搜尋引擎抓取網頁的流程
2020-07-16 10:05:14
搜尋引擎蜘蛛/機器人採集的力度直接決定了搜尋引擎前端檢索器可提供的資訊量及資訊覆蓋面,同時影響反饋給使用者檢索查詢資訊的品質。所以,搜尋引擎本身在不斷設法提高其資料採集/抓取及分析的能力。
本文將著重介紹搜尋引擎抓取頁面的流程及方式。
1. 頁面收錄/抓取流程
在整個網際網路中,URL 是每個頁面的入口地址,同時搜尋引擎蜘蛛程式也是通過 URL 來抓取網站頁面的,整個流程如圖1所示。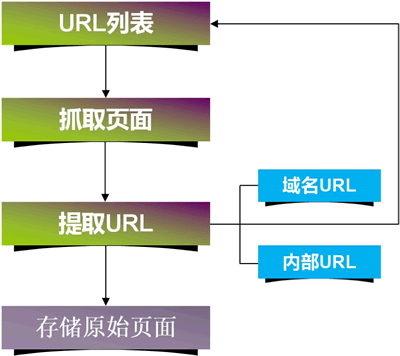
圖1:搜尋引擎抓取/收錄頁面的流程