利用Python讀取和修改Excel檔案(包括xls檔案和xlsx檔案)——基於xlrd、xlwt和openpyxl模組
本文介紹一下使用Python對Excel檔案的基本操作,包括使用xlrd模組讀取excel檔案,使用xlwt模組將資料寫入excel檔案,使用openpyxl模組讀取寫入和修改excel檔案。
【最近一些朋友反映個別程式碼無法偵錯(但是在我這裡沒問題),這裡程式碼我都是偵錯過的,之前一年也沒有朋友反饋過這些問題,所以大概率是版本問題。
我的版本如下: xlrd 1.1.0 、xlwt 1.3.0 、openpyxl 2.5.4 】
目錄
1、使用xlrd模組對xls檔案進行讀操作
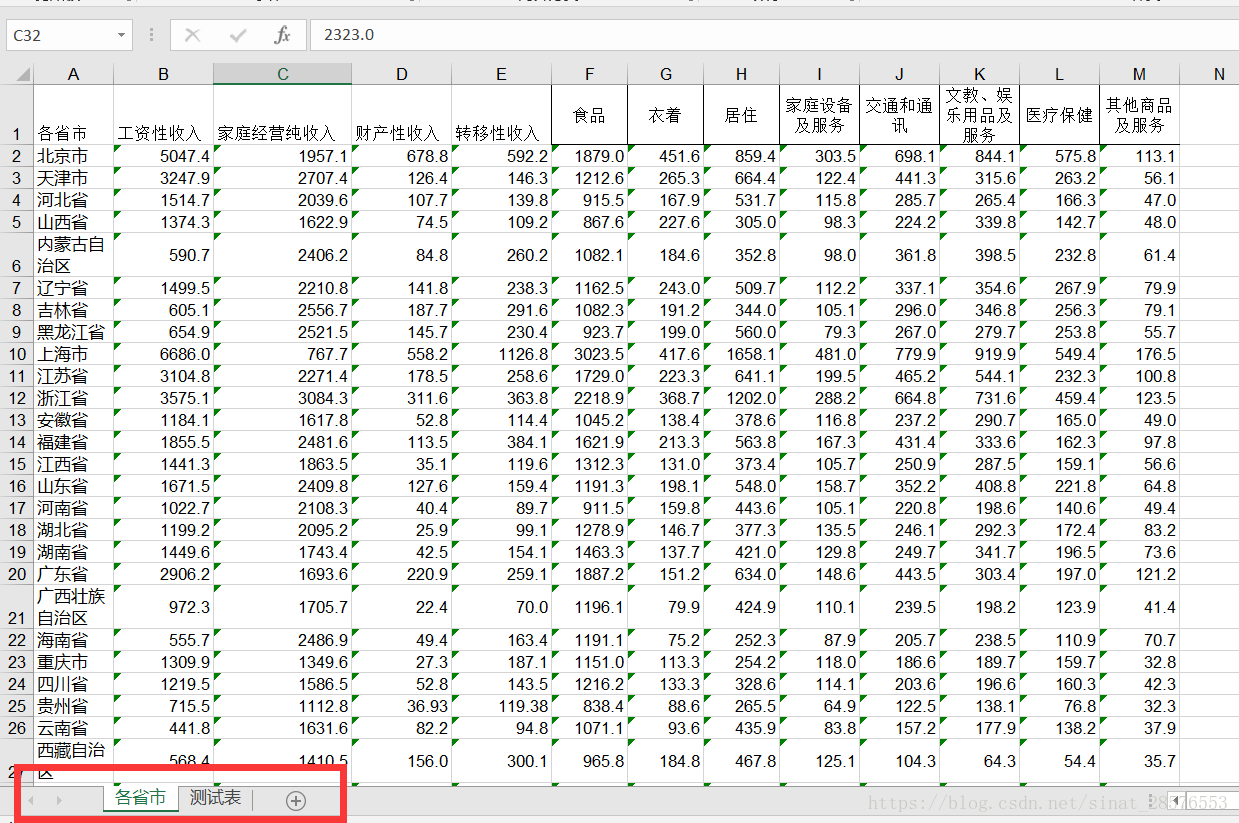
假設我們的表如下,是一個「農村居民家庭人均純收入和農村居民家庭人均消費情況」的表格。字尾為.xls。裡面包含兩個工作表,「各省市」和「測試表」。
提一下,一個Excel檔案,就相當於一個「工作簿」(workbook),一個「工作簿」裡面可以包含多個「工作表(sheet)」
1.1 獲取工作簿物件
引入模組,獲得工作簿物件。
import xlrd #引入模組
#開啟檔案,獲取excel檔案的workbook(工作簿)物件
workbook=xlrd.open_workbook("DataSource/Economics.xls") #檔案路徑
1.2 獲取工作表物件
我們知道一個工作簿裡面可以含有多個工作表,當我們獲取「工作簿物件」後,可以接著來獲取工作表物件,可以通過「索引」的方式獲得,也可以通過「表名」的方式獲得。
'''對workbook物件進行操作'''
#獲取所有sheet的名字
names=workbook.sheet_names()
print(names) #['各省市', '測試表'] 輸出所有的表名,以列表的形式
#通過sheet索引獲得sheet物件
worksheet=workbook.sheet_by_index(0)
print(worksheet) #<xlrd.sheet.Sheet object at 0x000001B98D99CFD0>
#通過sheet名獲得sheet物件
worksheet=workbook.sheet_by_name("各省市")
print(worksheet) #<xlrd.sheet.Sheet object at 0x000001B98D99CFD0>
#由上可知,workbook.sheet_names() 返回一個list物件,可以對這個list物件進行操作
sheet0_name=workbook.sheet_names()[0] #通過sheet索引獲取sheet名稱
print(sheet0_name) #各省市
1.3 獲取工作表的基本資訊
在獲得「表物件」之後,我們可以獲取關於工作表的基本資訊。包括表名、行數與列數。
'''對sheet物件進行操作'''
name=worksheet.name #獲取表的姓名
print(name) #各省市
nrows=worksheet.nrows #獲取該表總行數
print(nrows) #32
ncols=worksheet.ncols #獲取該表總列數
print(ncols) #13
1.4 按行或列方式獲得工作表的資料
有了行數和列數,迴圈列印出表的全部內容也變得輕而易舉。
for i in range(nrows): #迴圈列印每一行
print(worksheet.row_values(i)) #以列表形式讀出,列表中的每一項是str型別
#['各省市', '工資性收入', '家庭經營純收入', '財產性收入', ………………]
#['北京市', '5047.4', '1957.1', '678.8', '592.2', '1879.0,…………]
col_data=worksheet.col_values(0) #獲取第一列的內容
print(col_data)
1.5 獲取某一個單元格的資料
我們還可以將查詢精確地定位到某一個單元格。
在xlrd模組中,工作表的行和列都是從0開始計數的。
#通過座標讀取表格中的資料
cell_value1=sheet0.cell_value(0,0)
cell_value2=sheet0.cell_value(1,0)
print(cell_value1) #各省市
print(cell_value2) #北京市
cell_value1=sheet0.cell(0,0).value
print(cell_value1) #各省市
cell_value1=sheet0.row(0)[0].value
print(cell_value1) #各省市
2、使用xlwt模組對xls檔案進行寫操作
2.1 建立工作簿
# 匯入xlwt模組
import xlwt
#建立一個Workbook物件,相當於建立了一個Excel檔案
book=xlwt.Workbook(encoding="utf-8",style_compression=0)
'''
Workbook類初始化時有encoding和style_compression引數
encoding:設定字元編碼,一般要這樣設定:w = Workbook(encoding='utf-8'),就可以在excel中輸出中文了。預設是ascii。
style_compression:表示是否壓縮,不常用。
'''
2.2 建立工作表
建立完工作簿之後,可以在相應的工作簿中,建立工作表。
# 建立一個sheet物件,一個sheet物件對應Excel檔案中的一張表格。
sheet = book.add_sheet('test01', cell_overwrite_ok=True)
# 其中的test是這張表的名字,cell_overwrite_ok,表示是否可以覆蓋單元格,其實是Worksheet範例化的一個引數,預設值是False
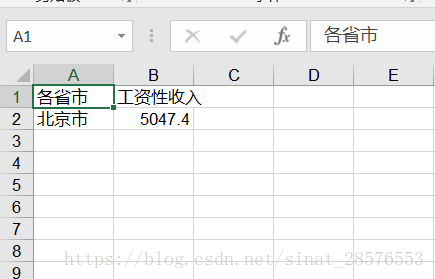
2.3 按單元格的方式向工作表中新增資料
# 向表test中新增資料
sheet.write(0, 0, '各省市') # 其中的'0-行, 0-列'指定表中的單元,'各省市'是向該單元寫入的內容
sheet.write(0, 1, '工資性收入')
#也可以這樣新增資料
txt1 = '北京市'
sheet.write(1,0, txt1)
txt2 = 5047.4
sheet.write(1, 1, txt2)最後被檔案被儲存之後,上文語句形成的「工作表」如下所示:
2.4 按行或列方式向工作表中新增資料
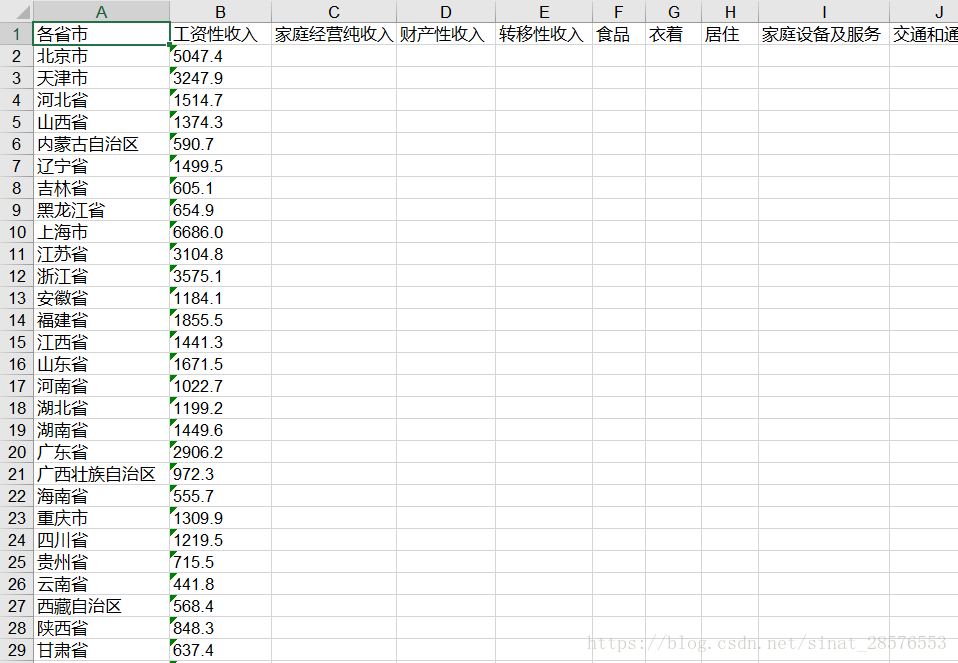
為了驗證這個功能,我們在工作簿中,再建立一個工作表,上個工作表叫「test01」,那麼這個工作表命名為「test02」,都隸屬於同一個工作簿。在下面程式碼中test02是表名,sheet2才是可供操作的工作表物件。
#新增第二個表
sheet2=book.add_sheet("test02",cell_overwrite_ok=True)
Province=['北京市', '天津市', '河北省', '山西省', '內蒙古自治區', '遼寧省',
'吉林省', '黑龍江省', '上海市', '江蘇省', '浙江省', '安徽省', '福建省',
'江西省', '山東省', '河南省', '湖北省', '湖南省', '廣東省', '廣西壯族自治區',
'海南省', '重慶市', '四川省', '貴州省', '雲南省', '西藏自治區', '陝西省', '甘肅省',
'青海省', '寧夏回族自治區', '新疆維吾爾自治區']
Income=['5047.4', '3247.9', '1514.7', '1374.3', '590.7', '1499.5', '605.1', '654.9',
'6686.0', '3104.8', '3575.1', '1184.1', '1855.5', '1441.3', '1671.5', '1022.7',
'1199.2', '1449.6', '2906.2', '972.3', '555.7', '1309.9', '1219.5', '715.5', '441.8',
'568.4', '848.3', '637.4', '653.3', '823.1', '254.1']
Project=['各省市', '工資性收入', '家庭經營純收入', '財產性收入', '轉移性收入', '食品', '衣著',
'居住', '家庭裝置及服務', '交通和通訊', '文教、娛樂用品及服務', '醫療保健', '其他商品及服務']
#填入第一列
for i in range(0, len(Province)):
sheet2.write(i+1, 0, Province[i])
#填入第二列
for i in range(0,len(Income)):
sheet2.write(i+1,1,Income[i])
#填入第一行
for i in range(0,len(Project)):
sheet2.write(0,i,Project[i])2.5 儲存建立的檔案
最後儲存在特定路徑即可。
# 最後,將以上操作儲存到指定的Excel檔案中
book.save('DataSource\\test1.xls') 執行出來的工作表test02如下所示:
3、使用openpyxl模組對xlsx檔案進行讀操作
上面兩個模組,xlrd和xlwt都是針對Excel97-2003操作的,也就是以xls結尾的檔案。很顯然現在基本上都是Excel2007以上的版本,以xlsx為字尾。要對這種型別的Excel檔案進行操作要使用openpyxl,該模組既可以進行「讀」操作,也可以進行「寫」操作,還可以對已經存在的檔案做修改。
3.1 獲取工作簿物件
import openpyxl
#獲取 工作簿物件
workbook=openpyxl.load_workbook("DataSource\Economics.xlsx")
#與xlrd 模組的區別
#wokrbook=xlrd.open_workbook(""DataSource\Economics.xls)3.2 獲取所有工作表名
#獲取工作簿 workbook的所有工作表
shenames=workbook.get_sheet_names()
print(shenames) #['各省市', '測試表']
#在xlrd模組中為 sheetnames=workbook.sheet_names()
#使用上述語句會發出警告:DeprecationWarning: Call to deprecated function get_sheet_names (Use wb.sheetnames).
#說明 get_sheet_names已經被棄用 可以改用 wb.sheetnames 方法
shenames=workbook.sheetnames
print(shenames) #['各省市', '測試表']
3.3 獲取工作表物件
上一小節獲取的工作表名,可以被應用在這一節中,用來獲取工作表物件。
#獲得工作簿的表名後,就可以獲得表物件
worksheet=workbook.get_sheet_by_name("各省市")
print(worksheet) #<Worksheet "各省市">
#使用上述語句同樣彈出警告:DeprecationWarning: Call to deprecated function get_sheet_by_name (Use wb[sheetname]).
#改寫成如下格式
worksheet=workbook["各省市"]
print(worksheet) #<Worksheet "各省市">
#還可以通過如下寫法獲得表物件
worksheet1=workbook[shenames[1]]
print(worksheet1) #<Worksheet "測試表">3.4 根據索引方式獲取工作表物件
上一小節獲取工作表物件的方式,實際上是通過「表名」來獲取,我們可以通過更方便的方式,即通過「索引」方式獲取工作表物件。
#還可以通過索引方式獲取表物件
worksheet=workbook.worksheets[0]
print(worksheet) #<Worksheet "各省市">
#也可以用如下方式
#獲取當前活躍的worksheet,預設就是第一個worksheet
ws = workbook.active3.5 獲取工作表的屬性
得到工作表物件後,可以獲取工作表的相應屬性,包括「表名」、「行數」、「列數」
#經過上述操作,我們已經獲得了第一個「表」的「表物件「,接下來可以對錶物件進行操作
name=worksheet.title #獲取表名
print(name) #各省市
#在xlrd中為worksheet.name
#獲取該表相應的行數和列數
rows=worksheet.max_row
columns=worksheet.max_column
print(rows,columns) #32 13
#在xlrd中為 worksheet.nrows worksheet.ncols3.6 按行或列方式獲取表中的資料
要想以行方式或者列方式,獲取整個工作表的內容,我們需要使用到以下兩個生成器:
sheet.rows,這是一個生成器,裡面是每一行資料,每一行資料由一個元組型別包裹。
sheet.columns,同上,裡面是每一列資料。
for row in worksheet.rows:
for cell in row:
print(cell.value,end=" ")
print()
"""
各省市 工資性收入 家庭經營純收入 財產性收入 轉移性收入 食品 衣著 居住 家庭裝置及服務 ……
北京市 5047.4 1957.1 678.8 592.2 1879.0 451.6 859.4 303.5 698.1 844.1 575.8 113.1 ……
天津市 3247.9 2707.4 126.4 146.3 1212.6 265.3 664.4 122.4 441.3 315.6 263.2 56.1 ……
……
"""
for col in worksheet.columns:
for cell in col:
print(cell.value,end=" ")
print()
'''
各省市 北京市 天津市 河北省 山西省 內蒙古自治區 遼寧省 吉林省 黑龍江省 上海市 江蘇省 浙江省 ……
工資性收入 5047.4 3247.9 1514.7 1374.3 590.7 1499.5 605.1 654.9 6686.0 3104.8 3575.1 ……
家庭經營純收入 1957.1 2707.4 2039.6 1622.9 2406.2 2210.8 2556.7 2521.5 767.7 2271.4 ……
……
'''我們可以通過檢視sheet.rows 裡面的具體格式,來更好的理解程式碼
for row in worksheet.rows:
print(row)
'''
(<Cell '各省市'.A1>, <Cell '各省市'.B1>, <Cell '各省市'.C1>, <Cell '各省市'.D1>, <Cell '各省市'.E1>,……
(<Cell '各省市'.A2>, <Cell '各省市'.B2>, <Cell '各省市'.C2>, <Cell '各省市'.D2>, <Cell '各省市'.E2>, ……
……
'''
#可知,需要二次迭代
for row in worksheet.rows:
for cell in row:
print(cell,end=" ")
print()
'''
<Cell '各省市'.A1> <Cell '各省市'.B1> <Cell '各省市'.C1> <Cell '各省市'.D1>……
<Cell '各省市'.A2> <Cell '各省市'.B2> <Cell '各省市'.C2> <Cell '各省市'.D2> ……
……
'''
#還需要cell.value
for row in worksheet.rows:
for cell in row:
print(cell.value,end=" ")
print()
3.7 獲取特定行或特定列的資料
上述方法可以迭代輸出表的所有內容,但是如果要獲取特定的行或列的內容呢?我們可以想到的是用「索引」的方式,但是sheet.rows是生成器型別,不能使用索引。所以我們將其轉換為list之後再使用索引,例如用list(sheet.rows)[3]來獲取第四行的tuple物件。
#輸出特定的行
for cell in list(worksheet.rows)[3]: #獲取第四行的資料
print(cell.value,end=" ")
print()
#河北省 1514.7 2039.6 107.7 139.8 915.5 167.9 531.7 115.8 285.7 265.4 166.3 47.0
#輸出特定的列
for cell in list(worksheet.columns)[2]: #獲取第三列的資料
print(cell.value,end=" ")
print()
#家庭經營純收入 1957.1 2707.4 2039.6 1622.9 2406.2 2210.8 2556.7 2521.5 767.7 2271.4 3084.3……
#已經轉換成list型別,自然是從0開始計數。3.8 獲取某一塊的資料
有時候我們並不需要一整行或一整列內容,那麼可以通過如下方式獲取其中一小塊的內容。
注意兩種方式的區別,在第一種方式中,由於生成器被轉換成了列表的形式,所以索引是從0開始計數的。
而第二種方式,行和列都是從1開始計數,這是和xlrd模組中最大的不同,在xlrd中行和列都是從0計數的,openpyxl之所這麼做是為了和Excel表統一,因為在Excel表,就是從1開始計數。
for rows in list(worksheet.rows)[0:3]:
for cell in rows[0:3]:
print(cell.value,end=" ")
print()
'''
各省市 工資性收入 家庭經營純收入
北京市 5047.4 1957.1
天津市 3247.9 2707.4
'''
for i in range(1, 4):
for j in range(1, 4):
print(worksheet.cell(row=i, column=j).value,end=" ")
print()
'''
各省市 工資性收入 家庭經營純收入
北京市 5047.4 1957.1
天津市 3247.9 2707.4
'''3.9 獲取某一單元格的資料
有兩種方式。
#精確讀取表格中的某一單元格
content_A1= worksheet['A1'].value
print(content_A1)
content_A1=worksheet.cell(row=1,column=1).value
#等同於 content_A1=worksheet.cell(1,1).value
print(content_A1)
#此處的行數和列數都是從1開始計數的,而在xlrd中是由0開始計數的
4、使用openpyxl模組對xlsx檔案進行寫操作
4.1 建立工作簿和獲取工作表
同樣的workbook=openpyxl.Workbook() 中「W」要大寫。
import openpyxl
# 建立一個Workbook物件,相當於建立了一個Excel檔案
workbook=openpyxl.Workbook()
#wb=openpyxl.Workbook(encoding='UTF-8')
#獲取當前活躍的worksheet,預設就是第一個worksheet
worksheet = workbook.active
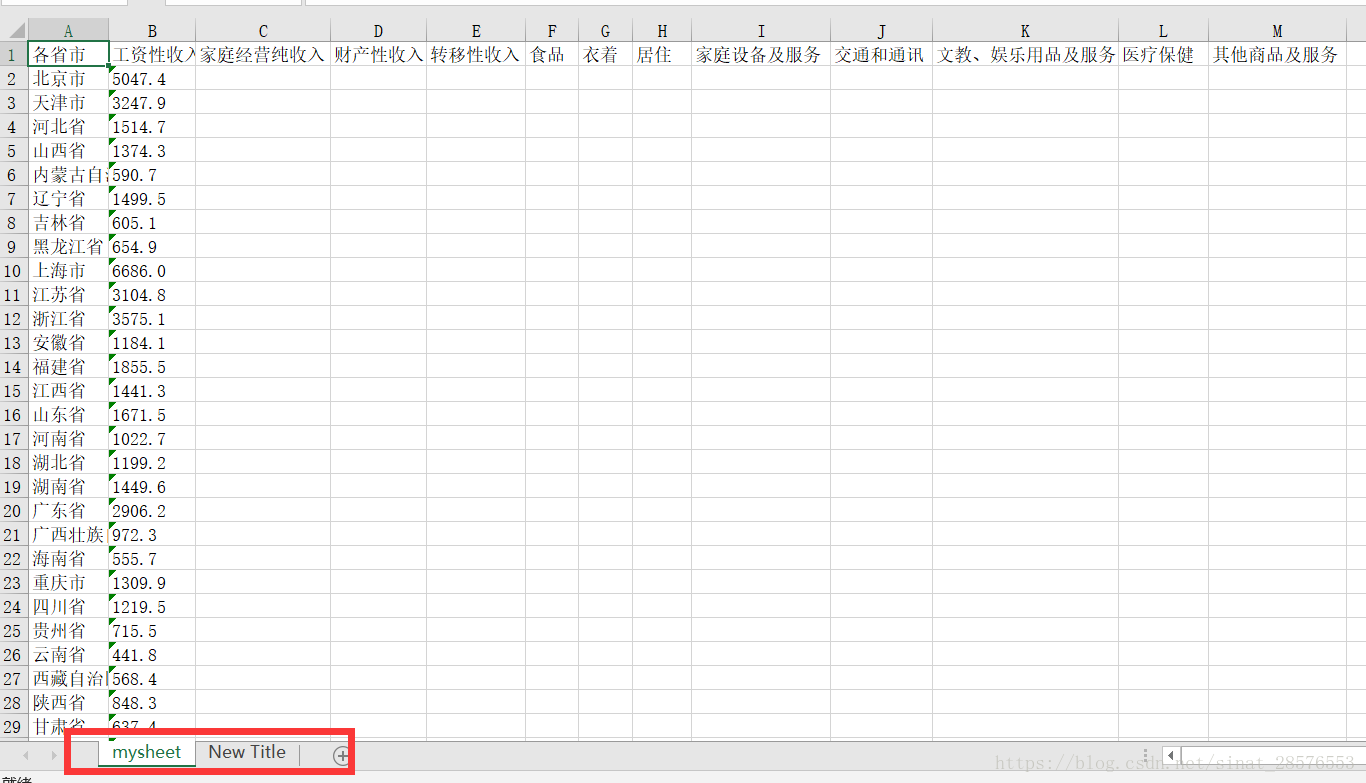
worksheet.title="mysheet"4.2 建立新的工作表
worksheet2 = workbook.create_sheet() #預設插在工作簿末尾
#worksheet2 = workbook.create_sheet(0) #插入在工作簿的第一個位置
worksheet2.title = "New Title"4.3 將資料寫入工作表
#以下是我們要寫入的資料
Province=['北京市', '天津市', '河北省', '山西省', '內蒙古自治區', '遼寧省',
'吉林省', '黑龍江省', '上海市', '江蘇省', '浙江省', '安徽省', '福建省',
'江西省', '山東省', '河南省', '湖北省', '湖南省', '廣東省', '廣西壯族自治區',
'海南省', '重慶市', '四川省', '貴州省', '雲南省', '西藏自治區', '陝西省', '甘肅省',
'青海省', '寧夏回族自治區', '新疆維吾爾自治區']
Income=['5047.4', '3247.9', '1514.7', '1374.3', '590.7', '1499.5', '605.1', '654.9',
'6686.0', '3104.8', '3575.1', '1184.1', '1855.5', '1441.3', '1671.5', '1022.7',
'1199.2', '1449.6', '2906.2', '972.3', '555.7', '1309.9', '1219.5', '715.5', '441.8',
'568.4', '848.3', '637.4', '653.3', '823.1', '254.1']
Project=['各省市', '工資性收入', '家庭經營純收入', '財產性收入', '轉移性收入', '食品', '衣著',
'居住', '家庭裝置及服務', '交通和通訊', '文教、娛樂用品及服務', '醫療保健', '其他商品及服務']
#寫入第一行資料,行號和列號都從1開始計數
for i in range(len(Project)):
worksheet.cell(1, i+1,Project[i])
#寫入第一列資料,因為第一行已經有資料了,i+2
for i in range(len(Province)):
worksheet.cell(i+2,1,Province[i])
#寫入第二列資料
for i in range(len(Income)):
worksheet.cell(i+2,2,Income[i])
4.4 儲存工作簿
workbook.save(filename='DataSource\\myfile.xlsx')最後執行結果如下所示:
5、修改已經存在的工作簿(表)
5.1 插入一列資料
將第四節中最後儲存的myfile.xlsx作為我們要修改的表格,我們計劃在最前面插入一列「編號」,如下所示:
import openpyxl
workbook=openpyxl.load_workbook("DataSource\myfile.xlsx")
worksheet=workbook.worksheets[0]
#在第一列之前插入一列
worksheet.insert_cols(1) #
for index,row in enumerate(worksheet.rows):
if index==0:
row[0].value="編號" #每一行的一個row[0]就是第一列
else:
row[0].value=index
#列舉出來是tuple型別,從0開始計數
workbook.save(filename="DataSource\myfile.xlsx")執行結果如下:
5.2 修改特定單元格
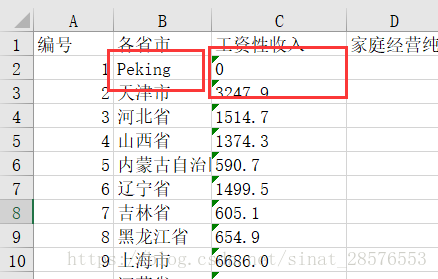
worksheet.cell(2,3,'0')
worksheet["B2"]="Peking"執行結果如下:
5.3 批次修改資料
批次修改資料就相當於寫入,會自動覆蓋。在上一節中已經有介紹,不再贅述。
還有sheet.append()方法,可以用來新增行。
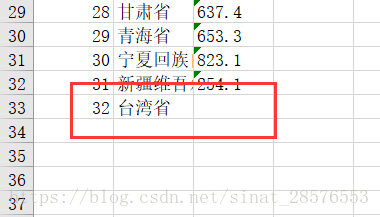
taiwan=[32,"臺灣省"]
worksheet.append(taiwan)執行結果如下:
本文完。行筆匆忙,如有錯誤,還請指出。