3D CV 論文調研
3D論文調研
Introduction
本文對3D的分類,分割,檢測任務進行了調研。在調研的論文中,主要使用的是3D點雲資料,因為其包含的資訊更多,使得檢測,分類,分割等任務的結果更好。也因此大多數方法圍繞如何更好的提取點雲資料特徵而展開。這些方法可以大致分為兩類,一類是將點雲資料通過投影或者體素化等變換,然後利用折積神經網路進行特徵提取,另一類是直接提取點雲資料的特徵,這裡提取的特徵包括每個點雲資料自身的資料特徵,以及點雲與點雲之間相對位置等資訊特徵,然後通過下取樣等方式提取出全域性特徵。第一類方法由於點雲資料本身的稀疏性,通過投影或體素化轉換之後獲得的結構也具有稀疏性,使用稀疏折積等方式可以快速高效的提取特徵,因此,此類方法的速度一般較快,但是由於轉換過程會導致一部分資訊的丟失,精度不是很好。第二類方法恰恰相反,由於其對每個點雲資料以及點雲資料之間的關係進行特徵提取,其速度較慢但精度高。此外,為了兼顧速度和精度,有的論文將這兩類方法相結合,獲得了不錯的效果。通過這些方法提取到的特徵,可以通過一些操作進一步表徵,或者直接用於各類任務。下面將具體介紹各類任務中各種不同的方法。
文章目錄
- 3D論文調研
- Introduction
- 1、classification & segmentation
- 1.1 Point-based Methods
- 1.1.1 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
- 1.1.2 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
- 1.1.3 Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling
- 1.1.4 Momen(e)t: Flavor the Moments in Learning to Classify Shapes
- 1.2 Convolution-based Networks
- 1.3 Projection based
- 1.4 Graph-based
- 參考:
1、classification & segmentation
1.1 Point-based Methods
1.1.1 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
機構:Stanford University
倉庫:https://github.com/charlesq34/pointnet
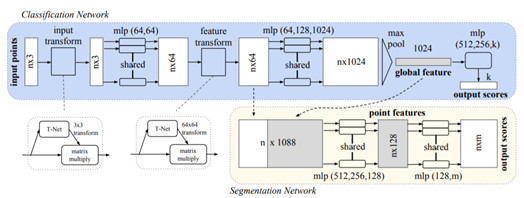
本文提出了一個可以直接提取點雲資料特徵的網路(PointNet)。由於點雲資料的無規則性,目前較多的處理方式是將其體素化,但是這會破壞一些點與點之間的聯絡。PointNet可以很好的解決這個問題,並且對輸入點雲資料中的一些干擾也具有很好的魯棒性。整個網路結構如圖1.1所示,其可以用於做分類和分割。這裡主要介紹分類網路。網路主要包括3個關鍵部分:the max pooling layer、a local and global information combination structure、two joint alignment networks。首先第一個部分主要是為了應對點雲的無序性。用數個MLP提取各個點雲的特徵,然後通過max pooling層進行初步特徵的降維和融合(這裡MLP + Max pooling的組合可以近似成一個對稱函數,應對點雲的無序性)。第二部分主要是為了分割部分,通過MLP + max pooling我們提取到了輸入點雲的全域性特徵(global feature),但是分割還需要一些區域性特徵,並且將其與全域性特徵相融合,因此第二部分主要完成這一步。第三部分是為了使得網路提取的特徵或者網路的分類結果不受點雲資料的幾何變化(rigid transformation)而改變。論文的思想很簡單,在提取特徵之前讓輸入與一個標準的空間對其,為了達到這一目的,論文使用了T-net對輸入先做一個變換。同時也對提取的特徵做了同樣的變換。上面淺藍色的部分為整個分類的網路框架。
1.1.2 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
機構:Stanford University
倉庫:https://github.com/charlesq34/pointnet2
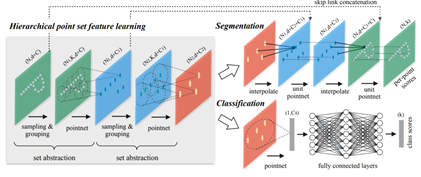
PointNet 的基本思想是學習每個點的空間編碼,然後將所有單個點特徵聚合到全域性特徵中。出於這一設計,PointNet 難以捕獲由度量(metric)引起的點的區域性結構,而區域性結構對摺積架構的成功有重要意義。我們知道 CNN 使用規則的輸入,在不同層應用不同的折積核,逐層次地提取特徵,更深的層擁有更大的感受野。通過層次結構抽象特徵能夠使網路在未知資料上具有更好的泛化能力。PointNet++ 對此做了改進。首先通過底層空間的距離度量將點集劃分為若干個區域性區域,使用 PointNet 在這些區域性區域中進行特徵提取。再以這些提取到的區域性特徵為單位,重複此過程,逐層抽象以產生更高階別的特徵,直到獲取整個點雲集合的全域性特徵。PointNet++ 的設計需要解決兩個問題:如何對點集進行區域性劃分(sampling & grouping),以及如何通過區域性特徵提取器(PointNet)來抽象點集或區域性特徵。
針對第一個問題,如何對點集進行區域性劃分。我們可以將每個區域性區域視作一個球體,其包括質心和半徑兩個引數。為了使選取的區域性區域均勻地覆蓋整個集合,作者使用 Farthest Point Sampling(FPS,最遠點取樣)來選擇質心。對於半徑的選擇,由於輸入點集的不均勻性,作者假設輸入點集在不同區域具有不同的密度。因此,PointNet++ 的輸入與 CNN 的輸入非常不同,CNN 的輸入可以看作是在具有均勻密度的常規網格上定義的資料(image 作為輸入其逐畫素之間是均勻的)。在 CNN 中,區域性區域的概念是通過 kernel 引入的,區域性區域的大小就對應於 kernel 的大小。因此,半徑就類似與 CNN 中使用的不同的步長(stride),而半徑的選擇需要依賴於(考慮)輸入資料和具體的度量。由於是以每個區域性區域為單位進行特徵提取,所以半徑的大小也決定了感受野的大小。作者僅以經驗表明,雖然在 CNN 中較小的折積核尺寸得到的效果越好,而在點雲資料中該結論是相反的。由於取樣不足,較小的領域可能包含太少的點,這可能不足以讓 PointNet 魯棒地提取資訊(在 query ball 中,半徑0.1,近鄰點64個,knn中k也是64,使用的是同樣的引數nsample)。針對第二個問題,我們已經知道 PointNet 能夠高效地對無序的點雲資料進行特徵提取,而且對輸入資料有很好的魯棒性。PointNet++ 中以 PointNet 作為區域性特徵提取器,將 PointNet 作為一個基礎的模組,將區域性點(特徵)抽象為更高層次的表示。可以理解為 PointNet++ 分層地對輸入中的區域性特徵應用 PointNet 進行特徵提取。網路的結構如下圖所示,其中一個SA結構包括先sampling和grouping,然後通過pointnet對每個區域性區域進行特徵提取。通過多個SA結構逐漸獲得高階特徵(global feature),然後用於分類。分割任務因為還需要各個點區域性的資訊,因此結合使用了插值和skin link跟之前的低階特徵相結合。
1.1.3 Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling
機構:上海交大MoE實驗室和華為諾亞方舟實驗室
倉庫:
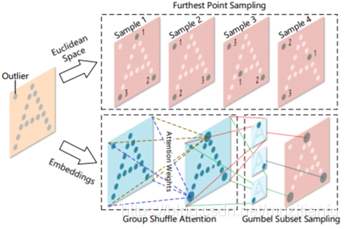
本文主要改進了PointNet++中的FPS的部分,使得選取的點更能處理外點,將down sampling的點選取在attention score大的點上。很形象的對比如圖1.3:
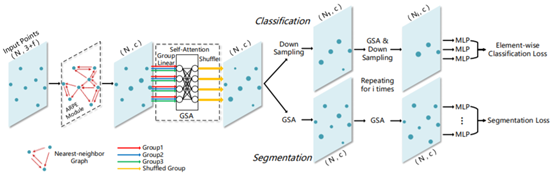
整個的網路結構如圖1.4所示,該結構中主要有三個重要的模組,ARPE module,GSA和GSS。ARPE module(Absolute and Relative Position Embedding)對top K(Nearest-neighbor Graph)點雲利用類似於PointNet的結構進行特徵提取。GSA模組主要是引入了注意力機制,可以更好的捕獲點與點之間的關係。GSS(一種下取樣方法) 用在GSA之後,通過使用Gumbel Softmax進行計算每個點的重要程度,然後根據這個概率選取down sampling的點。分類任務中,不斷地使用GSA和down sampling,最後對最終剩下的點使用MLP提取特徵,並使用average pooling得到分類結果。對於分割任務則一直使用GSA,最後對每個點使用MLP得到其對應的score。
1.1.4 Momen(e)t: Flavor the Moments in Learning to Classify Shapes
機構:Technion - Israel Institute Of Technology
倉庫:
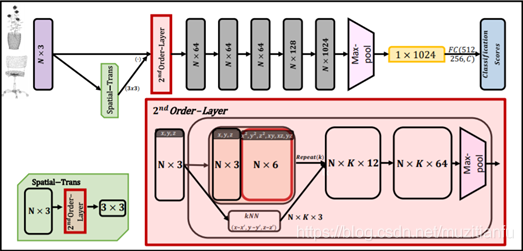
本文章提出的方法簡單,基本上就是增加網路的輸入,相比於pointnet++。其將網路的輸入由點的座標(x,y,z)增加到(x,y,z,x2,y2,z2,xy, xz, yz)。基本網路如圖1.5所示。可以從2nd Order-Layer 詳細網路中看到,其實與Pointnet++非常相似,無非就是還做了人工構造了2nd Order的特徵。具體的Spatial-Trans中也加入了2nd Order-Layer。最後的效果證明,在ModelNet40的資料集上,效果很好。
1.2 Convolution-based Networks
1.2.1 Pointwise Convolutional Neural Networks
機構:The University of Tokyo,Singapore University of Technology and Design
倉庫:https://github.com/hkust-vgd/pointwise
本文是Discrete Convolution Networks其中一類的代表:對中心點附近的區域進行區域劃分,每個區域內計算一個aggregated feature。區域固定,相當於得到了固定的grid,然後用固定的折積核去折積就可以了。這種權重域是離散的,就像普通的2D Convolution。離散折積公式如下:
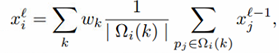
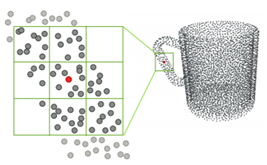
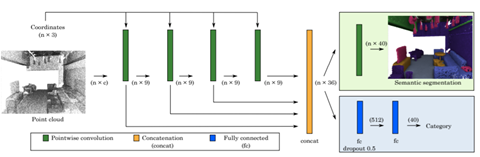
結合圖1.6可知,其將中心點附近的區域分成柵格,每個柵格內的特徵先相加然後用密度歸一化,最後再乘以柵格內的折積權重得到,得到一個柵格的特徵,多個柵格的特徵相加得到新的特徵。整個的網路結構如圖1.7所示,其首先用離散折積提取點雲資料的特徵,並最後將低階和高階的特徵相融合用於最終的分割和分類。
1.2.2 PointCNN: Convoution On X-Transformed Points
機構:華為,山東大學,北京大學
倉庫:https://github.com/yangyanli/PointCNN
本文主要介紹了一種 chi-transformation,該變換可以解決點雲的無規則性問題。我們希望點雲資料輸入的順序對最後的結果沒有影響。該變換與PointNet中的T-Net類似,T-Net是為了消除幾何變換對點雲的影響,而chi變換是為了保證不受點雲順序的影響。其變換的實現方式,也與T-Net類似,使用MLP實現,也就是使用FC層。在完成了chi變換之後,就可以對feature做Convolution,。下表1.1為PointCNN的演演算法。
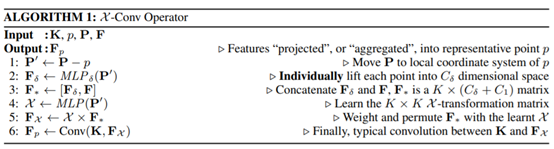
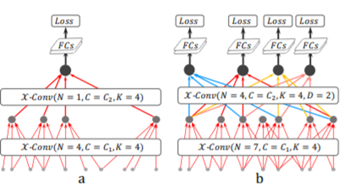
PointCNN的分類網路如圖1.8所示所示,比較簡單,首先使用chi-conv提取特徵,然後用全連線層進行分類。
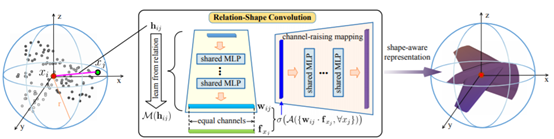
1.2.3 Relation-Shape Convolutional Neural Network for Point Cloud Analysis
機構:中科大
倉庫:https://github.com/Yochengliu/Relation-Shape-CNN
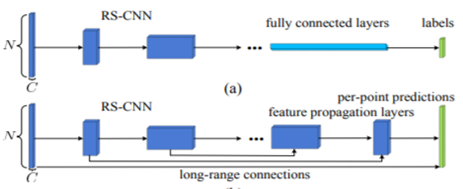
本文主要提出一種新的RS-Conv(Relation-Shape Conv),可以直接提取點雲資料中個點雲之間的位置關係特徵。同時該RS-Conv也滿足處理點雲資料需要的特性:即點雲輸入順序的不變性,點雲資料剛性變換的不變性等。RS-Conv的具體實現如圖1.9所示所示,hij表示點雲資料xi和xj之間的距離關係,通過共用權重的MLP將其轉換為wij特徵,並將特徵融合,然後再利用共用的MLP向高維特徵(chanel raising)轉化。這便是一個RS-conv的實現。最終RS-CNN通過使用多個RS-Conv提取特徵,然後用於分類和分割。如圖1.10所示。
1.2.4 KPConv: Flexible and Deformable Convolution for Point Clouds
機構:Mines ParisTech,Facebook AI Research,Stanford University
倉庫:https://github.com/HuguesTHOMAS/KPConv
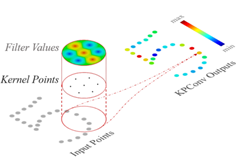
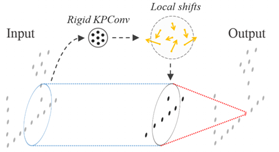
本文提出了一種高效提取點雲特徵的KP-Conv,具體包括兩種,rigid和deformable。並以KP-Conv為基礎構建KP-CNN和KP-FCNN完成點雲資料的分類和分割任務。Rigid KP-Conv如圖1.11所示,kernel中的每一個點對應一個權重Wk,然後計算input中的每個點與kernel中的點的距離,通過距離的遠近與kernel中的所有的Wk進行加權求和得到每個點最後的權重。Deformable KP-conv如圖1.12所示,其filter中各點的權重不是固定的,各點每次會生成一個偏移量(offset),然後將這個偏移量加在各點的權重上再做折積操作。這個偏移量是通過rigid KP-Conv獲得,因為先用rigid KP-Conv可以獲得filter中各點的權重,然後以此權重來作為deformable KP-Conv的偏移量。
1.3 Projection based
1.3.1 Multi-view Convolutional Neural Networks for 3D Shape Recognition
機構:University of Massachusetts, Amherst
倉庫地址:https://github.com/suhangpro/mvcnn
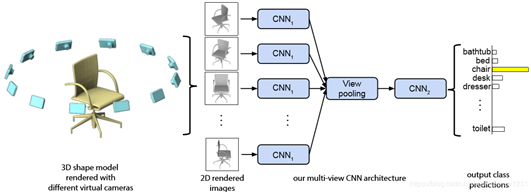
MVCNN將點雲投影到不同的視角下,每個投影可以使用CNN進行特徵的提取,然後將所有CNN提取的進行融合。論文闡述了該方法比直接使用3D的資料進行訓練結果要好,並且精度隨著投影的個數增加而提高。其網路框架如圖1.13所示。
1.3.2 RotationNet: Joint Object Categorization and Pose Estimation Using Multiviews from Unsupervised Viewpoints
機構:National Institute of Advanced Industrial Science and Technology (AIST)
倉庫:https://github.com/kanezaki/rotationnet
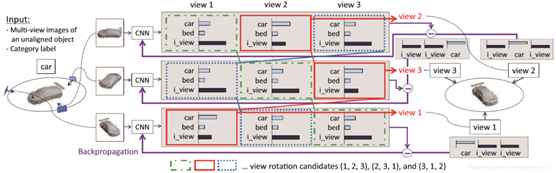
相比於MVCNN,RotationNet使用了更多的視角,並在處理了每個視角的關係。其網路結構如圖1.14所示。
1.3.3 VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition
機構:Robotics Institute, Carnegie Mellon University
倉庫:https://github.com/skyhehe123/VoxelNet-pytorch
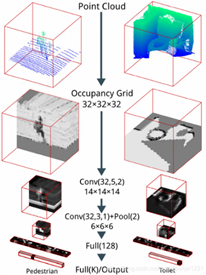
該論文把點雲投影為佔據柵格,然後使用3D CNN進行特徵提取,並給出分類的結果,網路結構如圖1.15所示。
1.4 Graph-based
1.4.1 Dynamic Graph CNN for Learning on Point Clouds
機構:Massachusetts Institute of Technology
倉庫:https://github.com/WangYueFt/dgcnn
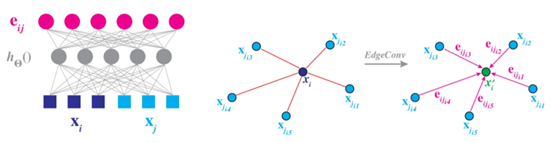
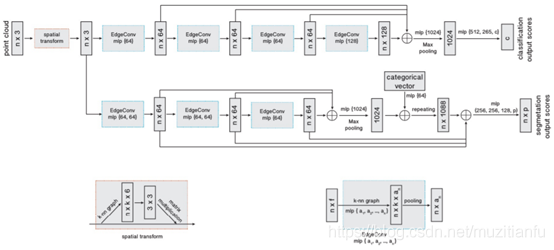
本文在PointNet的基礎上,提出了一種新的計算點雲中點的feature的演演算法,提升了點雲分類、分割等任務的效能。具體來說,論文提出了兩個新的概念:EdgeConv和Dynamic Graph。用EdgeConv替代PointNet中的MLP便可以得到論文提出的DGCNN網路。而在每次計算EdgeConv時,都需要更新一下graph。下面分別介紹EdgeConv和Dynamic Graph。 EdgeConv主要實現對點雲中節點的feature的更新操作,改進了PointNet中缺少區域性資訊的缺點。作者提出的edgeConv在計算(更新)每個點的特徵時,不僅考慮這個點當前的特徵,還考慮了在當前的特徵空間內,與當前點距離最近的K個點的特徵。在特徵空間內與目標點臨近的K個點,可以在小範圍內構成一個小的區域性圖,從中計算出來的資訊,可以認為是一種區域性feature。讓全域性特徵和區域性特徵共同來影響每個點特徵的更新。而隨著特徵空間的變換,每個點相鄰的K個點也在發生變化,因此需要對每個點相鄰點進行更新,也就是所謂的dynamic graph。如果把KNN找到的點,看作是receptvie field,那麼深層網路處,由於每層KNN的結構都不同,每個點的receptvie field會越來越大。直覺上,這種方式可能更有利於全域性feature的學習。DGCNN的網路結構如圖1.17所示。
1.4.2 Grid-GCN for Fast and Scalable Point Cloud Learning
機構:University of Southern California ,圖森未來
倉庫:https://github.com/Xharlie/Grid-GCN
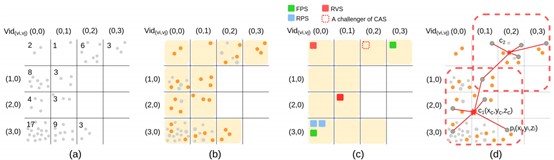
自PointNet++ 和DGCNN問世以後,基本所有的點雲處理模型都要使用取樣或近鄰查詢。但是,這兩種操作的時間複雜度太高,本文主要解決了這個問題。主要的模組有兩個:Coverage-aware Grid Query(CAGQ)和Grid Context Aggregation(GCA)。並由這兩個組合成GridConv。給定一組點雲資料,CAGQ 模組能夠高效地構建出結構化的點雲,並且加速取樣和近鄰查詢的操作。該模組首先對點雲進行體素化,將每個點對映到所屬體素中,每個體素記憶體儲的點的個數有上限。接著從所有非空體素中取樣M箇中心體素,並定義位於每個中心體素的相鄰體素內的點為上下文點 (context points),從上下文點中取樣K個結點(node points)。最後計算所有結點的質心,作為這一個分組的中心。其過程如圖1.19所示所示。第二個模組GCA 將所有結點的特徵聚合到分組中心上,聚合的過程中使用到了各種注意力機制,如圖所解釋的那樣,如果某個點在前一層包含了更多的資訊,那麼在特徵聚合的時候需要給予更多的權重,如圖1.20所示。最後利用多個由這兩個模組組成的GridConv提取到高階特徵用於分類,用於分割任務時,還需要利用GridConv進行上取樣,並與之前的低階特徵相結合。
參考:
1、https://blog.csdn.net/wqwqqwqw1231/article/details/104206664
2、Guo Y , Wang H , Hu Q , et al. Deep Learning for 3D Point Clouds: A Survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, PP(99):1-1.
3、相關的論文