要悄悄地學C語言,在成為大佬的路上一去不復返
一、什麼是C語言
什麼是C語言,C語言是一門計算機語言,那什麼是計算機語言?
就如世界有好多個國家,每個國家的語言可能都不一樣,有漢語、英語、俄羅斯語、法語等等,那麼按照正常來說,比如中國人,就會用漢語交流,美國人就用英語交流等等,如果要是想中國人和美國人交流,要麼中國人說英語,要麼美國人說漢語,這樣對方才能懂說的話是什麼意思
這個比喻就好比計算機語言,計算機語言就是:人和計算機交流,那麼我們就需要學習計算機語言,為什麼?因為計算機只認識0和1,這個要是在深究的話,請自行百度
那麼我們現在有什麼計算機語言,比如:C、C++、Java、Python、JavaScript、Go等等,這些都是計算機語言
接下來我們說一下計算機語言的發展史:
早期計算機能識別的語言叫做二進位制語言,這個怎麼理解呢,就是計算機是一個硬體,但是它要通電,而電分正電和負電,所以也就是我們上面說到的0和1,0為負電,1為正電,它們也被稱為電訊號
那麼我們現在就想讓計算機工作,寫一段程式碼,那可能二進位制語言表示就是這樣的
01010101010010010101011100010001
給計算機輸入這樣很多的電訊號,它是不是特別複雜啊,所以當時寫這樣程式碼就要查手冊才能寫出正確的程式碼
所以到後來出現了助記符,比如這段程式碼
010101010
假如這段程式碼就是表示ADD,就是加法助記符,那我們以後寫程式碼就直接寫ADD就好了,也簡單了,而這些助記符所表達的語言就是 組合語言
發現還是非常繁瑣,接著就有了B語言,而在B語言的基礎上發明了我們所熟知的C、C++等等,從C語言開始我們就稱這些語言為高階語言
C語言是一門程式導向的計算機程式語言,與C++,Java等物件導向的程式語言有所不同。
解析C語言程式的程式碼:
// 這個是我們C語言的一個主函數框架,也就是說程式碼是從這裡開始進行執行的
int main()
{
return 0;
}
那我們先來列印一個程式碼吧
人生的中的第一個C語言Hello World
int main()
{
printf("Hello World\n");
return 0;
}
直接按 F10 debug程式碼,看一下執行流程
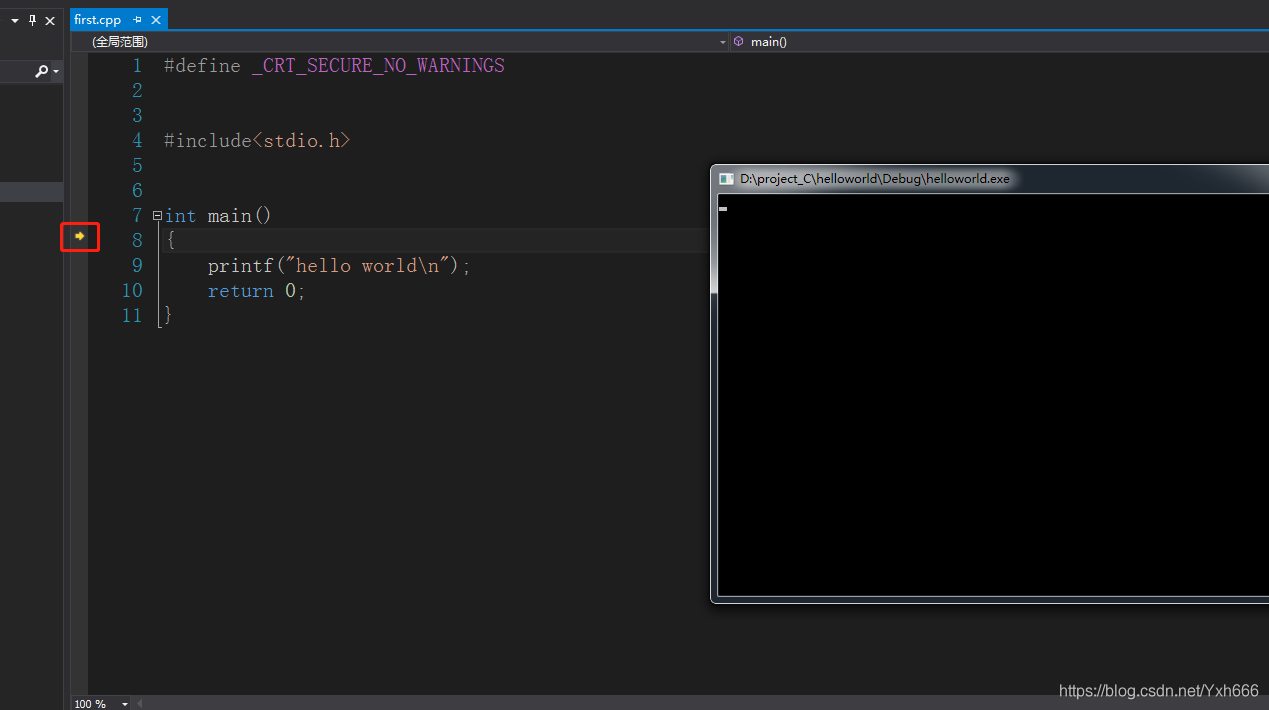
可以看到在第8行有一個小箭頭,再按F10,可以看到箭頭到了第9行,所以說程式碼是從main函數開始執行的
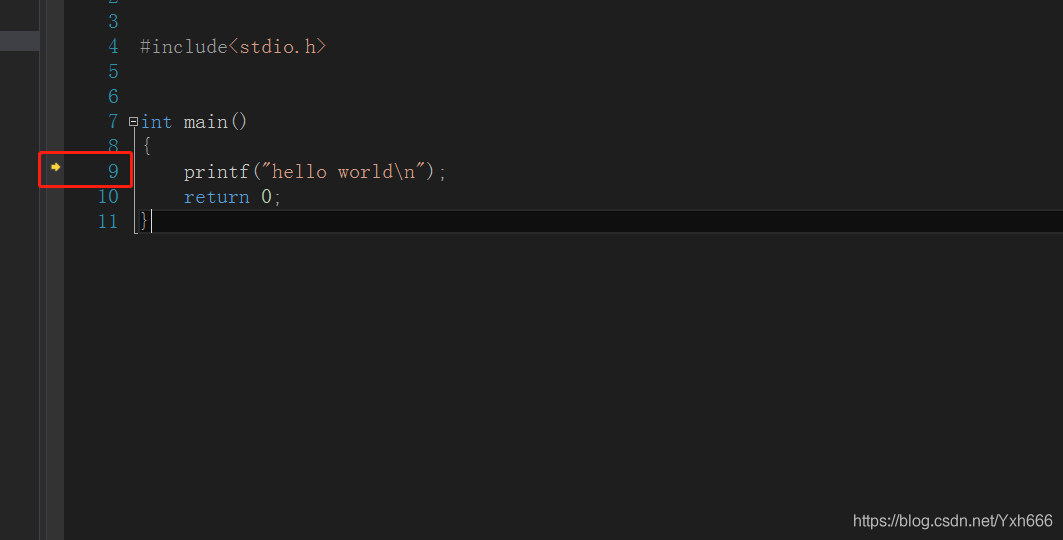
我們再建立一個main函數看會怎麼樣
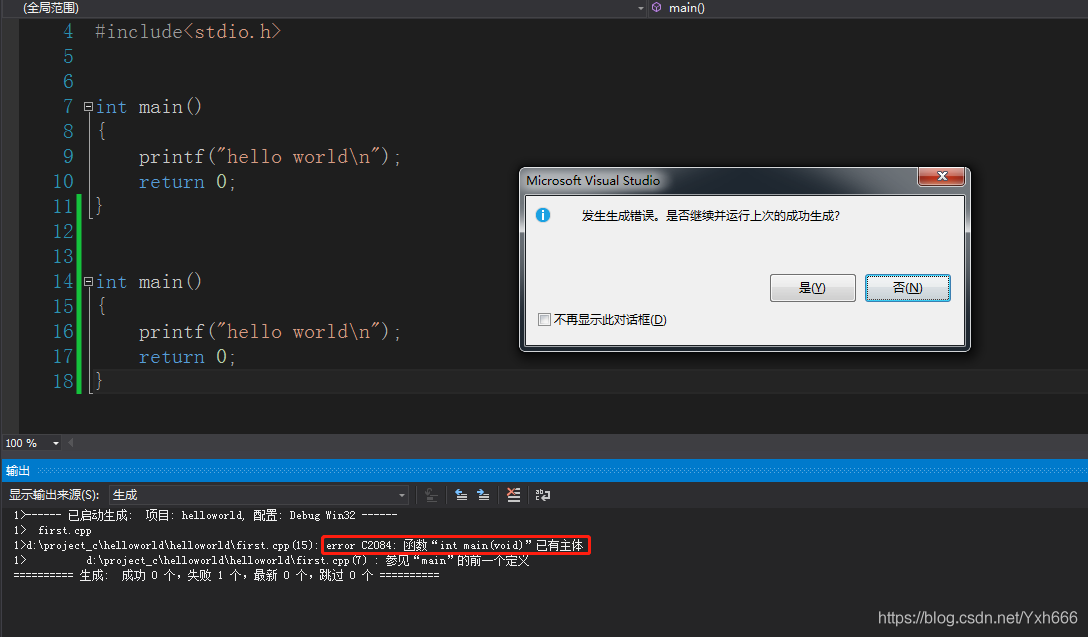
所以說main函數有且僅有一個
那麼這個函數體內還有return 0,這個的意思就是返回0,0是整數,而main() 函數之前的int 就是整型的意思
main()函數之前放int表示 main() 函數呼叫返回一個整型值
這樣return 0,就和int前後呼應的聯絡起來
但我們是不是在之前看到的C語言的main函數寫法是這樣的:
void main()
{
}
沒錯,這個也是我們C語言的寫法,但是這種寫法已經是過時的寫法了,所以我們在寫的時候,就不要再這樣寫了
接著看我們列印函數printf() 這個函數其實是可以拆解的它是分為print和function,顧名思義,就是列印函數
那麼這個列印函數又叫庫函數,庫函數就是C語言本身封裝好提供給我們的函數,那麼這個就相當於在使用別人的函數
使用別人給我提供的函數就要去 「打招呼」 也就是要去呼叫一下:
//include叫做包含
#include <stdio.h>
那麼這個程式碼的意思就是包含stdio.h的檔案
我們再來拆分stdio.h
- std:標準
- i:input 輸入
- o:outut 輸出
所以標頭檔案的意思就是標準輸入輸出標頭檔案
那麼我們以後要是寫輸入或者輸入的函數的時候都要引入這個標頭檔案
所以接下來寫一個列印程式碼的完整程式碼:
#include <stdio.h>
int manin()
{
printf("你好,世界!\n");
printf("我是程式設計師,是用程式碼編織世界的工程師\n");
return 0;
}
二、字元型別
| char | 字元格式資料 |
|---|---|
| short | 短整型 |
| int | 整型 |
| long | 長整型 |
| long long | 更長的整型 |
| float | 單精度浮點數 |
| double | 高精度浮點數 |
我挑幾個舉例這些都怎麼使用:
- char
#include <stdio.h>
int manin()
{
char ch = 'C';
printf("%c\n", ch);
return 0;
}
字元 ‘C’ 可以理解為在記憶體開闢了一塊空間,而 ch 就是對這塊空間的命名
那麼列印就是 %c 可以理解為一個預留位置,即要列印字元格式的資料,也就是列印ch所對應的字元
- int
#include <stdio.h>
int manin()
{
int age = 21;
printf("%d\n", age);
return 0;
}
同樣開闢記憶體空間命名為age,而列印的預留位置是 %d ,這個是代表整型十進位制資料
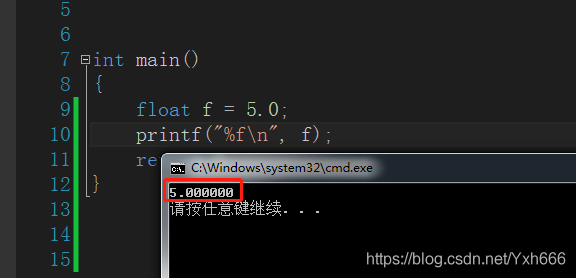
- float、double
#include <stdio.h>
int manin()
{
float f = 5.0;
printf("%f\n", f);
return 0;
}
#include<stdio.h>
int manin()
{
double d = 3.1415926;
printf("%lf\n", d);
return 0;
}
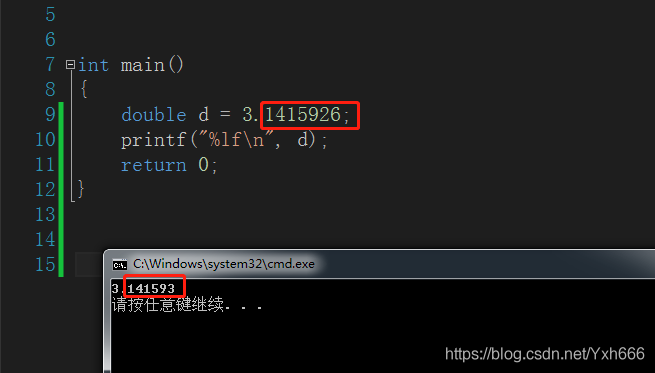
這兩個對比就可以看出都是輸出小數點6位數,double而且還四捨五入了,這也是說明double更加精確
那為什麼有這麼多的字元型別?對應不用的數值型別?減少記憶體消耗?
接下來我們圍繞著各個字元型別的大小展開理解
那我們接著寫程式碼:
//sizeof() 檢視大小
#include<stdio.h>
int main()
{
printf("%d\n", sizeof(char)); // 1
printf("%d\n", sizeof(short)); // 2
printf("%d\n", sizeof(int)); // 4
printf("%d\n", sizeof(long)); // 4/8
printf("%d\n", sizeof(long long)); // 8
printf("%d\n", sizeof(float)); // 4
printf("%d\n", sizeof(double)); // 8
return 0;
}
像他這個輸出的結果的數位單位是位元組,何為位元組?我這裡只列舉幾個
bit
byte
KB
MB
GB
TB
...
計算機最小的記憶體單位為bit,1byte = 8bit,1KB = 1024開始後面的進位制單位都是1024
我們還是看輸入的各個字元型別大小的單位都是位元組,那這和資料型別很多有什麼關係?
因為是在記憶體開闢空間,就會涉及到開闢大小的問題,那我們看int和short型別,一個是佔4個位元組,一個是佔2個位元組
試想一下,我們用int定義了一個人的年齡為21歲,那有沒有人是20000萬歲呢,肯定是沒有的,所以我們在定義年齡的時候,使用short int短整型更較為合適,這樣也是較為合理,最重要的是,節省了記憶體空間
int型別定義的話,會佔用4個位元組,也就是32個bit位,這樣如果定義年齡的話,會顯得比較浪費空間,而short定義的話,是節省了int型別的一半空間,long和long long就是更適合更長的整型了
所以每個字元型別是有著更較為合適的型別,減少了記憶體不必要的消耗
我們還看到了long長整型的長度是4或者8,這是因為跟作業系統和編譯器有關,long int長度至少32位元,而64位元類Unix系統為64位元
三、變數
我們生活中有些值是不變的,如:身份證號,血型、圓周率等,那麼這些值我們就稱為常數
而體重,年齡,薪資等是會變得,這樣我們稱為變數
1、區域性變數
#include<stdio.h>
int manin()
{
int a = 10; // 區域性變數
return 0;
}
2、全域性變數
定義在程式碼塊外面的變數
#include <stdio.h>
int b = 20; // 全域性變數
int manin()
{
return 0;
}
如果區域性變數和全域性變數同時存在,會優先輸出區域性變數,比如下面的程式碼
#include<stdio.h>
int a = 10;
int manin()
{
int a = 100;
printf("%d\n", a);
return 0;
}
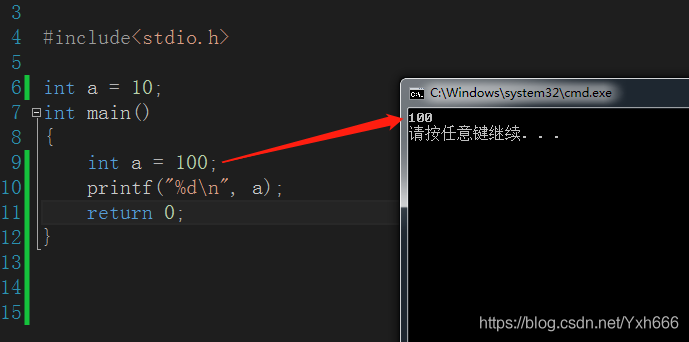
同樣的變數名字,會優先輸出區域性變數的值
那說到這裡就不得不提作用域和生命週期了
1.作用域
- 區域性變數
作用域(scope),程式設計概念,通常來說,通常來說一段程式碼中所用到的名字並不總是有效或者說是可用的
而限定這個名字的可用性的程式碼範圍就是這個名字的作用域
簡單來說就是,這個變數哪裡可以用,哪裡就是它的作用域
#include<stdio.h>
int manin()
{
int a = 100;
printf("%d\n", a)
return 0;
}
我們看這個上面的程式碼,這樣列印的話是可以直接用的,如果是這樣的:
#include<stdio.h>
int a = 10;
int main()
{
{
int a = 100;
}
printf("%d\n", a);
return 0;
}
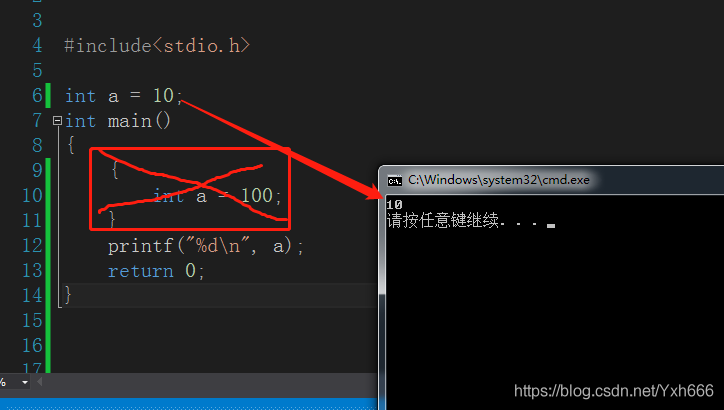
那麼這樣的話就是不可用了,這個變數在最裡面的括號中,也就是這個變數的作用域
- 全域性變數
我們在本工程裡面的原始碼中再新建立一個原始檔,看一下全域性變數的作用域
int c_a = 21;
然後在另一個原始檔就可以這樣使用
#include<stdio.h>
int main()
{
// extern 宣告外部符號,就是我們在另一個原始檔中建立的變數,這樣才可使用
extern int c_a;
printf("%d\n", c_a);
return 0;
}
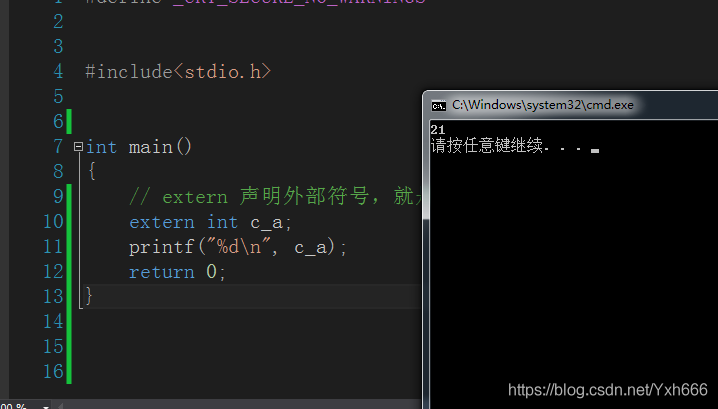
所以說全域性變數是的作用域是整個工程
2.生命週期
變數的生命週期是指變數的建立到變數的銷燬之間的的一個時間段
-
區域性變數
區域性變數的生命週期是:進入作用域生命週期開始,出作用域生命週期結束 -
全域性變數
全域性變數的生命週期是:整個程式的生命週期
那這個宣告週期我們是很難用程式碼解釋的,所以這個就是隻能是通過字面意思去理解
四、常數
C語言的常數和變數的定義的形式有所差異
C語言中的常數分為以下幾種:
- 字面常數
- const修飾的常變數
- #define定義的識別符號常數
- 列舉常數
我們分別來看:
//字面常數
#include<stdio.h>
int main()
{
3;
5;
100;
return 0;
}
//const
#include<stdio.h>
int main()
{
const int a = 8;
printf("a=%d\n", a);
a = 10;
printf("a=%d\n", a);
return 0;
}
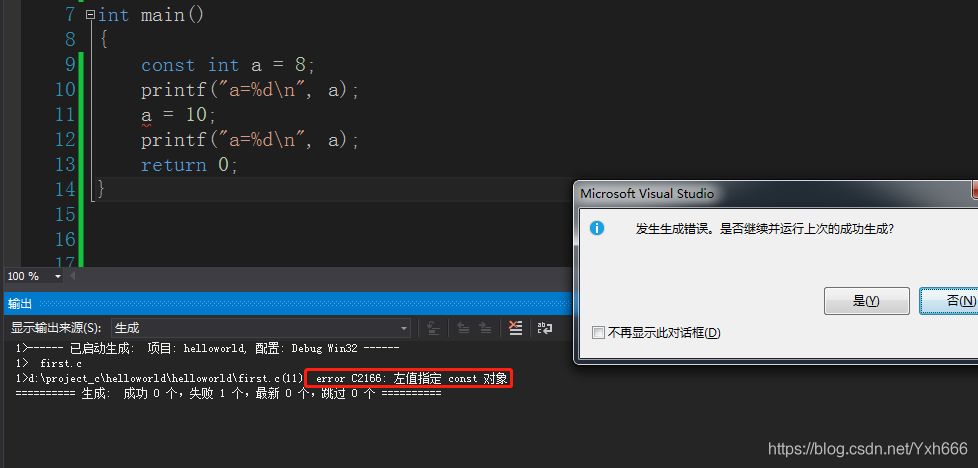
在定義的變數前面加一個const,後面再想修改變數的話就不可以了,如果去掉const,那麼修改變數是可以的
雖然被const修飾的變數是不可以被被改變的,但是變數本質還是變數,只是不能被修改,所以叫做const修飾的常變數
#define定義常數也是比較方便的
// #define
#include<stdio.h>
#define MIN 22
int main()
{
int arr[MIN] = {0};
printf("%d\n", MIN)
return 0;
}
列舉就是可以被一一列舉出來的值
//列舉常數
enum Color
{
RED,
YELLOW,
BLUE
};
int main()
{
enum Color c = BLUE; //使用列舉常數中的BLUE賦值給變數c
return 0;
}
列舉常數就是RED,YELLOW,BLUE 這個三個,這三個也是有值的,並且也是不可被改變的
int main()
{
printf("%d\n", RED);
printf("%d\n", YELLOW);
printf("%d\n", BLUE);
return 0;
}