實踐(2)--MySQL效能優化

相關學習推薦:
前言
- MySQL索引底層資料結構與演演算法
- MySQL效能優化原理-前篇
上一篇 《》我們講了資料庫表設計的一些原則,Explain工具的介紹、SQL語句優化索引的最佳實踐,本篇繼續來聊聊 MySQL 如何選擇合適的索引。
MySQL Trace 工具
MySQL 最終是否選擇走索引或者一張表涉及多個索引,最終是如何選擇索引,可以使用 trace 工具來一查究竟,開啟 trace工具會影響 MySQL 效能,所以只能臨時分析 SQL 使用,用完之後立即關閉。
案例分析
講 trace 工具之前我們先來看一個案例:
# 範例表CREATE TABLE`employees`(`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',`age` int(11) NOT NULL DEFAULT '0' COMMENT '年齡',`position` varchar(20) NOT NULL DEFAULT '' COMMENT '職位',`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入職時間',
PRIMARY KEY (`id`), KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
)ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='員工記錄表';
INSERT INTO employees(name,age,position,hire_time)VALUES('ZhangSan',23,'Manager',NOW());INSERT INTO employees(name,age,position,hire_time)VALUES('HanMeimei', 23,'dev',NOW());INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());複製程式碼MySQL 如何選擇合適的索引
EXPLAIN select * from employees where name > 'a';複製程式碼

如果用name索引需要遍歷name欄位聯合索引樹,然後還需要根據遍歷出來的主鍵值去主鍵索引樹裡再去查出最終資料,成本比全表掃描還高,可以用覆蓋索引優化,這樣只需要遍歷name欄位的聯合索引樹就能拿到所有結果,如下:
EXPLAIN select name,age,position from employees where name > 'a' ;複製程式碼

EXPLAIN select * from employees where name > 'zzz' ;複製程式碼
對於上面這兩種 name>'a' 和 name>'zzz' 的執行結果,mysql最終是否選擇走索引或者一張表涉及多個索引,mysql最終如何選擇索引,我們可以用trace工具來一查究竟,開啟trace工具會影響mysql效能,所以只能臨時分析sql使用,用完之後立即關閉。
trace工具用法
開啟/關閉Trace
#開啟traceset session optimizer_trace="enabled=on",end_markers_in_json=on; #關閉traceset session optimizer_trace="enabled=off";複製程式碼
案例1
執行這兩句sql
select * from employees where name >'a' order by position;sELECT * FROM information_schema.OPTIMIZER_TRACE; 複製程式碼
提出來trace值,詳見註釋
{ "steps": [
{ "join_preparation": { --第一階段:SQL準備階段 "select#": 1, "steps": [
{ "expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`employees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from `employees` where (`employees`.`name` > 'a') order by `employees`.`position`"
}
] /* steps */
} /* join_preparation */
},
{ "join_optimization": { --第二階段:SQL優化階段 "select#": 1, "steps": [
{ "condition_processing": { --條件處理 "condition": "WHERE", "original_condition": "(`employees`.`name` > 'a')", "steps": [
{ "transformation": "equality_propagation", "resulting_condition": "(`employees`.`name` > 'a')"
},
{ "transformation": "constant_propagation", "resulting_condition": "(`employees`.`name` > 'a')"
},
{ "transformation": "trivial_condition_removal", "resulting_condition": "(`employees`.`name` > 'a')"
}
] /* steps */
} /* condition_processing */
},
{ "substitute_generated_columns": {
} /* substitute_generated_columns */
},
{ "table_dependencies": [ --表依賴詳情
{ "table": "`employees`", "row_may_be_null": false, "map_bit": 0, "depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{ "ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{ "rows_estimation": [ --預估表的存取成本
{ "table": "`employees`", "range_analysis": { "table_scan": { --全表掃描 "rows": 3, --掃描行數 "cost": 3.7 --查詢成本
} /* table_scan */, "potential_range_indexes": [ --查詢可能使用的索引
{ "index": "PRIMARY", --主鍵索引 "usable": false, "cause": "not_applicable"
},
{ "index": "idx_name_age_position", --輔助索引 "usable": true, "key_parts": [ "name", "age", "position", "id"
] /* key_parts */
},
{ "index": "idx_age", "usable": false, "cause": "not_applicable"
}
] /* potential_range_indexes */, "setup_range_conditions": [
] /* setup_range_conditions */, "group_index_range": { "chosen": false, "cause": "not_group_by_or_distinct"
} /* group_index_range */, "analyzing_range_alternatives": { --分析各個索引使用成本 "range_scan_alternatives": [
{ "index": "idx_name_age_position", "ranges": [ "a < name" --索引使用範圍
] /* ranges */, "index_pes_for_eq_ranges": true, "rowid_ordered": false, --使用該索引獲取的記錄是否按照主鍵排序 "using_mrr": false, "index_only": false, --是否使用覆蓋索引 "rows": 3, --索引掃描行數 "cost": 4.61, --索引使用成本 "chosen": false, --是否選擇該索引 "cause": "cost"
}
] /* range_scan_alternatives */, "analyzing_roworder_intersect": { "usable": false, "cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */
} /* range_analysis */
}
] /* rows_estimation */
},
{ "considered_execution_plans": [
{ "plan_prefix": [
] /* plan_prefix */, "table": "`employees`", "best_access_path": { --最優存取路徑 "considered_access_paths": [ --最終選擇的存取路徑
{ "rows_to_scan": 3, "access_type": "scan", --存取型別:為sacn,全表掃描 "resulting_rows": 3, "cost": 1.6, "chosen": true, --確定選擇 "use_tmp_table": true
}
] /* considered_access_paths */
} /* best_access_path */, "condition_filtering_pct": 100, "rows_for_plan": 3, "cost_for_plan": 1.6, "sort_cost": 3, "new_cost_for_plan": 4.6, "chosen": true
}
] /* considered_execution_plans */
},
{ "attaching_conditions_to_tables": { "original_condition": "(`employees`.`name` > 'a')", "attached_conditions_computation": [
] /* attached_conditions_computation */, "attached_conditions_summary": [
{ "table": "`employees`", "attached": "(`employees`.`name` > 'a')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{ "clause_processing": { "clause": "ORDER BY", "original_clause": "`employees`.`position`", "items": [
{ "item": "`employees`.`position`"
}
] /* items */, "resulting_clause_is_simple": true, "resulting_clause": "`employees`.`position`"
} /* clause_processing */
},
{ "reconsidering_access_paths_for_index_ordering": { "clause": "ORDER BY", "index_order_summary": { "table": "`employees`", "index_provides_order": false, "order_direction": "undefined", "index": "unknown", "plan_changed": false
} /* index_order_summary */
} /* reconsidering_access_paths_for_index_ordering */
},
{ "refine_plan": [
{ "table": "`employees`"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{ "join_execution": { --第三階段:SQL執行階段
"select#": 1, "steps": [
{ "filesort_information": [
{ "direction": "asc", "table": "`employees`", "field": "position"
}
] /* filesort_information */, "filesort_priority_queue_optimization": { "usable": false, "cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */, "filesort_execution": [
] /* filesort_execution */, "filesort_summary": { "rows": 3, "examined_rows": 3, "number_of_tmp_files": 0, "sort_buffer_size": 200704, "sort_mode": "<sort_key, packed_additional_fields>"
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
] /* steps */
}複製程式碼結論:全表掃描的成本低於索引掃描,所以MySQL最終選擇全表掃描。
案例2
select * from employees where name > 'zzz' order by position;SELECT * FROM information_schema.OPTIMIZER_TRACE; 複製程式碼
結論:檢視trace欄位可知索引掃描的成本低於全表掃描,所以MySQL最終選擇索引掃描。
常見SQL深入優化
Order by 與 Group by 優化
案例1
EXPLAIN select * from employees where name = 'ZhangSan' and position = 'dev' order by age複製程式碼

分析:
利用最左字首法則:中間欄位不能斷,因此查詢用到了 name索引 ,從 key_len = 74 也能看出,age 索引列用在排序過程過程中,因為 Extra 欄位裡沒有 using filesort 。
案例2
EXPLAIN select * from employees where name = 'ZhangSan' order by position複製程式碼

分析:
從 explain 的執行結果來看:key_len = 74,查詢使用了 name 索引,由於用了 position 進行排序,跳過了 age,出現了 Using filesort。
案例3
EXPLAIN select * from employees where name = 'ZhangSan' order by age,position複製程式碼

分析:
查詢只用到索引name,age 和 position 用於排序,無Using filesort。
案例4
EXPLAIN select * from employees where name = 'ZhangSan' order by position,age複製程式碼

分析:
和案例3中explain的執行結果一樣,但是出現了Using filesort ,因為索引的建立順序為 name,age,position , 但是排序的時候 age 和 position 顛倒位置了。
案例5
EXPLAIN select * from employees where name = 'ZhangSan' and age = 18 order by position,age複製程式碼

分析:
與案例4對比,在Extra中並未出現** Using filesort **,因為 age 為常數,在排序中被優化,所以索引未顛倒,不會出現 Using filesort 。
案例6
EXPLAIN select * from employees where name = 'ZhangSan' order by age asc, position desc;複製程式碼

分析:
雖然排序的欄位列與索引順序一樣,且 order by 預設升序,這裡 position desc 變成列降序,導致與索引的排序方式不同,從而產生 Using filesort 。MySQL8 以上版本有降序索引可以支援該種查詢方式。
案例7
EXPLAIN select * from employees where name in ('ZhangSan', 'hjh') order by age, position;複製程式碼分析:
對於排序來說,多個相等條件也是範圍查詢。
案例8
EXPLAIN select * from employees where name > 'a' order by name;複製程式碼

可以用覆蓋索引優化
EXPLAIN select name,age,position from employees where name > 'a' order by name;複製程式碼

優化總結
- MySQL支援兩種方式的排序
filesort和index。Using index 是指MySQL 掃描索引本身完成排序。index 效率高,filesort 效率低。 - order by 滿足兩種情況會使用 Using index.
- order by 語句使用索引最左前例。
- 使用 where 子句與 order by 子句條件列組合滿足索引最左前例。
- 儘量在索引列上完成排序,遵循索引建立(索引建立的順序)時的最左字首法則。
- 如果 order by 的條件不在索引列上,就會產生 Using filesort。
- 能用覆蓋索引儘量用覆蓋索引。
- group by 和 order by 很類似,其實質是先排序後分組,遵循索引建立順序的最左字首法則。對於 group by 的優化如果不需要排序的可以加上
order by null禁止排序。注意:where 高於 having,能寫在 where 中的限定條件就不要去 having 限定了。
Using filesort檔案排序原理
filesort檔案排序方式
- 單路排序:是一次性取出滿足條件行的所有欄位,然後在
sort buffer中進行排序;用 trace 工具可以看到 sort_mode 資訊裡顯示 < sort_key, additional_fields > 或者 < sort_key, packed_additional_fields >。 - 雙路排序(又叫回表排序模式):是首先根據相應的條件取出相應的排序欄位和可以直接定位執行資料的行ID,然後在 sort buffer 中進行排序,排序完後需要再次取回其它需要的欄位;用 trace 工具可以看到 sort_mode 資訊裡顯示 < sort_key, rowid >
MySQL 通過比較系統變數 max_length_for_sort_data (預設1024位元組) 的大小和需要查詢的欄位總大小來判斷使用那種排序模式。
- 如果
max_length_for_sort_data比查詢的欄位的總長度大,那麼使用單路排序模式; - 如果
max_length_for_sort_data比查詢欄位的總長度小,那麼使用雙路排序模式。
驗證各種排序方式
EXPLAIN select * from employees where name = 'ZhangSan' order by position;複製程式碼

檢視下這條sql對應trace結果如下(只展示排序部分):
set session optimizer_trace="enabled=on",end_markers_in_json=on; #開啟traceselect * from employees where name = 'ZhangSan' order by position;select * from information_schema.OPTIMIZER_TRACE;複製程式碼
"join_execution": { --SQL執行階段
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": { --檔案排序資訊
"rows": 1, --預計掃描行數
"examined_rows": 1, --引數排序的行
"number_of_tmp_files": 0, --使用臨時檔案的個數,這個只如果為0代表全部使用的sort_buffer記憶體排序,否則使用的磁碟檔案排序
"sort_buffer_size": 200704, --排序快取的大小
"sort_mode": "<sort_key, packed_additional_fields>" --排序方式,這裡用的單路排序
} /* filesort_summary */
}
] /* steps */
} /* join_execution */複製程式碼修改系統變數 max_length_for_sort_data (預設1024位元組) ,employees 表所有欄位長度總和肯定大於10位元組
set max_length_for_sort_data = 10; select * from employees where name = 'ZhangSan' order by position;select * from information_schema.OPTIMIZER_TRACE;複製程式碼
trace排序部分結果:
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": {
"rows": 1,
"examined_rows": 1,
"number_of_tmp_files": 0,
"sort_buffer_size": 53248,
"sort_mode": "<sort_key, rowid>" --排序方式,這裡用餓的雙路排序
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
複製程式碼單路排序的詳細過程:
- 從索引 name 找到第一個滿足 name='ZhangSan' 條件的主鍵 id;
- 根據主鍵id取出整行,取出所有欄位的值,存入sort_buffer中;
- 從索引name找到下一個滿足 name='ZhangSan' 條件的主鍵 id;
- 重複步驟2、3直到不滿足 name='ZhangSan';
- 對 sort_buffer 中的資料按照欄位 position 進行排序;
- 返回結果給使用者端
雙路排序的詳細過程:
- 從索引 name 找到第一個滿足 name='ZhangSan' 的主鍵id;
- 根據主鍵id取出整行,把排序欄位 position 和 主鍵id 這兩個欄位放到 sort_buffer 中;
- 從索引 name 取下一個滿足 name='ZhangSan' 記錄的主鍵id;
- 重複步驟3、4直到不滿足 name='ZhangSan';
- 對 sort_buffer 中的欄位 position 和 主鍵id按照 position 進行排序;
- 遍歷排序好的 id 和 欄位 position,按照 id 的值回到原表中取出所有的欄位的值返回給使用者端。
對比兩個排序模式,單路排序會把所有需要查詢的欄位都放到 sort_buffer 中,而雙路排序只會把主鍵和需要排序的欄位放到 sort_buffer 中進行排序,然後再通過主鍵回到原表查詢需要的欄位。
如果MySQL排序記憶體設定的比較小並且沒有條件繼續增加了,可以適當把 max_length_for_sort_data 設定小點,讓優化器選擇使用雙路排序演演算法,可以在 sort_buffer 中一次排序更多的行,只是需要再根據主鍵回到原表取資料。
如果MySQL排序記憶體有條件可以設定比較大,可以適當增大 max_length_for_sort_data 的值,讓優化器優先選擇全欄位排序(單路排序),把需要的欄位放到 sort_buffer 中,這樣排序後就會直接從記憶體裡返回查詢結果了。
所以,MySQL 通過 max_length_for_sort_data 這個引數來控制排序,在不同場景使用不同的排序模式,從而提升排序效率。
注意:如果全部使用sort_buffer 記憶體排序一般情況下效率會高於磁碟檔案排序,但不能因為這個就隨便增大 sort_buffer(預設1M),MySQL很多引數設定都做過優化的,不要輕易調整。
分頁查詢優化
在這我們先往 employess 插入一些測試資料
drop procedure if exists insert_emp;
delimiter ;;
create procedure insert_emp()begin
declare i int;
set i=1;
while(i<=100000) do
insert into employees(name,age,position) values(CONCAT('hjh',i),i,'dev'); set i=i+1;
end while;end;;
delimiter ;
call insert_emp();複製程式碼很多時候我們業務系統實現分頁功能可能會用如下SQL實現
select * from employees limit 10000,10;複製程式碼
表示從表 employees 中取出從 10001 行開始的 10 行記錄。看似只查詢了 10 條記錄,實際這條 SQL 是先讀取 10010 條記錄,然後拋棄前 10000 條記錄,然後讀到後面 10 條想要的資料。因此要查詢一張大表比較靠後的資料,執行效率是非常低的。
常見的分頁場景優化技巧
- 根據自增且連續的主鍵排序的分頁查詢
- 根據非主鍵欄位排序的分頁查詢
案例1: 根據自增且連續的主鍵排序的分頁查詢
首先來看一個根據自增且連續主鍵排序的分頁查詢的例子:
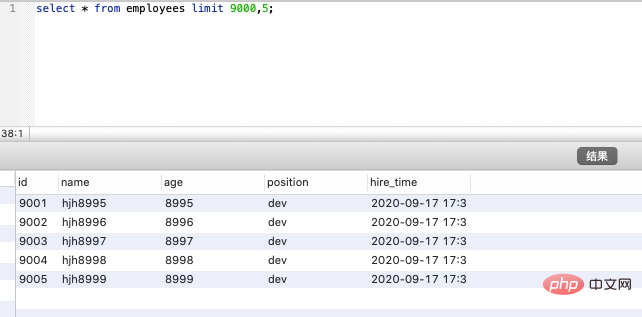
select * from employees limit 9000,5;複製程式碼
該 SQL 表示查詢從第 9001開始的五行資料,沒新增單獨 order by,表示通過主鍵排序。我們再看錶 employees ,因為主鍵是自增並且連續的,所以可以改寫成按照主鍵去查詢從第 9001開始的五行資料,如下:
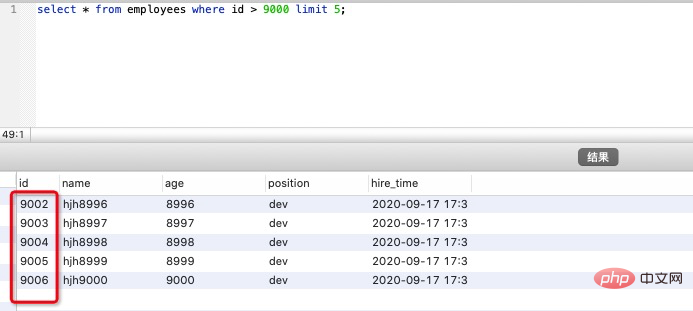
select * from employees where id > 9000 limit 5;複製程式碼
查詢結果是一致的,我們再對比一下執行計劃:
EXPLAIN select * from employees limit 9000,5;複製程式碼

EXPLAIN select * from employees where id > 9000 limit 5;複製程式碼

顯然改寫後的 SQL 走了索引,而且掃描的行數大大減少,執行效率更高。 但是,這條改寫的 SQL 在很多場景並不實用,因為表中可能某些記錄被刪後,主鍵空缺,導致結果不一致,如下圖試驗所示(先刪除一條前面的記錄,然後再測試原 SQL 和優化後的 SQL):
兩條 SQL 的結果並不一樣,因此,如果主鍵不連續,不能使用上面描述的優化方法。
另外如果原SQL是order by 非主鍵的欄位,按照上面說餓的方法改寫會導致兩條SQL的結果不一致。所以這種改寫得滿足以下兩個條件:
- 主鍵自增且連續
- 結果是按照主鍵排序的
案例2: 根據非主鍵欄位排序的分頁查詢
再看一個根據非主鍵欄位排序的分頁查詢,SQL 如下:
select * from employees ORDER BY name limit 9000,5;複製程式碼
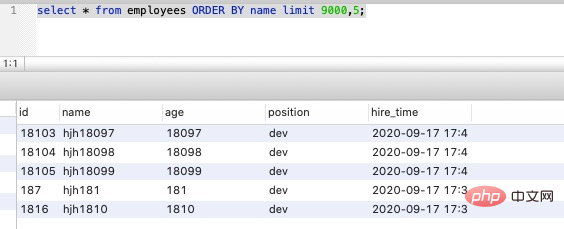
EXPLAIN select * from employees ORDER BY name limit 90000,5;複製程式碼

發現並沒有使用 name 欄位的索引(key 欄位對應的值為 null),具體原因上前面講過 : 掃描整個索引並查詢到沒索引的行(可能要遍歷多個索引樹)的成本比掃描全表的成本更高,所以優化器放棄使用索引。 知道不走索引的原因,那麼怎麼優化呢? 其實關鍵是讓排序時返回的欄位儘可能少,所以可以讓排序和分頁操作先查出主鍵,然後根據主鍵查到對應的記錄,SQL 改寫如下:
select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id;複製程式碼
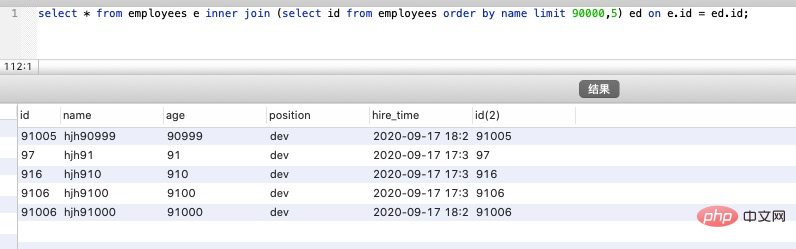
需要的結果與原 SQL 一致,執行時間減少了一半以上,我們再對比優化前後sql的執行計劃:
EXPLAIN select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id;複製程式碼
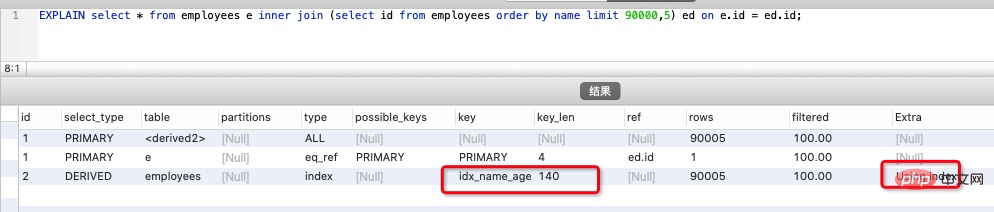
原 SQL 使用的是 filesort 排序,而優化後的 SQL 使用的是索引排序。
Join關聯查詢優化
#範例表CREATE TABLE `t1` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `a` INT (11) DEFAULT NULL, `b` INT (11) DEFAULT NULL,
PRIMARY KEY (`id`), KEY `idx_a` (`a`)
) ENGINE = INNODB AUTO_INCREMENT = 10001 DEFAULT CHARSET = utf8;CREATE TABLE t2 LIKE t1;複製程式碼往t1表插入1萬行記錄,往t2表插入100行記錄
#t1 1萬條記錄drop procedure if exists insert_emp_t1;
delimiter ;;
create procedure insert_emp_t1()begin
declare i int;
set i=1;
while(i<=10000) do
insert into t1(a,b) values(i,i); set i=i+1;
end while;end;;
delimiter ;
call insert_emp_t1();
#t2 100條記錄drop procedure if exists insert_emp_t2;
delimiter ;;
create procedure insert_emp_t2()begin
declare i int;
set i=1;
while(i<=100) do
insert into t2(a,b) values(i,i); set i=i+1;
end while;end;;
delimiter ;
call insert_emp_t2();複製程式碼MySQL 的表關聯常見有兩種演演算法
- Nested-Loop Join 演演算法
- Block Nested-Loop Join 演演算法
案例1:巢狀迴圈連線 Nested-Loop Join(NLJ)演演算法
一次一行迴圈地從第一張表(稱為驅動表)中讀取行,在這行資料中取到關聯欄位,根據關聯欄位在另一張表(被驅動表)裡取出滿足條件的行,然後取出兩張表的結果合集。
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;複製程式碼

從執行計劃中可以看到這些資訊:
- 驅動表是 t2,被驅動表是 t1。先執行的就是驅動表(執行計劃結果的id如果一樣則按從上到下順序執行sql);優化器一般會優先選擇小表做驅動表。所以使用 inner join 時,排在前面的表並不一定就是驅動表。
- 使用了 NLJ 演演算法。一般 join 語句中,如果執行計劃 Extra 中未出現 Using join buffer 則表示使用的 join 演演算法是 NLJ。
上面SQL的大致流程如下:
- 從表 t2 中讀取一行資料;
- 從第1步的資料中,取出關鍵字欄位 a,到表 t1 中查詢;
- 取出表 t1 中滿足條件的行,跟 t2 中獲取到的結果合併,作為結果返回給使用者端;
- 重複上面 3 步。
整個過程會讀取 t2 表的所有資料(掃描100行),然後遍歷這每行資料中欄位 a 的值,根據 t2 表中的 a 的值索引掃描 t1 表中對應的行(掃描 100次 t1 表的索引,1次掃描可以認為最終只掃描 t1 表一行完整資料,也就是總共 t1 表也掃描了100行)。因此整個過程掃描了 200 行。
如果被驅動表的關聯欄位沒有索引,使用NLJ演演算法效能會比較低(下面有詳細解釋),MySQL 會選擇 Block Nested-Loop Join 演演算法。
案例2:基於塊的巢狀迴圈連線 Block Nested-Loop Join(BNL)演演算法
把驅動表的資料讀入到 join_buffer 中,然後掃描被驅動表,把被驅動表每一行取出來跟 join_buffer 中的資料做對比。
EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;複製程式碼

Extra 中 的Using join buffer (Block Nested Loop)說明該關聯查詢使用的是 BNL 演演算法。
上面sql的大致流程如下:
- 把 t2 的所有資料放入到 join_buffer 中
- 把表 t1 中每一行取出來,跟 join_buffer 中的資料做對比
- 返回滿足 join 條件的資料
整個過程對錶 t1 和 t2 都做了一次全表掃描,因此掃描的總行數為10000(表 t1 的資料總量) + 100(表 t2 的資料總量) = 10100。並且 join_buffer 裡的資料是無序的,因此對錶 t1 中的每一行,都要做 100 次判斷,所以記憶體中的判斷次數是 100 * 10000= 100 萬次。
被驅動表的關聯欄位沒索引為什麼要選擇使用 BNL 演演算法而不使用 Nested-Loop Join 呢?
如果上面第二條sql使用 Nested-Loop Join,那麼掃描行數為 100 * 10000 = 100萬次,這個是磁碟掃描。
很顯然,用BNL磁碟掃描次數少很多,相比於磁碟掃描,BNJ 的記憶體計算會快得多。
因此MySQL對於被驅動表的關聯欄位沒索引的關聯查詢,一般都會使用 BNL 演演算法。如果有索引一般選擇 NLJ 演演算法,有索引的情況下 NLJ 演演算法比 BNL演演算法效能更高。
對於關聯SQL的優化
- 關聯欄位加索引,讓mysql做join操作時儘量選擇NLJ演演算法
- 小表驅動大表,寫多表連線sql時如果明確知道哪張表是小表可以用
straight_join寫法固定連線驅動方式,省去mysql優化器自己判斷的時間
straight_join解釋
straight_join功能同join類似,但能讓左邊的表來驅動右邊的表,能改變優化器對於聯表查詢的執行順序。
比如 : select * from t2 straight_join t1 on t2.a = t1.a; 代表制定mysql選擇 t2 表作為驅動表。
- straight_join只適用於inner join,並不適用於left join,right join。(因為left join,right join已經代表指 定了表的執行順序)
- 儘可能讓優化器去判斷,因為大部分情況下mysql優化器是比人要聰明的。使用straight_join一定要慎重,因 為部分情況下人為指定的執行順序並不一定會比優化引擎要靠譜。
in 和 exsits 優化
原則:小表驅動大表,即小的資料集驅動大的資料集。
in:當B表的資料集小於A表的資料集時,in優於exists
select * from A where id in(select id from B)
#等價於:for(select id from B){ select * from A where A.id = B.id
}複製程式碼exists:當A表的資料集小於B表的資料集時,exists優於in
將主查詢A的資料,放到子查詢B中做條件驗證,根據驗證結果(true或false)來決定主查詢的資料是否保留
select * from A where exists (select 1 from B whereB.id=A.id)
#等價於:for(select * from A){ select * from B where B.id = A.id
}
#A表與B表的ID欄位應建立索引複製程式碼- EXISTS (subquery)只返回TRUE或FALSE,因此子查詢中的SELECT * 也可以用SELECT 1替換,官方說法是實際執行時會 忽略SELECT清單,因此沒有區別;
- EXISTS子查詢的實際執行過程可能經過了優化而不是我們理解上的逐條對比;
- EXISTS子查詢往往也可以用JOIN來代替,何種最優需要具體問題具體分析;
Count(*) 查詢優化
臨時關閉mysql查詢快取,為了檢視sql多次執行的真實時間。
set global query_cache_size=0;set global query_cache_type=0;複製程式碼
EXPLAIN select count(1) from employees; EXPLAIN select count(id) from employees;EXPLAIN select count(name) from employees; EXPLAIN select count(*) from employees;複製程式碼

四個sql的執行計劃一樣,說明這四個sql執行效率應該差不多,區別在於根據某個欄位count不會統計欄位為null值的資料行。
為什麼mysql最終選擇輔助索引而不是主鍵聚集索引?
因為二級索引相對主鍵索引儲存資料更少,檢索效能應該更高
常見的優化方法如下:
- 查詢MySQL自己維護的總行數
- show table status
- 將總數維護到Redis裡
- 增加計數表
查詢MySQL自己維護的總行數
對於myisam儲存引擎的表做不帶where條件的count查詢效能是很高的,因為myisam儲存引擎的表的總行數會被 mysql儲存在磁碟上,查詢不需要計算。

對於innodb儲存引擎的表mysql不會儲存表的總記錄行數,查詢count需要實時計算。
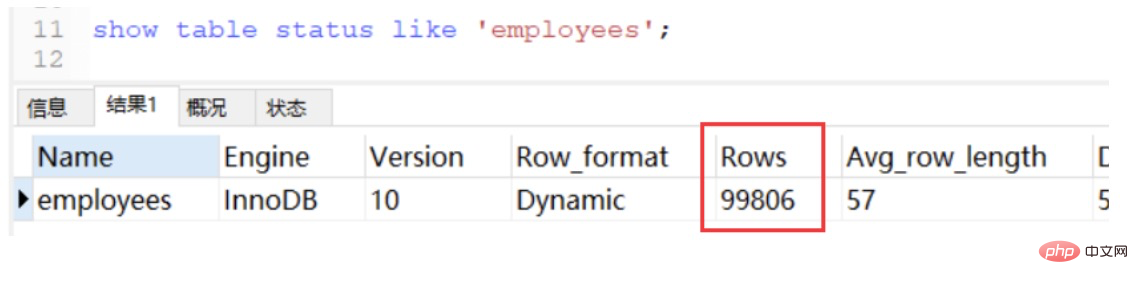
show table status
如果只需要知道表總行數的估計值可以用如下sql查詢,效能很高
將總數維護到Redis裡
插入或刪除表資料行的時候同時維護redis裡的表總行數key的計數值(用incr或decr命令),但是這種方式可能不準,很難保證表操作和redis操作的事務一致性。
增加計數表
插入或刪除表資料行的時候同時維護計數表,讓他們在同一個事務裡操作。
想了解更多程式設計學習,敬請關注欄目!
以上就是實踐(2)--MySQL效能優化的詳細內容,更多請關注TW511.COM其它相關文章!