巨量資料流式計算框架匯總和對比
2020-07-16 10:05:20
Storm 是比較早的流式計算框架,後來又出現了 Spark Streaming 和 Trident,現在又出現了 Flink 這種優秀的實時計算框架,那麼這幾種計算框架到底有什麼區別呢?下面我們來詳細分析一下,如下表所示。
| 產品 | 模型 | API | 保證次數 | 容錯機制 | 狀態管理 | 延時 | 吞吐量 |
|---|---|---|---|---|---|---|---|
| Storm | Native(資料進入立即處理) | 組合式(基礎API) | At-least-once (至少一次) | Record ACK(ACK機制) | 無 | 低 | 低 |
| Trident | Micro-Batching(劃分為小批 處理) | 組合式 | Exactly-once (僅一次) | Record ACK | 基於操作(每次操作有一個狀態) | 中等 | 中等 |
| Spark Streaming | Micro-Batching | 宣告式(提供封裝後的高階函數,如count函數) | Exactly-once | RDD CheckPoint(基於RDD做CheckPoint) | 基於DStream | 中等 | 高 |
| Flink | Native | 宣告式 | Exactly-once | CheckPoint(Flink的一種快照) | 基於操作 | 低 | 高 |
在這裡對這幾種框架進行對比。
模型
Storm 和 Flink 是真正的一條一條處理資料;而 Trident(Storm 的封裝框架)和 Spark Streaming 其實都是小批次處理,一次處理一批資料(小批次)。API
Storm 和 Trident 都使用基礎 API 進行開發,比如實現一個簡單的 sum 求和操作;而 Spark Streaming 和 Flink 中都提供封裝後的高階函數,可以直接拿來使用,這樣就比較方便了。保證次數
在資料處理方面,Storm 可以實現至少處理一次,但不能保證僅處理一次,這樣就會導致資料重複處理問題,所以針對計數類的需求,可能會產生一些誤差;Trident 通過事務可以保證對資料實現僅一次的處理,Spark Streaming 和 Flink 也是如此。容錯機制
Storm 和 Trident 可以通過 ACK 機制實現資料的容錯機制,而 Spark Streaming 和 Flink 可以通過 CheckPoint 機制實現容錯機制。狀態管理
Storm 中沒有實現狀態管理,Spark Streaming 實現了基於 DStream 的狀態管理,而 Trident 和 Flink 實現了基於操作的狀態管理。延時
表示資料處理的延時情況,因此 Storm 和 Flink 接收到一條資料就處理一條資料,其資料處理的延時性是很低的;而 Trident 和 Spark Streaming 都是小型批次處理,它們資料處理的延時性相對會偏高。吞吐量
Storm 的吞吐量其實也不低,只是相對於其他幾個框架而言較低;Trident 屬於中等;而 Spark Streaming 和 Flink 的吞吐量是比較高的。官網中 Flink 和 Storm 的吞吐量對比如下圖所示。
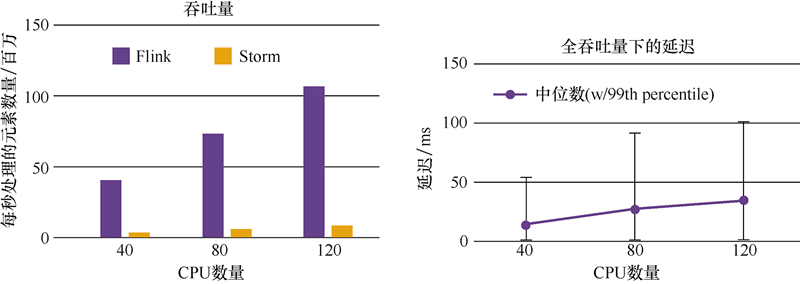
圖3:Flink 和 Storm 的吞吐量對比