C++總複習--9--C++程式設計--MySQL數據庫
C++總複習--9--C++程式設計--MySQL數據庫
1.SQL語句的編寫
(1)DDL
create drop alter show
(2)DML
insert delete update select
(3)DCL
grant revoke
2.MySQL儲存引擎
(1)MyISAM
(2) InnoDB
3.事務
1.SQL
(1)DDL 數據定義語言
create drop(回收) alter(修改) show
- 建立
create 結構標識(database,table,index) name;
drop 結構標識 name;
(2)DML 數據操作語言
inster delete update select
1.新增數據
insert into table_name values (xxx),(xxx);(values代表數據集合)
(*****)load 大批次插入
load data infile 「xxx/xxx/xxx(檔案路徑)」 into table table_name;
2.刪除數據
delete from table_name [where];
truncate(DDL語句)(無log,所以不能恢復)
truncate table table_name ;
3.修改數據
update table_name set field_name = new_val [where];
(field_name欄位名稱 ,new_val 新的數據)
4.查詢數據
(1)普通查詢
Select * from table_name [where];
Select field_1,field_2,field_3 from table_name [where];
(2)去重 distinct
Distinct field_1;
(3)排序 order by desc(降序) | asc(升序)
select field from table_name [where] order by sort_field [desc | asc];
5.分組 group by
Select sum(xxx) from table_name
Group by field;(filed比如按年齡來劃分,就寫age)
(1)多表查詢
(1.1)等值查詢
select field_1,...,field_n
from table_name_1,...,table_name_n
[where ];
等值查詢:次數m*n
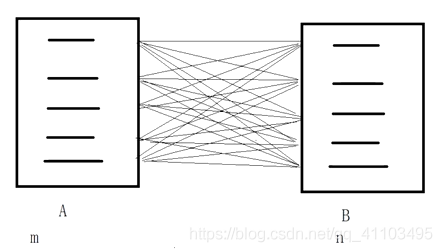
(1.2)連線查詢
縮小左右表的範圍,縮小後的範圍內進行匹配
m/x n/y mn/xy
(1.2.1)外連線查詢
左外連線查詢 範圍縮小後 左表的數據全部存在
右表匹配成功 用右表的數據
右表匹配失敗 右表補NULL
右外連線查詢 範圍縮小後 右表的數據全部存在
左表匹配成功 用左表的數據
左表匹配失敗 左表補NULL
全外連線查詢 範圍縮小後 右表的數據全部存在
左右表匹配成功 用左表的數據
左右表匹配失敗 對應一方補NULL
(1.2.2)內連線查詢
內連線查詢
範圍縮小後,匹配成功的項
6.聯合查詢 union (有去重) | union all
(3)DCL 數據控制語言
1.授予許可權
grant privileges on DB_NAME.TABLE_NAME to user_name;
2.回收許可權
revoke privileges on DB_NAME.TABLE_NAME from user_name;
MySQL
2.儲存引擎
數據的一種儲存方式
MyISAM
不支援外來鍵,不支援事務,支援全文索引,B+樹,表鎖
InnoDB
支援外來鍵,支援事務,不支援全文索引,B+樹,行鎖
MEMORY
記憶體中,臨時表,varchar當成char 雜湊索引
不支援text和blob欄位,如果儲存該型別欄位,交給MyISAM這個儲存引擎,數據存放磁碟上
ARCHIVE
數據1:10壓縮儲存,適用於日誌數據
只支援 insert和select
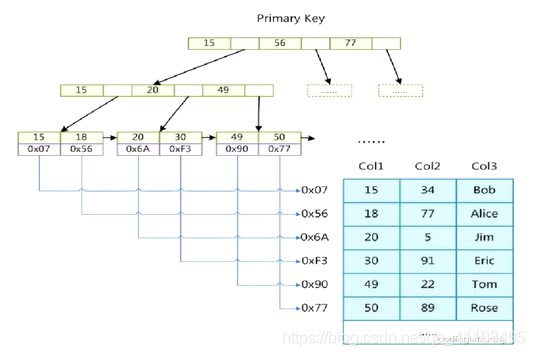
MyISAM B+樹 非聚集索引
索引和數據分離開來設計
葉子結點 儲存數據的地址
關鍵字不重複Dev,可做主索引
.frm 建立表的基本資訊
.myi 表對應的索引
.myd 儲存數據的檔案
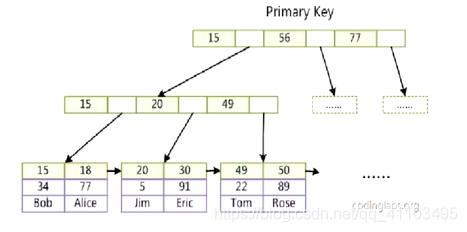
InnoDB 聚集索引
數據和索引結合
把索引當成數據的一部分儲存
葉子結點 存放數據
1.建立一個InnoDB的表
Insert 數據
系統建立索引
- 主鍵 主鍵索引
- 唯一鍵 唯一索引
- 新增一個隱藏的欄位,6個位元組,行id,auto_increment(可自增長型別)
輔助索引
允許關鍵字重複
葉子結點:數據的地址
2.索引的優化
1.哪種情況應該建立索引
2.哪種情況不應該建立索引
3.索引的分類
組合索引
最左字首原則
4.索引的注意事項
(1)索引不會包含有NULL值的列
(2)使用短索引
(3)索引列排序,如果where中用了索引,order by中列是不會使用索引的。
(4)like語句操作,like 「%aaa%」不會使用索引,like 「aaa%」可以使用索引
(5)不要在列上進行運算,where YEAR(adddate)<2007,不會用到索引,
where adddate<’2007-01-01’,會用到索引
3.事務
一組SQL語言的集合
A 原子性 要麼全部成功 要麼全部失敗
C 一制性 保證數據的完整性約束
I 隔離型 消除事務間的相互影響
D 永續性 保證事務執行的結果能在磁碟上永久的儲存
1.隔離性
(1)沒有隔離性會發生什麼情況
髒讀 A事務讀取了B事務執行過程中的結果
不可重複讀 修改 A事務讀取了B事務執行前和執行後兩個不同階段的結果
幻讀 insert | delete A事務讀取了B事務執行前和執行後兩個不同階段的結果
(2)四個隔離級別
未提交讀 髒讀 不可重複讀 幻讀
已提交讀 不可重複讀 幻讀
可重複讀 幻讀(是用間隙鎖解決的) MySQL
可序列化
2.原子性
日誌
redo log 事務將要執行的每一步操作
undo log 事務執行過程中的每一個狀態點
鎖機制 機製
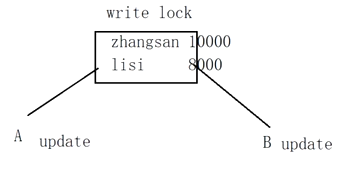
- MyISAM 表鎖 (非索引)
- read 讀鎖 共用讀鎖
- write 寫鎖 獨佔寫鎖
2.InnoDB 行鎖(索引支援)
1.read 讀鎖 共用鎖
2.write 寫鎖 排它鎖
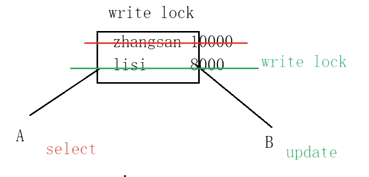
樂觀鎖和悲觀鎖
間隙鎖
觸發器(2*3=6種)
time before after
event Insert delete update
能觸發觸發器
insert:
insert replace load
delete:
delete
update:
update
儲存過程和儲存函數