虛擬記憶體精粹
部落格原文
導言
虛擬記憶體是當今計算機系統中最重要的抽象概念之一,它的提出是為了更加有效地管理記憶體並且降低記憶體出錯的概率。虛擬記憶體影響著計算機的方方面面,包括硬體設計、檔案系統、共用物件和程序/執行緒排程等等,每一個致力於編寫高效且出錯概率低的程式的程式設計師都應該深入學習虛擬記憶體。
本文全面而深入地剖析了虛擬記憶體的工作原理,幫助讀者快速而深刻地理解這個重要的概念。
計算機記憶體
記憶體是計算機的核心部件之一,在完全理想的狀態下,記憶體應該要同時具備以下三種特性:
- 速度足夠快:記憶體的存取速度應當快於 CPU 執行一條指令,這樣 CPU 的效率才不會受限於記憶體
- 容量足夠大:容量能夠儲存計算機所需的全部資料
- 價格足夠便宜:價格低廉,所有型別的計算機都能配備
但是現實往往是殘酷的,我們目前的計算機技術無法同時滿足上述的三個條件,於是現代計算機的記憶體設計採用了一種分層次的結構:
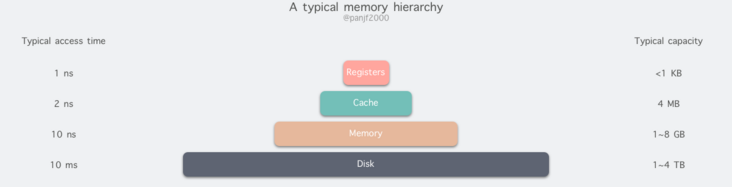
從頂至底,現代計算機裡的記憶體型別分別有:暫存器、快取記憶體、主記憶體和磁碟,這些記憶體的速度逐級遞減而容量逐級遞增。存取速度最快的是暫存器,因為暫存器的製作材料和 CPU 是相同的,所以速度和 CPU 一樣快,CPU 存取暫存器是沒有時延的,然而因為價格昂貴,因此容量也極小,一般 32 位的 CPU 配備的暫存器容量是 32✖️32 Bit,64 位的 CPU 則是 64✖️64 Bit,不管是 32 位還是 64 位,暫存器容量都小於 1 KB,且暫存器也必須通過軟體自行管理。
第二層是快取記憶體,也即我們平時瞭解的 CPU 快取記憶體 L1、L2、L3,一般 L1 是每個 CPU 獨享,L3 是全部 CPU 共用,而 L2 則根據不同的架構設計會被設計成獨享或者共用兩種模式之一,比如 Intel 的多核晶片採用的是共用 L2 模式而 AMD 的多核晶片則採用的是獨享 L2 模式。
第三層則是主記憶體,也即主記憶體,通常稱作隨機存取記憶體(Random Access Memory, RAM)。是與 CPU 直接交換資料的內部記憶體。它可以隨時讀寫(重新整理時除外),而且速度很快,通常作為作業系統或其他正在執行中的程式的臨時資料儲存媒介。
最後則是磁碟,磁碟和主記憶體相比,每個二進位制位的成本低了兩個數量級,因此容量比之會大得多,動輒上 GB、TB,而缺點則是存取速度則比主記憶體慢了大概三個數量級。機械硬碟速度慢主要是因為機械臂需要不斷在金屬碟片之間移動,等待磁碟磁區旋轉至磁頭之下,然後才能進行讀寫操作,因此效率很低。
主記憶體
實體記憶體
我們平時一直提及的實體記憶體就是上文中對應的第三種計算機記憶體,RAM 主記憶體,它在計算機中以記憶體條的形式存在,嵌在主機板的記憶體槽上,用來載入各式各樣的程式與資料以供 CPU 直接執行和使用。
虛擬記憶體
在計算機領域有一句如同摩西十誡般神聖的哲言:"電腦科學領域的任何問題都可以通過增加一個間接的中間層來解決",從記憶體管理、網路模型、並行排程甚至是硬體架構,都能看到這句哲言在閃爍著光芒,而虛擬記憶體則是這一哲言的完美實踐之一。
虛擬記憶體是現代計算機中的一個非常重要的記憶體抽象,主要是用來解決應用程式日益增長的記憶體使用需求:現代實體記憶體的容量增長已經非常快速了,然而還是跟不上應用程式對主記憶體需求的增長速度,對於應用程式來說記憶體還是可能會不夠用,因此便需要一種方法來解決這兩者之間的容量差矛盾。為了更高效地管理記憶體並儘可能消除程式錯誤,現代計算機系統對物理主記憶體 RAM 進行抽象,實現了虛擬記憶體 (Virtual Memory, VM) 技術。
虛擬記憶體
虛擬記憶體的核心原理是:為每個程式設定一段"連續"的虛擬地址空間,把這個地址空間分割成多個具有連續地址範圍的頁 (Page),並把這些頁和實體記憶體做對映,在程式執行期間動態對映到實體記憶體。當程式參照到一段在實體記憶體的地址空間時,由硬體立刻執行必要的對映;而當程式參照到一段不在實體記憶體中的地址空間時,由作業系統負責將缺失的部分裝入實體記憶體並重新執行失敗的指令。
其實虛擬記憶體技術從某種角度來看的話,很像是糅合了基址暫存器和界限暫存器之後的新技術。它使得整個程序的地址空間可以通過較小的虛擬單元對映到實體記憶體,而不需要為程式的程式碼和資料地址進行重定位。
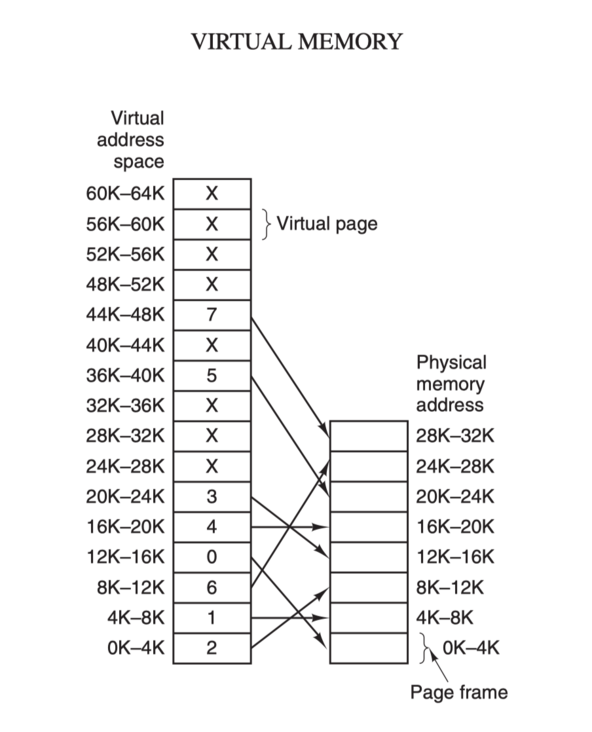
虛擬地址空間按照固定大小劃分成被稱為頁(Page)的若干單元,實體記憶體中對應的則是頁框(Page Frame)。這兩者一般來說是一樣的大小,如上圖中的是 4KB,不過實際上計算機系統中一般是 512 位元組到 1 GB,這就是虛擬記憶體的分頁技術。因為是虛擬記憶體空間,每個程序分配的大小是 4GB (32 位架構),而實際上當然不可能給所有在執行中的程序都分配 4GB 的實體記憶體,所以虛擬記憶體技術還需要利用到一種 交換(swapping)技術,也就是通常所說的頁面置換演演算法,在程序執行期間只分配對映當前使用到的記憶體,暫時不使用的資料則寫回磁碟作為副本儲存,需要用的時候再讀入記憶體,動態地在磁碟和記憶體之間交換資料。
頁表
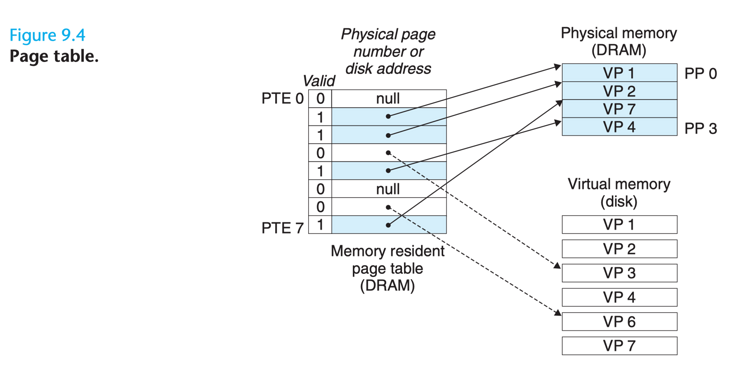
頁表(Page Table),每次進行虛擬地址到實體地址的對映之時,都需要讀取頁表,從數學角度來說頁表就是一個函數,入參是虛擬頁號(Virtual Page Number,簡稱 VPN),輸出是物理頁框號(Physical Page Number,簡稱 PPN,也就是實體地址的基址)。
頁表由多個頁表項(Page Table Entry, 簡稱 PTE)組成,頁表項的結構取決於機器架構,不過基本上都大同小異。一般來說頁表項中都會儲存物理頁框號、修改位、存取位、保護位和 "在/不在" 位(有效位)等資訊。
- 物理頁框號:這是 PTE 中最重要的域值,畢竟頁表存在的意義就是提供 VPN 到 PPN 的對映。
- 有效位:表示該頁面當前是否存在於主記憶體中,1 表示存在,0 表示缺失,當程序嘗試存取一個有效位為 0 的頁面時,就會引起一個缺頁中斷。
- 保護位:指示該頁面所允許的存取型別,比如 0 表示可讀寫,1 表示唯讀。
- 修改位和存取位:為了記錄頁面使用情況而引入的,一般是頁面置換演演算法會使用到。比如當一個記憶體頁面被程式修改過之後,硬體會自動設定修改位,如果下次程式發生缺頁中斷需要執行頁面置換演演算法把該頁面調出以便為即將調入的頁面騰出空間之時,就會先去存取修改位,從而得知該頁面被修改過,也就是髒頁 (Dirty Page),則需要把最新的頁面內容寫回到磁碟儲存,否則就表示記憶體和磁碟上的副本內容是同步的,無需寫回磁碟;而存取位同樣也是系統在程式存取頁面時自動設定的,它也是頁面置換演演算法會使用到的一個值,系統會根據頁面是否正在被存取來覺得是否要淘汰掉這個頁面,一般來說不再使用的頁面更適合被淘汰掉。
- 快取記憶體禁止位:用於禁止頁面被放入 CPU 快取記憶體,這個值主要適用於那些對映到暫存器等實時 I/O 裝置而非普通主記憶體的記憶體頁面,這一類實時 I/O 裝置需要拿到最新的資料,而 CPU 快取記憶體中的資料可能是舊的拷貝。
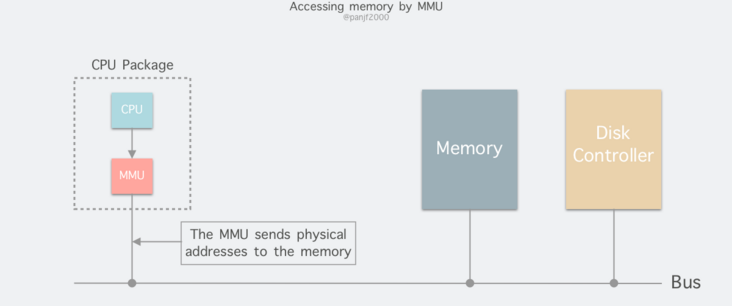
地址翻譯
程序在執行期間產生的記憶體地址都是虛擬地址,如果計算機沒有引入虛擬記憶體這種記憶體抽象技術的話,則 CPU 會把這些地址直接傳送到記憶體地址匯流排上,然後存取和虛擬地址相同值的實體地址;如果使用虛擬記憶體技術的話,CPU 則是把這些虛擬地址通過地址匯流排送到記憶體管理單元(Memory Management Unit,簡稱 MMU),MMU 將虛擬地址翻譯成實體地址之後再通過記憶體匯流排去存取實體記憶體:
虛擬地址(比如 16 位地址 8196=0010 000000000100)分為兩部分:虛擬頁號(Virtual Page Number,簡稱 VPN,這裡是高 4 位部分)和偏移量(Virtual Page Offset,簡稱 VPO,這裡是低 12 位部分),虛擬地址轉換成實體地址是通過頁表(page table)來實現的。
這裡我們基於一個例子來分析當頁面命中時,計算機各個硬體是如何互動的:
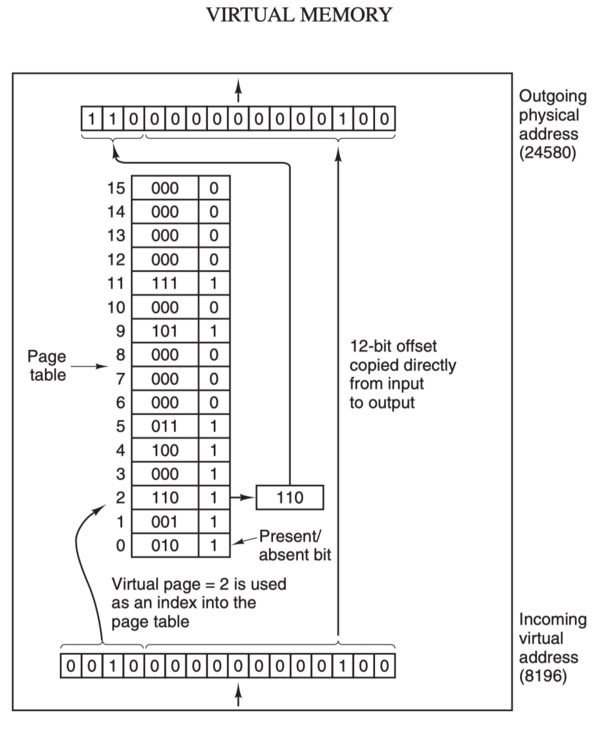
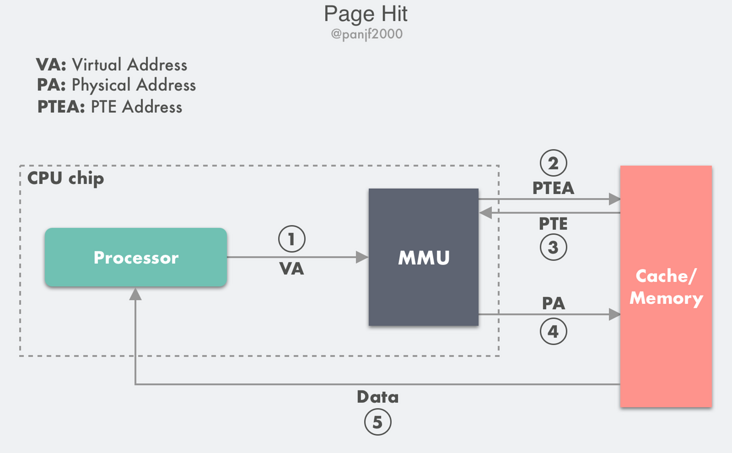
- 第 1 步:處理器生成一個虛擬地址 VA,通過匯流排傳送到 MMU;
- 第 2 步:MMU 通過虛擬頁號得到頁表項的地址 PTEA,通過記憶體匯流排從 CPU 快取記憶體/主記憶體讀取這個頁表項 PTE;
- 第 3 步:CPU 快取記憶體或者主記憶體通過記憶體匯流排向 MMU 返回頁表項 PTE;
- 第 4 步:MMU 先把頁表項中的物理頁框號 PPN 複製到暫存器的高三位中,接著把 12 位的偏移量 VPO 複製到暫存器的末 12 位構成 15 位的實體地址,即可以把該暫存器儲存的實體記憶體地址 PA 傳送到記憶體匯流排,存取快取記憶體/主記憶體;
- 第 5 步:CPU 快取記憶體/主記憶體返回該實體地址對應的資料給處理器。
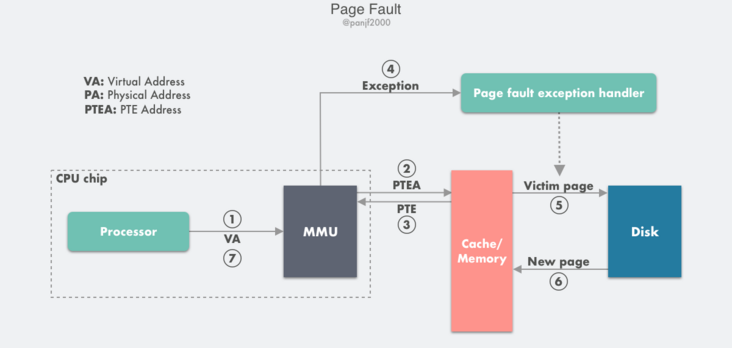
在 MMU 進行地址轉換時,如果頁表項的有效位是 0,則表示該頁面並沒有對映到真實的物理頁框號 PPN,則會引發一個缺頁中斷,CPU 陷入作業系統核心,接著作業系統就會通過頁面置換演演算法選擇一個頁面將其換出 (swap),以便為即將調入的新頁面騰出位置,如果要換出的頁面的頁表項裡的修改位已經被設定過,也就是被更新過,則這是一個髒頁 (Dirty Page),需要寫回磁碟更新該頁面在磁碟上的副本,如果該頁面是"乾淨"的,也就是沒有被修改過,則直接用調入的新頁面覆蓋掉被換出的舊頁面即可。
缺頁中斷的具體流程如下:
- 第 1 步到第 3 步:和前面的頁面命中的前 3 步是一致的;
- 第 4 步:檢查返回的頁表項 PTE 發現其有效位是 0,則 MMU 觸發一次缺頁中斷異常,然後 CPU 轉入到作業系統核心中的缺頁中斷處理器;
- 第 5 步:缺頁中斷處理程式檢查所需的虛擬地址是否合法,確認合法後系統則檢查是否有空閒物理頁框號 PPN 可以對映給該缺失的虛擬頁面,如果沒有空閒頁框,則執行頁面置換演演算法尋找一個現有的虛擬頁面淘汰,如果該頁面已經被修改過,則寫回磁碟,更新該頁面在磁碟上的副本;
- 第 6 步:缺頁中斷處理程式從磁碟調入新的頁面到記憶體,更新頁表項 PTE;
- 第 7 步:缺頁中斷程式返回到原先的程序,重新執行引起缺頁中斷的指令,CPU 將引起缺頁中斷的虛擬地址重新傳送給 MMU,此時該虛擬地址已經有了對映的物理頁框號 PPN,因此會按照前面『Page Hit』的流程走一遍,最後主記憶體把請求的資料返回給處理器。
虛擬記憶體和快取記憶體
前面在分析虛擬記憶體的工作原理之時,談到頁表的儲存位置,為了簡化處理,都是預設把主記憶體和快取記憶體放在一起,而實際上更詳細的流程應該是如下的原理圖:
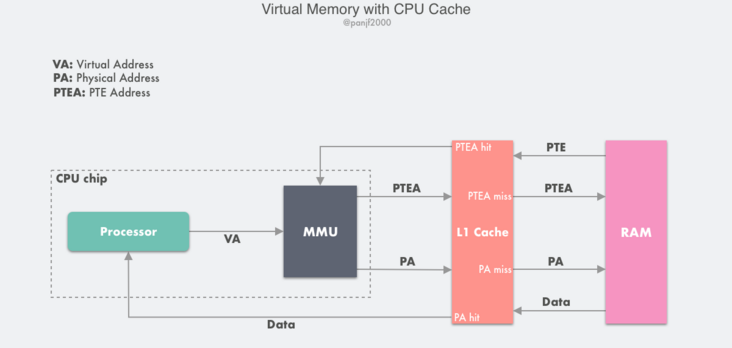
如果一臺計算機同時配備了虛擬記憶體技術和 CPU 快取記憶體,那麼 MMU 每次都會優先嚐試到快取記憶體中進行定址,如果快取命中則會直接返回,只有當快取不命中之後才去主記憶體定址。
通常來說,大多數系統都會選擇利用實體記憶體地址去存取快取記憶體,因為快取記憶體相比於主記憶體要小得多,所以使用物理定址也不會太複雜;另外也因為快取記憶體容量很小,所以系統需要儘量在多個程序之間共用資料塊,而使用實體地址能夠使得多程序同時在快取記憶體中儲存資料塊以及共用來自相同虛擬記憶體頁的資料塊變得更加直觀。
加速翻譯&優化頁表
經過前面的剖析,相信讀者們已經瞭解了虛擬記憶體及其分頁&地址翻譯的基礎和原理。現在我們可以引入虛擬記憶體中兩個核心的需求,或者說瓶頸:
- 虛擬地址到實體地址的對映過程必須要非常快,地址翻譯如何加速。
- 虛擬地址範圍的增大必然會導致頁表的膨脹,形成大頁表。
這兩個因素決定了虛擬記憶體這項技術能不能真正地廣泛應用到計算機中,如何解決這兩個問題呢?
正如文章開頭所說:"電腦科學領域的任何問題都可以通過增加一個間接的中間層來解決"。因此,雖然虛擬記憶體本身就已經是一箇中間層了,但是中間層裡的問題同樣可以通過再引入一箇中間層來解決。
加速地址翻譯過程的方案目前是通過引入頁錶快取模組 -- TLB,而大頁表則是通過實現多級頁表或倒排頁表來解決。
TLB 加速
翻譯後備緩衝器(Translation Lookaside Buffer,TLB),也叫快表,是用來加速虛擬地址翻譯的,因為虛擬記憶體的分頁機制,頁表一般是儲存在記憶體中的一塊固定的儲存區,而 MMU 每次翻譯虛擬地址的時候都需要從頁表中匹配一個對應的 PTE,導致程序通過 MMU 存取指定記憶體資料的時候比沒有分頁機制的系統多了一次記憶體存取,一般會多耗費幾十到幾百個 CPU 時鐘週期,效能至少下降一半,如果 PTE 碰巧快取在 CPU L1 快取記憶體中,則開銷可以降低到一兩個週期,但是我們不能寄希望於每次要匹配的 PTE 都剛好在 L1 中,因此需要引入加速機制,即 TLB 快表。
TLB 可以簡單地理解成頁表的快取記憶體,儲存了最高頻被存取的頁表項 PTE。由於 TLB 一般是硬體實現的,因此速度極快,MMU 收到虛擬地址時一般會先通過硬體 TLB 並行地在頁表中匹配對應的 PTE,若命中且該 PTE 的存取操作不違反保護位(比如嘗試寫一個唯讀的記憶體地址),則直接從 TLB 取出對應的物理頁框號 PPN 返回,若不命中則會穿透到主記憶體頁表裡查詢,並且會在查詢到最新頁表項之後存入 TLB,以備下次快取命中,如果 TLB 當前的儲存空間不足則會替換掉現有的其中一個 PTE。
下面來具體分析一下 TLB 命中和不命中。
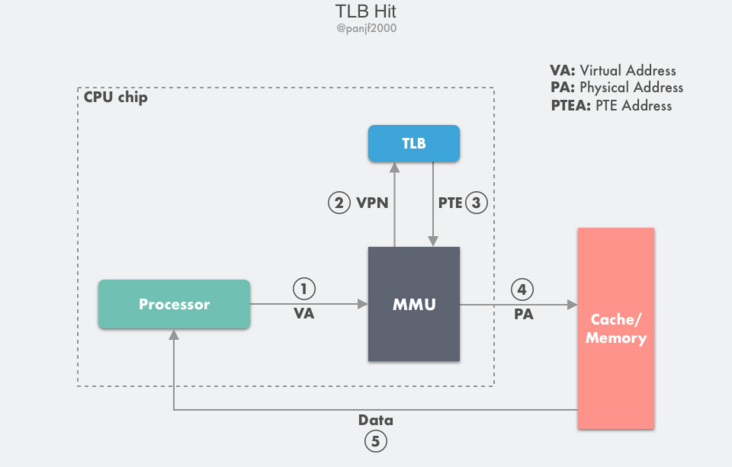
TLB 命中:
- 第 1 步:CPU 產生一個虛擬地址 VA;
- 第 2 步和第 3 步:MMU 從 TLB 中取出對應的 PTE;
- 第 4 步:MMU 將這個虛擬地址 VA 翻譯成一個真實的實體地址 PA,通過地址匯流排傳送到快取記憶體/主記憶體中去;
- 第 5 步:快取記憶體/主記憶體將實體地址 PA 上的資料返回給 CPU。
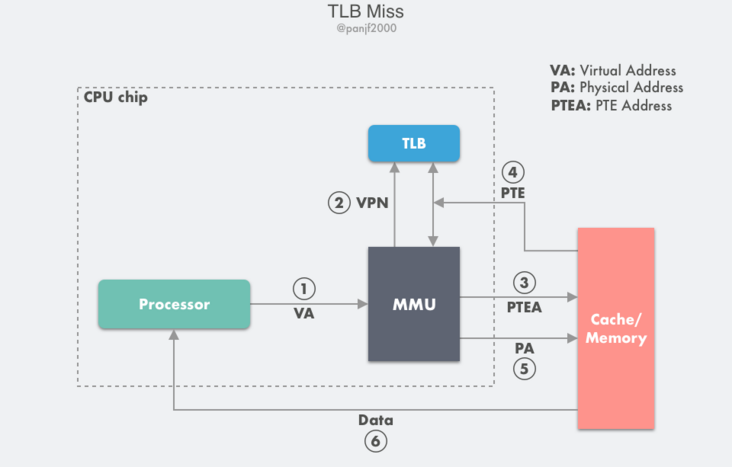
TLB 不命中:
- 第 1 步:CPU 產生一個虛擬地址 VA;
- 第 2 步至第 4 步:查詢 TLB 失敗,走正常的主記憶體頁表查詢流程拿到 PTE,然後把它放入 TLB 快取,以備下次查詢,如果 TLB 此時的儲存空間不足,則這個操作會汰換掉 TLB 中另一個已存在的 PTE;
- 第 5 步:MMU 將這個虛擬地址 VA 翻譯成一個真實的實體地址 PA,通過地址匯流排傳送到快取記憶體/主記憶體中去;
- 第 6 步:快取記憶體/主記憶體將實體地址 PA 上的資料返回給 CPU。
多級頁表
TLB 的引入可以一定程度上解決虛擬地址到實體地址翻譯的開銷問題,接下來還需要解決另一個問題:大頁表。
理論上一臺 32 位的計算機的定址空間是 4GB,也就是說每一個執行在該計算機上的程序理論上的虛擬定址範圍是 4GB。到目前為止,我們一直在討論的都是單頁表的情形,如果每一個程序都把理論上可用的記憶體頁都裝載進一個頁表裡,但是實際上程序會真正使用到的記憶體其實可能只有很小的一部分,而我們也知道頁表也是儲存在計算機主記憶體中的,那麼勢必會造成大量的記憶體浪費,甚至有可能導致計算機實體記憶體不足從而無法並行地執行更多程序。
這個問題一般通過多級頁表(Multi-Level Page Tables)來解決,通過把一個大頁表進行拆分,形成多級的頁表,我們具體來看一個二級頁表應該如何設計:假定一個虛擬地址是 32 位,由 10 位的一級頁表索引、10 位的二級頁表索引以及 12 位的地址偏移量,則 PTE 是 4 位元組,頁面 page 大小是 2^12 = 4KB,總共需要 2^20 個 PTE,一級頁表中的每個 PTE 負責對映虛擬地址空間中的一個 4MB 的 chunk,每一個 chunk 都由 1024 個連續的頁面 Page 組成,如果定址空間是 4GB,那麼一共只需要 1024 個 PTE 就足夠覆蓋整個程序地址空間。二級頁表中的每一個 PTE 都負責對映到一個 4KB 的虛擬記憶體頁面,和單頁表的原理是一樣的。
多級頁表的關鍵在於,我們並不需要為一級頁表中的每一個 PTE 都分配一個二級頁表,而只需要為程序當前使用到的地址做相應的分配和對映。因此,對於大部分程序來說,它們的一級頁表中有大量空置的 PTE,那麼這部分 PTE 對應的二級頁表也將無需存在,這是一個相當可觀的記憶體節約,事實上對於一個典型的程式來說,理論上的 4GB 可用虛擬記憶體地址空間絕大部分都會處於這樣一種未分配的狀態;更進一步,在程式執行過程中,只需要把一級頁表放在主記憶體中,虛擬記憶體系統可以在實際需要的時候才去建立、調入和調出二級頁表,這樣就可以確保只有那些最頻繁被使用的二級頁表才會常駐在主記憶體中,此舉亦極大地緩解了主記憶體的壓力。
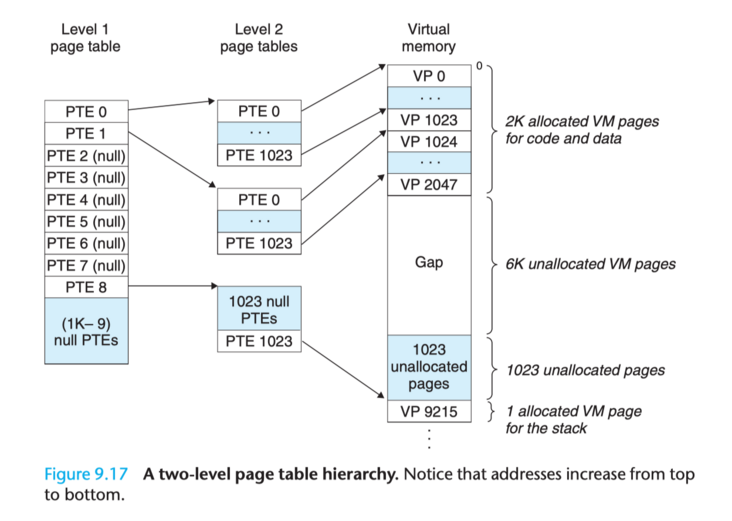
多級頁表的層級深度可以按照需求不斷擴充,一般來說,級數越多,靈活性越高。
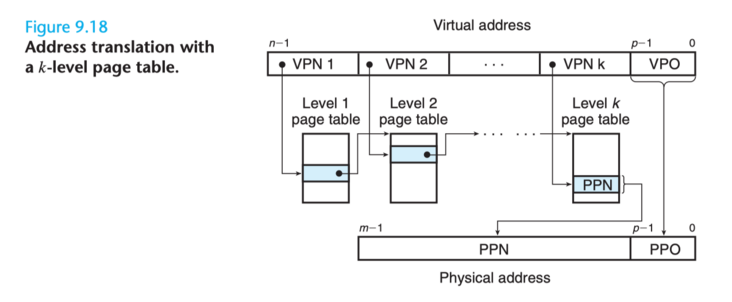
比如有個一個 k 級頁表,虛擬地址由 k 個 VPN 和 1 個 VPO 組成,每一個 VPN i 都是一個到第 i 級頁表的索引,其中 1 <= i <= k。第 j 級頁表中的每一個 PTE(1 <= j <= k-1)都指向第 j+1 級頁表的基址。第 k 級頁表中的每一個 PTE 都包含一個實體地址的頁框號 PPN,或者一個磁碟塊的地址(該記憶體頁已經被頁面置換演演算法換出到磁碟中)。MMU 每次都需要存取 k 個 PTE 才能找到物理頁框號 PPN 然後加上虛擬地址中的偏移量 VPO 從而生成一個實體地址。這裡讀者可能會對 MMU 每次都存取 k 個 PTE 表示效能上的擔憂,此時就是 TLB 出場的時候了,計算機正是通過把每一級頁表中的 PTE 快取在 TLB 中從而讓多級頁表的效能不至於落後單頁表太多。
倒排頁表
另一種針對頁式虛擬記憶體管理大頁表問題的解決方案是倒排頁表(Inverted Page Table,簡稱 IPT)。倒排頁表的原理和搜尋引擎的倒排索引相似,都是通過反轉對映過程來實現。
在搜尋引擎中,有兩個概念:檔案 doc 和 關鍵詞 keyword,我們的需求是通過 keyword 快速找到對應的 doc 列表,如果搜尋引擎的儲存結構是正向索引,也即是通過 doc 對映到其中包含的所有 keyword 列表,那麼我們要找到某一個指定的 keyword 所對應的 doc 列表,那麼便需要掃描索引庫中的所有 doc,找到包含該 keyword 的 doc,再根據打分模型進行打分,排序後返回,這種設計無疑是低效的;所以我們需要反轉一下正向索引從而得到倒排索引,也即通過 keyword 對映到所有包含它的 doc 列表,這樣當我們查詢包含某個指定 keyword 的 doc 列表時,只需要利用倒排索引就可以快速定位到對應的結果,然後還是根據打分模型進行排序返回。
上面的描述只是搜尋引擎倒排索引的簡化原理,實際的倒排索引設計是要複雜很多的,有興趣的讀者可以自行查詢資料學習,這裡就不再展開。
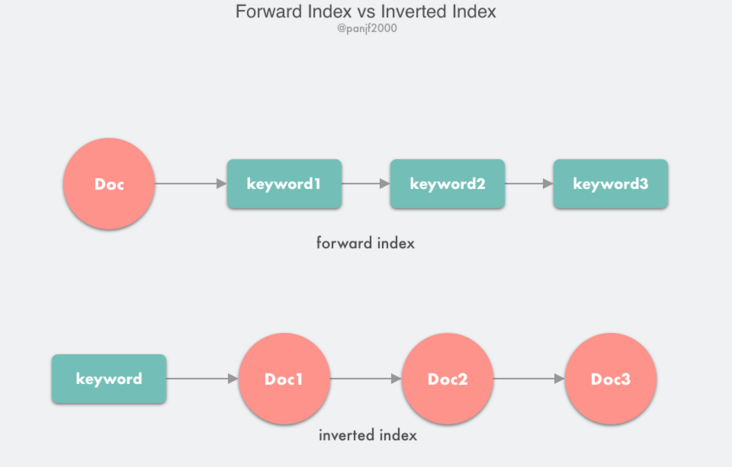
回到虛擬記憶體的倒排頁表,它正是採用了和倒排索引類似的思想,反轉了對映過程:前面我們學習到的頁表設計都是以虛擬地址頁號作為頁表項 PTE 索引,對映到物理頁框號 PPN,而在倒排頁表中則是以 PPN 作為 PTE 索引,對映到 (程序號,虛擬頁號 VPN)。
倒排頁表在定址空間更大的 CPU 架構下尤其高效,或者應該說更適合那些『虛擬記憶體空間/實體記憶體空間』比例非常大的場景,因為這種設計是以實際實體記憶體頁框作為 PTE 索引,而不是以遠超實體記憶體的虛擬記憶體作為索引。例如,以 64 位架構為例,如果是單頁表結構,還是用 12 位作為頁面地址偏移量,也就是 4KB 的記憶體頁大小,那麼以最理論化的方式來計算,則需要 2^52 個 PTE,每個 PTE 佔 8 個位元組,那麼整個頁表需要 32PB 的記憶體空間,這完全是不可接受的,而如果採用倒排頁表,假定使用 4GB 的 RAM,則只需要 2^20 個 PTE,極大減少記憶體使用量。
倒排頁表雖然在節省記憶體空間方面效果顯著,但同時卻引入了另一個重大的缺陷:地址翻譯過程變得更加低效。我們都清楚 MMU 的工作就是要把虛擬記憶體地址翻譯成實體記憶體地址,現在索引結構變了,物理頁框號 PPN 作為索引,從原來的 VPN --> PPN 變成了 PPN --> VPN,那麼當程序嘗試存取一個虛擬記憶體地址之時,CPU 在通過地址匯流排把 VPN 傳送到 MMU 之後,基於倒排頁表的設計,MMU 並不知道這個 VPN 對應的是不是一個缺頁,所以不得不掃描整個倒排頁表來找到該 VPN,而最要命的是就算是一個非缺頁的 VPN,每次記憶體存取還是需要執行這個全表掃描操作,假設是前面提到的 4GB RAM 的例子,那麼相當於每次都要掃描 2^20 個 PTE,相當低效。
這時候又是我們的老朋友 -- TLB 出場的時候了,我們只需要把高頻使用的頁面快取在 TLB 中,藉助於硬體,在 TLB 快取命中的情況下虛擬記憶體地址的翻譯過程就可以像普通頁表那樣快速,然而當 TLB 失效的時候,則還是需要通過軟體的方式去掃描整個倒排頁表,線性掃描的方式非常低效,因此一般倒排頁表會基於雜湊表來實現,假設有 1G 的實體記憶體,那麼這裡就一共有 2^18 個 4KB 大小的頁框,建立一張以 VPN 作為 key 的雜湊表,每一個 key 值對應的 value 中儲存的是 (VPN, PNN),那麼所有具有相同雜湊值的 VPN 會被連結在一起形成一個衝突鏈,如果我們把雜湊表的槽數設定成跟物理頁框數量一致的話,那麼這個倒排雜湊表中的衝突鏈的平均長度將會是 1 個 PTE,可以大大提高查詢速度。當 VPN 通過倒排頁表匹配到 PPN 之後,這個 (VPN, PPN) 對映關係就會馬上被快取進 TLB,以加速下次虛擬地址翻譯。
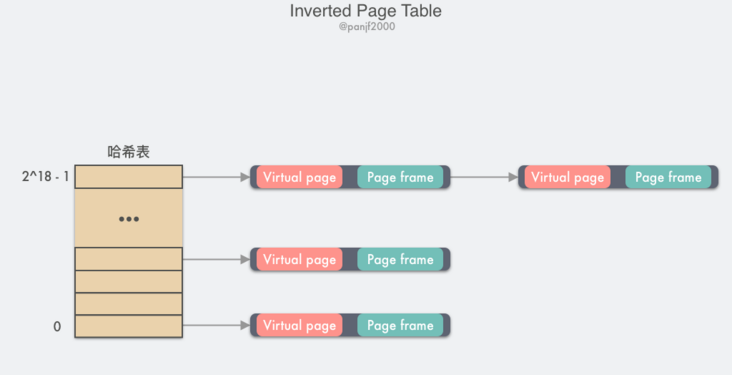
倒排頁表在 64 位架構的計算機中很常見,因為在 64 位架構下,基於分頁的虛擬記憶體中即便把頁面 Page 的大小從一般的 4KB 提升至 4MB,依然需要一個擁有 2^42 個 PTE 的巨型頁表放在主記憶體中(理論上,實際上不會這麼實現),極大地消耗記憶體。
總結
現在讓我們來回顧一下本文的核心內容:虛擬記憶體是存在於計算機 CPU 和實體記憶體之間一箇中間層,主要作用是高效管理記憶體並減少記憶體出錯。虛擬記憶體的幾個核心概念有:
- 頁表:從數學角度來說頁表就是一個函數,入參是虛擬頁號 VPN,輸出是物理頁框號 PPN,也就是實體地址的基址。頁表由頁表項組成,頁表項中儲存了所有用來進行地址翻譯所需的資訊,頁表是虛擬記憶體得以正常運作的基礎,每一個虛擬地址要翻譯成實體地址都需要藉助它來完成。
- TLB:計算機硬體,主要用來解決引入虛擬記憶體之後定址的效能問題,加速地址翻譯。如果沒有 TLB 來解決虛擬記憶體的效能問題,那麼虛擬記憶體將只可能是一個學術上的理論而無法真正廣泛地應用在計算機中。
- 多級頁表和倒排頁表:用來解決虛擬地址空間爆炸性膨脹而導致的大頁表問題,多級頁表通過將單頁表進行分拆並按需分配虛擬記憶體頁而倒排頁表則是通過反轉對映關係來實現節省記憶體的效果。
最後,虛擬記憶體技術中還需要涉及到作業系統的頁面置換機制,由於頁面置換機制也是一個較為龐雜和複雜的概念,本文便不再繼續剖析這一部分的原理,我們在以後的文章中再單獨拿來講解。
參考&延伸閱讀
本文的主要參考資料是《現代作業系統》和《深入理解計算機系統》這兩本書的英文原版,如果讀者還想更加深入地學習虛擬記憶體,可以深入閱讀這兩本書並且搜尋其他的論文資料進行學習。