Go語言網路爬蟲排程器的實現
2020-07-16 10:04:51
基本結構
依據排程器的職責及其介面宣告,可以編寫出排程器實現型別的基本結構,這個基本結構中的欄位比較多,這裡先把它們展示出來,然後再逐一說明://排程器的實現型別
type myScheduler struet {
//爬取的最大深度,首次請求的深度為0
maxDepth uint32
//可以接受的URL的主域名的字典
acceptedDomainMap cmap.ConcurrentMap
//元件註冊器
registrar module.Registrar
//請求的緩衝池
reqBufferPool buffer.Pool
//響應的緩衝池
respBufferPool buffer.Pool
//條目的緩衝池
itemBufferPool buffer.Pool
//錯誤的緩衝池
errorBufferPool buffer.Pool
//已處理的URL的字典
urlMap cmap.ConcurrentMap
//上下文,用於感知排程器的停止
ctx context.Context
//取消函數,用於停止排程器
cancelFunc context.CancelFunc
//狀態
status Status
//專用於狀態的讀寫鎖
statusLock sync.RWMutex
//摘要資訊
summary SchedSummary
}
下面簡要介紹各個欄位的含義。欄位 maxDepth 和 acceptedDomainMap 分別用於限定爬取目標的深度和廣度。在分析器解析出新的請求後,我會用它們逐一過濾那些請求,不符合要求的請求會直接扔掉。這兩個欄位的值會從 RequestArgs 型別的引數值中提取。
registrar 欄位代表元件註冊器。如前文所述,其值可由 module 包的 NewRegistrar 函數直接生成。需要註冊到該元件註冊器的所有元件範例都由 ModuleArgs 型別的引數值提供。
欄位 reqBufferPool、respBufferPool、itemBufferPool 和 errorBufferPool 分別代表針對請求、響應、條目和錯誤的緩衝池。前面講排程器介面時介紹過 DataArgs 型別,也提到過這 4 個緩衝池。
初始化它們所需的引數自然要從一個 DataArgs 型別的引數值中得到。排程器使用這些緩衝池在各類元件範例之間傳遞資料。也正因為如此,排程器才能讓資料真正流轉起來,各個元件範例才能發揮岀應有的作用。
urlMap 欄位的型別是 cmap.ConcurrentMap。還記得我們在第5章最後編寫的那個並行安全字典嗎?它的程式碼就在 gopcp.v2/chapter5/cmap 程式碼包中。由於 urlMap 欄位存在的目的是防止對同一個 URL 的重複處理,並且必會並行地操作它,所以把它宣告為 cmap.ConcurrentMap 型別再合適不過。在後面,你會看到排程器對它的簡單使用。
ctx 欄位和 cancelFunc 欄位是一對。兩者都是由同一個 context.Context 型別值生成出來的。cancelFunc 欄位代表的取消函數用於讓所有關注 ctx 並會呼叫其 Done 方法的程式碼都感知到排程器的停止。
status 欄位是 Status 型別的。關於 Status 型別以及排程器狀態的轉換規則,前面講排程器介面時已經詳細說明過。而 statusLock 欄位則代表專門為排程器狀態的轉換保駕護航的讀寫鎖。
summary 欄位是為儲存排程器摘要而準備的。與排程器介面中的 Summary 方法的結果一樣,它的型別是 SchedSummary,該型別的值可提供兩種格式的摘要資訊輸岀。
雖然上述欄位大都需要顯式賦值,但是用於建立排程器範例的 NewScheduler 函數仍然非常簡單:
//建立排程器範例
func NewScheduler() Scheduler {
return &myScheduler{}
}
一切初始化排程器的工作都交給 Init 方法去做。初始化
排程器介面中宣告的第一個方法就是 Init 方法,它的功能是初始化當前排程器。關於 Init 方法接受的那 3 個引數,前面已經提到多次。Init 方法會對它們進行檢查。不過在這之前,它必須先檢查排程器的當前狀態,請看下面的程式碼片段:
func (sched *myScheduler) Init(
requestArgs RequestArgs,
dataArgs DataArgs,
moduleArgs ModuleArgs) (err error) {
//檢查狀態
logger.Info("Check status for initialization...")
var oldStatus Status
oldStatus, err = sched.checkAndSetStatus(SCHED_STATUS_INITIALIZING)
if err != nil {
return
}
defer func() {
sched.statusLock.Lock()
if err 1= nil {
sched.status = oldStatus
} else {
sched.status = SCHED_STATUS_INITIALIZED
}
sched.statusLock.Unlock()
}()
//省略部分程式碼
}
這裡有對狀態的兩次檢查。第一次是在開始處,用於確認當前排程器的狀態允許我們對它進行初始化,這次檢查由排程器的 checkAndSetStatus 方法執行。該方法會在檢查通過後按照我們的意願設定排程器的狀態(這裡是“正在初始化”狀態),它的宣告如下://用於狀態檢查,並在條件滿足時設定.狀態
func (sched *myScheduler) checkAndSetStatus(
wantedStatus Status) (oldStatus Status, err error) {
sched.statusLock.Lock()
defer sched.statusLock.Unlock()
oldStatus = sched.status
err = checkStatus(oldStatus, wantedStatus, nil)
if err == nil {
sched.status = wantedStatus
}
return
}
下面是其中呼叫的 checkStatus 方法宣告的片段:// checkStatus 用於狀態檢查。
// 引數 currentStatus 代表當前狀態。
// 引數 wantedStatus 代表想要的狀態。
// 檢查規則:
// 1.處於正在初始化、正在啟動或正在停止狀態時,不能從外部改變狀態。
// 2.想要的狀態只能是正在初始化、正在啟動或正在停止狀態中的一個。
// 3.處於未初始化狀態時,不能變為正在啟動或正在停止狀態。
// 4.處於已啟動狀態時,不能變為正在初始化或正在啟動狀態。
// 5.只要未處於已啟動狀態,就不能變為正在停止狀態
func checkStatus(
currentStatus Status,
wantedStatus Status,
lock sync.Locker) (err error) {
//省略部分程式碼
}
這個方法的注釋詳細描述了檢查規則,這決定了排程器是否能夠從當前狀態轉換到我們想要的狀態。只要欲進行的轉換違反了這些規則中的某一條,該方法就會直接返回一個可以說明狀況的錯誤值,而 checkAndSetStatus 方法會檢查 checkStatus 方法返回的這個錯誤值。只有當該值為 nil 時,它才會對排程器狀態進行設定。Init 方法對排程器狀態的第二次檢查是通過 defer 語句實施的。在該方法執行結束時,它會檢查初始化是否成功完成。如果成功,就會把排程器狀態設定為“已初始化”狀態,否則就會讓狀態恢復原狀。
實際上,在排程器實現型別的 Start 方法和 Stop 方法的開始處,也都有類似的程式碼,它們共同保證了排程器的動作與狀態之間的協同。
如果當前狀態允許初始化,那麼 Init 方法就會開始做引數檢查。這並不麻煩,因為那 3 個引數的型別本身都提供了檢查自身的方法 Check。相關程式碼如下:
func (sched *myScheduler) Init(
requestArgs RequestArgs,
dataArgs DataArgs,
moduleArgs ModuleArgs) (err error) {
//省略部分程式碼
//檢查引數
logger.Info("Check request arguments...")
if err = requestArgs.Check(); err != nil {
return err
}
logger.Info("Check data arguments...")
if err = dataArgs.Check(); err != nil {
return err
}
logger.Info("Data arguments are valid.")
logger.Info("Check module arguments...")
if err = moduleArgs.Check(); err != nil {
return err
}
logger.Info("Module arguments are valid.")
//省略部分程式碼
}
在這之後,Init 方法就要初始化排程器內部的欄位了。關於這些欄位的初始化方法,之前都陸續講過,這裡就不再展示了。最後,我們來看一下用於元件範例註冊的程式碼:func (sched *myScheduler) Init(
requestArgs RequestArgs,
dataArgs DataArgs,
moduleArgs ModuleArgs) (err error) {
//省略部分程式碼
//註冊元件
logger.Info("Register modules...")
if err = sched.registerModules(moduleArgs); err != nil {
return err
}
logger.Info("Scheduler has been initialized.")
return nil
}
在 registerModules 方法中,利用已初始化的排程器的 registrar 欄位註冊使用方提供的所有元件範例,並在發現任何問題時直接返回錯誤值。Init 方法也是類似的,只要在初始化過程中發現問題,就忽略掉後面的步驟並把錯誤值返回給使用方。綜上所述,Init 方法做了 4 件事:檢查排程器狀態、檢查引數、初始化內部欄位以及註冊元件範例。一旦這 4 件事都做完,排程器就為啟動做好了準備。
啟動
排程器介面中用於啟動排程器的方法是 Start。它只接受一個引數,這個引數是 *http.Request 型別的,代表排程器在當次啟動時需要處理的第一個基於 HTTP/HTTPS 協定的請求。Start 方法首先要做的是防止啟動過程中發生執行時恐慌。其次,它還需要檢查排程器的狀態和使用方提供的引數值,並把首次請求的主域名新增到可接受的主域名的字典。因此,它的第一個程式碼片段如下:
func (sched *myScheduler) Start(firstHTTPReq *http.Request) (err error) {
defer func() {
if p := recover(); p != nil {
errMsg := fmt.Sprintf("Fatal scheduler error: %sched", p)
logger.Fatal(errMsg)
err = genError(errMsg)
}
}()
logger.Info("Start scheduler...")
//檢查狀態
logger.Info("Check status for start...")
var oldStatus Status oldStatus, err =
sched.checkAndSetStatus(SCHED_STATUS_STARTING)
defer func() {
sched.statusLock.Lock()
if err != nil {
sched.status = oldStatus
} else {
sched.status = SCHED_STATUS_STARTED
}
sched.statusLock.Unlock()
}()
if err != nil {
return
}
//檢查引數
logger.Info("Check first HTTP request...")
if firstHTTPReq == nil {
err = genParameterError("nil first HTTP request")
return
}
logger.Info("The first HTTP request is valid.")
//獲得首次請求的主域名,並將其新增到可接受的主域名的字典
logger.Info("Get the primary domain...")
logger.Infof("-- Host: %s", firstHTTPReq.Host)
var primaryDomain string
primaryDomain, err = getPrimaryDomain(firstHTTPReq.Host)
if err != nil {
return
}
logger.Infof("-- Primary domain: %s", primaryDomain)
sched.acceptedDomainMap.Put(primaryDomain, struet{}{})
//省略部分程式碼
}
大家可以把 Start 方法和 Init 方法中檢查排程器狀態的程式碼對照起來看,並想象這是一個狀態機在運轉。把首次請求的主域名新增到可接受主域名字典的原因是,網路爬蟲程式最起碼會爬取首次請求指向的那個網站中的內容。如果不新增這個主域名,那麼所有請求(包括首次請求)都不會被排程器受理。Start 方法至此已經做好了準備,可以真正啟動排程器了:
func (sched *myScheduler) Start(firstHTTPReq *http.Request) (err error) {
//省略部分程式碼
//開始排程資料和元件
if err = sched.checkBufferPoolForStart(); err != nil {
return
}
sched.download()
sched.analyze()
sched.pick()
logger.Info("Scheduler has been started.")
//放入第一個請求
firstReq := module.NewRequest(firstHTTPReq, 0)
sched.sendReq(firstReq)
return nil
}
把啟用各類元件和各類緩衝池的程式碼分別封裝到了排程器的 download、analyze 和 pick 方法中。依次呼叫這些方法後,通過 sendReq 方法把首次請求發給了請求緩衝池。一旦傳送成功,排程器就會運轉起來。這些啟用的操作以及排程器的運轉都是非同步的。Start 方法在啟動排程器之後,就會立即返回。以上就是 Start 方法的總體執行流程,下面我們詳細介紹幾個重要的內部方法。
1) 處理請求
處理請求需要下載器和請求緩衝池,下面先從排程器的 download 方法看起://從請求緩衝池取出請求並下載,然後把得到的響應放入響應緩衝池
func (sched *myScheduler) download() {
go func() {
for {
if sched.canceled() {
break
}
datum, err := sched.reqBufferPool.Get()
if err != nil {
logger.Warnln("The request buffer pool was closed. Break request reception.")
break
}
req, ok := datum.(*module.Request)
if !ok {
errMsg := fmt.Sprintf("incorrect request type: %T", datum)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
}
sched.downloadOne(req)
}
}()
}
在 download 方法中,新啟用了一個 goroutine。在對應的 go 函數中,先通過對 canceled 方法的呼叫感知排程器的停止。只要發現排程器已停止,download 方法(更確切地說是其中的卻函數)就會中止流程執行。canceled 方法的程式碼如下://用於判斷排程器的上下文是否已取消
func (sched *myScheduler) canceled() bool {
select {
case <- sched.ctx.Done():
return true
default:
return false
}
}
該方法感知排程器停止的手段實際上就是呼叫 ctx 欄位的 Done 方法。回顧一下,這個方法會返回一個通道。一旦那個由 cancelFunc 欄位代表的函數被呼叫,該通道就會關閉,試圖從該通道接收值的操作就會立即結束。回到 download 方法。在 for 語句的開始處,download 方法會從 reqBufferPool 獲取一個請求。如果 reqBufferPool 已關閉,這時就會得到一個非 nil 的錯誤值,這說明在 download 方法獲取請求時排程器關閉了。這同樣會讓流程中止。
在各方並行執行的情況下,這種情況是可能發生的,甚至發生概率還很高。注意,從 reqBufferPool 獲取到的請求是 interface{} 型別的,必須先做一下資料型別轉換。
萬一它的資料型別不對,download 方法就會呼叫 sendError 函數向 errorBufferPool 欄位代表的錯誤緩衝池傳送一個說明此情況的錯誤值。雖然正常情況下不應該發生這種資料型別的錯誤,但還是順便做一下容錯處理比較好。
之所以有 sendError 這個方法,是因為在真正向錯誤緩衝池傳送錯誤值之前還需要對錯誤值做進一步加工。請看該方法的宣告:
//用於向錯謀緩衝池傳送錯誤值
func sendError(err error, mid module.MID, errorBufferPool buffer.Pool) bool {
if err == nil || errorBufferPool == nil || errorBufferPool.Closed() {
return false
}
var crawlerError errors.CrawlerError
var ok bool
crawlerError, ok = err.(errors.CrawlerError)
if !ok {
var moduleType module.Type
var errorType errors.ErrorType
ok, moduleType = module.GetType(mid)
if !ok {
errorType = errors.ERROR_TYPE_SCHEDULER
} else {
switch moduleType {
case module.TYPE_DOWNLOADER:
errorType = errors.ERROR_TYPE_DOWNLOADER
case module.TYPE_ANALYZER:
errorType = errors.ERROR_TYPE_ANALYZER
case module.TYPE_PIPELINE:
errorType = errors.ERROR_TYPE_PIPELINE
}
}
crawlerError = errors.NewCrawlerError(errorType, err.Error())
}
if errorBufferPool.Closed() {
return false
}
go func(crawlerError errors .CrawlerEiro]:) {
if err := errorBufferPool.Put(crawlerError); err != nil {
logger.Warnln("The error buffer pool was closed. Ignore error sending.")
}
}(crawlerError)
return true
}
在確保引數無誤的情況下,sendError 函數會先判斷引數 err 的實際型別。如果它不是 errors.CrawlerError 型別的,就需要對它進行加工。sendError 函數依據引數 mid 判斷它代表的元件的型別,並以此確定錯誤型別。如果判斷不出元件型別,就會認為這個錯誤是排程器丟擲來的,並設定錯誤型別為 errors.ERROR_TYPE_SCHEDULER。從另一個角度講,如果傳給 sendError 函數的錯誤是由某個元件範例引起的,就把該元件範例的 ID 一同傳給該方法,這樣 sendError 函數就能正確包裝這個錯誤,從而讓它有更明確的錯誤資訊。當然,如果這個錯誤是由排程器給出的,就只需像 download 方法那樣把 "" 作為 sendError 函數的第二個引數值傳入。
正確包裝錯誤只是成功的一半。即使包裝完成,錯誤緩衝池關閉了也是枉然。另外請注意 sendError 函數後面的那條 go 語句。依據我之前的設計,排程器的 ErrorChan 方法用於獲得錯誤通道。
排程器的使用方應該在啟動排程器之後立即呼叫 ErrorChan 方法並不斷地嘗試從其結果值中獲取錯誤值。實際上,這裡錯誤通道中的錯誤值就是從錯誤緩衝池那裡獲得的。那麼問題來了,如果使用方不按照上述方式做,那麼一旦發生大量錯誤,錯誤通道以及錯誤緩衝池就會很快填滿,進而呼叫 sendError 函數的一方就會被阻塞。別忘了,緩衝池的 Put 方法是阻塞的。
所以,上面那條 go 語句的作用就是:即使排程器的使用方不按規矩辦事,爬取流程也不會因此停滯。當然,這並不是說不按規矩辦事沒有代價,執行中 goroutine 的大量增加會讓 Go 執行時系統的負擔加重,網路爬蟲程式的執行也會趨於緩慢。
再回到 download 方法。處理單個請求的程式碼都在 downloadOne 方法中,download 方法在 for 語句的最後呼叫了這個方法。downloadOne 方法的程式碼如下:
//根據給定的請求執行下載並把響應放入響應緩衝池
func (sched *myScheduler) downloadOne(req *module.Request) {
if req == nil {
return
}
if sched.canceled() {
return
}
m, err := sched.registrar.Get(module.TYPE_DOWNLOADER)
if err != nil || m == nil {
errMsg := fmt.Sprintf("couldn't get a downloader: %s", err)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
sched.sendReq(req)
return
}
downloader, ok := m.(module.Downloader)
if !ok {
errMsg := fmt.Sprintf("incorrect downloader type: %T (MID: %s)", m, m.ID())
sendError(errors.New(errMsg), m.ID(), sched.errorBufferPool)
sched.sendReq(req)
return
}
resp, err := downloader.Download(req)
if resp != nil {
sendResp(resp, sched.respBufferPool)
}
if err != nil {
sendError(err, m.ID(), sched.errorBufferPool)
}
}
可以看到,該方法也會在一開始就去感知排程器的停止,這是這些內部方法必做的事情。downloadOne 方法會試圖從排程器持有的元件註冊器中獲取一個下載器。如果獲取失敗,就沒必要去做後面的事情了。如果獲取成功,該方法就會去檢查並轉換下載器的型別,然後把請求作為引數傳給下載器的 download 方法,最後獲得結果並根據實際情況向響應緩衝池或錯誤緩衝池傳送資料。注意,一旦下載器獲取失敗或者下載器的型別不正確,downloadOne 方法就會把請求再放回請求緩衝池。這也是為了避免因區域性錯誤而導致的請求遺失。
sendResp 函數在執行流程上與 sendError 函數很類似,甚至還要簡單一些:
//用於向響應緩衝池傳送響應
func sendResp(resp *module.Response, respBufferPool buffer.Pool) bool {
if resp == nil || respBufferPool == nil || respBufferPool.Closed() {
return false
}
go func(resp *module.Response) {
if err := respBufferPool.Put(resp); err != nil {
logger.Warnln("The response buffer pool was closed. Ignore response sending.")
}
}(resp)
return true
}
它會在確認引數無誤後,啟用一個 goroutine 並把響應放入響應緩衝池。排程器的 download 方法只負責不斷地獲得請求,而 downloadOne 方法則負責獲得一個下載器,並讓它處理某個請求。這兩個方法的分工還是比較明確的。稍後會講的處理響應和處理條目的流程其實都與之類似。
在編寫程式的時候,我們可以讓實現類似功能的程式碼呈現近似甚至一致的總體流程和基本結構。注意,這與編寫重複的程式碼是兩碼事,而是說在更高的層面上讓程式碼更有規律。如此一來,閱讀程式碼的成本就會低很多,別人可以更容易地理解你的意圖和程式邏輯。在編寫網路爬蟲框架的時候,一直在有意識地這麼做。
2) 處理響應
處理響應需要分析器和響應緩衝池,具體的程式碼在 analyze 和 analyzeOne 方法中。analyze 方法看起來與 download 方法很相似,只不過它處理的是響應,使用的是響應緩衝池,呼叫的是 analyzeOne 方法。相關程式碼如下://用於從響應集衝池取出響應並解析,熱後把將■到的條目或請求放入相應的緩衝池
func (sched *myScheduler) analyze() {
go func() {
for {
if sched.canceled() {
break
}
datum, err := sched.respBufferPool.Get()
if err != nil {
logger.Warnln("The response buffer pool was closed. Break response reception.")
break
}
resp, ok := datum.(*module.Response)
if !ok {
errMsg := fmt.Sprintf("incorrect response type: %T", datum)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
}
sched.analyzeOne(resp)
}
}()
}
與 downloadOne 方法相比,analyzeOne 方法除了操縱的物件不同,還要多做一些事情://根據給定的響應執行解析並把結果放入相應的緩衝池
func (sched *myScheduler) analyzeOne(resp *module.Response) {
if resp == nil {
return
}
if sched.canceled() {
return
}
m, err := sched.registrar.Get(module.TYPE_ANALYZER)
if err != nil || m == nil {
errMsg := fmt.Sprintf("couldn't get an analyzer: %s", err)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
sendResp(resp, sched.respBufferPool)
return
}
analyzer, ok := m.(module.Analyzer)
if !ok {
errMsg := fmt.Sprintf("incorrect analyzer type: %T (MID: %s)",
m, m.ID())
sendError(errors.New(errMsg), m.ID(), sched.errorBufferPool)
sendResp(resp,sched.respBufferPool)
return
}
dataList, errs := analyzer.Analyze(resp)
if dataList != nil {
for _, data := range dataList {
if data == nil {
continue
}
switch d := data.(type) {
case *module.Request:
sched.sendReq(d)
case module.Item:
sendItem(d, sched.itemBufferPool)
default:
errMsg := fmt.Sprintf("Unsupported data type %T! (data: %#v)", d, d)
sendError(errors.New(errMsg), m.ID(), sched.errorBufferPool)
}
}
}
if errs != nil {
for _, err := range errs {
sendError(err, m.ID(), sched.errorBufferPool)
}
}
}
分析器的 Analyze 方法在處理某個響應之後會返回兩個結果值:資料列表和錯誤列表。其中,資料列表中的每個元素既可能是新請求也可能是新條目。analyzeOne 方法需要 對它們進行型別判斷,以便把它們放到對應的資料緩衝池中。對於錯誤列表,analyzeOne 方法也要進行遍歷並逐一處理其中的錯誤值。3) 處理條目
處理條目需使用條目處理管道,同時也要用到條目緩衝池。排程器的 pick 和 pickOne 方法承載了相關的程式碼。pick 方法同樣與 download 方法很相似,pickOne 方法的實現比 downloadOne 方法還要稍微簡單一些,因為條目處理管道的 Send 方法在對條目進行處理之後只返回錯誤列表。4) 資料、元件和緩衝池
縱觀排程器對它持有的資料、元件和緩衝池的調動方式,我們可以畫出一張更加詳細的資料流程圖,如下所示。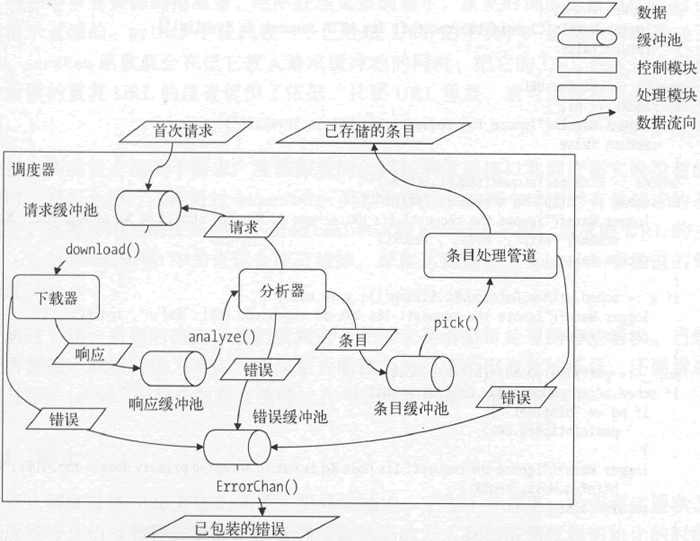
圖:更詳細的資料流程圖