Tensorflow入門(九)——MNIST(CNN實現)
原文鏈接:https://my.oschina.net/u/876354/blog/1926060
本文在原文基礎上進行細微的修改和完善。
關於MNIST的介紹可以參考《Tensorflow入門(八)——MNIST》
在構建AI模型時,一般有以下主要步驟:準備數據、數據預處理、劃分數據集、設定模型、訓練模型、評估優化、模型應用,如下圖所示:

下面 下麪將按照主要步驟進行介紹。
注意: 由於MNIST數據集太經典了,很多深度學習書籍在介紹該入門模型案例時,基本上就是直接下載獲取數據,然後就進行模型訓練,最後得出一個準確率出來。但這樣的入門案例學習後,當要拿自己的數據來訓練模型,卻往往不知該如何處理數據、如何訓練、如何應用。在本文,將分兩種情況進行介紹:
(1)使用MNIST數據(本案例)
(2)使用自己的數據。
下面 下麪將針對模型訓練的各個主要環節進行介紹,便於讀者快速遷移去訓練自己的數據模型。
1. 準備數據
準備數據是訓練模型的第一步,基礎數據可以是網上公開的數據集,也可以是自己的數據集。視覺、語音、語言等各種型別的數據在網上都能找到相應的數據集。
(1)使用MNIST數據(本案例)
MNIST數據集由於非常經典,已整合在tensorflow裏面,可以直接載入使用,也可以從MNIST的官網上(http://yann.lecun.com/exdb/mnist/) 直接下載數據集,程式碼如下:
# 從tensorflow.examples.tutorials.mnist引入模組。這是TensorFlow爲了教學MNIST而提前編制 編製的程式
from tensorflow.examples.tutorials.mnist import input_data
# 從MNIST_data/中讀取MNIST數據。這條語句在數據不存在時,會自動執行下載
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
整合或下載的MNIST數據集已經是打好標籤了,直接使用就行。
(2)使用自己的數據
如果是使用自己的數據集,在準備數據時的重要工作是「標註數據」,也就是對數據進行打標籤,主要的標註方式有:
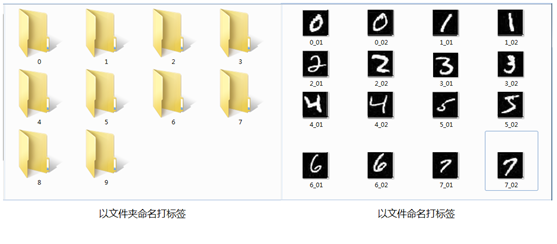
① 整個檔案打標籤。例如MNIST數據集,每個影象只有1個數字,可以從0至9建10個資料夾,裏面放相應數位的影象;也可以定義一個規則對影象進行命名,如按標籤+序號命名;還可以在數據庫裏面建立一張對應表,儲存檔名與標籤之間的關聯關係。如下圖:
② 圈定區域打標籤。例如ImageNet的物體識別數據集,由於每張圖片上有各種物體,這些物體位於不同位置,因此需要圈定某個區域進行標註,目前比較流行的是VOC2007、VOC2012數據格式,這是使用xml檔案儲存圖片中某個物體的名稱(name)和位置資訊(xmin,ymin,xmax,ymax)。
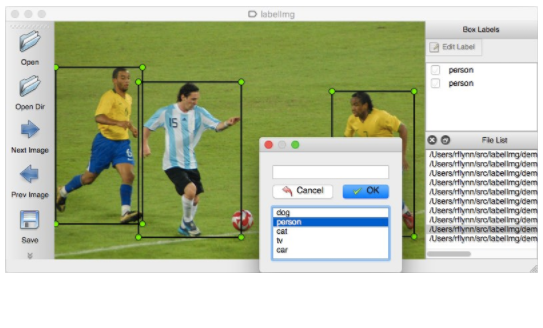
如果圖片很多,一張一張去計算位置資訊,然後編寫xml檔案,實在是太耗時耗力了。所幸,有一位大神開源了一個數據標註工具labelImg(https://github.com/tzutalin/labelImg),只要在介面上畫框標註,就能自動生成VOC格式的xml檔案了,非常方便,如下圖所示:
③ 數據截段打標籤。針對語音識別、文字識別等,有些是將數據截成一段一段的語音或句子,然後在另外的檔案中記錄對應的標籤資訊。
2. 數據預處理
在準備好基礎數據之後,需要根據模型需要對基礎數據進行相應的預處理。
(1)使用MNIST數據(本案例)
由於MNIST數據集的尺寸統一,只有黑白兩種畫素,無須再進行額外的預處理,直接拿來建模型就行。
(2)使用自己的數據
而如果是要訓練自己的數據,根據模型需要一般要進行以下預處理:

a. 統一格式: 即統一基礎數據的格式,例如影象數據集,則全部統一爲jpg格式;語音數據集,則全部統一爲wav格式;文字數據集,則全部統一爲UTF-8的純文字格式等,方便模型的處理;
b. 調整尺寸: 根據模型的輸入要求,將樣本數據全部調整爲統一尺寸。例如LeNet模型是32x32,AlexNet是224x224,VGG是224x224等;
c. 灰度化: 根據模型需要,有些要求輸入灰度影象,有些要求輸入RGB彩色影象;
d. 去噪平滑: 爲提升輸入影象的品質,對影象進行去噪平滑處理,可使用中值濾波器、高斯濾波器等進行影象的去噪處理。如果訓練數據集的影象品質很好了,則無須作去噪處理;
e. 其它處理: 根據模型需要進行直方圖均衡化、二值化、腐蝕、膨脹等相關的處理;
f. 樣本增強: 有一種觀點認爲神經網路是靠數據喂出來的,如果能夠增加訓練數據的樣本量,提供海量數據進行訓練,則能夠有效提升演算法的品質。常見的樣本增強方式有:水平翻轉影象、隨機裁剪、平移變換,顏色、光照變換等,如下圖所示:

3. 劃分數據集
在訓練模型之前,需要將樣本數據劃分爲訓練集、測試集,有些情況下還會劃分爲訓練集、測試集、驗證集。
(1)使用MNIST數據(本案例)
本案例要訓練模型的MNIST數據集,已經提供了訓練集、測試集,程式碼如下:
# 提取訓練集、測試集
train_xdata = mnist.train.images
test_xdata = mnist.test.images
# 提取標籤數據
train_labels = mnist.train.labels
test_labels = mnist.test.labels
(2)使用自己的數據
如果是要劃分自己的數據集,可使用scikit-learn工具進行劃分,程式碼如下:
from sklearn.model_selection import train_test_split
# 隨機選取75%的數據作爲訓練樣本,其餘25%的數據作爲測試樣本
# X_data:數據集
# y_labels:數據集對應的標籤
X_train, X_test, y_train, y_test = train_test_split(X_data, y_labels, test_size=0.25, random_state=33)
4. 設定模型
接下來是選擇模型、設定模型參數,建議先閱讀深度學習經典模型的文章,可以參考《Tensorflow入門(六)——初識折積神經網路(CNN)》,便於快速掌握深度學習模型的相關知識。
(1)選擇模型
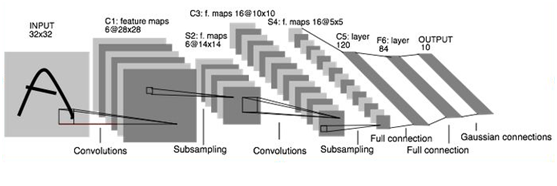
本案例將採用LeNet模型來訓練MNIST手寫數位模型,LeNet是一個經典折積神經網路模型,結構簡單,針對MNIST這種簡單的數據集可達到比較好的效果,LeNet模型的原理介紹請見文章《Tensorflow入門(七)——CNN經典模型:LeNet》,網路結構圖如下:
(2)設定參數
在訓練模型時,一般要設定的參數有:
step_cnt = 5000 # 訓練模型的迭代步數
batch_size = 100 # 每次迭代批次取樣本數據的量
learning_rate = 0.001 # 學習率
除此之外還有折積層權重和偏置、池化層權重、全聯接層權重和偏置、優化函數等等,根據模型需要進行設定。
5. 訓練模型
接下來便是根據選擇好的模型,構建網路,然後開始訓練。
(1)構建模型
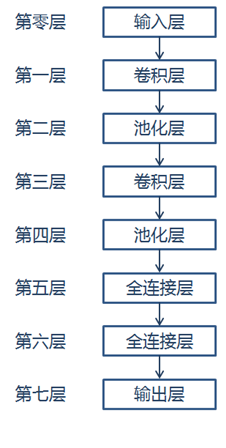
本案例按照LeNet的網路模型結構,構建網路模型,網路結構如下:
程式碼如下:
# 訓練數據,佔位符
x = tf.placeholder("float", shape=[None, 784])
# 訓練的標籤數據,佔位符
y_ = tf.placeholder("float", shape=[None, 10])
# 將樣本數據轉爲28x28
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 保留概率,用於 dropout 層
keep_prob = tf.placeholder(tf.float32)
# 第一層:折積層
# 折積核尺寸爲5x5,通道數爲1,深度爲32,移動步長爲1,採用ReLU激勵函數
conv1_weights = tf.get_variable("conv1_weights", [5, 5, 1, 32], initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("conv1_biases", [32], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(x_image, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
# 第二層:最大池化層
# 池化核的尺寸爲2x2,移動步長爲2,使用全0填充
pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第三層:折積層
# 折積核尺寸爲5x5,通道數爲32,深度爲64,移動步長爲1,採用ReLU激勵函數
conv2_weights = tf.get_variable("conv2_weights", [5, 5, 32, 64], initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("conv2_biases", [64], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
# 第四層:最大池化層
# 池化核尺寸爲2x2, 移動步長爲2,使用全0填充
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第五層:全連線層
fc1_weights = tf.get_variable("fc1_weights", [7 * 7 * 64, 1024], initializer=tf.truncated_normal_initializer(stddev=0.1))
fc1_baises = tf.get_variable("fc1_baises", [1024], initializer=tf.constant_initializer(0.1))
pool2_vector = tf.reshape(pool2, [-1, 7 * 7 * 64])
fc1 = tf.nn.relu(tf.matmul(pool2_vector, fc1_weights) + fc1_baises)
# Dropout層(即按keep_prob的概率保留數據,其它丟棄),以防止過擬合
fc1_dropout = tf.nn.dropout(fc1, keep_prob)
# 第六層:全連線層
# 神經元節點數1024, 分類節點10
fc2_weights = tf.get_variable("fc2_weights", [1024, 10], initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2_biases = tf.get_variable("fc2_biases", [10], initializer=tf.constant_initializer(0.1))
fc2 = tf.matmul(fc1_dropout, fc2_weights) + fc2_biases
# 第七層:輸出層
y_conv = tf.nn.softmax(fc2)
(2)訓練模型
在訓練模型時,需要選擇優化器,也就是說要告訴模型以什麼策略來提升模型的準確率,一般是選擇交叉熵損失函數,然後使用優化器在反向傳播時最小化損失函數,從而使模型的品質在不斷迭代中逐步提升。
程式碼如下:
# 定義交叉熵損失函數
# y_ 爲真實標籤
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1]))
# 選擇優化器,使優化器最小化損失函數
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
# 返回模型預測的最大概率的結果,並與真實值作比較
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 用平均值來統計測試準確率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 訓練模型
saver = tf.train.Saver()
model_dir = ''
with tf.Session() as sess:
tf.global_variables_initializer().run()
for step in range(step_cnt):
batch = mnist.train.next_batch(batch_size)
if step % 100 == 0:
# 每迭代100步進行一次評估,輸出結果,儲存模型,便於及時瞭解模型訓練進展
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g" % (step, train_accuracy))
saver.save(sess, model_dir + '/my_mnist_model.ctpk', global_step=step)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.8})
# 使用測試數據測試準確率
print("test accuracy %g" % accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
訓練的結果如下,由於MNIST數據集比較簡單,模型訓練很快就達到99%的準確率,如下圖所示:
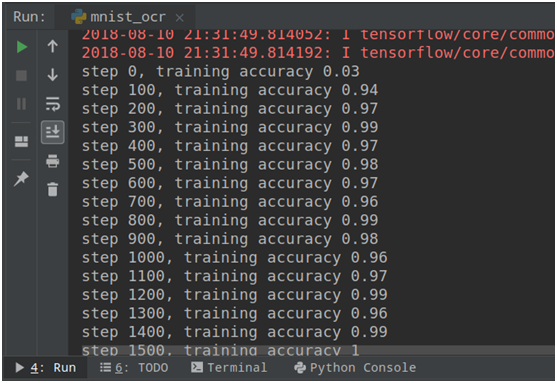
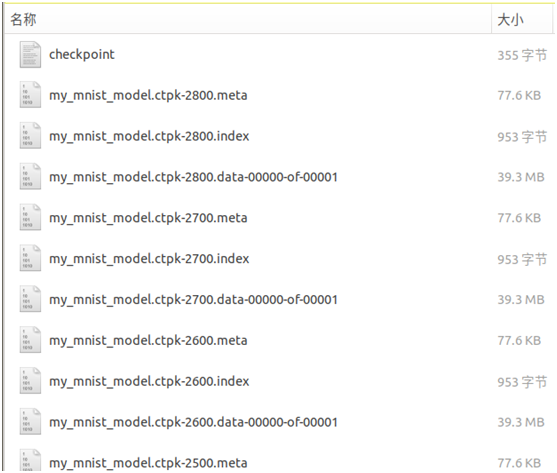
模型訓練後儲存的結果如下圖所示:
6. 評估優化
在使用訓練數據完成模型的訓練之後,再使用測試數據進行測試,瞭解模型的泛化能力,程式碼如下:
# 使用測試數據測試準確率
test_acc = accuracy.eval(feed_dict={x: test_xdata, y_: test_labels, keep_prob: 1.0})
print("test accuracy %g" % test_acc)
模型測試結果如下:
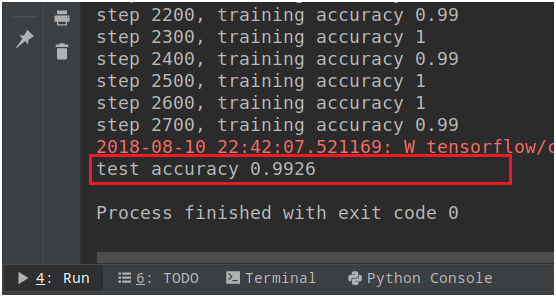
7. 模型應用
模型訓練完成後,將模型儲存起來,當要實際應用時,則通過載入模型,輸入影象進行應用。程式碼如下:
# 載入 MNIST 模型
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint(model_dir))
# 隨機提取 MNIST 測試集的一個樣本數據和標籤
test_len = len(mnist.test.images)
test_idx = random.randint(0, test_len-1)
x_image = mnist.test.images[test_idx]
y = np.argmax(mnist.test.labels[test_idx])
# 跑模型進行識別
y_conv = tf.argmax(y_conv, 1)
pred=sess.run(y_conv, feed_dict={x: [x_image], keep_prob: 1.0})
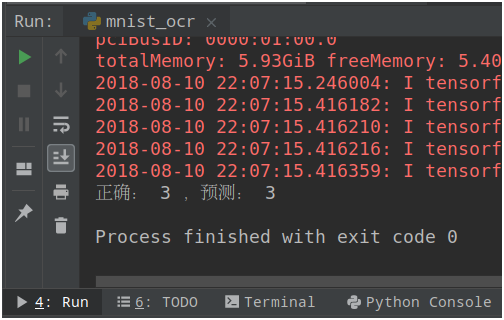
print('正確:', y, ',預測:', pred[0])
使用模型進行測試的結果如下圖:
至此,一個完整的模型訓練和應用的過程就介紹完了。
8. 完整程式碼
# coding: utf-8
# 基於 LeNet5 的 MNIST 手寫數位識別模型
import numpy as np
import random
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 數據集路徑
data_dir = 'MNIST_data/'
# 自動下載 MNIST 數據集
mnist = input_data.read_data_sets(data_dir, one_hot=True)
# 如果自動下載失敗,則手工從官網上下載 MNIST 數據集,然後進行載入
# 下載地址 http://yann.lecun.com/exdb/mnist/
# mnist=input_data.read_data_sets(data_dir,one_hot=True)
# 提取訓練集、測試集
train_xdata = mnist.train.images
test_xdata = mnist.test.images
# 提取標籤數據
train_labels = mnist.train.labels
test_labels = mnist.test.labels
# 訓練數據,佔位符
x = tf.placeholder("float", shape=[None, 784])
# 訓練的標籤數據,佔位符
y_ = tf.placeholder("float", shape=[None, 10])
# 將樣本數據轉爲28x28
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 保留概率,用於 dropout 層
keep_prob = tf.placeholder(tf.float32)
# 模型的相關參數
step_cnt = 5000 # 訓練模型的迭代次數
batch_size = 100 # 每次迭代時,批次獲取樣本的數據量
learning_rate = 0.001 # 學習率
# 模型儲存路徑
model_dir = 'model'
# LeNet5 網路模型
def lenet_network():
# 第一層:折積層
# 折積核尺寸爲5x5,通道數爲1,深度爲32,移動步長爲1,採用ReLU激勵函數
conv1_weights = tf.get_variable("conv1_weights", [5, 5, 1, 32],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("conv1_biases", [32], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(x_image, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
# 第二層:最大池化層
# 池化核的尺寸爲2x2,移動步長爲2,使用全0填充
pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第三層:折積層
# 折積核尺寸爲5x5,通道數爲32,深度爲64,移動步長爲1,採用ReLU激勵函數
conv2_weights = tf.get_variable("conv2_weights", [5, 5, 32, 64],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("conv2_biases", [64], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
# 第四層:最大池化層
# 池化核尺寸爲2x2, 移動步長爲2,使用全0填充
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第五層:全連線層
fc1_weights = tf.get_variable("fc1_weights", [7 * 7 * 64, 1024],
initializer=tf.truncated_normal_initializer(stddev=0.1))
fc1_baises = tf.get_variable("fc1_baises", [1024], initializer=tf.constant_initializer(0.1))
pool2_vector = tf.reshape(pool2, [-1, 7 * 7 * 64])
fc1 = tf.nn.relu(tf.matmul(pool2_vector, fc1_weights) + fc1_baises)
# Dropout層(即按keep_prob的概率保留數據,其它丟棄),以防止過擬合
fc1_dropout = tf.nn.dropout(fc1, keep_prob)
# 第六層:全連線層
fc2_weights = tf.get_variable("fc2_weights", [1024, 10],
initializer=tf.truncated_normal_initializer(stddev=0.1)) # 神經元節點數1024, 分類節點10
fc2_biases = tf.get_variable("fc2_biases", [10], initializer=tf.constant_initializer(0.1))
fc2 = tf.matmul(fc1_dropout, fc2_weights) + fc2_biases
# 第七層:輸出層
y_conv = tf.nn.softmax(fc2)
return y_conv
# 訓練模型
def train_model():
# 載入 LeNet5 網路結構
y_conv = lenet_network()
# 定義交叉熵損失函數
# y_ 爲真實標籤
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1]))
# 選擇優化器,使優化器最小化損失函數
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
# 返回模型預測的最大概率的結果,並與真實值作比較
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 用平均值來統計測試準確率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 訓練模型
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
for step in range(step_cnt):
batch = mnist.train.next_batch(batch_size)
if step % 100 == 0:
# 每迭代100步進行一次評估,輸出結果,儲存模型,便於及時瞭解模型訓練進展
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g" % (step, train_accuracy))
saver.save(sess, model_dir + '/my_mnist_model.ctpk', global_step=step)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.8})
# 使用測試數據測試準確率
test_acc = accuracy.eval(feed_dict={x: test_xdata, y_: test_labels, keep_prob: 1.0})
print("test accuracy %g" % test_acc)
# 模型測試應用
def test_model():
# 載入 LeNet5 網路結構
y_conv = lenet_network()
# 載入 MNIST 模型
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint(model_dir))
# 隨機提取 MNIST 測試集的一個樣本數據和標籤
test_len = len(mnist.test.images)
test_idx = random.randint(0, test_len - 1)
x_image = mnist.test.images[test_idx]
y = np.argmax(mnist.test.labels[test_idx])
# 跑模型進行識別
y_conv = tf.argmax(y_conv, 1)
pred = sess.run(y_conv, feed_dict={x: [x_image], keep_prob: 1.0})
print('正確:', y, ',預測:', pred[0])
if __name__ == "__main__":
# 訓練模型
train_model()
# 測試應用模型
# test_model()
該程式碼執行後預設爲訓練模型,若要測試模型,則僅需將最後一段改爲:
if __name__ == "__main__":
# 訓練模型
# train_model()
# 測試應用模型
test_model()