溪源的Java筆記—集合之Collection介面
溪源的Java筆記—集合之Collection介面
前言
在java中我們最常的資料介面就是集合,在面試的時候最常問的問題也是集合相關的問題,結合自己的面試經驗,我做了簡單地整理,希望可以能夠幫助小夥伴們一二。
正文
集合
集合有兩個介面組成:Collection和Map
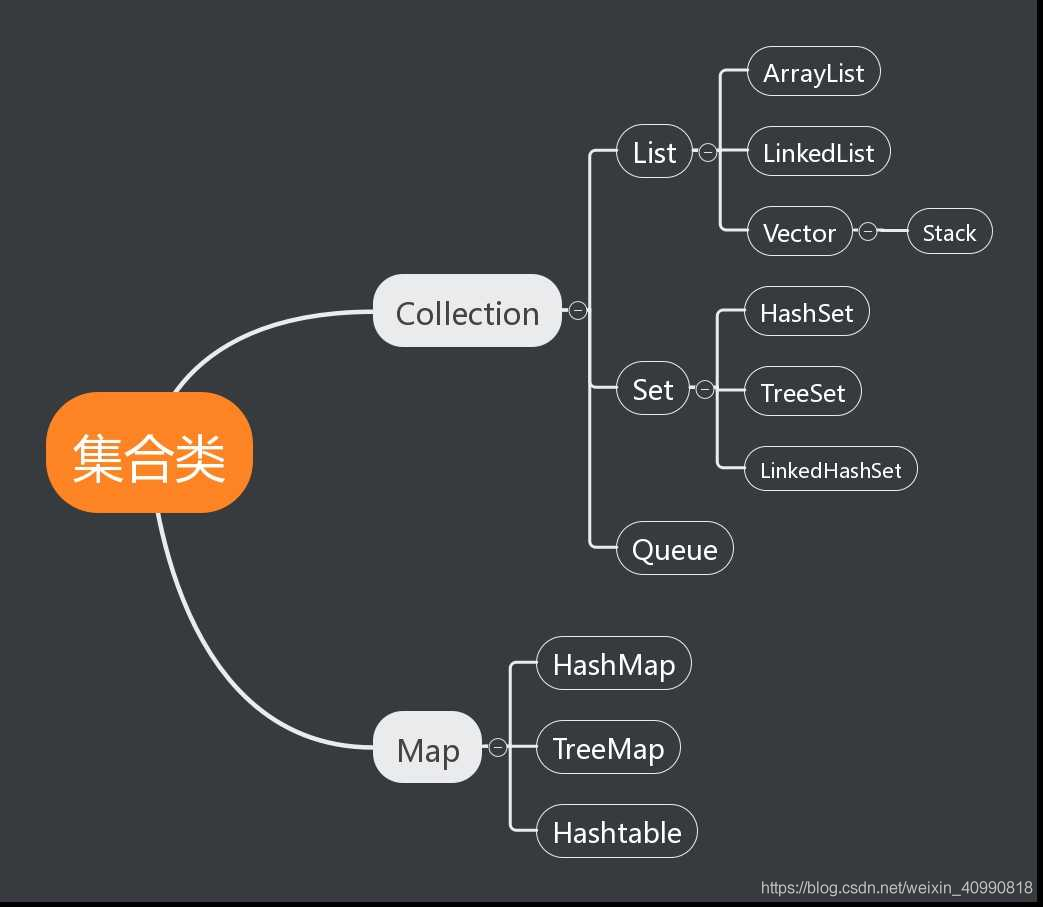
Collection介面
Collection介面有3個子介面分別是:
List:有序且元素是可重複的Set:無序並元素是不可重複的Queue:先進先出的線性資料結構,並且只能觀察到隊首元素.
List介面
List的常用實現類有:
ArrayList:底層是通過陣列實現的,查詢效能高,插入和刪除比較慢。它遍歷的優勢是在於它在記憶體的連續性決定的。LinkedList:通過雙向連結串列實現,查詢效能略低,但插入和刪除效能高,除了實現了List介面,還實現了Queue介面。Vector:資料結構與ArrayList類似,通過synchronized來實現執行緒安全,並且Stack棧是實現Vector介面的。
重點知識點:
1.實現ArrayList執行緒安全的方式
- 使用
synchronized或者鎖 - 直接使用
Vector,但jdk1.2官方推薦棄用 - 使用
Collections.synchronizedList(list)來實現
2.ArrayList的構建與擴容
ArrayList arrayList =new ArrayList(),預設生成一個容量為0的陣列,只有add()元素時才會分配預設10的初始容量。- 如果當10個容量都滿了,就會擴容50%的大小,即到達15的容量。
所以在實際的使用如果存取一個已知大小的陣列時,儘可能要設定初始容量,避免觸發連續的擴容操作。
3.ArrayList插入和刪除為什麼效能比較差?
插入和刪除都涉及到了陣列的copy(即資料遷移),操作的位置越在前面,需要copy的陣列長度就越長。
4.Vector為什麼會被棄用?
Vector所有的方法都使用了synchronized來實現執行緒安全的,這種在所有方法上都使用了synchronized極大影響了整個資料操作的效能,實際上hashtable也有類似的問題。所以ArrayList在jdk1.2後作為Vector的替代品。
Set介面
Set的常用實現類有:
HashSet:是基於HashMap實現的,預設建構函式是構建一個初始容量為16,負載因子為0.75 的HashMap。通過重寫equals(Object obj)方法和hashCode()來實現去重。TreeSet:資料結構是紅黑樹,通過比較器來實現去重。它的有序性指的是:會通過比較器隊元素進行排序。LinkedHashSet:LinkedHashSet底層使用LinkedHashMap來儲存所有元素,通過重寫equals(Object obj)方法和hashCode()來實現去重。它的有序性指的是,儲存的順序和取出的順序是一致的。
Queue介面
Queue的實現類主要有三類:
- 非阻塞的實現類:如
ConcurrentLinkedQueue,採用CAS操作實現無界執行緒安全佇列,避免了加鎖影響了效能。 - 阻塞的實現類:如
ArrayBlockingQueue(有界)、LinkedBlockingQueue(無界),它的阻塞性表現在當佇列滿了,再新增元素時會阻塞該執行緒,暫停新增,等待佇列有空位置。 - 雙端佇列:
Dueue,元素可以在兩端進行新增和移除操作。
Queue常見的方法:
add():在佇列隊尾新增元素,已滿拋異常。offer():在佇列隊尾新增元素,已滿返回false。remove():刪除隊首元素,元素為空拋異常。poll():刪除隊首元素,元素為空返回null,不為空則得到該元素。element():查詢隊首元素,為空拋異常。peek():查詢隊首元素,為空返回null。
ConcurrentLinkedQueue
ConcurrentLinkedQueue是java.util.concurrent下提供的原子操作的執行緒安全佇列,它和LinkedBlockingQueue都是執行緒安全的,它們的區別在於:
LinkedBlockingQueue: 多用於任務佇列,適用於一個消費者消費多個不同的生產者不同的訊息。ConcurrentLinkedQueue:多用於訊息佇列,適用於一個生產者為不同的消費者提供相同的訊息。
ArrayBlockingQueue
ArrayBlockingQueue執行緒池設定經常使用到的有界阻塞佇列。
ArrayList不適合做佇列,但是陣列是可以做佇列,ArrayBlockingQueue的實現就是一個環形佇列,它是一個定長的、執行緒安全阻塞式佇列,內部是用一個定長陣列來實現的。它的執行緒安全和阻塞性都是通過ReentrantLock來實現的。ArrayBlockingQueue的出佇列和入佇列過程,可以抽象地看作一個在記憶體上定長的遊標卡尺。所以當發生出隊時,隊頭是不斷變化的,並不是一直items[0],第一次是0,第二次出隊是1,所以這樣就不需要涉及資料遷移的操作了。
private final E[] items;//底層資料結構
private int takeIndex;//用來為下一個take/poll/remove的索引(出隊)
private int putIndex;//用來為下一個put/offer/add的索引(入隊)
private int count;//佇列中元素的個數
/** Main lock guarding all access */
private final ReentrantLock lock;//鎖
/** Condition for waiting takes */
private final Condition notEmpty;//等待出隊的條件
/** Condition for waiting puts */
private final Condition notFull;//等待入隊的條件
其他
1.集合和陣列的區別
- 陣列特點:大小固定,只能儲存相同資料型別的資料
- 集合特點:大小可動態擴充套件,可以儲存各種型別的資料
集合和陣列的相互轉變
//array轉換為list
int[] arr = {1,3,4,6,6};
List list =Arrays.asList(arr);
//list轉化成Array
String arratb[] =(String [])list.toArray();
2.集合的種類
- 普通集合:通常效能最高,但是不保證多執行緒的安全 性和並行的可靠性,如
ArrayList。 - 執行緒安全集合:僅僅是給集合新增了
synchronized同步鎖,嚴重犧牲了效能,而且對並行的效率就 更低了,如HashTable。 - 並行集合:則通過複雜的策略不僅保證了多執行緒的安全又提高的並行時的效率,如
ConcurrentLinkedQueue。
3.java提供的集合工具類——Collections
Collections是java提供的一個 Set、List和Map等集合的工具類, 提供了大量方法對集合進行排序、查詢和修改等操作:
Collections.sort(list):使用集合中的某一欄位,對集合進行排序:Collections.shuffle(list): 對集合進行隨機排序:Collections.binarySearch(list, "o"):查詢指定集合中的元素,返回所查詢元素的索引Collections.max(list)/Collections.min(list):求最大值/求最小值Collections.indexOfSubList(list, subList)/Collections.lastindexOfSubList(list, subList):首次/最後一次 出現元素的索引Collections.replaceAll(list, "a", "b"):替換批定元素為某元素,若要替換的值存在剛返回true,反之返回falseCollections.reverse(list):反轉集合中元素的順序
Collections提供對集合物件實現同步控制等方法:
Collections.synchronizedCollection(collection):針對實現collection介面物件的集合提供執行緒同步控制Collections.synchronizedList(list):針對實現list介面物件的集合提供執行緒同步控制Collections.synchronizedSet(set):針對實現set介面物件的集合提供執行緒同步控制Collections.synchronizedMap(map):針對實現map介面物件的集合提供執行緒同步控制
4.流式表示式
Stream 是 Java8 中處理集合的關鍵抽象概念,它可以指定你希望對集合進行的操作,可以執行非常複雜的查詢、過濾和對映資料等操作。
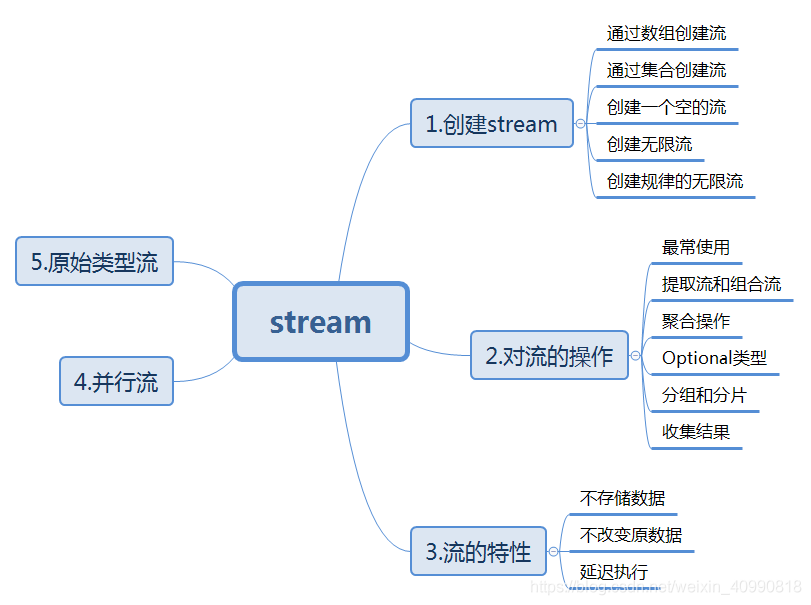
Stream的特性:
- 不儲存資料: 陣列或集合的基礎上建立
stream,stream不會專門儲存資料。 - 不改變原資料: 對
stream的操作也不會影響到建立它的陣列和集合 ,對於stream的聚合、消費或收集操作(終止操作)只能進行一次,再次操作會報錯。 - 延遲執行:
Stream延遲執行的特性,意味著它在聚合操作執行前修改資料來源是允許的,一旦開始聚合操作就不允許了。
聚合操作
聚合操作類似SQL語句一樣的操作, 比如filter, map, reduce, find, match, sorted等:
中間操作
中間操作返回結果還是Stream流物件。
篩選與切片
filter:過濾流中的某些元素limit(n):獲取n個元素skip(n):跳過n元素,配合limit(n)可實現分頁distinct():通過流中元素的hashCode()和equals()去除重複元素
對映
map():接收一個函數作為引數,該函數會被應用到每個元素上,並將其對映成一個新的元素。flatMap():接收一個函數作為引數,將流中的每個值都換成另一個流,然後把所有流連線成一個流。
排序
sorted():產生一個新流,其中按自然順序排序。sorted(Comparator comp): 產生一個新流,其中按比較器順序排序
終止操作
終止操作與中間操作相比,終止操作返回值已經不再是Stream流物件了,所以叫終止操作,能夠獲取到對應的值了。
一個是Stream流物件只能執行一次終止操作。
查詢與匹配
allMatch(Predicate p):檢查是否匹配所有元素findAny(): 返回當前流中的任意元素max(Comparator c): 返回流中最大值forEach(Consumer c):迭代器
歸約
reduce(T iden,BinaryOperator b): 可以將流中元素反覆結合起來,得到一個值。reduce(BinaryOperator b): 可以將流中元素反覆結合起來,得到一個值。返回Optional。
收集
collect(Collector c): 將流轉換為其他形式。接收一個Collector介面的實現,用於給Stream中元素



