基於深度學習的小目標檢測演演算法文獻綜述閱讀
基於深度學習的小目標檢測演演算法文獻綜述閱讀
最近做了一個對於小目標檢測演演算法的文獻的閱讀,在搜查文獻的時候,瞭解了目標檢測的發展過程以及其中比較典型的演演算法,以下根據彙報的PPT從四個方法介紹小目標檢測演演算法文獻綜述,分別是:目標檢測的簡要介紹、小目標檢測背景介紹及難點、小目標檢測演演算法介紹、總結與展望,此篇部落格也可作為彙報的講稿。
目標檢測簡要介紹


目標檢測過程簡單的可以分為兩個過程:定位和識別,定位是對於某一個目標位於哪一個位置而言,識別是指所定位的目標是什麼,是一個分類問題。目標檢測的發展也可以分為兩個過程,其一是傳統的目標檢測,另一個是基於深度學習的目標檢測。
傳統目標檢測
傳統目標檢測可以分為三個過程:獲取檢測視窗、手工設計感興趣目標的特徵、訓練分類器。
1998年Papageorgiou發表一篇關於A general framework for object detection,提出Harr分類器,這是一個用於檢測人臉的目標檢測分類器,計算獲取的每個檢測視窗的畫素總和,然後取它們的差值,利用差值作為特徵進行目標分類,該方法的優點是速度快。2004年,David Lowe首次提出旋轉尺度不變特徵變換SIFT,並在 2004 年進行補充完善,SIFT 提取影象的區域性特徵,影象旋轉、尺度縮放、亮度變化等現象不會影響特徵的提取;對視角變化、仿射變換和噪聲也具有很好的穩定性,並且具有高速性和可延伸性等眾多優點。Navneet Dalal 和 Bill Triggs 在 CVPR 2005 提出了方向梯度直方圖(Histogram of Oriented Gradient, HOG),HOG 通過統計並計算影象區域性區域的梯度直方圖來構成特徵,影象幾何和光學形變不會影響特徵提取,具有很好的穩定性,使用 HOG+SVM 演演算法在行人檢測中也取得相當好的效。
到 2010 年,由 Pedro Felzenszwalb 提出形變部件模型(Deformable Part Model, DPM),採用改進後的 HOG 特徵,結合 SVM分類器和滑動視窗(Sliding Windows),對目標多視角問題和本身的形變問題分別用多元件策略和圖結構部件模型策略來處理。此外,使用多範例學習自動確定樣本所屬類別和部件模型位置等潛變數。DPM由於其優秀的檢測效能連續在2007、2008、2009 年的 Pascal VOC (Visual Object Class)中獲得冠軍,Felzenszwalb 也因此在2010 年被授予終身成就獎。
傳統的目標檢測演演算法的優點是檢測的準確度較高,但缺點是時間複雜度比較高、視窗冗餘高。傳統的目標檢測的演演算法是對全圖進行華創掃描,對於要檢測的目標完全沒有針對性。而隨著電腦科學技術和GPU等硬體設施的發展,基於深度學習的目標檢測演演算法開始興起。
基於深度學習的目標檢測
基於深度學習的目標檢測是將深度網路應用於目標檢測,根據檢測的原理可將目標檢測演演算法分類兩階段法和單階段法。
基於候選區域的目標檢測
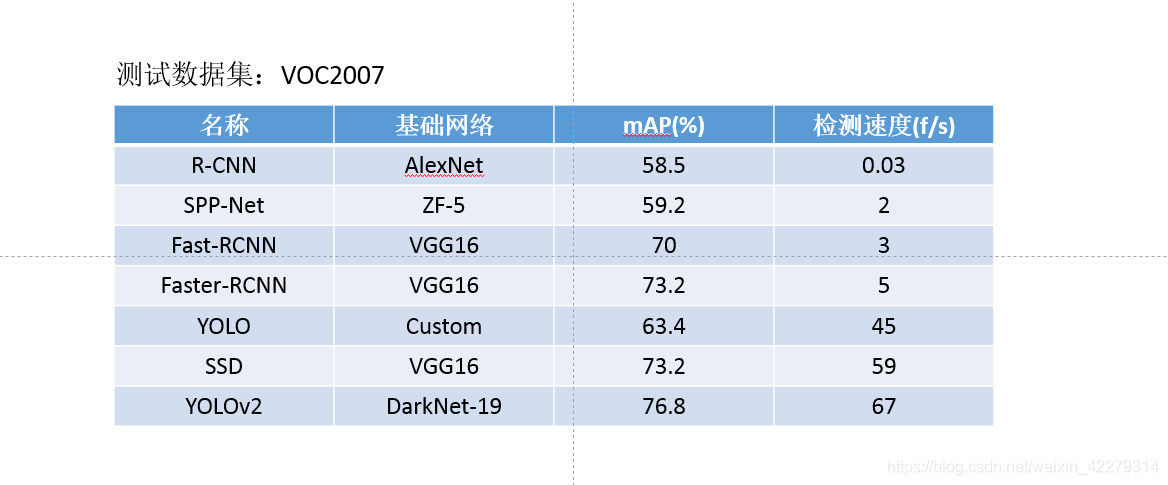
基於區域提取的檢測方法首先通過選擇性搜尋(Selective Search)或 RPN(Region Proposal Net)等方法提取出候選區域,然後利用迴歸等方法對候選區域進行分類和位置 預 測 ,代 表 算 法 有 RCNN、SPP-Net、Fast RCNN、Faster RCNN和 Mask RCNN等。
2014年Girshick等提出RCNN,該演演算法在VOC2007的測試集上的mAP達到了48%。RCNN 演演算法主要包含 4 個步驟:①利用選擇性搜尋演演算法提取候選區域,將候選區域縮放至同一大小;②使用折積神經網路提取候選區域特徵;③SVM 分類器對候選區域特徵分類;④利用邊框迴歸演演算法進行邊框預測。RCNN 演演算法作為第一個基於深度學習的較成熟演演算法,相比於傳統機器學習演演算法有了很大進步,但其劣勢也很明顯:
採用 4 個分離的步驟進行檢測不適於端到端訓練;每次檢測都需要生成 2 000 多個候選框,每個候選框都需要一次折積操作,重疊的候選框帶來大量的重複計算,極大影響了檢測速度。
2014年何愷明提出金字塔池化層網路SPP-Net,傳統的 CNN 網路由於連線了全連線層,因此需要對輸入的圖片尺寸進行裁剪或拉伸,以符合全連線層輸入要求。但是在圖片裁剪或拉伸過程中會扭曲影象,使目標特徵有所變形。為解決這一問題,SPP-Net 在 CNN 網路中加入了空間金字塔池化層(SPP)。不管輸入尺寸如何,SPP 都會將其輸出固定為同一個尺寸,提高了影象的尺度不變性並降低了過擬合。採用 SPP 後,只需要對影象作一次折積操作,通過計算原圖與特徵圖的對映關係即可得到影象的候選區域,大幅縮減了演演算法的檢測時間。1
2015年Ren提出FastRCNN演演算法,與RCNN不同的是,FastRCNN先對圖片通過神經網路提取特徵,再選出候選區域並將不同的輸入ROI池化為相同的大小,最後,對全連線層輸出進行邊框迴歸和分類。ROI池化可以避免對候選區域進行縮放,減少了演演算法的執行時間,但是選擇候選區域仍然比較費時。
2015年Ren等再次提出了Faster RCNN,首先提取圖片特徵;其次,將圖片特徵送入 RPN(Region Proposal Network)網路得到提取的區域;然後提取邊界框特徵;最後,根據候選框特徵預測物體的邊界框和類別。相比於 Fast RCNN 演演算法,該演演算法較重要的改進點就是採用 RPN 代替 Selective Search 提取候選區域。演演算法另一個極為重要的改進就是先驗框的引入,此後的YOLO等單階段的演演算法也採用了這個方法。
基於迴歸的目標檢測
基於迴歸的目標檢測演演算法只對圖片進行一次折積運算,其直接在第一次折積運算中對目標進行定位和識別,這類演演算法比如YOLO(You only look once)、SSD、YOLOv2等。
2016年Redmon等提出了YOLO網路,YOLO 將檢測看作迴歸問題,只作一次折積操作,因此檢測速度很快。但是 YOLO 演演算法由於劃分尺度問題,對小目標的檢測效果不太理想。若同時出現兩個目標中心落在同一個網格中,演演算法就不能很好地檢測出目標。之前看YOLO時做的筆記: YOLOv1閱讀筆記-掃描版.
2016年Liu等提出了SSD(Single Shot MultiBox Director),SSD在一個網路中直接回歸出目標的類別和具體位置,其次採用折積神經網路進行預測,另外在網路結構上採用不同尺度的特徵提取器,最終達到了很好的檢測精度和檢測速度。
2016年Redmon等在YOLO的基礎上提出了YOLOv2,YOLOv2對於YOLOv1的改進體現在以下幾方面:歸一化、使用高解析度影象對模型進行微調、採用了先驗框、聚類提取先驗尺度、約束預測邊框的位置、Passthrough層檢測細粒度特徵、多尺度影象訓練、採用Darknet-19網路。總的來說,YOLOv2就是對YOLO的改進,在檢測速度和檢測精度上都得到了提升。
小目標檢測背景介紹及難點
目前目標檢測演演算法算的發展是比較好了,現在YOLOv5都已經發布了,但是小目標檢測的問題在目標檢測領域來說時比較困難的,小目標從尺寸型別可以分為絕對尺寸和相對尺寸,絕對尺寸的小目標尺寸不大於 32*32,相對尺寸是相對於影象來說,目標尺寸不大於影象尺寸的十分之一。對於複雜場景下的小目標,尤其對衛星遙感影象來說,解析度高視野大,目標相對尺寸較小是它的主要特點。而目前主流的目標檢測演演算法對小目標檢測的召回率低,檢測精度不高,很難達到實時應用的要求。因此,對高解析度影象的小目標檢測的研究不僅是現在目標檢測中的重點,更是這一領域的難點,並且在現實應用中具有十分重要的意義。
小目標檢測演演算法介紹
就目前的小目標檢測來說,可以簡單分為三類:多尺度預測、反折積與上取樣、對抗網路GAN,這三類採用不同的方法對小目標的檢測進行改進。
多尺度預測
在之前的基於迴歸的目標檢測中,應用了多尺度的檢測,但是最終的預測值僅有一個,多尺度預測不僅採用多個尺度對圖片的特徵進行提取,而且在不同的尺度上都會進行預測。其中代表性的演演算法包括:LIN在2017提出的FPN模型,2018年Singh提出了SNIP演演算法,2018年趙亞男等提出了MFDSSD演演算法。以下通過介紹FPN演演算法來介紹多尺度預測方法。
FPN(Feature Pyramid Networks for Object Detection),
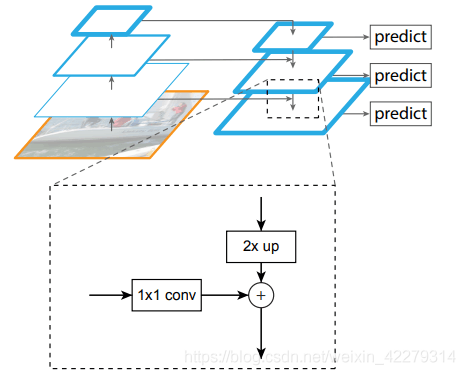
FPN主要是在網路的結構方面進行改進,首先,使用Resnet、vgg等網路,構建由下向上的特徵金字塔,然後通過上取樣,構建自上而下的網路,接著對其進行橫向連線。原來多數的目標檢測只採用頂層特徵做預測,但低層的特徵語意資訊比較少,但目標位置比較準確,高層的特徵語意資訊比較豐富,但目標比較粗略。其次,有一些演演算法雖然也採用了多尺度的特徵融合,但是隻對最後的融合特徵進行預測,FPN對每一個融合的特徵都進行了預測。
反折積和上取樣
小目標在影象中所佔畫素較少,而且輪廓比較粗糙。如果能提高影象特徵的解析度,使小目標的特徵變大,對小目標檢測是有幫助的。將反折積和上取樣應用在網路中可以提高特徵圖尺寸,通過與低層特徵融合可提高特徵的表達力,更好地預測小目標。2016年,Fu等人針對SSD方法在小目標上檢測效果不好的問題,提出了DSSD模型;2015,Jonathan提出了FNC網路;2018年,範欽明提出了AFFSSD網路;這些方法都通過反折積等方法提高了圖片中低分率的語意資訊。下面僅對DSSD進行粗略的介紹;
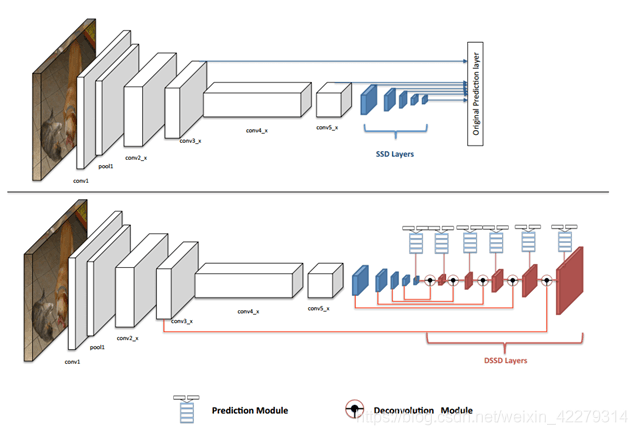
DSSD對於SSD網路的改進主要在以下兩點:一、把SSD網路的基礎網路由VGG換成了Resnet-101,增強了特徵提取能力;二、使用反折積層增加了大量的上下文資訊。低解析度的特徵資訊作為上下文你資訊,通過反折積與前面兩倍解析度資訊的特徵影象進行融合,最後通過一個預測模組進行預測。
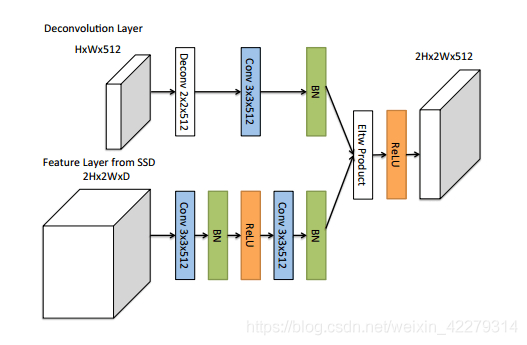
把紅色層做反折積操作,使其和上一級的藍色層的尺度相同,再把兩者融合起來,得到新的紅色層來做預測。
對抗網路GAN
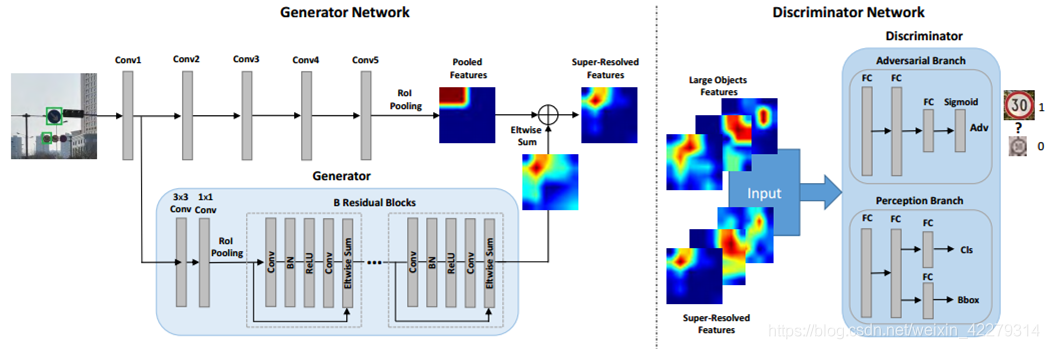
PGAN使用感知生成式對抗網路(Perceptual GAN)提高小物體檢測率,生成器將低解析度小目標的特徵轉化為高解析度大物體的特徵,分辨器與生成器以競爭的方式分辨特徵,在不斷的迭代過程中,縮小小目標與大目標直接的差異來提高小目標檢測的準確率。PGAN挖掘不同尺度物體間的結構關聯,提高小物體的特徵表示,使之與大物體類似。包含兩個子網路,生成網路和感知分辨網路。生成網路是一個深度殘差特徵生成模型,通過引入低層精細粒度的特徵將原始的較差的特徵轉換為高分變形的特徵。分辨網路一方面分辨小物體生成的高解析度特徵與真實大物體特徵,另一方面使用感知損失提升檢測率。
總結與展望
目前小目標檢測的演演算法基本都是在現有的深度網路上進行改進,使之能夠適應小目標識別;
其次,相對於大目標檢測,小目標檢測的資料集較少且品質不佳;
展望就算了吧哈哈哈
源於張新於2020年發表的基於深度學習的小目標檢測演演算法綜述 ↩︎