論文筆記-Co-GAT: A Co-Interactive Graph Attention Network for Joint Dialog Act Recognition and Sentimen
2021-03-10 12:01:24
Co-GAT: A Co-Interactive Graph Attention Network for Joint Dialog Act Recognition and Sentiment Classification
動機
- where dialog act and sentiment can indicate the explicit and the implicit intentions separately. SC can detect the sentiments in utterances which can help to capture speakers’implicit intentions.

- 認為兩個資訊很重要,上下文資訊和互動資訊,之前的方法要麼考慮一個資訊,要麼是使用pipeline的形式,單獨建模。
Related Work
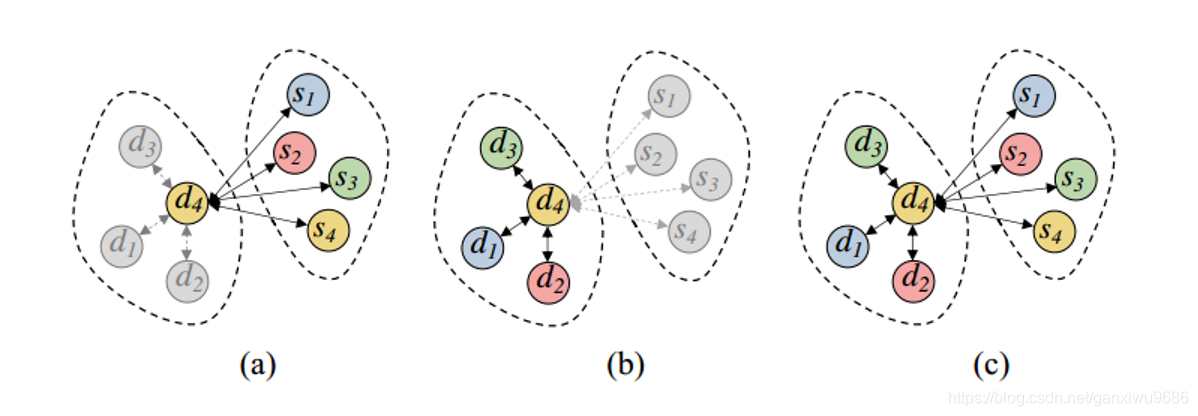
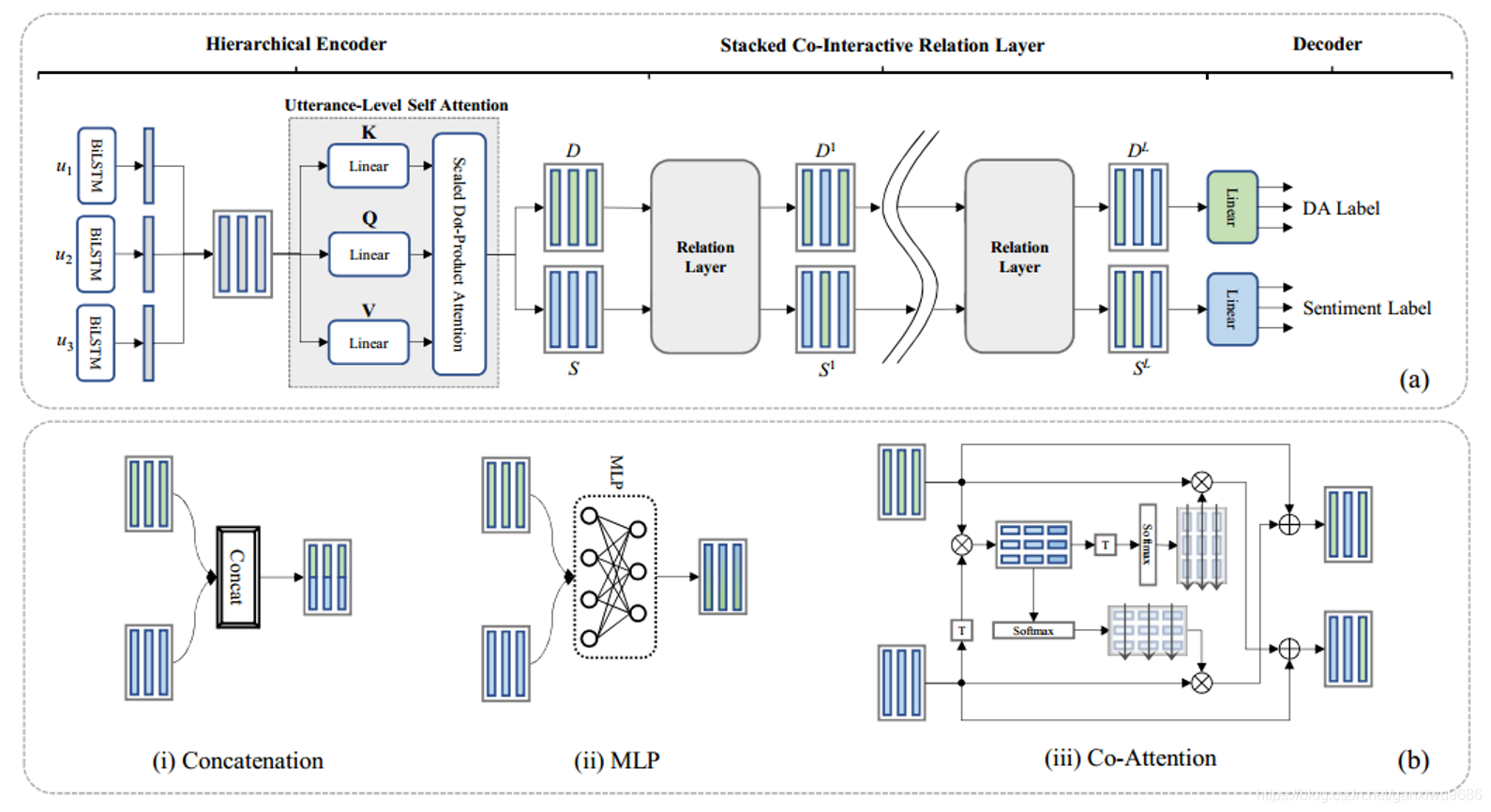
- 1、上圖a coling 2018:Multi-task dialog act and sentiment recognition on Mastodon
- We manually annotate both dialogues and sentiments on this corpus, and train a multi-task hierarchical recurrent network – joint learning
- can implicitly extract the shared mutual interaction information, but fail to effectively capture the contextual information
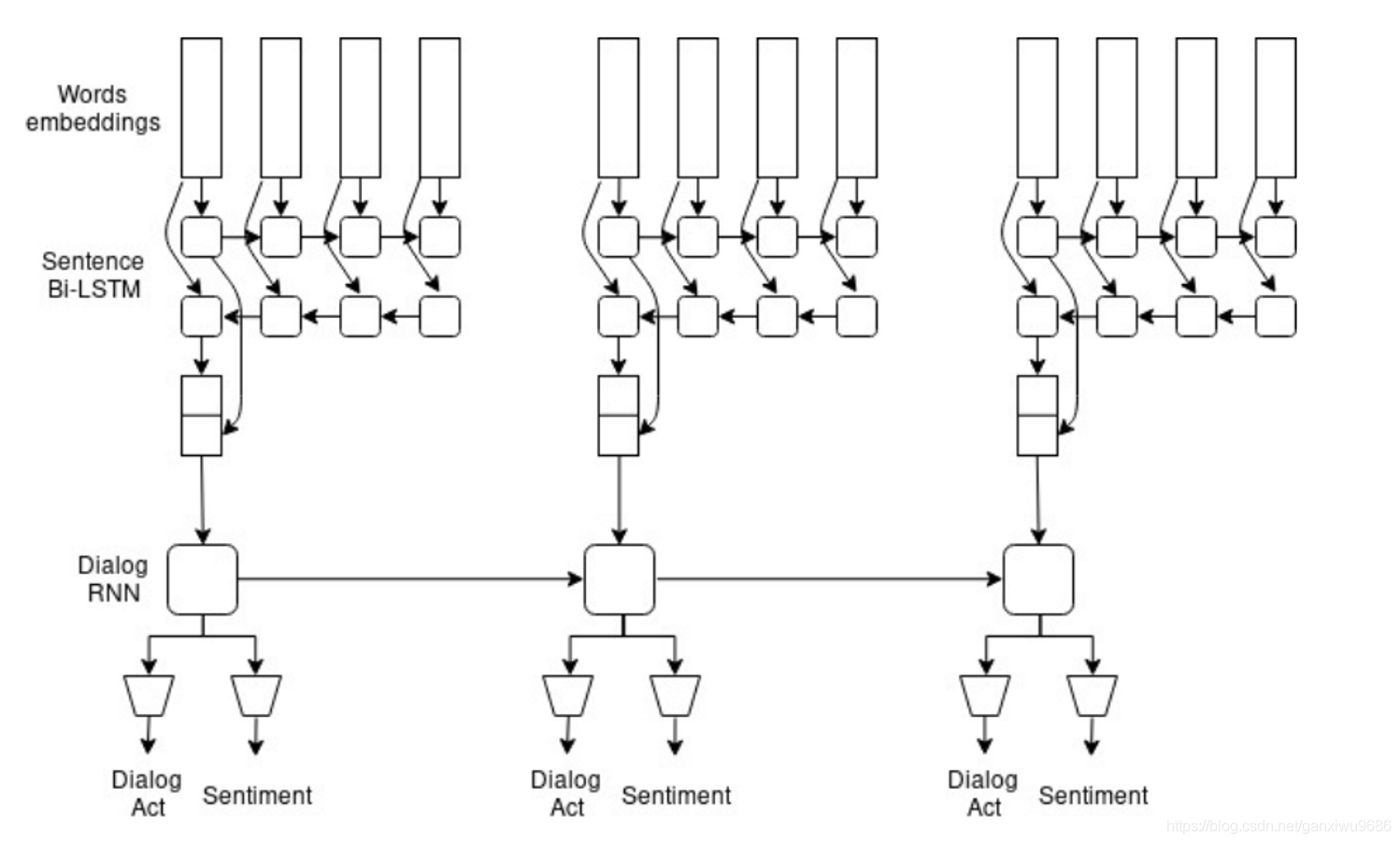
- 2、上圖b PR期刊,只考慮上下文的資訊 Integrated neural network model for identifying speech acts, predicators, and sentiments of dialogue utterances
- explicitly leverage the previous act information to guide the current DA prediction
- the model ignores the mutual interaction information
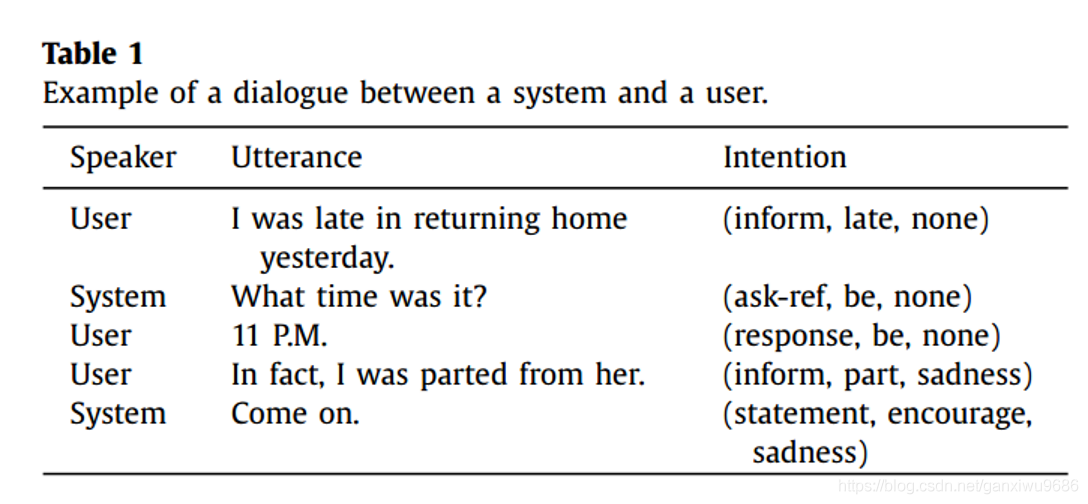
資料中的一個例子:
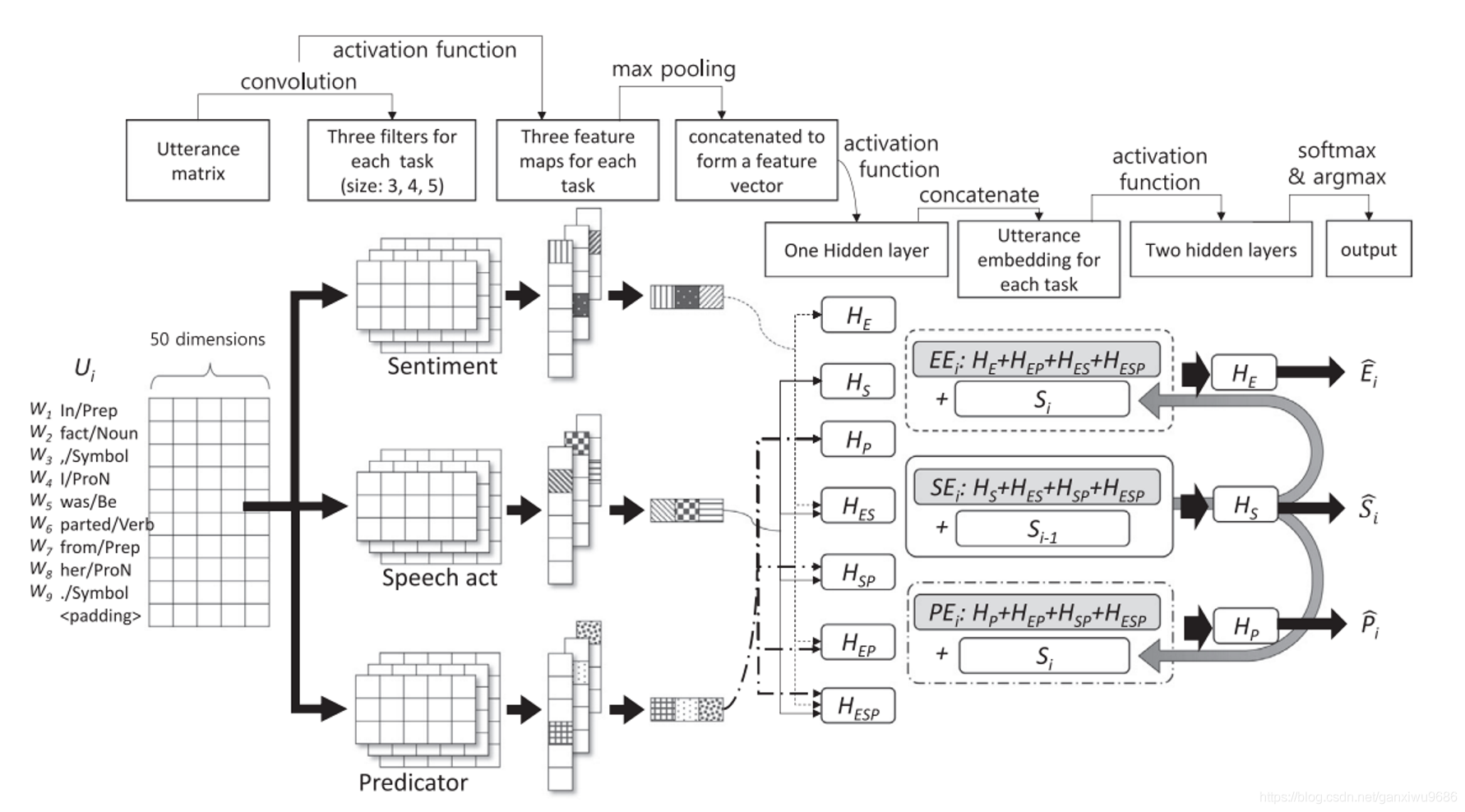
- 3、2020 AAAI DCR-Net
- capture the contextual information, followed then by a relation layer to consider the mutual interaction information.
- Pipeline way:two info model independently
Contributions
- first attempt to simultaneously incorporate contextual information and mutual interaction information
- propose a co-interactive graph attention network where a cross-tasks connection and cross-utterances connection
Method
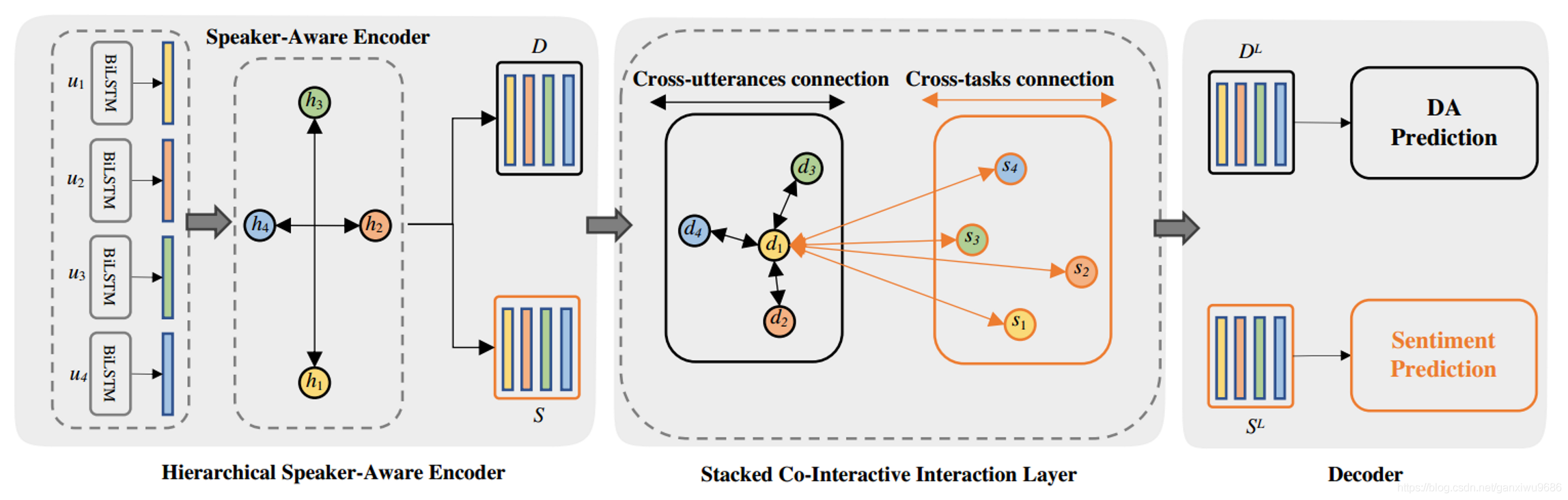
- Speaker-Level Encoder , 使用GNN考慮同一個說話的人的資訊。邊,如果是同一個人,為1
- Stacked Co-Interactive Graph Layer ,2N個結點,2N*2N條邊。
- Cross-utt info
- Cross-tasks info

Experiments
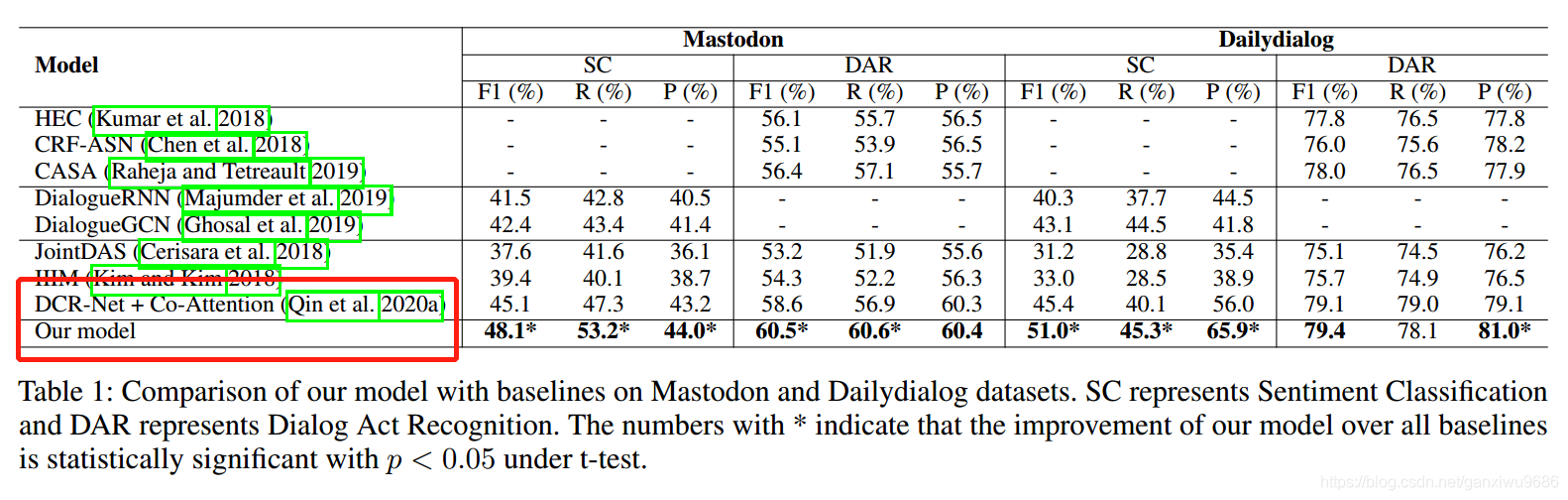
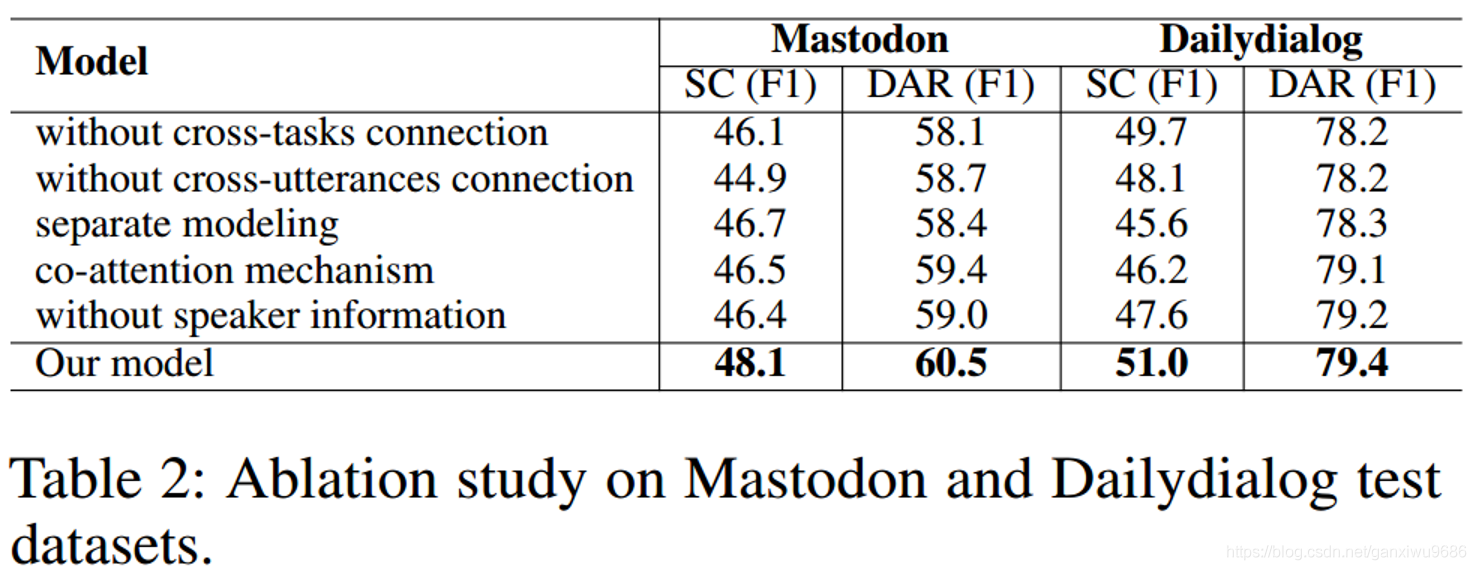
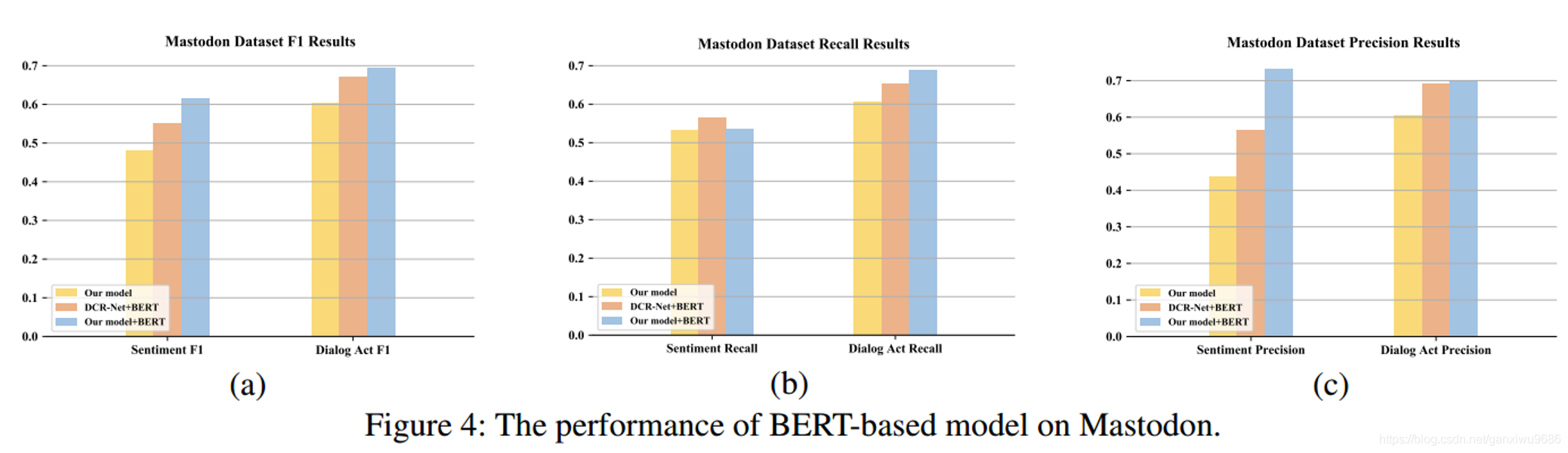
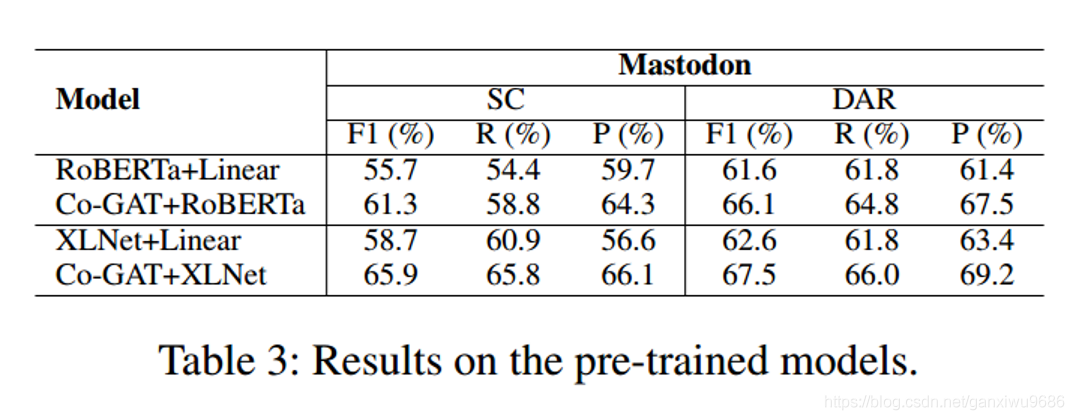
問題
- 本質上來說,該做法還是依賴資料中的某些規律。
- 跨任務圖的計算還是一種全連線的方式,有邊就是1,否則就是0;怎麼更好建模一階鄰居?