巨量資料6_04_Kafka架構原理
4 Kafka架構原理
4.1 Kafka工作流程及檔案儲存機制

Kafka中訊息是以topic進行分類的,生產者生產訊息,消費者消費訊息,都是面向topic的。
- topic是邏輯上的概念,partition是物理上的概念。每個partition對應一個log檔案,log檔案存放的是producer生產的資料。producer生產的資料會不斷的追加到log檔案末端,而且每一條資料都有自己的偏移量offset。
- 消費者組中的消費者,都會實時記錄自己消費到哪個offset,以便出錯恢復時,從上次位置繼續消費。
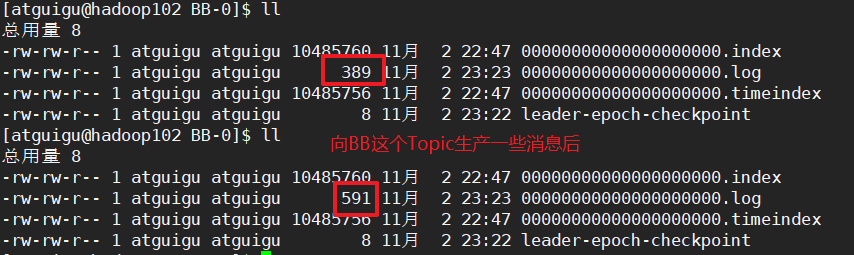
因為log檔案一直被追加,為了防止log存放資料的檔案太大,查詢效率太低。
Kafka採用①分片:log檔案每1G就分一個片
②索引機制:index檔案
00000000000000.log存放大量的資料,00000000000000.index存放大量的索引資訊。
4.2 Kafka生產者
①分割區策略
Kafka利用topic進行分類,然後每一個topic又進行分割區操作。
分割區的原則:將producer傳送的資料封裝成一個ProducerRecord物件(分3種情況)

(1)指明partition,直接將指明的值作為partition值。
(2)沒有指明partition值,但有key,將key的hash值與topic的partition數進行取餘得到partition的值。
(3)既沒有partition的值有沒有key,kafka採用Sticky Partition(黏性分割區器),會隨機選擇一個分割區,並儘可能一直使用該分割區,待該分割區的batch已滿或者已完成,kafka再隨機一個分割區進行使用。
②資料可靠性保證
生產者傳送資料到topic partition的資料可靠性保證:
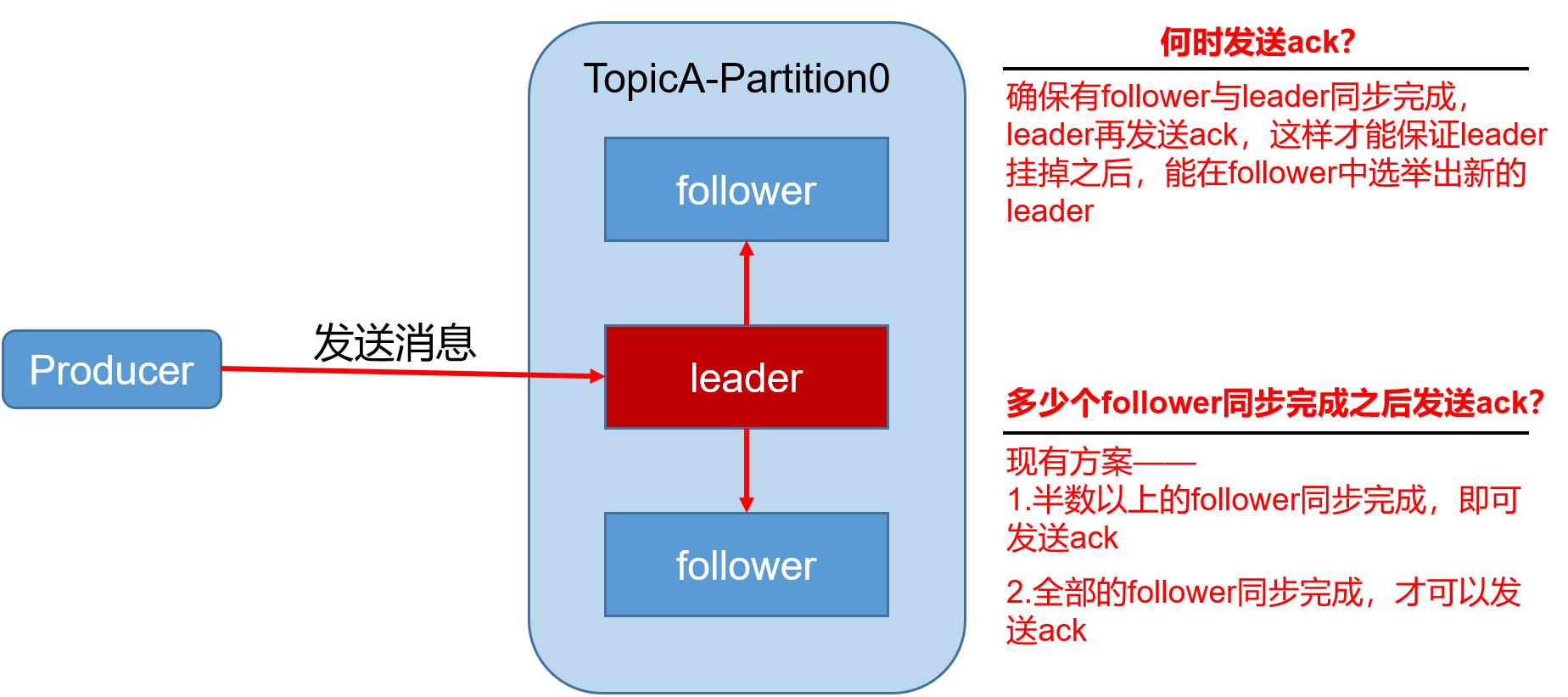
ACK應答策略
producer產生的訊息傳送給每個topic的partition(其實只發給了leader),每個partition收到訊息後會傳送一個ack(acknowledgement確認收到)
- 如果producer收到了ack,就進行下一輪傳送(!!!kafka是非同步傳送,不用收到ack就可以直接傳送)
- 如果producer沒有收到ack,就重新傳送
ack應答級別
預設ack=1
0 : 最低的延遲,leader接收到還沒寫入磁碟就返回ack;leader故障時可能丟資料
1 : leader寫完後返回ack,不等待follower寫完;follower同步成功之前leader故障肯能會丟資料
-1 : leader和ISO內的所有的follower寫完後,才返回ack;broker返回給producer時,leader故障,可能會資料重複
ISR同步副本策略
Kafka採用了ISR同步副本的策略進行同步副本。
Leader維護了一個動態的ISR(in-sync replica set),只要follower和leader的通訊時間夠快,就能進入到ISR集合中。時間閾值由replica.lag.time.max.ms引數設定。只同步ISR內所有的follower。
誰可以進入到ISR這個集合?之前的版本中:
- 通訊時間夠快(follower和leader互動快)預設10s
- 訊息條數,follower和leader同步的資料差距小的。(差距在10條內的進來,大於10條剔除)
新版本0.9取消了訊息的條數,為什麼去除呢?
如果一次batch傳送了11條給leader,此時全部的follower全部超過10條,全部剔除。同步很快,很快又小於10條,又全部拉回了ISR集合,這個傳送頻繁後,不僅消耗資源還增大ZK壓力。
leader和follower故障處理
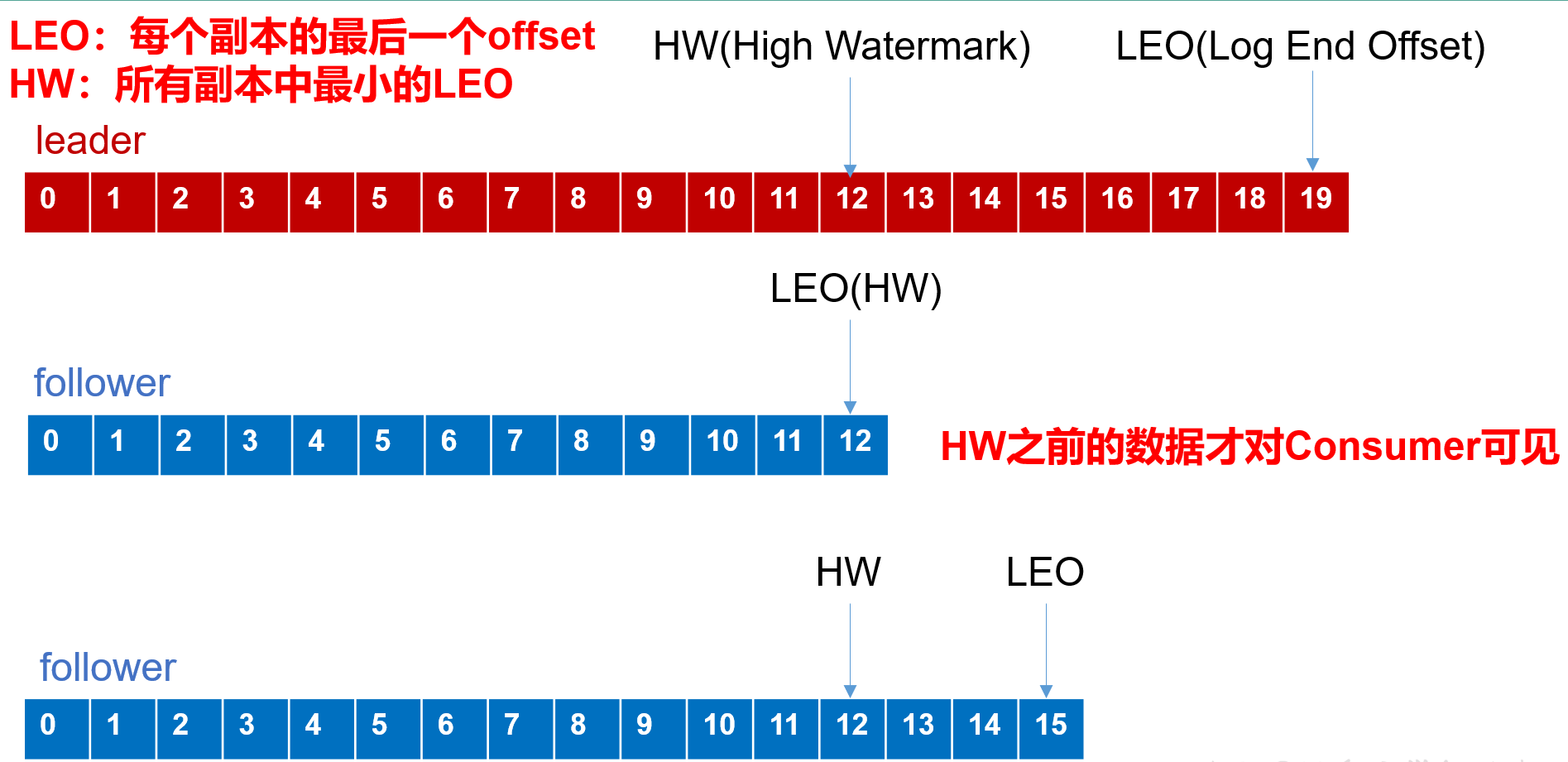
LEO:指的是每個副本最大的offset;
HW:指的是消費者能見到的最大的offset,ISR佇列中最小的LEO。
(1)follower故障
follower發生故障後會被臨時踢出ISR,待該follower恢復後,follower會讀取本地磁碟記錄的上次的HW,並將log檔案高於HW的部分擷取掉,從HW開始向leader進行同步。等該follower的LEO大於等於該Partition的HW,即follower追上leader之後,就可以重新加入ISR了。
(2)leader故障
leader發生故障之後,會從ISR中選出一個新的leader,之後,為保證多個副本之間的資料一致性,其餘的follower會先將各自的log檔案高於HW的部分截掉,然後從新的leader同步資料。
HW
消費者最大可見LEO=HW,作用(1)保證了消費者消費資料的一致性。
參差不齊的LEO,選出的leader會通知其他的follower,比leader高就截去,低就同步。作用(2)保證了資料儲存的一致性。
只能保證資料的一致性,但是不能保證是否有資料丟失或重複(ack應答級別的事)
③Exactly One語意
-
At Least Once語意:ACK級別設定為-1
-
At Most Once語意:ACK級別設定為0
-
Exactly Once:At Least Once + 冪等性
at least once的ack為-1,leader和ISR內的所有follower都同步完,再傳送ack,但是broker傳送ack給producer的時候,如果leader出錯誤了,producer會重發。這個時候回出現重複資料。
at most once的ack為0,不管leader和follower是否同步完,就返回ack,這個時候leader掛掉,會丟失資料。
在at least once的基礎上引入冪等性,在producer傳送資料時,就算重發了資料,也會只持久化一條相同資料。
開啟冪等性是在Producer初始化的時候分配一個PID,發往Partition的訊息會附帶一個Sequence Number。而在Broker端會對<PID, Partition, SeqNumber>做快取,當具有相同主鍵的訊息提交時,Broker只會持久化一條。
但是PID重新啟動就會變化,同時不同的Partition也具有不同的主鍵,所以冪等性不能跨分割區、不能跨對談。
# 開啟冪等性
enable.idempotence=true
4.3 Kafka消費者
kafka消費者採用pull拉取的方式從broder讀取資料。
push(推模式)缺點:很難適應消費速率不同的消費者,因為訊息傳送速率是由broker決定的。
pull模式缺點:如果kafka沒有資料,消費者可能會陷入迴圈中,一直返回空資料。
①分割區分配策略
有兩種:RoundRobin和Range兩種策略。
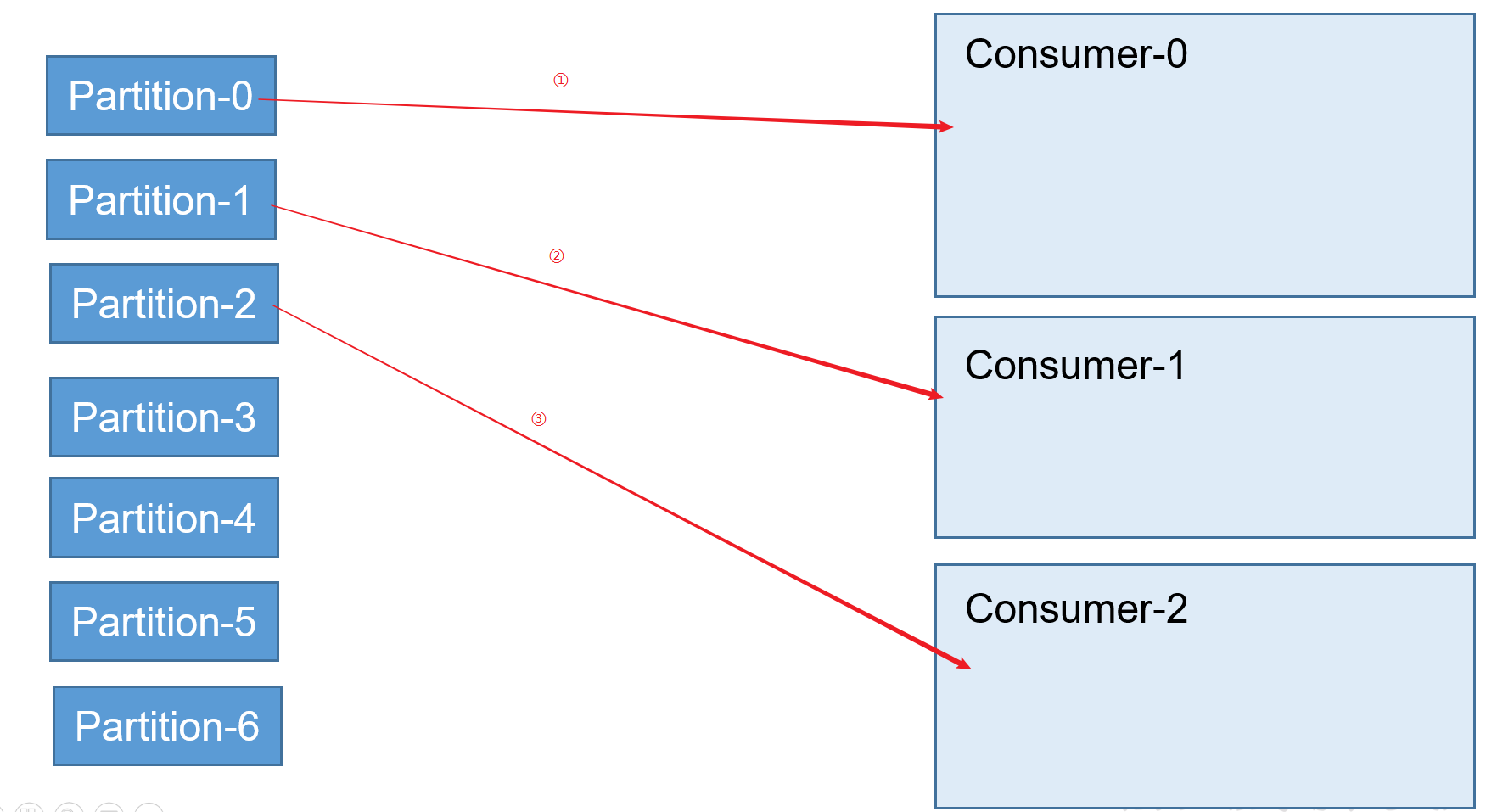
RoundRobin策略
根據組去劃分。將某一個Topic的不同分割區,封裝成多個物件,通過比較物件的hash值排序,輪詢的方式,分給不同的消費者。
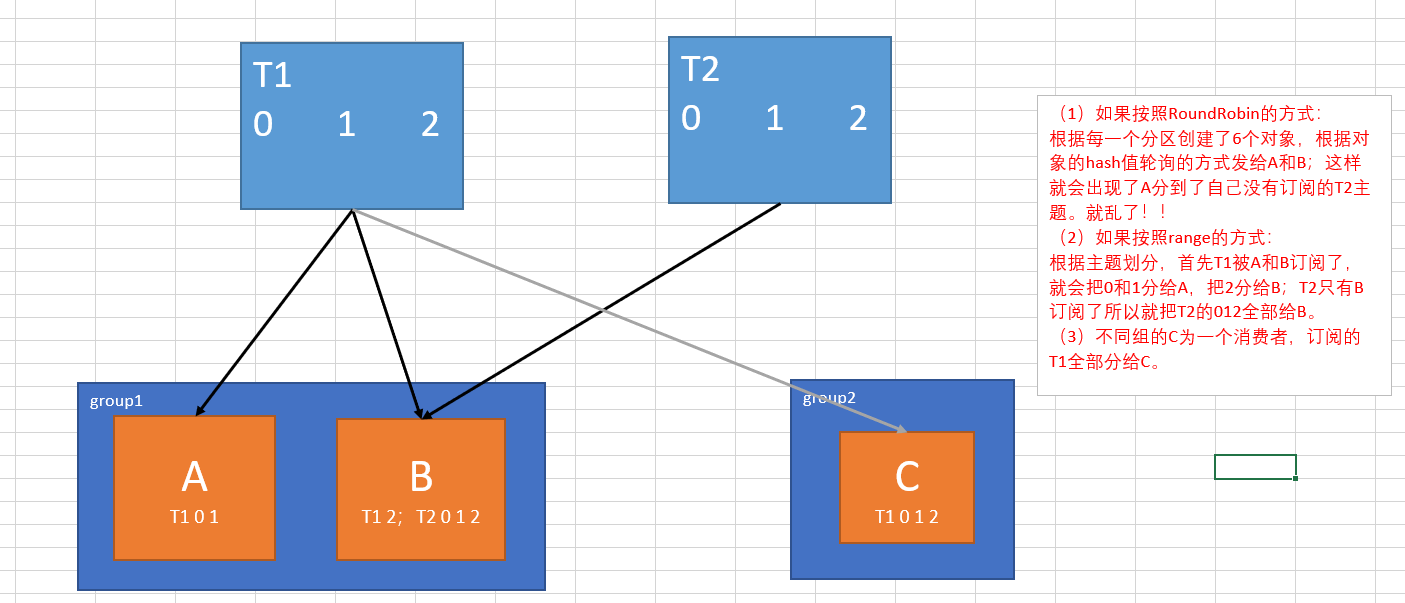
Range策略(系統預設)
根據主題劃分。將某一個Topic的不同分割區,根據分割區數/消費者數,將餘數給第一個消費者,模數給其他的消費者。
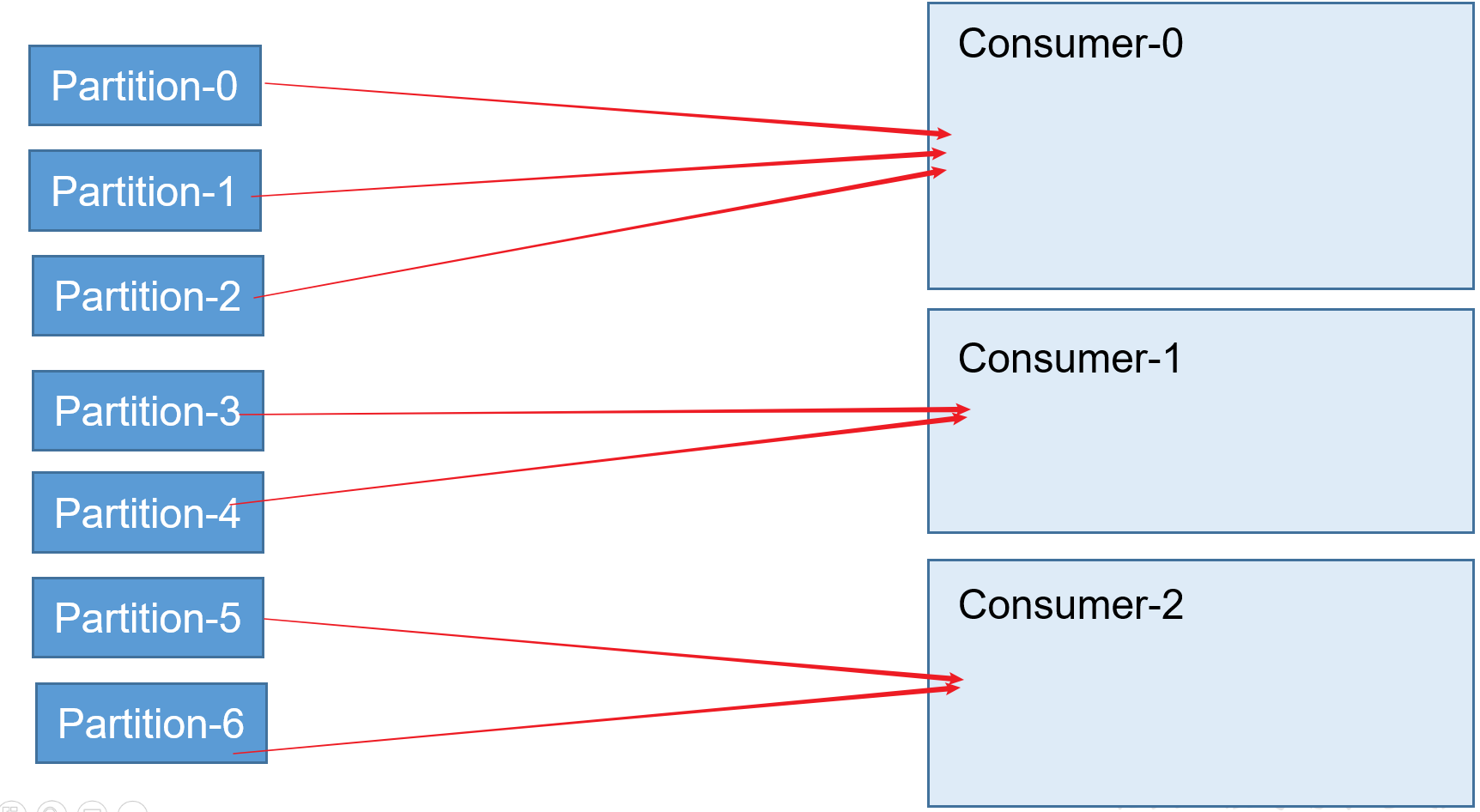
消費者組訂閱不同的Topic呢?
- RoundRobin:如果一個消費者組內的不同消費者訂閱了不同的Topic,還按照輪詢的方式分配給不同的消費者,會出現A訂閱了B的Topic,這樣就亂了!!!
- 所以如果RoundRobin策略下的消費者組內的不同消費者向訂閱多個Tiopic,就必須組內的所有消費者訂閱相同的多個Topic!!!
- Range:Range策略下,就能夠解決上面的訂閱亂了的現象!
② offset的維護
因為消費者在消費的過程中,有可能出現斷電宕機等故障,consumer恢復後,應該從故障前的位置繼續消費,所以consumer需要實時記錄自己消費到哪個offset。
-
在0.9版本之前,consumer預設將offset儲存在zookeeper中,從0.9版本開始consumer預設將offset儲存在Kafka一個內建的topic中,該topic為__consumer_offsets
-
本地中:按照GTP(groupid,topic,partition)就能確定唯一一個offset
思想: __consumer_offsets 為kafka中的topic, 那就可以通過消費者進行消費
那麼當前這個消費者組消費的資訊在哪個分割區儲存著呢?
系統50個分割區根據GTP的hash值取選擇存到這50個分割區中的某一箇中。
步驟1:修改consumer.properties
可以讓普通的消費者消費系統的topic,不改為false的話,系統的topic無法消費。
# 不排除內部的topic
exclude.internal.topics=false
步驟2:建立一個topic
[atguigu@hadoop102 config]$ kafka-topics.sh --zookeeper hadoop102:2181 --create --topic WEI --partitions 2 --replication-factor 2
步驟3:啟動生產者和消費者,分別向WEI這個topic生產資料和消費資料
[atguigu@hadoop102 ~]$ kafka-console-producer.sh --broker-list hadoop102:9092 --topic WEI
[atguigu@hadoop102 ~]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic WEI --from-beginning
步驟4:消費系統的topic(offset)
[atguigu@hadoop102 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
步驟5:收到的資料
[test-consumer-group,atguigu,1]::OffsetAndMetadata(offset=2, leaderEpoch=Optional[0],
metadata=, commitTimestamp=1591935656078, expireTimestamp=None)
[test-consumer-group,atguigu,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional[0], metadata=, commitTimestamp=1591935656078, expireTimestamp=None)
③消費者組案例
測試同一個消費者組中的消費者,同一時刻只能有一個消費者消費
步驟1:在hadoop102,hadoop103上修改/opt/module/kafka/config/consumer.properties組態檔中的group.id屬性為任意組名。
[atguigu@hadoop102 config]$ vim consumer.properties
group.id=mygroup
步驟2:在hadoop104上啟動生產者
[atguigu@hadoop104 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
步驟3:在hadoop102、hadoop103上分別啟動消費者
因為設定了consumer.properties內的groupid,所以需要指定當前的消費者是哪個組的。如果不指定,會隨機生成一個id,也就是自己是一個組。
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh bootstrap-server hadoop102:9092 --topic first --consumer.config config/consumer.properties
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --consumer.config config/consumer.properties
步驟4:檢視hadoop102和hadoop103的消費者的消費情況。
4.4 Kafka高效讀寫資料
①順序寫磁碟
②應用Pagecache
③零複製技術
直接由作業系統操作拷貝檔案。
**④分散式(分割區)**並行讀寫
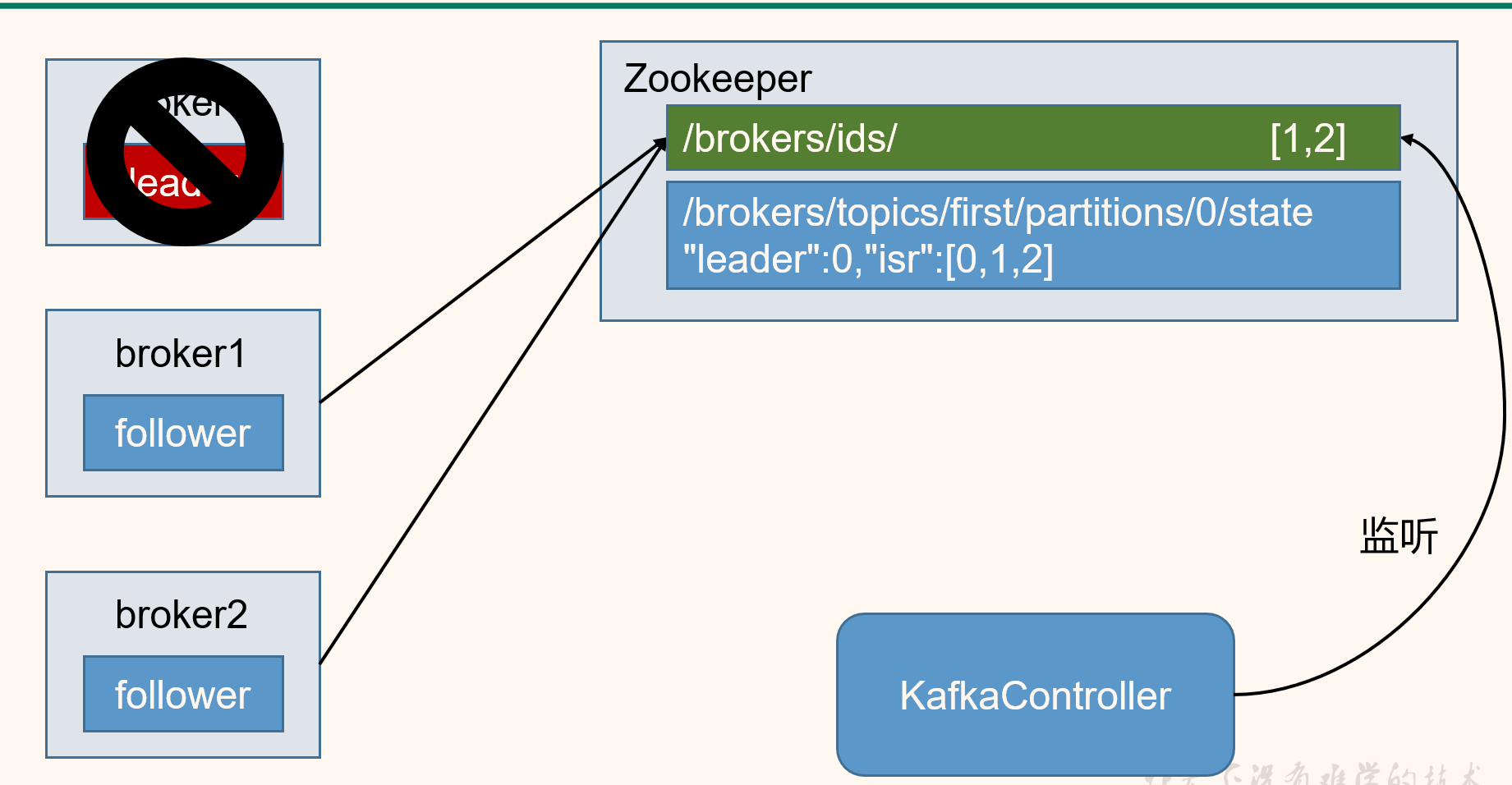
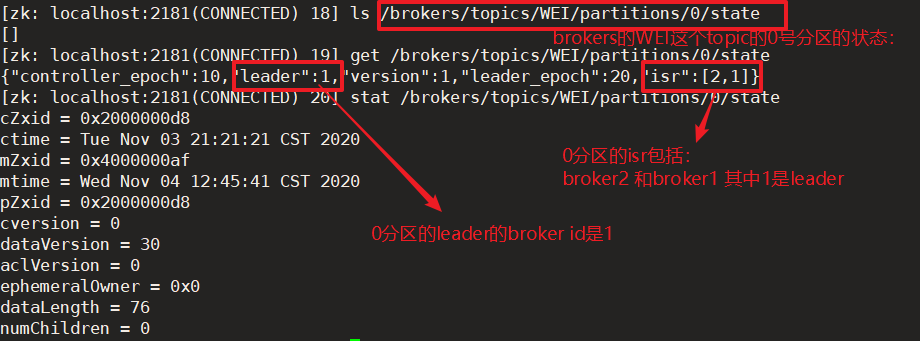
4.5 Zookeeper在Kafka中的作用
①後設資料儲存
zookeeper在kafka中的第一個作用就是,後設資料的儲存。
- Kafka的brokers資訊,包含了叢集id、topic等資訊。
- cluster叢集後設資料資訊。
- config組態檔資訊。
- controller叢集的老大,一般是broker0。
- 0.9版本的consumer的offset等資訊也儲存在zookeeper。如:/consumers/ [消費者組A,…]現在沒有

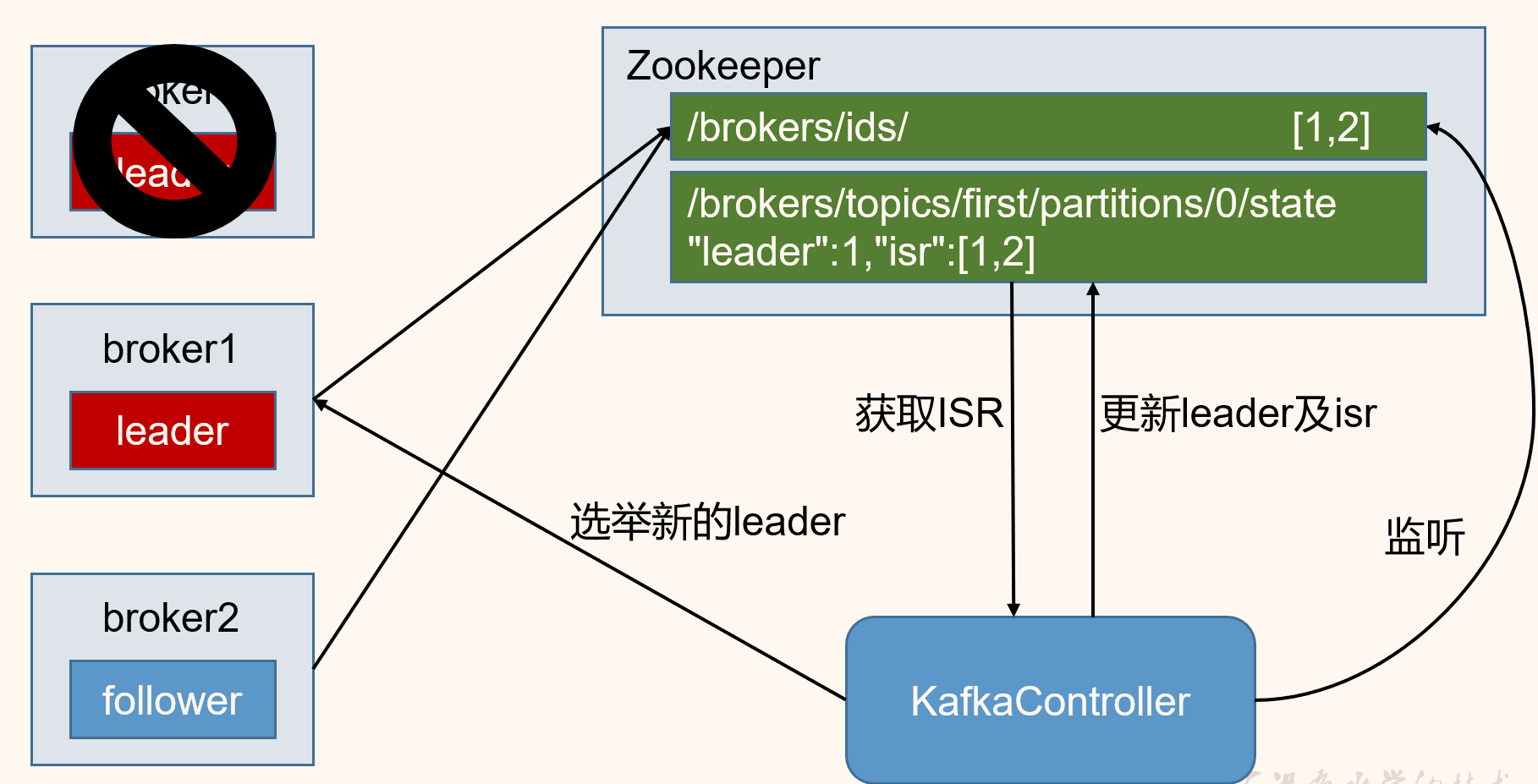
②Controller管理
zookeeper的第二個作用就是,為controller管理broker,所有分割區副本的分配和leader選舉提供支援。
- Controller的選舉機制是競爭資源,哪個broker搶到資源誰就是Controller。Controller負責管理叢集broker的上下線,分割區副本分配、leader的選舉。
- leader是怎樣選舉的呢?
第一次選leader是隨機的,之後如果leader掛掉了,那麼此後是輪詢的方式,選擇下一個作為leader。
4.6 Kafka事務
0.11版本引入事務。
- kafka的冪等性生產和消費不能夠跨分割區和對談;引入kafka事務後在Exactly Once語意的基礎上,生產和消費可以跨分割區和對談,要麼全部成功要麼全部失敗。
①Producer事務
Producer事務保證了精準一次性寫入
因為冪等性只能在當前對談和當前分割區有效,所以需要一個全域性唯一的Transaction ID,並將Producer獲得的PID和Transaction ID繫結。這樣當Producer重新啟動後就可以通過正在進行的Transaction ID找到原來的PID。
為了管理Transaction,kafka引入一個新的元件Transaction Coordinator 。Producer就是通過和Transaction Coordinator互動獲得Transaction ID對應的任務狀態。Transaction Coordinator還負責將事務所有寫入Kafka的一個內部Topic,這樣即使整個服務重新啟動,由於事務狀態得到儲存,進行中的事務狀態可以得到恢復,從而繼續進行。
②Consumer事務
Consumer事務解決的是精準一次性消費的問題。
消費者消費了訊息,但是沒有將offset更新,這個時候消費者掛掉了,再次消費的時候就會重複消費。