python爬蟲—分析Ajax請求對json檔案爬取今日頭條街拍美圖
python爬蟲—分析Ajax請求對json檔案爬取今日頭條街拍美圖
前言
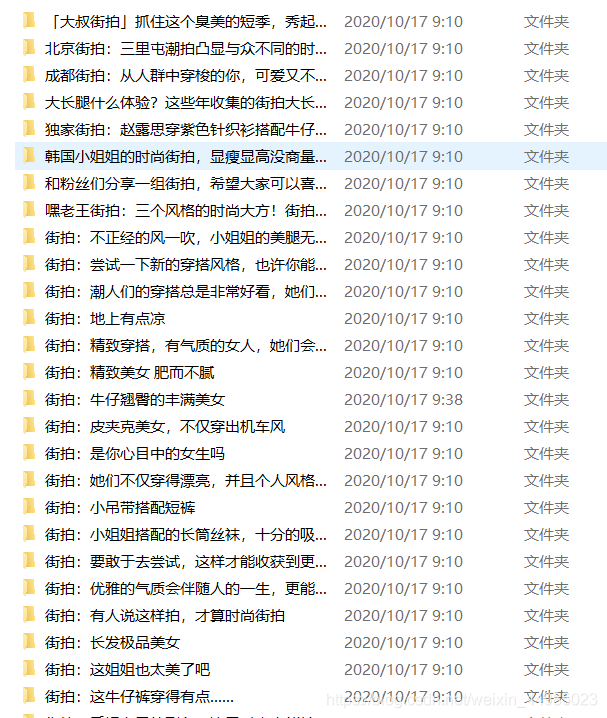
本次抓取目標是今日頭條的街拍美圖,爬取完成之後,將每組圖片下載到本地並儲存到不同資料夾下。下面通過抓取今日頭條街拍美圖講解一下具體操作步驟。
一、準備
網站:
https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
環境:anaconda3-spyder
二、分析網頁
一些網頁直接請求得到的HTML程式碼其實並沒有我們在網頁中看到的內容,這是因為一些資訊通過Ajax載入了,然後通過JavaScript渲染生成的,這時就需要通過分析網頁的請求來獲取想要爬取的內容。例如我進入街拍這個頁面下,右鍵檢視網頁原始碼,再返回街拍頁面一直向下拉動,街拍頁面會變換出現不同的內容和圖片,再右鍵檢視原始碼,發現原始碼和第一次我們檢視的原始碼是一樣的,沒有發生變化,並且原始碼很短。如下所示:
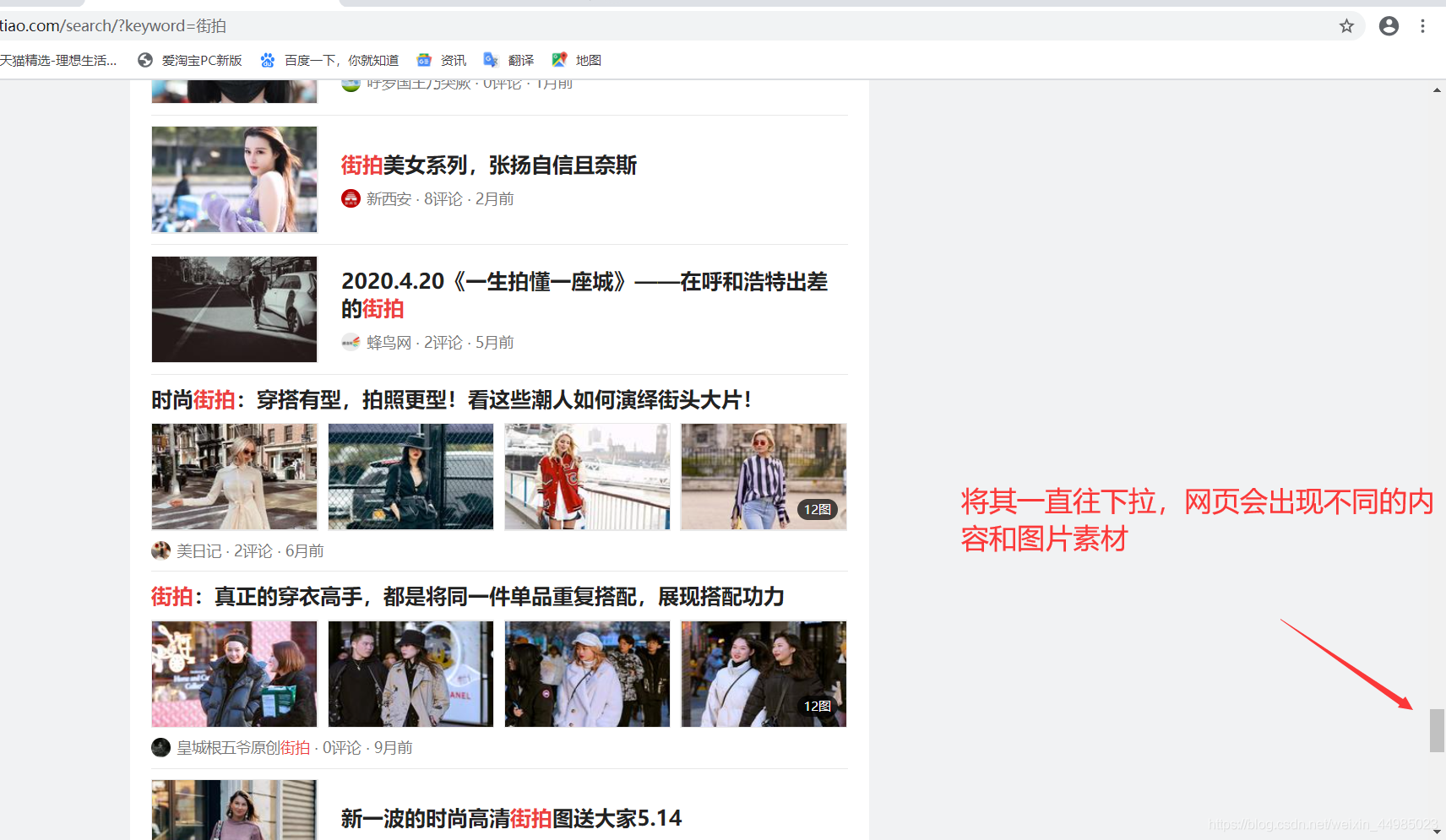
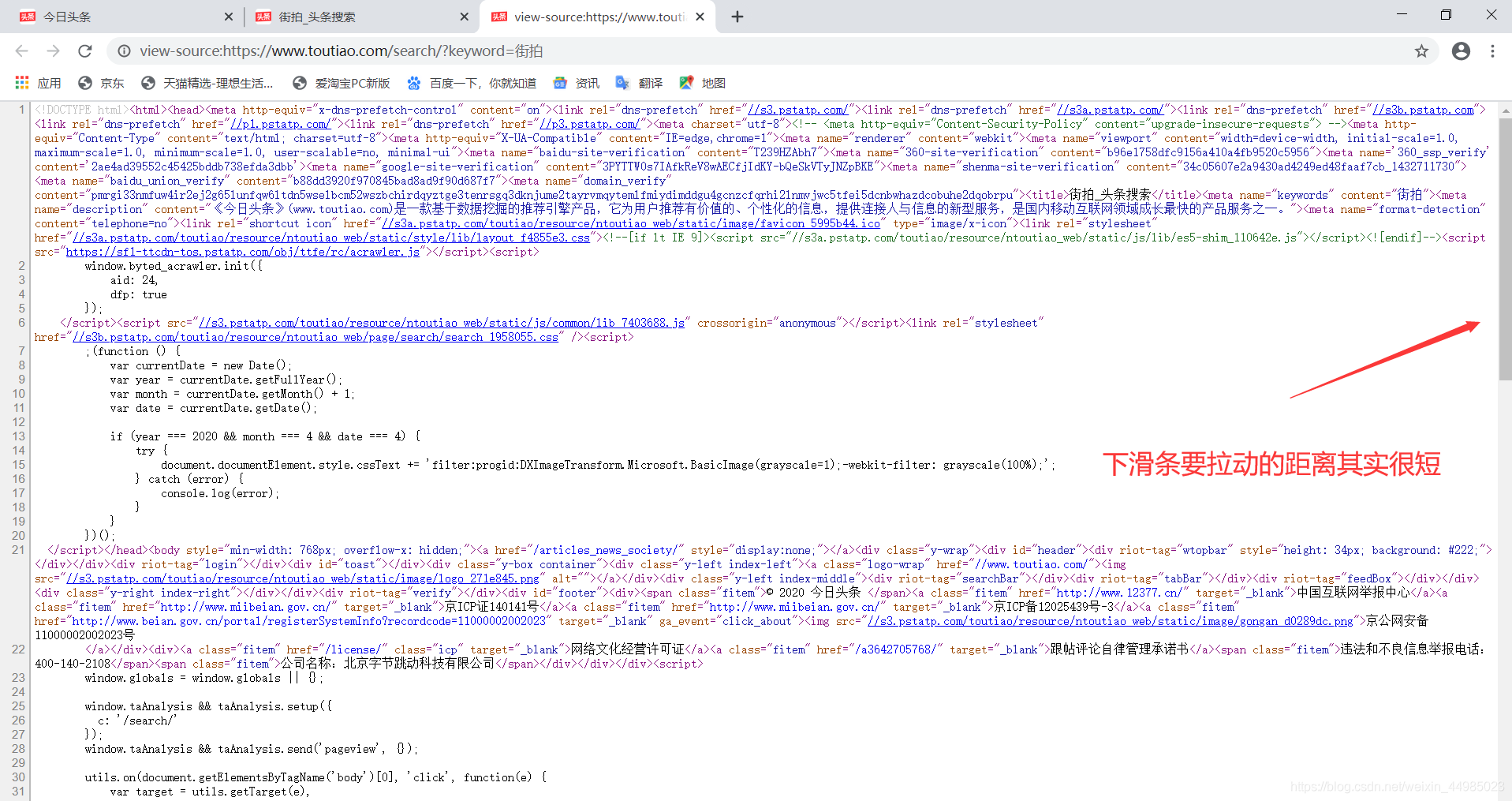 所以重點來了,想看資料在哪,我們如何定位呢?
所以重點來了,想看資料在哪,我們如何定位呢?
1、Chrome檢視的Ajax請求
開啟開發者工具,檢視所有的網路請求
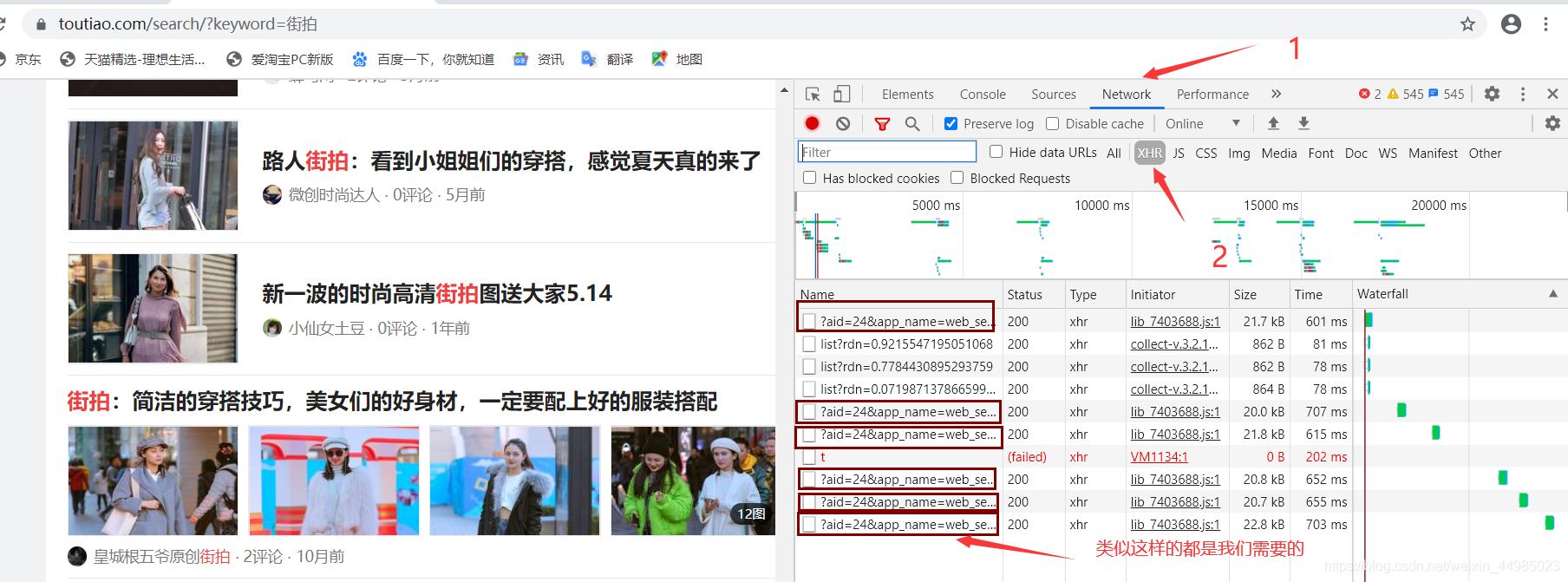
2、檢視URL內的資料
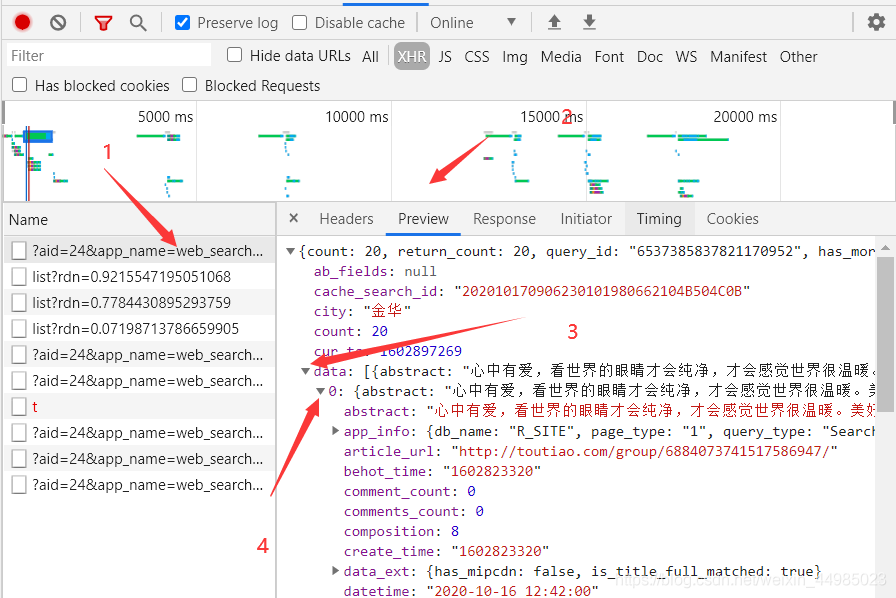
我們再data下面能夠找到title
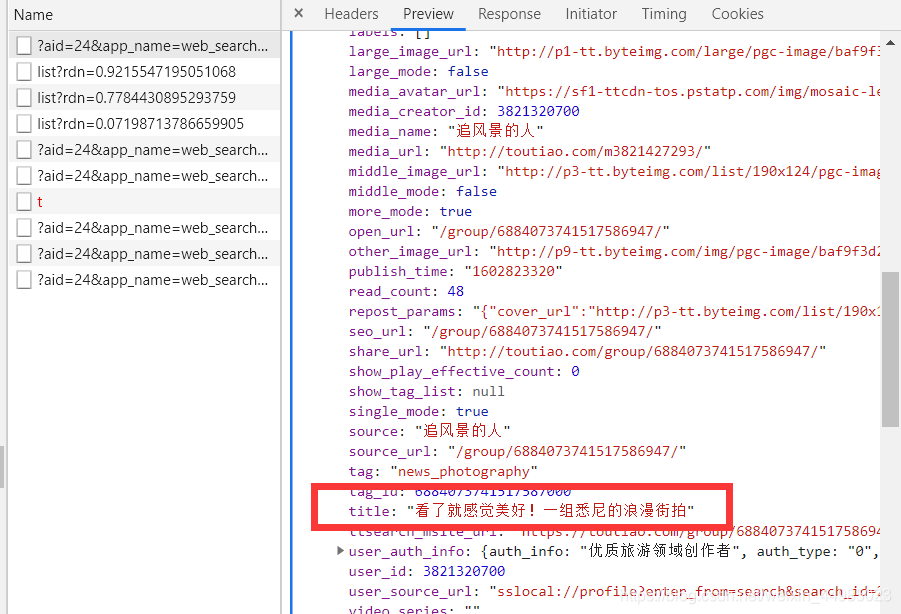 還能夠找到image_list,包含圖片的連結,也就是我們要爬取的圖片url。因此,我們只需要將列表中的url欄位提取出來並下載就ok了,每一組圖都建立一個資料夾,資料夾的名稱就為組圖的標題。
還能夠找到image_list,包含圖片的連結,也就是我們要爬取的圖片url。因此,我們只需要將列表中的url欄位提取出來並下載就ok了,每一組圖都建立一個資料夾,資料夾的名稱就為組圖的標題。
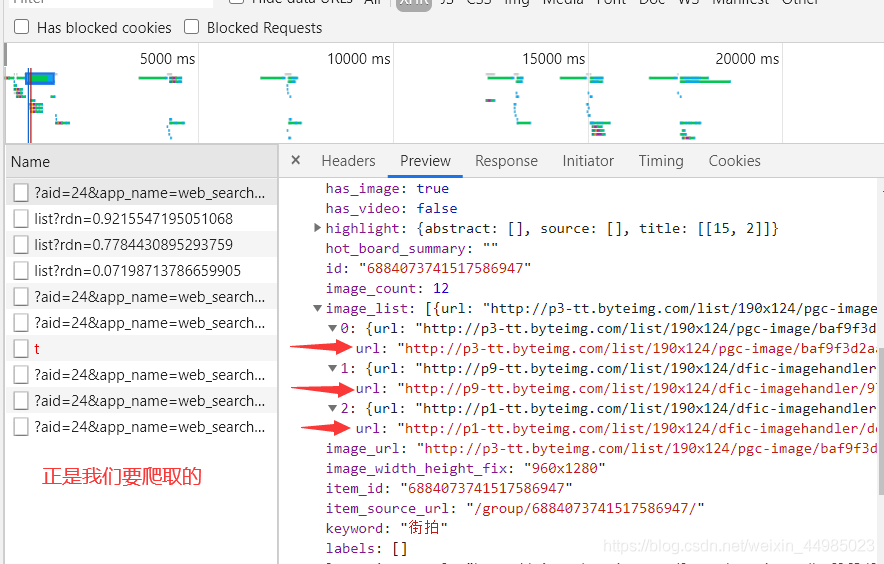 3、請求URL和Headers資訊找規律
3、請求URL和Headers資訊找規律
屬性位置的定位找到了以後,我們還需分析一下URL的變化規律。點選headers,觀察它的請求URL和Headers資訊,檢視第一個headers,紅框裡確實包含很多引數
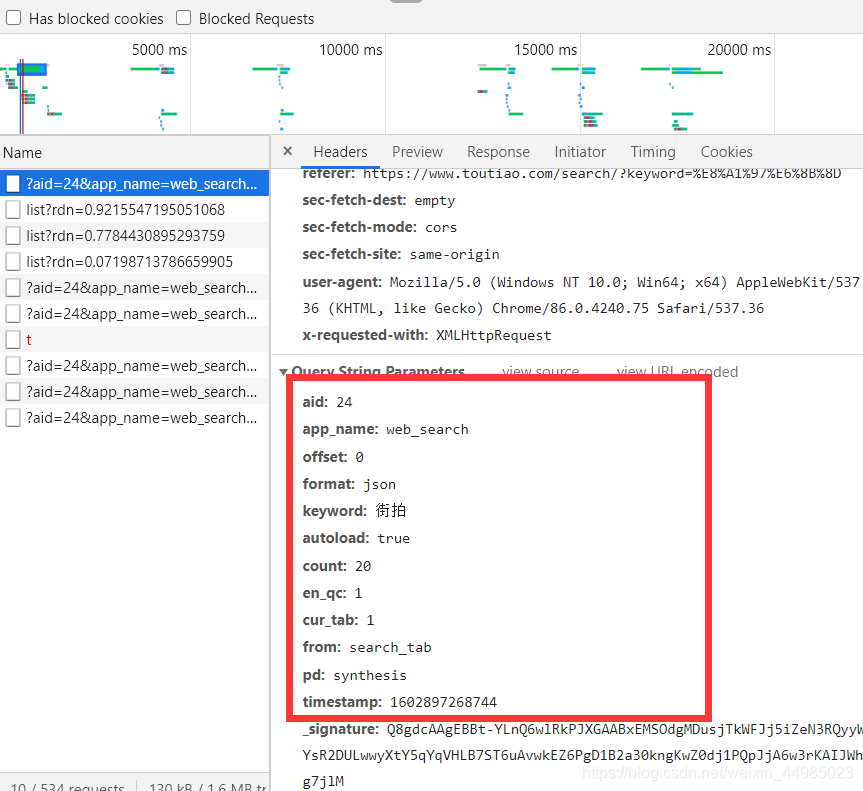
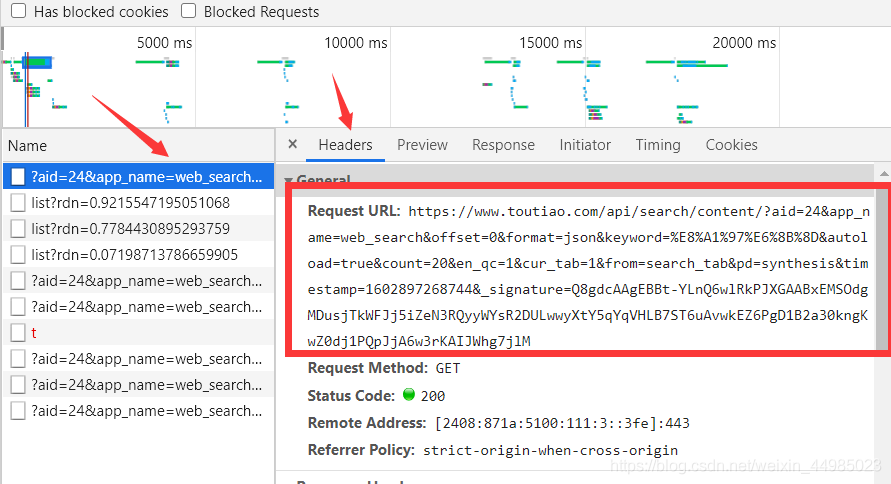 這麼多引數不用蒙圈,因為都在下面顯示好了
這麼多引數不用蒙圈,因為都在下面顯示好了
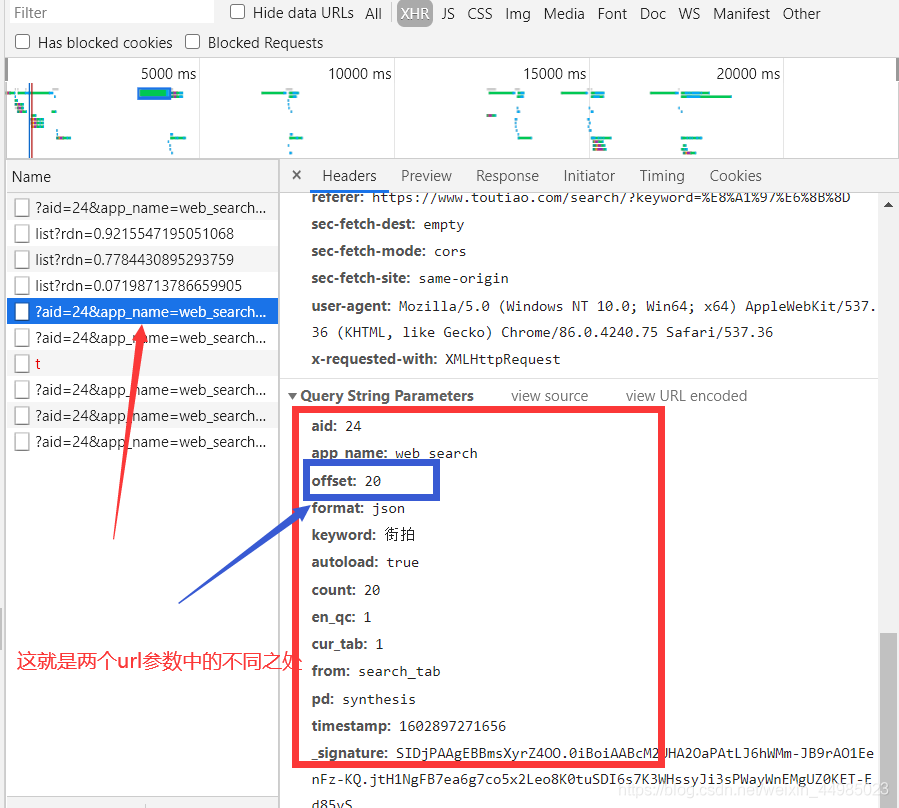
現在我們檢視第二個headers的url引數,發現有一個引數發生了變化,offest由0變成20
 我們再觀察第三個headers的url的引數
我們再觀察第三個headers的url的引數
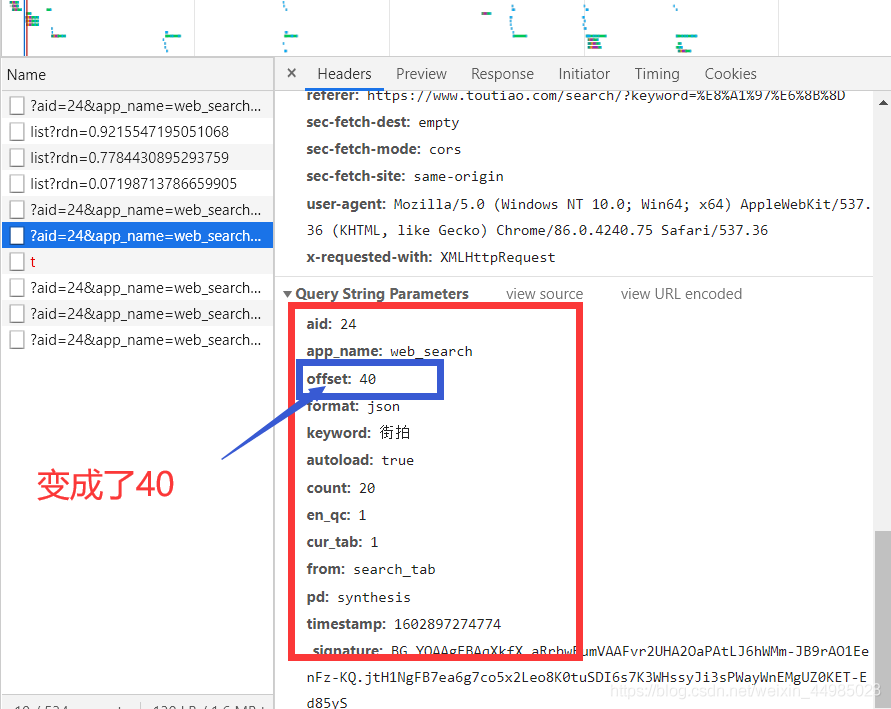 offest變成了40,所以不難發現,除了offest以外,其他引數都是不變的,只有offest發生變化,並且變化的規律為0、20、40、60…這樣的規律。所以說這個offset值就是偏移量,進而可以推斷出頁面每載入一次,獲取的資料條數為20。因此,我們可以用offset引數來控制資料分頁,通過這個介面批次獲取資料了,然後解析。
offest變成了40,所以不難發現,除了offest以外,其他引數都是不變的,只有offest發生變化,並且變化的規律為0、20、40、60…這樣的規律。所以說這個offset值就是偏移量,進而可以推斷出頁面每載入一次,獲取的資料條數為20。因此,我們可以用offset引數來控制資料分頁,通過這個介面批次獲取資料了,然後解析。
三、程式碼實現
1、導包
第一個包,主要目的是通過from urllib.parse import urlencode構造完整的URL。Urllib是python內建的HTTP請求庫,urllib.parse url解析模組。
第四個os模組主要和檔案路徑相關聯
第五個把字串換成MD5的方法
from urllib.parse import urlencode
import requests
import json
import os
from hashlib import md5
2、首先獲取請求並返回解析頁面
定義一個函數get_page()來載入單個Ajax請求的結果。由上述分析可知唯一變化的引數就是offset,所以我們將它當作引數傳遞進來。如果存取成功,狀態碼為200,最後返回的就是json格式的解析頁面
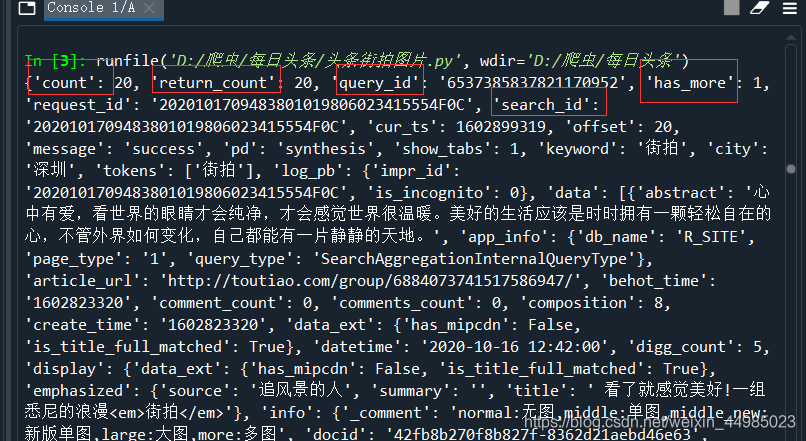
def get_page(offest):#獲取請求並返回解析頁面
params = {
'aid': '24',
'app_name': 'web_search',
'offset': offest,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': '1602563085392',
'_signature': 'LfFmxgAgEBBOl5xAwmvANy3wJ9AAHJ7m7oodN5ACyp.Hg2l3uBmMDqDDDN6rWnqjaV0akHlvj327I-FN9Xrxz9FT7hdlRtmAVGnGPJlX5zzT8tcamaIq51QEsm2ry1w0eu0'
}
url = base_url + urlencode(params)
try:
rq = requests.get(url,headers = headers)
if rq.status_code == 200 :
#print(rq.json())
return rq.json()
except rq.ConnectionError as e:
print('程式錯誤',e.args)
3、解析出data下的title和image_list的url
html為上面函數解析出來的json頁面資訊,我們作為引數傳進這個函數中,需先找到html下的data,再從data下找title和image_list.
def get_images(html):
if html.get('data'): #得到data下的全部內容
for item in html.get('data'): #用item迴圈每一條
#這裡需要判斷image_list是否為空
title = item.get('title')
if 'image_list' in item and item['image_list'] != []:
images=item['image_list']
for image in images:
yield{
'image': image.get('url'),
'title': title
}#返回一個字典
4、建資料夾存圖片
item為data下的所有內容
如果資料夾不存在,那麼就os.mkdir新建一個以title為名的資料夾,item.get(‘title’)中括號裡的title是上面那個函數返回的
‘image’: image.get(‘url’),
‘title’: title
把它定義成了title
如果我們成功存取了圖片的連結地址,那麼就可以圖片命名了,這裡用了雜湊演演算法(我下去還得好好再理解一下)。接下來如果資料夾裡面沒東西,就開啟資料夾寫入圖片response.content。
def save_image(item):
#os.path模組主要用於檔案的屬性獲取,exists是「存在」的意思,
#所以顧名思義,os.path.exists()就是判斷括號裡的資料夾'picture'+str(offset)是否存在的意思,括號內的可以是檔案路徑。
if not os.path.exists(item.get('title')):#判斷當前資料夾下是否有該檔案
os.mkdir(item.get('title'))#如果不存在就建立該資料夾
try:
response=requests.get(item['image']) #get函數獲取圖片連結地址,requests傳送存取請求,上面那個字典
if response.status_code==200:
file_path='{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
# md5摘要演演算法(雜湊演演算法),通過摘要演演算法得到一個長度固定的資料塊。將檔案儲存時,通過雜湊函數對每個檔案進行檔名的自動生成。
# md5() 獲取一個md5加密演演算法物件
# hexdigest() 獲取加密後的16進位制字串
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
print('Downloaded image path is: ', file_path)
else:
print('Already Dowloaded',file_path)
except requests.ConnectionError:
print('Failed to Save Image')
5、主函數呼叫
先存如兩頁的圖片
if __name__ == '__main__':
base_url = 'https://www.toutiao.com/api/search/content/?'
headers = {
'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
for offest in range(0,40,20):
html = get_page(offest)
a=get_images(html)
for item in a:
save_image(item)
for i in a:
print(i)
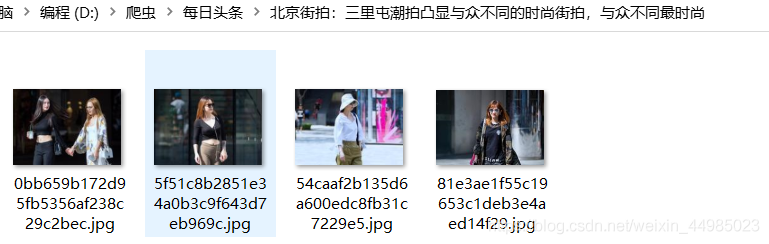
四、結果展示
我把存入的過程依次輸出
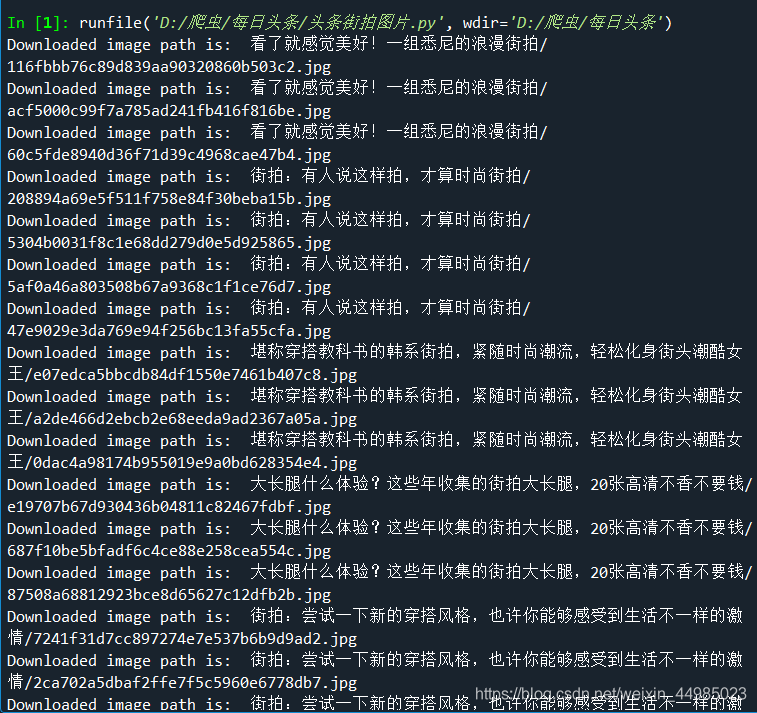 檢視檔案!
檢視檔案!