HTML DOM是什麼
2020-07-16 10:04:48
HTML 語言是由很多標籤組成的,程式碼如下所示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>程式設計師天天說的DOM到底是什麼</title>
</head>
<body>
<h1>我的第一個標題</h1>
<p>我的第一個段落</p>
</body>
</html>
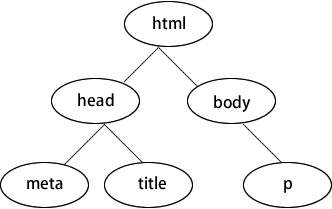
上述程式碼中,head 和 body 是標籤。這些標籤不是隨意擺放的,它們有自己的規則。首先,它們是巢狀的,一層套一層,比如 html 套 body,body 又套 h1。其次, 每一層可以同時存在很多標籤,比如 head 和 body 屬於同一層,它們被外面的 html 套著。這樣的結構很像計算機裡的資料夾。例如,“我的電腦”是最外層,裡面套著 C、D、E、F 盤,每個盤裡又有很多資料夾,資料夾裡又有資料夾,逐個開啟後才能看到具體的檔案。
為什麼要按照這種結構來組織呢?目的其實是方便解析和查詢。解析的時候,從外向裡循序漸進,好比按照圖紙蓋房子,先蓋圍牆,再蓋走廊,最後才蓋臥室。查詢的時候,會遵循一條明確的路線,例如“D槽/文化交流/影視作品/給產品經理講技術avi”,一層一層地縮小範圍,查詢效率會非常高。
所以,瀏覽器在解析 HTML 文件時,會把每個標籤抽象成程式碼裡的物件,按照這種層次分明的結構組織,這就是 DOM。
如下圖所示為資料結構裡典型的“樹”結構。程式設計師經常說的 DOM 樹,其實就是這個意思。瀏覽器在解析 HTML 時,會在它的內部構建這樣一棵 DOM 樹,然後按照這棵樹上的層次順序解析每個標籤。解析完成後,使用者就看到了網頁的內容。