搜尋引擎演算法大彙總
2020-07-16 10:05:15
接下來重點向大家介紹幾個演算法,包括TrustRank演算法、BadRank演算法、谷歌熊貓演算法、谷歌企鵝演算法、百度綠蘿演算法、百度石榴演算法等。
TrustRank 演算法
TrustRank 漢譯為“信任指數”,TrustRank 演算法是近年來比較受關注的基於連結關係的排名演算法,其目的是從網際網路中篩選出優質的網頁(品質較高的網頁)。TrustRank 演算法基於一個基本假設:品質好的網站基本不會去連結品質差的網站,反之則不成立。
也就是說,品質差的網站很少連結到品質好的網站這句話並不成立。恰恰相反,很多垃圾網站反而會想盡一切辦法連結到高權威、高信任指數的網站,試圖以此來提升自己網站的信任指數。
基於這個假設,如果能挑選出可以百分之百被信任的網站,那麼這些網站的 TrustRank 評分最高,而這些 TrustRank 評分最高的網站所連結的網站信任指數將會被稍微降低,但還是很高。同時,第二層被信任的網站所連結出去的第三層網站,信任程度將會繼續降低。
由於各種原因,品質高的網站難免會連結到一些垃圾網站,不過距第一層網站點選距離越近,所傳遞的信任指數就越高,其他網站的信任程度將依次降低,也就是說離第一層網站距離越遠,就越有可能被判定為垃圾網站。
BadRank 演算法
Badrank 演算法基於一個這樣的假設:如果該網頁與一個不可信任或有作弊行為的網頁之間存在連結關係,那麼該網頁也有可能存在作弊行為。與 TrustRank 演算法相反,BadRank 演算法的主要目的是從網際網路中篩選出品質低下的網頁。BadRank 演算法與 TrustRank 演算法的工作原理極其相似,首先是確定一批不可信任的網頁集合(網頁黑名單),再通過網頁與不可信任網頁間的連結關係及連結距離來計算網頁的不信任值,從而確定某個網頁是否為不可信任網頁。
谷歌 PageRank
PageRank 即網頁排名(又稱網頁級別,簡稱 PR,Google 左側排名或佩奇排名),是一種根據網頁之間相互的超連結計算的技術,Google 用它來體現網頁的相關性和重要性,也是我們在搜尋引擎優化操作中經常被用來評估網頁優化成效的因素之一。PageRank 是一種投票機制,通過網路浩瀚的超連結關係來確定一個頁面的等級,用於衡量特定網頁相對於搜尋引擎索引中其他網頁而言的重要程度。Google 把從 A 頁面到 B 頁面的連結解釋為 A 頁面給 B 頁面投票,Google 會根據投票的來源(甚至是來源的來源,即連結到 A 頁面的頁面)和投票目標的等級來決定新的等級。
簡單來說,一個高等級的頁面可以幫助提升其他低等級頁面的等級(這是我們需要交換友情連結及發布外部連結的原因)。
谷歌把 PageRank 的級別定義為 0~10,10 為滿分。PR 值越高說明該網頁越受歡迎。
例如一個網站 PR 值為1,表明這個網站不太具有流行度,而 PR 值為 7~10 則表明這個網站非常受歡迎(或者說極其重要)。一般 PR 值達到 4,就是一個不錯的網站了。
Google 把自己的網站的 PR 值定為 9,這說明 Google 網站是非常受歡迎的,也可以說這個網站非常重要。
谷歌 HillTop 演算法
HillTop 演算法的指導思想與 PageRank 是一致的,都是通過網頁被連結的數量和品質來確定搜尋結果的排序權重。但 HillTop 認為只計算來自具有相同主題的相關文件連結對於搜尋者的價值會更大,即主題相關網頁之間的連結對於權重計算的貢獻比主題不相關的連結價值要更高。比如,我們的網站是介紹“服裝”相關內容的,有 10 個連結都是從“服裝”相關的網站(如布料、布藝等)連結過來的,那麼這 10 個連結比另外 10 個從“機械”“化工”相關網站連結過來的貢獻要大。
HillTop 演算法實際上是拒絕了部分通過隨意交換連結的方法來擾亂 Google 排名規則而得到較好排名的做法。
谷歌熊貓演算法
谷歌熊貓(Panda)演算法是 Google 公司 2011 年推出的一種反垃圾網站的搜尋引擎演算法,旨在降低低品質內容的網站排名,同時是 Google 的網頁級別評判標準之一。我們可以簡單地將熊貓演算法理解為:反垃圾網站,降低低品質網站的排名。
谷歌熊貓演算法主要的判斷依據是點選流(Clickstream)、頁面內容(Page Content)和連結概況(Link Profiles),只要在這三者中表現優異,就不會被列為膚淺或劣質的網站。
從大量的分析來看,目前谷歌熊貓演算法的適用級別為網頁級別,並沒有細化到關鍵詞級別。同時一個網站內如果存在大量的低品質頁面,將會對整個網站的評級造成影響。
對於作為站長或者 SEOer 的我們而言,如何保障自己的網站不被熊貓演算法打擊呢?
1) 獲取信任
不要大量地複製貼上別人的內容,或者偽原創,儘量保證自己網站的內容品質,即網站內容原創,具有可讀性。2) 培養權威
不要妄想為自己的網站增加大量的外部連結,外連的發布需要循序漸進,並且需要保證連結的自然性。谷歌企鵝演算法
谷歌企鵝(Penguin)演算法於美國時間 2012 年 4 月 24 日推出,是谷歌繼 2011 年 2 月 24 日發布的“熊貓演算法”之後再次推出的新演算法。其目的是打擊那些通過過分 SEO 手段來提升排名的網站,意在降權那些充斥著廣告的網站。隨後,谷歌開始懲罰“過度優化”的網站,降低這些網站的排名,並鼓勵那些使用白帽技術的優化工程師。
對於這次谷歌針對過度優化的懲罰演算法,雖然對於外貿行業來說是一個打擊,但正是谷歌演算法的不斷完善,不斷淨化網際網路資訊,讓我們這些做白帽 SEO 的更有發展潛力,這也體現了谷歌的公平性。只要我們嚴格遵守搜尋引擎的演算法規則,不使用黑帽手法、不作弊、避免關鍵詞堆砌及不隨機插入不相關的連結等,我們一樣可以獲得很好的排名。
針對企鵝演算法,我們該如何應對呢?
1) 避免關鍵詞堆砌
在更新網站內容時不要刻意新增關鍵詞,保持自然,密度在 2%~8% 即可。2) 堅決不使用黑帽手段
如頁面偽裝、PR 劫持等。3) 避免重複內容
盡量多地提供原創內容,即便是微原創也一定要手動修改,這樣品質度更高,切不可借助工具進行內容的批次建立或偽原創。4) 避免垃圾連結
外連在質不在量,每天合理地新增高品質連結。谷歌貓頭鷹演算法
谷歌官方部落格於 2017 年 4 月 25 日發帖,宣布推出“貓頭鷹”演算法(Project Owl),提升權威度高的頁面的排名,降低低品質內容排名,尤其是查詢詞結果可能返回前面列出的幾種潛在問題內容時。“貓頭鷹”是谷歌內部的程式碼名稱,準確地翻譯應該是“貓頭鷹專案”,在 SEO 行業,稱為貓頭鷹演算法或貓頭鷹更新更容易理解。
貓頭鷹演算法的產生原因是谷歌搜尋面臨一類以前比較少見的問題,虛假新聞內容是源頭,進而帶來一系列相關問題,如編造的假新聞,帶有極度偏見、煽動仇恨的內容謠言,陰謀論類內容,冒犯性、誤導性內容等。
這類問題被使用者看到、搜尋得多了,就會影響搜尋方塊顯示的查詢詞建議,進一步帶來更多搜尋,一步步放大效應。
貓頭鷹演算法主要包括三方面內容:
1) 建議在搜尋方塊的右下角加上一個“舉報不當的聯想查詢”按鈕(如圖1所示),使用者看到宣揚仇恨的、色情的、暴力的、危險的內容時,可以舉報。
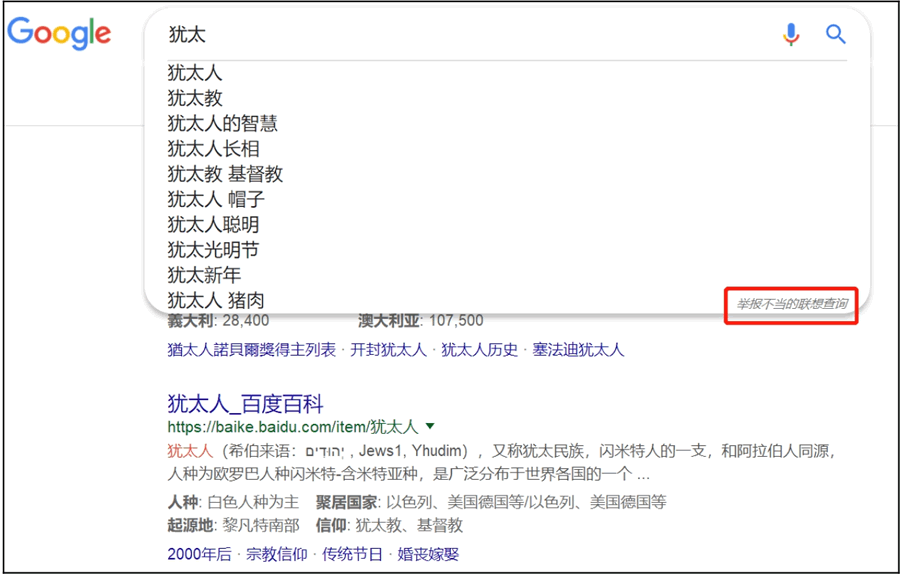
圖1:舉報不當的聯想查詢