機器學習是什麼?
2020-07-16 10:05:10
機器學習已經不僅僅只是一個未來幻想了,它已經存在了。事實上,在某些專門領域的應用中,例如光學字元識別(OCR),它甚至已經存在了幾十年。
但是,第一個真正成為主流並改善了億萬人民生活的機器學習應用,是 20 世紀 90 年代席捲了全世界的垃圾郵件過濾器。它不算是一個有自我意識的天網(Skynet),但從技術上來講,它確實有資格稱為一種機器學習(事實上它也學得很好,我們幾乎不需要再手動標記垃圾郵件了)。
隨後便是數以百計的機器學習應用,默默地為那些我們定期使用的產品和功能提供支援,從更好的推薦系統到語音搜尋。
什麼是機器學習
機器學習是一門能夠讓程式設計計算機從資料中學習的電腦科學(和藝術)。這裡有一個略微籠統的定義:
機器學習研究如何讓計算機不需要明確的程式也能具備學習能力。——Arthur Samuel,1959
還有一個更偏工程化的定義:一個計算機程式在完成任務 T 之後,獲得經驗 E,其表現效果為 P,如果任務 T 的效能表現,也就是用以衡量的 P,隨著 E 的增加而增加,可以稱其為學習。——Tom Mitchell,1997
舉例來說,垃圾郵件過濾器就是一個機器學習的程式,它通過垃圾郵件(比如使用者手動標記的垃圾郵件)以及常規郵件(非垃圾郵件)的範例,來學習標記垃圾郵件。系統用來學習的這些範例,我們稱之為訓練集。每一個訓練範例稱為訓練範例或者是訓練樣本。
在本例中,任務 T 就是給新郵件標記垃圾郵件,經驗 E 則是訓練資料,那麼衡量效能表現的指標 P 則需要我們來定義,例如,我們可以使用被正確分類的郵件的比率來衡量。這個特殊的效能衡量標準稱為精度,
經常用於衡量分類任務。
所以,如果你只是下載了維基百科的副本,你的電腦得到了更多的資料,這並不會給任何任務帶來提升。因此,它不是機器學習。
為什麼要使用機器學習
試想一下,如果讓你使用傳統程式設計技術來編寫一個垃圾郵件過濾器,你會怎麼做(如圖1)?1) 你會看看垃圾郵件通常長什麼樣。你可能會注意到某些單詞或用語(比如“4U”“信用卡”“免費”以及“神奇的”等字眼)在這類主題中出現的頻率非常高;也許你還會在發件人名稱和郵件的正文中發現一
些其他的模式。
2) 你會為你發現的每個模式編寫檢測演算法,如果檢測到一定數量的這類模式,你的程式會將其標記為垃圾郵件。
3) 你還要測試這個程式,不斷地重複過程1和過程2,直到它變得足夠好。
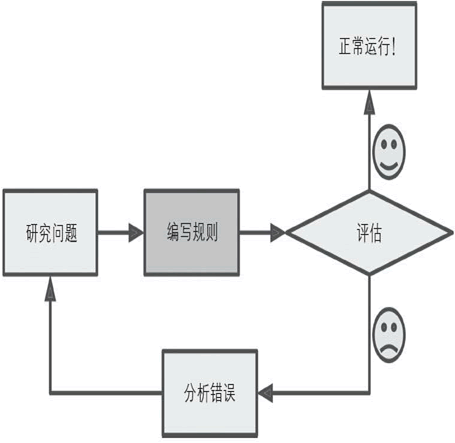
圖1:傳統程式設計方法