C# WinForm程式 PDF檔案分割程式碼實現
2021-06-05 07:00:04
C#使用itextsharp對PDF分割處理
程式執行介面:
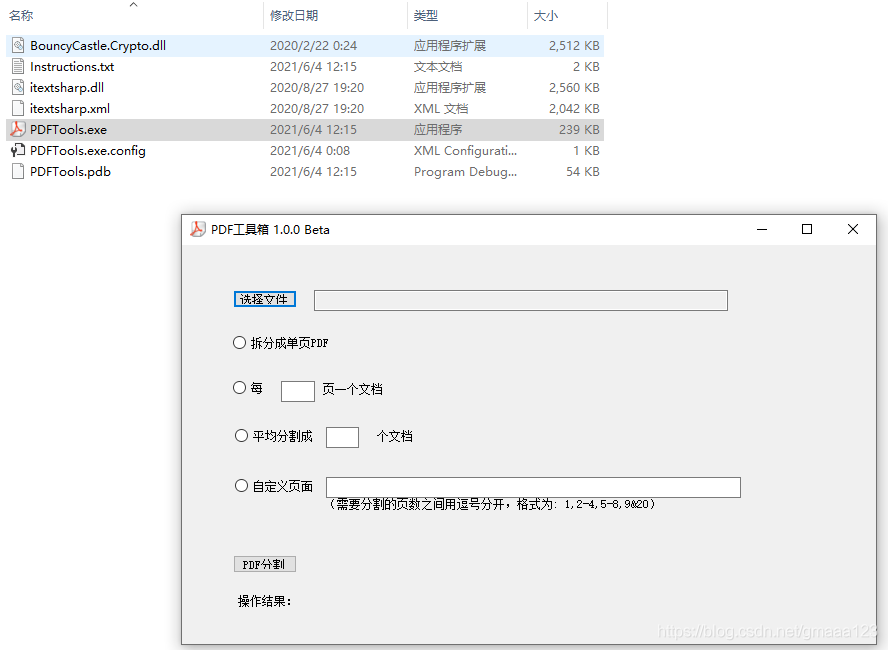
PDF分割操作共有以下幾個步驟:
1.執行資料夾裡面的PDFTools.exe檔案
2.點選瀏覽按鈕選擇需要分割的PDF檔案
3.選擇分割方式,可以分割成單頁的檔案,或者固定多少頁一個檔案,或者自定義每個檔案的頁數
4.點選分割後,新的檔案會生成在原始PDF的路徑
PDF分割功能說明
能快速方便的把一個PDF檔案任意分割成你所設想的多個PDF檔案,簡單、高效;一鍵操作,快速、方便
可以把檔案轉換成單頁的PDF,比如一個檔案有20頁,就可以分割成20個檔案
也可以分割成固定頁數一個檔案,比如20頁的檔案分割成每5頁一個檔案,就是拆分成4個檔案
當然頁可以自定義頁面分割,
比如 1-5,6-8 這樣就是分割成3個檔案,分別是第1頁到第5頁的內容合併到一個檔案、第6頁到第8頁的內容合併到一個檔案。
比如 1&3,3&10 這樣就是分割成2個檔案,分別是第1頁和第3頁的內容合併到一個檔案,第3頁和第10頁內容合併到一個檔案。
比如 1&2,1&2,3-5,14 這樣就是分割成5個檔案,分別是第1頁和第2頁的內容合併到一個檔案,第1頁和第2頁內容合併到一個檔案、第3-5頁的內容合併到一個檔案、第14頁單獨一個檔案。
PDF檔案分割 關鍵性程式碼
using System;
using System.Collections.Generic;
using iTextSharp.text;
using iTextSharp.text.pdf;
using System.Text;
namespace PDFTools
{
/// <summary>
/// 檔名:PdfExtractorUtility/
/// 檔案功能描述:處理PDF檔案/
/// 版權所有:Copyright (C) EXT.AZHANG/
/// 建立標識:2021.6.2/ /// 修改描述:/
/// </summary>
class PdfExtractorUtility
{
/// <summary>
/// 從已有PDF檔案中拷貝指定的頁碼範圍到一個新的pdf檔案中 使用pdfCopyProvider.AddPage()方法
/// </summary>
/// <param name="sourcePdfPath">檔案路徑+檔名</param>
public void SplitPDF(string sourcePdfPath, string outputPdfPath, int startPage, int endPage)
{
PdfReader reader = null;
Document sourceDocument = null;
PdfCopy pdfCopyProvider = null;
PdfImportedPage importedPage = null;
try
{
reader = new PdfReader(sourcePdfPath);
sourceDocument = new Document(reader.GetPageSizeWithRotation(startPage)); pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream(outputPdfPath, System.IO.FileMode.Create));
sourceDocument.Open();
for (int i = startPage; i <= endPage; i++)
{
importedPage = pdfCopyProvider.GetImportedPage(reader, i); pdfCopyProvider.AddPage(importedPage);
}
sourceDocument.Close();
reader.Close();
}
catch (Exception ex) { throw ex; }
}
/// <summary>
/// 將PDF檔案分割成單頁
/// </summary>
/// <param name="sourcePdfPath">檔案路徑+檔名</param>
public void Split2SinglePage(string sourcePdfPath)
{
PdfReader reader = null;
try
{
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
reader = new PdfReader(sourcePdfPath);
for (int i = 1; i <= reader.NumberOfPages; i++)
{
PdfCopy pdfCopyProvider = null;
PdfImportedPage importedPage = null;
Document sourceDocument = null;
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + "_" + i + ".pdf";
sourceDocument = new Document(reader.GetPageSizeWithRotation(i));
pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream(outputPdfPath, System.IO.FileMode.Create));
sourceDocument.Open();
importedPage = pdfCopyProvider.GetImportedPage(reader, i);
pdfCopyProvider.AddPage(importedPage);
sourceDocument.Close();
}
reader.Close();
}
catch (Exception ex) { throw ex; }
}
/// <summary>
/// 將PDF檔案平均分割成多個檔案,無法分盡,剩餘頁數就加到最後一個檔案
/// </summary>
/// <param name="sourcePdfPath">檔案路徑+檔名</param>
/// <param name="count">需要生成的檔案數量</param>
public void Split2AveragePage(string sourcePdfPath, int count)
{
PdfReader reader = null;
try
{
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
reader = new PdfReader(sourcePdfPath);
// int page = (reader.NumberOfPages / count);
// 計算每個檔案的頁數,總是捨去小數
int page = (int)Math.Floor((double)(reader.NumberOfPages) / (double)(count));
int startPage = 1;
int endPage = 1;
LogUtil.WriteLog("每個檔案的頁數:" + page.ToString());
for (int i = 1; i <= count; i++)
{
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + "_" + i + ".pdf"; ;
if (i == 1)
{
startPage = 1;
endPage = page;
}
else
{
startPage = endPage + 1;
endPage = startPage + page - 1;
}
if (startPage > reader.NumberOfPages)
break;
if (endPage > reader.NumberOfPages)
endPage = reader.NumberOfPages;
if (i == count)
endPage = reader.NumberOfPages;
LogUtil.WriteLog(outputPdfPath + " > " + startPage.ToString() + "-" + endPage.ToString());
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
reader.Close();
}
catch (Exception ex) { throw ex; }
}
/// <summary>
/// 將PDF檔案按檔案固定頁數割成多個檔案
/// </summary>
/// <param name="sourcePdfPath">檔案路徑+檔名</param>
/// <param name="page">每個檔案頁數</param>
public void Split2Page(string sourcePdfPath, int page)
{
PdfReader reader = null;
try
{
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
reader = new PdfReader(sourcePdfPath);
// int page = (reader.NumberOfPages / count);
// 計算按固定頁數生成檔案的數量 只要有小數都加1
int count = (int)Math.Ceiling((double)(reader.NumberOfPages) / (double)(page));
int startPage = 1;
int endPage = 1;
LogUtil.WriteLog("檔案數量:" + count.ToString());
for (int i = 1; i <= count; i++)
{
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + "_" + i + ".pdf"; ;
if (i == 1)
{
startPage = 1;
endPage = page;
}
else
{
startPage = endPage + 1;
endPage = endPage + page;
}
if (startPage > reader.NumberOfPages)
break;
if (endPage > reader.NumberOfPages)
endPage = reader.NumberOfPages;
if (i == count)
endPage = reader.NumberOfPages;
LogUtil.WriteLog(outputPdfPath + " > " + startPage.ToString() + "-" + endPage.ToString());
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
reader.Close();
}
catch (Exception ex) { throw ex; }
}
/// <summary>
/// 從已有PDF檔案中拷貝指定的頁碼範圍到一個新的pdf檔案中 使用pdfCopyProvider.AddPage()方法
/// </summary>
/// <param name="sourcePdfPath">檔案路徑+檔名</param>
/// <param name="custpages">自定義的頁數範圍</param>
public void SplitPDFCustPage(string sourcePdfPath, string custpages)
{
// string[] strArray = custpages.Trim().Split(",");
string[] strArray = custpages.Trim().Split(new Char[] { ',' });
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
int startPage;
int endPage;
for (int i = 0; i < strArray.Length; i++)
{
LogUtil.WriteLog("自定義頁面範圍:" + strArray[i]);
// 橫槓-相連的頁碼,抽取連續的範圍內的頁碼生成到一個檔案
if (strArray[i].Contains("-"))
{
// string[] array = strArray[i].Split("-");
string[] array = strArray[i].Split(new Char[] { '-' });
startPage = int.Parse(array[0]);
endPage = int.Parse(array[1]);
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + " " + startPage + "-" + endPage + ".pdf";
LogUtil.WriteLog(outputPdfPath);
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
// and &相連的頁碼,抽取指定頁碼生成到一個檔案
else if (strArray[i].Contains("&"))
{
// int[] intArray = Array.ConvertAll(strArray[i].Split("&"), int.Parse);
int[] intArray = Array.ConvertAll(strArray[i].Split(new Char[] { '&' }), int.Parse);
string pages = string.Join("&", intArray);
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + " " + pages + ".pdf";
LogUtil.WriteLog(outputPdfPath);
SplitPDF2ExtractPages(sourcePdfPath, outputPdfPath, intArray);
}
else
{
startPage = int.Parse(strArray[i]);
endPage = int.Parse(strArray[i]);
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + " " + strArray[i] + ".pdf"; ;
LogUtil.WriteLog(outputPdfPath);
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
}
}
/// <summary>
/// 將已有pdf檔案中 不連續 的頁拷貝至新的pdf檔案中。其中需要拷貝的頁碼存於陣列 int[] extractThesePages中
/// </summary>
/// <param name="sourcePdfPath">檔案路徑+檔名</param>
/// <param name="extractThesePages">頁碼集合</param>
/// <param name="outputPdfPath">檔案路徑+檔名</param>
public void SplitPDF2ExtractPages(string sourcePdfPath, string outputPdfPath, int[] extractThesePages)
{
PdfReader reader = null;
Document sourceDocument = null;
PdfCopy pdfCopyProvider = null;
PdfImportedPage importedPage = null;
try
{
reader = new PdfReader(sourcePdfPath);
sourceDocument = new Document(reader.GetPageSizeWithRotation(extractThesePages[0]));
pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream(outputPdfPath, System.IO.FileMode.Create));
sourceDocument.Open();
foreach (int pageNumber in extractThesePages)
{
importedPage = pdfCopyProvider.GetImportedPage(reader, pageNumber); pdfCopyProvider.AddPage(importedPage);
}
sourceDocument.Close();
reader.Close();
}
catch (Exception ex)
{
throw ex;
}
}
}
}
程式碼會後續開源,上傳到github。