2020年Python最新面試題(二):Python基礎
目錄
1. 上期真題答案
- 「1 or 2」、「1 and 2」、「1 < (2==2)」、「1 < 2==2」 分別輸出什麼? 1 2 False True
- 以下程式碼的執行結果是什麼? 「A」
value = "B" and "A" or "C"
print(value)
- 用4、9、2、7 四個數位,可以使用+、-、*、和/,每個數位使用一次,使表示式的結果為24,表示式是什麼? ==> (9+7-4)*2
- any()和all()方法有什麼區別? any()只要迭代器中有一個元素為真就為真,all()要求迭代器中所有的判斷項返回都是真,結果才為真。
- Python 中有什麼元素為假? 0 空字串、空列表、空字典、空元組、None、False都表示假。
- 在 Python 中是否有三元運運算元 「?:」 ? 沒有 min = a if a<b else b
- 如何宣告多個變數並賦值? a,b,c=3,4,5 a=b=c=3
- 以下程式是否會報錯 V3會報錯,因為字典元素的鍵不能為可變物件
v1 = {}
v2 = {3:5}
v3 = {[11,23]:5}
v4 = {(11,23):5}
- a = (1,),b = (1),c = (「1」) 分別是什麼型別的資料? a 為元組,b為整型,c為字串,可以使用type函數來驗證。
- 使用 for 迴圈分別遍歷列表、元組、字典和集合。(簡單)
- 99的八進位製表示是多少。print(oct(99)) ==> 0o143
- 請寫出十進位制轉二進位制、八進位制、十六進位制的程式。
# 獲取輸入十進位制數 dec = int(input("輸入數位: ")) print("十進位制為: ", dec) print("轉換為二進位制為: ", bin(dec)) print("轉換為八進位製為: ", oct(dec)) print("轉換為十進位制為: ", hex(dec))
2. 如何刪除一個列表(list)中的重複元素
刪除列表中重複的元素有多種方式,下面介紹五種刪除的方法。
方法一:使用集合 (set) 的方式
elements = ["a", "a", "b", "c", "c", "b", "d"]
e = list(set(elements))
print(e)
這種方法利用 set 中的元素不可重複的特性去重。除此之外,如果要保持列表元素的原來順序,那麼可以利用 list 類的 sort 方法:
elements = ["a", "a", "b", "c", "c", "b", "d"]
e = list(set(elements))
e.sort(key=elements.index)
print(e) # ['a', 'b', 'c', 'd']
方法二:使用字典的方式,利用字典 key 的唯一性
# 使用字典的方式,利用字典 key 的唯一性
elements = ["a", "a", "b", "c", "c", "b", "d"]
# e = list({}.fromkeys(elements))
e = list({}.fromkeys(elements).keys())
print(e) # ['a', 'b', 'c', 'd']
這種方法利用字典的鍵值不能重複的特性來去重。其中,Python 函數 dict.fromkeys(seq[.value]) 用於建立一個新字典,以序列 seq 中元素做字典的值,value 為字典所有鍵對應的初始值,如下所示:
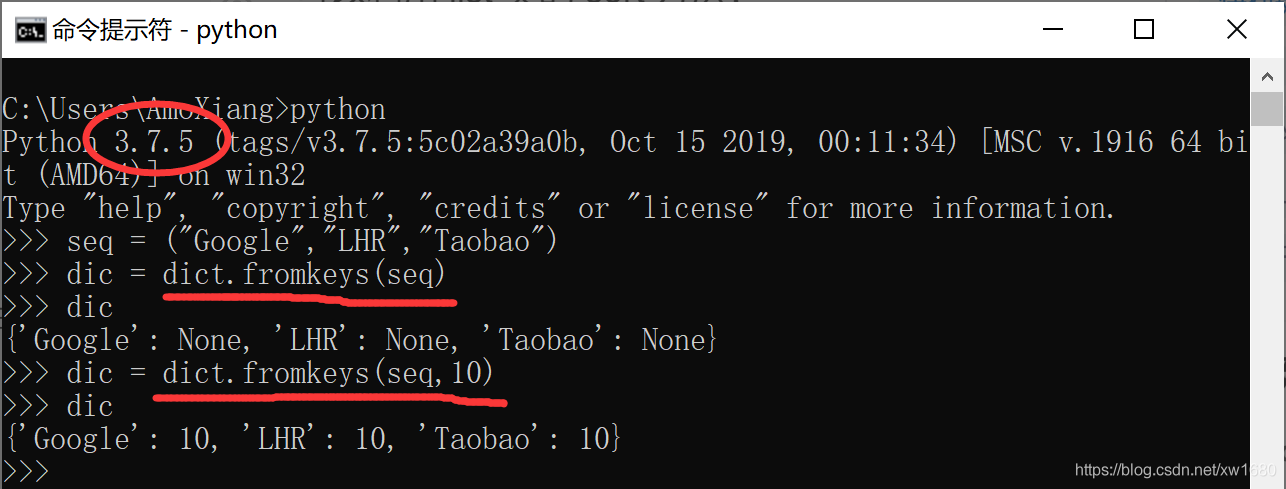
方法三:列表推導的方式
elements = ["a", "a", "b", "c", "c", "b", "d"]
e = []
for i in elements:
if i not in e:
e.append(i)
print(e)
方法四:count計數
elements = ["a", "a", "b", "c", "c", "b", "d"]
n = 0
while n < len(elements):
if elements.count(elements[n]) > 1:
elements.remove(elements[n])
continue
n += 1
print(elements) # ['a', 'c', 'b', 'd']
方法五:reduce 函數
from functools import reduce
elements = ["a", "a", "b", "c", "c", "b", "d"]
v = reduce(lambda x, y: x if y in x else x + [y], [[]] + elements)
print(v) # ['a', 'b', 'c', 'd']
3. 如何求兩個列表(list)的交集、差集或並集?
求兩個列表(list)的交集、差集或並集,最容易想到的方法就是用 for 迴圈來實現,如下所示:
a = [1, 2, 3, 4, 5]
b = [2, 4, 5, 6, 7]
# 交集
result = [r for r in a if r in b]
print(f"a與b的交集: {result}") # a與b的交集: [2, 4, 5]
# 差集 在a中但不在b中
result = [r for r in a if r not in b]
print(f"a與b的差集: {result}") # a與b的差集: [1, 3]
# 並集
result = a
for r in b:
if r not in result:
result.append(r)
print(f"a與b的並集: {result}") # a與b的並集: [1, 2, 3, 4, 5, 6, 7]
方法二:用 set 操作
a = [1, 2, 3, 4, 5]
b = [2, 4, 5, 6, 7]
# 交集
result = list(set(a).intersection(set(b)))
print(f"a與b的交集: ", result) # a與b的交集: [2, 4, 5]
# 差集 在a中但不在b中
result = list(set(a).difference(set(b)))
print(f"a與b的差集: ", result) # a與b的差集: [1, 3]
# 並集
result = list(set(a).union(set(b)))
print(f"a與b的並集: ", result) # a與b的並集: [1, 2, 3, 4, 5, 6, 7]
4. 如何反序地迭代一個序列?
Python 中常見的序列有字串、列表及元組。對序列反序,可以利用內建函數 reversed() 或 range() 來實現,也可以用擴充套件切片 [::-1] 的形式實現。如果這個序列是列表,那麼還可以使用列表自帶的 reverse()方法。
(1) reversed() 是 Python 內建的函數,它的引數可以是字串、列表或元組等序列。
(2) 利用 range() 方法生成序列的反序索引,然後從最後的元素遍歷到開始的元素,就可以反序輸出序列的元素。range(start, end[,step]) 方法的引數說明:
start:計數從 start 開始。預設是從 0開始。
end:計數到 end 結束,但不包括 end。
step:步長,預設為 1。
(3) seq[::-1] 擴充套件切片方法是利用了序列的切片操作,切片是序列的高階特性。seq[::-1] 表示反向獲取 seq 中的所有元素,並且每次取一個。-1 表示從序列的最後一個元素反向遍歷獲取。
(4) 如果是列表(list) 序列,那麼還可以直接用列表的 reverse() 方法。範例程式碼如下:
seq = "Hello World"
# reversed()內建函數方法
for s in reversed(seq):
print(s, end="")
print() # 換行
# range()函數方法
for i in range(len(seq) - 1, -1, -1):
s = seq[i]
print(s, end="")
print()
# [::-1]擴充套件切片方法
for s in seq[::-1]:
print(s, end="")
print()
# list 自帶的 reverse()方法
seq = [1, 2, 3, 4, 5, 6]
seq.reverse()
for s in seq:
print(s, end="")
print()
5. 列表的sort方法和sorted方法有何區別?
Python 對列表的排序提供了兩種方法,一種是自帶的 sort(),另一種方法是內建方法 sorted。可以用內建函數 help() 來檢視 sort()方法 和 sorted()方法的詳細說明。
列表的 sort 方法和內建方法 sorted 都有 key 和 reverse 引數, key 引數接收一個函教來實現自定義的排序,例如key=abs 按絕對值大小排序。reverse 預設值是False,表示不需要反向排序,如果需要反向排序,那麼可以將 reverse 的值設定為 True
sort 是列表方法,只可用來對列表進行排序,是在原序列上進行修改,不會產生新的序列。內建的 sorted 方法可以用於任何可迭代的物件 (字串、列表、元組、字典等),它會產生一個新的序列,舊的物件依然存在。如果不需要舊的列表序列,那麼可以採用 sort 方法。
# list的sort()方法對列表排序
seq = [1, 3, 5, 4, 2, 6]
print("原來的序列: ", seq)
seq.sort()
print("sort 排序後的序列: ", seq)
# 內建 sorted()方法對列表排序
seq = [1, 3, 5, 4, 2, 6]
s = sorted(seq)
print("原來的序列: ", seq)
print("sort 排序後的序列: ", seq)
print("sort 排序後的新序列: ", s)
# 內建sorted()方法對字串排序
seq = "135426"
s = sorted(seq)
print("原來的序列: ", seq)
print("sort 排序後的序列: ", seq)
print("sort 排序後的新序列: ", s)
執行結果如下圖所示:

6. 列表中常用的方法有哪些?
以下是 Python 列表中常用的方法:

7. 什麼是列表生成式?
用來建立列表 (list) 的表示式就是列表生成式,也被稱為列表推導式,它相當於 for 迴圈的簡寫形式。列表生成式返回的是一個列表,它提供了從序列建立列表的簡單途徑。通常應用程式將一些操作應用於某個序列的每個元素,用其獲得的結果作為生成新列表的元素,或者根據確定的判定條件建立子序列。
每個列表生成式都在 for 之後跟一個表示式,然後有零到多個 for 或 if 子句。返回結果是一個根據表達從其後的 for 和 if 上下文環境中生成出來的列表。如果希望表示式推匯出一個元組,那麼就必須使用括號。列表生成式的語法:[表示式 for 迴圈]
# 根據 range生成一個數位的平方的列表
num_list = []
for x in range(1, 11):
num_list.append(x * x)
print(num_list)
# 如果使用列表生成式,那麼程式碼如下:
num_list2 = [x * x for x in range(1, 11)]
print(num_list2)
# 針對偶數進行平方運算
num_list3 = [x * x for x in range(1, 11) if x % 2 == 0]
print(num_list3)
8. 字串格式化%和.format,f格式化字串的區別是什麼?
格式化字串有兩種方法:%和format,具體這兩種方法有什麼區別?請看以下解析。
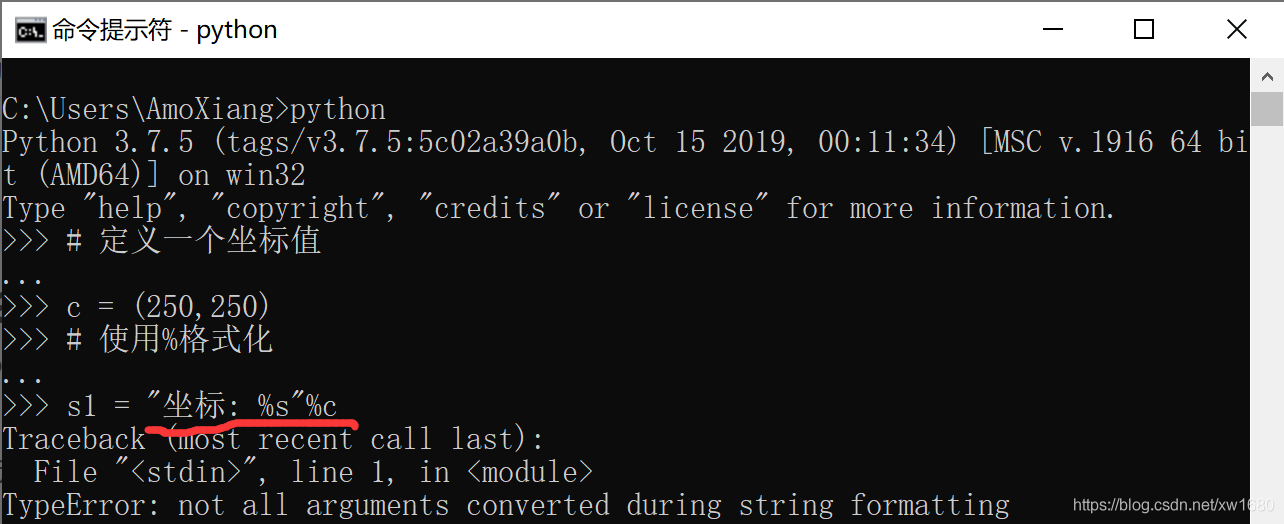
上面的程式碼在執行時會丟擲一個如下的TypeError。
TypeError: not all arguments converted during string formatting
像這類格式化的需求就需要寫成下面的格式:
# 定義一個座標值
c = (250, 250)
# 使用%格式化
s1 = "座標: %s" % (c,)
# 使用 format 就不會存在上面的問題
s2 = "座標: {}".format(c)
print(s2) # 座標: (250, 250)
一般情況下,使用 % 已經足夠滿足程式的需求,但是像這種需要在一個位置新增元素或列表型別的程式碼,最好選擇 format 方法。在 format 方法中,{} 表示預留位置,如下所示:
# {}表示預留位置
print("{},愛老虎".format("zhangsan")) # zhangsan,愛老虎
print("{},{}愛老虎".format("王雷", "李梅")) # 王雷,李梅愛老虎
# 0表示第一個引數的位置
print("{1},{0}愛老虎".format("李梅", "王雷")) # 王雷,李梅愛老虎
Python 3.6 版本開始出現了此新的格式化字串,f-string 格式化字串,效能又優於前面兩種方式。範例程式碼如下:
name = "testerzhang"
print(f'Hello {name}.')
print(f'Hello {name.upper()}.')
d = {'id': 1, 'name': 'testerzhang'}
print(f'User[{d["id"]}]: {d["name"]}')
9. 單引號、雙引號和三引號的區別有哪些?
單引號和雙引號是等效的,如果要換行,那麼需要使用符號(\)。三引號則可以直接換行,並且可以包含註釋,例如:
# 單引號括起來的字串: 'hello'
# 雙引號括起來的字串: "hello"
# 三引號括起來的字串: '''hello'''(三單引號), """hello"""(三雙引號)
需要注意的是:
- 三引號括起來的字串可以直接進行換行。
- 單引號裡面不能再加單引號,但是可以加
\或者是雙引號進行跳脫輸出。 - 雙引號裡面不能再加雙引號,但是可以加
\或者是單引號進行跳脫輸出。
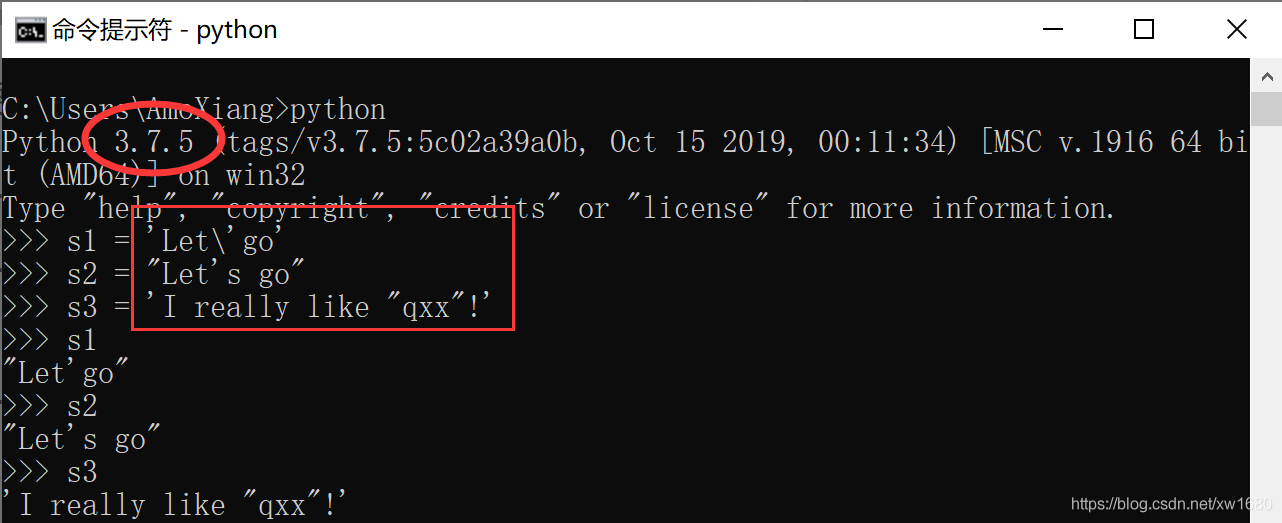
如果要表示 "Let's go" 這個字串,那麼:
10. Python 中常用字串方法有哪些?
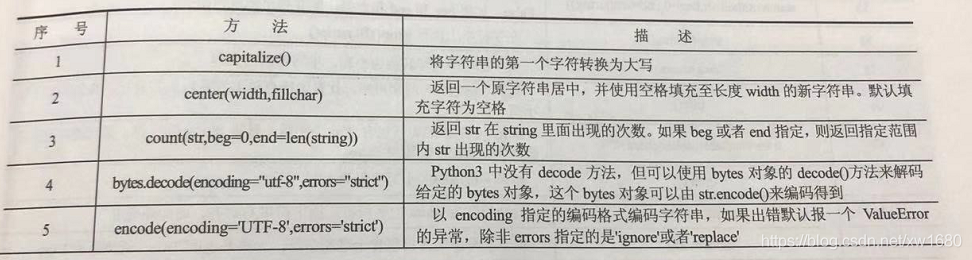
Python 中常用的字串內建函數如下:

11. 如何判斷一個字串是否全為數位?
可以有以下幾種辦法來判斷:
(1) Python isdigit() 方法檢測字串是否只由數位組成。
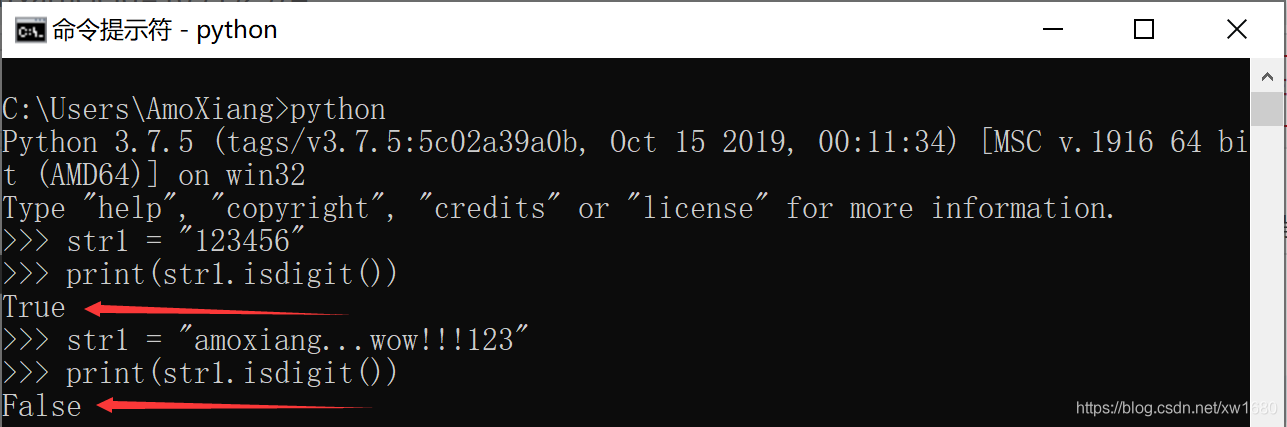
(2) Python isnumeric() 方法檢測字串是否只由數位組成。這種方法只針對 Unicode 字串。如果想要定義一個字串為 Unicode,那麼只需要在字串前新增 u 字首即可。
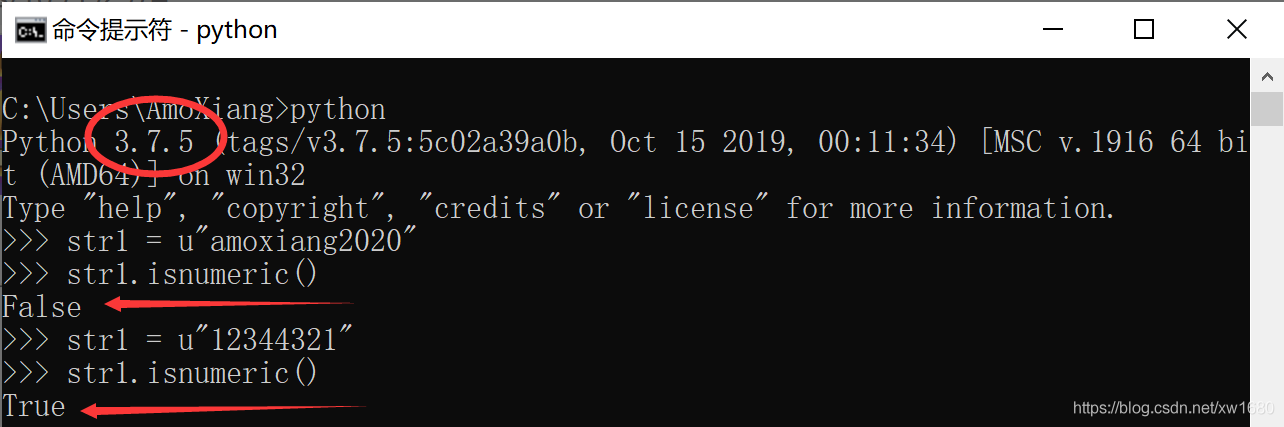
(3) 自定義函數 is_number 來判斷。
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:3.判斷一個字串是否全為數位.py
@time:2020/11/10
"""
def is_number(s):
try:
float(s) # 如果能執行float(s)語句,返回True(字串s是浮點數、整數)
return True
except ValueError:
pass
try:
import unicodedata # 處理ASCii碼的包
unicodedata.numeric(s) # 把一個表示數位的字串轉換為浮點數返回的函數
return True
except (TypeError, ValueError):
pass
return False
# 測試字串和數位
print(is_number("foo")) # False
print(is_number("1")) # True
print(is_number("1.3")) # True
print(is_number("-1.37")) # True
print(is_number("1e3")) # True
12. Python 字典有哪些內建函數?
Python 字典包含了以下內建函數:
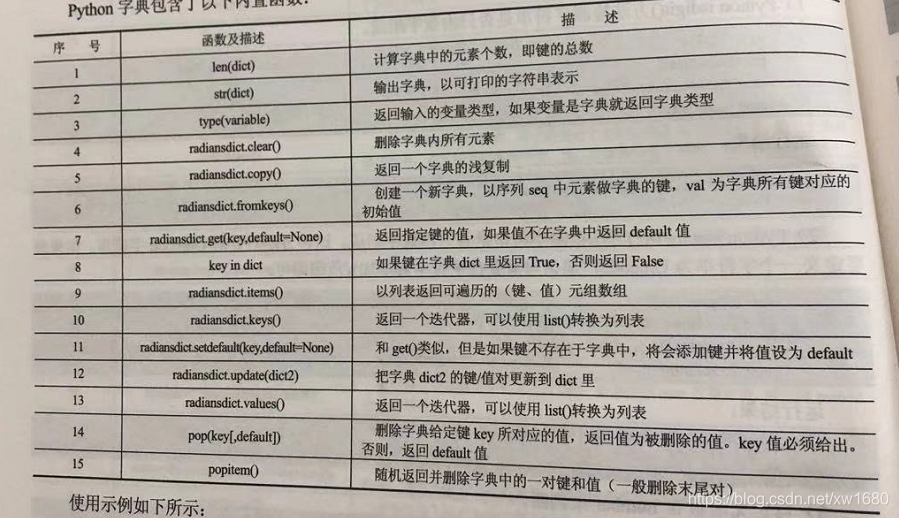
使用範例如下所示:
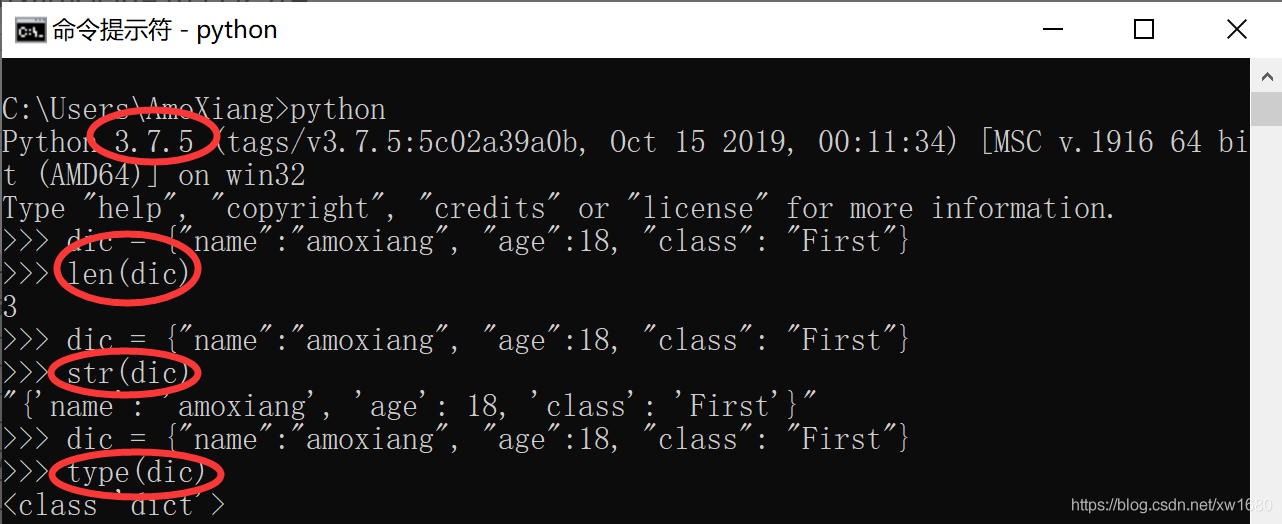
13. 字典的items()方法和iteritems()方法有什麼不同?
字典是 Python 語言中唯一的對映型別。對映型別物件裡雜湊鍵(鍵,key)和指向的物件(值,value)是多對一的關係,通常被認為是可變的雜湊表。字典物件是可變的,它是一個容器型別,能儲存任意個數的 Python 物件,其中也可包括其他容器型別。
字典是一種可變容器模型,且可儲存任意型別物件。字典的每個鍵值(key=>value)對用冒號 (😃 分割,每個對之間用逗號(,)分割,整個字典包括在花括號({})中,格式如下所示:
d= {key1:value1, key2:value2}
鍵必須是唯一的,但值則不必唯一。值可以取任何資料型別,但鍵必須是不可變的,例如字串、數位或元組。
字典的 items 方法可以將所有的字典項以列表方式返回,因為字典是無序的,所以用 items 方法返回字典的所有項,也是無序的。
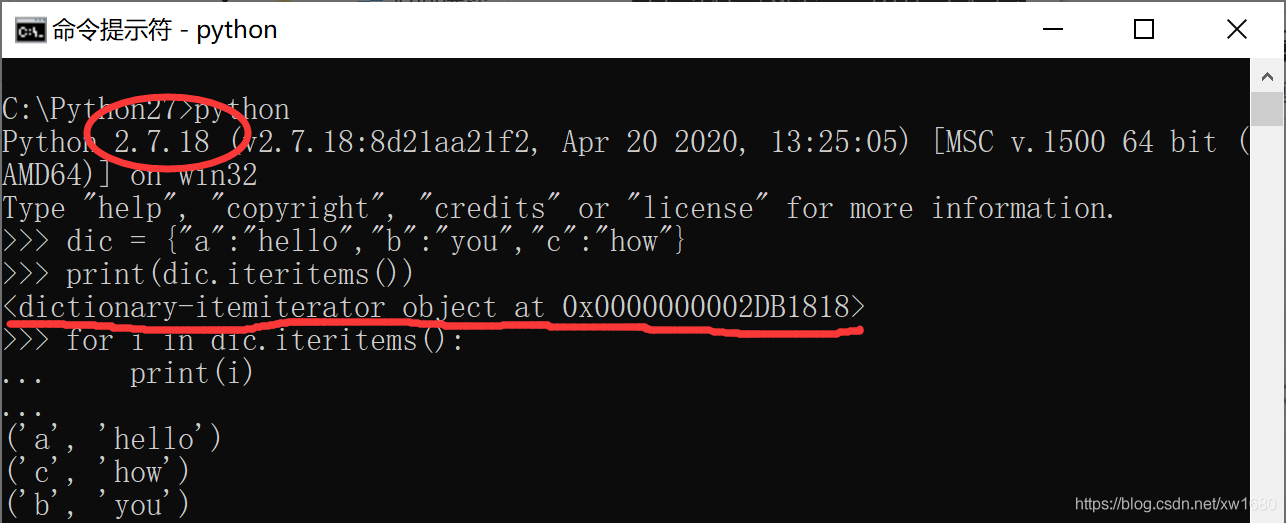
在 Python 2.x 中,items 會一次性取出所有的值,並以列表返回。iteritems 方法與 items 方法相比作用大致相同,只是它的返回值不是列表,而是一個迭代器,通過迭代取出裡面的值,一般在資料量大的時候,iteritems 會比 items 效率高些。
需要注意的是,在 Python 2.x 中,iteritems() 用於返回本身字典列表的迭代器 (Returns an iterator on allitems(key/value pairs)),不佔用額外的記憶體。但是,在Python 3.x中,iteritems() 方法已經被廢除了,用 items() 替換 iteritems(),可以用於 for 來回圈遍歷。在 Python 3.x 中範例:
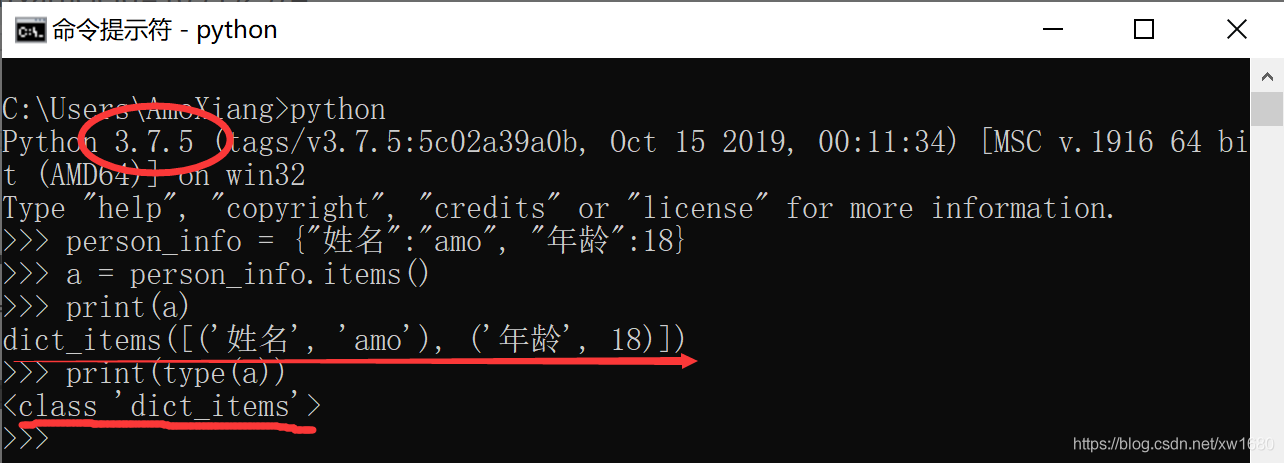
在 Python 2.x 中執行如下程式碼:
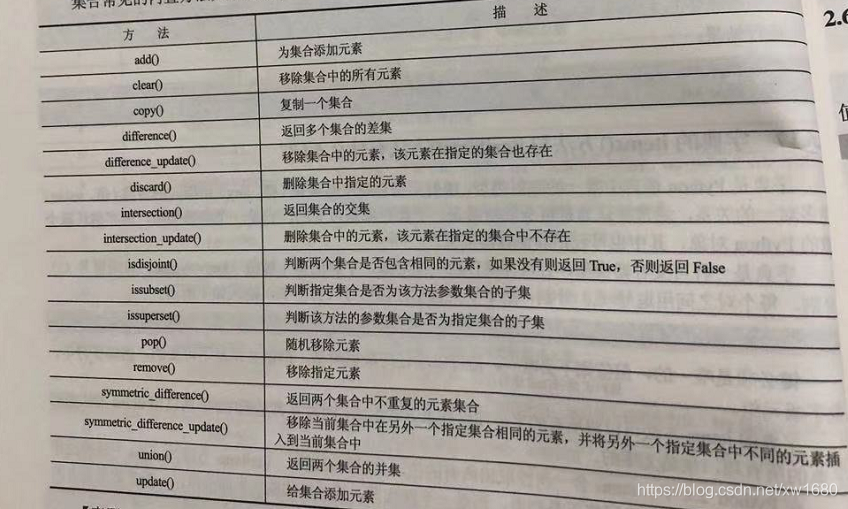
14. 集合常見內建方法有哪些?
集合常見的內建方法如下表所示:
15. 真題
- 兩個 list 物件 aList = [「a」,「b」,「c」,「d」,「e」,「f」],blist = [「x」,「y」,「z」,「d」,「e」,「f」],請用簡潔的方法合併這兩個 list,並且 list 裡面的元素不能重複,最終結果需要排序。
- 請將兩個列表[1,5,7,9]和[2,2,6,8] 合併為 [1,2,2,5,6,7,8,9]
- 如何將一個字串逆序輸出?
- 給定 list 物件 al=[{「name」:「a」,「age」:20},{「name」:「b」,「age」:30},{「name」:「c」,「age」:25}],請按 al 中元素的 age 由大到小排序。
- List = [-2,1,3,-6] ,如何實現以絕對值大小從小到大將List中內容排序
- 給定字典dic = {「a」:3,「bc」:5,「c」:3,「asd」:4,「33」:56,「d」:0},分別按照升序和降序進行排序。
- 給定一個巢狀列表 list2=[[1,2],[4,6],[3,1]],請分別按照巢狀列表中的子列表的第1個和第2個元素進行升序排序
- 使用 lambda 函數對 list 排序 foo=[-5,8,0,4,9,-4,-20,-2,8,2,-4],輸出結果為 [0,2,4,8,8,9,-2,-4,-4,-5,-20],正數從小到大,負數從大到小
- 現有字典 d= {「a」:24,「g」:52,「i」:12,「k」:33},請按字典中的 value值進行排序。
- 現有列表 foo = [[「zs」,19],[「ll」,54],[「wa」,23],[「df」,23],[「xf」,23]],列表巢狀列表排序,如果年齡相同,那麼就按照字母排序。