python——網路爬蟲快速入門【數據提取篇】
3. 數據提取方法
3.1數據提取的概念和數據的分類
在爬蟲爬取的數據中有很多不同類型的數據,我們需要瞭解數據的不同類型來又規律的提取和解析數據.
- 結構化數據:json,xml等 【前後端分離】
- 處理方式:直接轉化爲python型別
- 非結構化數據:HTML 【前後端不分離】
- 處理方式:正則表達式、xpath
3.2 快速辨別數據型別
- 數據型別判別,看第一條發出的請求的響應,這條由我們向瀏覽器發出的請求是最乾淨的,其他的數據請求都是由瀏覽器幫我們發出的。
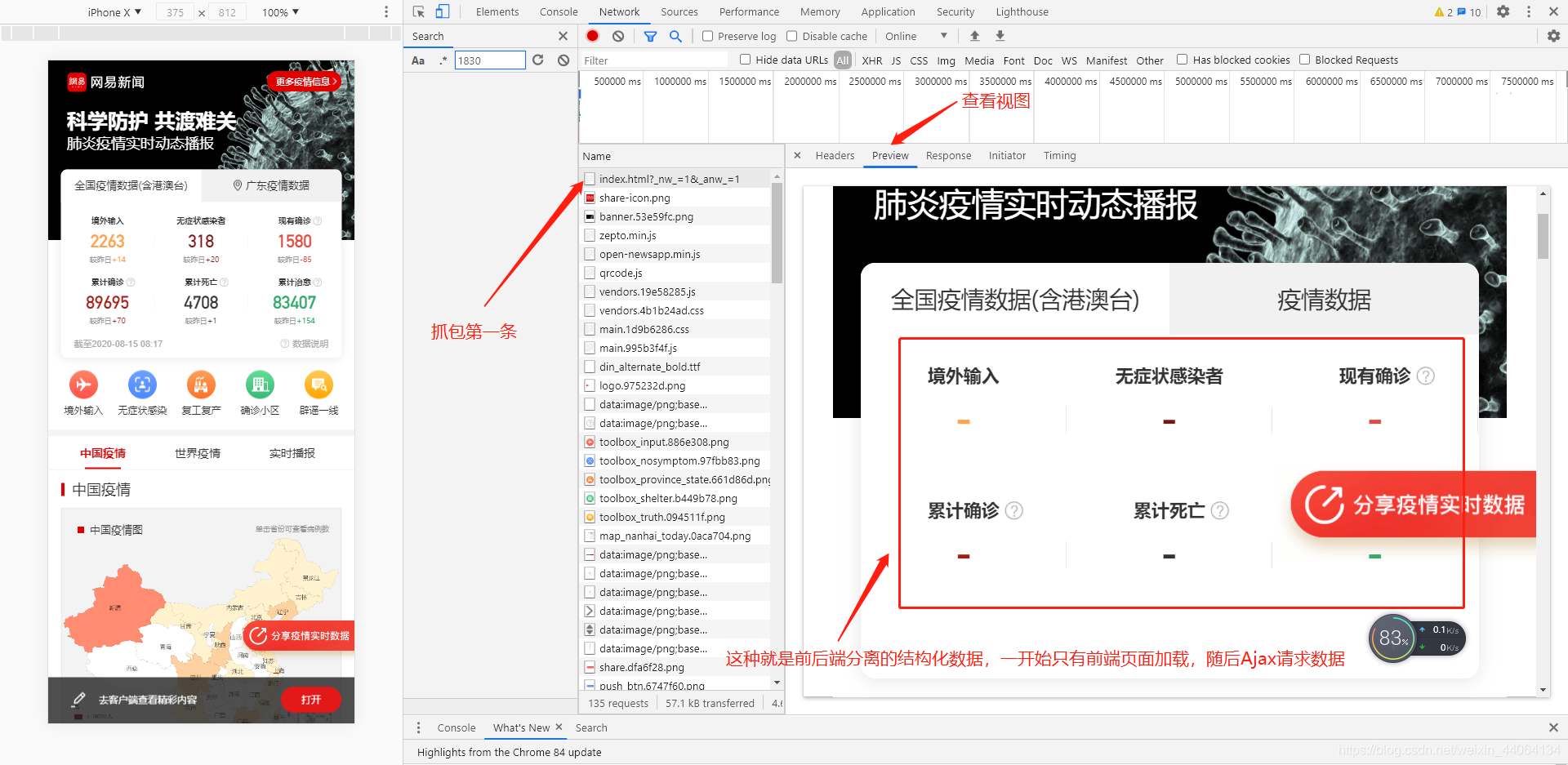
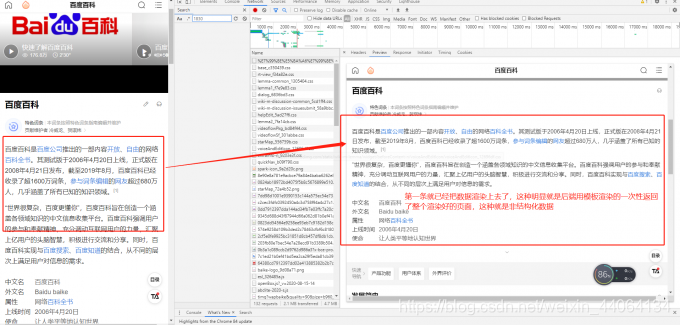
- 第一條請求的檢視,數據已經渲染上去,很明顯的就是後端模板渲染好才返回整個頁面的前後端不分離非結構化數據。
3.3 結構化數據型別的提取
- XML數據:(已淘汰,瞭解即可)
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
1. json的數據提取
-
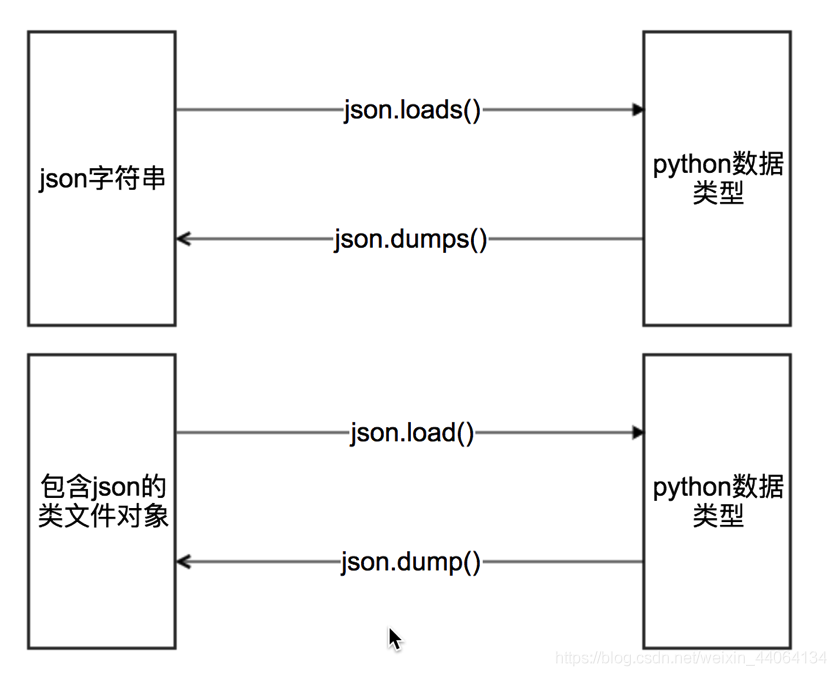
python 內建有一個標準庫叫 JSON 庫 ,可以實現 JSON 字串與字典之間的轉換
-
之前的案例中和練習中已經有大量的演示,提取時,現將 JSON 字串處理【切片】成一個標準的字串
然後用 json.loads() 轉化爲列表或者字典 , 然後進行需要的數據解析提取,隨後將提取的數據,再封裝成字典或者列表,隨後可以通過 json.dumps() 方法轉化爲字串通過檔案進行儲存, 或者根據需要存入數據庫中。
2. jsonpath模組的學習
2.1 jsonpath介紹
用來解析多層巢狀的json數據;JsonPath 是一種資訊抽取類庫,是從JSON文件中抽取指定資訊的工具,提供多種語言實現版本,包括:Javascript, Python, PHP 和 Java。
2.2 JsonPath 的安裝與語法
pip install jsonpath # 安裝
官方文件:http://goessner.net/articles/JsonPath
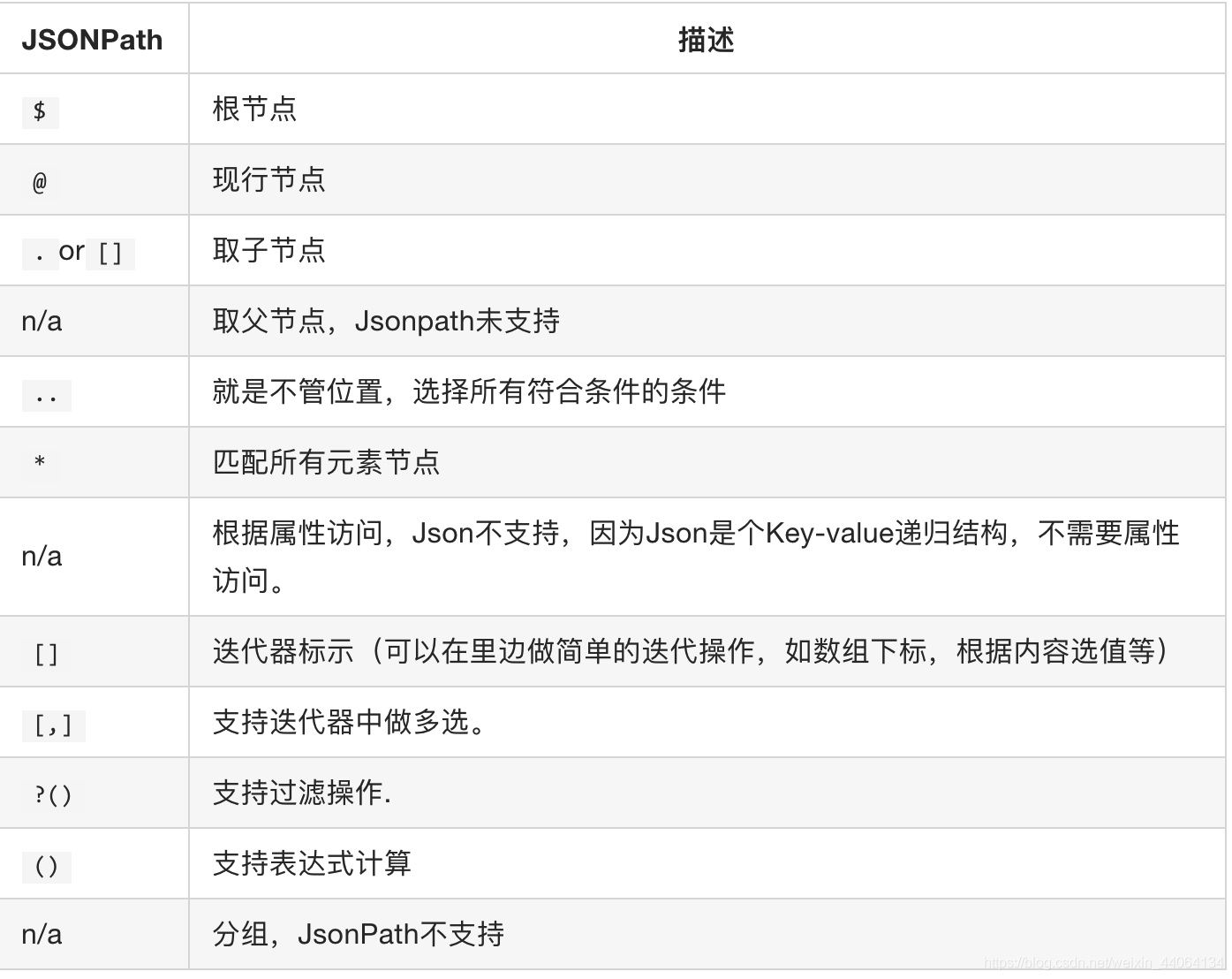
JSONPath 語法:
2.3 案例解析
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
| JSONPath | Result |
|---|---|
$.store.book[*].author |
store中的所有的book的作者 |
$..author |
所有的作者 |
$.store.* |
store下的所有的元素 |
$.store..price |
store中的所有的內容的價格 |
$..book[2] |
第三本書 |
$..book[(@.length-1)] |
$..book[-1:] |
$..book[0,1] |
$..book[:2] |
$..book[?(@.isbn)] |
獲取有isbn的所有數 |
$..book[?(@.price<10)] |
獲取價格大於10的所有的書 |
$..* |
獲取所有的數據 |
案例6
目標URL: https://www.lagou.com/lbs/getAllCitySearchLabels.json
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/8/15 14:54
# @Author : GHong
import requests
import jsonpath
from json import loads
url = "https://www.lagou.com/lbs/getAllCitySearchLabels.json"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
}
response = requests.get(url, headers=headers)
data_dict = loads(response.content.decode()) # 轉換成字典型別
# 通過結構分析我們想要獲取所有城市的名稱
# 這個數據在content=>data=>allCitySearchLabels=>A,B,C,D,E,F...=>[]["name"]
"""
方案一:不使用JsonPath 模組
"""
# node = data_dict["content"]["data"]["allCitySearchLabels"]
#
# upper = list(map(chr, range(65, 91))) # 快速生成大寫字母表
#
# for i in upper:
# try:
# for item in node[i]:
# print(item["name"])
# except:
# print("沒有以%s開頭的城市" % i)
"""使用Jsonpath模組"""
for item in jsonpath.jsonpath(data_dict, "$..name"):
print(item)
練習5 (3.5星)
爬取豆瓣上所有的 (國產劇,英美劇,動漫,韓劇,日劇,綜藝的 【片名,評分及鏈接】)

參考答案 提取碼:b8ml
3.4 非結構化數據提取
1. 正則提取法
1 .1什麼是正則表達式
用事先定義好的一些特定字元、及這些特定字元的組合,組成一個規則字串,這個規則字串用來表達對字串的一種過濾邏輯。
1.2 正則表達式的語法
知識點
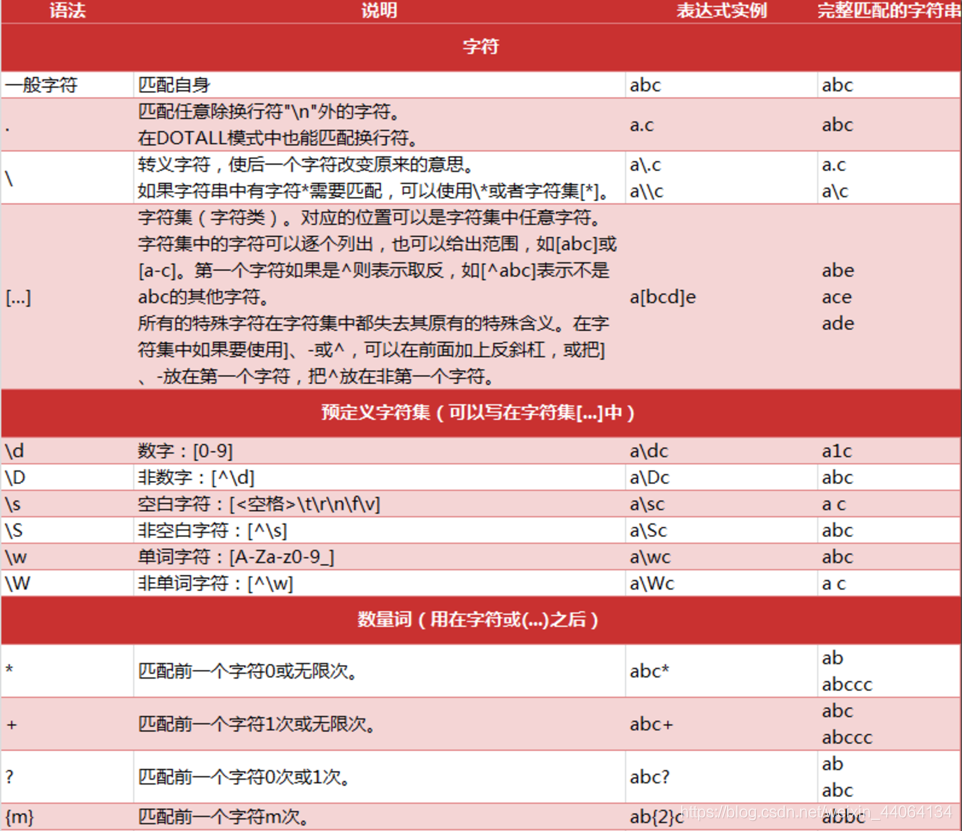
- 正則中的字元
- 正則中的預定義字元集
- 正則中的數量詞
1.3 re模組常見方法
-
pattern.match(從頭找一個)
-
pattern.search(找一個)
-
pattern.findall(找所有)
- 返回一個列表,沒有就是空列表
re.findall("\d","chuan1zhi2") >> ["1","2"]
-
pattern.sub(替換)
re.sub("\d","_","chuan1zhi2") >> ["chuan_zhi_"]
-
re.compile(編譯)
-
返回一個模型P,具有和re一樣的方法,但是傳遞的參數不同
-
匹配模式需要傳到compile中
p = re.compile("\d",re.S) p.findall("chuan1zhi2")
-
1.4 匹配中文
在某些情況下,我們想匹配文字中的漢字,有一點需要注意的是,中文的 unicode 編碼範圍 主要在 [u4e00-u9fa5],這裏說主要是因爲這個範圍並不完整,比如沒有包括全形(中文)標點,不過,在大部分情況下,應該是夠用的。
import re
str = "你好呀,ha殺ki"
print(re.findall(r'[\u4e00-\u9fa5]+', str))
1.5 正則實戰
目標URL:http://www.chinanews.com/
import re
import requests
url = "http://www.chinanews.com/"
response = requests.get(url)
# print(response.content.decode())
txt = response.content.decode()
# 通過觀察我們發現目標數據結構 :
"""
<img width="320" height="270" src="/part/home2013/451/U179P4T451D5F17256DT20200815171855.jpg" alt="烏魯木齊社羣做好居民服務">
"""
nodes = re.findall(r'<img width="320" height="270" src="(.*?)"', txt)
for node in nodes:
print(url + node)
3.5. Xpath 提取
- 一般情況下非結構化的數據我們都會用Xpath來提取,正則匹配效率低,且步驟較爲繁雜
- 瞭解 html和xml的區別
- 掌握 xpath獲取節點屬性的方法
- 掌握 xpath獲取文字的方法
- 掌握 xpath查詢特定節點的方法
1 爲什麼要學習xpath和lxml
lxml是一款高效能的 Python HTML/XML 解析器,我們可以利用XPath,來快速的定位特定元素以及獲取節點資訊
2 什麼是xpath
XPath (XML Path Language) 是一門在 HTML\XML 文件中查詢資訊的語言,可用來在 HTML\XML 文件中對元素和屬性進行遍歷。
W3School官方文件:http://www.w3school.com.cn/xpath/index.asp
3.瞭解xml (已淘汰,僅存部分組態檔有應用)
xml使用一系列簡單的標記描述數據,而這些標記可以用方便的方式建立,雖然可延伸標示語言佔用的空間比二進制數據要佔用更多的空間,但可延伸標示語言極其簡單易於掌握和使用。
4.xpath的節點關係
知識點:
- 認識xpath中的節點
- 瞭解xpath中節點之間的關係
4.1 xpath中的節點是什麼
每個XML的標籤我們都稱之爲節點,其中最頂層的節點稱爲根節點。

5 xpath中節點選擇的工具
- Chrome外掛 XPath Helper
- 下載地址:鏈接:https://pan.baidu.com/s/1psnkF25EkxsfsZjz5wLHdQ 提取碼:79fq
- Firefox外掛 XPath Checker
注意: 這些工具是用來學習xpath語法的,他們都是從elements中匹配數據,elements中的數據和url地址對應的響應不相同,所以在程式碼中,不建議使用這些工具進行數據的提取
Xpath Helper 快捷鍵 ctrl + shift +alt +x 【啓用Xpath視窗】
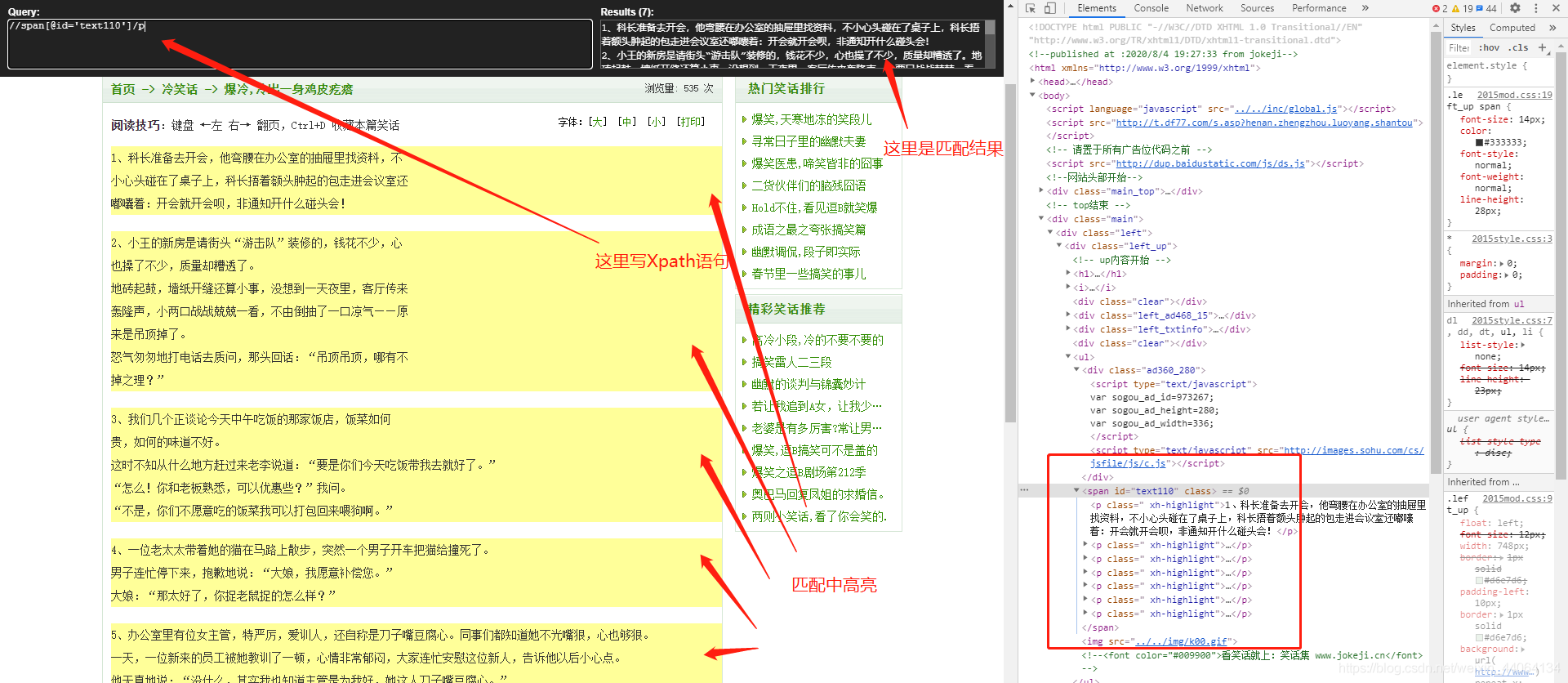
6.1 選取節點
XPath 使用路徑表達式來選取 XML 文件中的節點或者節點集。這些路徑表達式和我們在常規的電腦檔案系統中看到的表達式非常相似。
使用chrome外掛選擇標籤時候,選中時,選中的標籤會新增屬性class="xh-highlight"
下面 下麪列出了最有用的表達式:
| 表達式 | 描述 |
|---|---|
| nodename | 選中該元素。 |
| / | 從根節點選取、或者是元素和元素間的過渡。 |
| // | 從匹配選擇的當前節點選擇文件中的節點,而不考慮它們的位置。 |
| . | 選取當前節點。 |
| … | 選取當前節點的父節點。 |
| @ | 選取屬性。 |
| text() | 選取文字。 |
範例
目標URL: http://www.jokeji.cn/jokehtml/%E5%86%B7%E7%AC%91%E8%AF%9D/2020080419273330.htm
- 一般數據提取爲 json 或者 Xpath
3.6 lxml模組
- 應用 lxml庫提取數據方法
- 瞭解 lxml對數據處理和提取之後的數據型別
- 瞭解 lxml把element轉化爲字串的方法
在前面學習了xpath的語法,那麼在python爬蟲程式碼中我們如何使用xpath呢? 對應的我們需要lxml
1 lxml的安裝
pip install lxml
2 lxml的使用
2.1 lxml模組的入門使用
-
匯入lxml 的 etree 庫 (匯入沒有提示不代表不能用)
from lxml import etree -
利用etree.HTML,將字串轉化爲Element物件,Element物件具有xpath的方法,返回結果的列表,能夠接受bytes型別的數據和str型別的數據
html = etree.HTML(text) ret_list = html.xpath("xpath字串") -
把轉化後的element物件轉化爲字串,返回bytes型別結果
etree.tostring(element)
假設我們現有如下的html字元換,嘗試對他進行操作
案例7
目標URL: http://www.jokeji.cn/jokehtml/%E5%86%B7%E7%AC%91%E8%AF%9D/2020080419273330.htm
爬取十頁冷笑話
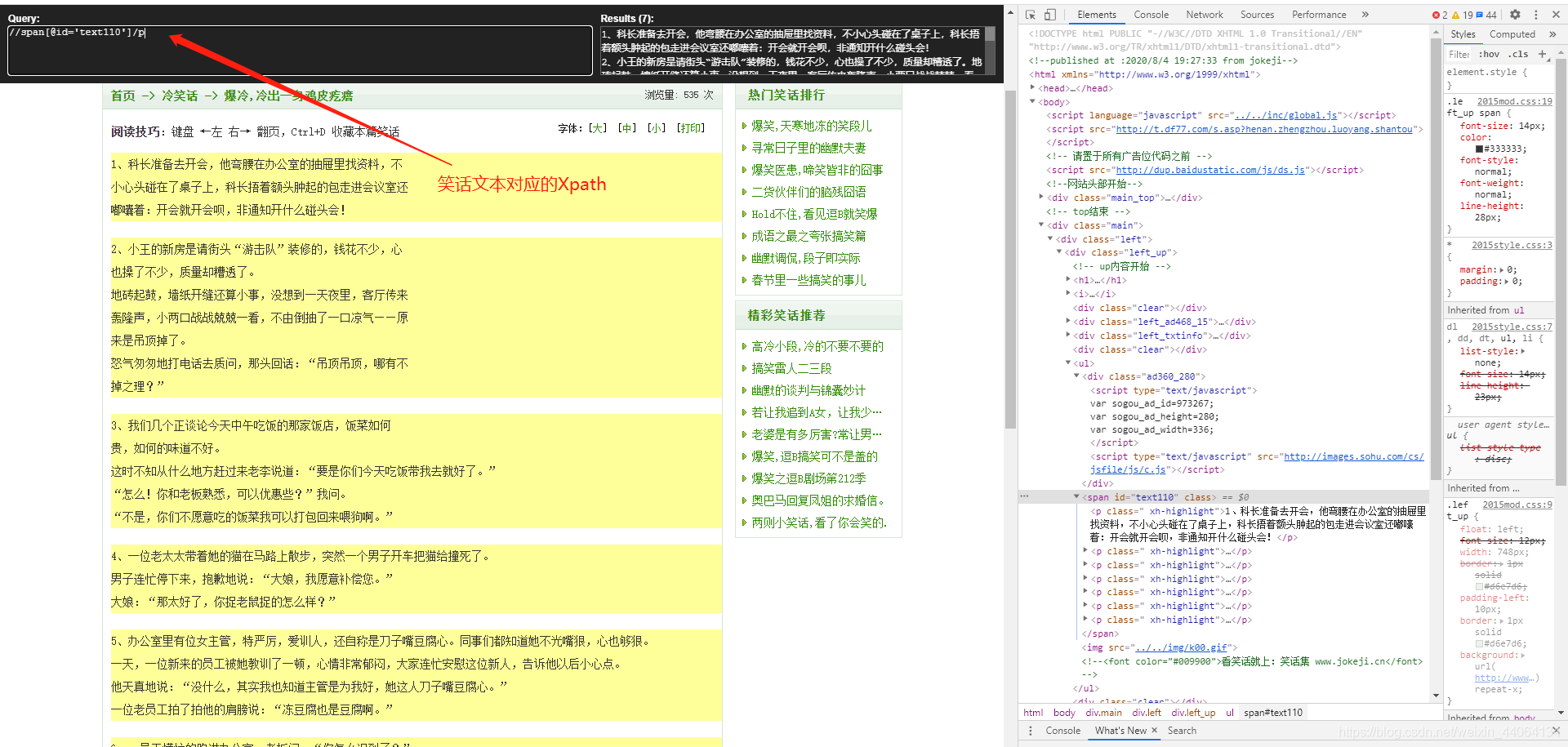
//span[@id='text110']/p
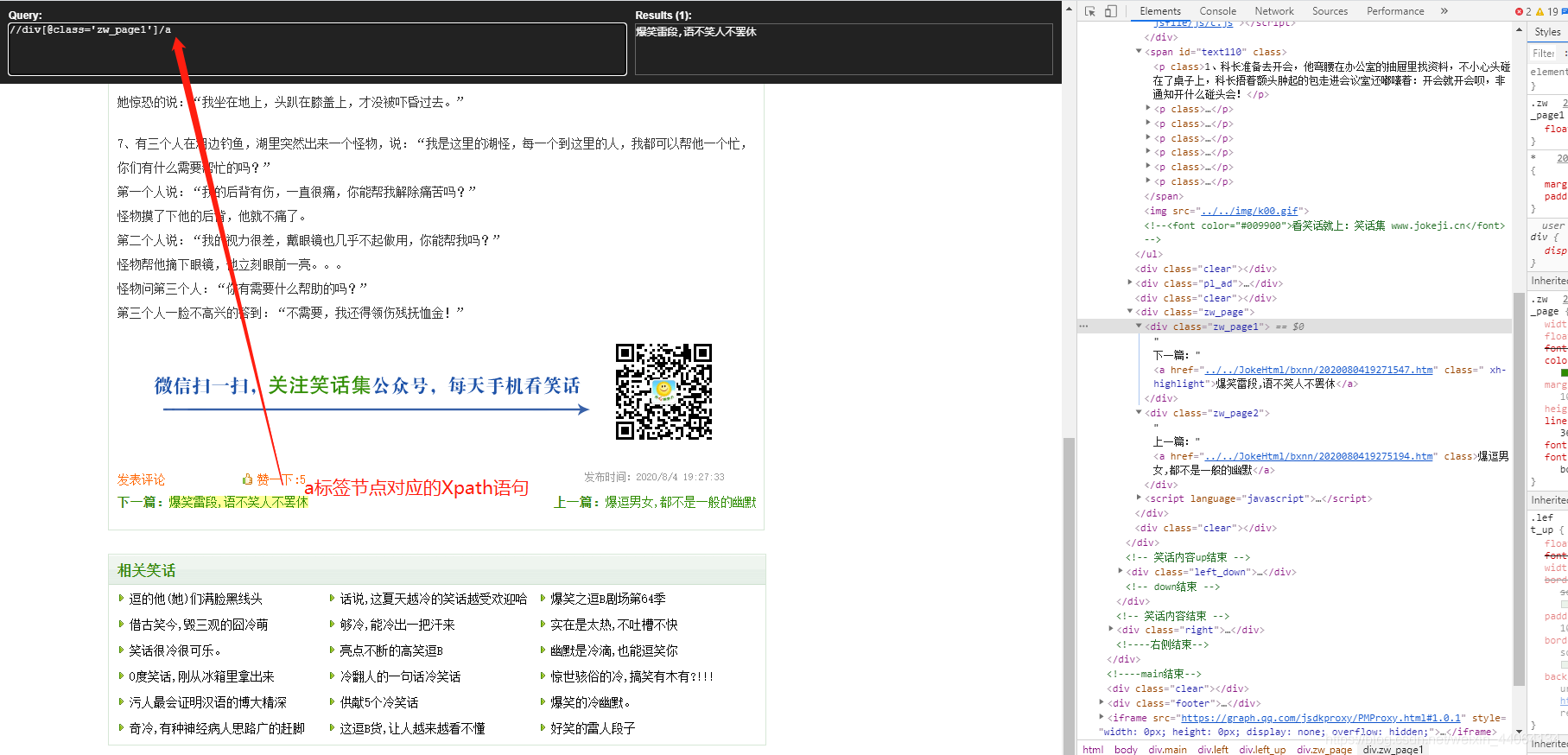
//div[@class='zw_page1']/a
import requests
from lxml import etree
"""jokehtml/冷笑話/2020080419273330.htm""" # 頭頁結點
class Joke:
def __init__(self):
self._count = 1
def get(self, url, page):
self._url = "http://www.jokeji.cn/" + url # 拼接組建新頁的URL
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"Referer": "http://www.jokeji.cn/list43_1.htm"
}
response = requests.get(self._url, headers)
self.analytical(response, page)
def analytical(self, response, page):
html = etree.HTML(response.content.decode("gbk"))
if self._count < page:
self._count += 1
node = html.xpath("//div[@class='zw_page1']/a/@href")[0][5:] # 提取下一頁的url節點
self.get(node, page)
jokes = html.xpath("//span[@id='text110']/p/text()") # 解析笑話節點
for joke in jokes:
print(joke)
print("===" * 15)
if __name__ == '__main__':
joke = Joke()
joke.get("jokehtml/冷笑話/2020080419273330.htm", 10)
練習6
百度音樂【千千音樂】 https://music.taihe.com/
要求輸入歌手名字即可返回其的歌曲,及鏈接(4 星)
參考答案 提取碼:2pfv
4. 總結
- 到此爲止爬蟲入門的所有內容就學完了
- 最後一個練習中所用的知識,幾乎貫穿了整個爬蟲開發流程的知識點
"""
本次練習比較複雜,沒有加入翻頁功能,翻頁的URL在JS裏邊,需要對網站JS程式碼進行進一步的剖析
涉及知識點:
1.reuqests的使用,headers、params參數等
2.使用者ip代理
3.多種反反爬手段
4.Json數據提取 json結構分析
5.Xpath數據提取 xpath數據定位
6.jsonpath模組的使用
7.lxml模組的使用
8.retrying模組的使用
9.檔案的讀寫
10.系統操作
"""
- 至此已經可以爬取web上的70%左右的數據
- 後邊還有進階內容爬蟲效能提升:
- 多執行緒爬蟲,多進程爬蟲
- 自動化無頭瀏覽器 selenium 模組
- 打碼平臺、驗證碼識別、滾軸驗證碼等
- 爬蟲的反反爬策略,js解析等
- Scrapy爬蟲框架
- Scrapy-redis 分佈式
- 爬蟲部署上線
- 爬蟲 + 數據分析 + Web 開發一體化【數據視覺化】 echarts模組等
(博主能力有限,如有錯誤的地方,歡迎批評指正,歡迎大家點選關注,以防錯過最新內容)