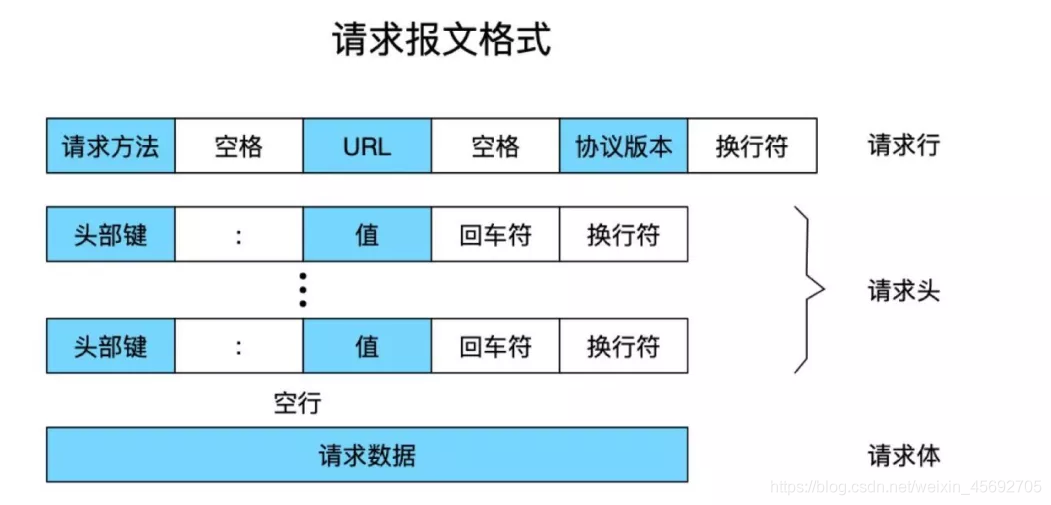
Http請求訊息結構
- 請求行以一個方法符號開頭,以空格分開,後面跟著請求的URI和協定的版本。

-
第一部分:請求行,用來說明請求型別,要存取的資源以及所使用的HTTP版本。GET說明請求型別為GET,[/department/87423/users]為要存取的資源,該行的最後一部分說明使用的是HTTP1.1版本。
-
第二部分:請求頭部,緊接著請求行(即第一行)之後的部分,用來說明伺服器要使用的附加資訊。從第二行起為請求頭部,HOST將指出請求的目的地.User-Agent,伺服器端和使用者端指令碼都能存取它,它是瀏覽器型別檢測邏輯的重要基礎.該資訊由你的瀏覽器來定義,並且在每個請求中自動傳送等等
-
第三部分:空行,請求頭部後面的空行是必須的。即使第四部分的請求資料為空,也必須有空行。
-
第四部分:請求資料也叫主體,可以新增任意的其他資料。這個例子的請求資料為name=flyhero。
響應訊息Response
- 一般情況下,伺服器接收並處理使用者端發過來的請求後會返回一個HTTP的響應訊息。
伺服器端響應使用者端格式:狀態行,響應頭,響應體
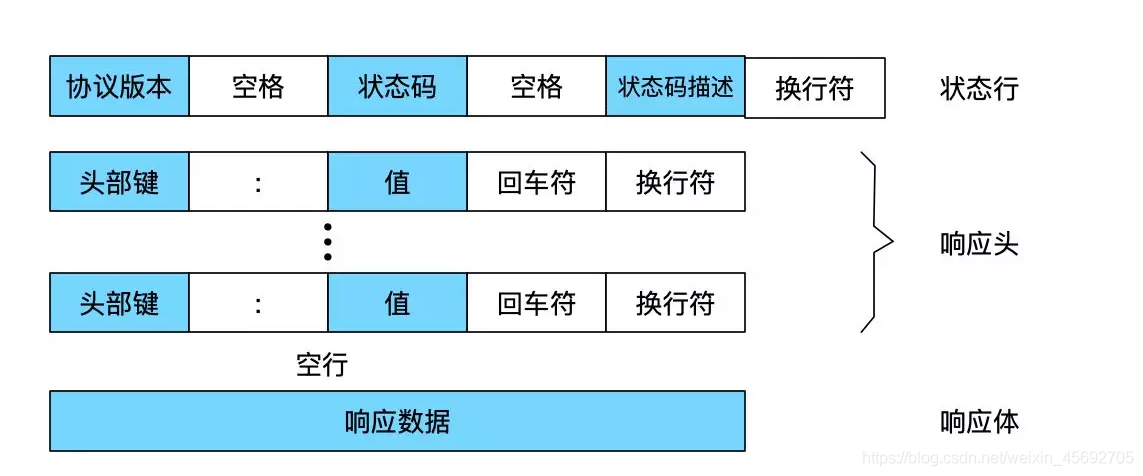
Http響應訊息結構

-
第一部分:狀態行,由HTTP協定版本號, 狀態碼, 狀態訊息 三部分組成。第一行為狀態行,(HTTP/1.1)表明HTTP版本為1.1版本,狀態碼為200,狀態訊息為(ok)
-
第二部分:訊息報頭,用來說明使用者端要使用的一些附加資訊 第二行和第三行為訊息報頭,Date:生成響應的日期和時間;Content-Type:指定了MIME型別的HTML(text/html),編碼型別是UTF-8
-
第三部分:空行,訊息報頭後面的空行是必須的
-
第四部分:響應正文,伺服器返回給使用者端的文字資訊。 {「name」:「flyhero」,「id」:「push-code」}
狀態碼
- HTTP狀態碼由三個十進位制數位組成,第一個十進位制數位定義了狀態碼的型別,後兩個數位沒有分類的作用。HTTP狀態碼共分為5種型別:
| 分類 | 分類描述 |
|---|---|
| 1** | 資訊,伺服器收到請求,需要請求者繼續執行操作 |
| 2** | 成功,操作被成功接收並處理 |
| 3** | 重定向,需要進一步的操作以完成請求 |
| 4** | 使用者端錯誤,請求包含語法錯誤或無法完成請求 |
| 5** | 伺服器錯誤,伺服器在處理請求的過程中發生了錯誤 |
更詳細的狀態碼可檢視 HTTP狀態碼:https://www.runoob.com/http/http-status-codes.html
但一般我們只需要知道幾個常見的就行,比如 :
- 200:使用者端請求成功
- 400:使用者端請求有語法錯誤,不能被伺服器所理解
- 401:請求未經授權,這個狀態程式碼必須和WWW-Authenticate報頭域一起使用
- 403:伺服器收到請求,但是拒絕提供服務
- 404:請求資源不存在,eg:輸入了錯誤的URL
- 500:伺服器發生不可預期的錯誤
- 502:伺服器當前不能處理使用者端的請求,一段時間後可能恢復正常
請求方法
- 截止到HTTP1.1共有下面幾種方法
| 方法 | 描述 |
|---|---|
| GET | GET請求會顯示請求指定的資源。一般來說GET方法應該只用於資料的讀取,而不應當用於會產生副作用的非冪等的操作中。它期望的應該是而且應該是安全的和冪等的。這裡的安全指的是,請求不會影響到資源的狀態。 |
| POST | 向指定資源提交資料進行處理請求(例如提交表單或者上傳檔案)。資料被包含在請求體中。POST請求可能會導致新的資源的建立和/或已有資源的修改。 |
| PUT | PUT請求會身向指定資源位置上傳其最新內容,PUT方法是冪等的方法。通過該方法使用者端可以將指定資源的最新資料傳送給伺服器取代指定的資源的內容。 |
| PATCH | PATCH方法出現的較晚,它在2010年的RFC 5789標準中被定義。PATCH請求與PUT請求類似,同樣用於資源的更新。二者有以下兩點不同:1.PATCH一般用於資源的部分更新,而PUT一般用於資源的整體更新。2.當資源不存在時,PATCH會建立一個新的資源,而PUT只會對已在資源進行更新。 |
| DELETE | DELETE請求用於請求伺服器刪除所請求URI(統一資源識別符號,Uniform Resource Identifier)所標識的資源。DELETE請求後指定資源會被刪除,DELETE方法也是冪等的。 |
| OPTIONS | 允許使用者端檢視伺服器的效能。 |
| CONNECT | HTTP/1.1協定中預留給能夠將連線改為管道方式的代理伺服器。 |
| HEAD | 類似於get請求,只不過返回的響應中沒有具體的內容,用於獲取報頭。 |
| TRACE | 回顯伺服器收到的請求,主要用於測試或診斷。 |
注意事項:
-
方法名稱是區分大小寫的。當某個請求所針對的資源不支援對應的請求方法的時候,伺服器應當返回狀態碼405(Method Not Allowed),當伺服器不認識或者不支援對應的請求方法的時候,應當返回狀態碼501(Not Implemented)。
-
HTTP伺服器至少應該實現GET和HEAD方法,其他方法都是可選的。當然,所有的方法支援的實現都應當匹配下述的方法各自的語意定義。此外,除了上述方法,特定的HTTP伺服器還能夠擴充套件自定義的方法。例如PATCH(由 RFC 5789 指定的方法)用於將區域性修改應用到資源。
GET和POST請求的區別
- GET請求
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
注意最後一行是空行
- POST請求
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
1. GET提交,請求的資料會附在URL之後(就是把資料放置在HTTP協定頭中),以?分割URL和傳輸資料,多個引數用&連線;例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果資料是英文字母/數位,原樣傳送,如果是空格,轉換為+,如果是中文/其他字元,則直接把字串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX為該符號以16進位製表示的ASCII。
POST提交:把提交的資料放置在是HTTP包的包體中。上文範例中紅色字型標明的就是實際的傳輸資料
- 因此,GET提交的資料會在位址列中顯示出來,而POST提交,位址列不會改變
2. 傳輸資料的大小
首先宣告:HTTP協定沒有對傳輸的資料大小進行限制,HTTP協定規範也沒有對URL長度進行限制。而在實際開發中存在的限制主要有:
-
GET:特定瀏覽器和伺服器對URL長度有限制,例如 IE對URL長度的限制是2083位元組(2K+35)。對於其他瀏覽器,如Netscape、FireFox等,理論上沒有長度限制,其限制取決於操作系 統的支援。因此對於GET提交時,傳輸資料就會受到URL長度的 限制。 -
POST:由於不是通過URL傳值,理論上資料不受 限。但實際各個WEB伺服器會規定對post提交資料大小進行限制,Apache、IIS6都有各自的設定。
3. 安全性
- POST的安全性要比GET的安全性高。比如:通過GET提交資料,使用者名稱和密碼將明文出現在URL上,因為(1)登入頁面有可能被瀏覽器快取;(2)其他人檢視瀏覽器的歷史紀錄,那麼別人就可以拿到你的賬號和密碼了,除此之外,使用GET提交資料還可能會造成Cross-site request forgery攻擊
4. Http get,post,soap協定都是在http上執行的
-
get:請求引數是作為一個key/value對的序列(查詢字串)附加到URL上的查詢字串的長度受到web瀏覽器和web伺服器的限制(如IE最多支援2048個字元),不適合傳輸大型資料集同時,它很不安全
-
post:請求引數是在http標題的一個不同部分(名為entity body)傳輸的,這一部分用來傳輸表單資訊,因此必須將Content-type設定為:application/x-www-form- urlencoded。post設計用來支援web表單上的使用者欄位,其引數也是作為key/value對傳輸。但是:它不支援複雜資料型別,因為post沒有定義傳輸資料結構的語意和規則。
-
soap:是http post的一個專用版本,遵循一種特殊的xml訊息格式Content-type設定為: text/xml 任何資料都可以xml化。
- Http協定定義了很多與伺服器互動的方法,最基本的有4種,分別是GET,POST,PUT,DELETE. 一個URL地址用於描述一個網路上的資源,而HTTP中的GET, POST, PUT, DELETE就對應著對這個資源的查,改,增,刪4個操作。 我們最常見的就是GET和POST了。GET一般用於獲取/查詢資源資訊,而POST一般用於更新資源資訊.
我們看看GET和POST的區別
-
GET提交的資料會放在URL之後,以?分割URL和傳輸資料,引數之間以&相連,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的資料放在HTTP包的Body中.
-
GET提交的資料大小有限制(因為瀏覽器對URL的長度有限制),而POST方法提交的資料沒有限制.
-
GET方式需要使用Request.QueryString來取得變數的值,而POST方式通過Request.Form來獲取變數的值。
-
GET方式提交資料,會帶來安全問題,比如一個登入頁面,通過GET方式提交資料時,使用者名稱和密碼將出現在URL上,如果頁面可以被快取或者其他人可以存取這臺機器,就可以從歷史記錄獲得該使用者的賬號和密碼.
請求和響應常見通用頭
| 名稱 | 作用 |
|---|---|
| Content-Type | 請求體/響應體的型別,如:text/html、application/json |
| Accept | 說明接收的型別,可以多個值,用,(半形逗號)分開 |
| Content-Length | 請求體/響應體的長度,單位位元組 |
| Content-Encoding | 請求體/響應體的編碼格式,如gzip,deflate |
| Accept-Encoding | 告知對方我方接受的Content-Encoding |
| ETag | 給當前資源的標識,和Last-Modified、If-None-Match、If-Modified-Since配合,用於快取控制 |
| Cache-Control | 取值為一般為no-cache或max-age=XX,XX為個整數,表示該資源快取有效期(秒) |
注意:Content-Type,內容型別,一般是指網頁中存在的Content-Type,用於定義網路檔案的型別和網頁的編碼,決定瀏覽器將以什麼形式、什麼編碼讀取這個檔案。
常見的媒體格式型別如下:
| Content-Type(Mime-Type) | 描述 |
|---|---|
| text/html | HTML格式 |
| text/plain | 純文字格式 |
| text/xml | XML格式 |
| image/gif | gif圖片格式 |
| image/jpeg | jpg圖片格式 |
| image/png | png圖片格式 |
以application開頭的媒體格式型別:
| Content-Type(Mime-Type) | 描述 |
|---|---|
| application/xml | XML資料格式 |
| application/json | JSON資料格式 |
| application/pdf | pdf格式 |
| application/msword | Word檔案格式 |
| application/octet-stream | 二進位制流資料(如常見的檔案下載) |
| application/x-www-form-urlencoded | form表單資料被編碼為key/value格式傳送到伺服器(表單預設的提交資料的格式) |
| multipart/form-data | 需要在表單中進行檔案上傳時,就需要使用該格式 |
請求頭
| 名稱 | 作用 |
|---|---|
| Authorization | 用於設定身份認證資訊 |
| User-Agent | 使用者標識,如:OS和瀏覽器的型別和版本 |
| If-Modified-Since | 值為上一次伺服器返回的 Last-Modified 值,用於確認某個資源是否被更改過,沒有更改過(304)就從快取中讀取 |
| If-None-Match | 值為上一次伺服器返回的 ETag 值,一般會和If-Modified-Since一起出現 |
| Cookie | 已有的Cookie |
| Referer | 表示請求參照自哪個地址,比如你從頁面A跳轉到頁面B時,值為頁面A的地址 |
| Host | 請求的主機和埠號 |
常見響應頭
| 名稱 | 作用 |
|---|---|
| Date | 伺服器的日期 |
| Last-Modified | 該資源最後被修改時間 |
| Transfer-Encoding | 取值為一般為chunked,出現在Content-Length不能確定的情況下,表示伺服器不知道響應版體的資料大小,一般同時還會出現Content-Encoding響應頭 |
| Set-Cookie | 設定Cookie |
| Location | 重定向到另一個URL,如輸入瀏覽器就輸入baidu.com回車,會自動跳到 https://www.baidu.com ,就是通過這個響應頭控制的 |
| Server | 後臺伺服器 |
HTTP的不足
- 通訊使用明文(不加密),內容可能會被竊聽
- 不驗證通訊方的身份,因此有可能遭遇偽裝
- 無法證明報文的完整性,所以有可能已遭篡改
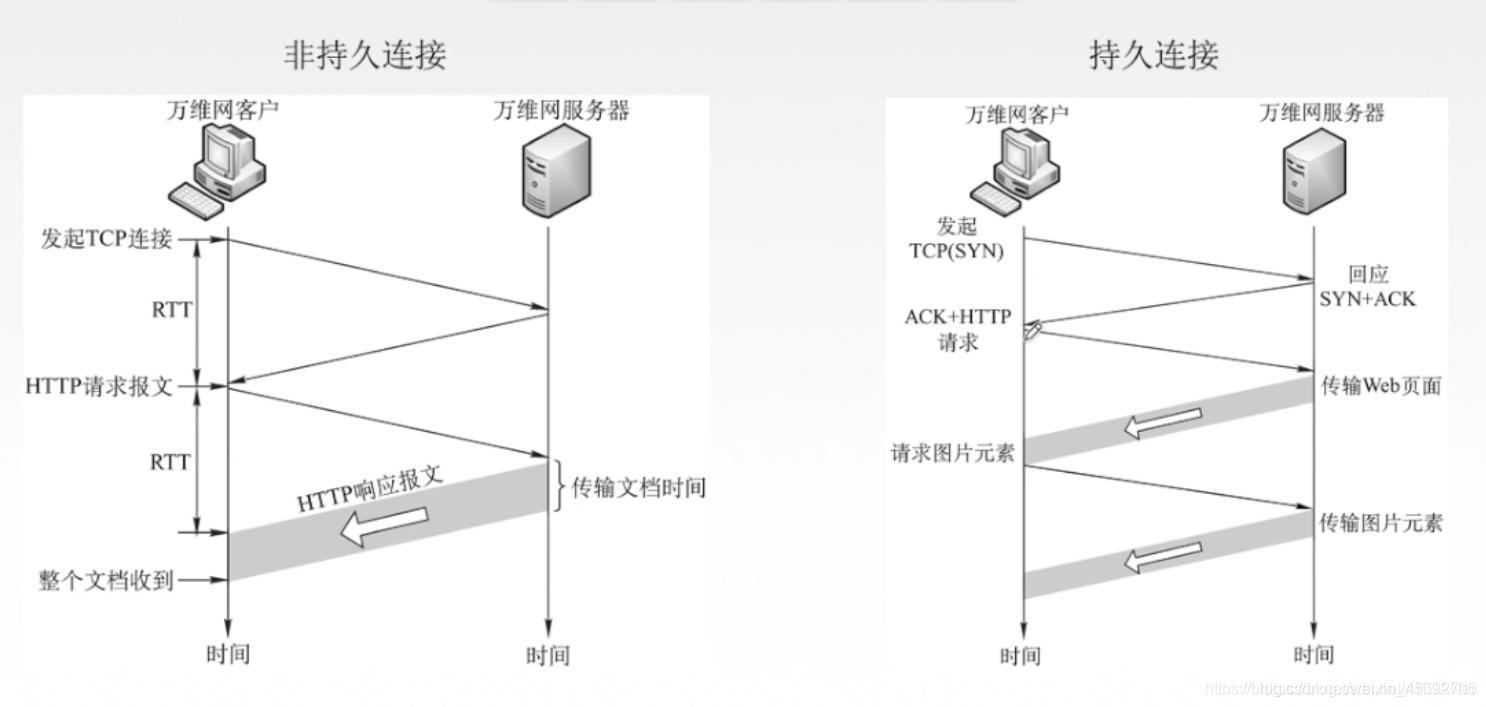
非持久連線和持久連線
- 在實際的應用中,使用者端往往會發出一系列請求,接著伺服器端對每個請求進行響應。對於這些請求|響應,如果每次都經過一個單獨的TCP連線傳送,稱為非持久連線。反之,如果每次都經過相同的TCP連線進行傳送,稱為持久連線。
-
非持久連線在每次請求|響應之後都要斷開連線,下次再建立新的TCP連線,這樣就造成了大量的通訊開銷。例如前面提到的往返時間(RTT) 就是在建立TCP連線的過程中的代價。
-
非持久連線給伺服器帶來了沉重的負擔,每臺伺服器可能同時面對數以百計甚至更多的請求。持久連線就是為了解決這些問題,其特點是一直保持TCP連線狀態,直到遇到明確的中斷要求之後再中斷連線。持久連線減少了通訊開銷,節省了通訊量。
HTTPS

HTTPS介紹
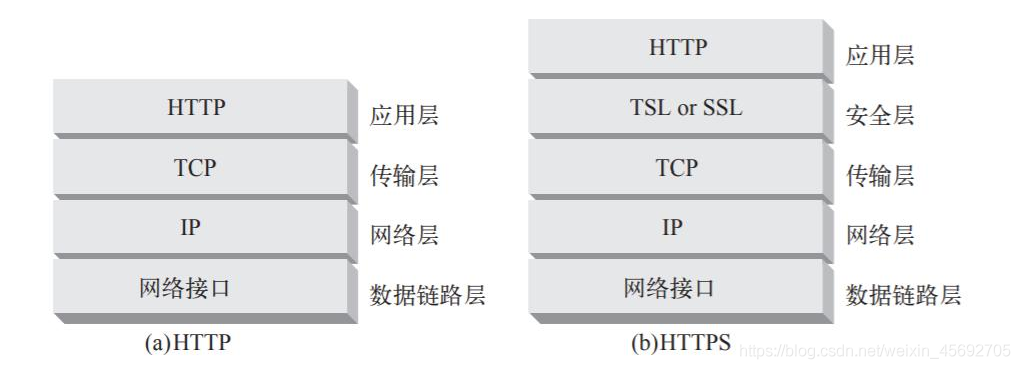
HTTP協定中沒有加密機制,但可以通 過和 SSL(Secure Socket Layer, 安全通訊協定 )或 TLS(Transport Layer Security, 安全層傳輸協定)的組合使用,加密 HTTP 的通訊內容。屬於通訊加密,即在整個通訊線路中加密。
HTTP + 加密 + 認證 + 完整性保護 = HTTPS(HTTP Secure )
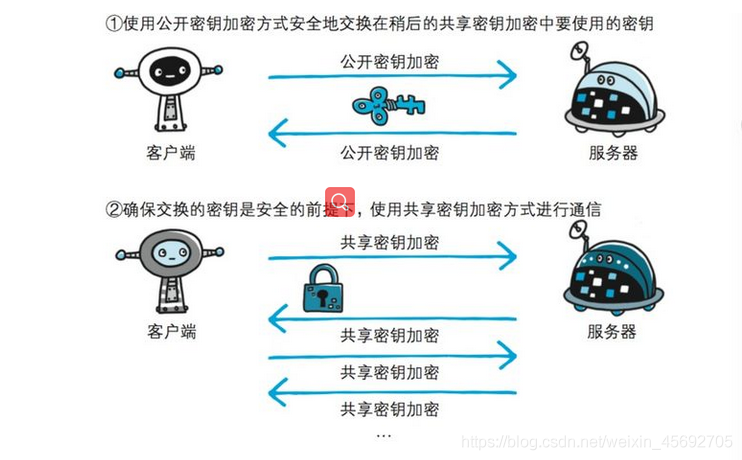
HTTPS採用共用金鑰加密(對稱)和公開金鑰加密(非對稱)兩者並用的混合加密機制。若金鑰能夠實現安全交換,那麼有可能會考慮僅使用公開金鑰加密來通訊。但是公開金鑰加密與共用金鑰加密相比,其處理速度要慢。
所以應充分利用兩者各自的優勢, 將多種方法組合起來用於通訊。 在交換金鑰階段使用公開金鑰加密方式,之後的建立通訊交換報文階段 則使用共用金鑰加密方式。
HTTPS握手過程的簡單描述如下:
- 瀏覽器將自己支援的一套加密規則傳送給網站。
伺服器獲得瀏覽器公鑰。 - 網站從中選出一組加密演演算法與HASH演演算法,並將自己的身份資訊以證書的形式發回給瀏覽器。證書裡面包含了網站地址,加密公鑰,以及證書的頒發機構等資訊。
瀏覽器獲得伺服器公鑰。 - 獲得網站證書之後瀏覽器要做以下工作:
-
- 證證書的合法性(頒發證書的機構是否合法,證書中包含的網站地址是否與正在存取的地址一致等),如果證書受信任,則瀏覽器欄裡面會顯示一個小鎖頭,否則會給出證書不受信的提示。
-
- 如果證書受信任,或者是使用者接受了不受信的證書,瀏覽器會生成一串亂數的密碼(接下來通訊的金鑰),並用證書中提供的公鑰加密(共用金鑰加密)。
-
- 使用約定好的HASH計算握手訊息,並使用生成的亂數對訊息進行加密,最後將之前生成的所有資訊傳送給網站。
瀏覽器驗證 -> 隨機密碼 伺服器的公鑰加密 -> 通訊的金鑰 通訊的金鑰 -> 伺服器
- 使用約定好的HASH計算握手訊息,並使用生成的亂數對訊息進行加密,最後將之前生成的所有資訊傳送給網站。
- 網站接收瀏覽器發來的資料之後要做以下的操作:
-
- 使用自己的私鑰將資訊解密取出密碼,使用密碼解密瀏覽器發來的握手訊息,並驗證HASH是否與瀏覽器發來的一致。
-
- 使用密碼加密一段握手訊息,傳送給瀏覽器。
伺服器用自己的私鑰解出隨機密碼 -> 用密碼解密握手訊息(共用金鑰通訊)-> 驗證HASH與瀏覽器是否一致(驗證瀏覽器)
- 使用密碼加密一段握手訊息,傳送給瀏覽器。
HTTPS的不足
- 加密解密過程複雜
- 導致存取速度慢加密需要認向證機構付費
- 整個頁面的請求都要使用HTTPS
HTTPS的工作原理
- 我們都知道HTTPS能夠加密資訊,以免敏感資訊被第三方獲取,所以很多銀行網站或電子郵箱等等安全級別較高的服務都會採用HTTPS協定。
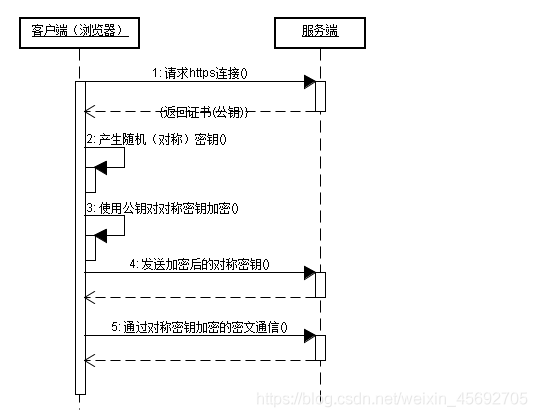
使用者端在使用HTTPS方式與Web伺服器通訊時有以下幾個步驟,如圖所示。
- 客戶使用https的URL存取Web伺服器,要求與Web伺服器建立SSL連線。
- Web伺服器收到使用者端請求後,會將網站的證書資訊(證書中包含公鑰)傳送一份給使用者端。
- 使用者端的瀏覽器與Web伺服器開始協商SSL連線的安全等級,也就是資訊加密的等級。
- 使用者端的瀏覽器根據雙方同意的安全等級,建立對談金鑰,然後利用網站的公鑰將對談金鑰加密,並傳送給網站。
- Web伺服器利用自己的私鑰解密出對談金鑰。
- Web伺服器利用對談金鑰加密與使用者端之間的通訊。
HTTP與HTTPS的區別
- HTTP協定傳輸的資料都是未加密的,也就是明文的,因此使用HTTP協定傳輸隱私資訊非常不安全,為了保證這些隱私資料能加密傳輸,於是網景公司設計了SSL(Secure Sockets Layer)協定用於對HTTP協定傳輸的資料進行加密,從而就誕生了HTTPS。簡單來說,HTTPS協定是由SSL+HTTP協定構建的可進行加密傳輸、身份認證的網路協定,要比http協定安全。
HTTPS和HTTP的區別主要如下:
- https協定需要到ca申請證書,一般免費證書較少,因而需要一定費用。
- http是超文字傳輸協定,資訊是明文傳輸,https則是具有安全性的ssl加密傳輸協定。
- http和https使用的是完全不同的連線方式,用的埠也不一樣,前者是80,後者是443。
- http的連線很簡單,是無狀態的;HTTPS協定是由SSL+HTTP協定構建的可進行加密傳輸、身份認證的網路協定,比http協定安全。
總結
- 相比 HTTP 協定,HTTPS 協定增加了很多握手、加密解密等流程,雖然過程很複雜,但其可以保證資料傳輸的安全。
整理不易,看完還請一鍵三連!有條件的打賞一下o( ̄▽ ̄)ブ !