流疊代器實現檔案操作(讀取和寫入)方法詳解
2020-07-16 10:04:31
檔案流
檔案流封裝了一個實際的檔案。檔案流有長度,也就是這個流中字元的個數,因此對於新的輸出檔案,長度就是 0;檔案流有起始位置,起始位置是流中索引為 0 的第一個字元的索引;檔案流也有結束位置,結束位置是檔案流中最後一個字元的下一個位置。檔案流還有當前位置,是下一個寫或讀操作的開始位置的索引。可以以文字模式或二進位制模式將資料轉移到檔案中或從檔案中讀出來。在文字模式下,資料是字元的序列。可以用提取和插入運算子來讀寫資料,至少對於輸入來說,資料項必須由一個或多個空格隔開。資料經常被寫成以 'n' 終止的連續行。一些系統,例如微軟的 Windows 系統,在讀寫時會轉換換行符。在讀到回車和換行符時,它們會被對映到單個字元 'n'。在另一些系統中,換行符被當作單個字元讀寫。因此,檔案輸入流的長度依賴於它們所來自的系統環境。
在二進位制模式下,記憶體和流之間是以位元組的形式傳送資料的,不需要轉換。流疊代器只能工作在文字模式下,因此不能用流疊代器來讀寫二進位制檔案。本章後面要介紹的流緩衝疊代器,可以讀寫二進位制檔案。
儘管在二進位制模式下,從記憶體中讀取和寫入的位元組從來不會改變,但當談到處理寫到不同系統中的二進位制檔案時,仍然會有很多陷阱。一個考慮是,寫檔案的系統的位元組順序和讀檔案的系統的位元組順序是相反的。位元組順序決定了記憶體中字的寫入順序。
在小端位元組序的處理器中,例如英特爾的 X86 處理器,最低位的位元組在最低的地址,所以位元組的寫入順序是從最底位元組到最髙位元組。在大端位元組序的處理器中,例如 EBM 大型電腦,位元的順序是相反的,最高位元組在最低位置,因此它們的檔案會出現和小端位元組序的處理器相反的順序。因此,當在小端位元組序的系統中讀來自於大端位元組序的系統中的二進位制檔案時,需要考慮位元組序的差別。
注意,大端位元組序也被稱為網路位元組序,因為資料一般是以大端序在網際網路上傳輸的。
檔案流類的模板
這裡有 3 個表示檔案流的類別範本:- ifstream:表示檔案的輸出流;
- ofstream:是為輸出定義的檔案流;
- fstream:定義了可以讀和寫的檔案流;
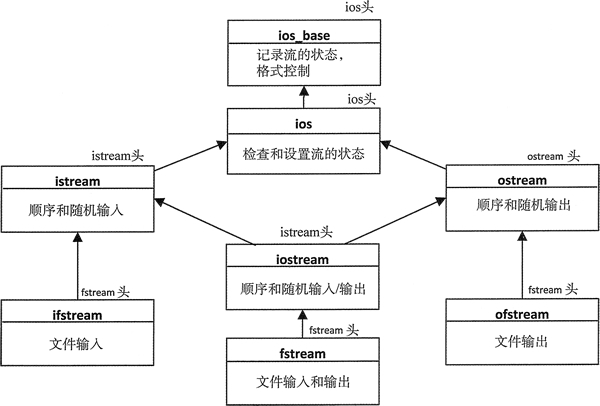
圖 1 表示檔案流的類別範本的繼承層次結構