【kimol君的無聊小發明】—用python寫圖片下載器
2020-10-09 16:00:42
Tip:本文僅供學習與參考,且勿用作不法用途~
前言
某個夜深人靜的夜晚,我開啟了自己的資料夾,發現了自己寫了許多似乎很無聊的程式碼。於是乎,一個想法油然而生:「生活已經很無聊了,不如再無聊一點叭」。
說幹就幹,那就開一個專題,我們稱之為kimol君的無聊小發明。
妙…啊~~~
網上爬蟲入門教學有很多,大多是從下載圖片開始~正經人誰不下載一下圖片呢,對叭?
kimol君也不例外,咱上圖瞧一瞧:
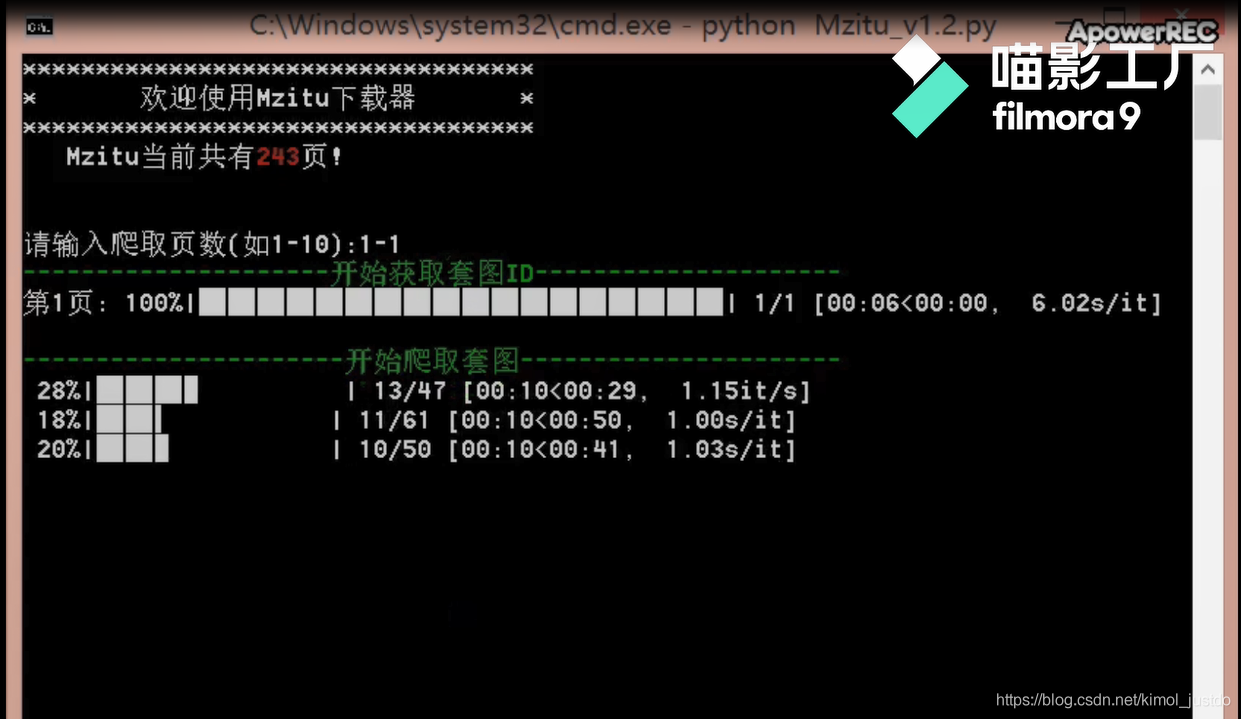
一、單執行緒版
關於該網站的爬取應該來說是比較入門的了,因為並沒涉及到太多的反爬機制,據目前來看主要有兩點:
- headers中Referer引數:其解決方法也很簡單,只需要在請求頭中加入這個引數就可以了,而且也不需要動態變化,固定為主頁地址即可。
- 請求速度限制:在實際爬取過程中我們會發現,如果爬取速度過快IP往往會被封了,而這裡我們只需要適當限制速度或者加入代理池即可。
具體的爬蟲分析,網上隨便一搜就是一堆,我這裡就直接獻上程式碼好了:
# =============================================================================
# Mzitu圖片爬取
# =============================================================================
import re
import os
import time
import queue
import requests
from tqdm import tqdm
from termcolor import *
from colorama import init
# 解決CMD無法顯示顏色問題
init(autoreset=False)
class spider_Mzidu():
def __init__(self):
# 定義請求地址
self.url_page = 'https://www.mzitu.com/page/%d/' # 搜尋頁面(用以獲取ID)
self.url_taotu = 'https://www.mzitu.com/%s' # 頁面(用以獲取圖片地址)
# 定義請求頭
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'Referer': 'https://www.mzitu.com',
}
# 定義正規表示式
self.p_id = '<span><a href="https://www.mzitu.com/(\d*?)" target="_blank">(.*?)</a></span>'
self.p_imgurl = '<img class="blur" src="(.*?)"'
self.p_page = '…</span>.*?<span>(\d*?)</span>'
# 儲存變數
self.queue_id = queue.Queue()
def getPages(self): # 獲取總頁數
res = requests.get(self.url_page%1,headers=self.headers)
html = res.text
N = re.findall('''class="page-numbers dots">[\s\S]*?>(\d*?)</a>[\s\S]*?"next page-numbers"''',html)[0]
return int(N)
def getID(self): # 獲取ID
page_range = input('請輸入爬取頁數(如1-10):')
p_s = int(page_range.split('-')[0])
p_e = int(page_range.split('-')[1])
time.sleep(0.5)
print(colored('開始獲取套圖ID'.center(50,'-'),'green'))
bar = tqdm(range(p_s,p_e+1),ncols=60) # 進度條
for p in bar:
res = requests.get(self.url_page%p,headers=self.headers)
html = res.text
ids = re.findall(self.p_id,html)
for i in ids:
self.queue_id.put(i)
bar.set_description('第%d頁'%p)
def downloadImg(self,imgurl): # 下載圖片
res = requests.get(imgurl,headers=self.headers)
img = res.content
return img
def parseTaotu(self,taotuID): # 解析"圖片數量",以及"圖片地址"
res = requests.get(self.url_taotu%taotuID,headers=self.headers)
html = res.text
page = int(re.findall(self.p_page,html)[0])
imgurl = re.findall(self.p_imgurl,html)[0]
imgurl = imgurl[:-6]+'%s'+imgurl[-4:]
return(imgurl,page)
def downloadTaotu(self): # 下載
while not self.queue_id.empty():
taotu = self.queue_id.get()
taotuID = taotu[0]
taotuName = taotu[1]
try:
imgurl,page = self.parseTaotu(taotuID)
path = '[P%d]'%page+taotuName
if not os.path.exists(path):
os.mkdir(path)
bar = tqdm(range(1,page+1),ncols=50) # 進度條
for i in bar:
url = imgurl%(str(i).zfill(2))
img = self.downloadImg(url)
with open('./%s/%d.jpg'%(path,i),'wb') as f:
f.write(img)
print('套圖("'+colored(taotuName,'red')+'")爬取完成')
except:
time.sleep(3)
self.queue_id.put(taotu)
def run(self): # 主程式
os.system('cls') # 清空控制檯
print('*'*35)
print('*'+'歡迎使用Mzitu下載器'.center(26)+'*')
print('*'*35)
N = self.getPages()
print(('Mzitu當前共有%s頁!'%colored(N,'red')).center(30))
print('\n')
self.getID()
print('\n'+colored('開始爬取套圖'.center(50,'-'),'green'))
self.downloadTaotu()
spider = spider_Mzidu()
spider.run()
二、多執行緒版
有小夥伴估計得問了:「單執行緒這麼慢?您是在開玩笑的叭,等得我不得憋壞咯?」
客官這邊請,來試試多執行緒版的好了:
# =============================================================================
# Mzitu圖片爬取(多執行緒)
# =============================================================================
import re
import os
import time
import queue
import requests
import threading
from tqdm import tqdm
from termcolor import *
from colorama import init
# 解決CMD無法顯示顏色問題
init(autoreset=False)
# 代理(XXX代理)
def Get_proxy():
res = requests.get('xxxxxxxxxxxxxxxxxxx')
html = res.text
return html
class spider_Mzidu():
def __init__(self):
# 定義請求地址
self.url_page = 'https://www.mzitu.com/page/%d/' # 搜尋頁面(用以獲取ID)
self.url_taotu = 'https://www.mzitu.com/%s' # 頁面(用以獲取地址)
# 定義請求頭
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'Referer': 'https://www.mzitu.com',
}
# 定義正規表示式
self.p_id = '<span><a href="https://www.mzitu.com/(\d*?)" target="_blank">(.*?)</a></span>'
self.p_imgurl = '<img class="blur" src="(.*?)"'
self.p_page = '…</span>.*?<span>(\d*?)</span>'
# 儲存變數
self.queue_id = queue.Queue()
#HTTP代理
proxy = Get_proxy()
self.proxies = {'http':'http://'+proxy,
'https':'https://'+proxy}
def getPages(self): # 獲取總頁數
res = requests.get(self.url_page%1,headers=self.headers,proxies=self.proxies,timeout=10)
html = res.text
N = re.findall('''class="page-numbers dots">[\s\S]*?>(\d*?)</a>[\s\S]*?"next page-numbers"''',html)[0]
return int(N)
def getID(self): # 獲取ID
page_range = input('請輸入爬取頁數(如1-10):')
p_s = int(page_range.split('-')[0])
p_e = int(page_range.split('-')[1])
time.sleep(0.5)
print(colored('開始獲取套圖ID'.center(50,'-'),'green'))
bar = tqdm(range(p_s,p_e+1),ncols=60) # 進度條
for p in bar:
res = requests.get(self.url_page%p,headers=self.headers,proxies=self.proxies,timeout=10)
html = res.text
ids = re.findall(self.p_id,html)
for i in ids:
self.queue_id.put(i)
bar.set_description('第%d頁'%p)
def downloadImg(self,imgurl,proxies): # 下載圖片
res = requests.get(imgurl,headers=self.headers,proxies=proxies,timeout=10)
img = res.content
return img
def parseTaotu(self,taotuID,proxies): # 解析的"圖片數量",以及"圖片地址"
res = requests.get(self.url_taotu%taotuID,headers=self.headers,proxies=proxies,timeout=10)
html = res.text
page = int(re.findall(self.p_page,html)[0])
imgurl = re.findall(self.p_imgurl,html)[0]
imgurl = imgurl[:-6]+'%s'+imgurl[-4:]
return(imgurl,page)
def downloadTaotu(self): # 下載
proxy = Get_proxy()
proxies = {'http':'http://'+proxy,
'https':'https://'+proxy}
while not self.queue_id.empty():
taotu = self.queue_id.get()
taotuID = taotu[0]
taotuName = taotu[1]
try:
imgurl,page = self.parseTaotu(taotuID,proxies)
path = '[P%d]'%page+taotuName
if not os.path.exists(path):
os.mkdir(path)
bar = tqdm(range(1,page+1),ncols=50) # 進度條
for i in bar:
url = imgurl%(str(i).zfill(2))
img = self.downloadImg(url,proxies)
with open('./%s/%d.jpg'%(path,i),'wb') as f:
f.write(img)
print('套圖("'+colored(taotuName,'red')+'")爬取完成')
except:
time.sleep(3)
proxy = Get_proxy()
proxies = {'http':'http://'+proxy,
'https':'https://'+proxy}
self.queue_id.put(taotu)
def changeProxy(self): # 更換代理
proxy = Get_proxy()
self.proxies = {'http':'http://'+proxy,
'https':'https://'+proxy}
def run(self): # 主程式
os.system('cls') # 清空控制檯
print('*'*35)
print('*'+'歡迎使用Mzitu下載器'.center(26)+'*')
print('*'*35)
N = self.getPages()
print(('Mzitu當前共有%s頁!'%colored(N,'red')).center(30))
print('\n')
self.getID()
print('\n'+colored('開始爬取套圖'.center(50,'-'),'green'))
# 多執行緒下載
N_thread = 3
thread_list = []
for i in range(N_thread):
thread_list.append(threading.Thread(target=self.downloadTaotu))
for t in thread_list:
t.start()
for t in thread_list:
t.join()
spider = spider_Mzidu()
spider.run()
細心的大大應該發現了,其實多執行緒版跟單執行緒版結構上幾乎沒有太大的差別(這裡也提供了一種程式碼思路,這樣使得如果我們以後想把原來程式碼改為多執行緒,可以更加方便快捷),主要是這兩點:
- 呼叫downloadTaotu()函數的時候,使用threading模組開啟多執行緒多次呼叫。
- 加入了HTTP代理模組。這裡大家可以酌情考慮是否保留,不過根據我測試發現,如果是使用多執行緒的話,建議大家還是加入代理,不然IP很可能被封。
寫在最後
如果大家對程式碼裡的進度條或者輸出的文字顏色感興趣,讓自己的程式碼輸出更風騷,大家可以參考這裡。(Python炫酷的顏色輸出與進度條列印)
文中如有不足,還望大家批評指正!
最後,感謝各位大大的耐心閱讀~
慢著,大俠請留步… 動起可愛的雙手,來個贊再走唄 (๑◕ܫ←๑)