《C++物件導向程式設計》✍千處細節、萬字總結(建議收藏)
《C++物件導向程式設計》✍千處細節、萬字總結
文章目錄
一、物件導向程式設計
物件導向程式設計(Object-Oriented Programming,OOP)是一種新的程式設計範型。程式設計範型是指設計程式的規範、模型和風格,它是一類程式設計語言的基礎。
程式導向程式設計範型是使用較廣泛的程式導向性語言,其主要特徵是:程式由過程定義和過程呼叫組成(簡單地說,過程就是程式執行某項操作的一段程式碼,函數就是最常用的過程)。
物件導向程式的基本元素是物件,物件導向程式的主要結構特點是:第一,程式一般由類的定義和類的使用兩部分組成;第二,程式中的一切操作都是通過向物件傳送訊息來實現的,物件接收到訊息後,啟動有關方法完成相應的操作。
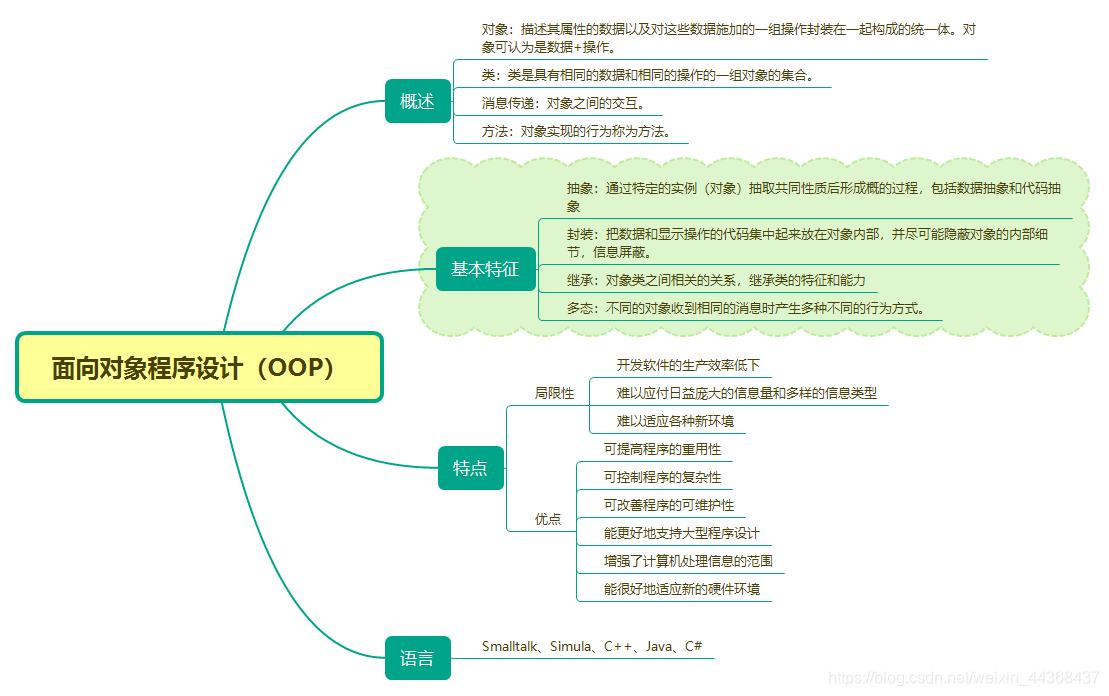
物件:描述其屬性的資料以及對這些資料施加的一組操作封裝在一起構成的統一體。物件可認為是資料+操作。
類:類是具有相同的資料和相同的操作的一組物件的集合。
訊息傳遞:物件之間的互動。
**方法:**物件實現的行為稱為方法。
物件導向程式設計的基本特徵:抽象、封裝、繼承、多型。
二、C++基礎
~
2.1 C++的產生和特點
C++是美國貝爾實驗室的Bjarne Stroustrup博士在C語言的基礎上,彌補了C語言存在的一些缺陷,增加了物件導向的特徵,於1980年開發出來的一種程式導向性與物件導向性相結合的程式設計語言。最初他把這種新的語言稱為「含類的C」,到1983年才取名為C++。
相比C語言,C++的主要特點是增加了物件導向機制。
~
2.2 一個簡單的C++範例程式
詳細建立步驟可參考部落格【Visual Studio】 建立C/C++專案
#include <iostream> //編譯預處理命令
using namespace std; //使用名稱空間
int add(int a, int b); //函數原型說明
int main() //主函數
{
int x, y;
cout << "Enter two numbers: " << endl;
cin >> x;
cin >> y;
int sum = add(x, y);
cout << "The sum is : " << sum << '\n';
return 0;
}
int add(int a, int b) //定義add()函數,函數值為整型
{
return a + b;
}
~
2.3 C++在非物件導向方面對C語言的擴充
輸入和輸出
int i;
float f;
cin >> i;
cout << f;
------------
scanf("%d", &i);
printf("%f", f);
----------------
連續讀入
cin >> a >> b >> c;
cin
- 在預設情況下,運運算元「
>>」將跳過空白符,然後讀入後面與變數型別相對應的值。因此,給一組變數輸入值時可用空格符、回車符、製表符將輸入的資料間隔開。 - 當輸入字串(即型別為string的變數)時,提取運運算元「
>>」的作用是跳過空白字元,讀入後面的非空白字元,直到遇到另一個空白字元為止,並在串尾放一個字串結束標誌‘\0’。
~
C++允許在程式碼塊中的任何地方宣告區域性變數。
const修飾符
在C語言中,習慣使用#define來定義常數,例如#define PI 3.14,C++提供了一種更靈活、更安全的方式來定義常數,即使用const修飾符來定義常數。例如const float PI = 3.14;
const可以與指標一起使用,它們的組合情況複雜,可歸納為3種:指向常數的指標、常指標和指向常數的常指標。
-
指向常數的指標:一個指向常數的指標變數。
const char* pc = "abcd"; 該方法不允許改變指標所指的變數,即 pc[3] = ‘x'; 是錯誤的, 但是,由於pc是一個指向常數的普通指標變數,不是常指標,因此可以改變pc所指的地址,例如 pc = "ervfs"; 該語句付給了指標另一個字串的地址,改變了pc的值。 -
常指標:將指標變數所指的地址宣告為常數
char* const pc = "abcd"; 建立一個常指標,一個不能移動的固定指標,可更改內容,如 pc[3] = 'x'; 但不能改變地址,如 pc = 'dsff'; 不合法 -
指向常數的常指標:這個指標所指的地址不能改變,它所指向的地址中的內容也不能改變。
const char* const pc = "abcd"; 內容和地址均不能改變
說明:
如果用const定義整型常數,關鍵字可以省略。即
const in bufsize = 100與const bufsize = 100等價;常數一旦被建立,在程式的任何地方都不能再更改。
與#define不同,const定義的常數可以有自己的資料型別。
函數引數也可以用const說明,用於保證實參在該函數內不被改動。
void型指標
void通常表示無值,但將void作為指標的型別時,它卻表示不確定的型別。這種void型指標是一種通用型指標,也就是說任何型別的指標值都可以賦給void型別的指標變數。
需要指出的是,這裡說void型指標是通用指標,是指它可以接受任何型別的指標的賦值,但對已獲值的void型指標,對它進行再處理,如輸出或者傳遞指標值時,則必須再進行顯式型別轉換,否則會出錯。
void* pc;
int i = 123;
char c = 'a';
pc = &i;
cout << pc << endl; //輸出指標地址006FF730
cout << *(int*)pc << endl; //輸出值123
pc = &c;
cout << *(char*)pc << endl; //輸出值a
行內函式
在函數名前冠以關鍵字inline,該函數就被宣告為行內函式。每當程式中出現對該函數的呼叫時,C++編譯器使用函數體中的程式碼插入到呼叫該函數的語句之處,同時使用實參代替形參,以便在程式執行時不再進行函數呼叫。引入行內函式主要是為了消除呼叫函數時的系統開銷,以提高執行速度。
說明:
- 行內函式在第一次被呼叫之前必須進行完整的定義,否則編譯器將無法知道應該插入什麼程式碼
- 在行內函式體內一般不能含有複雜的控制語句,如for語句和switch語句等
- 使用行內函式是一種空間換時間的措施,若行內函式較長,較複雜且呼叫較為頻繁時不建議使用
#include <iostream>
using namespace std;
inline double circle(double r) //行內函式
{
double PI = 3.14;
return PI * r * r;
}
int main()
{
for (int i = 1; i <= 3; i++)
cout << "r = " << i << " area = " << circle(i) << endl;
return 0;
}
使用行內函式替代宏定義,能消除宏定義的不安全性
帶有預設引數值的函數
當進行函數呼叫時,編譯器按從左到右的順序將實參與形參結合,若未指定足夠的實參,則編譯器按順序用函數原型中的預設值來補足所缺少的實參。
void init(int x = 5, int y = 10);
init (100, 19); // 100 , 19
init(25); // 25, 10
init(); // 5, 10
-
在函數原型中,所有取預設值的引數都必須出現在不取預設值的引數的右邊。
如 int fun(int a, int b, int c = 111); -
在函數呼叫時,若某個引數省略,則其後的引數皆應省略而採取預設值。不允許某個引數省略後,再給其後的引數指定引數值。
函數過載
在C++中,使用者可以過載函數。這意味著,在同一作用域內,只要函數引數的型別不同,或者引數的個數不同,或者二者兼而有之,兩個或者兩個以上的函數可以使用相同的函數名。
#include <iostream>
using namespace std;
int add(int x, int y)
{
return x + y;
}
double add(double x, double y)
{
return x + y;
}
int add(int x, int y, int z)
{
return x + y + z;
}
int main()
{
int a = 3, b = 5, c = 7;
double x = 10.334, y = 8.9003;
cout << add(a, b) << endl;
cout << add(x, y) << endl;
cout << add(a, b, c) << endl;
return 0;
}
說明:
-
呼叫過載函數時,函數返回值型別不在引數匹配檢查之列。因此,若兩個函數的引數個數和型別都相同,而只有返回值型別不同,則不允許過載。
int mul(int x, int y); double mul(int x, int y); -
函數的過載與帶預設值的函數一起使用時,有可能引起二義性。
void Drawcircle(int r = 0, int x = 0, int y = 0); void Drawcircle(int r); Drawcircle(20); -
在呼叫函數時,如果給出的實參和形參型別不相符,C++的編譯器會自動地做型別轉換工作。如果轉換成功,則程式繼續執行,在這種情況下,有可能產生不可識別的錯誤。
void f_a(int x); void f_a(long x); f_a(20.83);
作用域識別符號"::"
通常情況下,如果有兩個同名變數,一個是全域性的,另一個是區域性的,那麼區域性變數在其作用域內具有較高的優先權,它將遮蔽全域性變數。
如果希望在區域性變數的作用域內使用同名的全域性變數,可以在該變數前加上「::」,此時::value代表全域性變數value,「::」稱為作用域識別符號。
#include <iostream>
using namespace std;
int value; //定義全域性變數value
int main()
{
int value; //定義區域性變數value
value = 100;
::value = 1000;
cout << "local value : " << value << endl;
cout << "global value : " << ::value << endl;
return 0;
}
強制型別轉換
可用強制型別轉換將不同型別的資料進行轉換。例如,要把一個整型數(int)轉換為雙精度型數(double),可使用如下的格式:
int i = 10;
double x = (double)i;
或
int i = 10;
double x = double(i);
以上兩種方法C++都能接受,建議使用後一種方法。
new和delete運運算元
程式執行時,計算機的記憶體被分為4個區:程式程式碼區、全域性資料區、堆和棧。其中,堆可由使用者分配和釋放。C語言中使用函數malloc()和free()來進行動態記憶體管理。C++則提供了運運算元new和delete來做同樣的工作,而且後者比前者效能更優越,使用更靈活方便。
指標變數名 = new 型別
int *p;
p = new int;
delete 指標變數名
delete p;
下面對new和delete的使用再做一下幾點說明:
-
用運運算元new分配的空間,使用結束後應該用也只能用delete顯式地釋放,否則這部分空間將不能回收而變成死空間。
-
在使用運運算元new動態分配記憶體時,如果沒有足夠的記憶體滿足分配要求,new將返回空指標(
NULL)。 -
使用運運算元new可以為陣列動態分配記憶體空間,這時需要在型別後面加上陣列大小。
指標變數名 = new 型別名[下標表示式]; int *p = new int[10];釋放動態分配的陣列儲存區時,可使用delete運運算元。
delete []指標變數名; delete p; -
new 可在為簡單變數分配空間的同時,進行初始化
指標變數名 = new 型別名(初值); int *p; p = new int(99); ··· delete p;
參照
參照(reference)是C++對C的一個重要擴充。變數的參照就是變數的別名,因此參照又稱別名。
型別 &參照名 = 已定義的變數名
參照與其所代表的變數共用同一記憶體單元,系統並不為參照另外分配儲存空間。實際上,編譯系統使參照和其代表的變數具有相同的地址。
#include <iostream>
using namespace std;
int main()
{
int i = 10;
int &j = i;
cout << "i = " << i << " j = " << j << endl;
cout << "i的地址為 " << &i << endl;
cout << "j的地址為 " << &j << endl;
return 0;
}
上面程式碼輸出i和j的值相同,地址也相同。
- 參照並不是一種獨立的資料型別,它必須與某一種型別的變數相聯絡。在宣告參照時,必須立即對它進行初始化,不能宣告完成後再賦值。
- 為參照提供的初始值,可以是一個變數或者另一個參照。
- 指標是通過地址間接存取某個變數,而參照則是通過別名直接存取某個變數。
參照作為函數引數、使用參照返回函數值
#include <iostream>
using namespace std;
void swap(int &a, int &b)
{
int t = a;
a = b;
b = t;
}
int a[] = {1, 3, 5, 7, 9};
int& index(int i)
{
return a[i];
}
int main()
{
int a = 5, b = 10;
//交換數位a和b
swap(a, b);
cout << "a = " << a << " b = " << b << endl;
cout << index(2) << endl; //等價於輸出元素a[2]的值
index(2) = 100; //等價於將a[2]的值賦為100;
cout << index(2) << endl;
return 0;
}
對參照的進一步說明
- 不允許建立void型別的參照
- 不能建立參照的陣列
- 不能建立參照的參照。不能建立指向參照的指標。參照本身不是一種資料型別,所以沒有參照的參照,也沒有參照的指標。
- 可以將參照的地址賦值給一個指標,此時指標指向的是原來的變數。
- 可以用const對參照加以限定,不允許改變該參照的值,但是它不阻止參照所代表的變數的值。
三、類和物件(一)
~
3.1 類的構成
類宣告中的內容包括資料和函數,分別稱為資料成員和成員函數。按存取許可權劃分,資料成員和成員函數又可分為共有、保護和私有3種。
class 類名{
public:
公有資料成員;
公有成員函數;
protected:
保護資料成員;
保護成員函數;
private:
私有資料成員;
私有成員函數;
};
如成績類
class Score{
public:
void setScore(int m, int f);
void showScore();
private:
int mid_exam;
int fin_exam;
};
- 對一個具體的類來講,類宣告格式中的3個部分並非一定要全有,但至少要有其中的一個部分。一般情況下,一個類的資料成員應該宣告為私有成員,成員函數宣告為共有成員。這樣,內部的資料整個隱蔽在類中,在類的外部根本就無法看到,使資料得到有效的保護,也不會對該類以外的其餘部分造成影響,程式之間的相互作用就被降低到最小。
- 類宣告中的關鍵字private、protected、public可以任意順序出現。
- 若私有部分處於類的第一部分時,關鍵字private可以省略。這樣,如果一個類體中沒有一個存取許可權關鍵字,則其中的資料成員和成員函數都預設為私有的。
- 不能在類宣告中給資料成員賦初值。
~
3.2 成員函數的定義
普通成員函數的定義
在類的宣告中只給出成員函數的原型,而成員函數的定義寫在類的外部。這種成員函數在類外定義的一般形式是:
返回值型別 類名::成員函數名(參數列){ 函數體}
例如,表示分數的類Score可宣告如下:
class Score{
public:
void setScore(int m, int f);
void showScore();
private:
int mid_exam;
int fin_exam;
};
void Score::setScore(int m, int f)
{
mid_exam = m;
fin_exam = f;
}
void Score::showScore()
{
cout << "期中成績: " << mid_exam << endl;
cout << "期末成績:" << fin_exam << endl;
}
內聯成員函數的定義
- 隱式宣告:將成員函數直接定義在類的內部
class Score{
public:
void setScore(int m, int f)
{
mid_exam = m;
fin_exam = f;
}
void showScore()
{
cout << "期中成績: " << mid_exam << endl;
cout << "期末成績:" << fin_exam << endl;
}
private:
int mid_exam;
int fin_exam;
};
- 顯式宣告:在類宣告中只給出成員函數的原型,而將成員函數的定義放在類的外部。
class Score{
public:
inline void setScore(int m, int f);
inline void showScore();
private:
int mid_exam;
int fin_exam;
};
inline void Score::setScore(int m, int f)
{
mid_exam = m;
fin_exam = f;
}
inline void Score::showScore()
{
cout << "期中成績: " << mid_exam << endl;
cout << "期末成績:" << fin_exam << endl;
}
說明:在類中,使用inline定義行內函式時,必須將類的宣告和內聯成員函數的定義都放在同一個檔案(或同一個標頭檔案)中,否則編譯時無法進行程式碼置換。
~
3.3 物件的定義和使用
通常把具有共同屬性和行為的事物所構成的集合稱為類。
類的物件可以看成該類型別的一個範例,定義一個物件和定義一個一般變數相似。
物件的定義
- 在宣告類的同時,直接定義物件
class Score{
public:
void setScore(int m, int f);
void showScore();
private:
int mid_exam;
int fin_exam;
}op1, op2;
- 宣告了類之後,在使用時再定義物件
Score op1, op2;
物件中成員的存取
物件名.資料成員名物件名.成員函數名[(參數列)]op1.setScore(89, 99);
op1.showScore();
說明:
-
在類的內部所有成員之間都可以通過成員函數直接存取,但是類的外部不能存取物件的私有成員。
-
在定義物件時,若定義的是指向此物件的指標變數,則存取此物件的成員時,不能用「
.」操作符,而應該使用「->「操作符。如Score op, *sc; sc = &op; sc->setScore(99, 100); op.showScore();
類的作用域和類成員的存取屬性
私有成員只能被類中的成員函數存取,不能在類的外部,通過類的物件進行存取。
一般來說,公有成員是類的對外介面,而私有成員是類的內部資料和內部實現,不希望外界存取。將類的成員劃分為不同的存取級別有兩個好處:一是資訊隱蔽,即實現封裝,將類的內部資料與內部實現和外部介面分開,這樣使該類的外部程式不需要了解類的詳細實現;二是資料保護,即將類的重要資訊保護起來,以免其他程式進行不恰當的修改。
物件賦值語句
Score op1, op2;
op1.setScore(99, 100);
op2 = op1;
op2.showScore();
~
3.4 建構函式與解構函式
建構函式
建構函式是一種特殊的成員函數,它主要用於為物件分配空間,進行初始化。建構函式的名字必須與類名相同,而不能由使用者任意命名。它可以有任意型別的引數,但不能具有返回值。它不需要使用者來呼叫,而是在建立物件時自動執行。
class Score{
public:
Score(int m, int f); //建構函式
void setScore(int m, int f);
void showScore();
private:
int mid_exam;
int fin_exam;
};
Score::Score(int m, int f)
{
mid_exam = m;
fin_exam = f;
}
在建立物件的同時,採用建構函式給資料成員賦值,通常由以下兩種形式
-
類名 物件名[(實參表)] Score op1(99, 100); op1.showScore(); -
類名 *指標變數名 = new 類名[(實參表)] Score *p; p = new Score(99, 100); p->showScore(); ----------------------- Score *p = new Score(99, 100); p->showScore();
說明:
- 建構函式的名字必須與類名相同,否則編譯程式將把它當做一般的成員函數來處理。
- 建構函式沒有返回值,在定義建構函式時,是不能說明它的型別的。
- 與普通的成員函數一樣,建構函式的函數體可以寫在類體內,也可寫在類體外。
- 建構函式一般宣告為共有成員,但它不需要也不能像其他成員函數那樣被顯式地呼叫,它是在定義物件的同時被自動呼叫,而且只執行一次。
- 建構函式可以不帶引數。
成員初始化列表
在宣告類時,對資料成員的初始化工作一般在建構函式中用賦值語句進行。此外還可以用成員初始化列表實現對資料成員的初始化。
類名::建構函式名([參數列])[:(成員初始化列表)]
{
//建構函式體
}
class A{
private:
int x;
int& rx;
const double pi;
public:
A(int v) : x(v), rx(x), pi(3.14) //成員初始化列表
{ }
void print()
{
cout << "x = " << x << " rx = " << rx << " pi = " << pi << endl;
}
};
**說明:**類成員是按照它們在類裡被宣告的順序進行初始化的,與它們在成員初始化列表中列出的順序無關。
帶預設引數的建構函式
#include <iostream>
using namespace std;
class Score{
public:
Score(int m = 0, int f = 0); //帶預設引數的建構函式
void setScore(int m, int f);
void showScore();
private:
int mid_exam;
int fin_exam;
};
Score::Score(int m, int f) : mid_exam(m), fin_exam(f)
{
cout << "建構函式使用中..." << endl;
}
void Score::setScore(int m, int f)
{
mid_exam = m;
fin_exam = f;
}
void Score::showScore()
{
cout << "期中成績: " << mid_exam << endl;
cout << "期末成績:" << fin_exam << endl;
}
int main()
{
Score op1(99, 100);
Score op2(88);
Score op3;
op1.showScore();
op2.showScore();
op3.showScore();
return 0;
}
解構函式
解構函式也是一種特殊的成員函數。它執行與建構函式相反的操作,通常用於復原物件時的一些清理任務,如釋放分配給物件的記憶體空間等。解構函式有以下一些特點:
- 解構函式與建構函式名字相同,但它前面必須加一個波浪號(~)。
- 解構函式沒有引數和返回值,也不能被過載,因此只有一個。
- 當復原物件時,編譯系統會自動呼叫解構函式。
class Score{
public:
Score(int m = 0, int f = 0);
~Score(); //解構函式
private:
int mid_exam;
int fin_exam;
};
Score::Score(int m, int f) : mid_exam(m), fin_exam(f)
{
cout << "建構函式使用中..." << endl;
}
Score::~Score()
{
cout << "解構函式使用中..." << endl;
}
**說明:**在以下情況中,當物件的生命週期結束時,解構函式會被自動呼叫:
- 如果定義了一個全域性物件,則在程式流程離開其作用域時,呼叫該全域性物件的解構函式。
- 如果一個物件定義在一個函數體內,則當這個函數被呼叫結束時,該物件應該被釋放,解構函式被自動呼叫。
- 若一個物件是使用
new運運算元建立的,在使用delete運運算元釋放它時,delete會自動呼叫解構函式。
如下範例:
#include <iostream>
#include <string>
using namespace std;
class Student{
private:
char *name;
char *stu_no;
float score;
public:
Student(char *name1, char *stu_no1, float score1);
~Student();
void modify(float score1);
void show();
};
Student::Student(char *name1, char *stu_no1, float score1)
{
name = new char[strlen(name1) + 1];
strcpy(name, name1);
stu_no = new char[strlen(stu_no1) + 1];
strcpy(stu_no, stu_no1);
score = score1;
}
Student::~Student()
{
delete []name;
delete []stu_no;
}
void Student::modify(float score1)
{
score = score1;
}
void Student::show()
{
cout << "姓名: " << name << endl;
cout << "學號: " << stu_no << endl;
cout << "成績:" << score << endl;
}
int main()
{
Student stu("雪女", "2020199012", 99);
stu.modify(100);
stu.show();
return 0;
}
預設的建構函式和解構函式
如果沒有給類定義建構函式,則編譯系統自動生成一個預設的建構函式。
說明:
-
對沒有定義建構函式的類,其公有資料成員可以用初始值列表進行初始化。
class A{ public: char name[10]; int no; }; A a = {"chen", 23}; cout << a.name << a.no << endl; -
只要一個類定義了一個建構函式(不一定是無參建構函式),系統將不再給它提供預設的建構函式。
每個類必須有一個解構函式。若沒有顯示地為一個類定義解構函式,編譯系統會自動生成一個預設的解構函式。
建構函式的過載
class Score{
public:
Score(int m, int f); //建構函式
Score();
void setScore(int m, int f);
void showScore();
private:
int mid_exam;
int fin_exam;
};
**注意:**在一個類中,當無引數的建構函式和帶預設引數的建構函式過載時,有可能產生二義性。
拷貝建構函式
拷貝建構函式是一種特殊的建構函式,其形參是本類物件的參照。拷貝建構函式的作用是在建立一個新物件時,使用一個已存在的物件去初始化這個新物件。
拷貝建構函式具有以下特點:
- 因為拷貝建構函式也是一種建構函式,所以其函數名與類名相同,並且該函數也沒有返回值。
- 拷貝建構函式只有一個引數,並且是同類物件的參照。
- 每個類都必須有一個拷貝建構函式。可以自己定義拷貝建構函式,用於按照需要初始化新物件;如果沒有定義類的拷貝建構函式,系統就會自動生成一個預設拷貝建構函式,用於複製出與資料成員值完全相同的新物件。
自定義拷貝建構函式
類名::類名(const 類名 &物件名)
{
拷貝建構函式的函數體;
}
class Score{
public:
Score(int m, int f); //建構函式
Score();
Score(const Score &p); //拷貝建構函式
~Score(); //解構函式
void setScore(int m, int f);
void showScore();
private:
int mid_exam;
int fin_exam;
};
Score::Score(int m, int f)
{
mid_exam = m;
fin_exam = f;
}
Score::Score(const Score &p)
{
mid_exam = p.mid_exam;
fin_exam = p.fin_exam;
}
呼叫拷貝建構函式的一般形式為:
類名 物件2(物件1);
類名 物件2 = 物件1;
Score sc1(98, 87);
Score sc2(sc1); //呼叫拷貝建構函式
Score sc3 = sc2; //呼叫拷貝建構函式
呼叫拷貝建構函式的三種情況:
- 當用類的一個物件去初始化該類的另一個物件時;
- 當函數的形參是類的物件,呼叫函數進行形參和實參結合時;
- 當函數的返回值是物件,函數執行完成返回撥用者時。
淺拷貝和深拷貝
淺拷貝,就是由預設的拷貝建構函式所實現的資料成員逐一賦值。通常預設的拷貝建構函式是能夠勝任此工作的,但若類中含有指標型別的資料,則這種按資料成員逐一賦值的方法會產生錯誤。
class Student{
public:
Student(char *name1, float score1);
~Student();
private:
char *name;
float score;
};
如下語句會產生錯誤
Student stu1("白", 89);
Student stu2 = stu1;
上述錯誤是因為stu1和stu2所指的記憶體空間相同,在解構函式釋放stu1所指的記憶體後,再釋放stu2所指的記憶體會發生錯誤,因為此記憶體空間已被釋放。解決方法就是重定義拷貝建構函式,為其變數重新生成記憶體空間。
Student::Student(const Student& stu)
{
name = new char[strlen(stu.name) + 1];
if (name != 0) {
strcpy(name, stu.name);
score = stu.score;
}
}
四、類和物件(二)
~
4.1 自參照指標this
this指標儲存當前物件的地址,稱為自參照指標。
void Sample::copy(Sample& xy)
{
if (this == &xy) return;
*this = xy;
}
~
4.2 物件陣列與物件指標
物件陣列
類名 陣列名[下標表示式]
用只有一個引數的建構函式給物件陣列賦值
Exam ob[4] = {89, 97, 79, 88};
用不帶引數和帶一個引數的建構函式給物件陣列賦值
Exam ob[4] = {89, 90};
用帶有多個引數的建構函式給物件陣列賦值
Score rec[3] = {Score(33, 99), Score(87, 78), Score(99, 100)};
物件指標
每一個物件在初始化後都會在記憶體中佔有一定的空間。因此,既可以通過物件名存取物件,也可以通過物件地址來存取物件。物件指標就是用於存放物件地址的變數。宣告物件指標的一半語法形式為:類名 *物件指標名
Score score;
Score *p;
p = &score;
p->成員函數();
用物件指標存取物件陣列
Score score[2];
score[0].setScore(90, 99);
score[1].setScore(67, 89);
Score *p;
p = score; //將物件score的地址賦值給p
p->showScore();
p++; //物件指標變數加1
p->showSccore();
Score *q;
q =&score[1]; //將第二個陣列元素的地址賦值給物件指標變數q
~
4.3 string類
C++支援兩種型別的字串,第一種是C語言中介紹過的、包括一個結束符’\0’(即以NULL結束)的字元陣列,標準庫函數提供了一組對其進行操作的函數,可以完成許多常用的字串操作。
C++標準庫中宣告了一種更方便的字串型別,即字串類string,類string提供了對字串進行處理所需要的操作。使用string類必須在程式的開始包括標頭檔案string,即要有以下語句:#include <string>
常用的string類運運算元如下:
=、+、+=、==、!=、<、<=、>、>=、[](存取下標對應字元)、>>(輸入)、<<(輸出)
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str1 = "ABC";
string str2("dfdf");
string str3 = str1 + str2;
cout<< "str1 = " << str1 << " str2 = " << str2 << " str3 = " << str3 << endl;
str2 += str2;
str3 += "aff";
cout << "str2 = " << str2 << " str3 = " << str3 << endl;
cout << "str1[1] = " << str1[1] << " str1 == str2 ? " << (str1 == str2) << endl;
string str = "ABC";
cout << "str == str1 ? " << (str == str1) << endl;
return 0;
}
~
4.4 向函數傳遞物件
- 使用物件作為函數引數:物件可以作為引數傳遞給函數,其方法與傳遞其他型別的資料相同。在向函數傳遞物件時,是通過「傳值呼叫」的方法傳遞給函數的。因此,函數中對物件的任何修改均不影響呼叫該函數的物件(實參本身)。
- 使用物件指標作為函數引數:物件指標可以作為函數的引數,使用物件指標作為函數引數可以實現傳值呼叫,即在函數呼叫時使實參物件和形參物件指標變數指向同一記憶體地址,在函數呼叫過程中,形參物件指標所指的物件值的改變也同樣影響著實參物件的值。
- 使用物件參照作為函數引數:在實際中,使用物件參照作為函數引數非常普遍,大部分程式設計師喜歡使用物件參照替代物件指標作為函數引數。因為使用物件參照作為函數引數不但具有用物件指標做函數引數的優點,而且用物件參照作函數引數將更簡單、更直接。
#include <iostream>
using namespace std;
class Point{
public:
int x;
int y;
Point(int x1, int y1) : x(x1), y(y1) //成員初始化列表
{ }
int getDistance()
{
return x * x + y * y;
}
};
void changePoint1(Point point) //使用物件作為函數引數
{
point.x += 1;
point.y -= 1;
}
void changePoint2(Point *point) //使用物件指標作為函數引數
{
point->x += 1;
point->y -= 1;
}
void changePoint3(Point &point) //使用物件參照作為函數引數
{
point.x += 1;
point.y -= 1;
}
int main()
{
Point point[3] = {Point(1, 1), Point(2, 2), Point(3, 3)};
Point *p = point;
changePoint1(*p);
cout << "the distance is " << p[0].getDistance() << endl;
p++;
changePoint2(p);
cout << "the distance is " << p->getDistance() << endl;
changePoint3(point[2]);
cout << "the distance is " << point[2].getDistance() << endl;
return 0;
}
~
4.5 靜態成員
靜態資料成員
在一個類中,若將一個資料成員說明為static,則這種成員被稱為靜態資料成員。與一般的資料成員不同,無論建立多少個類的物件,都只有一個靜態資料成員的拷貝。從而實現了同一個類的不同物件之間的資料共用。
定義靜態資料成員的格式如下:static 資料型別 資料成員名;
說明:
-
靜態資料成員的定義與普通資料成員相似,但前面要加上static關鍵字。
-
靜態資料成員的初始化與普通資料成員不同。靜態資料成員初始化應在類外單獨進行,而且應在定義物件之前進行。一般在main()函數之前、類宣告之後的特殊地帶為它提供定義和初始化。
-
靜態資料成員屬於類(準確地說,是屬於類中物件的集合),而不像普通資料成員那樣屬於某一物件,因此,可以使用「
類名::」存取靜態的資料成員。格式如下:類名::靜態資料成員名。 -
靜態資料成員與靜態變數一樣,是在編譯時建立並初始化。它在該類的任何物件被建立之前就存在。因此,共有的靜態資料成員可以在物件定義之前被存取。物件定以後,共有的靜態資料成員也可以通過物件進行存取。其存取格式如下
物件名.靜態資料成員名; 物件指標->靜態資料成員名;
靜態成員函數
在類定義中,前面有static說明的成員函數稱為靜態成員函數。靜態成員函數屬於整個類,是該類所有物件共用的成員函數,而不屬於類中的某個物件。靜態成員函數的作用不是為了物件之間的溝通,而是為了處理靜態資料成員。定義靜態成員函數的格式如下:
static 返回型別 靜態成員函數名(參數列);
與靜態資料成員類似,呼叫公有靜態成員函數的一般格式有如下幾種:
類名::靜態成員函數名(實參表);
物件.靜態成員函數名(實參表);
物件指標->靜態成員函數名(實參表);
一般而言,靜態成員函數不存取類中的非靜態成員。若確實需要,靜態成員函數只能通過物件名(或物件指標、物件參照)存取該物件的非靜態成員。
下面對靜態成員函數的使用再做幾點說明:
- 一般情況下,靜態函數成員主要用來存取靜態成員函數。當它與靜態資料成員一起使用時,達到了對同一個類中物件之間共用資料的目的。
- 私有靜態成員函數不能被類外部的函數和物件存取。
- 使用靜態成員函數的一個原因是,可以用它在建立任何物件之前呼叫靜態成員函數,以處理靜態資料成員,這是普通成員函數不能實現的功能
- 編譯系統將靜態成員函數限定為內部連線,也就是說,與現行檔案相連線的其他檔案中的同名函數不會與該函數發生衝突,維護了該函數使用的安全性,這是使用靜態成員函數的另一個原因。
- 靜態成員函數是類的一部分,而不是物件的一部分。如果要在類外呼叫公有的靜態成員函數,使用如下格式較好:
類名::靜態成員函數名()
#include <iostream>
using namespace std;
class Score{
private:
int mid_exam;
int fin_exam;
static int count; //靜態資料成員,用於統計學生人數
static float sum; //靜態資料成員,用於統計期末累加成績
static float ave; //靜態資料成員,用於統計期末平均成績
public:
Score(int m, int f);
~Score();
static void show_count_sum_ave(); //靜態成員函數
};
Score::Score(int m, int f)
{
mid_exam = m;
fin_exam = f;
++count;
sum += fin_exam;
ave = sum / count;
}
Score::~Score()
{
}
/*** 靜態成員初始化 ***/
int Score::count = 0;
float Score::sum = 0.0;
float Score::ave = 0.0;
void Score::show_count_sum_ave()
{
cout << "學生人數: " << count << endl;
cout << "期末累加成績: " << sum << endl;
cout << "期末平均成績: " << ave << endl;
}
int main()
{
Score sco[3] = {Score(90, 89), Score(78, 99), Score(89, 88)};
sco[2].show_count_sum_ave();
Score::show_count_sum_ave();
return 0;
}
~
4.6 友元
類的主要特點之一是資料隱藏和封裝,即類的私有成員(或保護成員)只能在類定義的範圍內使用,也就是說私有成員只能通過它的成員函數來存取。但是,有時為了存取類的私有成員而需要在程式中多次呼叫成員函數,這樣會因為頻繁呼叫帶來較大的時間和空間開銷,從而降低程式的執行效率。為此,C++提供了友元來對私有或保護成員進行存取。友元包括友元函數和友元類。
友元函數
友元函數既可以是不屬於任何類的非成員函數,也可以是另一個類的成員函數。友元函數不是當前類的成員函數,但它可以存取該類的所有成員,包括私有成員、保護成員和公有成員。
在類中宣告友元函數時,需要在其函數名前加上關鍵字friend。此宣告可以放在公有部分,也可以放在保護部分和私有部分。友元函數可以定義在類內部,也可以定義在類外部。
1、將非成員函數宣告為友元函數
#include <iostream>
using namespace std;
class Score{
private:
int mid_exam;
int fin_exam;
public:
Score(int m, int f);
void showScore();
friend int getScore(Score &ob);
};
Score::Score(int m, int f)
{
mid_exam = m;
fin_exam = f;
}
int getScore(Score &ob)
{
return (int)(0.3 * ob.mid_exam + 0.7 * ob.fin_exam);
}
int main()
{
Score score(98, 78);
cout << "成績為: " << getScore(score) << endl;
return 0;
}
說明:
- 友元函數雖然可以存取類物件的私有成員,但他畢竟不是成員函數。因此,在類的外部定義友元函數時,不必像成員函數那樣,在函數名前加上「
類名::」。 - 因為友元函數不是類的成員,所以它不能直接存取物件的資料成員,也不能通過this指標存取物件的資料成員,它必須通過作為入口引數傳遞進來的物件名(或物件指標、物件參照)來存取該物件的資料成員。
- 友元函數提供了不同類的成員函數之間、類的成員函數與一般函數之間進行資料共用的機制。尤其當一個函數需要存取多個類時,友元函數非常有用,普通的成員函數只能存取其所屬的類,但是多個類的友元函數能夠存取相關的所有類的資料。
例子:一個函數同時定義為兩個類的友元函數
#include <iostream>
#include <string>
using namespace std;
class Score; //對Score類的提前參照說明
class Student{
private:
string name;
int number;
public:
Student(string na, int nu) {
name = na;
number = nu;
}
friend void show(Score &sc, Student &st);
};
class Score{
private:
int mid_exam;
int fin_exam;
public:
Score(int m, int f) {
mid_exam = m;
fin_exam = f;
}
friend void show(Score &sc, Student &st);
};
void show(Score &sc, Student &st) {
cout << "姓名:" << st.name << " 學號:" << st.number << endl;
cout << "期中成績:" << sc.mid_exam << " 期末成績:" << sc.fin_exam << endl;
}
int main() {
Score sc(89, 99);
Student st("白", 12467);
show(sc, st);
return 0;
}
2、將成員函數宣告為友元函數
一個類的成員函數可以作為另一個類的友元,它是友元函數中的一種,稱為友元成員函數。友元成員函數不僅可以存取自己所在類物件中的私有成員和公有成員,還可以存取friend宣告語句所在類物件中的所有成員,這樣能使兩個類相互合作、協調工作,完成某一任務。
#include <iostream>
#include <string>
using namespace std;
class Score; //對Score類的提前參照說明
class Student{
private:
string name;
int number;
public:
Student(string na, int nu) {
name = na;
number = nu;
}
void show(Score &sc);
};
class Score{
private:
int mid_exam;
int fin_exam;
public:
Score(int m, int f) {
mid_exam = m;
fin_exam = f;
}
friend void Student::show(Score &sc);
};
void Student::show(Score &sc) {
cout << "姓名:" << name << " 學號:" << number << endl;
cout << "期中成績:" << sc.mid_exam << " 期末成績:" << sc.fin_exam << endl;
}
int main() {
Score sc(89, 99);
Student st("白", 12467);
st.show(sc);
return 0;
}
說明:
- 一個類的成員函數作為另一個類的友元函數時,必須先定義這個類。並且在宣告友元函數時,需要加上成員函數所在類的類名;
友元類
可以將一個類宣告為另一個類的友元
class Y{
···
};
class X{
friend Y; //宣告類Y為類X的友元類
};
當一個類被說明為另一個類的友元類時,它所有的成員函數都成為另一個類的友元函數,這就意味著作為友元類中的所有成員函數都可以存取另一個類中的所有成員。
友元關係不具有交換性和傳遞性。
~
4.7 類的組合
在一個類中內嵌另一個類的物件作為資料成員,稱為類的組合。該內嵌物件稱為物件成員,又稱為子物件。
class Y{
···
};
class X{
Y y;
···
};
~
4.8 共用資料的保護
常型別的引入就是為了既保護資料共用又防止資料被改動。常型別是指使用型別修飾符const說明的型別,常型別的變數或物件成員的值在程式執行期間是不可改變的。
常參照
如果在說明參照時用const修飾,則被說明的參照為常參照。常參照所參照的物件不能被更新。如果用常參照做形參,便不會產生對實參的不希望的更改。
const 型別& 參照名
int a = 5;
const int& b = a;
此時再對b賦值是非法的。
---------------------------
int add(const int& m, const int& n) {
return m + n;
}
在此函數中對變數m和變數n更新時非法的
常物件
如果在說明物件時用const修飾,則被說明的物件為常物件。常物件中的資料成員為常數且必須要有初值。
類名 const 物件名[(參數列)];
const Date date(2021, 5, 31);
常物件成員
1、常資料成員
類的資料成員可以是常數或常參照,使用const說明的資料成員稱為常資料成員。如果在一個類中說明了常資料成員,那麼建構函式就只能通過成員初始化列表對該資料成員進行初始化,而任何其他函數都不能對該成員賦值。
class Date{
private:
int year;
int month;
int day;
public:
Date(int y, int m, int d) : year(y), month(m), day(d) {
}
};
一旦某物件的常資料成員初始化後,該資料成員的值是不能改變的。
2、常成員函數
型別 函數名(參數列) const;
const是函數型別的一個組成部分,因此在宣告函數和定義函數時都要有關鍵字const。在呼叫時不必加const。
class Date{
private:
int year;
int month;
int day;
public:
Date(int y, int m, int d) : year(y), month(m), day(d){
}
void showDate();
void showDate() const;
};
void Date::showDate() {
//···
}
void Date::showDate() const {
//···
}
關鍵字const可以被用於對過載函數進行區分。
說明:
- 常成員函數可以存取常資料成員,也可以存取普通資料成員。
- 常物件只能呼叫它的常成員物件,而不能呼叫普通成員函數。常成員函數是常物件唯一的對外介面。
- 常物件函數不能更新物件的資料成員,也不能呼叫該類的普通成員函數,這就保證了在常成員函數中絕不會更新資料成員的值。
五、繼承與派生
繼承可以在已有類的基礎上建立新的類,新類可以從一個或多個已有類中繼承成員函數和資料成員,而且可以重新定義或加進新的資料和函數,從而形成類的層次或等級。其中,已有類稱為基礎類別或父類別,在它基礎上建立的新類稱為派生類或子類。
~
5.1 繼承與派生的概念
類的繼承是新的類從已有類那裡得到已有的特性。從另一個角度來看這個問題,從已有類產生新類的過程就是類的派生。類的繼承和派生機制較好地解決了程式碼重用的問題。
關於基礎類別和派生類的關係,可以表述為:派生類是基礎類別的具體化,而基礎類別則是派生類的抽象。
使用繼承的案例如下:
#include <iostream>
#include <string>
using namespace std;
class Person{
private:
string name;
string id_number;
int age;
public:
Person(string name1, string id_number1, int age1) {
name = name1;
id_number = id_number1;
age = age1;
}
~Person() {
}
void show() {
cout << "姓名: " << name << " 身份證號: " << id_number << " 年齡: " << age << endl;
}
};
class Student:public Person{
private:
int credit;
public:
Student(string name1, string id_number1, int age1, int credit1):Person(name1, id_number1, credit1) {
credit = credit1;
}
~Student() {
}
void show() {
Person::show();
cout << "學分: " << credit << endl;
}
};
int main() {
Student stu("白", "110103**********23", 12, 123);
stu.show();
return 0;
}
從已有類派生出新類時,可以在派生類內完成以下幾種功能:
- 可以增加新的資料成員和成員函數
- 可以對基礎類別的成員進行重定義
- 可以改變基礎類別成員在派生類中的存取屬性
基礎類別成員在派生類中的存取屬性
派生類可以繼承基礎類別中除了建構函式與解構函式之外的成員,但是這些成員的存取屬性在派生過程中是可以調整的。從基礎類別繼承來的成員在派生類中的存取屬性也有所不同。
| 基礎類別中的成員 | 繼承方式 | 基礎類別在派生類中的存取屬性 |
|---|---|---|
| private | public|protected|private | 不可直接存取 |
| public | public|protected|private | public|protected|private |
| protected | public|protected|private | protected|protected|private |
派生類對基礎類別成員的存取規則
基礎類別的成員可以有public、protected、private3中存取屬性,基礎類別的成員函數可以存取基礎類別中其他成員,但是在類外通過基礎類別的物件,就只能存取該基礎類別的公有成員。同樣,派生類的成員也可以有public、protected、private3種存取屬性,派生類的成員函數可以存取派生類中自己增加的成員,但是在派生類外通過派生類的物件,就只能存取該派生類的公有成員。
派生類對基礎類別成員的存取形式主要有以下兩種:
- 內部存取:由派生類中新增的成員函數對基礎類別繼承來的成員的存取。
- 物件存取:在派生類外部,通過派生類的物件對從基礎類別繼承來的成員的存取。
~
5.2 派生類別建構函式和解構函式
建構函式的主要作用是對資料進行初始化。在派生類中,如果對派生類新增的成員進行初始化,就需要加入派生類別建構函式。與此同時,對所有從基礎類別繼承下來的成員的初始化工作,還是由基礎類別的建構函式完成,但是基礎類別的建構函式和解構函式不能被繼承,因此必須在派生類別建構函式中對基礎類別的建構函式所需要的引數進行設定。同樣,對復原派生類物件的掃尾、清理工作也需要加入新的解構函式來完成。
呼叫順序
#include <iostream>
#include <string>
using namespace std;
class A{
public:
A() {
cout << "A類物件構造中..." << endl;
}
~A() {
cout << "解構A類物件..." << endl;
}
};
class B : public A{
public:
B() {
cout << "B類物件構造中..." << endl;
}
~B(){
cout << "解構B類物件..." << endl;
}
};
int main() {
B b;
return 0;
}
程式碼執行結果如下:
A類物件構造中...
B類物件構造中...
解構B類物件...
解構A類物件...
可見:建構函式的呼叫嚴格地按照先呼叫基礎類別的建構函式,後呼叫派生類別建構函式的順序執行。解構函式的呼叫順序與建構函式的呼叫順序正好相反,先呼叫派生類的解構函式,後呼叫基礎類別的解構函式。
派生類建構函式和解構函式的構造規則
派生類建構函式的一般格式為:
派生類名(引數總表):基礎類別名(參數列) {
派生類新增資料成員的初始化語句
}
-----------------------------------------------------------------
含有子物件的派生類別建構函式:
派生類名(引數總表):基礎類別名(參數列0),子物件名1(參數列1),...,子物件名n(參數列n)
{
派生類新增成員的初始化語句
}
在定義派生類物件時,建構函式的呼叫順序如下:
呼叫基礎類別的建構函式,對基礎類別資料成員初始化。
呼叫子物件的建構函式,對子物件的資料成員初始化。
呼叫派生類別建構函式體,對派生類的資料成員初始化。
說明:
- 當基礎類別建構函式不帶引數時,派生類不一定需要定義建構函式;然而當基礎類別的建構函式哪怕只帶有一個引數,它所有的派生類都必須定義建構函式,甚至所定義的派生類建構函式的函數體可能為空,它僅僅起引數的傳遞作用。
- 若基礎類別使用預設建構函式或不帶引數的建構函式,則在派生類中定義建構函式時可略去「
:基礎類別建構函式名(參數列)」,此時若派生類也不需要建構函式,則可不定義建構函式。 - 如果派生類的基礎類別也是一個派生類,每個派生類只需負責其直接基礎類別資料成員的初始化,依次上溯。
~
5.3 調整基礎類別成員在派生類中的存取屬性的其他方法
派生類可以宣告與基礎類別成員同名的成員。在沒有虛擬函式的情況下,如果在派生類中定義了與基礎類別成員同名的成員,則稱派生類成員覆蓋了基礎類別的同名成員,在派生類中使用這個名字意味著存取在派生類中宣告的成員。為了在派生類中使用與基礎類別同名的成員,必須在該成員名之前加上基礎類別名和作用域識別符號「::」,即
基礎類別名::成員名
存取宣告
存取宣告的方法就是把基礎類別的保護成員或共有成員直接寫在私有派生類定義式中的同名段中,同時給成員名前冠以基礎類別名和作用域識別符號「::」。利用這種方法,該成員就成為派生類的保護成員或共有成員了。
class B:private A{
private:
int y;
public:
B(int x1, int y1) : A(x1) {
y = y1;
}
A::show; //存取宣告
};
存取宣告在使用時應注意以下幾點:
- 資料成員也可以使用存取宣告。
- 存取宣告中只含不帶型別和引數的函數名或變數名。
- 存取宣告不能改變成員在基礎類別中的存取屬性。
- 對於基礎類別的過載函數名,存取宣告將對基礎類別中所有同名函數其起作用。
~
5.4 多繼承
宣告多繼承派生類的一般形式如下:
class 派生類名:繼承方式1 基礎類別名1,...,繼承方式n 基礎類別名n {
派生類新增的資料成員和成員函數
};
預設的繼承方式是private
多繼承派生類別建構函式與解構函式:
與單繼承派生類建構函式相同,多重繼承派生類建構函式必須同時負責該派生類所有基礎類別建構函式的呼叫。
多繼承建構函式的呼叫順序與單繼承建構函式的呼叫順序相同,也是遵循先呼叫基礎類別的建構函式,再呼叫物件成員的建構函式,最後呼叫派生類建構函式的原則。解構函式的呼叫與之相反。
~
5.5 虛基礎類別
虛基礎類別的作用:如果一個類有多個直接基礎類別,而這些直接基礎類別又有一個共同的基礎類別,則在最低層的派生類中會保留這個間接的共同基礎類別資料成員的多份同名成員。在存取這些同名成員時,必須在派生類物件名後增加直接基礎類別名,使其唯一地標識一個成員,以免產生二義性。
#include <iostream>
#include <string>
using namespace std;
class Base{
protected:
int a;
public:
Base(){
a = 5;
cout << "Base a = " << a << endl;
}
};
class Base1: public Base{
public:
Base1() {
a = a + 10;
cout << "Base1 a = " << a << endl;
}
};
class Base2: public Base{
public:
Base2() {
a = a + 20;
cout << "Base2 a = " << a << endl;
}
};
class Derived: public Base1, public Base2{
public:
Derived() {
cout << "Base1::a = " << Base1::a << endl;
cout << "Base2::a = " << Base2::a << endl;
}
};
int main() {
Derived obj;
return 0;
}
程式碼執行結果如下
Base a = 5
Base1 a = 15
Base a = 5
Base2 a = 25
Base1::a = 15
Base2::a = 25
虛基礎類別的宣告:
不難理解,如果在上列中類base只存在一個拷貝(即只有一個資料成員a),那麼對a的存取就不會產生二義性。在C++中,可以通過將這個公共的基礎類別宣告為虛基礎類別來解決這個問題。這就要求從類base派生新類時,使用關鍵字virtual將base宣告為虛基礎類別。
宣告虛基礎類別的語法形式如下:
class 派生類:virtual 繼承方式 類名{
·····
};
上述程式碼修改如下:
class Base1:virtual public Base{
public:
Base1() {
a = a + 10;
cout << "Base1 a = " << a << endl;
}
};
class Base2:virtual public Base{
public:
Base2() {
a = a + 20;
cout << "Base2 a = " << a << endl;
}
};
執行結果如下:
Base a = 5
Base1 a = 15
Base2 a = 35
Base1::a = 35
Base2::a = 35
虛基礎類別的初始化:
虛基礎類別的初始化與一般的多繼承的初始化在語法上是一樣的,但建構函式的呼叫順序不同。在使用虛基礎類別機制時應該注意以下幾點:
- 如果在虛基礎類別中定義有帶形參的建構函式,並且沒有定義預設形式的建構函式,則整個繼承結構中,所有直接或間接的派生類都必須在建構函式的成員初始化列表中列出對虛基礎類別建構函式的呼叫,以初始化在虛基礎類別中定義的資料成員。
- 建立一個物件時,如果這個物件中含有從虛基礎類別繼承來的成員,則虛基礎類別的成員是由最遠派生類別建構函式通過呼叫虛基礎類別的建構函式進行初始化的。該派生類的其他基礎類別對虛基礎類別建構函式的呼叫都被自動忽略。
- 若同一層次中同時包含虛基礎類別和非虛基礎類別,應先呼叫虛基礎類別的建構函式,再呼叫非虛基礎類別的建構函式,最後呼叫派生類建構函式。
- 對於多個虛基礎類別,建構函式的執行順序仍然是先左後右,自上而下。
- 若虛基礎類別由非虛基礎類別派生而來,則仍然先呼叫基礎類別建構函式,再呼叫派生類別建構函式。
~
5.6 賦值相容規則
在一定條件下,不同型別的資料之間可以進行型別轉換,如可以將整型資料賦值給雙精度型變數。在賦值之前,先把整型資料轉換成雙精度資料,然後再把它賦給雙精度變數。這種不同資料型別之間的自動轉換和賦值,稱為賦值相容。在基礎類別和派生類物件之間也存有賦值相容關係,基礎類別和派生類物件之間的賦值相容規則是指在需要基礎類別物件的任何地方,都可以用子類的物件代替。
例如,下面宣告的兩個類:
class Base{
·····
};
class Derived: public Base{
·····
};
根據賦值相容規則,在基礎類別Base的物件可以使用的任何地方,都可以使用派生類Derived的物件來代替,但只能使用從基礎類別繼承來的成員。具體的表現在以下幾個方面:
-
派生類物件可以賦值給基礎類別物件,即用派生類物件中從基礎類別繼承來的資料成員,逐個賦值給基礎類別物件的資料成員。
Base b; Derived d; b = d; -
派生類物件可以初始化基礎類別物件的參照。
Derived d; Base &br = d; -
派生類物件的地址可以賦值給指向基礎類別物件的指標。
Derived d; Base *bp = &d;
六、多型性與虛擬函式
多型性是物件導向程式設計的重要特徵之一。多型性機制不僅增加了物件導向軟體系統的靈活性,進一步減少了冗餘資訊,而且顯著提高了軟體的可重用性和可擴充性。多型性的應用可以使程式設計顯得更簡潔便利,它為程式的模組化設計又提供了一種手段。
~
6.1 多型性概述
所謂多型性就是不同物件收到相同的訊息時,產生不同的動作。這樣,就可以用同樣的介面存取不同功能的函數,從而實現「一個介面,多種方法」。
從實現的角度來講,多型可以劃分為兩類:編譯時的多型和執行時的多型。在C++中,多型的實現和連編這一概念有關。所謂連編就是把函數名與函數體的程式程式碼連線在一起的過程。靜態連編就是在編譯階段完成的連編。編譯時的多型是通過靜態連編來實現的。靜態連編時,系統用實參與形參進行匹配,對於同名的過載函數便根據引數上的差異進行區分,然後進行連編,從而實現了多型性。執行時的多型是用動態連編實現的。動態連編時執行階段完成的,即當程式呼叫到某一函數名時,才去尋找和連線其程式程式碼,對物件導向程式設計而言,就是當物件接收到某一訊息時,才去尋找和連線相應的方法。
一般而言,編譯型語言(如C,Pascal)採用靜態連編,而直譯語言(如LISP)採用動態連編。靜態連編要求在程式編譯時就知道呼叫函數的全部資訊。因此,這種連編型別的函數呼叫速度快、效率高,但缺乏靈活性;而動態連編方式恰好相反,採用這種連編方式,一直要到程式執行時才能確定呼叫哪個函數,它降低了程式的執行效率,但增強了程式的靈活性。純粹的物件導向程式語言由於其執行機制是訊息傳遞,所以只能採用動態連編。C++實際上採用了靜態連編和動態連編相結合的方式。
在C++中,編譯時多型性主要是通過函數過載和運運算元過載實現的;執行時多型性主要是通過虛擬函式來實現的。
~
6.2 虛擬函式
虛擬函式的定義是在基礎類別中進行的,它是在基礎類別中需要定義為虛擬函式的成員函數的宣告中冠以關鍵字virtual,從而提供一種介面介面。定義虛擬函式的方法如下:
virtual 返回型別 函數名(形參表) {
函數體
}
在基礎類別中的某個成員函數被宣告為虛擬函式後,此虛擬函式就可以在一個或多個派生類中被重新定義。虛擬函式在派生類中重新定義時,其函數原型,包括返回型別、函數名、引數個數、引數型別的順序,都必須與基礎類別中的原型完全相同。
#include <iostream>
#include <string>
using namespace std;
class Family{
private:
string flower;
public:
Family(string name = "鮮花"): flower(name) { }
string getName() {
return flower;
}
virtual void like() {
cout << "家人喜歡不同的花: " << endl;
}
};
class Mother: public Family{
public:
Mother(string name = "月季"): Family(name) { }
void like() {
cout << "媽媽喜歡" << getName() << endl;
}
};
class Daughter: public Family{
public:
Daughter(string name = "百合"): Family(name) { }
void like() {
cout << "女兒喜歡" << getName() << endl;
}
};
int main() {
Family *p;
Family f;
Mother mom;
Daughter dau;
p = &f;
p->like();
p = &mom;
p->like();
p = &dau;
p->like();
return 0;
}
程式執行結果如下:
家人喜歡不同的花:
媽媽喜歡月季
女兒喜歡百合
C++規定,如果在派生類中,沒有用virtual顯式地給出虛擬函式宣告,這時系統就會遵循以下的規則來判斷一個成員函數是不是虛擬函式:該函數與基礎類別的虛擬函式是否有相同的名稱、引數個數以及對應的引數型別、返回型別或者滿足賦值相容的指標、參照型的返回型別。
下面對虛擬函式的定義做幾點說明:
- 由於虛擬函式使用的基礎是賦值相容規則,而賦值相容規則成立的前提條件是派生類從其基礎類別公有派生。因此,通過定義虛擬函式來使用多型性機制時,派生類必須從它的基礎類別公有派生。
- 必須首先在基礎類別中定義虛擬函式;
- 在派生類對基礎類別中宣告的虛擬函式進行重新定義時,關鍵字virtual可以寫也可以不寫。
- 雖然使用物件名和點運運算元的方式也可以呼叫虛擬函式,如mom.like()可以呼叫虛擬函式Mother::like()。但是,這種呼叫是在編譯時進行的靜態連編,它沒有充分利用虛擬函式的特性,只有通過基礎類別指標存取虛擬函式時才能獲得執行時的多型性
- 一個虛擬函式無論被公有繼承多少次,它仍然保持其虛擬函式的特性。
- 虛擬函式必須是其所在類的成員函數,而不能是友元函數,也不能是靜態成員函數,因為虛擬函式呼叫要靠特定的物件來決定該啟用哪個函數。
- 行內函式不能是虛擬函式,因為行內函式是不能在執行中動態確定其位置的。即使虛擬函式在類的內部定義,編譯時仍將其看做非內聯的。
- 建構函式不能是虛擬函式,但是解構函式可以是虛擬函式,而且通常說明為虛擬函式。
~
在一個派生類中重新定義基礎類別的虛擬函式是函數過載的另一種形式。
多繼承可以視為多個單繼承的組合,因此,多繼承情況下的虛擬函式呼叫與單繼承下的虛擬函式呼叫由相似之處。
~
6.3 虛解構函式
如果在主函數中用new運運算元建立一個派生類的無名物件和定義一個基礎類別的物件指標,並將無名物件的地址賦值給這個物件指標,當用delete運運算元復原無名物件時,系統只執行基礎類別的解構函式,而不執行派生類的解構函式。
Base *p;
p = new Derived;
delete p;
-----------------
輸出:呼叫基礎類別Base的解構函式
原因是當復原指標p所指的派生類的無名物件,而呼叫解構函式時,採用了靜態連編方式,只呼叫了基礎類別Base的解構函式。
如果希望程式執行動態連編方式,在用delete運運算元復原派生類的無名物件時,先呼叫派生類的解構函式,再呼叫基礎類別的解構函式,可以將基礎類別的解構函式宣告為虛解構函式。一般格式為
virtual ~類名(){
·····
}
雖然派生類的解構函式與基礎類別的解構函式名字不相同,但是如果將基礎類別的解構函式定義為虛擬函式,由該類所派生的所有派生類的解構函式也都自動成為虛擬函式。範例如下,
#include <iostream>
#include <string>
using namespace std;
class Base{
public:
virtual ~Base() {
cout << "呼叫基礎類別Base的解構函式..." << endl;
}
};
class Derived: public Base{
public:
~Derived() {
cout << "呼叫派生類Derived的解構函式..." << endl;
}
};
int main() {
Base *p;
p = new Derived;
delete p;
return 0;
}
輸出如下:
呼叫派生類Derived的解構函式...
呼叫基礎類別Base的解構函式...
~
6.4 純虛擬函式
純虛擬函式是在宣告虛擬函式時被「初始化為0的函數」,宣告純虛擬函式的一般形式如下:
virtual 函數型別 函數名(參數列) = 0;
宣告為純虛擬函式後,基礎類別中就不再給出程式的實現部分。純虛擬函式的作用是在基礎類別中為其派生類保留一個函數的名字,以便派生類根據需要重新定義。
~
6.5 抽象類
如果一個類至少有一個純虛擬函式,那麼就稱該類為抽象類,對於抽象類的使用有以下幾點規定:
- 由於抽象類中至少包含一個沒有定義功能的純虛擬函式。因此,抽象類只能作為其他類的基礎類別來使用,不能建立抽象類物件。
- 不允許從具體類派生出抽象類。所謂具體類,就是不包含純虛擬函式的普通類。
- 抽象類不能用作函數的引數型別、函數的返回型別或是顯式轉換的型別。
- 可以宣告指向抽象類的指標或參照,此指標可以指向它的派生類,進而實現多型性。
- 如果派生類中沒有定義純虛擬函式的實現,而派生類中只是繼承基礎類別的純虛擬函式,則這個派生類仍然是一個抽象類。如果派生類中給出了基礎類別純虛擬函式的實現,則該派生類就不再是抽象類了,它是一個可以建立物件的具體類了。
~
6.6 範例:利用多型計算面積
應用C++的多型性,計算三角形、矩形和圓的面積。
#include <iostream>
using namespace std;
/*** 定義一個公共基礎類別 ***/
class Figure{
protected:
double x, y;
public:
Figure(double a, double b): x(a), y(b) { }
virtual void getArea() //虛擬函式
{
cout << "No area computation defind for this class.\n";
}
};
class Triangle: public Figure{
public:
Triangle(double a, double b): Figure(a, b){ }
//虛擬函式重定義,用於求三角形的面積
void getArea(){
cout << "Triangle with height " << x << " and base " << y;
cout << " has an area of " << x * y * 0.5 << endl;
}
};
class Square: public Figure{
public:
Square(double a, double b): Figure(a, b){ }
//虛擬函式重定義,用於求矩形的面積
void getArea(){
cout << "Square with dimension " << x << " and " << y;
cout << " has an area of " << x * y << endl;
}
};
class Circle: public Figure{
public:
Circle(double a): Figure(a, a){ }
//虛擬函式重定義,用於求圓的面積
void getArea(){
cout << "Circle with radius " << x ;
cout << " has an area of " << x * x * 3.14 << endl;
}
};
int main(){
Figure *p;
Triangle t(10.0, 6.0);
Square s(10.0, 6.0);
Circle c(10.0);
p = &t;
p->getArea();
p = &s;
p->getArea();
p = &c;
p->getArea();
return 0;
}
程式輸出如下:
Triangle with height 10 and base 6 has an area of 30
Square with dimension 10 and 6 has an area of 60
Circle with radius 10 has an area of 314
七、運運算元過載
運運算元過載是物件導向程式設計的重要特徵。
~
7.1 運運算元過載概述
運運算元過載是對已有的運運算元賦予多重含義,使同一個運運算元作用於不同型別的資料導致不同的行為。
下面的案例實現+號運運算元過載:
#include <iostream>
using namespace std;
class Complex{
private:
double real, imag;
public:
Complex(double r = 0.0, double i = 0.0): real(r), imag(i) { }
friend Complex operator+(Complex& a, Complex& b) {
Complex temp;
temp.real = a.real + b.real;
temp.imag = a.imag + b.imag;
return temp;
}
void display() {
cout << real;
if (imag > 0) cout << "+";
if (imag != 0) cout << imag << "i" << endl;
}
};
int main()
{
Complex a(2.3, 4.6), b(3.6, 2.8), c;
a.display();
b.display();
c = a + b;
c.display();
c = operator+(a, b);
c.display();
return 0;
}
程式輸出結果如下:
2.3+4.6i
3.6+2.8i
5.9+7.4i
5.9+7.4i
~
這一章偷個懶😁
八、函數模板與類別範本
利用模板機制可以顯著減少冗餘資訊,能大幅度地節約程式程式碼,進一步提高物件導向程式的可重用性和可維護性。模板是實現程式碼重用機制的一種工具,它可以實現型別引數化,即把型別定義為引數,從而實現程式碼的重用,使得一段程式可以用於處理多種不同型別的物件,大幅度地提高程式設計的效率。
~
8.1 模板的概念
在程式設計中往往存在這樣的現象:兩個或多個函數的函數體完全相同,差別僅在與它們的引數型別不同。
例如:
int Max(int x, int y) {
return x >= y ? x : y;
}
double Max(double x, double y) {
return x >= y ? x : y;
}
能否為上述這些函數只寫出一套程式碼呢?解決這個問題的一種方式是使用宏定義
#define Max(x, y)((x >= y) ? x : y)
宏定義帶來的另一個問題是,可能在不該替換的地方進行了替換,而造成錯誤。事實上,由於宏定義會造成不少麻煩,所以在C++中不主張使用宏定義。解決以上問題的另一個方法就是使用模板。
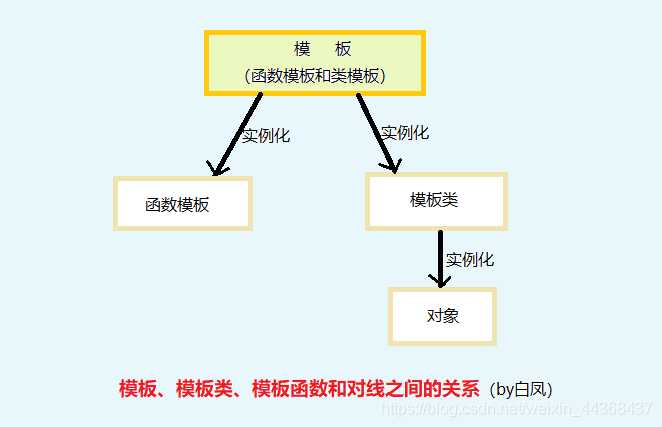
~
8.2 函數模板
所謂函數模板,實際上是建立一個通用函數,其函數返回型別和形參型別不具體指定,用一個虛擬的型別來代表,這個通用函數就稱為函數模板。在呼叫函數時,系統會根據實參的型別(模板實參)來取代模板中的虛擬型別,從而實現不同函數的功能。
函數的宣告格式如下
template <typename 型別引數>
返回型別 函數名(模板形參表)
{
函數體
}
也可以定義為如下形式
template <class 型別引數>
返回型別 函數名(模板形參表)
{
函數體
}
實際上,template是一個宣告模板的關鍵字,它表示宣告一個模板。型別引數(通常用C++識別符號表示,如T、type等)實際上是一個虛擬的型別名,使用前並未指定它是哪一種具體的型別,但使用函數模板時,必須將型別範例化。型別引數前需加關鍵字typename或class,typename和class的作用相同,都是表示一個虛擬的型別名(即型別引數)。
例1:一個與指標有關的函數模板
#include <iostream>
using namespace std;
template <typename T>
T Max(T *array, int size = 0) {
T max = array[0];
for (int i = 1 ; i < size; i++) {
if (array[i] > max) max = array[i];
}
return max;
}
int main() {
int array_int[] = {783, 78, 234, 34, 90, 1};
double array_double[] = {99.02, 21.9, 23.90, 12.89, 1.09, 34.9};
int imax = Max(array_int, 6);
double dmax = Max(array_double, 6);
cout << "整型陣列的最大值是:" << imax << endl;
cout << "雙精度型陣列的最大值是:" << dmax << endl;
return 0;
}
例2:函數模板的過載
#include <iostream>
using namespace std;
template <class Type>
Type Max(Type x, Type y) {
return x > y ? x : y;
}
template <class Type>
Type Max(Type x, Type y, Type z) {
Type t = x > y ? x : y;
t = t > z ? t : z;
return t;
}
int main() {
cout << "33,66中最大值為 " << Max(33, 66) << endl;
cout << "33,66,44中最大值為 " << Max(33, 66, 44) << endl;
return 0;
}
注意:
- 在函數模板中允許使用多個型別引數。但是,應當注意template定義部分的每個型別引數前必須有關鍵字typename或class。
- 在template語句與函數模板定義語句之間不允許插入別的語句。
- 同一般函數一樣,函數模板也可以過載。
- 函數模板與同名的非模板函數可以過載。在這種情況下,呼叫的順序是:首先尋找一個引數完全匹配的非模板函數,如果找到了就呼叫它;若沒有找到,則尋找函數模板,將其範例化,產生一個匹配的模板引數,若找到了,就呼叫它。
~
8.3 類別範本
所謂類別範本,實際上就是建立一個通用類,其資料成員、成員函數的返回型別和形參型別不具體指定,用一個虛擬的型別來代表。使用類別範本定義物件時,系統會根據實參的型別來取代類別範本中虛擬型別,從而實現不同類的功能。
template <typename T>
class Three{
private:
T x, y, z;
public:
Three(T a, T b, T c) {
x = a; y = b; z = c;
}
T sum() {
return x + y + z;
}
}
上面的例子中,成員函數(其中含有型別引數)是定義在類體內的。但是,類別範本中的成員函數也可以在類別範本體外定義。此時,若成員函數中有型別引數存在,則C++有一些特殊的規定:
- 需要在成員函數定義之前進行模板宣告;
- 在成員函數名前要加上「類名<型別引數>::」;
在類別範本體外定義的成員函數的一般形式如下:
template <typename 型別引數>
函數型別 類名<型別引數>::成員函數名(形參表)
{
·····
}
例如,上例中成員函數sum()在類外定義時,應該寫成
template<typename T>
T Three<T>::sum() {
return x + y + z;
}
**例子:**棧類別範本的使用
#include <iostream>
#include <string>
using namespace std;
const int size = 10;
template <class T>
class Stack{
private:
T stack[size];
int top;
public:
void init() {
top = 0;
}
void push(T t);
T pop();
};
template <class T>
void Stack<T>::push(T t) {
if (top == size) {
cout << "Stack is full!" << endl;
return;
}
stack[top++] = t;
}
template <class T>
T Stack<T>::pop() {
if (top == 0) {
cout << "Stack is empty!" <<endl;
return 0;
}
return stack[--top];
}
int main() {
Stack<string> st;
st.init();
st.push("aaa");
st.push("bbb");
cout << st.pop() << endl;
cout << st.pop() << endl;
return 0;
}
九、C++的輸入和輸出
~
9.1 C++為何建立自己的輸入/輸出系統
C++除了完全支援C語言的輸入輸出系統外,還定義了一套物件導向的輸入/輸出系統。C++的輸入輸出系統比C語言更安全、可靠。
c++的輸入/輸出系統明顯地優於C語言的輸入/輸出系統。首先,它是型別安全的、可以防止格式控制符與輸入輸出資料的型別不一致的錯誤。另外,C++可以通過過載運運算元「>>」和"<<",使之能用於使用者自定義型別的輸入和輸出,並且向預定義型別一樣有效方便。C++的輸入/輸出的書寫形式也很簡單、清晰,這使程式程式碼具有更好的可讀性。
~
9.2 C++的流庫及其基本結構
「流」指的是資料從一個源流到一個目的的抽象,它負責在資料的生產者(源)和資料的消費者(目的)之間建立聯絡,並管理資料的流動。凡是資料從一個地方傳輸到另一個地方的操作都是流的操作,從流中提取資料稱為輸入操作(通常又稱提取操作),向流中新增資料稱為輸出操作(通常又稱插入操作)。
C++的輸入/輸出是以位元組流的形式實現的。在輸入操作中,位元組流從輸入裝置(如鍵盤、磁碟、網路連線等)流向記憶體;在輸出操作中,位元組流從記憶體流向輸出裝置(如顯示器、印表機、網路連線等)。位元組流可以是ASCII碼、二進位制形式的資料、圖形/影象、音訊/視訊等資訊。檔案和字串也可以看成有序的位元組流,分別稱為檔案流和字串流。
~
用於輸入/輸出的標頭檔案
C++編譯系統提供了用於輸入/輸出的I/O類流庫。I/O流類庫提供了數百種輸入/輸出功能,I/O流類庫中各種類的宣告被放在相應的標頭檔案中,使用者在程式中用#include命令包含了有關的標頭檔案就相當於在本程式中宣告了所需要用到的類。常用的標頭檔案有:
iostream包含了對輸入/輸出流進行操作所需的基本資訊。使用cin、cout等流物件進行鍼對標準裝置的I/O操作時,須包含此標頭檔案。fstream用於使用者管理檔案的I/O操作。使用檔案流物件進行鍼對磁碟檔案的操作,須包含此標頭檔案。strstream用於字串流的I/O操作。使用字串流物件進行鍼對記憶體字串空間的I/O操作,須包含此標頭檔案。iomanip用於輸入/輸出的格式控制。在使用setw、fixed等大多數操作符進行格式控制時,須包含此標頭檔案。
用於輸入/輸出的流類
I/O流類庫中包含了許多用於輸入/輸出操作的類。其中,類istream支援流輸入操作,類ostream支援流輸出操作,類iostream同時支援流輸入和輸出操作。
下表列出了iostream流類庫中常用的流類,以及指出了這些流類在哪個標頭檔案中宣告。
| 類名 | 類名 | 說明 | 標頭檔案 |
|---|---|---|---|
| 抽象流基礎類別 | ios | 流基礎類別 | iostream |
| 輸入流類 | istream | 通用輸入流類和其他輸入流的基礎類別 | iostream |
| 輸入流類 | ifstream | 輸入檔案流類 | fstream |
| 輸入流類 | istrstream | 輸入字串流類 | strstream |
| 輸出流類 | ostream | 通用輸出流類和其他輸出流的基礎類別 | iostream |
| 輸出流類 | ofstream | 輸出檔案流類 | fstream |
| 輸出流類 | ostrstream | 輸出字串流類 | strstream |
| 輸入/輸出流類 | iostream | 通用輸入輸出流類和其他輸入/輸出流的基礎類別 | iostream |
| 輸入/輸出流類 | fstream | 輸入/輸出檔案流類 | fstream |
| 輸入/輸出流類 | strstream | 輸入/輸出字串流類 | strstream |
~
9.3 預定義的流物件
用流定義的物件稱為流物件。與輸入裝置(如鍵盤)相關聯的流物件稱為輸入流物件;與輸出裝置(如螢幕)相聯絡的流物件稱為輸出流物件。
C++中包含幾個預定義的流物件,它們是標準輸入流物件cin、標準輸出流物件cout、非緩衝型的標準出錯流物件cerr和緩衝型的標準出錯流物件clog。
~
9.4 輸入/輸出流的成員函數
使用istream和類ostream流物件的一些成員函數,實現字元的輸出和輸入。
1、put()函數
cout.put(單字元/字元形變數/ASCII碼);
2、get()函數
get()函數在讀入資料時可包括空白符,而提取運運算元「>>」在預設情況下拒絕接收空白字元。
cin.get(字元型變數)
3、getline()函數
cin.getline(字元陣列, 字元個數n, 終止標誌字元)
cin.getline(字元指標, 字元個數n, 終止標誌字元)
4、ignore()函數
cin.ignore(n, 終止字元)
ignore()函數的功能是跳過輸入流中n個字元(預設個數為1),或在遇到指定的終止字元(預設終止字元是EOF)時提前結束。
~
9.5 預定義型別輸入/輸出的格式控制
在很多情況下,需要對預定義型別(如int、float、double型等)的資料的輸入/輸出格式進行控制。在C++中,仍然可以使用C中的printf()和scanf()函數進行格式化。除此之外,C++還提供了兩種進行格式控制的方法:一種是使用ios類中有關格式控制的流成員函數進行格式控制;另一種是使用稱為操作符的特殊型別的函數進行格式控制。
1、用流成員函數進行輸入/輸出格式控制
- 設定狀態標誌的流成員函數
setf() - 清除狀態標誌的流成員函數
unsetf() - 設定域寬的流成員函數
width() - 設定實數的精度流成員函數
precision() - 填充字元的流成員函數
fill()
2、使用預定義的操作符進行輸入/輸出格式控制
3、使用使用者自定義的操作符進行輸入/輸出格式控制
若為輸出流定義操作符函數,則定義形式如下:
ostream &操作符名(ostream &stream)
{
自定義程式碼
return stream;
}
若為輸入流定義操作符函數,則定義形式如下:
istream &操作符名(istream &stream)
{
自定義程式碼
return stream;
}
例如,
#include <iostream>
#include <iomanip>
using namespace std;
ostream &output(ostream &stream)
{
stream.setf(ios::left);
stream << setw(10) << hex << setfill('-');
return stream;
}
int main() {
cout << 123 << endl;
cout << output << 123 << endl;
return 0;
}
輸出結果如下:
123
7b--------
~
9.6 檔案的輸入/輸出
所謂檔案,一般指存放在外部媒介上的資料的集合。
檔案流是以外存檔案為輸入/輸出物件的資料流。輸出檔案流是從記憶體流向外存檔案的資料,輸入檔案流是從外存流向記憶體的資料。
根據檔案中資料的組織形式,檔案可分為兩類:文字檔案和二進位制檔案。
在C++中進行檔案操作的一般步驟如下:
- 為要進行操作的檔案定義一個流物件。
- 建立(或開啟)檔案。如果檔案不存在,則建立該檔案。如果磁碟上已存在該檔案,則開啟它。
- 進行讀寫操作。在建立(或開啟)的檔案基礎上執行所要求的輸入/輸出操作。
- 關閉檔案。當完成輸入/輸出操作時,應把已開啟的檔案關閉。
~
9.7 檔案的開啟與關閉
為了執行檔案的輸入/輸出,C++提供了3個檔案流類。
| 類名 | 說明 | 功能 |
|---|---|---|
istream | 輸入檔案流類 | 用於檔案的輸入 |
ofstream | 輸出檔案流類 | 用於檔案的輸出 |
fstream | 輸入/輸出檔案流類 | 用於檔案的輸入/輸出 |
這3個檔案流類都定義在標頭檔案fstream中。
要執行檔案的輸入/輸出,須完成以下幾件工作:
- 在程式中包含標頭檔案
fstream。 - 建立流物件
- 使用成員函數
open()開啟檔案。 - 進行讀寫操作。
- 使用
close()函數將開啟的檔案關閉。
~
9.8 文字檔案的讀/寫
**例子:**把字串「I am a student.」寫入磁碟檔案text.txt中。
#include <iostream>
#include <fstream>
using namespace std;
int main() {
ofstream fout("../test.txt", ios::out);
if (!fout) {
cout << "Cannot open output file." << endl;
exit(1);
}
fout << "I am a student.";
fout.close();
return 0;
}
**例子:**把磁碟檔案test1.dat中的內容讀出並顯示在螢幕上。
#include <iostream>
#include <fstream>
using namespace std;
int main() {
ifstream fin("../test.txt", ios::in);
if (!fin) {
cout << "Cannot open output file." << endl;
exit(1);
}
char str[80];
fin.getline(str , 80);
cout << str <<endl;
fin.close();
return 0;
}
~
9.9 二進位制檔案的讀寫
用get()函數和put()函數讀/寫二進位制檔案
**例子:**將a~z的26個英文字母寫入檔案,而後從該檔案中讀出並顯示出來。
#include <iostream>
#include <fstream>
using namespace std;
int cput() {
ofstream outf("test.txt", ios::binary);
if (!outf) {
cout << "Cannot open output file.\n";
exit(1);
}
char ch = 'a';
for (int i = 0; i < 26; i++) {
outf.put(ch);
ch++;
}
outf.close();
return 0;
}
int cget() {
fstream inf("test.txt", ios::binary);
if (!inf) {
cout << "Cannot open input file.\n";
exit(1);
}
char ch;
while (inf.get(ch)) {
cout << ch;
}
inf.close();
return 0;
}
int main() {
cput();
cget(); //此處檔案打不開,不知為什麼。。。
return 0;
}
用read()函數和write()函數讀寫二進位制檔案
有時需要讀寫一組資料(如一個結構變數的值),為此C++提供了兩個函數read()和write(),用來讀寫一個資料塊,這兩個函數最常用的呼叫格式如下:
inf.read(char *buf, int len);
outf.write(const char *buf, int len);
**例子:**將兩門課程的課程名和成績以二進位制形式存放在磁碟檔案中。
#include <iostream>
#include <fstream>
using namespace std;
struct list{
char course[15];
int score;
};
int main() {
list ob[2] = {"Computer", 90, "History", 99};
ofstream out("test.txt", ios::binary);
if (!out) {
cout << "Cannot open output file.\n";
abort(); //退出程式,作用與exit相同。
}
for (int i = 0; i < 2; i++) {
out.write((char*) &ob[i], sizeof(ob[i]));
}
out.close();
return 0;
}
**例子:**將上述例子以二進位制形式存放在磁碟檔案中的資料讀入記憶體。
#include <iostream>
#include <fstream>
using namespace std;
struct list{
char course[15];
int score;
};
int main() {
list ob[2];
ifstream in("test.txt", ios::binary);
if (!in) {
cout << "Cannot open input file.\n";
abort();
}
for (int i = 0; i < 2; i++) {
in.read((char *) &ob[i], sizeof(ob[i]));
cout << ob[i].course << " " << ob[i].score << endl;
}
in.close();
return 0;
}
檢測檔案結束
在檔案結束的地方有一個標誌位,即為EOF。採用檔案流方式讀取檔案時,使用成員函數eof()可以檢測到這個結束符。如果該函數的返回值非零,表示到達檔案尾。返回值為零表示未達到檔案尾。該函數的原型是:
int eof();
函數eof()的用法範例如下:
ifstream ifs;
···
if (!ifs.eof()) //尚未到達檔案尾
···
還有一個檢測方法就是檢查該流物件是否為零,為零表示檔案結束。
ifstream ifs;
···
if (!ifs)
···
如下例子:
while (cin.get(ch))
cut.put(ch);
這是一個很通用的方法,就是檢測檔案流物件的某些成員函數的返回值是否為0,為0表示該流(亦即對應的檔案)到達了末尾。
從鍵盤上輸入字元時,其結束符是Ctrl+Z,也就是說,按下【Ctrl+Z】組合鍵,eof()函數返回的值為真。
~
十、例外處理和名稱空間
10.1 例外處理
程式中常見的錯位分為兩大類:編譯時錯誤和執行時錯誤。編譯時的錯誤主要是語法錯誤,如關鍵字拼寫錯誤、語句末尾缺分號、括號不匹配等。執行時出現的錯誤統稱為異常,對異常的處理稱為例外處理。
C++處理異常的辦法:如果在執行一個函數的過程中出現異常,可以不在本函數中立即處理,而是發出一個資訊,傳給它的上一級(即呼叫函數)來解決,如果上一級函數也不能處理,就再傳給其上一級,由其上一級處理。如此逐級上傳,如果到最高一級還無法處理,執行系統一般會自動呼叫系統函數terminate(),由它呼叫abort終止程式。
**例子:**輸入三角形的三條邊長,求三角形的面積。當輸入邊的長度小於0時,或者當三條邊都大於0時但不能構成三角形時,分別丟擲異常,結束程式執行。
#include <iostream>
#include <cmath>
using namespace std;
double triangle(double a, double b, double c) {
double s = (a + b + c) / 2;
if (a + b <= c || a + c <= b || b + c <= a) {
throw 1.0; //語句throw丟擲double異常
}
return sqrt(s * (s - a) * (s - b) * (s - c));
}
int main() {
double a, b, c;
try {
cout << "請輸入三角形的三個邊長(a, b, c): " << endl;
cin >> a >> b >> c;
if (a < 0 || b < 0 || c < 0) {
throw 1; //語句throw丟擲int異常
}
while (a > 0 && b > 0 && c > 0) {
cout << "a = " << a << " b = " << b << " c = " << c << endl;
cout << "三角形的面積 = " << triangle(a, b, c) << endl;
cin >> a >> b >> c;
if (a <= 0 || b <= 0 || c <= 0) {
throw 1;
}
}
} catch (double) {
cout << "這三條邊不能構成三角形..." << endl;
} catch (int) {
cout << "邊長小於或等於0..." << endl;
}
return 0;
}
~
10.2 名稱空間和標頭檔案命名規則
名稱空間:一個由程式設計者命名的記憶體區域。程式設計者可以根據需要指定一些有名字的名稱空間,將各名稱空間中宣告的識別符號與該名稱空間識別符號建立關聯,保證不同名稱空間的同名識別符號不發生衝突。
1.帶擴充套件名的標頭檔案的使用
在C語言程式中標頭檔案包括擴充套件名.h,使用規則如下面例子
#include <stdio.h>
2.不帶擴充套件名的標頭檔案的使用
C++標準要求系統提供的標頭檔案不包括擴充套件名.h,如string,string.h等。
#include <cstring>
十一、STL標準模板庫
標準模板庫(Standard Template Library)中包含了很多實用的元件,利用這些元件,程式設計師程式設計方便而高效。
11.1 Vector
vector容器與陣列類似,包含一組地址連續的儲存單元。對vector容器可以進行很多操作,包括查詢、插入、刪除等常見操作。
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> nums;
nums.insert(nums.begin(), 99);
nums.insert(nums.begin(), 34);
nums.insert(nums.end(), 1000);
nums.push_back(669);
cout << "\n當前nums中元素為: " << endl;
for (int i = 0; i < nums.size(); i++)
cout << nums[i] << " " ;
cout << nums.at(2);
nums.erase(nums.begin());
nums.pop_back();
cout << "\n當前nums中元素為: " << endl;
for (int i = 0; i < nums.size(); i++)
cout << nums[i] << " " ;
return 0;
}
~
11.2 list容器
#include <iostream>
#include <list>
using namespace std;
int main() {
list<int> number;
list<int>::iterator niter;
number.push_back(123);
number.push_back(234);
number.push_back(345);
cout << "連結串列內容:" << endl;
for (niter = number.begin(); niter != number.end(); ++niter)
cout << *niter << endl;
number.reverse();
cout << "逆轉後的連結串列內容:" << endl;
for (niter = number.begin(); niter != number.end(); ++niter)
cout << *niter << endl;
number.reverse();
return 0;
}
~
11.3 stack
**例子:**利用棧進行進位制轉換
#include <iostream>
#include <stack>
using namespace std;
int main() {
stack<int> st;
int num = 100;
cout << "100的八進位製表示為:";
while (num) {
st.push(num % 8);
num /= 8;
}
int t;
while (!st.empty()) {
t = st.top();
cout << t;
st.pop();
}
cout << endl;
return 0;
}
~
11.4 queue
#include <iostream>
#include <queue>
using namespace std;
int main() {
queue<int> qu;
for (int i = 0; i < 10; i++)
qu.push(i * 3 + i);
while (!qu.empty()) {
cout << qu.front() << " ";
qu.pop();
}
cout << endl;
return 0;
}
~
11.5 優先佇列priority_queue
#include <iostream>
#include <queue>
#include <functional>
#include <cstdlib>
#include <ctime>
using namespace std;
int main() {
priority_queue<int> pq;
srand((unsigned)time(0));
for (int i = 0; i < 6; i++) {
int t = rand();
cout << t << endl;
pq.push(t);
}
cout << "優先佇列的值:" << endl;
for (int i = 0; i < 6; i++) {
cout << pq.top() << endl;
pq.pop();
}
return 0;
}
~
11.6 雙端佇列deque
push_back();
push_front();
insert();
pop_back();
pop_front();
erase();
begin();
end();
rbegin();
rend();
size();
maxsize();
~
11.7 set
#include <iostream>
#include <set>
#include <string>
using namespace std;
int main() {
set<string> s;
s.insert("aaa");
s.insert("bbb");
s.insert("ccc");
if (s.count("aaa") != 0) {
cout << "存在元素aaa" << endl;
}
set<string>::iterator iter;
for (iter = s.begin(); iter != s.end(); ++iter)
cout << *iter << endl;
return 0;
}
~
11.8 map
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, int> m;
m["aaa"] = 111;
m["bbb"] = 222;
m["ccc"] = 333;
if (m.count("aaa")) {
cout << "鍵aaa對應的值為" << m.at("aaa") << endl;
cout << "鍵aaa對應的值為" << m["aaa"] << endl;
}
return 0;
}
完結撒花~~~🌸🌸🌸🌸🌸

博主就是在複習的過程中順便總結下知識點,以便以後檢視學習。
注:本部落格僅供學習和參考,內容較多,難免會有錯誤,請大家多多包涵。如有侵權敬請告知。
參考資料《C++物件導向程式設計》陳維興、林小茶編著
讀完本文的小可愛,恭喜您堅持到了最後❤
創作整理不易,如果對您有所幫助,還望多+點贊、收藏☚
歡迎在評論區留下您寶貴的建議😉😉😉