pydbgen:一個資料庫隨機生成器
用這個簡單的工具生成帶有多表的大型資料庫,讓你更好地用 SQL 研究資料科學。
在研究資料科學的過程中,最麻煩的往往不是演算法或者技術,而是如何獲取到一批原始資料。儘管網上有很多真實優質的資料集可以用於機器學習,然而在學習 SQL 時卻不是如此。
對於資料科學來說,熟悉 SQL 的重要性不亞於了解 Python 或 R 程式設計。如果想收集諸如姓名、年齡、信用卡資訊、地址這些資訊用於機器學習任務,在 Kaggle 上查詢專門的資料集比使用足夠大的真實資料庫要容易得多。
如果有一個簡單的工具或庫來幫助你生成一個大型資料庫,表裡還存放著大量你需要的資料,豈不美哉?
不僅僅是資料科學的入門者,即使是經驗豐富的軟體測試人員也會需要這樣一個簡單的工具,只需編寫幾行程式碼,就可以通過隨機(但是是假隨機)生成任意數量但有意義的資料集。
因此,我要推薦這個名為 pydbgen 的輕量級 Python 庫。在後文中,我會簡要說明這個庫的相關內容,你也可以閱讀它的文件詳細了解更多資訊。
pydbgen 是什麼
pydbgen 是一個輕量的純 Python 庫,它可以用於生成隨機但有意義的資料記錄(包括姓名、地址、信用卡號、日期、時間、公司名稱、職位、車牌號等等),存放在 Pandas Dataframe 物件中,並儲存到 SQLite 資料庫或 Excel 檔案。
如何安裝 pydbgen
目前 1.0.5 版本的 pydbgen 託管在 PyPI(Python 包索引儲存庫)上,並且對 Faker 有依賴關係。安裝 pydbgen 只需要執行命令:
pip install pydbgen已經在 Python 3.6 環境下測試安裝成功,但在 Python 2 環境下無法正常安裝。
如何使用 pydbgen
在使用 pydbgen 之前,首先要初始化 pydb 物件。
import pydbgenfrom pydbgen import pydbgenmyDB=pydbgen.pydb()隨後就可以呼叫 pydb 物件公開的各種內部函數了。可以按照下面的例子,輸出隨機的美國城市和車牌號碼:
myDB.city_real()>> 'Otterville'for _ in range(10): print(myDB.license_plate())>> 8NVX937 6YZH485 XBY-564 SCG-2185 XMR-158 6OZZ231 CJN-850 SBL-4272 TPY-658 SZL-0934另外,如果你輸入的是 city() 而不是 city_real(),返回的將會是虛構的城市名。
print(myDB.gen_data_series(num=8,data_type='city'))>>New MichelleRobinboroughLeeburyKaylatownHamiltonfortLake ChristopherHannahstadWest Adamborough生成隨機的 Pandas Dataframe
你可以指定生成資料的數量和種類,但需要注意的是,返回結果均為字串或文字型別。
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])testdf最終產生的 Dataframe 類似下圖所示。
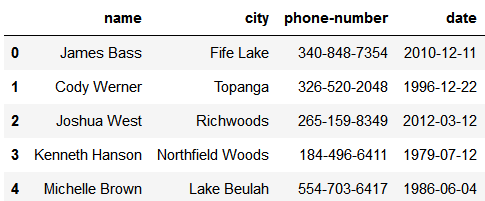
生成資料庫表
你也可以指定生成資料的數量和種類,而返回結果是資料庫中的文字或者變長字串型別。在生成過程中,你可以指定對應的資料庫檔名和表名。
myDB.gen_table(db_file='Testdb.DB',table_name='People',fields=['name','city','street_address','email'])上面的例子種生成了一個能被 MySQL 和 SQLite 支援的 .db 檔案。下圖則顯示了這個檔案中的資料表在 SQLite 視覺化用戶端中開啟的畫面。
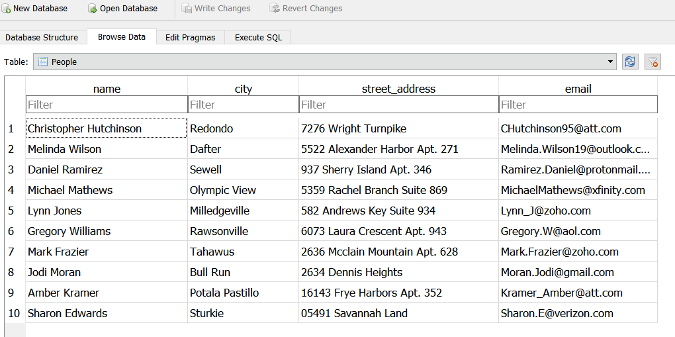
生成 Excel 檔案
和上面的其它範例類似,下面的程式碼可以生成一個具有亂數據的 Excel 檔案。值得一提的是,通過將 phone_simple 引數設為 False ,可以生成較長較複雜的電話號碼。如果你想要提高自己在資料提取方面的能力,不妨嘗試一下這個功能。
myDB.gen_excel(num=20,fields=['name','phone','time','country'],phone_simple=False,filename='TestExcel.xlsx')最終的結果類似下圖所示:
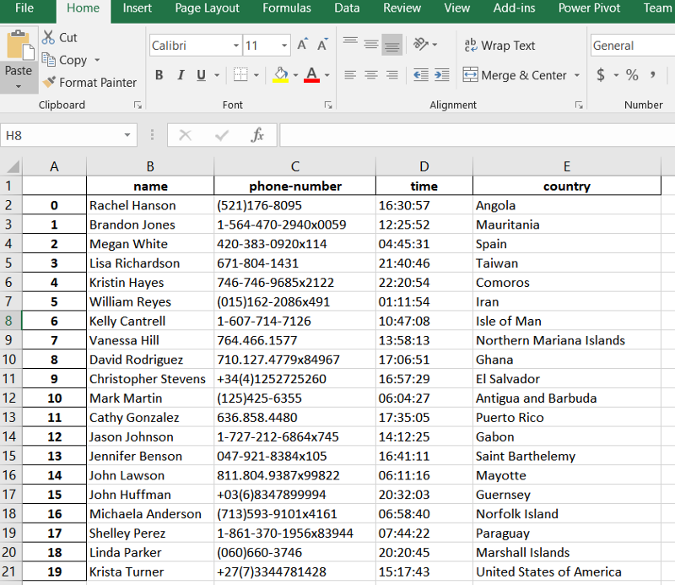
生成隨機電子郵箱地址
pydbgen 內建了一個 realistic_email 方法,它基於種子來生成隨機的電子郵箱地址。如果你不想在網路上使用真實的電子郵箱地址時,這個功能可以派上用場。
for _ in range(10): print(myDB.realistic_email('Tirtha Sarkar'))>>[email protected]@[email protected][email protected]@[email protected]@[email protected]@[email protected]未來的改進和使用者貢獻
目前的版本中並不完美。如果你發現了 pydbgen 的 bug 導致它在執行期間發生崩潰,請向我反饋。如果你打算對這個專案貢獻程式碼,也隨時歡迎你。當然現在也還有很多改進的方向:
- pydbgen 作為亂數據生成器,可以整合一些機器學習或統計建模的功能嗎?
- pydbgen 是否會新增視覺化功能?
一切皆有可能!
如果你有任何問題或想法想要分享,都可以通過 [email protected] 與我聯絡。如果你像我一樣對機器學習和資料科學感興趣,也可以新增我的 LinkedIn 或在 Twitter 上關注我。另外,還可以在我的 GitHub 上找到更多 Python、R 或 MATLAB 的有趣程式碼和機器學習資源。
本文以 CC BY-SA 4.0 許可在 Towards Data Science 首發。