jstl <x:parse>標籤
2019-10-16 22:12:34
<x:parse>標籤用於解析通過屬性或標籤主體指定的XML資料。
屬性
<x:out>標籤具有以下屬性 -
| 屬性 | 描述 | 必需 | 預設 |
|---|---|---|---|
var |
包含解析的XML資料的變數 | 否 | — |
xml |
要解析的文件的文字(String或Reader) |
否 | 主體 |
systemId |
用於解析文件的系統識別符號URI | 否 | — |
filter |
要應用於源文件的過濾器 | 否 | — |
doc |
要解析的XML文件 | 否 | page |
scope |
在var屬性中指定的變數的範圍 |
否 | page |
varDom |
包含解析的XML資料的變數 | 否 | page |
scopeDom |
varDom屬性中指定的變數的範圍 |
否 | — |
範例
以下範例顯示了如何使用解析來讀取外部XML檔案 -
下面來看看如何從給定文件的正文解析XML。假設有以下內容放在books.xml檔案中 -
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book>
<name>Padam History</name>
<author>Maxsu</author>
<price>69</price>
</book>
<book>
<name>Great Mistry</name>
<author>Newsu</author>
<price>299</price>
</book>
</books>
編寫一個JSP檔案:xml_parse.jsp 如下所示:
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<%@ taglib prefix="x" uri="http://java.sun.com/jsp/jstl/xml"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>jstl x:parse標籤範例</title>
</head>
<body>
<div style="margin: auto; width: 90%">
<h3>圖書資訊:</h3>
<c:import var="bookInfo" url="http://localhost:8080/jstl/books.xml" />
<x:parse xml="${bookInfo}" var="output" />
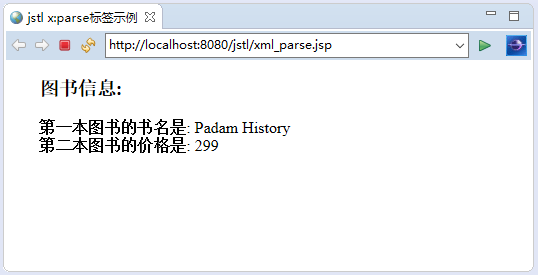
<b>第一本圖書的書名是</b>:
<x:out select="$output/books/book[1]/name" />
<br> <b>第二本圖書的價格是</b>:
<x:out select="$output/books/book[2]/price" />
</div>
</body>
</html>
執行上述專案程式碼,得到以下結果如下 -