網站有反爬機制你的爬蟲功夫就不好使了?那是你不會反反爬!【Python解決網站的反爬機制戰略總結】
對於很多學Python的人來說,爬蟲是一個很有意思的學習方向,通常剛接觸完爬蟲的小夥伴們就喜歡在各大網站躍躍欲試,結果很多時候就碰一鼻子灰…因為很多網站都設定了反爬機制這道門檻。
一個不會反爬機制的沒網站,不是一個好網址。
一個不會反反爬的爬蟲愛好者,永遠成為不了爬蟲高手。
爬蟲世界一直都是道高一尺魔高一丈,你有反爬我就有反反爬,你giao我就giao giao!

一、何為反爬
首先我們得先來了解一下什麼是反爬。所謂反爬機制通俗講就是不讓爬蟲去抓取資料的一些機制措施,比如以下幾種反爬機制:
- 資料是通過動態載入的,比如微博,今日頭條,b站
- 需要登入,需要驗證碼,比如鐵路12306,淘寶,京東
- 請求次數頻繁,IP地址在同一時間存取次數過多,導致IP被封
- 資料遮蔽方式,比如存取的資料不在原始碼中,資料隱藏在js中,比如今日分享,b站
網站為什麼要設定反爬機制?
- 保護網站安全,減輕伺服器壓力
- 保護網站資料安全
世間萬物,相生相剋,有反爬就有反反爬:即見即可爬
二、反爬解決策略(反反爬)
-
偽裝瀏覽器
-
使用代理IP
-
抓包分析突破非同步載入 / selenium自動化測試工具
-
新增cookie
…
下面就為大家詳細介紹網站的反爬蟲策略,在這裡把我寫爬蟲以來遇到的各種反爬蟲策略和應對的方法總結一下。
從功能上來講,爬蟲一般分為資料採集,處理,儲存三個部分。這裡我們只討論資料採集部分。
一般網站從三個方面反爬蟲:使用者請求的Headers,使用者行為,網站目錄和資料載入方式。前兩種比較容易遇到,大多數網站都從這些角度來反爬蟲。第三種一些應用ajax的網站會採用,這樣增大了爬取的難度(防止靜態爬蟲使用ajax技術動態載入頁面)。
1、從使用者請求的Headers反爬蟲是最常見的反爬蟲策略。
在存取某些網站的時候,網站通常會用判斷存取是否帶有標頭檔案來鑑別該存取是否為爬蟲,用來作為反爬取的一種策略。那我們就需要偽裝headers。很多網站都會對Headers的User-Agent進行檢測,還有一部分網站會對Referer進行檢測(一些資源網站的防盜鏈就是檢測Referer)。
如果遇到了這類反爬蟲機制,可以直接在爬蟲中新增Headers,將瀏覽器的User-Agent複製到爬蟲的Headers中;或者將Referer值修改為目標網站域名[評論:往往容易被忽略,通過對請求的抓包分析,確定referer,在程式中模擬存取請求頭中新增]。對於檢測Headers的反爬蟲,在爬蟲中修改或者新增Headers就能很好的繞過。
例如開啟搜狐首頁,先來看一下Chrome的頭資訊(F12開啟開發者模式)如下:
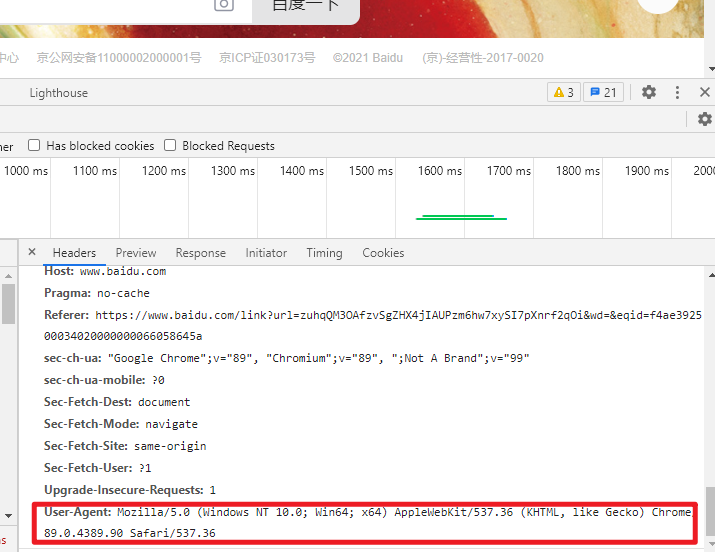
如圖,存取頭資訊中顯示了瀏覽器以及系統的資訊(headers所含資訊眾多,其中User-Agent就是使用者瀏覽器身份的一種標識,具體可自行查詢)
Python中urllib中的request模組提供了模擬瀏覽器存取的功能,程式碼如下:
from urllib import request
url = http://www. baidu.com
# page= requestRequest (url)
# page add header (' User-Agent',' Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebki
headers ={'User-Agent': ' Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebkit/537. 36'}
page = request Request(url, headersheaders)
page_info = request urlopen(page). read().decode('utf-8')
print(page_info)
可以通過add_header(key, value) 或者直接以引數的形式和URL一起請求存取
urllib.request Request()
urllib.request Request(url, data=None, headers={}, origin req host=None, unverifiable )
其中headers是一個字典,通過這種方式可以將爬蟲模擬成瀏覽器對網站進行存取。
2、基於使用者行為反爬蟲
還有一部分網站是通過檢測使用者行為,例如同一IP短時間內多次存取同一頁面,或者同一賬戶短時間內多次進行相同操作。[這種防爬,需要有足夠多的ip來應對]
(1)、大多數網站都是前一種情況,對於這種情況,使用IP代理就可以解決。可以專門寫一個爬蟲,爬取網上公開的代理ip,檢測後全部儲存起來。有了大量代理ip後可以每請求幾次更換一個ip,這在requests或者urllib中很容易做到,這樣就能很容易的繞過第一種反爬蟲。
編寫爬蟲代理:
步驟:
1.引數是一個字典{‘型別’:‘代理ip:埠號’}
proxy_support=urllib.request.ProxyHandler({})
2.客製化、建立一個opener
opener=urllib.request.build_opener(proxy_support)
3.安裝opener
urllib.request.install_opener(opener)
4.呼叫opener
opener.open(url)
用大量代理隨機請求目標網站,應對反爬蟲
import urllib request
import random
import re
url='http://www. whatismyip. com. tw '
iplist=['121.193.143.249:88',"112.126.65.193:88',122.96.59.184:82',115.29.98.139:9]
proxy_support = urllib. request Proxyhandler({'httP': random choice(iplist)})
opener = urllib.request.build_opener(proxy_suppor)
opener.addheaders=[(' User-Agent, ' Mozilla/5.0(X11; Linux x86-64) AppleWebkit/537.36'
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read().decode(' utf-8)
pattern = re.compile('<h1>(.*?)</h1>.*?<h2>(,*?)</h2>')
iterms=re.findall(pattern, html)
for item in iterms:
print(item[0]+:"+item[1])
(2)對於第二種情況,可以在每次請求後隨機間隔幾秒再進行下一次請求。有些有邏輯漏洞的網站,可以通過請求幾次,退出登入,重新登入,繼續請求來繞過同一賬號短時間內不能多次進行相同請求的限制。
[評論:對於賬戶做防爬限制,一般難以應對,隨機幾秒請求也往往可能被封,如果能有多個賬戶,切換使用,效果更佳]
3、動態頁面的反爬蟲
上述的幾種情況大多都是出現在靜態頁面,還有一部分網站,我們需要爬取的資料是通過ajax請求得到,或者通過Java生成的。
解決方案:Selenium+PhantomJS
Selenium:自動化web測試解決方案,完全模擬真實的瀏覽器環境,完全模擬基本上所有的使用者操作
PhantomJS :一個沒有圖形介面的瀏覽器
比如獲取淘寶的個人詳情地址:
from selenium import webdriver
import time
import re
drive = webdriver.PhantomJs(executable_path = ' phantomjs-21.1-linux-x86 64/bin/phanto drive.get('https://mm. taobaocom/self/modelinfohtm? userid=189942305& iscoment=fal)
time. sleep(5)
pattern = re.compile(r'<div. *? mm-p-domain-info>*? class="mm-p-info-cell clearfix">.
html = drive.page_source.encode(' utf-8,' ignore')
items=re.findall(pattern, html)
for item in items:
print(item[0], 'http':+item[1])
drive.close()
今天的反反爬攻略到這裡就結束了,你學到了嗎?


各位友友,我的網路硬碟資料是越堆越多了,尤其是Python的資料,我已經用不到了,現準備拿出來分享給每一個看我文章的人,有需要的話直接拿走。
需要的話可以加我微訊號pykf20(連結老是被F),全部免費拿走,備註一下"領資料",方便我知道你的來意和最快速度給你東西,細品下圖:

