Sed 命令完全指南
在前面的文章中,我展示了 Sed 命令的基本用法, Sed 是一個實用的流編輯器。今天,我們準備去了解關於 Sed 更多的知識,深入了解 Sed 的執行模式。這將是你全面了解 Sed 命令的一個機會,深入挖掘它的執行細節和精妙之處。因此,如果你已經做好了準備,那就開啟終端吧,下載測試檔案 然後坐在電腦前:開始我們的探索之旅吧!
關於 Sed 的一點點理論知識
首先我們看一下 sed 的執行模式
要準確理解 Sed 命令,你必須先了解工具的執行模式。
當處理資料時,Sed 從輸入源一次讀入一行,並將它儲存到所謂的模式空間中。所有 Sed 的變換都發生在模式空間。變換都是由命令列上或外部 Sed 指令碼檔案提供的單字母命令來描述的。大多數 Sed 命令都可以由一個地址或一個地址範圍作為前導來限制它們的作用範圍。
預設情況下,Sed 在結束每個處理迴圈後輸出模式空間中的內容,也就是說,輸出發生在輸入的下一個行覆蓋模式空間之前。我們可以將這種執行模式總結如下:
- 嘗試將下一個行讀入到模式空間中
- 如果讀取成功:
- 按指令碼中的順序將所有命令應用到與那個地址匹配的當前輸入行上
- 如果 sed 沒有以靜默模式(
-n)執行,那麼將輸出模式空間中的所有內容(可能會是修改過的)。 - 重新回到 1。
因此,在每個行被處理完畢之後,模式空間中的內容將被丟棄,它並不適合長時間儲存內容。基於這種目的,Sed 有第二個緩衝區:保持空間。除非你顯式地要求它將資料置入到保持空間、或從保持空間中取得資料,否則 Sed 從不清除保持空間的內容。在我們後面學習到 exchange、get、hold 命令時將深入研究它。
Sed 的抽象機制
你將在許多的 Sed 教學中都會看到上面解釋的模式。的確,這是充分正確理解大多數基本 Sed 程式所必需的。但是當你深入研究更多的高階命令時,你將會發現,僅這些知識還是不夠的。因此,我們現在嘗試去瞭解更深入的一些知識。
的確,Sed 可以被視為是抽象機制的實現,它的狀態由三個緩衝區 、兩個暫存器和兩個標誌來定義的:
- 三個緩衝區用於去儲存任意長度的文字。是的,是三個!在前面的基本執行模式中我們談到了兩個:模式空間和保持空間,但是 Sed 還有第三個緩衝區:追加佇列。從 Sed 指令碼的角度來看,它是一個只寫緩衝區,Sed 將在它執行時的預定義階段來自動重新整理它(一般是在從輸入源讀入一個新行之前,或僅在它退出執行之前)。
- Sed 也維護兩個暫存器:行計數器(LC)用於儲存從輸入源讀取的行數,而程式計數器(PC)總是用來儲存下一個將要執行的命令的索引(就是指令碼中的位置),Sed 將它作為它的主迴圈的一部分來自動增加 PC。但在使用特定的命令時,指令碼也可以直接修改 PC 去跳過或重複執行程式的一部分。這就像使用 Sed 實現的一個迴圈或條件語句。更多內容將在下面的專用分支一節中描述。
- 最後,兩個標誌可以修改某些 Sed 命令的行為:自動輸出(AP)標誌和<ruby替換 substitution(SF)標誌。當自動輸出標誌 AP 被設定時,Sed 將在模式空間的內容被覆蓋前自動輸出(尤其是,包括但不限於,在從輸入源讀入一個新行之前)。當自動輸出標誌被清除時(即:沒有設定),Sed 在指令碼中沒有顯式命令的情況下,將不會輸出模式空間中的內容。你可以通過在“靜默模式”(使用命令列選項
-n或者在第一行或指令碼中使用特殊注釋#n)執行 Sed 命令來清除自動輸出標誌。當它的地址和查詢模式與模式空間中的內容都匹配時,替換標誌 SF 將被替換命令(s命令)設定。替換標誌在每個新的迴圈開始時、或當從輸入源讀入一個新行時、或獲得條件分支之後將被清除。我們將在分支一節中詳細研究這一話題。
另外,Sed 維護一個進入到它的地址範圍(關於地址範圍的更多知識將在地址範圍一節詳細描述)的命令列表,以及用於讀取和寫入資料的兩個檔案控制代碼(你將在讀取和寫入命令的描述中獲得更多有關檔案控制代碼的內容)。
一個更精確的 Sed 執行模式
一圖勝千言,所以我畫了一個流程圖去描述 Sed 的執行模式。我將兩個東西放在了旁邊,像處理多個輸入檔案或錯誤處理,但是我認為這足夠你去理解任何 Sed 程式的行為了,並且可以避免你在編寫你自己的 Sed 指令碼時浪費在摸索上的時間。
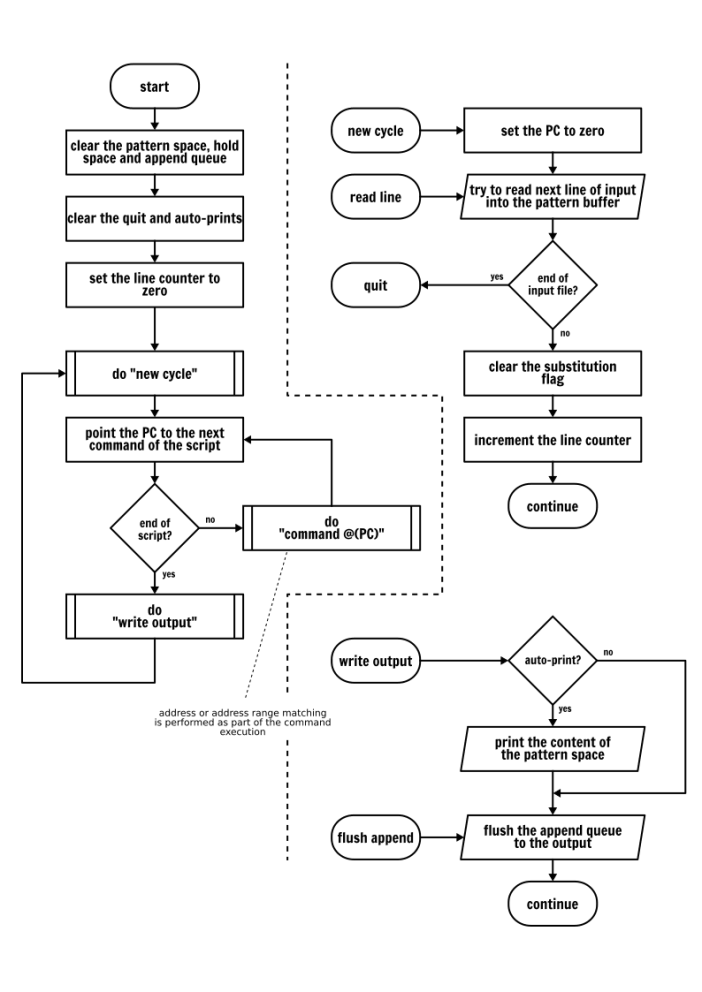
你可能已經注意到,在上面的流程圖上我並沒有描述特定的命令動作。對於命令,我們將逐個詳細講解。因此,不用著急,我們馬上開始!
列印命令
列印命令(p)是用於輸出在它執行那一刻模式空間中的內容。它並不會以任何方式改變 Sed 抽象機制中的狀態。
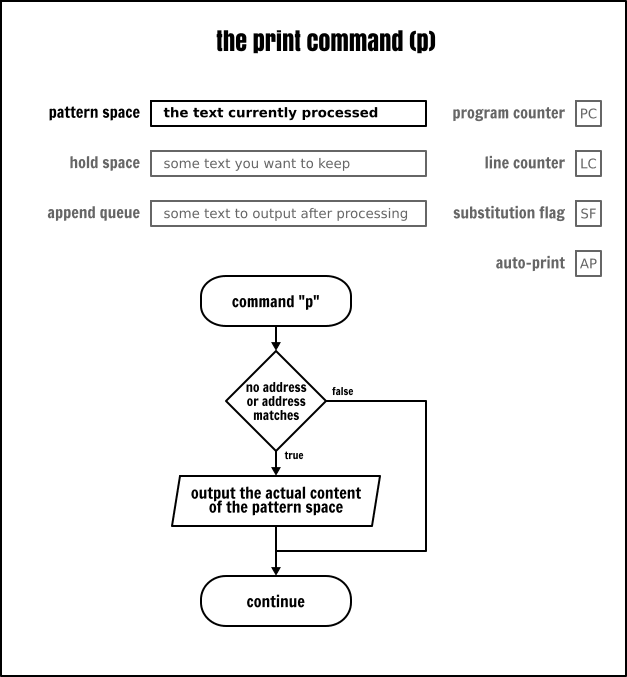
範例:
sed -e 'p' inputfile上面的命令將輸出輸入檔案中每一行的內容……兩次,因為你一旦顯式地要求使用 p 命令時,將會在每個處理迴圈結束時再隱式地輸出一次(因為在這裡我們不是在“靜默模式”中執行 Sed)。
如果我們不想每個行看到兩次,我們可以用兩種方式去解決它:
sed -n -e 'p' inputfile # 在靜默模式中顯式輸出sed -e '' inputfile # 空的“什麼都不做的”程式,隱式輸出注意:-e 選項是引入一個 Sed 命令。它被用於區分命令和檔名。由於一個 Sed 表示式必須包含至少一個命令,所以對於第一個命令,-e 標誌不是必需的。但是,由於我個人使用習慣問題,為了與在這裡的大多數的一個命令列上給出多個 Sed 表示式的更複雜的案例保持一致性,我新增了它。你自己去判斷這是一個好習慣還是壞習慣,並且在本文的後面部分還將延用這一習慣。
地址
顯而易見,print 命令本身並沒有太多的用處。但是,如果你在它之前新增一個地址,這樣它就只輸出輸入檔案的一些行,這樣它就突然變得能夠從一個輸入檔案中過濾一些不希望的行。那麼 Sed 的地址又是什麼呢?它是如何來辨別輸入檔案的“行”呢?
行號
Sed 的地址既可以是一個行號($ 表示“最後一行”)也可以是一個正規表示式。在使用行號時,你需要記住 Sed 中的行數是從 1 開始的 —— 並且需要注意的是,它不是從 0 行開始的。
sed -n -e '1p' inputfile # 僅輸出檔案的第一行sed -n -e '5p' inputfile # 僅輸出第 5 行sed -n -e '$p' inputfile # 輸出檔案的最後一行sed -n -e '0p' inputfile # 結果將是報錯,因為 0 不是有效的行號根據 POSIX 規範,如果你指定了幾個輸出檔案,那麼它的行號是累加的。換句話說,當 Sed 開啟一個新輸入檔案時,它的行計數器是不會被重置的。因此,以下的兩個命令所做的事情是一樣的。僅輸出一行文字:
sed -n -e '1p' inputfile1 inputfile2 inputfile3cat inputfile1 inputfile2 inputfile3 | sed -n -e '1p'實際上,確實在 POSIX 中規定了多個檔案是如何處理的:
如果指定了多個檔案,將按指定的檔案命名順序進行讀取並被串聯編輯。
但是,一些 Sed 的實現提供了命令列選項去改變這種行為,比如, GNU Sed 的 -s 標誌(在使用 GNU Sed -i 標誌時,它也被隱式地應用):
sed -sn -e '1p' inputfile1 inputfile2 inputfile3如果你的 Sed 實現支援這種非標準選項,那麼關於它的具體細節請檢視 man 手冊頁。
正規表示式
我前面說過,Sed 地址既可以是行號也可以是正規表示式。那麼正規表示式是什麼呢?
正如它的名字,一個正規表示式是描述一個字串集合的方法。如果一個指定的字串符合一個正規表示式所描述的集合,那麼我們就認為這個字串與正規表示式匹配。
正規表示式可以包含必須完全匹配的文字字元。例如,所有的字母和數位,以及大部分可以列印的字元。但是,一些符號有特定意義:
- 它們相當於錨,像
^和$它們分別表示一個行的開始和結束; - 能夠做為整個字元集的預留位置的其它符號(比如圓點
.可以匹配任意單個字元,或者方括號[]用於定義一個自定義的字元集); - 另外的是表示重複出現的數量(像 克萊尼星號(
*) 表示前面的模式出現 0、1 或多次);
這篇文章的目的不是給大家講正規表示式。因此,我只黏幾個範例。但是,你可以在網路上隨便找到很多關於正規表示式的教學,正規表示式的功能非常強大,它可用於許多標準的 Unix 命令和程式語言中,並且是每個 Unix 使用者應該掌握的技能。
下面是使用 Sed 地址的幾個範例:
sed -n -e '/systemd/p' inputfile # 僅輸出包含字串“systemd”的行sed -n -e '/nologin$/p' inputfile # 僅輸出以“nologin”結尾的行sed -n -e '/^bin/p' inputfile # 僅輸出以“bin”開頭的行sed -n -e '/^$/p' inputfile # 僅輸出空行(即:開始和結束之間什麼都沒有的行)sed -n -e '/./p' inputfile # 僅輸出包含字元的行(即:非空行)sed -n -e '/^.$/p' inputfile # 僅輸出只包含一個字元的行sed -n -e '/admin.*false/p' inputfile # 僅輸出包含字串“admin”後面有字串“false”的行(在它們之間有任意數量的任意字元)sed -n -e '/1[0,3]/p' inputfile # 僅輸出包含一個“1”並且後面是一個“0”或“3”的行sed -n -e '/1[0-2]/p' inputfile # 僅輸出包含一個“1”並且後面是一個“0”、“1”、“2”或“3”的行sed -n -e '/1.*2/p' inputfile # 僅輸出包含字元“1”後面是一個“2”(在它們之間有任意數量的字元)的行sed -n -e '/1[0-9]*2/p' inputfile # 僅輸出包含字元“1”後面跟著“0”、“1”、或更多數位,最後面是一個“2”的行如果你想在正規表示式(包括正規表示式分隔符)中去除字元的特殊意義,你可以在它前面使用一個反斜槓:
# 輸出所有包含字串“/usr/sbin/nologin”的行sed -ne '/\/usr\/sbin\/nologin/p' inputfile並不限制你只能使用斜槓作為地址中正規表示式的分隔符。你可以通過在第一個分隔符前面加上反斜槓(\)的方式,來使用任何你認為適合你需要和偏好的其它字元作為正規表示式的分隔符。當你用地址與帶檔案路徑的字元一起來匹配的時,是非常有用的:
# 以下兩個命令是完全相同的sed -ne '/\/usr\/sbin\/nologin/p' inputfilesed -ne '\=/usr/sbin/nologin=p' inputfile擴充套件的正規表示式
預設情況下,Sed 的正規表示式引擎僅理解 POSIX 基本正規表示式 的語法。如果你需要用到 擴充套件正規表示式,你必須在 Sed 命令上新增 -E 標誌。擴充套件正規表示式在基本正規表示式基礎上增加了一組額外的特性,並且很多都是很重要的,它們所要求的反斜槓要少很多。我們來比較一下:
sed -n -e '/\(www\)\|\(mail\)/p' inputfilesed -En -e '/(www)|(mail)/p' inputfile花括號量詞
正規表示式之所以強大的一個原因是範圍量詞 {,}。事實上,當你寫一個不太精確匹配的正規表示式時,量詞 * 就是一個非常完美的符號。但是,(用花括號量詞)你可以顯式在它邊上新增一個下限和上限,這樣就有了很好的靈活性。當量詞範圍的下限省略時,下限被假定為 0。當上限被省略時,上限被假定為無限大:
| 括號 | 速記詞 | 解釋 |
|---|---|---|
{,} | * | 前面的規則出現 0、1、或許多遍 |
{,1} | ? | 前面的規則出現 0 或 1 遍 |
{1,} | + | 前面的規則出現 1 或許多遍 |
{n,n} | {n} | 前面的規則精確地出現 n 遍 |
花括號在基本正規表示式中也是可以使用的,但是它要求使用反斜槓。根據 POSIX 規範,在基本正規表示式中可以使用的量詞僅有星號(*)和花括號(使用反斜杠,如 \{m,n\})。許多正規表示式引擎都擴充套件支援 \? 和 \+。但是,為什麼魔鬼如此有誘惑力呢?因為,如果你需要這些量詞,使用擴充套件正規表示式將不但易於寫而且可移植性更好。
為什麼我要花點時間去討論關於正規表示式的花括號量詞,這是因為在 Sed 指令碼中經常用這個特性去計數位符。
sed -En -e '/^.{35}$/p' inputfile # 輸出精確包含 35 個字元的行sed -En -e '/^.{0,35}$/p' inputfile # 輸出包含 35 個字元或更少字元的行sed -En -e '/^.{,35}$/p' inputfile # 輸出包含 35 個字元或更少字元的行sed -En -e '/^.{35,}$/p' inputfile # 輸出包含 35 個字元或更多字元的行sed -En -e '/.{35}/p' inputfile # 你自己指出它的輸出內容(這是留給你的測試題)地址範圍
到目前為止,我們使用的所有地址都是唯一地址。在我們使用一個唯一地址時,命令是應用在與那個地址匹配的行上。但是,Sed 也支援地址範圍。Sed 命令可以應用到那個地址範圍中從開始到結束的所有地址中的所有行上:
sed -n -e '1,5p' inputfile # 僅輸出 1 到 5 行sed -n -e '5,$p' inputfile # 從第 5 行輸出到檔案結尾sed -n -e '/www/,/systemd/p' inputfile # 輸出與正規表示式 /www/ 匹配的第一行到與接下來匹配正規表示式 /systemd/ 的行為止(LCTT 譯註:下面用的一個生成的列表例子,如下供參考:)
printf "%s\n" {a,b,c}{d,e,f} | cat -n 1 ad 2 ae 3 af 4 bd 5 be 6 bf 7 cd 8 ce 9 cf如果在開始和結束地址上使用了同一個行號,那麼範圍就縮小為那個行。事實上,如果第二個地址的數位小於或等於地址範圍中選定的第一個行的數位,那麼僅有一個行被選定:
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,4p' 4 bdprintf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,3p' 4 bd下面有點難了,但是在前面的段落中給出的規則也適用於起始地址是正規表示式的情況。在那種情況下,Sed 將對正規表示式匹配的第一個行的行號和給定的作為結束地址的顯式的行號進行比較。再強調一次,如果結束行號小於或等於起始行號,那麼這個範圍將縮小為一行:
(LCTT 譯註:此處作者陳述有誤,Sed 會在處理以正規表示式表示的開始行時,並不會同時測試結束表示式:從匹配開始行的正規表示式開始,直到不匹配時,才會測試結束行的表示式——無論是否是正規表示式——並在結束的表示式測試不通過時停止,並迴圈此測試。)
# 這個 /b/,4 地址將匹配三個單行# 因為每個匹配的行有一個行號 >= 4#(LCTT 譯註:結果正確,但是說明不正確。4、5、6 行都會因為匹配開始正規表示式而通過,第 7 行因為不匹配開始正規表示式,所以開始比較行數: 7 > 4,遂停止。)printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,4p' 4 bd 5 be 6 bf# 你自己指出匹配的範圍是多少# 第二個例子:printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/d/,4p' 1 ad 2 ae 3 af 4 bd 7 cd但是,當結束地址是一個正規表示式時,Sed 的行為將不一樣。在那種情況下,地址範圍的第一行將不會與結束地址進行檢查,因此地址範圍將至少包含兩行(當然,如果輸入資料不足的情況除外):
(LCTT 譯註:如上譯注,當滿足開始的正規表示式時,並不會測試結束的表示式;僅當不滿足開始的表示式時,才會測試結束表示式。)
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,/d/p' 4 bd 5 be 6 bf 7 cdprintf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,/d/p' 4 bd 5 be 6 bf 7 cd(LCTT 譯註:對地址範圍的總結,當滿足開始的條件時,從該行開始,並不測試該行是否滿足結束的條件;從下一行開始測試結束條件,並在結束條件不滿足時結束;然後對剩餘的行,再從開始條件開始匹配,以此迴圈——也就是說,匹配結果可以是非連續的單/多行。大家可以調整上述命令列的條件以理解。)
補集
在一個地址選擇行後面新增一個感嘆號(!)表示不匹配那個地址。例如:
sed -n -e '5!p' inputfile # 輸出除了第 5 行外的所有行sed -n -e '5,10!p' inputfile # 輸出除了第 5 到 10 之間的所有行sed -n -e '/sys/!p' inputfile # 輸出除了包含字串“sys”的所有行交集
(LCTT 譯註:原文標題為“合集”,應為“交集”)
Sed 允許在一個塊中使用花括號 {…} 組合命令。你可以利用這個特性去組合幾個地址的交集。例如,我們來比較下面兩個命令的輸出:
sed -n -e '/usb/{ /daemon/p}' inputfilesed -n -e '/usb.*daemon/p' inputfile通過在一個塊中巢狀命令,我們將在任意順序中選擇包含字串 “usb” 和 “daemon” 的行。而正規表示式 “usb.*daemon” 將僅匹配在字串 “daemon” 前面包含 “usb” 字串的行。
離題太長時間後,我們現在重新回去學習各種 Sed 命令。
退出命令
退出命令(q)是指在當前的疊代迴圈處理結束之後停止 Sed。
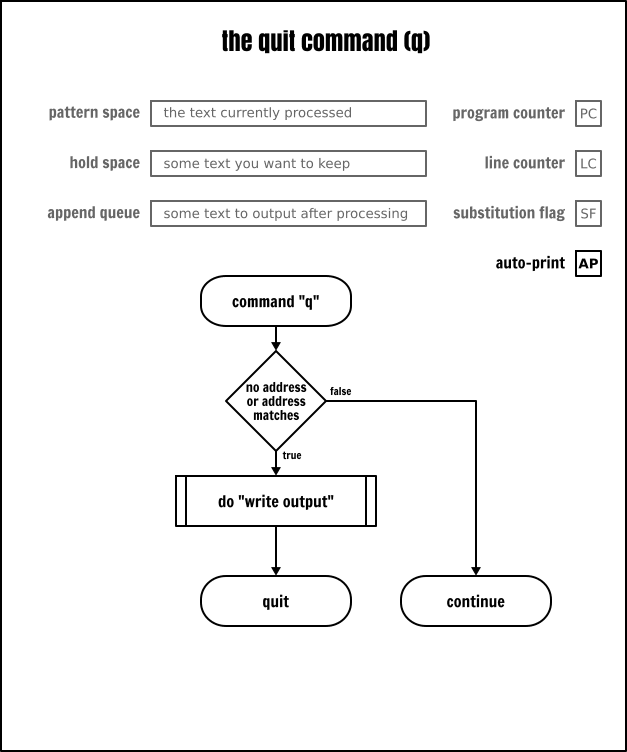
q 命令是在到達輸入檔案的尾部之前停止處理輸入的方法。為什麼會有人想去那樣做呢?
很好的問題,如果你還記得,我們可以使用下面的命令來輸出檔案中第 1 到第 5 的行:
sed -n -e '1,5p' inputfile對於大多數 Sed 的實現方式,工具將迴圈讀取輸入檔案的所有行,那怕是你只處理結果中的前 5 行。如果你的輸入檔案包含了幾百萬行(或者更糟糕的情況是,你從一個無限的資料流,比如像 /dev/urandom 中讀取)將有重大影響。
使用退出命令,相同的程式可以被修改的更高效:
sed -e '5q' inputfile由於我在這裡並不使用 -n 選項,Sed 將在每個迴圈結束後隱式輸出模式空間的內容。但是在你處理完第 5 行後,它將退出,並且因此不會去讀取更多的資料。
我們能夠使用一個類似的技巧只輸出檔案中一個特定的行。這也是從命令列中提供多個 Sed 表示式的幾種方法。下面的三個變體都可以從 Sed 中接受幾個命令,要麼是不同的 -e 選項,要麼是在相同的表示式中新起一行,或用分號(;)隔開:
sed -n -e '5p' -e '5q' inputfilesed -n -e ' 5p 5q' inputfilesed -n -e '5p;5q' inputfile如果你還記得,我們在前面看到過能夠使用花括號將命令組合起來,在這裡我們使用它來防止相同的地址重複兩次:
# 組合命令sed -e '5{ p q}' inputfile# 可以簡寫為:sed '5{p;q;}' inputfile# 作為 POSIX 擴充套件,有些實現方式可以省略閉花括號之前的分號:sed '5{p;q}' inputfile替換命令
你可以將替換命令(s)想像為 Sed 的“查詢替換”功能,這個功能在大多數的“所見即所得”的編輯器上都能找到。Sed 的替換命令與之類似,但比它們更強大。替換命令是 Sed 中最著名的命令之一,在網上有大量的關於這個命令的文件。
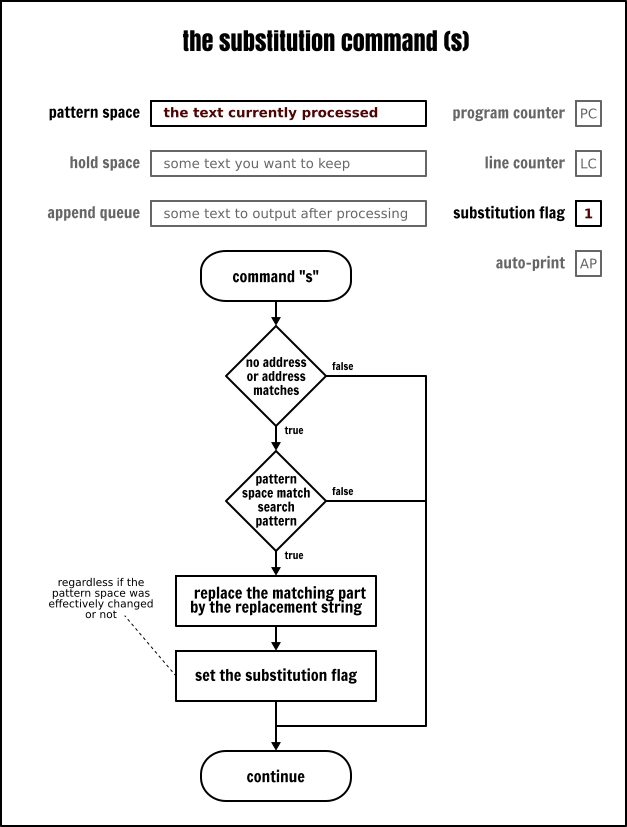
在前一篇文章中我們已經講過它了,因此,在這裡就不再重複了。但是,如果你對它的使用不是很熟悉,那麼你需要記住下面的這些關鍵點:
- 替換命令有兩個引數:查詢模式和替換字串:
sed s/:/-----/ inputfile s命令和它的引數是用任意一個字元來分隔的。這主要看你的習慣,在 99% 的時間中我都使用斜槓,但也會用其它的字元:sed s%:%-----% inputfile、sed sX:X-----X inputfile或者甚至是sed 's : ----- ' inputfile- 預設情況下,替換命令僅被應用到模式空間中匹配到的第一個字串上。你可以通過在命令之後指定一個匹配指數作為標誌來改變這種情況:
sed 's/:/-----/1' inputfile、sed 's/:/-----/2' inputfile、sed 's/:/-----/3' inputfile、… - 如果你想執行一個全域性替換(即:在模式空間上的每個非重疊匹配上進行),你需要增加
g標誌:sed 's/:/-----/g' inputfile - 在字串替換中,出現的任何一個
&符號都將被與查詢模式匹配的子字串替換:sed 's/:/-&&&-/g' inputfile、sed 's/.../& /g' inputfile - 圓括號(在擴充套件的正規表示式中的
(...),或者基本的正規表示式中的\(...\))被當做捕獲組。那是匹配字串的一部分,可以在替換字串中被參照。\1是第一個捕獲組的內容,\2是第二個捕獲組的內容,依次類推:sed -E 's/(.)(.)/\2\1/g' inputfile、sed -E 's/(.):x:(.):(.*)/\1:\3/' inputfile(後者之所能正常工作是因為 正規表示式中的量詞星號表示盡可能多的匹配,直到不匹配為止,並且它可以匹配許多個字元) - 在查詢模式或替換字串時,你可以通過使用一個反斜槓來去除任何字元的特殊意義:
sed 's/:/--\&--/g' inputfile,sed 's/\//\\/g' inputfile
所有的這些看起來有點抽象,下面是一些範例。首先,我想去顯示我的測試輸入檔案的第一個欄位並給它在右側附加 20 個空格字元,我可以這樣寫:
sed < inputfile -E -e ' s/:/ / # 用 20 個空格替換第一個欄位的分隔符 s/(.{20}).*/\1/ # 只保留一行的前 20 個字元 s/.*/| & |/ # 為了輸出好看新增豎條'第二個範例是,如果我想將使用者 sonia 的 UID/GID 修改為 1100,我可以這樣寫:
sed -En -e ' /sonia/{ s/[0-9]+/1100/g p }' inputfile注意在替換命令結束部分的 g 選項。這個選項改變了它的行為,因此它將查詢全部的模式空間並替換,如果沒有那個選項,它只替換查詢到的第一個。
順便說一下,這也是使用前面講過的輸出(p)命令的好機會,可以在命令執行時輸出修改前後的模式空間的內容。因此,為了獲得替換前後的內容,我可以這樣寫:
sed -En -e ' /sonia/{ p s/[0-9]+/1100/g p }' inputfile事實上,替換後輸出一個行是很常見的用法,因此,替換命令也接受 p 選項:
sed -En -e '/sonia/s/[0-9]+/1100/gp' inputfile最後,我就不詳細講替換命令的 w 選項了,我們將在稍後的學習中詳細介紹。
刪除命令
刪除命令(d)用於清除模式空間的內容,然後立即開始下一個處理迴圈。這樣它將會跳過隱式輸出模式空間內容的行為,即便是你設定了自動輸出標誌(AP)也不會輸出。
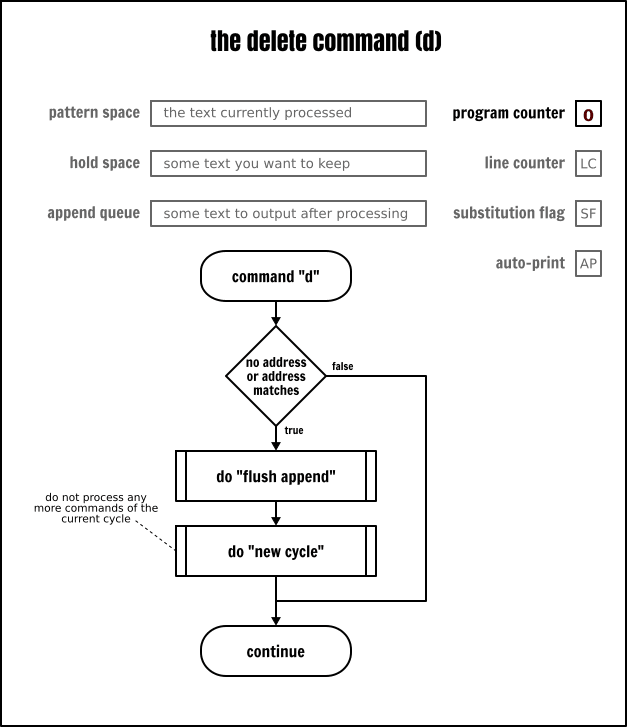
只輸出一個檔案前五行的一個很低效率的方法將是:
sed -e '6,$d' inputfile你猜猜看,我為什麼說它很低效率?如果你猜不到,建議你再次去閱讀前面的關於退出命令的章節,答案就在那裡!
當你組合使用正規表示式和地址,從輸出中刪除匹配的行時,刪除命令將非常有用:
sed -e '/systemd/d' inputfile次行命令
如果 Sed 命令沒有執行在靜默模式中,這個命令(n)將輸出當前模式空間的內容,然後,在任何情況下它將讀取下一個輸入行到模式空間中,並使用新的模式空間中的內容來執行當前迴圈中剩餘的命令。
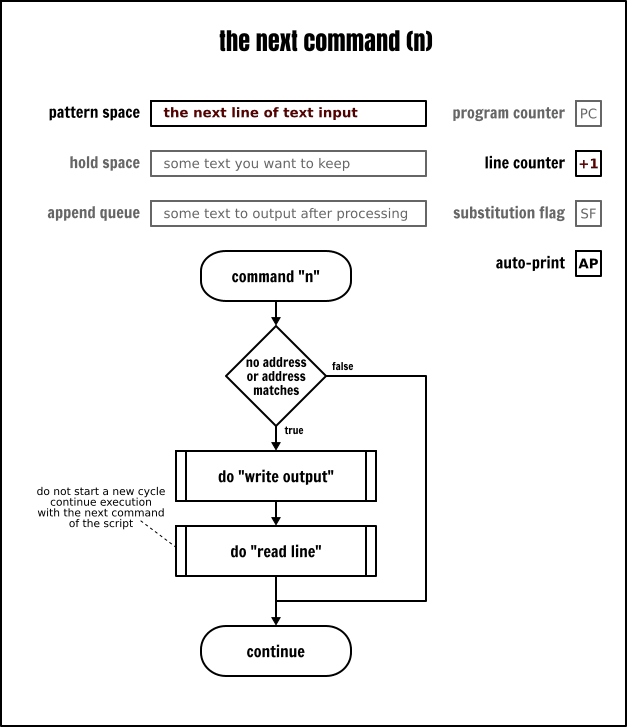
用次行命令去跳過行的一個常見範例:
cat -n inputfile | sed -n -e 'n;n;p'在上面的例子中,Sed 將隱式地讀取輸入檔案的第一行。但是次行命令將丟棄對模式空間中的內容的輸出(不輸出是因為使用了 -n 選項),並從輸入檔案中讀取下一行來替換模式空間中的內容。而第二個次行命令做的事情和前一個是一模一樣的,這就實現了跳過輸入檔案 2 行的目的。最後,這個指令碼顯式地輸出包含在模式空間中的輸入檔案的第三行的內容。然後,Sed 將啟動一個新的迴圈,由於次行命令,它會隱式地讀取第 4 行的內容,然後跳過它,同樣地也跳過第 5 行,並輸出第 6 行。如此迴圈,直到檔案結束。總體來看,這個指令碼就是讀取輸入檔案然後每三行輸出一行。
使用次行命令,我們也可以找到一些顯示輸入檔案的前五行的幾種方法:
cat -n inputfile | sed -n -e '1{p;n;p;n;p;n;p;n;p}'cat -n inputfile | sed -n -e 'p;n;p;n;p;n;p;n;p;q'cat -n inputfile | sed -e 'n;n;n;n;q'更有趣的是,如果你需要根據一些地址來處理行時,次行命令也非常有用:
cat -n inputfile | sed -n '/pulse/p' # 輸出包含 “pulse” 的行cat -n inputfile | sed -n '/pulse/{n;p}' # 輸出包含 “pulse” 之後的行cat -n inputfile | sed -n '/pulse/{n;n;p}' # 輸出包含 “pulse” 的行的下一行的下一行使用保持空間
到目前為止,我們所看到的命令都是僅使用了模式空間。但是,我們在文章的開始部分已經提到過,還有第二個緩衝區:保持空間,它完全由使用者管理。它就是我們在第二節中描述的目標。
交換命令
正如它的名字所表示的,交換命令(x)將交換保持空間和模式空間的內容。記住,你只要沒有把任何東西放入到保持空間中,那麼保持空間就是空的。
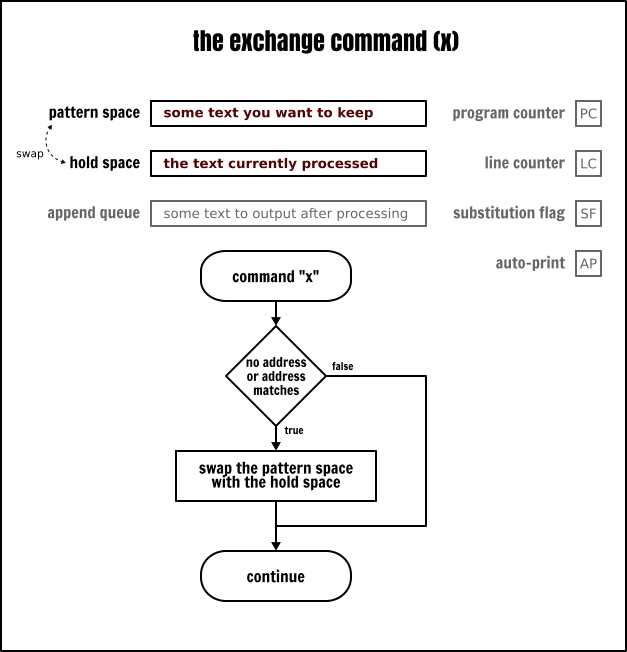
作為第一個範例,我們可使用交換命令去反序輸出一個輸入檔案的前兩行:
cat -n inputfile | sed -n -e 'x;n;p;x;p;q'當然,在你設定保持空間之後你並沒有立即使用它的內容,因為只要你沒有顯式地去修改它,保持空間中的內容就保持不變。在下面的例子中,我在輸入一個檔案的前五行後,使用它去刪除第一行:
cat -n inputfile | sed -n -e ' 1{x;n} # 交換保持和模式空間 # 儲存第 1 行到保持空間中 # 然後讀取第 2 行 5{ p # 輸出第 5 行 x # 交換保持和模式空間 # 去取得第 1 行的內容放回到模式空間 } 1,5p # 輸出第 2 到第 5 行 # (並沒有輸錯!嘗試找出這個規則 # 沒有在第 1 行上執行的原因 ;)'保持命令
保持命令(h)是用於將模式空間中的內容儲存到保持空間中。但是,與交換命令不同的是,模式空間中的內容不會被改變。保持命令有兩種用法:
h將複製模式空間中的內容到保持空間中,覆蓋保持空間中任何已經存在的內容。H將模式空間中的內容追加到保持空間中,使用一個新行作為分隔符。
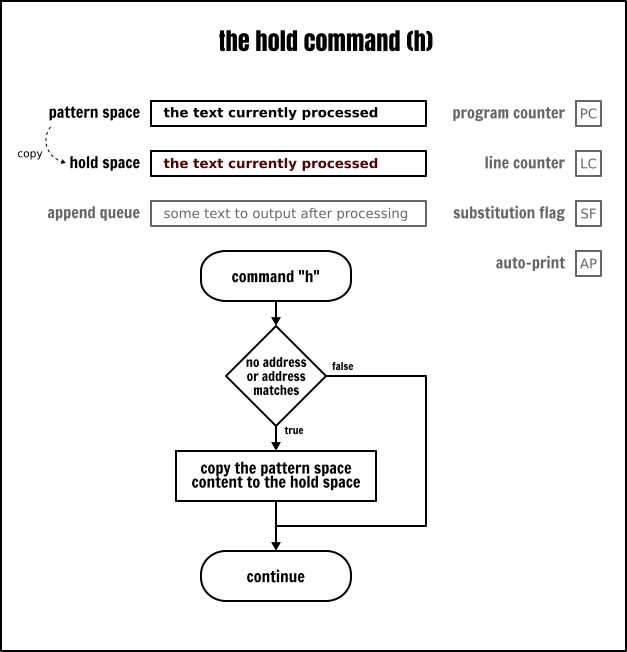
上面使用交換命令的例子可以使用保持命令重寫如下:
cat -n inputfile | sed -n -e ' 1{h;n} # 儲存第 1 行的內容到保持緩衝區並繼續 5{ # 在第 5 行 x # 交換模式和保持空間 # (現在模式空間包含了第 1 行) H # 在保持空間的第 5 行後追加第 1 行 x # 再次交換第 5 行和第 1 行,第 5 行回到模式空間 } 1,5p # 輸出第 2 行到第 5 行 # (沒有輸錯!嘗試去找到為什麼這個規則 # 不在第 1 行上執行 ;)'獲取命令
獲取命令(g)與保持命令恰好相反:它從保持空間中取得內容並將它置入到模式空間中。同樣它也有兩種方式:
g將複製保持空間中的內容並將其放入到模式空間,覆蓋模式空間中已存在的任何內容G將保持空間中的內容追加到模式空間中,並使用一個新行作為分隔符
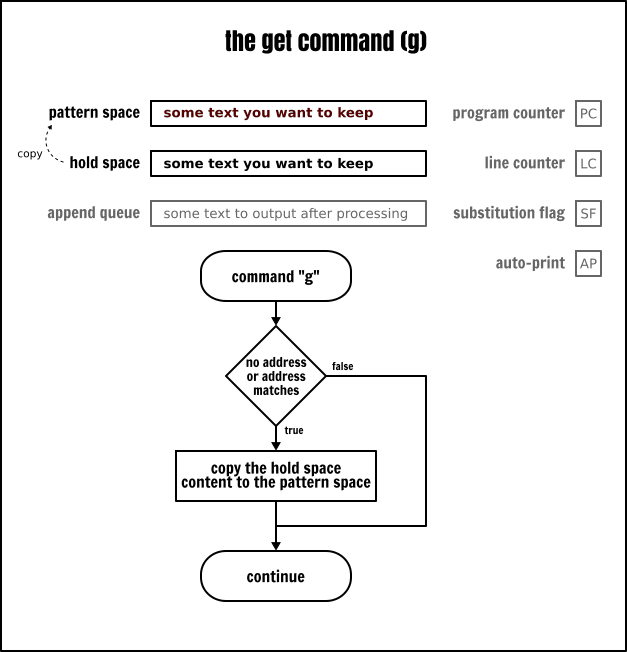
將保持命令和獲取命令一起使用,可以允許你去儲存並調回資料。作為一個小挑戰,我讓你重寫前一節中的範例,將輸入檔案的第 1 行放置在第 5 行之後,但是這次必須使用獲取和保持命令(使用大寫或小寫命令的版本)而不能使用交換命令。帶點小運氣,可以更簡單!
同時,我可以給你展示另一個範例,它能給你一些靈感。目標是將擁有登入 shell 許可權的使用者與其它使用者分開:
cat -n inputfile | sed -En -e ' \=(/usr/sbin/nologin|/bin/false)$= { H;d; } # 追回匹配的行到保持空間 # 然後繼續下一個迴圈 p # 輸出其它行 $ { g;p } # 在最後一行上 # 獲取並列印保持空間中的內容'複習列印、刪除和次行命令
現在你已經更熟悉使用保持空間了,我們回到列印、刪除和次行命令。我們已經討論了小寫的 p、d 和 n 命令了。而它們也有大寫的版本。因為每個命令都有大小寫版本,似乎是 Sed 的習慣,這些命令的大寫版本將與多行緩衝區有關:
P將模式空間中第一個新行之前的內容輸出D刪除模式空間中第一個新行之前的內容(包含新行),然後不讀取任何新的輸入而是使用剩餘的文字去重新啟動一個迴圈N讀取輸入並追加一個新行到模式空間,用一個新行作為新舊資料的分隔符。繼續執行當前的迴圈。
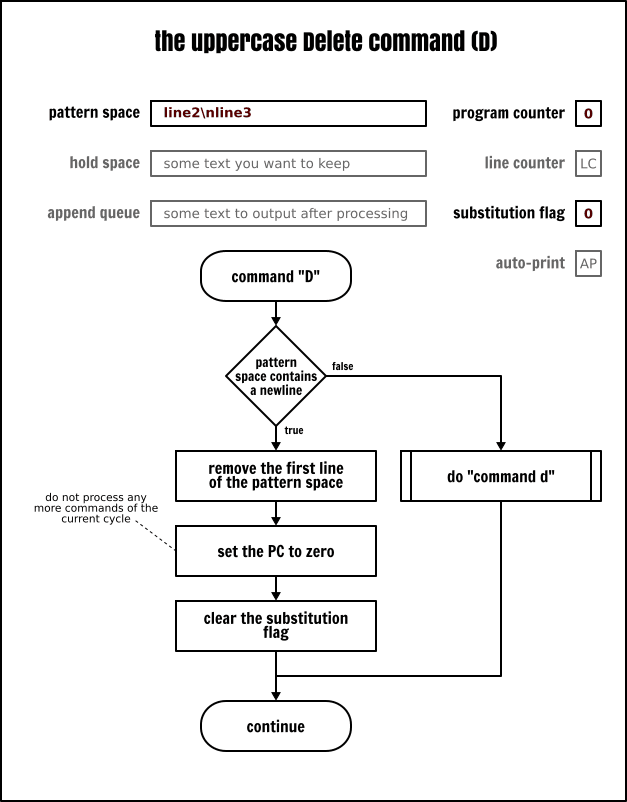
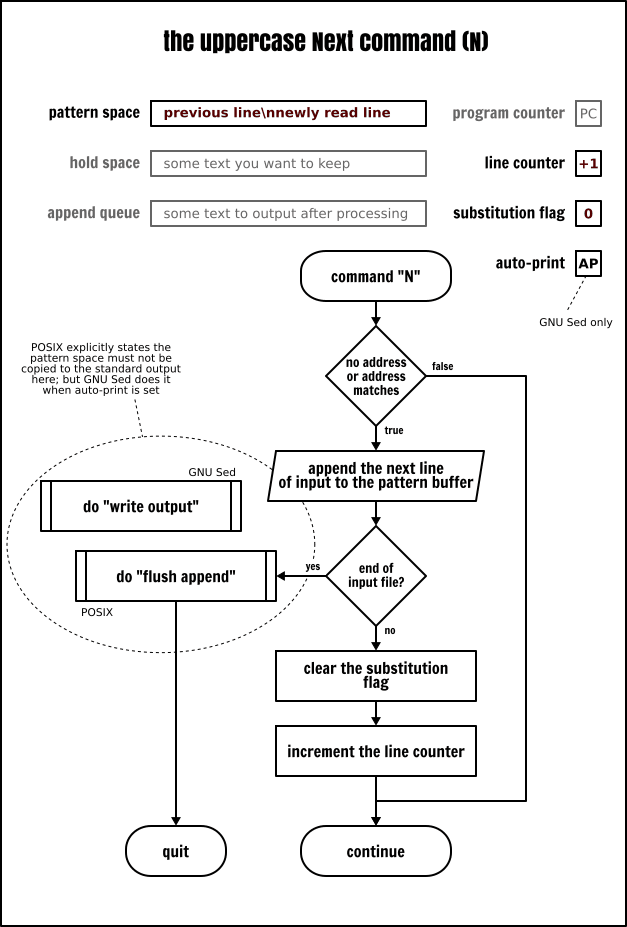
這些命令的使用場景主要用於實現佇列(FIFO 列表)。從一個輸入檔案中刪除最後 5 行就是一個很權威的例子:
cat -n inputfile | sed -En -e ' 1 { N;N;N;N } # 確保模式空間中包含 5 行 N # 追加第 6 行到佇列中 P # 輸出佇列的第 1 行 D # 刪除佇列的第 1 行'作為第二個範例,我們可以在兩個列上顯示輸入資料:
# 輸出兩列sed < inputfile -En -e ' $!N # 追加一個新行到模式空間 # 除了輸入檔案的最後一行 # 當在輸入檔案的最後一行使用 N 命令時 # GNU Sed 和 POSIX Sed 的行為是有差異的 # 需要使用一個技巧去處理這種情況 # https://www.gnu.org/software/sed/manual/sed.html#N_005fcommand_005flast_005fline # 用空間填充第 1 行的第 1 個欄位 # 並丟棄其餘行 s/:.*\n/ \n/ s/:.*// # 除了第 2 行上的第 1 個欄位外,丟棄其餘的行 s/(.{20}).*\n/\1/ # 修剪並連線行 p # 輸出結果'分支
我們剛才已經看到,Sed 因為有保持空間所以有了快取的功能。其實它還有測試和分支的指令。因為有這些特性使得 Sed 是一個圖靈完備的語言。雖然它可能看起來很傻,但意味著你可以使用 Sed 寫任何程式。你可以實現任何你的目的,但並不意味著實現起來會很容易,而且結果也不一定會很高效。
不過不用擔心。在本文中,我們將使用能夠展示測試和分支功能的最簡單的例子。雖然這些功能乍一看似乎很有限,但請記住,有些人用 Sed 寫了 http://www.catonmat.net/ftp/sed/dc.sed [計算器]、http://www.catonmat.net/ftp/sed/sedtris.sed [俄羅斯方塊] 或許多其它型別的應用程式!
標籤和分支
從某些方面,你可以將 Sed 看到是一個功能有限的組合語言。因此,你不會找到在高階語言中常見的 “for” 或 “while” 迴圈,或者 “if … else” 語句,但是你可以使用分支來實現同樣的功能。
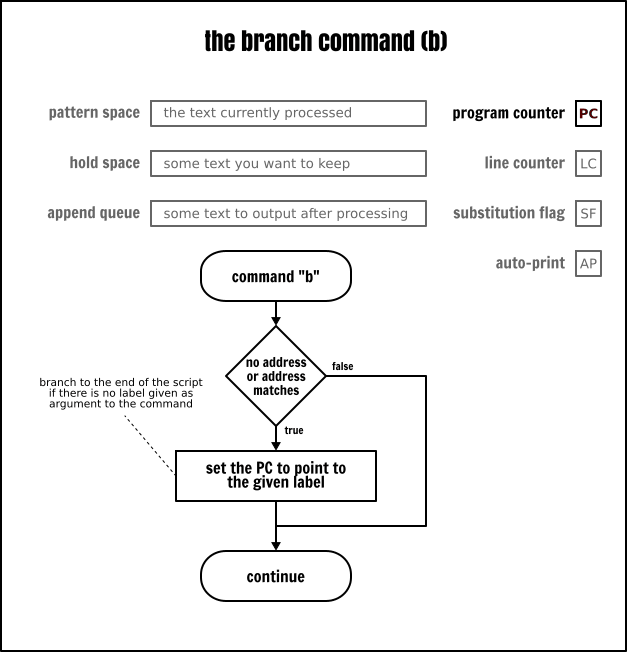
如果你在本文開始部分看到了用流程圖描述的 Sed 執行模型,那麼你應該知道 Sed 會自動增加程式計數器(PC)的值,命令是按程式的指令順序來執行的。但是,使用分支(b)指令,你可以通過選擇執行程式中的任意命令來改變順序執行的程式。跳轉目的地是使用一個標籤(:)來顯式定義的。
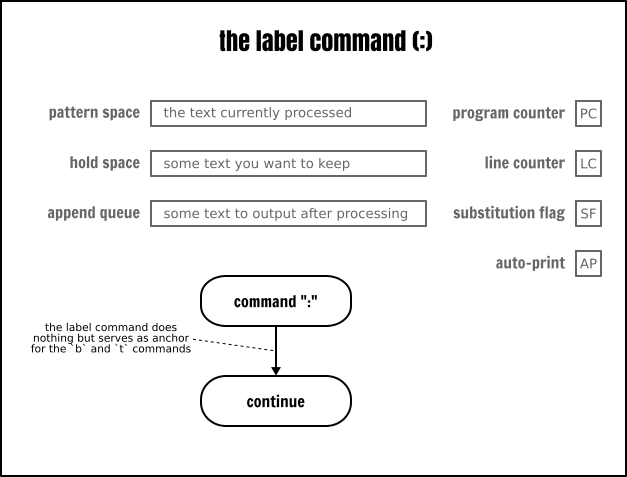
這是一個這樣的範例:
echo hello | sed -ne ' :start # 在程式的該行上放置一個 “start” 標籤 p # 輸出模式空間內容 b start # 繼續在 :start 標籤上執行' | less那個 Sed 程式的行為非常類似於 yes 命令:它獲取一個字串並產生一個包含那個字串的無限流。
切換到一個標籤就像我們繞開了 Sed 的自動化特性一樣:它既不讀取任何輸入,也不輸出任何內容,更不更新任何緩衝區。它只是跳轉到源程式指令順序中下一條的另外一個指令。
值得一提的是,如果在分支命令(b)上沒有指定一個標簽作為它的引數,那麼分支將直接切換到程式結束的地方。因此,Sed 將啟動一個新的迴圈。這個特性可以用於去跳過一些指令並且因此可以用於作為“塊”的替代者:
cat -n inputfile | sed -ne '/usb/!b/daemon/!bp'條件分支
到目前為止,我們已經看到了無條件分支,這個術語可能有點誤導嫌疑,因為 Sed 命令總是基於它們的可選地址來作為條件的。
但是,在傳統意義上,一個無條件分支也是一個分支,當它執行時,將跳轉到特定的目的地,而條件分支既有可能也或許不可能跳轉到特定的指令,這取決於系統的當前狀態。
Sed 只有一個條件指令,就是測試(t)命令。只有在當前迴圈的開始或因為前一個條件分支執行了替換,它才跳轉到不同的指令。更多的情況是,只有替換標誌被設定時,測試命令才會切換分支。
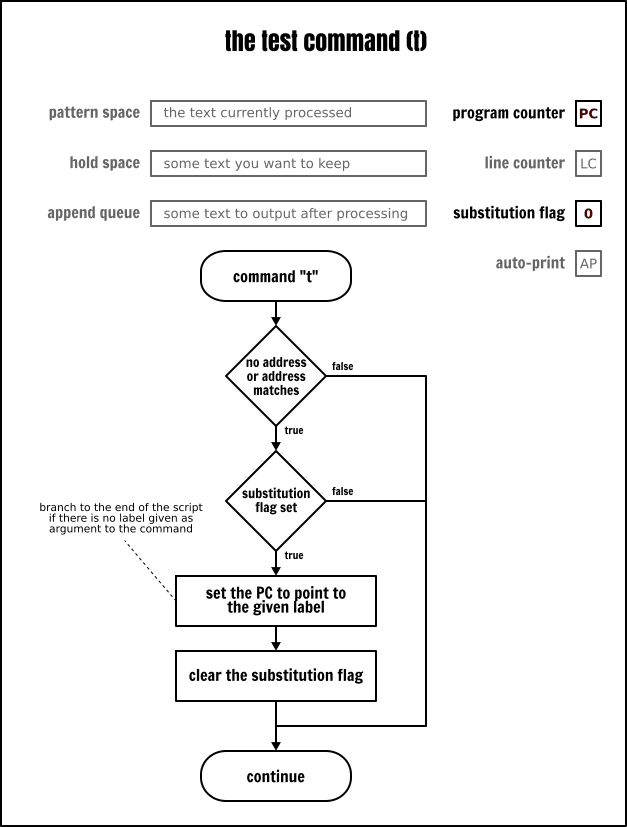
使用測試指令,你可以在一個 Sed 程式中很輕鬆地執行一個迴圈。作為一個特定的範例,你可以用它將一個行填充到某個長度(這是使用正規表示式無法實現的):
# 居中文字cut -d: -f1 inputfile | sed -Ee ' :start s/^(.{,19})$/ \1 / # 用一個空格填充少於 20 個字元的行的開始處 # 並在結束處新增另一個空格 t start # 如果我們已經新增了一個空格,則返回到 :start 標籤 s/(.{20}).*/| \1 |/ # 只保留一個行的前 20 個字元 # 以修復由於奇數行引起的差一錯誤'如果你仔細讀前面的範例,你可能注意到,在將要把資料“喂”給 Sed 之前,我通過 cut 命令做了一點小修正去預處理資料。
不過,我們也可以只使用 Sed 對程式做一些小修改來執行相同的任務:
cat inputfile | sed -Ee ' s/:.*// # 除第 1 個欄位外刪除剩餘欄位 t start :start s/^(.{,19})$/ \1 / # 用一個空格填充少於 20 個字元的行的開始處 # 並在結束處新增另一個空格 t start # 如果我們已經新增了一個空格,則返回到 :start 標籤 s/(.{20}).*/| \1 |/ # 僅保留一個行的前 20 個字元 # 以修復由於奇數行引起的差一錯誤'在上面的範例中,你或許對下列的結構感到驚奇:
t start:start乍一看,在這裡的分支並沒有用,因為它只是跳轉到將要執行的指令處。但是,如果你仔細閱讀了測試命令的定義,你將會看到,如果在當前迴圈的開始或者前一個測試命令執行後發生了一個替換,分支才會起作用。換句話說就是,測試指令有清除替換標誌的副作用。這也正是上面的程式碼片段的真實目的。這是一個在包含條件分支的 Sed 程式中經常看到的技巧,用於在使用多個替換命令時避免出現誤報的情況。
通過它並不能絕對強制地清除替換標誌,我同意這一說法。因為在將字串填充到正確的長度時我使用的特定的替換命令是冪等的。因此,一個多餘的疊代並不會改變結果。不過,我們可以現在再次看一下第二個範例:
# 基於它們的登入程式來分類使用者帳戶cat inputfile | sed -Ene ' s/^/login=/ /nologin/s/^/type=SERV / /false/s/^/type=SERV / t print s/^/type=USER / :print s/:.*//p'我希望在這裡根據使用者預設設定的登入程式,為使用者帳戶打上 “SERV” 或 “USER” 的標籤。如果你執行它,預計你將看到 “SERV” 標籤。然而,並沒有在輸出中跟蹤到 “USER” 標籤。為什麼呢?因為 t print 指令不論行的內容是什麼,它總是切換,替換標誌總是由程式的第一個替換命令來設定。一旦替換標誌設定完成後,在下一個行被讀取或直到下一個測試命令之前,這個標誌將保持不變。下面我們給出修復這個程式的解決方案:
# 基於使用者登入程式來分類使用者帳戶cat inputfile | sed -Ene ' s/^/login=/ t classify # clear the "substitution flag" :classify /nologin/s/^/type=SERV / /false/s/^/type=SERV / t print s/^/type=USER / :print s/:.*//p'精確地處理文字
Sed 是一個非互動式文字編輯器。雖然是非互動式的,但仍然是文字編輯器。而如果沒有在輸出中插入一些東西的功能,那它就不算一個完整的文字編輯器。我不是很喜歡它的文字編輯的特性,因為我發現它的語法太難用了(即便是以 Sed 的標準而言),但有時你難免會用到它。
採用嚴格的 POSIX 語法的只有三個命令:改變(c)、插入(i)或追加(a)一些文字文字到輸出,都遵循相同的特定語法:命令字母後面跟著一個反斜槓,並且文字從指令碼的下一行上開始插入:
head -5 inputfile | sed '1i\# List of user accounts$a\# end'插入多行文字,你必須每一行結束的位置使用一個反斜槓:
head -5 inputfile | sed '1i\# List of user accounts\# (users 1 through 5)$a\# end'一些 Sed 實現,比如 GNU Sed,在初始的反斜槓後面的換行符是可選的,即便是在 --posix 模式下仍然如此。我在標準中並沒有找到任何關於該替代語法的說明(如果是因為我沒有在標準中找到那個特性,請在評論區留言告訴我!)。因此,如果對可移植性要求很高,請注意使用它的風險:
# 非 POSIX 語法:head -5 inputfile | sed -e '1i\# List of user accounts$a\# end'也有一些 Sed 的實現,讓初始的反斜槓完全是可選的。因此毫無疑問,它是一個廠商對 POSIX 標準進行擴充套件的特定版本,它是否支援那個語法,你需要去檢視那個 Sed 版本的手冊。
在簡單概述之後,我們現在來回顧一下這些命令的更多細節,從我還沒有介紹的改變命令開始。
改變命令
改變命令(c\)就像 d 命令一樣刪除模式空間的內容並開始一個新的迴圈。唯一的不同在於,當命令執行之後,使用者提供的文字是寫往輸出的。
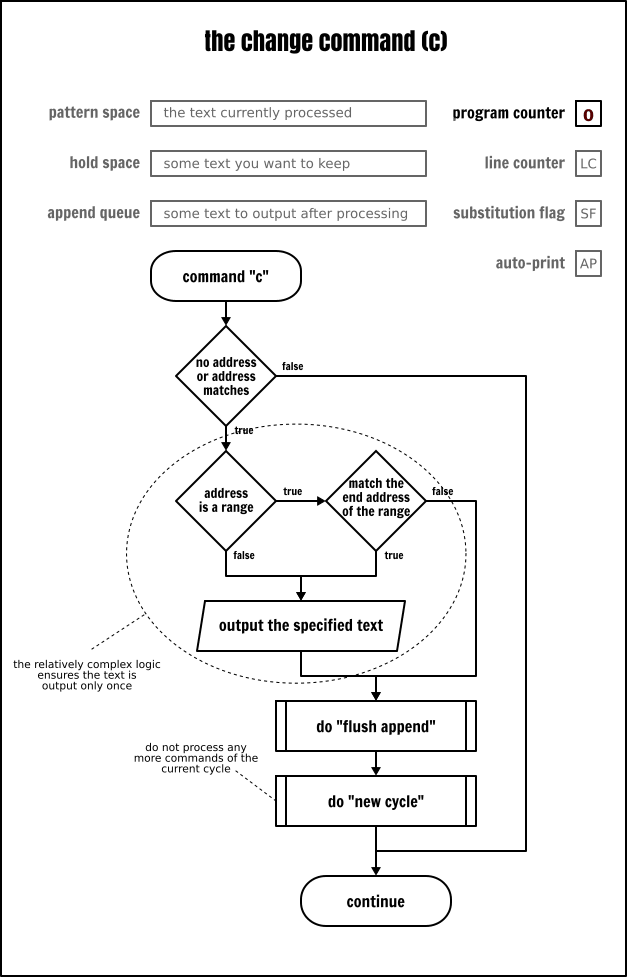
cat -n inputfile | sed -e '/systemd/c\# :REMOVED:s/:.*// # This will NOT be applied to the "changed" text'如果改變命令與一個地址範圍關聯,當到達範圍的最後一行時,這個文字將僅輸出一次。這在某種程度上成為 Sed 命令將被重複應用在地址範圍內所有行這一慣例的一個例外情況:
cat -n inputfile | sed -e '19,22c\# :REMOVED:s/:.*// # This will NOT be applied to the "changed" text'因此,如果你希望將改變命令重複應用到地址範圍內的所有行上,除了將它封裝到一個塊中之外,你將沒有其它的選擇:
cat -n inputfile | sed -e '19,22{c\# :REMOVED:}s/:.*// # This will NOT be applied to the "changed" text'插入命令
插入命令(i\)將立即在輸出中給出使用者提供的文字。它並不以任何方式修改程式流或緩衝區的內容。
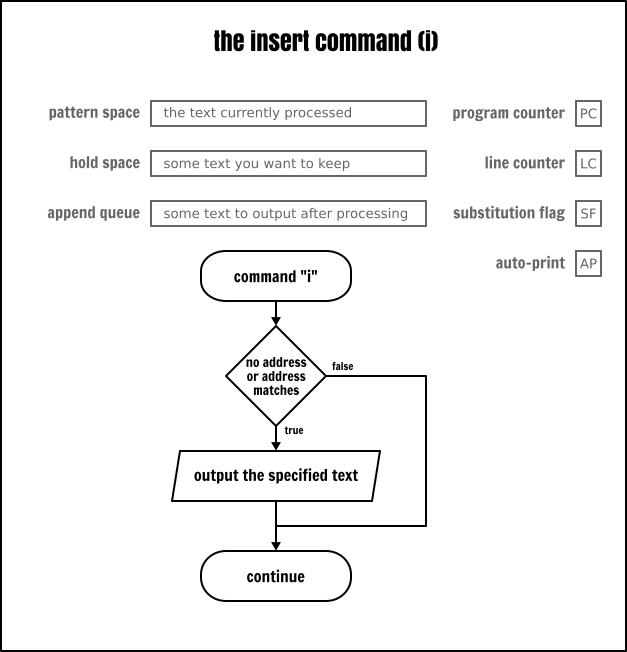
# display the first five user names with a title on the first rowsed < inputfile -e '1i\USER NAMEs/:.*//5q'追加命令
當輸入的下一行被讀取時,追加命令(a\)將一些文字追加到顯示佇列。文字在當前迴圈的結束部分(包含程式結束的情況)或當使用 n 或 N 命令從輸入中讀取一個新行時被輸出。
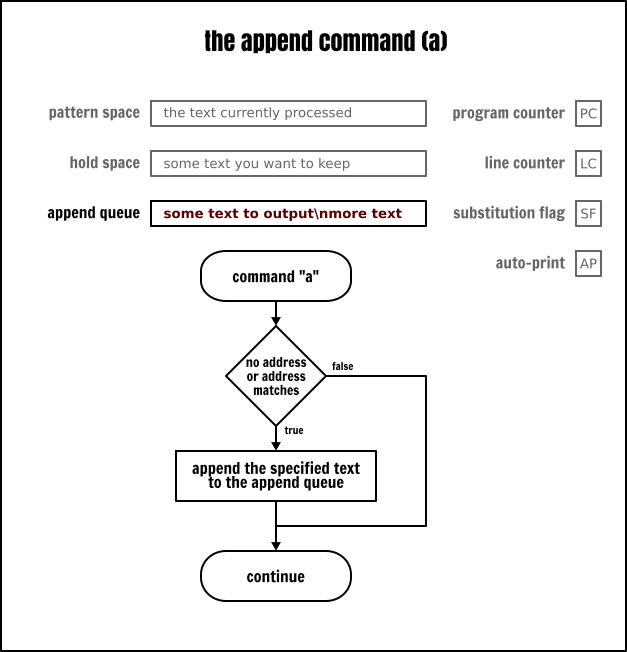
與上面相同的一個範例,但這次是插入到底部而不是頂部:
sed < inputfile -e '5a\USER NAMEs/:.*//5q'讀取命令
這是插入一些文字內容到輸出流的第四個命令:讀取命令(r)。它的工作方式與追加命令完全一樣,但不同的,它不從 Sed 指令碼中取得寫死到指令碼中的文字,而是把一個檔案的內容寫入到一個輸出上。
讀取命令只排程要讀取的檔案。當清理追加佇列時,後者才被高效地讀取,而不是在讀取命令執行時。如果這時候對這個檔案有並行的存取讀取,或那個檔案不是一個普通的檔案(比如,它是一個字元裝置或命名管道),或檔案在讀取期間被修改,這時可能會產生嚴重的後果。
作為一個例證,如果你使用我們將在下一節詳細講述的寫入命令,它與讀取命令共同配合從一個臨時檔案中寫入並重新讀取,你可能會獲得一些創造性的結果(使用法語版的 Shiritori 遊戲作為一個例證):
printf "%s\n" "Trois p'tits chats" "Chapeau d' paille" "Paillasson" |sed -ne ' r temp a\ ---- w temp'現在,在流輸出中專門用於插入一些文字的 Sed 命令清單結束了。我的最後一個範例純屬好玩,但是由於我前面提到過有一個寫入命令,這個範例將我們完美地帶到下一節,在下一節我們將看到在 Sed 中如何將資料寫入到一個外部檔案。
替代的輸出
Sed 的設計思想是,所有的文字轉換都將寫入到進程的標準輸出上。但是,Sed 也有一些特性支援將資料傳送到替代的目的地。你有兩種方式去實現上述的輸出目標替換:使用專門的寫入命令(w),或者在一個替換命令(s)上新增一個寫入標誌。
寫入命令
寫入命令(w)會追加模式空間的內容到給定的目標檔案中。POSIX 要求在 Sed 處理任何資料之前,目標檔案能夠被 Sed 所建立。如果給定的目標檔案已經存在,它將被覆寫。
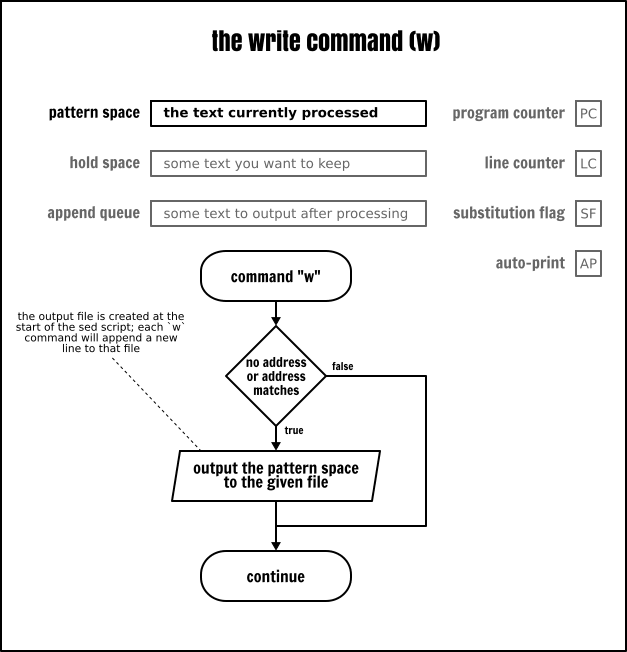
因此,即便是你從未真的寫入到該檔案中,但該檔案仍然會被建立。例如,下列的 Sed 程式將建立/覆寫這個 output 檔案,那怕是這個寫入命令從未被執行過:
echo | sed -ne ' q # 立刻退出 w output # 這個命令從未被執行'你可以將幾個寫入命令指向到同一個目標檔案。指向同一個目標檔案的所有寫入命令將追加那個檔案的內容(工作方式幾乎與 shell 的重定向符 >> 相同):
sed < inputfile -ne ' /:\/bin\/false$/w server /:\/usr\/sbin\/nologin$/w server w output'cat server替換命令的寫入標誌
在前面,我們已經學習了替換命令(s),它有一個 p 選項用於在替換之後輸出模式空間的內容。同樣它也提供一個類似功能的 w 選項,用於在替換之後將模式空間的內容輸出到一個檔案中:
sed < inputfile -ne ' s/:.*\/nologin$//w server s/:.*\/false$//w server'cat server注釋
我無數次使用過它們,但我從未花時間正式介紹過它們,因此,我決定現在來正式地介紹它們:就像大多數程式語言一樣,注釋是新增軟體不去解析的自由格式文字的一種方法。Sed 的語法很晦澀,我不得不強調在指令碼中需要的地方新增足夠的注釋。否則,除了作者外其他人將幾乎無法理解它。
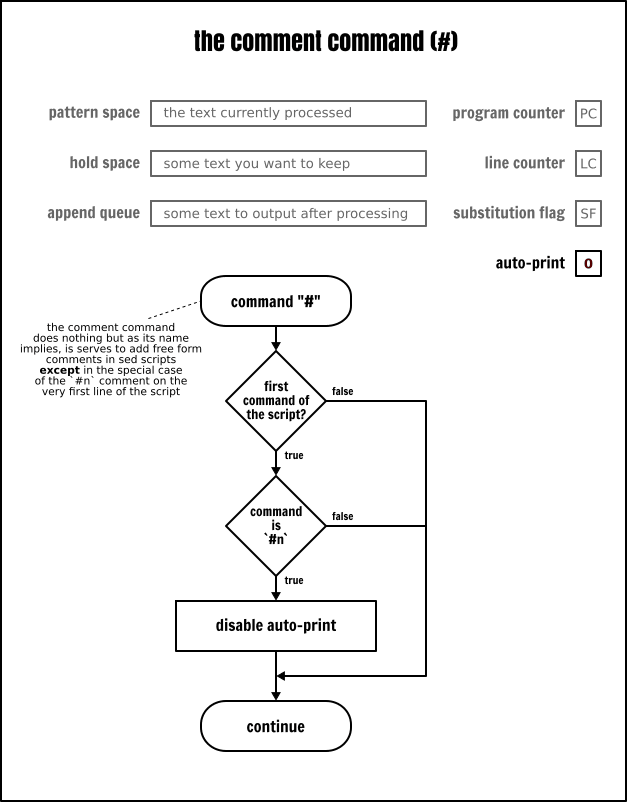
不過,和 Sed 的其它部分一樣,注釋也有它自己的微妙之處。首先並且是最重要的,注釋並不是語法結構,但它是真正意義的 Sed 命令。注釋雖然是一個“什麼也不做”的命令,但它仍然是一個命令。至少,它是在 POSIX 中定義了的。因此,嚴格地說,它們只允許使用在其它命令允許使用的地方。
大多數 Sed 實現都通過允許行內命令來放鬆了那種要求,就像在那個文章中我到處都使用的那樣。
結束那個主題之前,需要說一下 #n 注釋(# 後面緊跟一個字母 n,中間沒有空格)的特殊情況。如果在指令碼的第一行找到這個精確注釋,Sed 將切換到靜默模式(即:清除自動輸出標誌),就像在命令列上指定了 -n 選項一樣。
很少用得到的命令
現在,我們已經學習的命令能讓你寫出你所用到的 99.99% 的指令碼。但是,如果我沒有提到剩餘的 Sed 命令,那麼本教學就不能稱為完全指南。我把它們留到最後是因為我們很少用到它。但或許你有實際使用案例,那麼你就會發現它們很有用。如果是那樣,請不要猶豫,在下面的評論區中把它分享給我們吧。
行數命令
這個 = 命令將向標準輸出上顯示當前 Sed 正在讀取的行數,這個行數就是行計數器(LC)的內容。沒有任何方式從任何一個 Sed 緩衝區中捕獲那個數位,也不能對它進行輸出格式化。由於這兩個限制使得這個命令的可用性大大降低。
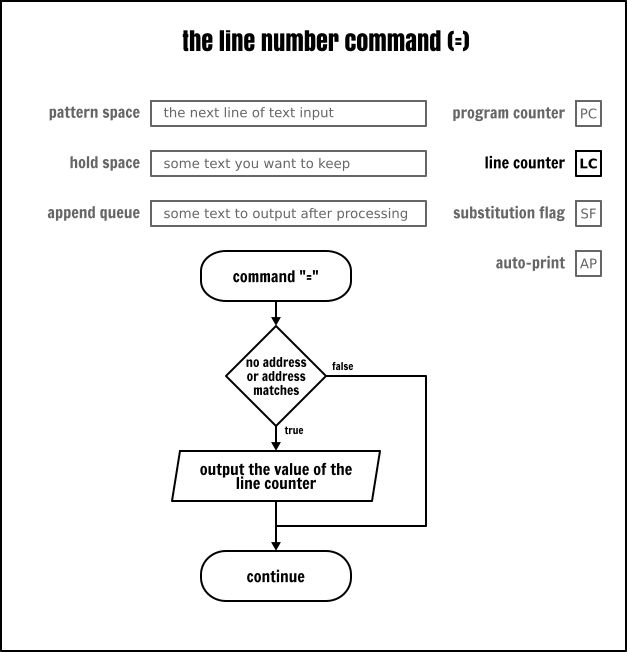
請記住,在嚴格的 POSIX 相容模式中,當在命令列上給定幾個輸入檔案時,Sed 並不重置那個計數器,而是連續地增長它,就像所有的輸入檔案是連線在一起的一樣。一些 Sed 實現,像 GNU Sed,它就有一個選項可以在每個輸入檔案讀取結束後去重置計數器。
明確列印命令
這個 l(小寫的字母 l)作用類似於列印命令(p),但它是以精確的格式去輸出模式空間的內容。以下參照自 POSIX 標準:
在 XBD 跳脫序列中列出的字元和相關的動作(
\\、\a、\b、\f、\r、\t、\v)將被寫為相應的跳脫序列;在那個表中的\n是不適用的。不在那個表中的不可列印字元將被寫為一個三位八進位制數位(在前面使用一個反斜槓\),表示字元中的每個位元組(最重要的位元組在前面)。長行應該被換行,通過寫一個反斜槓後跟一個換行符來表示換行位置;發生換行時的長度是不確定的,但應該適合輸出裝置的具體情況。每個行應該以一個$標記結束。
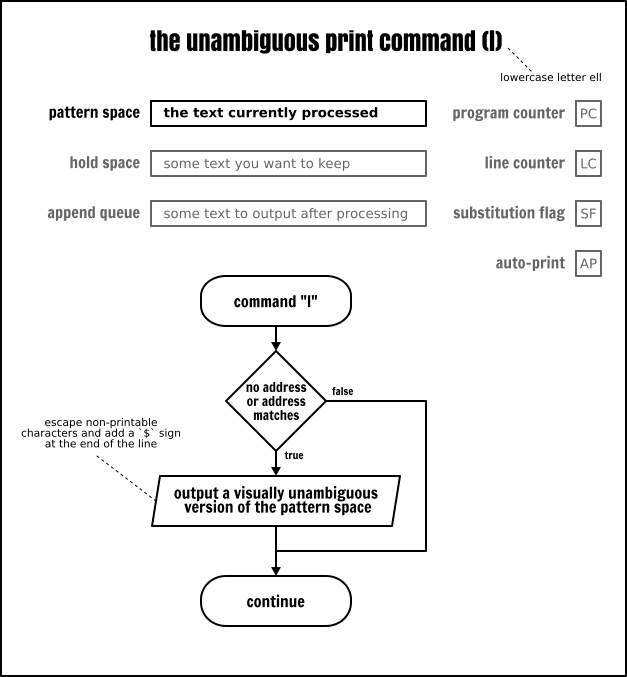
我懷疑這個命令是在非 8 位規則化通道 上交換資料的。就我本人而言,除了偵錯用途以外,也從未使用過它。
移譯命令
移譯(y)命令允許從一個源集到一個目標集對映模式空間的字元。它非常類似於 tr 命令,但是限制更多。
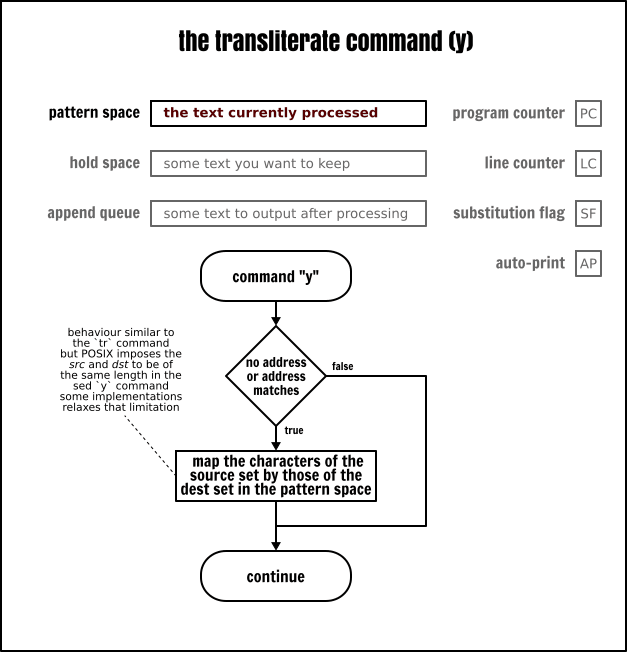
# The `y` c0mm4nd 1s for h4x0rz onlysed < inputfile -e ' s/:.*// y/abcegio/48<3610/'雖然移譯命令語法與替換命令的語法有一些相似之處,但它在替換字串之後不接受任何選項。這個移譯總是全域性的。
請注意,移譯命令要求源集和目標集之間要一一對應地轉換。這意味著下面的 Sed 程式可能所做的事情並不是你乍一看所想的那樣:
# 注意:這可能並不如你想的那樣工作!sed < inputfile -e ' s/:.*// y/[a-z]/[A-Z]/'寫在最後的話
# 它要做什麼?# 提示:答案就在不遠處...sed -E ' s/.*\W(.*)/\1/ h ${ x; p; } d' < inputfile我們已經學習了所有的 Sed 命令,真不敢相信我們已經做到了!如果你也讀到這裡了,應該恭喜你,尤其是如果你花費了一些時間,在你的系統上嘗試了所有的不同範例!
正如你所見,Sed 是非常複雜的,不僅因為它的語法比較零亂,也因為許多極端案例或命令列為之間的細微差別。毫無疑問,我們可以將這些歸結於歷史的原因。儘管它有這麼多缺點,但是 Sed 仍然是一個非常強大的工具,甚至到現在,它仍然是 Unix 工具箱中為數不多的大量使用的命令之一。是時候總結一下這篇文章了,沒有你們的支援我將無法做到:請節選你對喜歡的或最具創意的 Sed 指令碼,並共用給我們。如果我收集到的你們共用出的指令碼足夠多了,我將會把這些 Sed 指令碼結集發布!