Python爬蟲之Requests 庫的介紹和操作範例
一、什麼是爬蟲?
網路爬蟲(又被稱為網頁蜘蛛,網路機器人,在FOAF社群中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取全球資訊網資訊的程式或者指令碼。另外一些不常使用的名字還有螞蟻、自動索引、模擬程式或者蠕蟲。
其實通俗的講就是通過程式去獲取web頁面上自己想要的資料,也就是自動抓取資料。
你可以爬去妹子的圖片,爬取自己想看看的視訊。。等等你想要爬取的資料,只要你能通過瀏覽器存取的資料都可以通過爬蟲獲取
二、爬蟲的本質
模擬瀏覽器開啟網頁,獲取網頁中我們想要的那部分資料
瀏覽器開啟網頁的過程:
當你在瀏覽器中輸入地址後,經過DNS伺服器找到伺服器主機,向伺服器傳送一個請求,伺服器經過解析後傳送給使用者瀏覽器結果,包括html,js,css等檔案內容,瀏覽器解析出來最後呈現給使用者在瀏覽器上看到的結果
所以使用者看到的瀏覽器的結果就是由HTML程式碼構成的,我們爬蟲就是為了獲取這些內容,通過分析和過濾html程式碼,從中獲取我們想要資源(文字,圖片,視訊…)
三、爬蟲的基本流程
發起請求
通過HTTP庫向目標站點發起請求,也就是傳送一個Request,請求可以包含額外的header等資訊,等待伺服器響應
獲取響應內容
如果伺服器能正常響應,會得到一個Response,Response的內容便是所要獲取的頁面內容,型別可能是HTML,Json字串,二進位制資料(圖片或者視訊)等型別
解析內容
得到的內容可能是HTML,可以用正規表示式,頁面解析庫進行解析,可能是Json,可以直接轉換為Json物件解析,可能是二進位制資料,可以做儲存或者進一步的處理
儲存資料
儲存形式多樣,可以存為文字,也可以儲存到資料庫,或者儲存特定格式的檔案
四、什麼是Requests
Requests是用python語言基於urllib編寫的,採用的是Apache2 Licensed開源協定的HTTP庫
如果你看過上篇文章關於urllib庫的使用,你會發現,其實urllib還是非常不方便的,而Requests它會比urllib更加方便,可以節約我們大量的工作。(用了requests之後,你基本都不願意用urllib了)一句話,requests是python實現的最簡單易用的HTTP庫,建議爬蟲使用requests庫。
預設安裝好python之後,是沒有安裝requests模組的,需要單獨通過pip安裝
五、Requests 庫的基礎知識
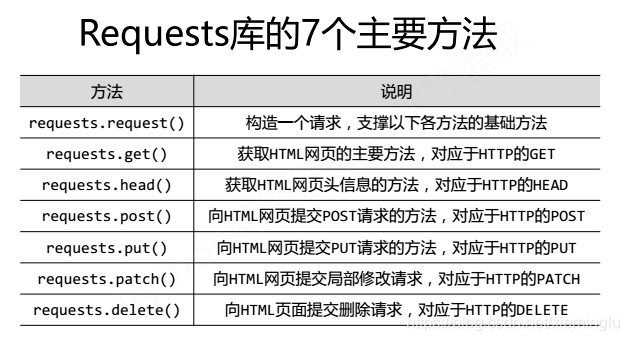
我們通過呼叫Request庫中的方法,得到返回的物件。其中包括兩個物件,request物件和response物件。
request物件就是我們要請求的url,response物件是返回的內容,如圖:

六、Requests的安裝
1.強烈建議大家使用pip進行安裝:pip insrall requests
2.Pycharm安裝:file-》default settings-》project interpreter-》搜尋requests-》install package-》ok
七、Requests庫實的操作例
1、京東商品的爬取–普通爬取框架
import requests
url = "https://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失敗!")
2、亞馬遜商品的爬取–通過修改headers欄位,模擬瀏覽器向網站發起請求
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.status_code)
print(r.text[:1000])
except:
print("爬取失敗")
3、百度/360搜尋關鍵詞提交–修改params引數提交關鍵詞
百度的關鍵詞介面:http://www.baidu.com/s?wd=keyword
360的關鍵詞介面:http://www.so.com/s?q=keyword
import requests
url="http://www.baidu.com/s"
try:
kv={'wd':'Python'}
r=requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
print(r.text[500:5000])
except:
print("爬取失敗")
4、網路圖片的爬取和儲存–結合os庫和檔案操作的使用
import requests
import os
url="http://tc.sinaimg.cn/maxwidth.800/tc.service.weibo.com/p3_pstatp_com/6da229b421faf86ca9ba406190b6f06e.jpg"
root="D://pics//"
path=root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("檔案儲存成功")
else:
print("檔案已存在")
except:
print("爬取失敗")
最後:例外處理
在你不確定會發生什麼錯誤時,儘量使用try…except來捕獲異常所有的requests exception:
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException
try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')