Go語言網路爬蟲概述
2020-07-16 10:04:51
網路爬蟲會模仿人類使用者輸入某個網站的網路地址,並試圖存取該網站上的內容,還會模仿網路瀏覽器根據給定的網路地址去下載相應的內容。這裡所說的內容可以是 HTML 頁面、圖片檔案、音視訊資料流,等等。
在下載到對應的內容之後,網路爬蟲會根據預設的規則對它進行分析和篩選。這些篩選岀的部分會馬上得到特定的處理。與此同時,網路爬蟲還會像人類使用者點選網頁中某個他感興趣的連結那樣,繼續存取和下載相關聯的其他內容,然後再重複上述步驟,直到滿足停止的條件。
如上所述,網路爬蟲應該根據使用者的意願自動下載、分析、篩選、統計以及儲存指定的網路內容。注意,這裡的關鍵詞是“自動”和“根據意願”。“自動”的含義是,網路爬蟲在啟動後自己完成整個爬取過程而無需人工干預,並且還能夠在過程結束之後自動停止。而“根據意願”則是說,網路爬蟲最大限度地允許使用者對其爬取過程進行客製化。
乍一看,要做到自動爬取貌似並不困難。我們只需讓網路爬蟲根據相關的網路地址不斷地下載對應的內容即可。但是,窺探其中就可以發現,這裡有很多細節需要我們進行特別處理,如下所示。
- 有效網路地址的發現和提取。
- 有效網路地址的邊界定義和檢查。
- 重複的網路地址的過濾。
在這些細節當中,有的是比較容易處理的,而有的則需要額外的解決方案。例如,我們都知道,基於 HTML 的網頁中可以包含代表按鈕的 button 標籤。
讓網路瀏覽器在終端使用者點選按鈕的時候載入並顯示另一個網頁可以有很多種方法,其中,非常常用的一種方法就是為該標籤新增 onclick 屬性並把一些 JavaScript 語言的程式碼作為它的值。
雖然這個方法如此常用,但是我們要想讓網路爬蟲可以從中提取出有效的網路地址卻是比較 困難的,因為這涉及對JavaScript程式的理解。JavaScript程式碼的編寫方法繁多,要想讓 網路爬蟲完全理解它們,恐怕就需要用到某個JavaScript程式解析器的 Go語言實現了。
另一方面,由於網際網路對人們生活和工作的全面滲透,我們可以通過各種途徑找到各式各樣的網路爬蟲實現,它們幾乎都有著複雜而又獨特的邏輯。這些複雜的邏輯主要針對如下幾個方面。
- 在根據網路地址組裝 HTTP 請求時,需要為其設定各種各樣的頭部 (Header) 和主體 (Body)。
- 對網頁中的連結和內容進行篩選時需要用到的各種條件,這裡所說的條件包括提取條件、過濾條件和分類條件,等等。
- 處理篩選出的內容時涉及的各種方式和步驟。
這些邏輯絕大多數都與網路爬蟲使用者當時的意願有關。換句話說,它們都與具體的使用目的有著緊密的聯絡。也許它們並不應該是網路爬蟲的核心功能,而應該作為擴充套件功能或可客製化的功能存在。
因此,我想我們更應該編寫一個容易被客製化和擴充套件的網路爬蟲框架,而非一個滿足特定爬取目的的網路爬蟲,這樣才能使這個程式成為一個可適用於不同應用場景的通用工具。
既然如此,接下來我們就要搞清楚該程式應該或可以做哪些事,這也能夠讓我們進一步明確它的功能、用途和意義。
功能需求和分析
概括來講,網路爬蟲框架會反復執行如下步驟直至觸碰到停止條件。1) “下載器”
下載與給定網路地址相對應的內容。其中,在下載“請求”的組裝方面,網路爬蟲框架為使用者盡量預留出客製化介面。使用者可以使用這些介面自定義“請求”的組裝方法。2) “分析器”
分析下載到的內容,並從中篩選出可用的部分(以下稱為“條目”)和需要存取的新網路地址。其中,在用於分析和篩選內容的規則和策略方面,應該由網路爬蟲框架提供靈活的客製化介面。換句話說,由於只有使用者自己才知道他們真正想要的是什麼,所以應該允許他們對這些規則和策略進行深入的客製化。網路爬蟲框架僅需要規定好客製化的方式即可。
3) “分析器”
把篩選出的“條目”傳送給“條目處理管道”。同時,它會把發現的新網路地址和其他一些資訊組裝成新的下載“請求”,然後把這些請求傳送給“下載器”。在此步驟中,我們會過濾掉一些不符合要求的網路地址,比如忽略超出有效邊界的網路地址。你可能已經注意到,在這幾個步驟中,我使用引號突出展示了幾個名詞,即下載器、請求、分析器、條目和條目處理管道,其中,請求和條目都代表了某類資料,而其他 3 個名詞則代表了處理資料的子程式(可稱為處理模組或元件)。
它們與前面已經提到過的網路內容(或稱對請求的響應)共同描述了資料在網路爬蟲程式中的流轉方式。下圖演示了起始於首次請求的資料流程圖。
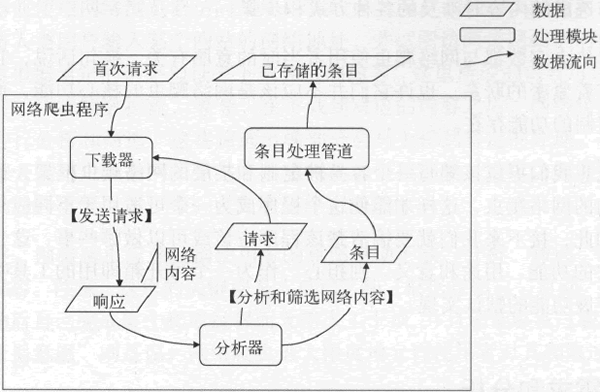
圖:起始於首次請求的資料流程圖