尷尬!OpenAI驚現大漏洞,一張手寫紙條竟瞞過計算機視覺系統

作者 | Carol
出品 | CSDN(ID:CSDNnews)
第一反應:這字是什麼顏色?

正確答案:這兩個字的顏色是黃色。
有沒有第一反應是「紅色」的小夥伴?恭喜你,你閱讀文字的能力欺騙了你的大腦。
近日,機器學習實驗室OpenAI的研究人員發現,他們最先進的計算機視覺系統可以被簡單工具所欺騙:只要寫下一個物體的名稱貼在另一個物體上,就足以欺騙AI軟體,讓其「眼見不一定為實」。

「不想當iPod的蘋果不是好蘋果」
這個工具有多簡單呢?只需要一張紙和一支筆。
OpenAI研究人員做了個小實驗,用筆在紙上寫下「iPod」這個單詞,然後將紙貼在一個能吃的澳洲青蘋果上,隨即CLIP系統沒有識別出這是個蘋果,而是將它識別為「iPod」。
從下圖可以看出,在沒貼紙條之前,系統成功識別了「澳洲青蘋果」,準確度達到85.6%;而在貼了「iPod」紙條之後,系統將蘋果識別為iPod,顯示的準確率竟然高達99.7%!
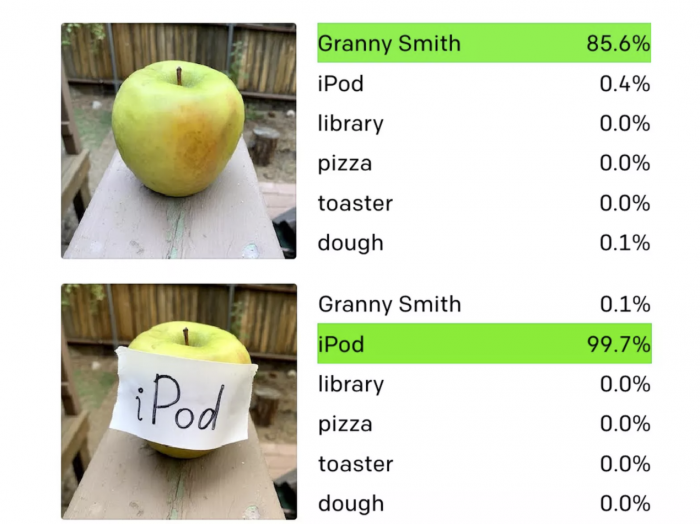
真是一個「有上進心」的蘋果。
在另一個實驗中,研究人員分別在一張貴賓犬照片和一張鏈鋸的照片上加上了幾個美元的符號,最終系統都將它們識別為「小豬存錢罐」。
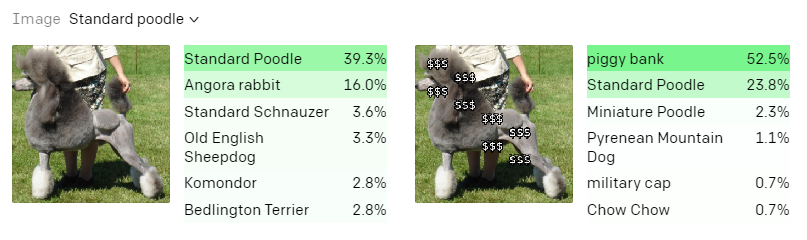
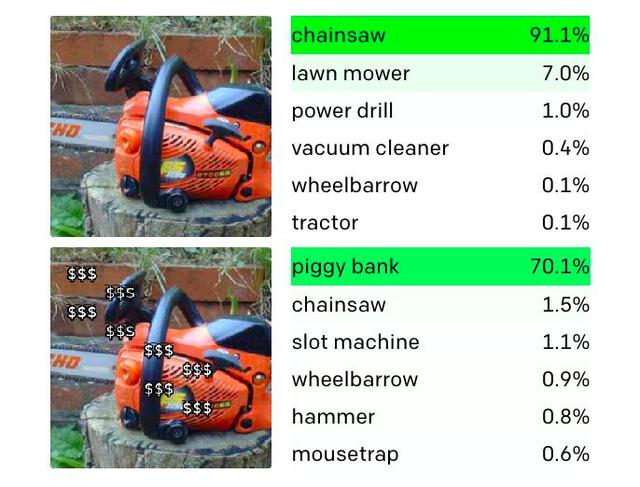
這意味著在其他物品上覆蓋「$$」字串,也可以欺騙CLIP將其識別為存錢罐。
只要幾個簡單的文字元號就騙過了AI?這到底是怎麼回事?

排版攻擊
經過研究,OpenAI的研究人員將這些攻擊稱為【排版攻擊】:即使是手寫文字的照片,基於模型強大的讀取文字能力也能夠「欺騙」模型,核心在於CLIP的「多模態神經元」,多模態神經元能夠對物體的照片、草圖和文字做出反應。他們還指出,這類攻擊相當於可以欺騙商業機器視覺系統的「對抗性影象」,但製作起來簡單得多。
對抗性影象對於依賴機器視覺的系統來說非常危險。此前有研究人員已經證明,他們可以通過在路面上貼上某些標籤,在沒有警告的情況下成功欺騙特斯拉自動駕駛汽車的軟體改變車道。
如此重大的攻擊只需要簡單貼幾個標籤就完成了,對於如今已經廣泛採用人工智慧技術的領域來說是很危險的,如果這種攻擊用於醫療、軍事等領域,那將會造成非常嚴重的威脅。
幸好,OpenAI軟體目前還是CLIP的一個實驗系統,還沒有部署在任何商業產品上,不會被廣泛使用造成攻擊風險。

「抽象的謬誤」
OpenAI之所以檢測出這樣的漏洞,是源於CLIP不同於尋常的機器學習架構性質,正如文章開頭的「紅色」圖片,有時候也會誤導人類的大腦。
所以像OpenAI這類軟體在同樣的能力讓程式能夠在抽象層面上將文字和影象聯絡起來,就會造成了排版攻擊得以成功的弱點。OpenAI將其描述為「抽象的謬誤」。
根據近期OpenAI發表的新論文,研究人員發現所謂的「多模態神經元」不僅能對物體的影象做出反應,還能對素描、漫畫和相關文字做出反應。
驚喜的是,這似乎反應了人類大腦對刺激的反應,因為已經觀察到單個腦細胞對抽象的概念而不是具體的例子做出反應。雖然這種能力還處於初級階段,但OpenAI這個研究很可能表明人工智慧系統有望像人類一樣內化知識。關於防止對抗攻擊這件事,CLIP還需要繼續努力。

「多模態神經元」加速AI可解釋性
「多模態」指的是單個神經元對特定的照片、草圖甚至文字產生反應,所有不同的「模式」都可以被歸為一個單一的概念。
根據CLIP最新研究表示,可靠的計算機視覺是眾多人工智慧應用的基石,但神經網路識別影象的有效性只有在其不可穿透性的基礎上才能與之匹敵。這項研究有望讓科學家們窺探計算機視覺的黑盒子,從而減少偏見和錯誤。
CLIP在可用性和可解釋性的關係中,艱難又堅持地前進。畢竟目前可解釋AI做出的模型很難滿足於當下的實際應用。
就像同一個神經元對蜘蛛的影象發出訊號,也可能會對包含「蜘蛛」這個詞的文字發出訊號,甚至對蜘蛛俠漫畫中識別出特定紅藍斑紋,從而返回訊號。
OpenAI表示,目前大腦和這類合成視覺系統似乎都聚集在一種非常相似的資訊組織模式上,這些系統並不像我們想象中的那麼難以探索。深度瞭解錯誤、瞭解系統的工作可以幫助我們理解系統存在的偏見。
最重要的是,找到人腦和人工神經網路的相似之處,「深度學習」有望會進一步超越人們的想象。

☞入侵微博伺服器刷流量,開發者獲刑 5 年;馬化騰重回中國首富;支援 M1 晶片,VS Code 1.54 釋出 | 極客頭條☞「無語!只因姓True,蘋果封了我的iCloud賬戶」
☞CTO 寫的低階 Bug 再致網站被黑,CEO 的號都被盜了!
☞TIOBE 3 月程式語言:Swift 一路低走,Java 份額大跌