爬動漫「上癮」之後,放棄午休,迫不及待的用Python薅了騰訊動漫的資料,嘖嘖嘖
這是爬蟲 120 例的第 10 篇
本篇部落格在編寫的過程中,擦哥跟我說,他順帶複習了一遍 《一人之下》 和 《 至尊瞳術師:絕世大小姐》 ,doge。
閱讀本文,你將收穫
- 5000+騰訊動漫資料;
- 正規表示式區域提取;
- 多執行緒爬蟲。
騰訊動漫資料大采集術
目標資料來源分析
爬取目標網站
本次抓取的目標網站為:https://ac.qq.com/Comic/index/page/1。
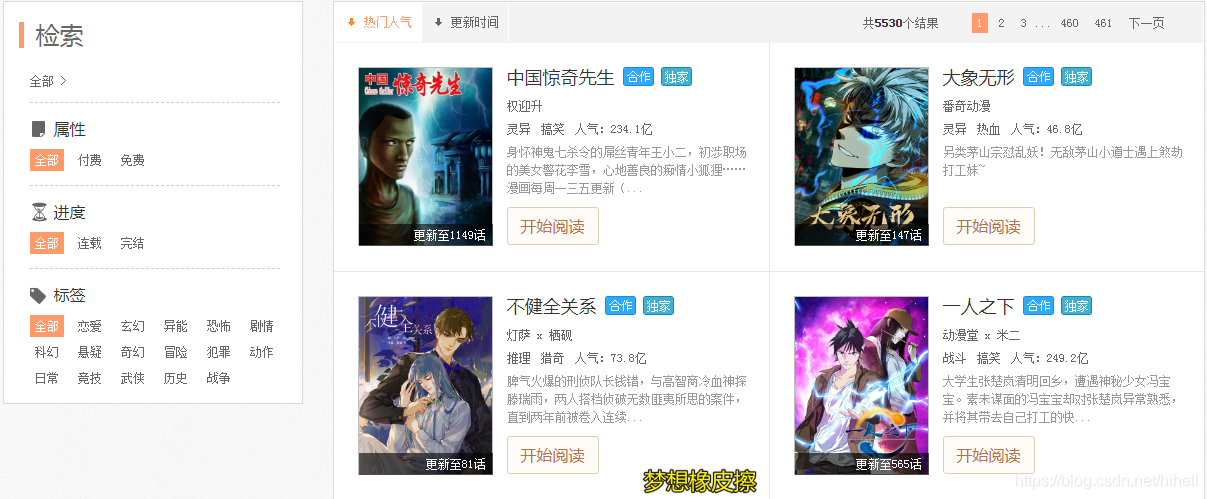
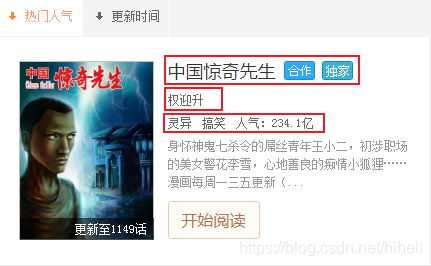
針對上圖資料,本文將採集下圖框選區域資料,同時本文將通過正規表示式進行區域塊匹配。
使用的 Python 模組
requests 模組,re 模組,fake_useragent 模組,threading 模組。
重點學習內容
本文在學習的過程中,重點掌握 fake_useragent 模組與正規表示式分塊提取,以及 CSV 檔案特殊符號問題。
列表頁分析
通過開發者工具頁面,檢視網頁資料由伺服器直接返回,顧直接通過正規表示式提取資料即可。
提取過程中,先提取每一動漫所在的 li 標籤,然後再提取標籤內具體資料資訊。
頁面規則比較簡單,羅列如下:
https://ac.qq.com/Comic/index/page/1
https://ac.qq.com/Comic/index/page/2
https://ac.qq.com/Comic/index/page/3
整理需求如下
- 限制 5 個執行緒爬取資料;
- 寫入檔案通過執行緒互斥鎖,防止異常;
- 清洗資料,再儲存;
- 因為儲存格式為
CSV檔案,所以需要處理,,"等特殊符號。
編碼時間
本次爬蟲學習引入一個新的庫,fake_useragent,該庫用於隨機獲取請求引數中的 User-Agent,
使用前需提前通過 pip 進行安裝,簡易 Demo 如下:
from fake_useragent import UserAgent
ua = UserAgent()
headers= {'User-Agent':ua.random}
如果上述程式碼出現 BUG,一般禁用瀏覽器快取問題即可。
ua = UserAgent(use_cache_server=False)
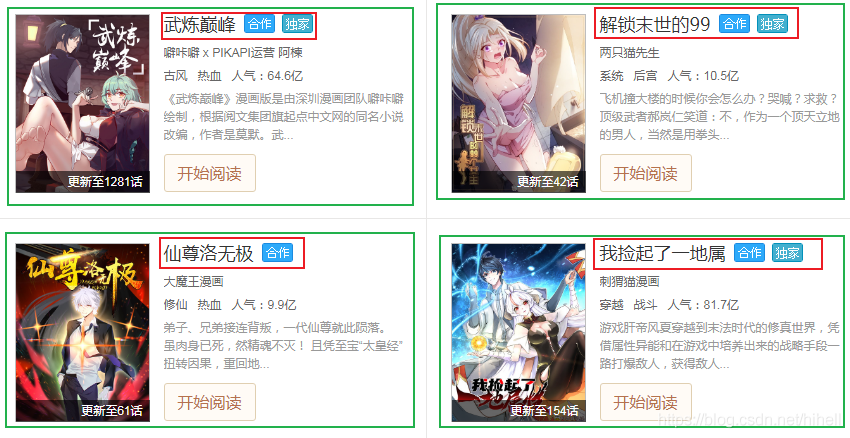
另一個在本文需要注意的一點是,優先使用正規表示式提取父級標籤,再在父級標籤內部提取子級標籤,具體如下圖所示。第一步提取綠色方框資料,第二步提取紅色方框資料。
在寫入 CSV 檔案處,需要注意使用了執行緒互斥鎖,防止檔案寫入異常。鎖的宣告在 main 部分,案例完整程式碼如下所示,部分邏輯直接寫在註釋部分。
import requests
from fake_useragent import UserAgent
import re
import threading
def replace_mark(my_str):
return my_str.replace(",", ",").replace('"', "「")
def format_html(html):
# 各提取正規表示式部分,編寫人橡皮擦@CSDN
li_pattern = re.compile(
'<li\sclass="ret-search-item clearfix">[\s\S]+?</li>')
title_url_pattern = re.compile(
'<a href="(.*?)" target="_blank" title=".*?">(.*?)</a>')
sign_pattern = re.compile('<i class="ui-icon-sign">簽約</i>')
exclusive_pattern = re.compile('<i class="ui-icon-exclusive">獨家</i>')
author_pattern = re.compile(
'<p class="ret-works-author" title=".*?">(.*?)</p>')
tags_pattern = re.compile('<span href=".*?" target="_blank">(.*?)</span>')
score_pattern = re.compile('<span>人氣:<em>(.*?)</em></span>')
items = li_pattern.findall(html)
# 依次迭代提取的 li 標籤
for item in items:
title_url = title_url_pattern.search(item)
title = title_url.group(2)
url = title_url.group(1)
sign = 0
exclusive = 0
# 資料非空檢驗
if sign_pattern.search(item) is not None:
sign = 1
if exclusive_pattern.search(item) is not None:
exclusive = 1
author = author_pattern.search(item).group(1)
tags = tags_pattern.findall(item)
score = score_pattern.search(item).group(1)
# 鎖開啟
lock.acquire()
with open("./acqq.csv", "a+", encoding="utf-8") as f:
f.write(
f'{replace_mark(title)},{url},{sign},{exclusive},{replace_mark(author)},{"#".join(tags)},"{replace_mark(score)}" \n')
# 鎖關閉
lock.release()
def run(index):
ua = UserAgent(use_cache_server=False)
response = requests.get(
f"https://ac.qq.com/Comic/index/page/{index}", headers={'User-Agent': ua.random})
html = response.text
format_html(html)
# 注意釋放執行緒
semaphore.release()
lock = threading.Lock()
if __name__ == "__main__":
num = 0
semaphore = threading.BoundedSemaphore(5)
lst_record_threads = []
for index in range(1, 462):
print(f"正在抓取{index}")
semaphore.acquire()
t = threading.Thread(target=run, args=(index, ))
t.start()
lst_record_threads.append(t)
for rt in lst_record_threads:
rt.join()
print("資料爬取完畢")
上述程式碼補充說明:
在提取過程中發現,變數 title,author,score 的值存在特殊符號,例如 ",,,這些符號會導致 CSV 檔案亂版,針對該內容增加 replace_mark 函數,將這些符號進行中文化處理,即 " → 「, , → ,。
抓取結果展示時間
本案例是 Python 爬蟲 120 例的第 10 例,如果你已經全部打卡,相信你對爬蟲已經建立了初步的認知,下一篇橡皮擦將引入 lxml 模組,更換 re 模組,進行資料提取,爬蟲 120 例學習進入第二階段,一起加油。
完整程式碼下載地址:https://codechina.csdn.net/hihell/python120,NO10。
以下是爬取過程中產生的各種學習資料,如果只需要資料,可去下載頻道下載~。
爬取資源僅供學習使用,侵權刪。
抽獎時間
評論數過 100,隨機抽取一名幸運讀者,
獲取 29.9 元《Python 遊戲世界》專欄 1 折購買券一份,只需 2.99 元。
今天是持續寫作的第 173 / 200 天。可以點贊、評論、收藏啦。
相關閱讀
- 10 行程式碼集 2000 張美女圖,Python 爬蟲 120 例,再上征途
- 通過 Python 爬蟲,發現 60%女裝大佬遊走在 cosplay 領域
- Python 千貓圖,簡單技術滿足你的收集控
- 熊孩子說「你沒看過奧特曼」,趕緊用 Python 學習一下,沒想到
- 技術圈的【多肉小達人】,一篇文章你就能做到
- 我用 Python 連夜離線了 100G 圖片,只為了防止網站被消失
- 對 Python 爬蟲編寫者充滿誘惑的網站,《可愛圖片網》,瞧人這網站名字起的
- 5000 張高清桌布大圖(手機用),用 Python 在法律的邊緣又試探了一把
- 10994 部漫畫資訊,用 Python 實施大采集,因為反爬差一點就翻車了