一文教你用Spider製作簡易的翻譯工具
大家好,我是不溫卜火,是一名計算機學院巨量資料專業大三的學生,暱稱來源於成語—
不溫不火,本意是希望自己性情溫和。作為一名網際網路行業的小白,博主寫部落格一方面是為了記錄自己的學習過程,另一方面是總結自己所犯的錯誤希望能夠幫助到很多和自己一樣處於起步階段的萌新。但由於水平有限,部落格中難免會有一些錯誤出現,有紕漏之處懇請各位大佬不吝賜教!暫時只在csdn這一個平臺進行更新,部落格主頁:https://buwenbuhuo.blog.csdn.net/。
PS:由於現在越來越多的人未經本人同意直接爬取博主本人文章,博主在此特別宣告:未經本人允許,禁止轉載!!!

嗯!請原諒博主最近的不守時。至於原因嘛~ 由於前段時間的瘋狂透支,現在博主真的有點相形見絀了。有句話完美驗證了博主如今的情況:真的一滴也沒有了 -。- 在此,博主只想說:少年不知xx貴,老來望x空流淚啊 ! 啊不好意思開車了 0.0
雖然精力有所不濟,可能更新速度會比以往有所下降。但是博主在此保證,斷更是不可能的,這輩子都不可能斷更的。這段時間可能會先暫停更新Scrapy_Spider部分,先更新Spider_Web的一些小demo給大家,至於為什麼暫停更新Scrapy_Spider這一部分?別問,問就是沉澱 -。-
哈哈哈,好了,廢話不再多說。下面正片開始… …
在開始進行製作簡易的翻譯工具之前,我們需要先明確我們用那個翻譯的介面。
博主本次所選擇的是百度翻譯的介面。
下面為百度翻譯的網址:https://fanyi.baidu.com/
但是,我們通過檢視網頁結構,我們發現這個網址並不是我們所需要的,那麼我們就需要尋找介面了。
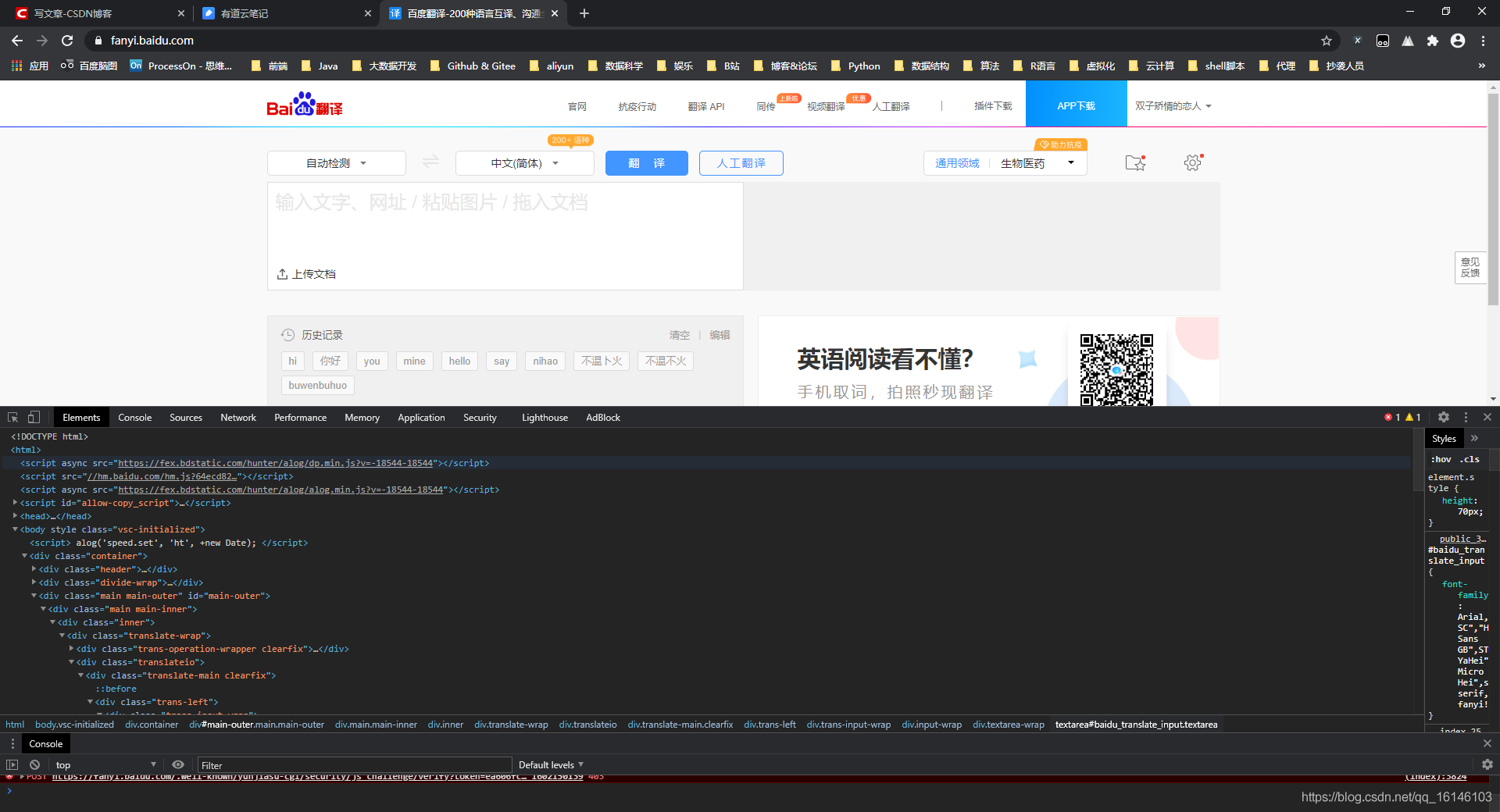
一. 獲取百度翻譯的請求介面
- 1.開啟瀏覽器 F12 開啟百度翻譯網頁原始碼
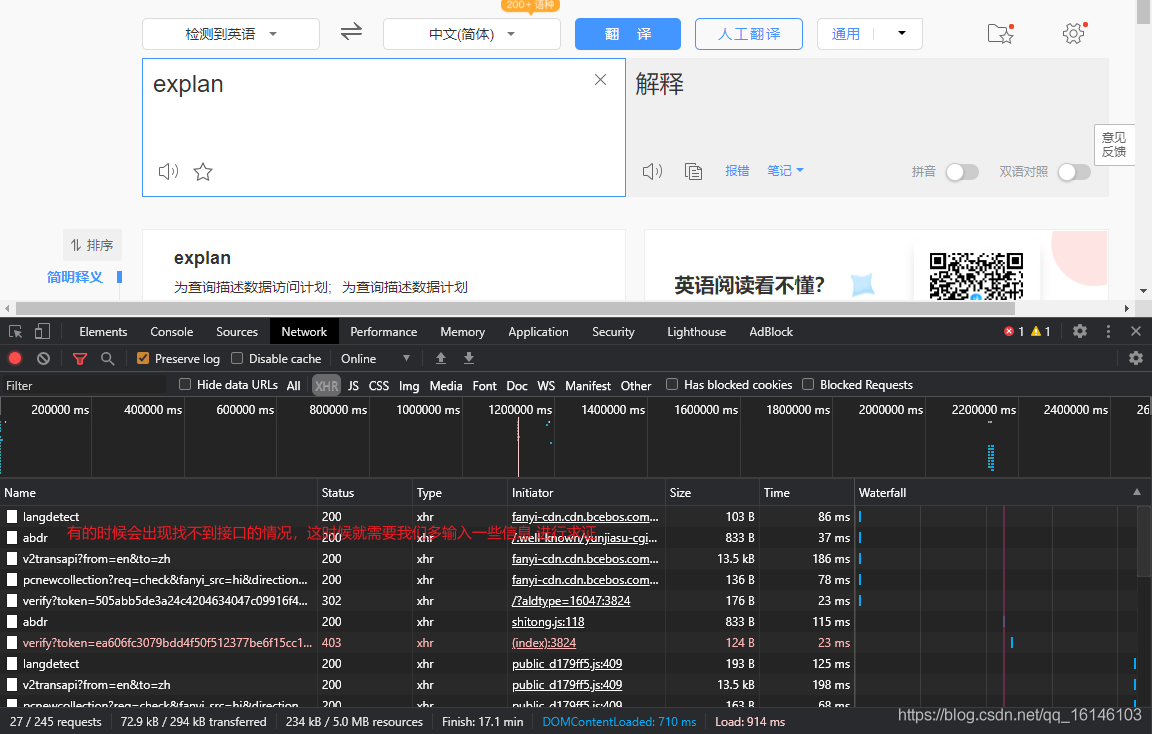
如果出現上圖情況,我們多輸幾次就能夠出現https://fanyi.baidu.com/sug。如下圖:
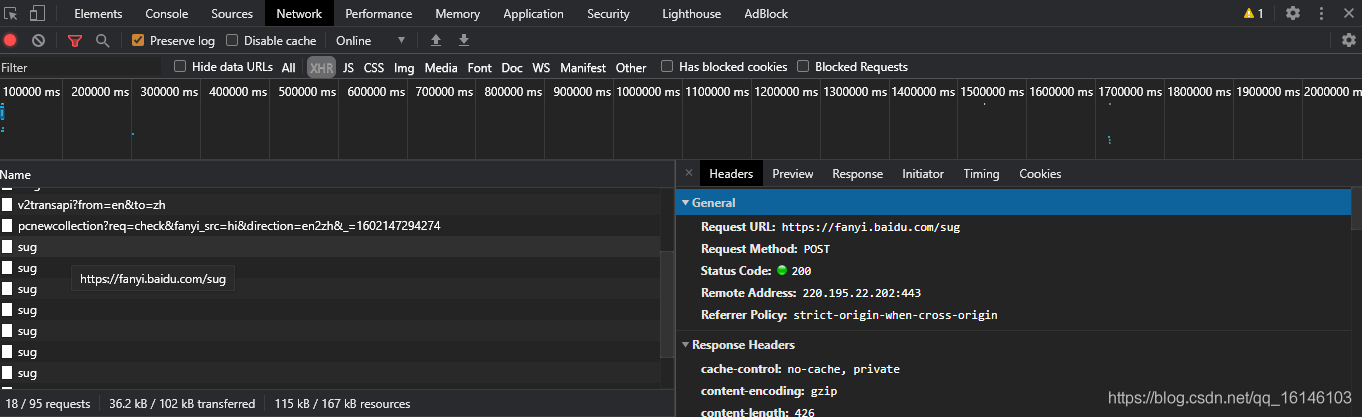
- 2. 從方法為POST的請求中找到引數為:kw:hi(hi是輸入翻譯的內容)

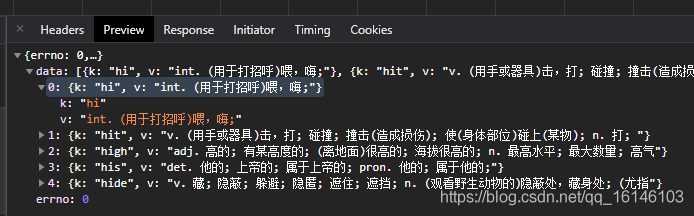
從上圖中我們可以很容易的看出data是一個列表,裡面儲存的為鍵值對,並且裡面有好幾個單詞及含義,而只有第一個是我們所需要的,那麼我們就可以去第一個鍵值對的值即可即:["data"][0]["v"])
二. 編寫思想
既然找到了介面,那麼接下來就要分析需要如何編寫程式碼了,編寫程式碼一般需要以下幾步:
- 1.首先我們需要設定一個請求頭,使其模擬成瀏覽器,這算是最基本的反扒手段
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
- 2.傳送post請求,獲取json,並將其轉成字典
#傳送post請求
response = requests.post(url=url,params=params,headers=headers)
#獲取返回內容,這裡是json,獲取json資料轉字典
content = response.json()
#獲取資料
print(content)

- 3. 獲取單詞意思
print(content["data"][0]["v"])

三. 原始程式及封裝修改程式
- 1. 原始程式
#!/usr/bin/env python
# encoding: utf-8
'''
@author 李華鑫
@create 2020-10-06 11:23
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: baidu翻譯.py
@Version:1.0
'''
import requests
url = "https://fanyi.baidu.com/sug"
data = {
"kw":input(">")
}
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
#傳送post請求
response = requests.post(url=url,data=data,headers=headers)
#獲取返回內容,這裡是json,獲取json資料轉字典
content = response.json()
#獲取資料
print(content["data"][0]["v"])
- 2.基本封裝的程式
#!/usr/bin/env python
# encoding: utf-8
'''
@author 李華鑫
@create 2020-10-06 11:23
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: baidu翻譯.py
@Version:1.0
'''
import requests
def baidufanyi():
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
#傳送post請求
response = requests.post(url=url,params=params,headers=headers)
#獲取返回內容,這裡是json,獲取json資料轉字典
content = response.json()
#獲取資料
# print(content)
print('*'*100)
print(content["data"][0]["v"])
# 遍歷列印出所有的查詢的單詞及相近單詞和註釋
# for k in content["data"]:
# print(k["k"],k["v"])
print('*' * 100)
if __name__ == '__main__':
while True:
# sug有些不出現,這時候需要多輸入些內容
url = "https://fanyi.baidu.com/sug"
params = {
"kw": input("請輸入單詞:")
}
baidufanyi()
- 3. 執行結果圖
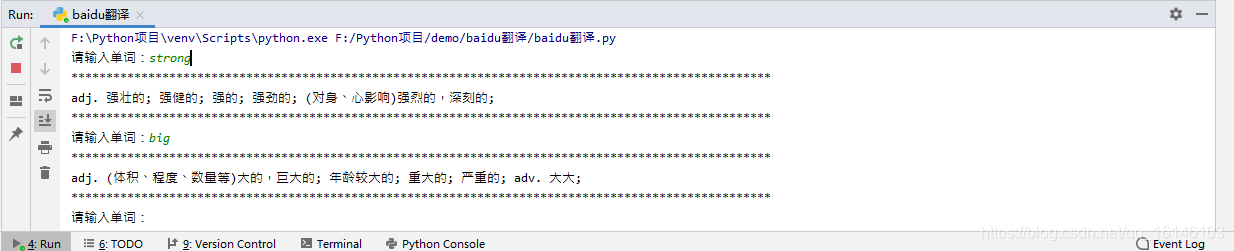
美好的日子總是短暫的,雖然還想繼續與大家暢談,但是本篇博文到此已經結束了,如果還嫌不夠過癮,不用擔心,我們下篇見!

好書不厭讀百回,熟讀課思子自知。而我想要成為全場最靚的仔,就必須堅持通過學習來獲取更多知識,用知識改變命運,用部落格見證成長,用行動證明我在努力。
如果我的部落格對你有幫助、如果你喜歡我的部落格內容,請「點贊」 「評論」「收藏」一鍵三連哦!聽說點讚的人運氣不會太差,每一天都會元氣滿滿呦!如果實在要白嫖的話,那祝你開心每一天,歡迎常來我部落格看看。
碼字不易,大家的支援就是我堅持下去的動力。點贊後不要忘了關注我哦!