強化學習(三) - Gym庫介紹和使用,Markov決策程式範例,動態規劃決策範例
強化學習(三) - Gym庫介紹和使用,Markov決策程式範例,動態規劃決策範例
1. 引言
在這個部分補充之前馬爾科夫決策和動態規劃部分的程式碼。在以後的內容我會把相關程式碼都附到相關內容的後面。本部分程式碼和將來的程式碼會參考《深度強化學習原理與python實現》與Udacity的課程《Reinforcement Learning》。
2. Gym庫
Gym庫(http://gym.openai.com/)是OpenAI推出的強化學習實驗環境庫,它用python語言實現了離散時間智慧體/環境介面中的環境部分。除了依賴少量的商業庫外,整個專案時開源免費的。

Gym庫內建上百種實驗環境,包括以下幾類。
- 演算法環境:包括一些字串處理等傳統計算機方法的實驗環境。
- 簡單文字環境:包括幾個用文字表示的簡單遊戲。
- 經典控制環境:包括一些簡單幾何體運動,常用於經典強化學習演算法的研究。
- Atari遊戲環境:包括數十個Atari 2600遊戲,具有畫素化的圖形介面,希望玩家儘可能奪得高分。
- MuJoCo環境:利用收費的MuJoCo運動引擎進行連續性的控制任務。
- 機械控制環境:關於機械臂的抓取和控制等。
2.1 Gym庫安裝
Python版本要求爲 3.5+(在以後的內容中我將使用python 3.6)。然後就可以是使用pip安裝Gym庫
首先升級pip,
pip install --upgrade pip
以下命令爲最小安裝Gym環境,
pip install gym
利用原始碼構建
如果願意,還可以直接克隆gym Git儲存庫。若想要修改Gym本身或新增環境時,這是特別有用的。下載和安裝使用:
git clone https://github.com/openai/gym
cd gym
pip install -e .
之後可以執行pip install -e .[all]來執行包含所有環境的完整安裝。這需要安裝多個涉及的依賴項,包括cmake和一個最近的pip版本。
2.2 Gym庫使用
2.2.1 環境(enviroment)
這裏有一個執行程式的最簡單的例子。這將爲1000個時間步驟執行CartPole-v0環境的一個範例,並在每個步驟中呈現環境。你應該看到一個視窗彈出渲染經典的車桿問題:
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # 採取隨機行動
env.close()
輸出如下:
通常,我們將結束模擬之前,車桿被允許離開螢幕。現在,忽略關於呼叫step()的警告,即使這個環境已經返回done = True。
如果希望執行其他一些環境,可以嘗試用類似MountainCar-v0、MsPacman-v0(需要Atari依賴項)或Hopper-v1(需要MuJoCo依賴項)來替換上面的cartpole-v0。環境都來自於Env基礎類別。
若丟失了任何依賴項,應該會得到錯誤訊息來提示丟失了什麼。安裝缺少的依賴項通常非常簡單。對於Hopper-v1需要一個的MuJoCo許可證。
程式碼解釋
匯入Gym庫:
import gym
在匯入Gym庫後,可以通過make()函數來得到環境物件。每一個環境都有一個ID,它是形如「Xxxxx-v0」的字串,如「CartPloe-v0」等。環境名稱的最後的部分表示版本號,不同版本的環境可能有不同的行爲。使用取出環境「CartPloe-v0」的程式碼爲:
env = gym.make('CartPole-v0')
想要檢視當前的Gym庫已經註冊了哪些環境,可以使用以下程式碼:
from gym import envs
env_specs = envs.registry.all()
env_ids = [env_spec.id for env_spec in env_specs]
env_ids
每個環境都定義了自己的觀測空間和動作空間。環境env的觀測空間用env.observation_space表示,動作空間用env.action_space表示。觀測空間和動作空間既可以是離散空間(即取值是有限個離散的值),也可以使連續的空間(即取值是連續的)。在Gym庫中,離散空間一般用gym.spaces.Discrete類表示,連續空間用gym.spaces.Box類表示。例如,環境‘MountainCar-v0’的動作空間是Box(2,)表示觀測可以用2個float值表示;環境‘MountainCar-v0’的動作空間是Dicrete(3),表示動作取自{0,1,2}。對於離散空間gym.spaces.Discrete類範例成員n表示有幾個可能的取值;對於連續空間,Box類範例的成員low和high表示每個浮點數的取值範圍。
接下來使用環境物件env。首先初始化環境物件env,
env.reset()
該呼叫能返回智慧體的初始觀測,是np.array物件。
環境初始化之後就可以使用了。使用環境的核心是使用環境物件的step()方法,具體內容會在下面 下麪介紹。
env.step()的參數需要取自動作空間。可以使用以下語句從動作空間中隨機選取一個動作。
action = env.action_space.sample()
每次呼叫env.step()只會讓環境前進一步。所以,env.step()往往放在回圈結構裡,通過回圈呼叫來完成整個回合。
在env.reset()或env.step()後,可以使用以下語句以圖形化的方法顯示當前的環境。
env.render()
使用完環境後,可以使用下列語句關閉環境。
env.close()
如果繪製和實驗的圖形介面視窗,那麼關閉該視窗的最佳方式是呼叫env.close()。試圖直接關閉圖形介面可能會導致記憶體不能釋放,甚至會導致宕機。
測試智慧體在Gym庫中某個任務的效能時,學術界一般最關心100個回合的平均回合獎勵。對於有些環境,還會制定一個參考的回合獎勵值,當連續100個回合的獎勵大於指定的值時,就認爲這個任務被解決了。但是,並不是所有的任務都指定了這樣的值。對於沒有指定值的任務,就無所謂任務被解決了或者沒有被解決。
2.2.2 觀測(observation)
如果我們想得到一個更好的結果,那我們就不能在每一步都採取隨機的行動。我們需要知道我們的行動對環境做了什麼可能會更好。
環境的step函數返回的正是我們需要的東西。事實上,step函數會返回四個值。這四個值是
- observation (object): 一個特定環境的物件,代表智慧體對環境的觀察。例如,來自攝像頭的畫素數據,機器人的關節角度和關節速度,或者棋盤遊戲中的棋盤狀態,和env.reset()返回值的意義相同。。
- reward(float):前一個動作所獲得的獎勵量。不同環境下的比例不同,但目標始終是增加你的總獎勵。
- done (boolean):是否要再次重置環境。大多數(但不是全部)任務都被劃分爲定義明確的情節,done爲True表示該情節已經終止。(例如,可能是桿子 桿子翻得太厲害,或者失去了最後的生命。)
- info(dict):對偵錯有用的診斷資訊。它有時會對學習有用(例如,它可能包含環境最後一次狀態變化背後的原始概率)。然而,你的智慧體的評估是不允許使用它來學習的。
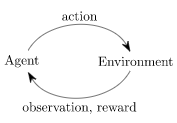
這只是經典的 "智慧體-環境回圈 "的一個實現。每一個時間步,智慧體選擇一個動作(action),環境返回一個觀察(observation)和一個獎勵(reward)。
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
輸出如下:
[-0.061586 -0.75893141 0.05793238 1.15547541]
[-0.07676463 -0.95475889 0.08104189 1.46574644]
[-0.0958598 -1.15077434 0.11035682 1.78260485]
[-0.11887529 -0.95705275 0.14600892 1.5261692 ]
[-0.13801635 -0.7639636 0.1765323 1.28239155]
[-0.15329562 -0.57147373 0.20218013 1.04977545]
Episode finished after 14 timesteps
[-0.02786724 0.00361763 -0.03938967 -0.01611184]
[-0.02779488 -0.19091794 -0.03971191 0.26388759]
[-0.03161324 0.00474768 -0.03443415 -0.04105167]
2.2.3 空間(spaces)
在上面的範例中,我們從環境的操作空間中隨機取樣操作。但這些行爲到底是什麼呢?每個環境都帶有一個action_space和一個observation_space。這些屬性型別爲Space,它們描述了有效動作和觀察的格式:
import gym
env = gym.make('CartPole-v0')
print(env.action_space)
#> Discrete(2)
print(env.observation_space)
#> Box(4,)
離散(Discrete)空間允許一個固定的非負數範圍,因此在本例中有效的動作(action)要麼是0要麼是1。Box空間表示一個n維的盒子,因此有效的觀察結果將是一個4個數字的陣列。我們也可以檢查Box的邊界:
print(env.observation_space.high)
#> array([ 2.4 , inf, 0.20943951, inf])
print(env.observation_space.low)
#> array([-2.4 , -inf, -0.20943951, -inf])
這種內省有助於編寫適用於許多不同環境的泛型程式碼。Box和離散空間是最常見的空間(space)。我們可以從一個空間取樣或檢查某物是否屬於它:
from gym import spaces
space = spaces.Discrete(8) # Set with 8 elements {0, 1, 2, ..., 7}
x = space.sample()
assert space.contains(x)
assert space.n == 8
2.2.4 程式範例
這裏我們通過一個完整的例子來學習如何與Gym庫中的環境互動,選用經典控制任務,小車上山(MountainCar-v0)。這裏主要介紹互動的程式碼,而不詳細說明這個控制任務及其求解。
首先我們看一下這個任務的觀測空間的動作空間
import gym
env = gym.make('MountainCar-v0')
print('觀測空間 = {}'.format(env.observation_space))
print('動作空間 = {}'.format(env.action_space))
print('觀測範圍 = {} ~ {}'.format(env.observation_space.low, env.observation_space.high))
print('動作數 = {}'.format(env.action_space.n))
輸出如下,
觀測空間 = Box(2,)
動作空間 = Discrete(3)
觀測範圍 = [-1.2 -0.07] ~ [0.6 0.07]
動作數 = 3
執行結果告訴我們,觀測空間是形狀爲(2,)的浮點型np.array,而動作空間是取{0, 1, 2}的int型數值。
接下來考慮智慧體。智慧體往往是我們自己實現的。下面 下麪程式碼給出了一個智慧體類——BespokeAgent類。智慧體的decide()方法實現了決策功能,而learn()方法實現了學習功能。BespokeAgent類是一個比較簡單的類,它只能根據給定的數學表達式進行決策,並且不能有效學習。所以它並不是一個真正意義上的強化學習智慧體類。但是,用於演示智慧體和環境的互動已經足夠了。
class BespokeAgent:
def __init__(self, env):
pass
def decide(self, observation): # 決策
position, velocity = observation
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03, 0.3 * (position + 0.9) ** 4 - 0.008)
ub = -0.07 * (position + 0.38) ** 2 + 0.06
if lb < velocity < ub:
action = 2
else:
action = 0
return action # 返回動作
def learn(self, *args): # 學習
pass
agent = BespokeAgent(env)
接下來我們試圖讓智慧體與環境互動。play_once()函數可以讓智慧體和環境互動一個回合。這個函數有4個參數。
- 參數env是環境類。
- 參數agent是智慧體類。
- 參數render是bool型別變數,指示在執行過程中是否要圖形化顯示。如果函數參數render爲True,那麼在互動過程中會呼叫env.render()以顯示圖形化介面,而這個介面可以通過呼叫env.close()關閉。
- 參數train是bool型別的變數,指示在執行過程中是否訓練智慧體。在訓練過程中應當設定爲True,以呼叫agent.learn()函數;在測試過程中應當設定爲False,使得智慧體不變。
這個函數有一個返回值episode_reward,是float型別的數值,表示智慧體與環境互動一個回合的回合總獎勵。
def play_montecarlo(env, agent, render=False, train=False):
episode_reward = 0. # 記錄回合總獎勵,初始化爲0
observation = env.reset() # 重置遊戲環境,開始新回合
while True: # 不斷回圈,直到回合結束
if render: # 判斷是否顯示
env.render() # 顯示圖形介面,圖形介面可以用env.close()語句關閉
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action) # 執行動作
episode_reward += reward # 收集回合獎勵
if train: # 判斷是否訓練智慧體
agent.learn(observation, action, reward, done) # 學習
if done: # 回合結束,跳出回圈
break
observation = next_observation
return episode_reward # 返回回合總獎勵
我們可以用下列程式碼讓智慧體和環境互動一個回合,並在互動過程中圖形化顯示。互動完畢後,可用env.close()語句關閉圖形化介面。
env.seed(0) # 設定亂數種子,只是爲了讓結果可以精確復現,一般情況下可刪去
episode_reward = play_montecarlo(env, agent, render=True)
print('回合獎勵 ={}'.format(episode_reward))
env.close() # 此語句可關閉圖形介面
爲了系統評估智慧體的效能,下列程式碼求出了連續互動100回合的平均回合獎勵。小車上山環境有一個參考的回合獎勵值-110,如果當連續100個回合的平均回合獎勵大於-110,則認爲這個任務被解決了。BespokeAgent類對應的策略的平均回合獎勵大概就在-110左右。
episode_rewards = [play_montecarlo(env, agent) for _ in range(100)]
print('平均回合獎勵 ={}'.format(np.mean(episode_rewards)))
3.Markov 決策過程
3.1 範例:懸崖尋路
本節考慮Gym庫中懸崖尋路問題(CliffWalking-v0)。懸崖尋路問題是這樣一種回合制問題:在一個的網格中,智慧體最開始在左下角的網格,希望移動到右下角的網格。智慧體每次可以在上下左右這四個方向中移動一步,每移動一步會懲罰一個單位的獎勵。但是,移動有以下的限制。
- 智慧體不能移出網格。如果智慧體想執行某個動作移出網格,那麼就讓本步不移動。但是這個操作仍然會懲罰一個單位的獎勵。
- 如果智慧體將要到達最下一排網格(幾開始網格和目標網格之間的10個網格),智慧體會立刻回到開始網格,並懲罰100個單位的獎勵。這10個網格可被視爲「懸崖」。
當智慧體移動到終點時,回合結束,回合獎勵爲各步獎勵相加。

3.1.1 實驗環境使用
以下程式碼演示瞭如何倒入這個環境並檢視這個環境的基本資訊。
import gym
env = gym.make('CliffWalking-v0')
print('觀察空間 = {}'.format(env.observation_space))
print('動作空間 = {}'.format(env.action_space))
print('狀態數量 = {}, 動作數量= {}'.format(env.nS, env.nA))
print('地圖大小 = {}'.format(env.shape))
輸出爲,
觀察空間 = Discrete(48)
動作空間 = Discrete(4)
狀態數量 = 48, = 4
地圖大小 = (4, 12)
這個環境是一個離散的Markov決策過程。在這個Markov決策過程中,每個狀態是取自的int型數值(加上終止狀態則爲):0表示向上,1表示向右,2表示向下,3表示向左。獎勵取自,遇到懸崖爲-100,否則爲-1。
下面 下麪程式碼給出了用給出的策略執行一個回合的程式碼。函數play_once()有兩個參數, 一個是環境物件,另外一個是策略policy,它是np.array型別的範例。
import numpy as np
def play_once(env, policy):
total_reward = 0
state = env.reset()
loc = np.unravel_index(state, env.shape)
print('狀態 = {} , 位置={} '.format(state, loc))
while True:
action = np.random.choice(env.nA, p=policy[state])
# step函數,詳情見2.2.2 觀測
next_state, reward, done, _ = env.step(action)
print('狀態 = {}, 位置 ={}, 獎勵 ={}'.format(state, loc, reward))
total_reward += reward
if done:
break
state = next_state
return total_reward
以下程式碼給出了一個最優策略。optimal_policy最優策略是在開始處向上,接着一 路向右,然後到最右邊時向下。
actions = np.ones(env.shape, dtype=int)
actions[-1, :] = 0
actions[:, -1] = 2
optimal_policy = np.eye(4)[actions.reshape(-1)]
下面 下麪的程式碼用最優策略執行一個回合。採用最優策略,從開始網格到目標網格一共要 移動13步,回合總獎勵爲-13。
total_reward = play_once(env, optimal_policy)
print('總獎勵 ={}'.format(total_reward))
輸出爲,
狀態 = 36, 位置 =(3, 0), 獎勵 =-1
狀態 = 24, 位置 =(2, 0), 獎勵 =-1
狀態 = 25, 位置 =(2, 1), 獎勵 =-1
狀態 = 26, 位置 =(2, 2), 獎勵 =-1
狀態 = 27, 位置 =(2, 3), 獎勵 =-1
狀態 = 28, 位置 =(2, 4), 獎勵 =-1
狀態 = 29, 位置 =(2, 5), 獎勵 =-1
狀態 = 30, 位置 =(2, 6), 獎勵 =-1
狀態 = 31, 位置 =(2, 7), 獎勵 =-1
狀態 = 32, 位置 =(2, 8), 獎勵 =-1
狀態 = 33, 位置 =(2, 9), 獎勵 =-1
狀態 = 34, 位置 =(2, 10), 獎勵 =-1
狀態 = 35, 位置 =(2, 11), 獎勵 =-1
總獎勵 =-13
3.1.2 求解Bellman期望方程
接下來考慮策略評估。我們用Bellman期望方程求解給定策略的狀態價值和動作價值。 首先來看狀態價值。用狀態價值表示狀態價值的Bellmn期望方程爲:
這是一個線性方程組,其標準形式爲
得到標準形式後就可以呼叫相關函數直接求解。得到狀態價值函數後,可以用狀態價值表示動作價值的Bellan方程,
來求動作價值函數。
函數evaluate_bellman ()實現了上述功能。狀態價值求解部分用np.linalg.solve()函數求解標準形式的線性方程組。得到狀態價值後,直接計算得到動作價值.
環境的動力系統儲存在env.P裡,它是一個元組列表,每個元組包括概率、下一狀態、獎勵\回合結束指示這4個部分。
# 用Bellman方程求解狀態價值和動作價值
def evaluate_bellman(env, policy, gamma=1.):
a, b = np.eye(env.nS), np.zeros((env.nS))
for state in range(env.nS - 1):
for action in range(env.nA):
pi = policy[state][action]
# print('{}{}:pi:{}'.format(state, action, pi))
# env.P中儲存環境的動力
for p, next_state, reward, done in env.P[state][action]:
a[state, next_state] -= (pi * gamma)
b[state] += (pi * reward * p)
# np.linalg.solve()函數求解標準形式的線性方程組
v = np.linalg.solve(a, b)
q = np.zeros((env.nS, env.nA))
# 利用狀態價值函數求解動作價值函數
for state in range(env.nS - 1):
for action in range(env.nA):
for p, next_state, reward, done in env.P[state][action]:
q[state][action] += ((reward + gamma * v[next_state]) * p)
return v, q
接下來使用evaluate_bellman()函數評估給出的策略。以下程式碼分別評估了一個隨機策略和最優確定性策略,並輸出了狀態價值函數和動作價值函數。
評估隨機策略,
policy = np.random.uniform(size=(env.nS, env.nA))
policy = policy / np.sum(policy, axis=1)[:, np.newaxis]
state_values, action_values = evaluate_bellman(env, policy)
print('狀態價值 ={}'.format(state_values))
print('動作價值 ={}'.format(action_values))
狀態價值 =[-134140.09187241 -134085.47213402 -133971.92139818 -133616.23666259
-133194.20403738 -132781.56536103 -132435.88940662 -128380.91096168
...
-133680.76568151 -130121.16858665 -115062.2396112 0. ]
動作價值 =[[-1.34141092e+05 -1.34086472e+05 -1.34152621e+05 -1.34141092e+05]
[-1.34086472e+05 -1.33972921e+05 -1.34152699e+05 -1.34141092e+05]
...
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00]]
評估最優策略,
optimal_state_values, optimal_action_values = evaluate_bellman(env, optimal_policy)
print('最優狀態價值 = {}'.format(optimal_state_values))
print('最優動作價值 = {}'.format(optimal_action_values))
最優狀態價值 = [[-14. -13. -12. -11. -10. -9. -8. -7. -6. -5. -4. -3.]
[-13. -12. -11. -10. -9. -8. -7. -6. -5. -4. -3. -2.]
[-12. -11. -10. -9. -8. -7. -6. -5. -4. -3. -2. -1.]
[-13. -12. -11. -10. -9. -8. -7. -6. -5. -4. -3. 0.]]
最優動作價值 = [[ -15. -14. -14. -15.]
[ -14. -13. -13. -15.]
[ -13. -12. -12. -14.]
...
[ 0. 0. 0. 0.]]
3.1.3 求解Bellman最優方程
對於懸崖尋路這樣的數值環境,可以使用線性規劃求解。線性規劃問題的標準形式爲:
其中目標函數中狀態價值的係數已經被固定爲1。也可以選擇其他正實數作爲係數。
以下程式碼使用scipy.optimize.linprog()函數來計算這個動態規劃問題。
scipy.optimize.linprog(c,A_ub = None,b_ub = None,A_eq = None,b_eq = None,bounds = None,method = 'interior-point',callback = None,options = None,x0 = None)
其中,c是價值向量;A_ub和b_ub對應線性不等式約束;A_eq和b_eq對應線性等式約束;bounds對應公式中的lb和ub,決策向量的下界和上界;method是求解器的型別,如單純形法.
官方幫助文件可檢視此處.
這個函數的 第0個參數是目標函數中各決策變數在目標函數中的係數,本例中都取1;第1個和第2個 參數是形如「」這樣的不等式約束的A和b的值。函數optimal_bellman ()剛開始就 計算得到這些值。scipy.optimize.linprog()還有關鍵字參數bounds,指定決策變數是否爲有界的。本例中,決策變數都是無界的。無界也要顯式指定,不可以忽略。還有關鍵字參數 method確定優化方法。預設的優化方法不能處理不等式約束,這裏選擇了能夠處理不等式約束的內點法(interior-point method)。
import scipy
def optimal_bellman(env, gamma=1.):
p = np.zeros((env.nS, env.nA, env.nS))
r = np.zeros((env.nS, env.nA))
for state in range(env.nS - 1):
for action in range(env.nA):
for prob, next_state, reward, done in env.P[state][action]:
p[state, action, next_state] += prob
r[state, action] += (reward * prob)
c = np.ones(env.nS)
a_ub = gamma * p.reshape(-1, env.nS) - np.repeat(np.eye(env.nS), env.nA, axis=0)
b_ub = -r.reshape(-1)
a_eq = np.zeros((0, env.nS))
b_eq = np.zeros(0)
bounds = [(None, None), ] * env.nS
res = scipy.optimize.linprog(c, a_ub, b_ub, bounds=bounds, method='interior-point')
v = res.x
q = r + gamma * np.dot(p, v)
return v, q
optimal_state_values, optimal_action_values = optimal_bellman(env)
print('最優狀態價值 ={}'.format(optimal_state_values))
print('最優動作價值 ={}'.format(optimal_action_values))
求得最優動作價值後,可以用argmax計算出最優確定策略。以下程式碼給出了最優策略,
optimal_actions = optimal_action_values.argmax(axis=1)
print('最優策略 ={}'.format(optimal_actions))
在pycharm IDE下的總程式爲
import gym
import numpy as np
import scipy
# 單回合執行函數
def play_once(env, policy):
total_reward = 0
state = env.reset()
while True:
action = np.random.choice(env.nA, p=policy[state])
next_state, reward, done, _ = env.step(action)
# np.unravel_index函數的作用是獲取一個/組int型別的索引值在一個多維陣列中的位置。
loc = np.unravel_index(state, env.shape)
print('狀態 = {}, 位置 ={}, 獎勵 ={}'.format(state, loc, reward))
total_reward += reward
if done:
break
state = next_state
return total_reward
# 用Bellman方程求解狀態價值和動作價值
def evaluate_bellman(env, policy, gamma=1.):
a, b = np.eye(env.nS), np.zeros((env.nS))
for state in range(env.nS - 1):
for action in range(env.nA):
pi = policy[state][action]
# print('{}{}:pi:{}'.format(state, action, pi))
# env.P中儲存環境的動力
for p, next_state, reward, done in env.P[state][action]:
a[state, next_state] -= (pi * gamma)
b[state] += (pi * reward * p)
# np.linalg.solve()函數求解標準形式的線性方程組
v = np.linalg.solve(a, b)
q = np.zeros((env.nS, env.nA))
# 利用狀態價值函數求解動作價值函數
for state in range(env.nS - 1):
for action in range(env.nA):
for p, next_state, reward, done in env.P[state][action]:
q[state][action] += ((reward + gamma * v[next_state]) * p)
return v, q
# 使用動態規劃求解最優策略
def optimal_bellman(env, gamma=1.):
p = np.zeros((env.nS, env.nA, env.nS))
r = np.zeros((env.nS, env.nA))
for state in range(env.nS - 1):
for action in range(env.nA):
for prob, next_state, reward, done in env.P[state][action]:
p[state, action, next_state] += prob
r[state, action] += (reward * prob)
c = np.ones(env.nS)
a_ub = gamma * p.reshape(-1, env.nS) - np.repeat(np.eye(env.nS), env.nA, axis=0)
b_ub = -r.reshape(-1)
a_eq = np.zeros((0, env.nS))
b_eq = np.zeros(0)
bounds = [(None, None), ] * env.nS
res = scipy.optimize.linprog(c, a_ub, b_ub, bounds=bounds, method='interior-point')
v = res.x
q = r + gamma * np.dot(p, v)
return v, q
# 主函數
if __name__ == '__main__':
env = gym.make('CliffWalking-v0')
print('觀察空間 = {}'.format(env.observation_space))
print('動作空間 = {}'.format(env.action_space))
print('狀態數量 = {}, 動作數量= {}'.format(env.nS, env.nA))
print('地圖大小 = {}'.format(env.shape))
'''
# 定義最優策略
actions = np.ones(env.shape, dtype=int)
actions[-1, :] = 0
actions[:, -1] = 2
optimal_policy = np.eye(4)[actions.reshape(-1)]
total_reward = play_once(env, optimal_policy)
print('總獎勵 ={}'.format(total_reward))
optimal_state_values, optimal_action_values = evaluate_bellman(env, optimal_policy)
print('最優狀態價值 = {}'.format(optimal_state_values.reshape(4, -1)))
print('最優動作價值 = {}'.format(optimal_action_values))
'''
'''
# 定義隨機策略
policy = np.random.uniform(size=(env.nS, env.nA))
# 歸一化
policy = policy / np.sum(policy, axis=1)[:, np.newaxis]
state_values, action_values = evaluate_bellman(env, policy)
print('狀態價值 ={}'.format(state_values))
print('動作價值 ={}'.format(action_values))
'''
# 求解最優策略
optimal_state_values, optimal_action_values = optimal_bellman(env)
print('最優狀態價值 ={}'.format(optimal_state_values))
print('最優動作價值 ={}'.format(optimal_action_values))
optimal_actions = optimal_action_values.argmax(axis=1)
print('最優策略 ={}'.format(optimal_actions))
輸出爲,
觀察空間 = Discrete(48)
動作空間 = Discrete(4)
狀態數量 = 48, 動作數量= 4
地圖大小 = (4, 12)
最優狀態價值 =[-1.40000000e+01 -1.30000000e+01 -1.20000000e+01 -1.10000000e+01
-1.00000000e+01 -9.00000000e+00 -8.00000000e+00 -7.00000000e+00
-6.00000000e+00 -5.00000000e+00 -4.00000000e+00 -3.00000000e+00
-1.30000000e+01 -1.20000000e+01 -1.10000000e+01 -1.00000000e+01
-9.00000000e+00 -8.00000000e+00 -7.00000000e+00 -6.00000000e+00
-5.00000000e+00 -4.00000000e+00 -3.00000000e+00 -2.00000000e+00
-1.20000000e+01 -1.10000000e+01 -1.00000000e+01 -9.00000000e+00
-8.00000000e+00 -7.00000000e+00 -6.00000000e+00 -5.00000000e+00
-4.00000000e+00 -3.00000000e+00 -2.00000000e+00 -1.00000000e+00
-1.30000000e+01 -1.20000000e+01 -1.10000000e+01 -1.00000000e+01
-9.00000000e+00 -8.00000000e+00 -7.00000000e+00 -6.00000000e+00
-5.00000000e+00 -4.00000000e+00 -9.99999999e-01 1.82291993e-11]
最優動作價值 =[[ -14.99999999 -13.99999999 -13.99999999 -14.99999999]
[ -13.99999999 -13. -13. -14.99999999]
...
[ 0. 0. 0. 0. ]]
最優策略 =[2 1 1 1 1 1 1 1 1 1 1 2
1 1 1 1 1 1 1 1 1 1 1 2
1 1 1 1 1 1 1 1 1 1 1 2
0 0 0 0 0 0 0 0 0 0 1 0]
4. 動態規劃
4.1 案例:冰面滑行
冰面滑行問題(FrozenLake-v0)是擴充套件庫Gym裡內建的一個文字環境任務。該問題的背景如下:在一個大小爲4x4的湖面上,有些地方結冰了,有些地方沒有結冰。我們可以用一個4x4的字元矩陣來表示湖面的情況,
SFFF
FHFH
FFFH
HFFG
其中字母「F」(Frozen)表示結冰的區域,字母「H」(Hole)表示未結冰的冰窟窿,字母「S」(Start)和字母「G」(Goal)分別表示移動任務的起點和目標。在這個湖面上要執行以下的移動任務:要從「S」處移動到「G」處。每一次移動,可以選擇「左」、「下」、「右」、「上」4個方向之一進行移動,每次移動一格。如果移動到G處,則回合結束,獲得1個單位的獎勵;如果移動到「H」處,則回合結束,沒有獲得獎勵;如果移動到其它字母,暫不獲得獎勵,可以繼續。由於冰面滑,所以實際移動的方向和想要移動的方向並不一定完全一致。例如,如果在某個地方想要左移,但是由於冰面滑,實際可能下移、右移或者上移。任務的目標是儘可能達到「G」處,以獲得獎勵。
4.1.1 實驗環境使用
首先我們來看如何使用擴充套件庫Gym中的環境。
用下列語句引入環境物件:
import gym
env = gym.make('FrozenLake-v0')
env = env.unwrapped
這個環境的狀態空間有16個不同的狀態,表示當前處在哪一個位置;動作空間有4個不同的動作,分別表示上、下、左、右四個方向。在擴充套件庫Gym中,直接用int型數值來表示這些狀態和動作。下列程式碼可以檢視環境的狀態空間和動作空間,
print(env.observation_space)
print(env.action_space)
這個環境的動力系統儲存在env.P裡。可以用下列方法檢視某個狀態(如狀態14)某個動作(如右移)情況下的動力,
env.unwrapped.P[14][2]
它是一個元組列表,每個元組包括概率、下一狀態、獎勵和回合結束指示這4個部分。例如,env.P[14][2]返回元組列表[(0.333333333333333,14, 0.0, False),(0.333333333333333, 15, 1.0 True), (0.333333333333333333, 10, 0.0, False)]這表明:
接下來我們來看怎麼使用環境。像之前介紹的,要使用env.reset()和env.step來執行。執行一個回合的程式碼如下所示,其中的play_policy()函數接受參數policy,這是一個16x4的np.array物件,表示策略。
play_policy()函數返回一個浮點數,表示本回合的獎勵。
# 使用策略執行一個回合
def play_policy(env, policy, render=False):
total_reward = 0.
observation = env.reset()
while True:
if render:
env.render() # 此行可顯示
action = np.random.choice(env.action_space.n, p=policy[observation])
observation, reward, done, _ = env.step(action)
total_reward += reward # 統計回合獎勵
if done: # 遊戲結束
break
return total_reward
接下來用剛剛定義的play_policy()函數來看看隨機策略的效能。下面 下麪程式碼夠早了隨機策略random_policy,它對於任意的均有.執行下列程式碼,可以求得隨機策略獲得獎勵的期望值。一般情況下的結果基本爲0,這意味着隨機策略幾乎不可能成功到達目的地。
# 隨機策略
random_policy = np.ones((env.unwrapped.nS, env.unwrapped.nA)) / env.unwrapped.nA
episode_rewards = [play_policy(env, random_policy) for _ in range(100)]
print("隨機策略 平均獎勵 :{}".format(np.mean(episode_rewards)))
4.1.2 有模型策略迭代求解
這個部分實現策略評估、策略提升和策略迭代。
首先來看策略評估。以下程式碼給出了策略評估的程式碼。它首先定義了函數v2q(),這個函數可以根據狀態價值函數計算含有某個狀態的動作價值函數。利用者函數evaluate_policy()函數迭代結算了給定策略policy的狀態價值。這個函數使用theta作爲精度控制的參數。之後的程式碼測試了evaluate_policy()函數。它首先求得了隨機策略的狀態價值函數,然後利用v2q求得動作價值函數。
# 策略評估的實現
def v2q(env, v, s=None, gamma=1.):
if s is not None:
q = np.zeros(env.unwrapped.nA)
for a in range(env.unwrapped.nA):
for prob, next_state, reward, done in env.unwrapped.P[s][a]:
q[a] += prob * (reward + gamma * v[next_state] * (1. - done))
else:
q = np.zeros((env.unwrapped.nS, env.unwrapped.nA))
for s in range(env.unwrapped.nS):
q[s] = v2q(env, v, s, gamma)
return q
# 定義策略評估函數
def evaluate_policy(env, policy, gamma=1., tolerant=1e-6):
v = np.zeros(env.unwrapped.nS)
while True:
delta = 0
for s in range(env.unwrapped.nS):
vs = sum(policy[s] * v2q(env, v, s, gamma))
delta = max(delta, abs(v[s]-vs))
v[s] = vs
if delta < tolerant:
break
return v
# 對隨機策略進行策略評估
print('狀態價值函數:')
v_random = evaluate_policy(env, random_policy)
print(v_random.reshape(4, 4))
print('動作價值函數:')
q_random = v2q(env, v_random)
print(q_random)
接下來看看策略改進。improve_policy()函數實現了策略改進演算法。輸入的策略是policy,改進後的策略直接覆蓋原有的policy。該函數返回一個bool型別的值,表示輸入的策略是不是最優策略。之後的程式碼測試了improve_policy()函數,它對隨機策略進行改進,得到了一個確定性策略。
# 策略改進的實現
def improve_policy(env, v, policy, gamma=1.):
optimal = True
for s in range(env.unwrappped.nS):
q = v2q(env, v, s, gamma)
a = np.argmax(q)
if policy[s][a] != 1:
optimal = False
policy[s] = 0.
policy[s][a] = 1.
return optimal
# 對隨機策略進行策略改進
policy = random_policy.copy()
optimal = improve_policy(env, v_random, policy)
if optimal:
print('無更新, 最優策略爲:')
else:
print('有更新,最優策略爲:')
print(policy)
實現了策略評估和策略改進後,我們就可以實現策略迭代。iterate_policy()函數實現了策略迭代演算法。之後的程式碼對iterate_policy()進行測試。針對冰面滑性問題,該程式碼求得了最優策略,並進行了測試。
# 策略迭代的實現
def iterate_policy(env, gamma=1., tolerant=1e-6:
policy = np.ones((env.unwrapped.nS, env.unwrapped.nA)) / env.wrapped.nA
while True:
v = evaluate_policy(env, policy, gamma, tolerant)
if improve_policy(env, v, policy):
break
return policy, v
# 利用策略迭代求解最優策略
policy_pi, v_pi = iterate_policy(env)
print('狀態價值函數 = ')
print(v_pi.reshape(4, 4)
print('最優策略 = ')
print(np.argmax(policy_pi, axis=1).reshape(4, 4))
4.1.3 有模型價值迭代求解
現在我們用價值迭代演算法求解冰面滑行問題的最優策略。以下程式碼中iterate_value()函數實現了價值迭代演算法。這個函數使用參數tolerant來控制價值迭代的精度。之後的程式碼在冰面滑行問題上測試了iterate_value()函數。
# 價值迭代的實現
def iterate_value(env, gamma=1, tolerant=1e-6):
v = np.zeros(env.unwrapped.nS)
while True:
delta = 0
for s in range(env.unwrapped.nS):
vmax = max(v2q(env, v, s, gamma))
delta = max(delta, abs(v[s]-vmax))
v[s] = vmax
if delta < tolerant:
break
policy = np.zeros((env.unwrapped.nS, env.unwrapped.nA))
for s in range(env.unwrapped.nS):
a = np.argmax(v2q(env, v, s, gamma))
policy[s][a] = 1.
return policy, v
# 利用策略迭代求解最優策略
policy_pi, v_pi = iterate_policy(env)
print('狀態價值函數 = ')
print(v_pi.reshape(4, 4))
print('最優策略 = ')
print(np.argmax(policy_pi, axis=1).reshape(4, 4))
print('價值迭代 平均獎勵:{}'.format(play_policy(env, policy_pi)))
策略迭代和價值迭代得到的最優價值函數和最優策略應該是一致的。最優狀態價值函數爲:
最優策略爲:
在pycharm中可以執行的總程式如下,
import gym
import numpy as np
# 使用策略執行一個回合
def play_policy(env, policy, render=False):
total_reward = 0.
observation = env.reset()
while True:
if render:
env.render() # 此行可顯示
action = np.random.choice(env.action_space.n, p=policy[observation])
observation, reward, done, _ = env.step(action)
total_reward += reward # 統計回合獎勵
if done: # 遊戲結束
break
return total_reward
# 策略評估的實現
def v2q(env, v, s=None, gamma=1.):
if s is not None:
q = np.zeros(env.unwrapped.nA)
for a in range(env.unwrapped.nA):
for prob, next_state, reward, done in env.unwrapped.P[s][a]:
q[a] += prob * (reward + gamma * v[next_state] * (1. - done))
else:
q = np.zeros((env.unwrapped.nS, env.unwrapped.nA))
for s in range(env.unwrapped.nS):
q[s] = v2q(env, v, s, gamma)
return q
# 定義策略評估函數
def evaluate_policy(env, policy, gamma=1., tolerant=1e-6):
v = np.zeros(env.unwrapped.nS)
while True:
delta = 0
for s in range(env.unwrapped.nS):
vs = sum(policy[s] * v2q(env, v, s, gamma))
delta = max(delta, abs(v[s]-vs))
v[s] = vs
if delta < tolerant:
break
return v
# 策略改進
def improve_policy(env, v, policy, gamma=1.):
optimal = True
for s in range(env.unwrapped.nS):
q = v2q(env, v, s, gamma)
a = np.argmax(q)
if policy[s][a] != 1:
optimal = False
policy[s] = 0.
policy[s][a] = 1.
return optimal
# 策略迭代的實現
def iterate_policy(env, gamma=1., tolerant=1e-6):
policy = np.ones((env.unwrapped.nS, env.unwrapped.nA)) / env.unwrapped.nA
while True:
v = evaluate_policy(env, policy, gamma, tolerant)
if improve_policy(env, v, policy):
break
return policy, v
# 價值迭代的實現
def iterate_value(env, gamma=1, tolerant=1e-6):
v = np.zeros(env.unwrapped.nS)
while True:
delta = 0
for s in range(env.unwrapped.nS):
vmax = max(v2q(env, v, s, gamma))
delta = max(delta, abs(v[s]-vmax))
v[s] = vmax
if delta < tolerant:
break
policy = np.zeros((env.unwrapped.nS, env.unwrapped.nA))
for s in range(env.unwrapped.nS):
a = np.argmax(v2q(env, v, s, gamma))
policy[s][a] = 1.
return policy, v
if __name__ == '__main__':
env = gym.make('FrozenLake-v0')
env = env.unwrapped
random_policy = np.ones((env.unwrapped.nS, env.unwrapped.nA)) / env.unwrapped.nA
episode_rewards = [play_policy(env, random_policy) for _ in range(100)]
print("隨機策略 平均獎勵 :{}".format(np.mean(episode_rewards)))
print('狀態價值函數:')
v_random = evaluate_policy(env, random_policy)
print(v_random.reshape(4, 4))
print('動作價值函數:')
q_random = v2q(env, v_random)
print(q_random)
policy = random_policy.copy()
optimal = improve_policy(env, v_random, policy)
if optimal:
print('無更新, 最優策略爲:')
else:
print('有更新,最優策略爲:')
print(policy)
# 利用策略迭代求解最優策略
policy_pi, v_pi = iterate_policy(env)
print('狀態價值函數 = ')
print(v_pi.reshape(4, 4))
print('最優策略 = ')
print(np.argmax(policy_pi, axis=1).reshape(4, 4))
print('價值迭代 平均獎勵:{}'.format(play_policy(env, policy_pi)))
隨機策略 平均獎勵 :0.04
狀態價值函數:
[[0.0139372 0.01162942 0.02095187 0.01047569]
[0.01624741 0. 0.04075119 0. ]
[0.03480561 0.08816967 0.14205297 0. ]
[0. 0.17582021 0.43929104 0. ]]
動作價值函數:
[[0.01470727 0.01393801 0.01393801 0.01316794]
[0.00852221 0.01162969 0.01086043 0.01550616]
[0.02444416 0.0209521 0.02405958 0.01435233]
[0.01047585 0.01047585 0.00698379 0.01396775]
[0.02166341 0.01701767 0.0162476 0.01006154]
[0. 0. 0. 0. ]
[0.05433495 0.04735099 0.05433495 0.00698396]
[0. 0. 0. 0. ]
[0.01701767 0.04099176 0.03480569 0.04640756]
[0.0702086 0.11755959 0.10595772 0.05895286]
[0.18940397 0.17582024 0.16001408 0.04297362]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]
[0.08799662 0.20503708 0.23442697 0.17582024]
[0.25238807 0.53837042 0.52711467 0.43929106]
[0. 0. 0. 0. ]]
有更新,最優策略爲:
[[1. 0. 0. 0.]
[0. 0. 0. 1.]
[1. 0. 0. 0.]
[0. 0. 0. 1.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 0. 0. 1.]
[0. 1. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 0. 1. 0.]
[0. 1. 0. 0.]
[1. 0. 0. 0.]]
狀態價值函數 =
[[0.82351246 0.82350689 0.82350303 0.82350106]
[0.82351416 0. 0.5294002 0. ]
[0.82351683 0.82352026 0.76469786 0. ]
[0. 0.88234658 0.94117323 0. ]]
最優策略 =
[[0 3 3 3]
[0 0 0 0]
[3 1 0 0]
[0 2 1 0]]
價值迭代 平均獎勵:1.0