void指標及其應用,C語言void指標及使用注意事項詳解
2020-07-16 10:04:26
void *p1; int *p2; … p1 = p2;雖然如此,但這並不意味著可以無需任何強制型別轉換就將 void 指標直接賦給其他型別的指標,因為“空型別”可以包容“有型別”,而“有型別”則不能包容“空型別”。正如我們可以說“男人和女人都是人”,但不能說“人是男人”或者“人是女人”一樣。因此,下面的範例程式碼將編譯出錯,如果在 VC++2010 中,將提示“a value of type"void*"cannot be assigned to an entity of type"int*"”的錯誤資訊。
void *p1; int *p2; … p2 = p1;由此可見,要將 void 指標賦值給其他型別的指標,必須進行強制型別轉換。如下面的範例程式碼所示:
void *p1; int *p2; … p2 = (int*)p1;
避免對void指標進行算術操作
ANSI C 標準規定,進行演算法操作的指標必須確定知道其指向資料型別大小,也就是說必須知道記憶體目的地址的確切值。如下面的範例程式碼所示:char a[20]="qwertyuiopasdfghjkl";
int *p=(int *)a;
p++;
printf("%s", p);
在上面的範例程式碼中,指標變數 p 的型別是“int*”,指向的型別是 int,被初始化為指向整型變數 a。在執行語句“p++”時,編譯器是這樣處理的:把指標 p 的值加上了“sizeof(int)”(由於在 32 位系統中,int 佔 4 位元組,所以這裡是被加上了 4),即 p 所指向的地址由原來的變數 a 的地址向高地址方向增加了 4 位元組。但又由於 char 型別的長度是一個位元組,所以語句“printf("%s",p)”將輸出“tyuiopasdfghjkl”。
而對於 void 指標,編譯器並不知道所指物件的大小,所以對 void 指標進行算術操作都是不合法的,如下面的範例程式碼所示:
void * p; p++; // ANSI:錯誤 p+= 1; // ANSI:錯誤上面的程式碼在 VC++2010 中將提示“expression must be a pointer to a complete object type”的錯誤資訊。
但值得注意的是,GNU 則不這麼認為,它指定“void*”的演算法操作與“char*”一致。因此下列語句在 GNU 編譯器中都是正確的:
void * p; p++; // GUN:正確 p+=1; // GUN:正確下面的範例程式碼演示了在 GCC 中執行對 void 指標的自增操作:
#include <stdio.h>
int main(void)
{
void * p="ILoveC";
p++;
printf("%sn", p);
}
執行結果為:LoveC
由此可見,GNU 和 ANSI 還存在著一些區別,相比之下,GNU 較 ANSI 更“開放”,提供了對更多語法的支援。但是在真實的設計環境中,還是應該盡可能符合 ANSI 標準,盡量避免對 void 指標進行算術操作。
如果函數的引數可以是任意型別指標,應該將其引數宣告為 void*
前面提到,void 指標可以指向任意型別的資料,同時任何型別的指標都可以直接賦值給 void 指標,而無需進行其他相關的強制型別轉換。因此,在程式設計中,如果函數的引數可以是任意型別指標,那麼應該使用 void 指標作為函數的形參,這樣函數就可以接受任意資料型別的指標作為引數。比較典型的函數有記憶體操作函數 memcpy 和 memset,如下面的程式碼所示:
void *memset(void *buffer, int b, size_t size)
{
assert(buffer!=NULL);
char* retAddr = (char*)buffer;
while (size--> 0)
{
*(retAddr++) = (char)b;
}
return retAddr;
}
void *memcpy (void *dst, const void *src, size_t size)
{
assert((dst!=NULL) && (src!=NULL));
char *temp_dest = (char *)dst;
char *temp_src = (char *)src;
char* retAddr = temp_dest;
size_t i = 0;
/* 解決資料區重疊問題*/
if ((retAddr>temp_src) && (retAddr<(temp_src+size)))
{
for (i=size-1; i>=0; i--)
{
*(temp_dest++) = *(temp_src++);
}
}
else
{
for (i=0; i<size; i++)
{
*(temp_dest++) = *(temp_src++);
}
}
*(retAddr+size)='';
return retAddr;
}
這樣,任何型別的指標都可以傳入 memcpy 函數和 memset 函數中,這也真實地體現了記憶體操作函數的意義,因為它操作的物件僅僅是一片記憶體,而不論這片記憶體是什麼型別。memcpy 函數的呼叫範例如下面的程式碼所示:char buf[]="abcdefg";
// buf+2(從c開始,長度3個,即cde)
memcpy(buf, buf+2 ,3);
printf("%sn", buf);
或者進行如下形式的呼叫:int dst[100]; int src[100]; memcpy(dst, src, 100*sizeof(int));因為引數型別是 void*,所以上面的呼叫都是正確的。現在假設 memcpy 函數的引數型別不是 void*,而是 char*,如下面的程式碼所示:
char *memcpy(char* dst, const char* src, size_t size)
{
assert((dst !=NULL) && (src != NULL));
char *retAddr = dst;
size_t i = 0;
if ((retAddr>src) && (retAddr<(src+size)))
{
for (i=size-1; i>=0; i--)
{
*(dst++)= *(src++);
}
}
else
{
for (i=0; i<size; i++)
{
*(dst++) = *(src++);
}
}
*(retAddr+size)='';
return retAddr;
}
現在繼續執行如下形式的呼叫:int dst[100]; int src[100]; memcpy(dst, src, 100*sizeof(int));由於型別不匹配,編譯器就會報錯,如圖 1 所示。
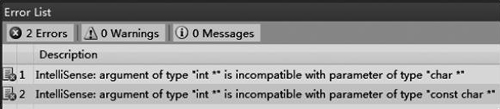
圖 1