HEVC中低複雜度量化技術
本文提出了一種HEVC中的低複雜度量化技術,並希望對新一代視訊編碼標準VVC有一定的啟發。
文章目錄
摘要
在HEVC中,率失真優化量化(RDOQ)在rate和distortion之間有著很好的折衷,這使得它在率失真效能方面有著很不錯的發展前景。但是,RDOQ在如今視訊編碼下的大量使用導致的結果就是大幅提升了複雜度。因此,基於這一點,本文對HEVC中的fast RDOQ和全零塊檢測進行了回顧,希望將來可以將兩者應用於VVC,從而減少其編碼複雜度,實現低複雜度量化。
提示:本文從以下幾個方面對低複雜度量化進行了全面剖析,主要從fast RDOQ和全零塊檢測兩個方面。
一、引言
相比於H.264,HEVC標準採用了更加有效的編碼工具。具體來說,HEVC採用靈活的塊樹結構來更好地適應視訊的區域性特徵,比如編碼單元、預測單元和變換單元。而且,HEVC的幀內預測模式從9種擴充套件到35種,來更好解釋複雜的紋理方向;同時採用一系列先進的幀間預測技術來消除時間冗餘。量化方面,硬決策量化(hard-decision quantization)慢慢演變成軟決策量化(soft-decision quantization),而且把率失真優化(RDO)準則加入到量化部分,由此對於各個係數可以得到更優的量化level。除此之外,還用CABAC來消除統計冗餘。
在量化方案中,由僅依賴輸入變換系數和量化步長的硬決策量化演變成基於RDO優化量化準則的軟決策量化。
其中,在早期廣泛使用的硬決策量化中,給定一個量化引數(QP),將變換系數對映到相應的量化level。在H.264中採用了帶dead-zone的硬決策量化,其中的舍入偏移量由殘差係數分佈來決定。
在軟決策量化中,確定量化level時,還要考慮一個變換塊(TB)的量化殘差之間的相互依賴性。也就是說,量化候選的RD cost會被認真處理評估,從而以這種軟決策量化確定的量化level可以在殘差的coding bits和量化失真之間達到極好的平衡。
研究表明,與傳統的帶有dead-zone的硬決策量化相比,軟決策量化在計算複雜度高的情況下可以節省6%~8%的位元率。然而,由於殘差coding bits應當是通過熵編碼來同步計算的,軟決策量化的高複雜度可能會對此帶來麻煩。
因此,已經有很多方案來實現視訊編碼中的軟決策量化。例如,在H.263+和H.264中,這種演演算法可以通過網格搜尋的方式來實現,簡單來說就是把每個量化候選的RD cost整合到網格分支中,通過動態規劃或維特比演演算法來確定最優路徑。但是,在量化中進行全網格搜尋具有極高的計算複雜度。鑑於此,網格搜尋被簡化為RDOQ,通過RDOQ可以實現次優量化。在H.264/AVC、HEVC和AVS2編碼器中已經廣泛應用了RDOQ,它可以檢測有限個數量的量化候選,最終使用ED cost最小的那一個。
本文主要闡述視訊編碼中的量化問題,這對平衡視訊編碼的失真程度和編碼位元具有重要意義。其中,快量化技術的目的就是以一種最有效的方式來得到最優量化係數。更具體的說,本文主要從兩個角度實現低複雜度量化。
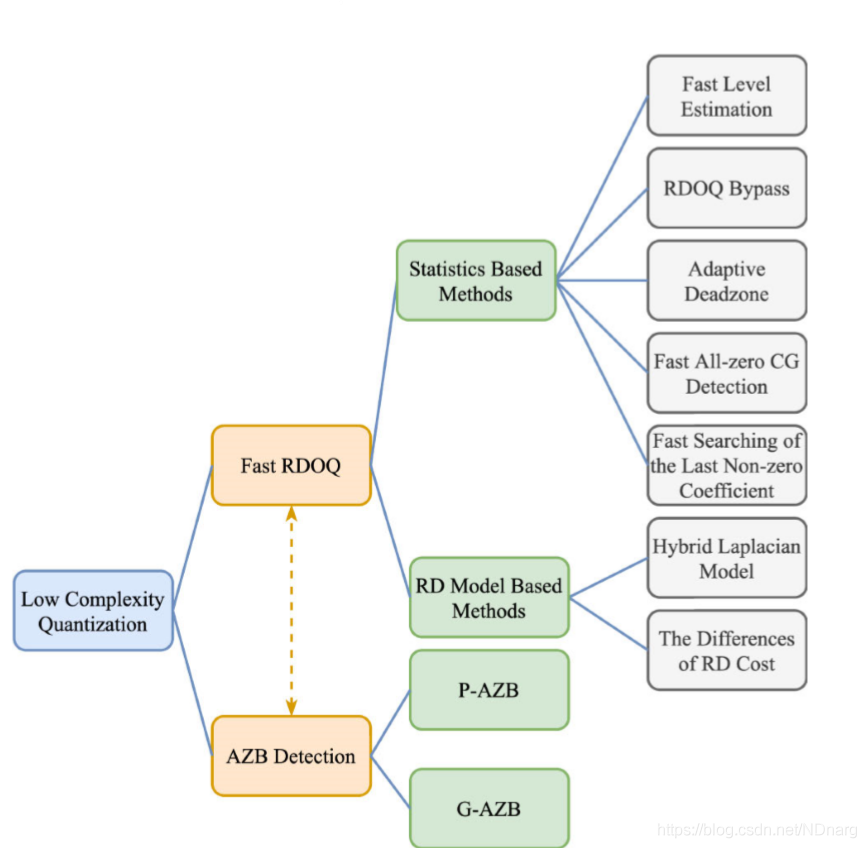
如上圖,大的來說,本文將從兩個角度研究低複雜度量化技術,也就是fast RDOQ和全零塊檢測。在fast RDOQ方面,主要介紹基於統計的方法和基於RD模型的方法。在全零塊檢測方面,主要從真全零塊(G-AZB)和偽全零塊(P-AZB)的不同檢測方法入手來研究。總之,從以上兩個大的角度入手來實現低複雜度量化,從而期望對新一代的VVC標準的量化優化方案有一定的幫助。
二、HEVC中採用的量化技術
這部分主要回顧HEVC標準中的量化技術。
硬決策量化可以表示如下,
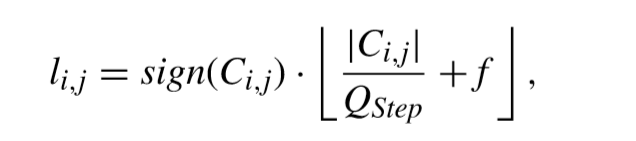
其中f表示舍入偏移量,一般根據slice型別設定。
軟決策量化中的RDOQ中,利用RDO準則來尋找最優量化係數。具體來說,RDO的目標就是在coding bits budget(R^)的約束下讓失真D儘可能的小,可以用下面的式子來表示,
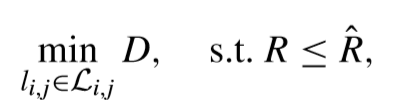
可以看出,上面的式子是在一定的約束條件下的,可以引入λ多項式來把這樣的有約束問題轉換為無約束問題,這樣上面的式子就變成了,
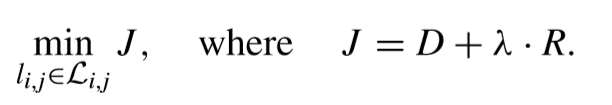
這樣,RDOQ可以根據上面式子來選擇最優量化level。再具體一點,在RDOQ中主要有兩個過程。
第一,對變換系數進行預量化,量化候選值如下,
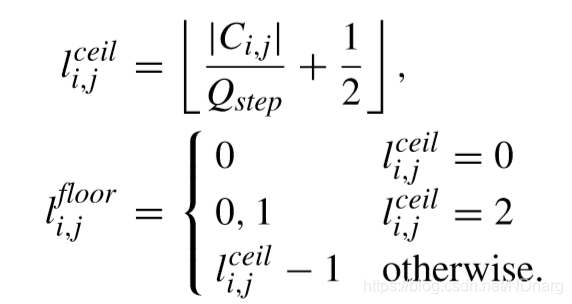
至此,最優量化可寫成,
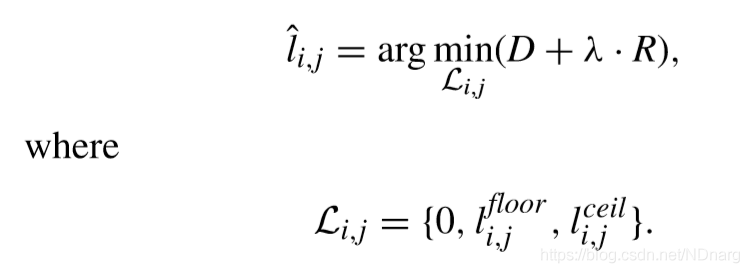
要知道的是,RDOQ和殘差熵編碼是基於CG(一個TB下的4x4的組)來實現的。
RDOQ的第二步,就是計算RD cost來確定當前CG能否量化為全零CG,同時,確定最後一個非零係數的位置,將之後位置的係數置零。
可以看出,RDOQ過程還是比較繁瑣的,為了加速RDOQ過程,一種方式就是加速量化過程,另一種方式就是檢測出全零塊,以跳過繁瑣的變換、量化、熵編碼、反量化和反變換過程。這也就是本文研究的兩個主要角度。
三、FAST RDOQ
RDOQ的目的就是確定一組最佳量化結果,使得TB的RD cost最小,這種方式儘管增加了計算複雜度,但是無疑會帶來壓縮效能方面的收益。本文主要有兩種方式來實現低複雜度RDOQ,一種是基於統計的方法,另一種是基於RD模型的方法。
1.STATISTICS-BASED FAST RDOQ
這種基於統計的方法主要是根據統計分析來跳過RDOQ過程來避免不必要的計算。
有一種比較特殊的塊即不包含DC係數的全量化零塊(AQZB-DC)可以被檢測,它佔據了非零塊的20%左右。再者,統計結果表明,在AQZB-DC塊中,超過30%的DC係數仍舊維持了l(i,j)ceil。因此,研究一種對於AQZB-DC塊的預測模型,它可以自適應調節DC係數的量化level。這樣的話,對於這種型別的TB,RDOQ過程可以直接跳過。
在遞迴TB劃分結構下重複呼叫RDOQ,這無疑會加重量化的計算負擔。因此,有研究提出將硬決策量化直接應用於TB,在獲得最佳TB大小後採用RDOQ。這種方法在low delay P設定下,BD-Rate僅損失0.25%就達到了27%量化複雜度的減少。
雖然RDOQ對於HEVC來說取得了極大效能的提升,但是,比起硬決策量化,它不能一直變化量化level。比如,如果當前TB在預量化之後是一個全零塊,那麼RDOQ就顯得沒有必要。再者,如果硬決策量化的量化結果和RDOQ的結果相同,那麼計算RD cost是相當浪費的。因此又有研究提出了基於變換系數統計的RDOQ bypass方案。根據統計實驗發現,當一個TB的所有變換系數比閾值(量化步長大小決定)小時,無需RDOQ,當前TB可以直接被認為是零塊。而且,當一個TB的絕對量化係數和比給定的閾值小時,表明非零係數佔據了比較小的一部分,那麼RDOQ將被跳過,並且硬決策量化將來優化編碼時間。
有研究提出了一種簡化RDOQ候選的選擇和最後非零係數搜尋的方案。特別地,來評估條件概率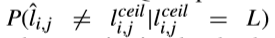 其中,L可能為1、2、3或者大於3。具有不同QP的隨機存取設定下的統計結果得出,當L>3時,這個條件概率平均值為4%,這表明,量化level在預量化的結果下很容易保持不變,因此可以跳過RDOQ。除此之外,對最後非零係數搜尋的簡化是在4x4TB上進行的,在此之上,其搜尋範圍縮小到了前四個非零係數。
其中,L可能為1、2、3或者大於3。具有不同QP的隨機存取設定下的統計結果得出,當L>3時,這個條件概率平均值為4%,這表明,量化level在預量化的結果下很容易保持不變,因此可以跳過RDOQ。除此之外,對最後非零係數搜尋的簡化是在4x4TB上進行的,在此之上,其搜尋範圍縮小到了前四個非零係數。
另有研究提出了一種早期量化level決策的方案,因為觀察到對於較大TB中位於高頻域的係數,RDOQ傾向於將量化level從「1」調整到「0」。這種方案讓量化level為0,而且沒有RDOQ過程,如下面式子所示,
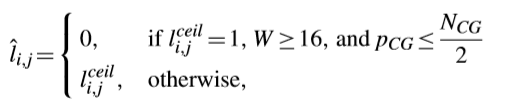
這種方案在all intra(AI)設定下節省了12.84%的量化時間,並且BD-Rate損失僅0.21%。另外,考慮到某些序列需要調整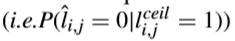
為70%以下,因此,相關人員建議在預量化階段採用自適應舍入偏移量來計算l(i,j)ceil。對於舍入偏移量f可以調整如下,
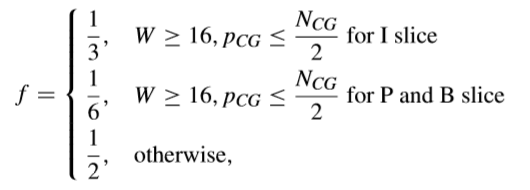
提出的這種自適應舍入偏移量在all intra設定下,實現了15.29%的量化時間節省,並且BD-Rate損失非常小(平均0.01%)。
2.RATE DISTORTION MODELS FOR FAST RDOQ
達到低複雜度RDOQ的關鍵就是建立一個精確的RD模型來估計RD cost。考慮到RDOQ是通過比較l(i,j)ceil和l(i,j)floor的RD cost來調整量化level,從而得到關於不同量化候選的RD cost差異。特別地,有研究用ΔJ估計模型制定了一種簡化的level調整方法,如下所示,
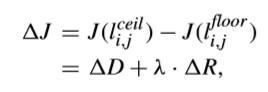
這裡ΔD表示如下,
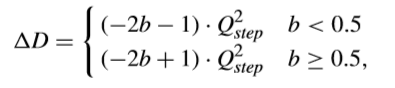
其中,b是l(i,j)float的小數部分。通過這種方式,可以放心大膽地移除反量化過程。而對於ΔR,可以表示如下,
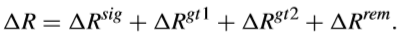
可以根據l(i,j)ceil的值推匯出前三個語法元素的ΔR。這四個語法元素的explicit值可以通過在HEVC測試模型中定義的查詢表來獲得。
有研究還為低複雜度RDOQ建立了ΔJ模型。通常,符號標誌的編碼位和用於表示最後有效係數的編碼位還包括在ΔR估計中。隨後,將之前等式中的ΔJ設定為0,可以得出閾值,
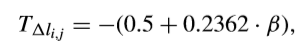
這樣的話,最佳量化level可以確定,如下所示,
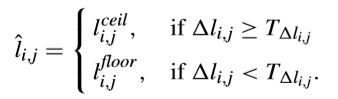
還有研究提出了針對HEVC編碼器的並行RDOQ方案,利用該方案可以在GPU上並行執行RDO程式,從而實現實時編碼4K序列。
除此之外,還有人提出用混合拉普拉斯分佈對變換系數進行建模。在HEVC中,使用四元樹結構,這使得TB大小從4x4到32x32變化,從而變換系數的分佈也截然不同。而提出的混合拉普拉斯分佈包含一系列具有不同引數的模型,這可以來適應不同TB尺寸的特徵。此外,在建模中考慮了4x4TU的變換型別,綠如DCT-II、DST-VII和變換跳過。混合拉普拉斯分佈可以用下式來表示,
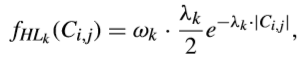
其中k表示TB層索引。第0層到第3層分別表示TB尺寸從32x32到4x4變化。第4層表示採用DST-VII變換。第5層表示採用變換跳過。
在量化失真建模方面,採用了硬決策量化的量化level,將反量化係數和原變換系數之間的SSE視為量化失真。以這種方式,可以得到每個量化候選的RD cost。最終,估算的最優量化結果可以將不同量化候選的RD cost最小化來得出,如下所示,
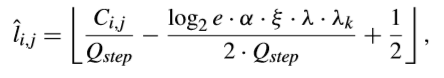
其中α是可以用於調整模型精度的訓練引數。
全零CG也可以根據下面的閾值來有效得出,
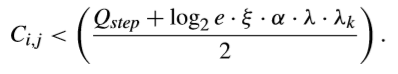
如果一個CG的所有變換系數都滿足上式,那這樣的CG也可以被認為是全零CG。
四、全零塊檢測
試想,在變換或量化之前儘早的檢測出全零塊對於優化編碼具有重要意義,因為檢測出全零塊可以省去像變換、量化、殘差編碼、反量化和反變換這樣的繁瑣步驟,到那個時候,這些步驟可以直接跳過,無疑減少了編碼複雜度。
對於全零塊的檢測,已經有很多方案。例如在H.264中,有一種方案就是用一種混合模型來檢測零係數。稍微具體來說,就是用高斯分佈對空間域殘差進行建模,然後用SAD來確定用於檢測零係數的閾值,為適應哈達瑪變換,用SATD代替SAD。
對於HEVC中全零塊的檢測,由於HEVC引入了大尺寸的TB(如16x16和32x32),這使得其全零塊的檢測更具有挑戰性,也就是說,H.264/AVC用於全零塊檢測的方法也許不能用於HEVC。
在HEVC中為了更好地與RDOQ過程協同,有一些研究專注於兩種型別全零塊的檢測,即真全零塊(G-AZB)和偽全零塊(P-AZB)。解釋一下,所謂真全零塊,是指通過硬決策量化可以直接將TB量化成全零塊;偽全零塊指那些通過RDOQ有可能量化成全零塊的TB。
下面仔細來介紹一下G-AZB和P-AZB的檢測。
對於G-AZB的檢測:
首先,之前提到的硬決策量化也可以寫成下面這樣的式子,
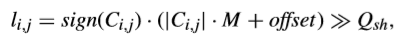
其中,M是與QP有關的多項式係數,offset是與slice型別有關的舍入偏移量,Qsh取決於QP、TB尺寸和編碼bit-depth。在G-AZB中,|li,j|應當是小於1的。因此,給出TB尺寸W和量化引數QP,對於某一個DCT係數Ci,j的檢測閾值可以寫成下面式子,
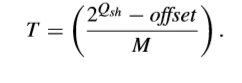
閾值T也被廣泛用於檢測全零塊。
還有相關人員提出了一種用於HEVC的混合全零塊檢測方法。起初,為減少計算複雜度,對於4x4和8x8的TU,用Walsh-order的哈達瑪變換來代替DCT變換,對於16x16和32x32的TU,用DCT變換。由此,提取不同TB大小的SATD*,可以得到兩個真全零塊的檢測閾值。
第一個檢測閾值,即在之前提到的閾值基礎上增加了一個係數W^2(W即TB尺寸),表示如下,
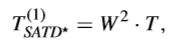
第二個對於G-AZB的檢測閾值可以通過用拉普拉斯分佈對預測殘差建模得到,表示如下,
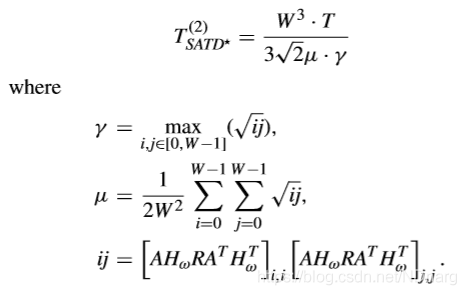
這樣,G-AZB的檢測閾值就可以取上面提到兩個閾值中較小的那一個來得到,即
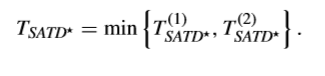
除此之外,還有人提出,基於全零塊檢測修改哈達瑪變換去更好適應HEVC的變換量化特徵。也就是說,對於不同尺寸大小的TB,G-AZB的檢測閾值也不同,即
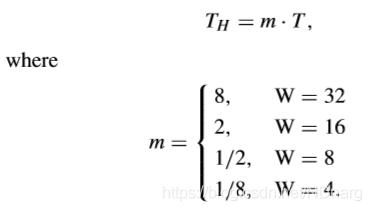
這樣的話,在HM平臺上,哈達瑪變換將被預設用於4x4和8x8的TU,即使更小的TU也不會額外帶來計算cost。然而,對於像16x16和32x32這樣大尺寸的TU,哈達瑪變換的計算cost是非常大的。因此,對於大尺寸的TU,哈達瑪變換系數應當統一一下。首先,把16x16和32x32的TU分成8x8的子塊,在每個這樣的子塊上用8x8的哈達瑪變換。然後,提取8x8子塊左上部分的DC係數,得到2x2和4x4的DC塊,再在DC塊上再一次使用哈達瑪變換(DC哈達瑪變換)。值得注意的是,每個8x8子塊的DC係數可以通過在空間域增加殘差來有效獲得。如果所有的係數均小於TH,那麼這個TB可以認為是一個全零塊。
基於之前提到的真全零塊的檢測閾值,又有人額外提出了一種較低和較高的SAD閾值來對全零塊和非全零塊進行分類。較低的閾值被設定為(d/100)·T,如果一個TB的SAD比這個較低的閾值小,那麼這個TB可以認為是真全零塊。而較高的閾值如下所示,
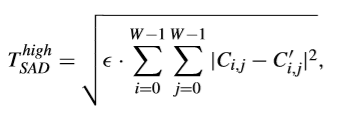
其中,€根據經驗定義如下,

至此,真全零塊的檢測就告一段落。
偽全零塊的檢測是在「非真全零塊」上進行的。本質上,P-AZB檢測的關鍵就是AZB的RD cost是否低於NAZB。RD cost可以表示如下,
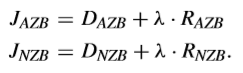
JAZB也可以寫成這樣,
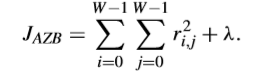
而對於DNZB可以寫成這樣,
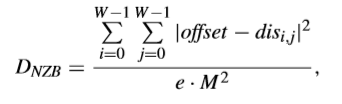
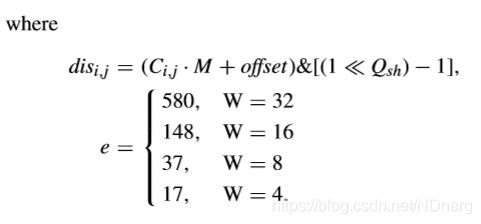
對於P-AZB的檢測,為更好地適應較大TU的特徵,TB將根據QP和QPmax分為高頻區域和低頻區域。低頻區域尺寸如下,
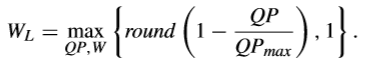
P-AZB的檢測實際上是在低頻區域進行的,如果低頻區域的最大變化係數比下面的閾值還要小,那麼這個TB可以認為是P-AZB,
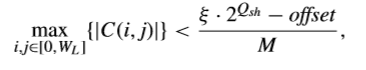
其中,kfei一般為2.2。
為更進一步研究P-AZB,需要進一步比較關於JAZB和JNZB的率失真效能。特別地,JAZB可以通過下面式子得到,
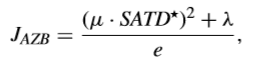
DAZB可以同通過訓練來得到,由此,匯出兩個確定區間來預測P-AZB。
五、率失真效能和編碼複雜度
這一部分主要討論fast RDOQ和全零塊檢測在RD效能和編碼複雜度方面所實現的效果。
其中,fast RDOQ在all intra(AI)、random access(RA)和low delay(LD)設定下進行評估。由於在AI設定下對於全零塊檢測效能評估較少,所以全零塊檢測效能評估主要在RA和LD設定下進行。
基於fast RDOQ的混合拉普拉斯分佈演演算法在編碼效能和計算複雜度上達到了很好的折衷,與傳統的RDOQ相比,它在僅增加0.3%BD-Rate的情況下節省了70%的量化時間。之前提到過的基於統計的fast RDOQ可以帶來30%到40%量化時間的減少。包括之前提到的對於 G-AZB的混合模型檢測的方法可以很精確地預測全零塊,在效能損失僅0.06%的情況下,達到了超過20%的時間節省的效果,據研究,這種混合模型檢測全零塊的方法在4K序列上以AI設定的方式也表現突出,量化時間節省了20%~26%,這對於4K視訊的量化有積極重要的意義!
六、討論
fast RDOQ和全零快檢測之間有著微妙的聯絡。他們的目的都是為了在找出最優量化level的前提下,實現減少RD cost計算複雜度的目的。由於前者是在係數上進行,後者在塊上進行,因此,它們必須一起協同起來,才能實現低複雜度量化優化的目的。
可以相信,用在HEVC上的fast RDOQ和全零塊檢測,在不久的將來,在VVC中也可以用到低複雜度的量化方式。提出幾點憧憬,第一,係數應該是低複雜度,對實際應用友好的;第二,對於VVC來說,這種低複雜度量化優化演演算法應當可以更好地適應網格結構;第三,RD模型應當是可以重複建立的;最後一點,希望在RD建模過程中也可以考慮多變換核選擇(MTS)。
總結
量化在現今視訊編碼中對於平衡位元速率和失真扮演著極其重要的作用。本文主要回顧了HEVC中的低複雜度量化技術,並且對與將來VVC中的量化優化做了簡單憧憬。本質上,快速量化技術依賴於最佳量化指標,從而不需要經過變化、量化、熵編碼、反量化和反變換這些繁瑣的步驟。有理由相信,近年來機器學習的興起,可以以一種低複雜度高效的方法來實現智慧地得到量化係數,這也會在率失真複雜度cost上大展宏圖。
注:本文是博主在研讀了一篇IEEE上Low Complexity Quantization in High Efficiency Video Coding論文後,自行總結,希望對大家有所幫助,謝謝!