基於貝葉斯定理的單詞提示器實現
摘要
貝葉斯這個簡單的公式可以解決我們現實生活中很多的問題,個人閒暇之餘寫了一個單詞提示器來體現貝葉斯的巨大魔力。
1. 貝葉斯定理:
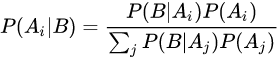
或者
P
(
A
∣
B
)
=
P
(
B
∣
A
)
∗
P
(
A
)
/
P
(
B
)
\ P(A|B) = P(B|A)*P(A)/P(B)
P(A∣B)=P(B∣A)∗P(A)/P(B)
關於貝葉斯的通俗解釋,貝葉斯個人的理解,舉個例子說明下:
假設:
九點前起床的概率為50%
九點前起床我吃早點的概率是80%
九點後起床吃早點的概率是30%
我今天去吃了早點為事件A
我今天九點前起了為事件B
P(A|B) = 80%
那我吃了早點,我九點前起的概率為P(B|A) = P(A|B)*P(B)/P(A)=80% * 50% / 1 = 0.4
上述例子是個人根據生活聯想的,如果有誤請指正。
2. 貝葉斯公式的實際意義
這個簡單的公式在我們現實生活中卻有著巨大的魔力。
人們根據不確定性資訊作出推理和決策需要對各種結論的概率作出估計,這類推理稱為概率推理。概率推理既是概率學和邏輯學的研究物件,也是心理學的研究物件,但研究的角度是不同的。概率學和邏輯學研究的是客觀概率推算的公式或規則;而心理學研究人們主觀概率估計的認知加工過程規律。貝葉斯推理的問題是條件概率推理問題,這一領域的探討對揭示人們對概率資訊的認知加工過程與規律、指導人們進行有效的學習和判斷決策都具有十分重要的理論意義和實踐意義。1
看完個人用python寫了一個單詞提示器
思路如下:
3. 原理
當使用者輸入一個單詞 token p(token) = 的概率就是該詞,在所有檔案中出現的概率
eg: 使用者想要輸入單詞hello hello在所有檔案中出現了a次,所有檔案中總共有b個單詞。
此處不做任何stemming,duplicate removing操作。(減枝,去重)
假設使用者想輸入一個單詞是d,但是實際寫成了單詞r。
實際寫成了r p® = 1 p(d)
p(r|d) = p(d|r)/p(d) * p®
p(d|r) = p(r|d)/p® * p(d)
p® 是先決條件1,想要的結果就轉變成了 p(r|d) * p(d)
在實際中 p(r|d) * p(d) 用d該詞出現的可能性表示
4. 程式設計思路
模型 所有詞-詞頻字典|詞集合
輸入詞 -(錯誤詞)-> 可能出現詞 ->(模型取詞頻)目標詞
# 原理
# 當使用者輸入一個單詞 token p(token) = 的概率就是該詞
# 在所有檔案中出現的概率
# eg: 使用者想要輸入單詞hello hello在所有檔案中出現了a次,所有檔案中總共有b個單詞。
# 此處不做任何stemming,duplicate removing操作。(減枝,去重)
#
# 假設使用者想輸入一個單詞是d,但是實際寫成了單詞r。
# 實際寫成了r p(r) = 1 p(d)
# p(r|d) = p(d|r)/p(d) * p(r)
#
# p(d|r) = p(r|d)/p(r) * p(d)
# p(r) 是先決條件1,想要的結果就轉變成了 p(r|d) * p(d)
#
# 在實際中 p(r|d) * p(d) 用d該詞出現的可能性表示
#
# 程式設計思路
# ---------------------------------------------------
# 模型 所有詞-詞頻字典|詞集合
# ---------------------------------------------------
# 輸入詞 -(錯誤詞)-> 可能出現詞 ->(模型取詞頻)目標詞
# ---------------------------------------------------
#
import collections
with open('documents.txt') as docs:
src = docs.read().lower().split(' ')
model = collections.Counter(src)
token_set = model.keys()
input_token = input("input a token!")
# 輸入的詞的錯誤型別,假設錯誤只會是一個字元
#
# 增 如hello 寫成了helllo, 對於機器推測原來可能是 elllo, hlllo, hello, helll
#
# 刪 如hello 寫成了hell, 對於機器依次補'a-z'的字元
#
# 錯 如hello 寫成了helle, 對於機器依次替換'a-z'
def destination_set(token=""):
result = []
r = "abcdefghijklmnopqrstuvwxyz"
# 增
for i in range(0, len(token)):
replace = token[0:i] + token[i+1:len(token)]
result.append(replace)
# 刪
# 錯
for i in range(0, len(token)):
token_list = list(token)
for j in range(0, len(r)):
replace = token[0:i]+r[j:j+1]+token[i:len(token)]
result.append(replace)
token_list[i] = r[j]
result.append("".join(token_list))
return result
# 可能出現的結果集
re = destination_set(input_token)
intersection = set(re).intersection(set(token_set))
# 詞頻模型取分數,分數高的排前
return_value = {}
for key in list(intersection):
return_value[key] = model.get(key)
return_value = sorted(return_value.items(), key=lambda item: item[1], reverse=True)
print(return_value)
5. 實驗效果
input a token!
helo
[(‘hello’, 1), (‘help’, 1)]
input a token!
jave
[(‘java’, 31), (‘have’, 6), (‘save’, 2)]
6. 驗證結果:
通過單詞提示器可以很好的去找出使用者可能想要輸入的內容。其思想核心就是
使用者輸入錯誤的單詞是事件A
使用者想要輸入的詞是事件B
那P(B|A) 是使用者想要輸入詞(B)但已經輸入錯誤詞(A)
根據貝葉斯 P(A|B)*P(B)/P(A),使用者輸入錯誤是先決條件1,之和使用者想要輸入詞B事件相關,此處簡單轉換成想要輸入的詞的詞頻,就可以實現一個簡單的單詞提示器。
7. 總結
貝葉斯在我們實際生活中發揮著巨大的作用,可以根據貝葉斯來完成我們很多需要處理的事情,上述單詞提示器在一定程度上解決了我們計算機在詞彙試別上就發揮了巨大作用。
上述程式碼中基本沒有難點,程式碼中用的模型資料’documents.txt’只需要在程式碼所在目錄放一個該檔案,多放幾篇英文文章就可以就可以完成該實驗。
為了實驗的準確性,可能還需要大量的文字,和更細節的演演算法實現來進行處理。
托馬斯·貝葉斯 .智庫[參照日期2013-03-07] ↩︎