深度學習PyTorch,TensorFlow中GPU利用率較低,CPU利用率很低,且模型訓練速度很慢的問題總結與分析
在深度學習模型訓練過程中,在伺服器端或者本地pc端,輸入nvidia-smi來觀察顯示卡的GPU記憶體佔用率(Memory-Usage),顯示卡的GPU利用率(GPU-util),然後採用top來檢視CPU的執行緒數(PID數)和利用率(%CPU)。往往會發現很多問題,比如,GPU記憶體佔用率低,顯示卡利用率低,CPU百分比低等等。接下來仔細分析這些問題和處理辦法。
1. GPU記憶體佔用率問題
這往往是由於模型的大小以及batch size的大小,來影響這個指標。當你發下你的GPU佔用率很小的時候,比如40%,70%,等等。此時,如果你的網路結構已經固定,此時只需要改變batch size的大小,就可以儘量利用完整個GPU的記憶體。GPU的記憶體佔用率主要是模型的大小,包括網路的寬度,深度,引數量,中間每一層的快取,都會在記憶體中開闢空間來進行儲存,所以模型本身會佔用很大一部分記憶體。其次是batch size的大小,也會佔用影響記憶體佔用率。batch size設定為128,與設定為256相比,記憶體佔用率是接近於2倍關係。當你batch size設定為128,佔用率為40%的話,設定為256時,此時模型的佔用率約等於80%,偏差不大。所以在模型結構固定的情況下,儘量將batch size設定大,充分利用GPU的記憶體。(GPU會很快的算完你給進去的資料,主要瓶頸在CPU的資料吞吐量上面。)
2. GPU利用率問題
這個是Volatile GPU-Util表示,當沒有設定好CPU的執行緒數時,這個引數是在反覆的跳動的,0%,20%,70%,95%,0%。這樣停息1-2 秒然後又重複起來。其實是GPU在等待資料從CPU傳輸過來,當從匯流排傳輸到GPU之後,GPU逐漸起計算來,利用率會突然升高,但是GPU的算力很強大,0.5秒就基本能處理完資料,所以利用率接下來又會降下去,等待下一個batch的傳入。因此,這個GPU利用率瓶頸在記憶體頻寬和記憶體媒介上以及CPU的效能上面。最好當然就是換更好的四代或者更強大的記憶體條,配合更好的CPU。
另外的一個方法是,在PyTorch這個框架裡面,資料載入Dataloader上做更改和優化,包括num_workers(執行緒數),pin_memory,會提升速度。解決好資料傳輸的頻寬瓶頸和GPU的運算效率低的問題。在TensorFlow下面,也有這個載入資料的設定。
torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size,
shuffle=True,
num_workers=8,
pin_memory=True)為了提高利用率,首先要將num_workers(執行緒數)設定得體,4,8,16是幾個常選的幾個引數。本人測試過,將num_workers設定的非常大,例如,24,32,等,其效率反而降低,因為模型需要將資料平均分配到幾個子執行緒去進行預處理,分發等資料操作,設高了反而影響效率。當然,執行緒數設定為1,是單個CPU來進行資料的預處理和傳輸給GPU,效率也會低。其次,當你的伺服器或者電腦的記憶體較大,效能較好的時候,建議開啟pin_memory開啟,就省掉了將資料從CPU傳入到快取RAM裡面,再給傳輸到GPU上;為True時是直接對映到GPU的相關記憶體塊上,省掉了一點資料傳輸時間。
3. CPU的利用率問題
很多人在模型訓練過程中,不只是關注GPU的各種效能引數,往往還需要檢視CPU處理的怎麼樣,利用的好不好。這一點至關重要。但是對於CPU,不能一味追求超高的佔用率。如圖所示,對於14339這個程式來說,其CPU佔用率為2349%(我的伺服器是32核的,所以最高為3200%)。這表明用了24核CPU來載入資料和做預處理和後處理等。其實主要的CPU花在載入傳輸資料上。此時,來測量資料載入的時間發現,即使CPU利用率如此之高,其實際資料載入時間是設定恰當的DataLoader的20倍以上,也就是說這種方法來載入資料慢20倍。當DataLoader的num_workers=0時,或者不設定這個引數,會出現這個情況。
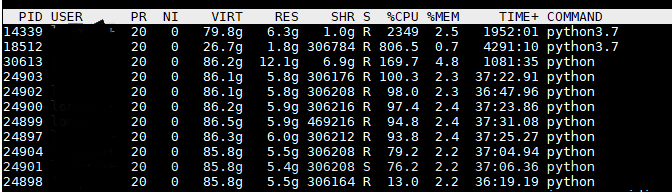
下圖中可以看出,載入資料的實際是12.8s,模型GPU運算時間是0.16s,loss反傳和更新時間是0.48s。此時,即使CPU為2349%,但模型的訓練速度還是非常慢,而且,GPU大部分是時間是空閒等待狀態。

當我將num_workers=1時,出現的時間統計如下,load data time為6.3,資料載入效率提升1倍。且此時的CPU利用率為170%,用的CPU並不多,效能提升1倍。

此時,檢視GPU的效能狀態(我的模型是放在1,2,3號卡上訓練),發現,雖然GPU(1,2,3)的記憶體利用率很高,基本上為98%,但是利用率為0%左右。表面此時網路在等待從CPU傳輸資料到GPU,此時CPU瘋狂載入資料,而GPU處於空閒狀態。
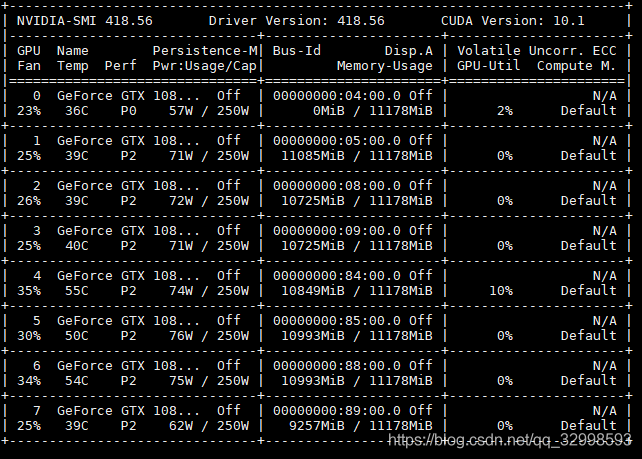
由此可見,CPU的利用率不一定最大才最好。
對於這個問題,解決辦法是,增加DataLoader這個num_wokers的個數,主要是增加子執行緒的個數,來分擔主執行緒的資料處理壓力,多執行緒協同處理資料和傳輸資料,不用放在一個執行緒裡負責所有的預處理和傳輸任務。
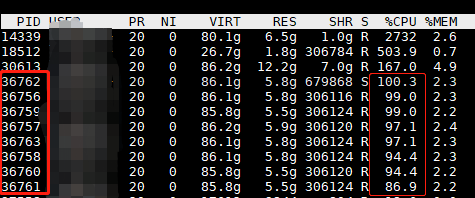
我將num_workers=8,16都能取得不錯的效果。此時用top檢視CPU和執行緒數,如果我設定為num_workers=8,執行緒數有了8個連續開闢的執行緒PID,且大家的佔用率都在100%左右,這表明模型的CPU端,是較好的分配了任務,提升資料吞吐效率。效果如下圖所示,CPU利用率很平均和高效,每個執行緒是發揮了最大的效能。
此時,在用nvidia-smi檢視GPU的利用率,幾塊GPU都在滿負荷,滿GPU記憶體,滿GPU利用率的處理模型,速度得到巨大提升。
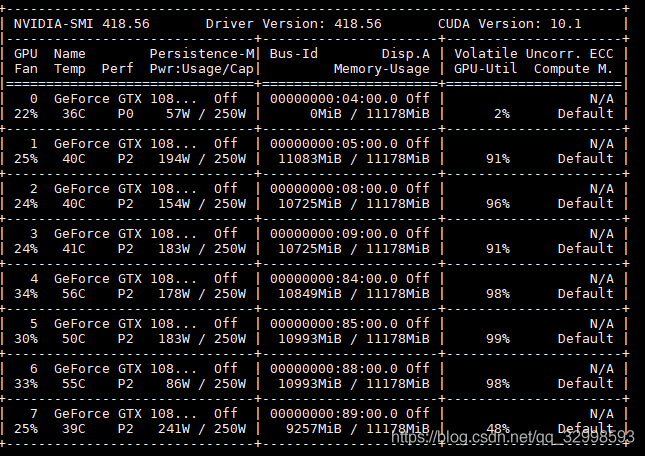
上圖中可以看見,GPU的記憶體利用率最大化,此時是將batch size設定的較大,佔滿了GPU的記憶體,然後將num_workers=8,分配多個子執行緒,且設定pin_memory=True,直接對映資料到GPU的專用記憶體,減少資料傳輸時間。GPU和CPU的資料瓶頸得到解決。整體效能得到權衡。
此時的執行時間在表中做了統計:
| 處理階段 | 時間 |
| 資料載入 | 0.25s |
| 模型在GPU計算 | 0.21s |
| loss反傳,引數更新 | 0.43s |
4. 總結
對上面的分析總結一下,第一是增加batch size,增加GPU的記憶體佔用率,儘量用完記憶體,而不要剩一半,空的記憶體給另外的程式用,兩個任務的效率都會非常低。第二,在資料載入時候,將num_workers執行緒數設定稍微大一點,推薦是8,16等,且開啟pin_memory=True。不要將整個任務放在主程序裡面做,這樣消耗CPU,且速度和效能極為低下。
Supplementary:看到大家在評論回覆的問題比較多,所以再加一些敘述!
開這麼多執行緒。第一個,檢視你的資料的batch_size,batchsize小了,主CPU直接就載入,處理,而且沒有分配到多GPU裡面(如果你使用的是多GPU);如果是單GPU,那麼就是CPU使勁讀資料,載入資料,然後GPU一下就處理完了,你的模型應該是很小,或者模型的FLOPs很小。檢查一下模型問題。還有就是,現在這個情況下,開8個執行緒和1個執行緒,沒什麼影響,你開一個num_workers都一樣的。如果速度快,沒必要分配到多個num_workers去。當資料量大的時候,num_workers設定大,會非常降低資料載入階段的耗時。這個主要還是應該配合過程。
在偵錯過程,命令:top 實時檢視你的CPU的程序利用率,這個引數對應你的num_workers的設定;
命令: watch -n 0.5 nvidia-smi 每0.5秒重新整理並顯示顯示卡設定。
實時檢視你的GPU的使用情況,這是GPU的設定相關。這兩個配合好。包括batch_size的設定。
時間:2019年9月20日
5. 再次補充內容
有很多網友都在討論一些問題,有時候,我們除了排查程式碼,每個模組的處理資訊之外,其實還可以查一下,你的記憶體卡,是插到哪一塊插槽的。這個插槽的位置,也非常影響程式碼在GPU上執行的效率。
大家除了看我上面的一些小的建議之外,評論裡面也有很多有用的資訊。遇到各自問題的網友們,把他們的不同情況,都描述和討論了一下,經過交流,大家給出了各自在訓練中,CPU,GPU效率問題的一些新的發現和解決問題的方法。
針對下面的問題,給出一點補充說明:
問題1. CPU忙碌,GPU清閒。
資料的預處理,和載入到GPU的記憶體裡面,花費時間。平衡一下batch size, num_workers。
問題2. CPU利用率低,GPU跑起來,利用率浮動,先增加,然後降低,然後等待,CPU也是浮動。
- 2.1 下面是具體的步驟和對策:
在pytorch訓練模型時出現以下情況, 情況描述: 首先環境:2080Ti + I7-10700K, torch1.6, cuda10.2, 驅動440 引數設定:shuffle=True, num_workers=8, pin_memory=True; 現象1:該程式碼在另外一臺電腦上,可以將GPU利用率穩定在96%左右 現象2:在個人電腦上,CPU利用率比較低,導致資料載入慢,GPU利用率浮動,訓練慢約4倍;有意思的是,偶然開始訓練時,CPU利用率高,可以讓GPU跑起來,但僅僅幾分鐘,CPU利用率降下來就上不去了,又回到蝸牛速度。
- 可以採用的方法:
兩邊的設定都一樣嗎。另一臺電腦和你的電腦。你看整體,好像設定設定有點不同。包括硬體,CPU的核,記憶體大小。你對比一下兩臺裝置。這是第一個。第二個,還是程式碼裡面的設定,程式碼的高效性。你一來,CPU利用率低,你看一下每一步,卡到哪裡,哪裡是瓶頸,什麼步驟最耗時。都記錄一下每一個大的步驟的耗時,然後在分析。測試了每一個大的過程的時間,可以看見,耗時在哪裡。主要包括,載入資料,前向傳播,反向更新,然後下一步。
- 2.2 經過測試之後,第二次問題分析:
經過測試,發現本機卡的地方在載入影象的地方,有時載入10kb左右的影象需要1s以上,導致整個batch資料載入慢!程式碼應該沒有問題,因為在其他電腦能全速跑起來;硬體上,本機的GPU,CPU都強悍,環境上也看不出差距,唯一差在記憶體16G,其他測試電腦為32G,請問這種現象和記憶體直接關係大嗎?
- 情況分析
最多可能就在這邊。你可以直接測試batch size為1情況下的整個計算。或者將batch size 開到不同的設定下。看載入資料,計算之間的差值。最有可能就是在這個load data,讀取資料這塊。 電腦的執行記憶體16g 32g。其實都已經夠了,然後載入到GPU上,GPU記憶體能放下,影響不大。所以估計是你的記憶體相對小了,導致的問題。試一下。
- 2.3 問題定位,解決方法:
- 這臺電腦的記憶體條插的位置不對,4個插槽的主機板,1根記憶體的時候應該插在第2個插槽(以cpu端參考起),而組裝電腦的商家不專業,放在了第4個插槽上,影響效能,更換位置後,速度飛起來了!關於插槽詳情,有遇到的朋友去網上收,一大堆!
在自己電腦,或者自己配的主機上,跑GPU的時候,記得注意檢視你自己的記憶體卡是插到哪一個槽上的。
補充時間:2021年1月15日